En este tutorial se describe cómo habilitar la replicación asíncrona de discos persistentes (replicación asíncrona de PD) en dos Google Cloud regiones como solución de recuperación tras desastres (DR), y cómo poner en marcha las instancias de DR en caso de desastre.
A los efectos de este documento, un desastre es un evento en el que falla o deja de estar disponible un clúster de alta disponibilidad (HA) de una base de datos principal. Una base de datos principal puede fallar si falla la región en la que se encuentra o si se vuelve inaccesible.
Este tutorial está dirigido a arquitectos, administradores e ingenieros de bases de datos.
Recuperación tras fallos en Google Cloud
En Google Cloud, la recuperación ante desastres se centra en mantener la continuidad del procesamiento, sobre todo cuando una región falla o deja de estar accesible. Hay varias opciones de implementación para el sitio de recuperación tras desastres, que se determinarán en función de los requisitos de objetivo de punto de recuperación (RPO) y objetivo de tiempo de recuperación (RTO). En este tutorial se explica una de las opciones para replicar discos de máquinas virtuales (VMs) de la región principal a la de recuperación ante desastres.
Recuperación tras fallos para la replicación asíncrona de Persistent Disk
La réplica asíncrona de Persistent Disk (réplica asíncrona de PD) ofrece replicación de almacenamiento en bloques con RPO y RTO bajos para la recuperación tras fallos activa-pasiva entre regiones.
La réplica asíncrona de PD es una opción de almacenamiento que proporciona la replicación asíncrona de datos entre dos regiones. En el improbable caso de una interrupción regional, la replicación asíncrona de PD te permite conmutar por error tus datos a una región secundaria y reiniciar tus cargas de trabajo en esa región.
La réplica asíncrona de PD replica los datos de un disco conectado a una carga de trabajo en ejecución, conocido como disco principal, en otro disco situado en otra región. El disco que recibe los datos replicados se denomina disco secundario.
Para asegurarse de que las réplicas de todos los discos conectados a cada nodo de SQL Server contengan datos del mismo momento, los discos se añaden a un grupo de coherencia. Los grupos de coherencia te permiten realizar pruebas de recuperación ante desastres en varios discos.
Arquitectura de recuperación tras fallos
En el caso de la réplica asíncrona de PD, el siguiente diagrama muestra una arquitectura mínima que admite la alta disponibilidad de la base de datos en una región primaria y la replicación de discos de la región primaria a la región de recuperación tras fallos.
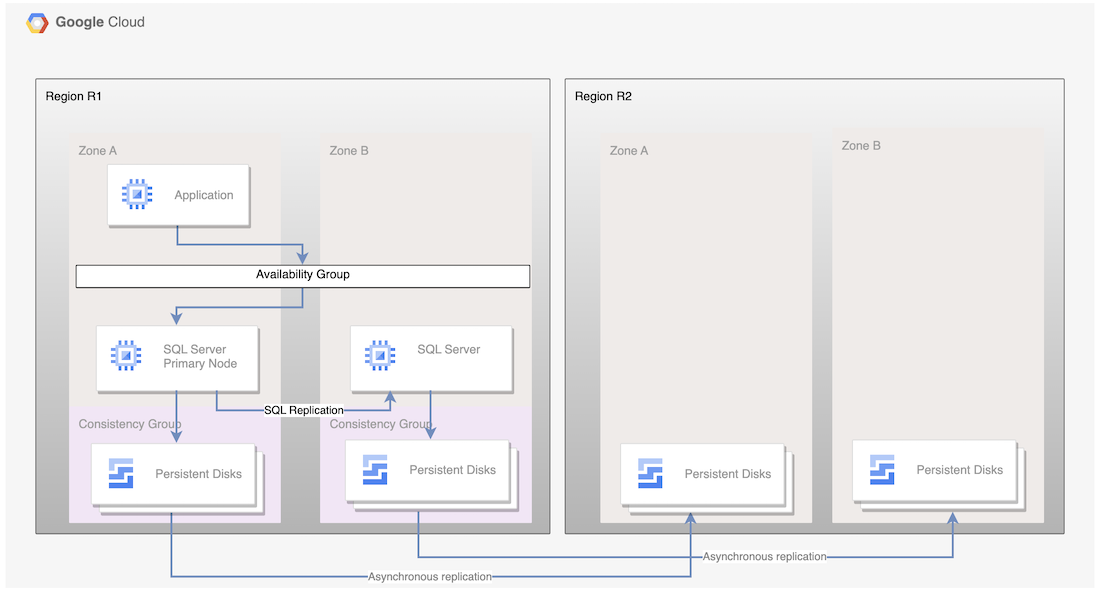
Imagen 1. Arquitectura de recuperación tras desastres con Microsoft SQL Server y replicación asíncrona de PD
Esta arquitectura funciona de la siguiente manera:
- Dos instancias de Microsoft SQL Server, una principal y otra de reserva, forman parte de un grupo de disponibilidad y están ubicadas en la misma región (R1), pero en zonas diferentes (zonas A y B). Las dos instancias de R1 coordinan sus estados mediante el modo de confirmación síncrona. El modo síncrono se usa porque admite una alta disponibilidad y mantiene un estado de datos coherente.
- Los discos de ambos nodos de SQL se añaden a grupos de coherencia y se replican en la región de recuperación ante desastres R2. La infraestructura subyacente replica los datos de forma asíncrona.
- Solo se replican los discos en la región R2. Durante la recuperación ante desastres, se crean máquinas virtuales y los discos replicados se vinculan a las máquinas virtuales para poner los nodos online.
Proceso de recuperación tras fallos
El proceso de recuperación ante desastres se inicia cuando una región deja de estar disponible. El proceso de recuperación ante desastres prescribe los pasos operativos que se deben seguir, ya sea de forma manual o automática, para mitigar el fallo de la región y establecer una instancia principal en ejecución en una región disponible.
Un proceso básico de recuperación ante desastres de una base de datos consta de los siguientes pasos:
- La primera región (R1), que ejecuta la instancia de base de datos principal, deja de estar disponible.
- El equipo de Operaciones reconoce formalmente el desastre y decide si es necesario realizar una conmutación por error.
- Si es necesaria una conmutación por error, se termina la replicación de disco de la región principal a la de recuperación tras desastres. Se crea una VM a partir de las réplicas del disco y se pone en línea.
- Se valida la nueva base de datos principal de la región de recuperación ante desastres (R2) y se pone en línea para habilitar la conectividad.
- Los usuarios reanudan el procesamiento en la nueva base de datos principal y acceden a la instancia principal de R2.
Aunque este proceso básico vuelve a establecer una base de datos principal operativa, no establece una arquitectura de alta disponibilidad completa, en la que la nueva base de datos principal tenga un nodo de espera.
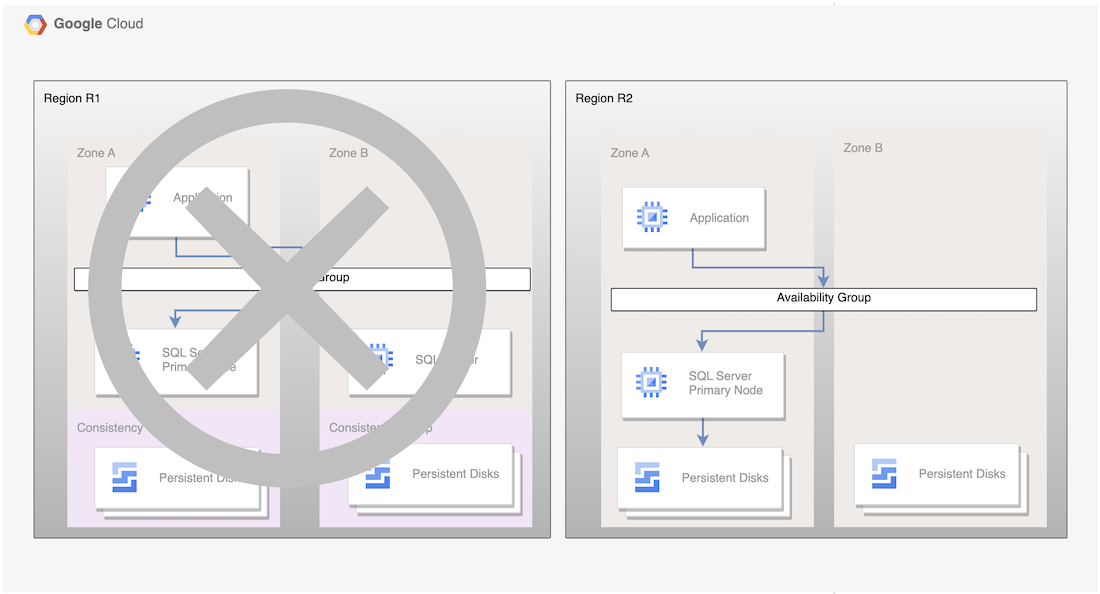
Imagen 2. Implementación de SQL Server tras la recuperación tras fallos con la réplica asíncrona de Persistent Disk
Volver a una región recuperada
Cuando la región principal (R1) vuelva a estar online, puedes planificar y ejecutar el proceso de conmutación por recuperación. El proceso de conmutación por recuperación consta de todos los pasos descritos en este tutorial, pero, en este caso, R2 es el origen y R1 es la región de recuperación.
Elegir una edición de SQL Server
Este tutorial es compatible con las siguientes versiones de Microsoft SQL Server:
- SQL Server 2016 Enterprise Edition
- SQL Server 2017 Enterprise Edition
- SQL Server 2019 Enterprise Edition
- SQL Server 2022 Enterprise Edition
En el tutorial se usa la función de grupos de disponibilidad AlwaysOn de SQL Server.
Si no necesitas una base de datos principal de Microsoft SQL Server con alta disponibilidad y te basta con una sola instancia de base de datos como principal, puedes usar las siguientes versiones de SQL Server:
- SQL Server 2016 Standard Edition
- SQL Server 2017 Standard Edition
- SQL Server 2019 Standard Edition
- SQL Server 2022 Standard Edition
Las versiones 2016, 2017, 2019 y 2022 de SQL Server tienen Microsoft SQL Server Management Studio instalado en la imagen, por lo que no es necesario instalarlo por separado. Sin embargo, en un entorno de producción, te recomendamos que instales una instancia de Microsoft SQL Server Management Studio en una VM independiente de cada región. Si configura un entorno de alta disponibilidad, debe instalar Microsoft SQL Server Management Studio una vez por cada zona para asegurarse de que siga estando disponible si otra zona deja de estarlo.
Configurar la recuperación tras fallos para Microsoft SQL Server
En este tutorial se usa la imagen de sql-ent-2022-win-2022 para Microsoft SQL Server Enterprise.
Para ver una lista completa de las imágenes, consulta Imágenes de SO.
Configurar un clúster de alta disponibilidad de dos instancias
Para configurar la replicación de discos en la región de recuperación tras desastres de SQL Server, primero crea un clúster de alta disponibilidad de dos instancias en una región.
Una instancia actúa como principal y la otra como de reserva. Para completar este paso, sigue las instrucciones que se indican en el artículo sobre cómo configurar grupos de disponibilidad AlwaysOn de SQL Server.
En este tutorial se usa us-central1 para la región principal (R1).
Si has seguido los pasos descritos en Configurar grupos de disponibilidad AlwaysOn de SQL Server, habrás creado dos instancias de SQL Server en la misma región (us-central1). Habrás implementado una instancia de SQL Server principal (node-1) en us-central1-a y una instancia de espera (node-2) en us-central1-b.
Habilitar la replicación asíncrona de discos
Una vez que se hayan creado y configurado todas las VMs, habilita la copia de discos entre regiones creando un grupo de coherencia para todos los discos conectados a las VMs. Los datos se copian de los discos de origen a los discos en blanco recién creados en la región designada.
Crea un grupo de coherencia para los nodos de SQL y el controlador de dominio. Una de las limitaciones de un disco zonal es que los grupos de coherencia no pueden abarcar varias zonas.
gcloud compute resource-policies create disk-consistency-group node-1-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group node-2-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group witness-disk-const-grp \ --region=$REGION
Añade los discos de las máquinas virtuales principal y de espera a los grupos de coherencia correspondientes.
gcloud compute disks add-resource-policies node-1 \ --zone=$REGION-a \ --resource-policies=node-1-disk-const-grp gcloud compute disks add-resource-policies node-1-datadisk \ --zone=$REGION-a \ --resource-policies=node-1-disk-const-grp gcloud compute disks add-resource-policies node-2 \ --zone=$REGION-b \ --resource-policies=node-2-disk-const-grp gcloud compute disks add-resource-policies node-2-datadisk \ --zone=$REGION-b \ --resource-policies=node-2-disk-const-grp gcloud compute disks add-resource-policies witness \ --zone=$REGION-c \ --resource-policies=witness-disk-const-grp
Crear discos secundarios en blanco en la región emparejada
DR_REGION="us-west1" gcloud compute disks create node-1-replica \ --zone=$DR_REGION-a \ --size=50 \ --primary-disk=node-1 \ --primary-disk-zone=$REGION-a gcloud compute disks create node-1-datadisk-replica \ --zone=$DR_REGION-a \ --size=$PD_SIZE \ --primary-disk=node-1-datadisk \ --primary-disk-zone=$REGION-a gcloud compute disks create node-2-replica \ --zone=$DR_REGION-b \ --size=50 \ --primary-disk=node-2 \ --primary-disk-zone=$REGION-b gcloud compute disks create node-2-datadisk-replica \ --zone=$DR_REGION-b \ --size=$PD_SIZE \ --primary-disk=node-2-datadisk \ --primary-disk-zone=$REGION-b gcloud compute disks create witness-replica \ --zone=$DR_REGION-c \ --size=50 \ --primary-disk=witness \ --primary-disk-zone=$REGION-c
Inicia la replicación del disco. Los datos se replican del disco principal al disco en blanco recién creado en la región de recuperación ante desastres.
gcloud compute disks start-async-replication node-1 \ --zone=$REGION-a \ --secondary-disk=node-1-replica \ --secondary-disk-zone=$DR_REGION-a gcloud compute disks start-async-replication node-1-datadisk \ --zone=$REGION-a \ --secondary-disk=node-1-datadisk-replica \ --secondary-disk-zone=$DR_REGION-a gcloud compute disks start-async-replication node-2 \ --zone=$REGION-b \ --secondary-disk=node-2-replica \ --secondary-disk-zone=$DR_REGION-b gcloud compute disks start-async-replication node-2-datadisk \ --zone=$REGION-b \ --secondary-disk=node-2-datadisk-replica \ --secondary-disk-zone=$DR_REGION-b gcloud compute disks start-async-replication witness \ --zone=$REGION-c \ --secondary-disk=witness-replica \ --secondary-disk-zone=$DR_REGION-c
En este punto, los datos deberían replicarse entre las regiones.
El estado de replicación de cada disco debe ser Active.
Simular una recuperación tras fallos
En esta sección, probarás la arquitectura de recuperación tras fallos configurada en este tutorial.
Simular una interrupción del servicio y ejecutar una conmutación por error de recuperación tras desastres
Durante una conmutación por error de recuperación ante desastres, se crean máquinas virtuales en la región de recuperación ante desastres y se les adjuntan los discos replicados. Para simplificar la conmutación por error, puedes usar otra nube privada virtual (VPC) en la región de recuperación ante desastres para la recuperación y, así, usar la misma dirección IP.
Antes de iniciar la conmutación por error, asegúrese de que node-1 sea el nodo principal del grupo de disponibilidad Always On que ha creado. Inicia el controlador de dominio y el nodo principal de SQL Server para evitar problemas de sincronización de datos, ya que los dos nodos están protegidos por dos grupos de coherencia independientes.
Para simular una interrupción, sigue estos pasos:
Crea una VPC de recuperación.
DRVPC_NAME="default-dr" DRSUBNET_NAME="default-recovery" gcloud compute networks create $DRVPC_NAME \ --subnet-mode=custom CIDR = $(gcloud compute networks subnets describe default \ --region=$REGION --format=value\(ipCidrRange\)) gcloud compute networks subnets create $DRSUBNET_NAME \ --network=$DRVPC_NAME --range=$CIDR --region=$DR_REGION
Finaliza la replicación de datos.
PROJECT=$(gcloud config get-value project) gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-1-disk-const-grp \ --zone=$REGION-a gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-2-disk-const-grp \ --zone=$REGION-b gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/witness-disk-const-grp \ --zone=$REGION-c
Detén las VMs de origen en la región principal.
gcloud compute instances stop node-1 \ --zone=$REGION-a gcloud compute instances stop node-2 \ --zone=$REGION-b gcloud compute instances stop witness \ --zone=$REGION-c
Crea VMs en la región de recuperación tras desastres mediante réplicas de disco. Estas máquinas virtuales tendrán la dirección IP de la máquina virtual de origen.
NODE1IP=$(gcloud compute instances describe node-1 --zone $REGION-a --format=value\(networkInterfaces[0].networkIP\)) NODE2IP=$(gcloud compute instances describe node-2 --zone $REGION-a --format=value\(networkInterfaces[0].networkIP\)) WITNESSIP=$(gcloud compute instances describe witness --zone $REGION-a --format=value\(networkInterfaces[0].networkIP\)) gcloud compute instances create node-1 \ --zone=$DR_REGION-a \ --machine-type $MACHINE_TYPE \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $NODE1IP\ --disk=boot=yes,device-name=node-1-replica,mode=rw,name=node-1-replica \ --disk=auto-delete=yes,boot=no,device-name=node-1-datadisk-replica,mode=rw,name=node-1-datadisk-replica gcloud compute instances create witness \ --zone=$DR_REGION-c \ --machine-type=n2-standard-2 \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $WITNESSIP \ --disk=boot=yes,device-name=witness-replica,mode=rw,name=witness-replica
Hemos simulado un corte de servicio y hemos cambiado a la región de recuperación ante desastres. Ahora podemos comprobar si la instancia secundaria funciona correctamente.
Verificar la conectividad de SQL Server
Una vez creadas las VMs, comprueba que las bases de datos se han recuperado correctamente y que el servidor funciona según lo previsto. Para probar la base de datos, ejecutarás una consulta de selección desde la base de datos recuperada.
- Conéctate a la máquina virtual de SQL Server mediante Escritorio remoto.
- Abre SQL Server Management Studio.
- En el cuadro de diálogo Conectar con el servidor, comprueba que el nombre del servidor sea
NODE-1y selecciona Conectar. En el menú Archivo, selecciona Archivo > Nuevo > Consulta con la conexión actual.
USE [bookshelf]; SELECT * FROM Books;