このドキュメントでは、 Google Cloudでの障害復旧の設計と実装を担当するアーキテクトおよび技術担当者を対象に、Microsoft SQL Server の障害復旧(DR)戦略について説明します。
データベースは、ハードウェア障害やネットワーク障害など、さまざまな理由で使用不能になる可能性があります。障害発生時にデータベースへの継続的なアクセスを提供するために、プライマリ データベースのレプリカであるセカンダリ データベースを維持します。セカンダリ データベースを別の場所に配置することで、プライマリ データベースの障害発生時にセカンダリ データベースの可用性を高めることができます。
プライマリ データベースが使用不能になった場合、ミッション クリティカルなアプリはセカンダリ データベースに接続し、最後に同期されたデータを使用してサービスの提供を継続することでダウンタイムを最小限に抑えます。
プライマリ データベースの障害発生時にセカンダリ データベースに切り替えるプロセスをデータベースの障害復旧(DR)といいます。このプロセスでは、プライマリ データベースの障害から復旧するためにセカンダリ データベースを使用します。セカンダリ データベースは、プライマリ データベースとまったく同じ状態か、プライマリ データベースで障害が発生する直前までの状態を反映しているのが理想的です。
データベース DR は企業にとって重要な機能で、ミッション クリティカルなアプリの継続性を維持するうえで欠かせません。ミッション クリティカルなアプリはさまざまな役割を果たしています。たとえば、e コマースでは収益の源泉であり、飛行管理や発電所では信頼できるサービスを継続的に提供しています。また、医療分野では生命維持機能をサポートしています。どの例でも、ミッション クリティカルなアプリは常に使用可能な状態にしておかなければなりません。
Microsoft SQL Server など、ほとんどのデータベース管理システムは障害復旧機能を備えています。このドキュメントでは、SQL Server によって提供される DR 機能を Google Cloudでどのように実装するのかについて説明します。
用語
以下では、このドキュメント全体で使用されている用語について説明します。
一般的な DR アーキテクチャ
次の図は、一般的な DR アーキテクチャのトポロジを示しています。
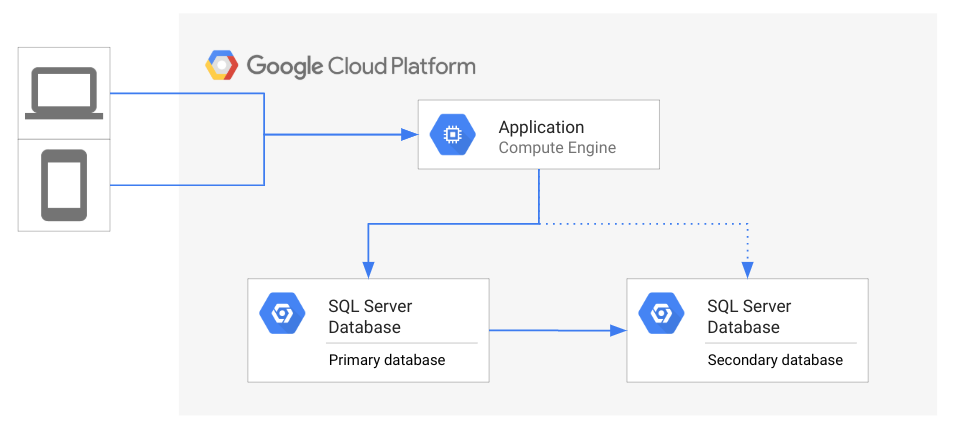
上の図では、アプリがプライマリ データベースにアクセスしている間、セカンダリ データベースは待機状態で、プライマリ データベースの状態をミラーリングしています。クライアントは Google Cloudで実行されるアプリにアクセスしています。
プライマリ データベースが使用不能になった場合、データベース管理者または運用チームは、障害復旧プロセスを開始するかどうか判断します。データベースの障害復旧を開始すると、アプリはセカンダリ データベースに接続します。接続後、アプリはクライアントへのサービス提供を再開します。理想的な状況では、アプリはすぐにセカンダリ データベースに接続するため、クライアントで機能が停止することはありません。障害復旧を開始せず、プライマリ データベースが再びアクセス可能になるまで待つという選択肢もあります。たとえば、障害が断続的に発生している場合は、フェイルオーバーを行うよりも、問題の解決を優先したほうが結果的に早く復旧できることもあります。
プライマリ データベースとセカンダリ データベース
プライマリ データベースには複数のアプリがアクセスしています。プライマリ データベースは、アプリの状態管理のために継続的なサービスを提供しています。セカンダリ データベースはプライマリ データベースに対応し、プライマリ データベースのレプリカとして機能します。セカンダリ データベースのコンテンツが常にプライマリ データベースと完全に一致しているのが理想的ですが、多くの場合、プライマリ データベースで発生したトランザクションの変更は一定の間隔で適用されるため、プライマリ データベースの最新の状態が反映されているとは限りません。データベース テクノロジによっては、プライマリ データベースに複数のセカンダリ データベースが存在する場合もあります。SQL Server では、複数のセカンダリ データベースをプライマリ データベースに関連付けることができます。
障害復旧
プライマリ データベースが使用不能になると、DR はセカンダリ データベースの役割をプライマリ データベースに変更します。複数のセカンダリ データベースがある場合は、手動またはフェイルオーバーの優先リストに基づいてデータベースを選択します。アプリは新しいプライマリ データベースに接続して、アプリの状態を維持します。新しいプライマリ データベースに前のプライマリ データベースの最後の状態が反映されていない場合、アプリは過去の状態から開始することになります(この状態をフラッシュバックともいいます)。
1 つのプライマリ データベースに対して常に 1 つ以上のセカンダリ データベースを用意しておくことが重要です。障害復旧の後、今後の障害復旧に対応できるように新しいセカンダリ データベースを設定しておく必要があります。
フェイルオーバー、スイッチオーバー、フォールバック
プライマリ データベースとセカンダリ データベースの間で役割を切り替えるプロセスとしては、次のような機能があります。
- フェイルオーバー: セカンダリ データベースの役割を新しいプライマリ データベースに移行し、すべてのアプリを接続するプロセス。フェイルオーバーは、プライマリ データベースが使用不能になったときにトリガーされるため、いつ発生するか予測できません。フェイルオーバーは自動的または手動でトリガーするように構成できます。
- スイッチオーバー: フェイルオーバーとは対照的に、プライマリ データベースからセカンダリ データベース(新しいプライマリ データベース)へのスイッチオーバーは、初期テストと定期メンテナンスで意図的に行われます。障害復旧の信頼性を維持するため、DR システムを定期的に切り替えてテストします。
- フォールバック: 元のプライマリ データベースが修復された後に、現在のプライマリ データベースをセカンダリ データベースに戻すプロセス。フォールバックは、フェイルオーバーまたはスイッチオーバーの開始前の状態に戻すために意図的に実行されます。厳密には必要ありませんが、局所性や利用可能なリソースなどの障害復旧要件で行われる場合があります。
Google Cloud ゾーンとリージョン
データベースのようなリソースは Google Cloud のゾーンやリージョンに存在します。各ゾーンはリージョンに属しています。ゾーンは単一障害点ドメインになるため、リージョン内の複数のゾーンに高可用性と耐障害性を備えたリソースを配置することをおすすめします。
リージョン全体の機能停止を防ぐため、障害復旧ではマルチリージョン戦略を使用します。たとえば、プライマリ データベースとセカンダリ データベースを別々のリージョンに配置します。
アクティブ モード: アクティブ / パッシブとアクティブ / アクティブ
プライマリ データベースは読み書きオペレーション(DML オペレーション)用のデータベースで、アプリはこのデータベースにアクセスして状態を管理します。プライマリ データベースはアクティブ データベースといいます。対応するセカンダリ データベースにはプライマリ データベースのコンテンツが複製されますが、このデータベースは、アプリの状態変更オペレーションに使用できないため、パッシブになります。フェイルオーバーまたはスイッチオーバーが開始すると、セカンダリ データベースは新しいプライマリ データベースになり、アクティブ データベースになります。
データベース テクノロジでサポートされている場合、プライマリ データベースとセカンダリ データベースの両方をアクティブにできます。この機能をアクティブ / アクティブ モードといいます。この場合、両方のデータベースが状態管理に使用できるため、アプリはどちらのデータベースにも接続できます。アクティブ / アクティブ モードでは、アクティブ データベースの 1 つが使用不能になってもフェイルオーバーを行う必要はありません。1 つのアクティブ データベースで障害が発生しても、もう一方のアクティブ データベースを引き続き使用できます。SQL Server はこのモードをサポートしていないため、この記事ではアクティブ / アクティブ モードについて説明しません。
スタンバイ モード: ホット、ウォーム、コールド、スタンバイなし
データベースをアクティブ データベースにするには、データベースが稼働状態で、DML ステートメントを実行できる状態にする必要があります。セカンダリ データベースは稼働状態にしておく必要はなく、シャットダウン状態でもかまいません。ただし、稼働していない場合は、プライマリ データベースの役割を引き継ぐ前に、データベースを稼働状態にする必要があるため、障害復旧にかかる時間が長くなります。
セカンダリ データベースにはいくつかの設定方法があります。
- ホット スタンバイ: セカンダリ データベースは稼働状態で、クライアントから接続可能な状態になっています。プライマリ データベースで発生した変更はすぐに適用されます。
- ウォーム スタンバイ: セカンダリ データベースは稼働状態になっていますが、プライマリ データベースで発生した変更がすべて適用されているとは限りません。
- コールド スタンバイ: セカンダリ データベースは稼働状態ではありません。まず、データベースを起動し、利用可能な最新の状態と同期する必要があります。
- スタンバイなし: まず、データベース ソフトウェアをインストールし、その後データベースを起動してプライマリ データベースの変更をすべて適用する必要があります。このモードは、不要なリソースを消費しないため、最も費用のかからないモードになりますが、他のモードと比較すると、新しいプライマリ データベースに切り替わるまでの時間が最も長くなります。
DR 戦略
以下では、Microsoft SQL Server でサポートされる DR 戦略について説明します。
復旧戦略の要素
データベースの障害復旧戦略を選択または実装する際に考慮すべきいくつかの重要な要素があります。障害復旧戦略の目標値はどの要素を重視するかによって異なります。主な要素は次のとおりです。
- 目標復旧時点(RPO): 重大な事象によりアプリからデータが失われている状態が許容される最大期間です。この値はデータの用途によって異なります。RPO は、プライマリ データベースが使用不能になってからの経過時間(秒、分、時間)か、識別可能な処理状態(最後の完全バックアップまたは最後の増分バックアップ)で表すことができます。いずれの場合でも、RPO の要件を満たすために障害復旧戦略で対策を講じる必要があります。最も厳しい条件は、最後に commit されたトランザクションです。これは、プライマリ データベースからセカンダリ データベースへの損失がまったく発生しないことを意味します。
- 目標復旧時間(RTO)。アプリがオフラインであることが許容される最大時間です。この値は通常、サービスレベル契約の中で規定されています。RTO は通常、プライマリ データベースが使用不能になった時点からの期間で表されます。たとえば、アプリは 5 分以内に完全に機能する必要がある、と指定します。最も厳しい条件は即時で、これはアプリユーザーが障害復旧に気づかないことを意味します。
- 単一障害点ドメイン。障害復旧要件で特定のリージョンを単一障害点ドメインにするかどうかは、ご使用の環境やビジネス要件によって異なります。1 つのリージョンが単一障害点ドメインになると判断した場合は、複数のリージョンが関係するように障害復旧を設定する必要があります。たとえば、プライマリ データベースを含むリージョンに障害が発生した場合、別のリージョンのセカンダリ データベースが新しいプライマリ データベースになるように設定します。1 つのゾーンが単一障害点ドメインになると判断した場合は、リージョン内のゾーン間で障害復旧を設定します。ゾーンに障害が発生した場合、障害復旧は 2 番目のゾーンを利用して、新しいプライマリ データベースを使用可能にします。
これらの要素を決める際は、コストと品質のバランスを考慮する必要があります。RTO と RPO を低く設定すると、使用されるアクティブ リソースが多くなり、障害復旧のコストが高くなります。以下では、Microsoft SQL Server データベースの DR 戦略を例に、これらのポイントについて説明します。
SQL Server の DR 戦略
ビジネス継続性とデータベースの復旧 - SQL Server では、障害復旧戦略の実装に使用できる可用性機能について説明しています。
準備
SQL Server は Windows と Linux の両方で動作します。ただし、すべての可用性機能が Linux で利用できるわけではありません。SQL Server には複数のエディションがありますが、すべての可用性機能がすべてのエディションで利用できるわけではありません。
SQL Server ではインスタンスとデータベースを区別します。インスタンスは実行中の SQL Server ソフトウェアですが、データベースは SQL Server インスタンスによって管理されるデータのセットです。
Always On 可用性グループ
Always On 可用性グループはデータベース レベルの保護を提供します。可用性グループには 2 つ以上のレプリカがあります。1 つのレプリカは読み取り / 書き込み権限を持つプライマリ レプリカで、残りのレプリカは読み取り専用のセカンダリ レプリカです。それぞれのデータベース レプリカは、スタンドアロンの SQL Server インスタンスによって管理されます。可用性グループには 1 つ以上のデータベースを含めることができます。可用性グループに設定できるデータベースの数とサポートされるセカンダリ レプリカの数は SQL Server のエディションによって異なります。可用性グループ内のすべてのデータベースには、同じライフサイクルの変更が同時に適用されます。プライマリ データベースのみが書き込みアクセスをサポートするため、可用性グループはアクティブ / パッシブモードになります。
フェイルオーバーが発生すると、セカンダリ レプリカが新しいプライマリ レプリカになります。可用性グループにはスタンドアロンの SQL Server インスタンスが含まれるため、トランザクション ログに記録されたオペレーションはすべてレプリカで利用できます。SQL Server インスタンス レベルのログインや SQL Server エージェントのジョブなど、トランザクション ログに記録されていない変更は手動で同期する必要があります。データベース レベルの保護と SQL Server インスタンスの保護を行うには、フェイルオーバー クラスタ インスタンス(FCI)を設定する必要があります。このデプロイ アーキテクチャについては、後の Always On フェイルオーバー クラスタ インスタンスのセクションで説明します。
リスナーを使用すると、役割の変更からアプリを保護できます。リスナーは、可用性グループに接続するアプリをサポートします。アプリからは、どの SQL Server インスタンスがプライマリ データベースまたはセカンダリ レプリカを管理しているかわかりません。ビジネス継続性とデータベースの復旧 - SQL Server で説明されているように、リスナーを使用するには、クライアントで .NET バージョン 3.5(更新適用済み)または 4.0 以降が実行されている必要があります。
可用性グループは、機能を提供するために、基盤となる抽象化レイヤーに依存しています。Windows Server フェイルオーバー クラスタリングと SQL Server で説明されているように、可用性グループは Windows Server フェイルオーバー クラスタ(WSFC)で実行されます。SQL Server インスタンスを実行するすべてのノードは、同じ WSFC に含まれている必要があります。
トランザクションは、プライマリ データベースからすべてのセカンダリ レプリカに送信されます。トランザクションの送信には、同期と非同期の 2 つのモードがあります。レプリカごとに使用するモードを構成できます。同期モードの場合、プライマリ データベースのトランザクションは、同期状態のすべてのセカンダリ レプリカにトランザクションが適用された場合にのみ成功します。非同期モードの場合、すべてのセカンダリ レプリカにトランザクションが適用されていなくても、プライマリ データベースのトランザクションは成功します。
選択する送信モードによって、RTO、RPO、スタンバイ モードの選択が変わる可能性があります。たとえば、同期モードでトランザクションがすべてのレプリカに送信されると、すべてのレプリカはまったく同じ状態になります。すべてのレプリカが完全に同期されるため、最も条件の厳しい RPO(最新のトランザクション)が履行されます。セカンダリ レプリカはホット スタンバイのため、すぐにプライマリ データベースとして使用できます。
フェイルオーバーは自動または手動に設定できます。すべてのレプリカが完全に同期されていれば、自動フェイルオーバーが可能です。前述の例では、すべてのレプリカが常に完全に同期されているので、この設定が可能です。
次の図は、単一リージョンの Always On 可用性グループを示しています。
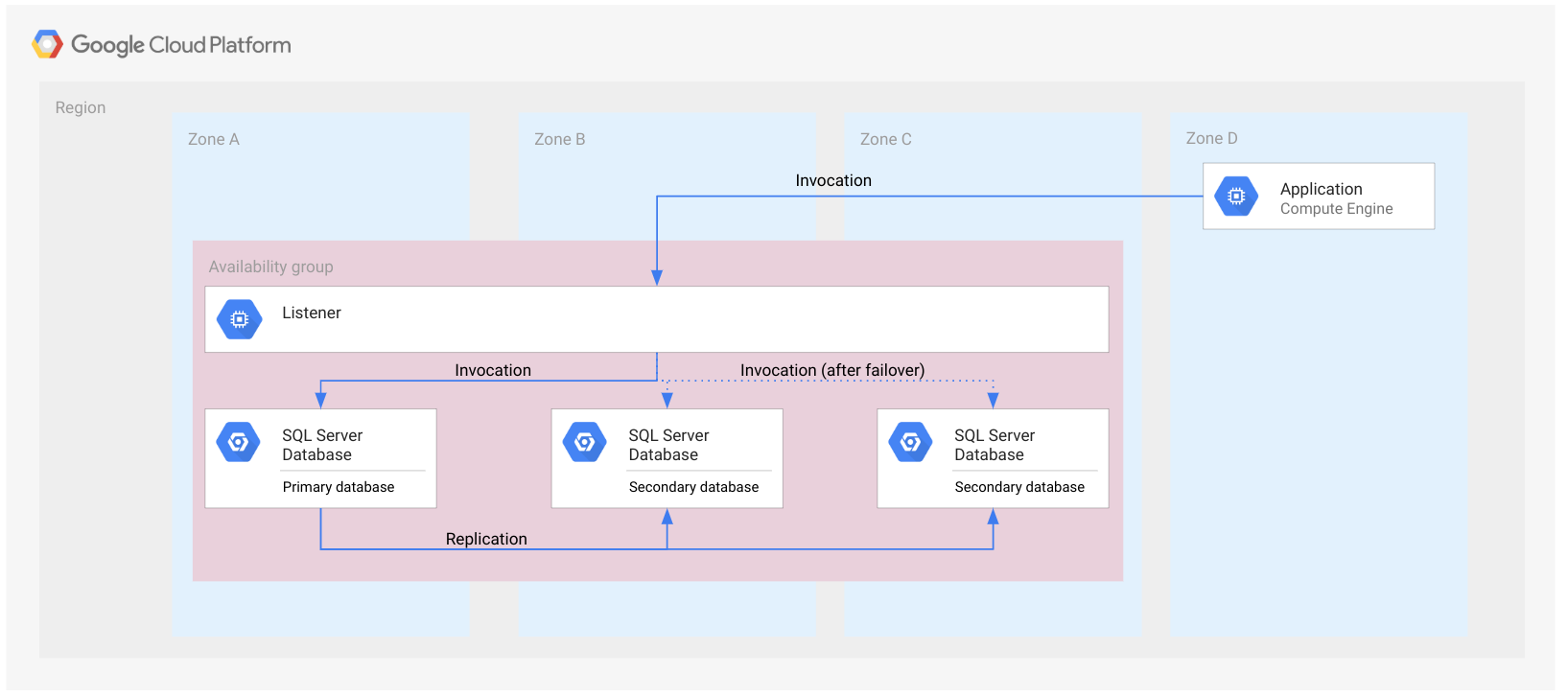
可用性グループは、複数のゾーンにまたがる長方形で表されています。これは、すべてのデータベースが同じ可用性グループに属していることを意味します。可用性グループはクラウド リソースではないため、ノードなどのリソースには実装されません。
Always On フェイルオーバー クラスタ インスタンス
ノードの障害から保護するため、スタンドアロンの SQL Server インスタンスの代わりに、フェイルオーバー クラスタ インスタンス(FCI)を使用できます。データベース(プライマリまたはセカンダリ)を管理するため、2 つ以上のノードで SQL Server インスタンスが実行されています。データベースを管理するノードからフェイルオーバー クラスタが構成されています。クラスタ内の 1 つのノードで SQL Server インスタンスが実行されていますが、他のノードでは SQL Server インスタンスが実行されていません。SQL Server インスタンスが実行されているノードで障害が発生すると、クラスタ内の別のノードで SQL Server インスタンスが起動し、データベースの管理を引き継ぎます(ノード フェイルオーバー)。SQL Server インスタンスを自動的に起動するこのプロセスにより、高可用性が提供されます。
FCI クラスタは 1 つの単位で、クラスタにアクセスしているクライアントはノード間のフェイルオーバーを認識しません(短時間使用不能になる可能性はあります)。ノードのフェイルオーバーが発生しても、データが失われることはありません。障害が発生した SQL Server インスタンス内で実行されているものはすべて、同じクラスタ内の別の SQL Server インスタンスに移動します。たとえば、SQL Server エージェント ジョブまたはリンクサーバーが別のインスタンスに移動します。
FCI クラスタノードは複数の Google Cloud ゾーンに設定できます。このアーキテクチャは、ノード障害時の高可用性だけでなく、ゾーン障害時にも高可用性を提供します。この戦略のデプロイについては、DR デプロイの選択肢で説明します。
異なるノードが同じデータベースを管理し、データベースを共有している場合でも、FCI クラスタのノード間で共通のストレージは必要ありません。SQL Server は、Storage Spaces Direct(S2D)機能を使用して、専用ノードディスク上のデータベースを管理します。詳しくは、SQL Server フェイルオーバー クラスタ インスタンスの構成をご覧ください。
次の図は、前のセクションの例と似ていますが、スタンドアロンの SQL Server インスタンスの代わりに FCI を使用した Always On 可用性グループを示しています。各 FCI には、データベースを管理するアクティブな SQL Server インスタンスが 1 つ存在します。
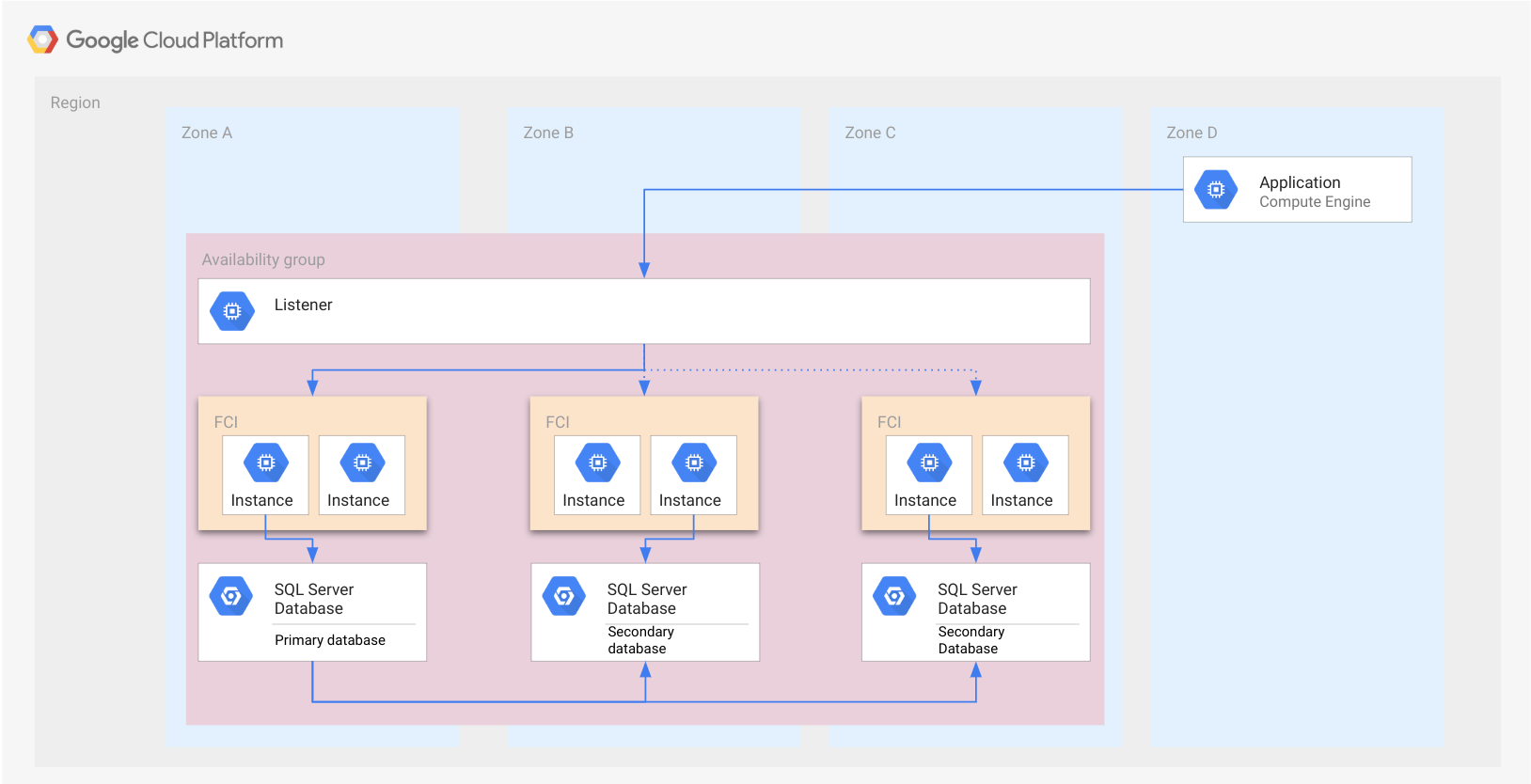
可用性グループの場合と同様に、FCI は長方形で示されています。ここでは、説明をわかりやすくするため、すべてのノードが同じ FCI に属しています。FCI はクラウド リソースではないため、ノードなどのリソースには実装されません。
詳しくは、Always On フェイルオーバー クラスタ - インスタンス(SQL Server)をご覧ください。
分散型可用性グループ
分散型可用性グループは特別なタイプの可用性グループです。分散型可用性グループは、2 つの可用性グループにまたがり、1 つはプライマリ可用性グループの役割を担い、もう 1 つはセカンダリ可用性グループの役割を果たしています。分散型可用性グループは、プライマリ可用性グループからセカンダリ可用性グループに同期または非同期モードでトランザクションを転送できます。
各可用性グループには独自のプライマリ データベースがありますが、これはアクティブ / アクティブではありません。プライマリ可用性グループのプライマリ データベースだけが書き込みオペレーションを処理できます。セカンダリ可用性グループのプライマリ データベースは、フォワーダーといいます。フォワーダーは、プライマリ可用性グループからトランザクションを受信し、セカンダリ可用性グループのセカンダリ データベースに転送します。プライマリ可用性グループからセカンダリ可用性グループへのフェイルオーバーにより、新しいプライマリ可用性グループのプライマリ データベースが書き込みオペレーションでアクセス可能になります。
プライマリ可用性グループとセカンダリ可用性グループは同じ場所にある必要はなく、同じオペレーティング システム上にある必要もありません。ただし、各可用性グループにリスナーをインストールする必要があります。分散型可用性グループ自体にはリスナーはありません。分散型可用性グループでは、2 つの可用性グループが同じ WSFC 内にある必要はありません。分散型可用性グループに必要なすべての機能は SQL Server の機能に含まれています。基盤となるコンポーネントを追加でインストールする必要はありません。
分散型可用性グループは、2 つの可用性グループにまたがっています。可用性グループは、2 つの分散型可用性グループの一部にできます。これにより、さまざまなトポロジがサポートされます。たとえば、複数の場所にまたがる可用性グループで構成されるデイジー チェーン トポロジがサポートされます。また、プライマリ可用性グループが 2 つの異なる分散型可用性グループの一部になっているツリー型トポロジもサポートされます。
分散型可用性グループは、主にオペレーティング システム間で障害復旧を実装する場合に使用されます。たとえば、プライマリ可用性グループを Windows に設定し、対応する 2 番目の可用性グループを Linux に設定して、両方の可用性グループから分散型可用性グループを構成します。
次の図は、分散型可用性グループを構成する 2 つの可用性グループを示しています。
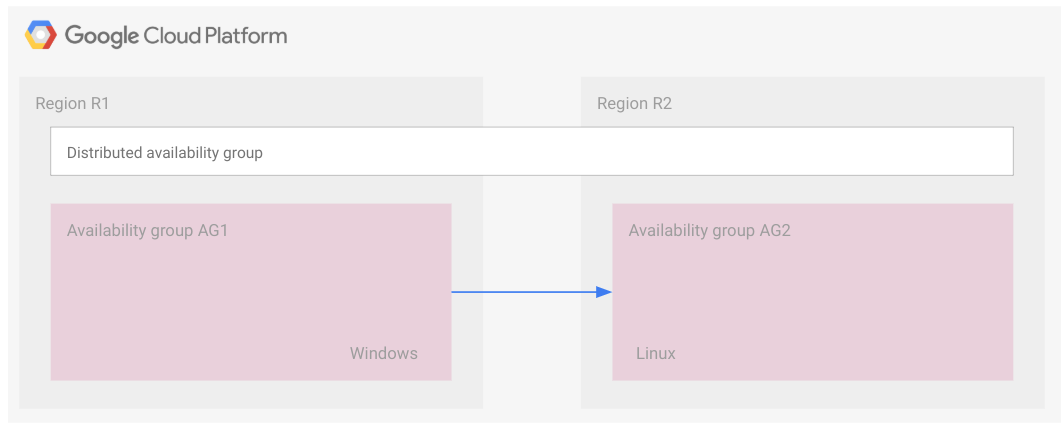
可用性グループ 1 がプライマリ可用性グループ、可用性グループ 2 がセカンダリ可用性グループです。
FCI の場合と同様に、分散型可用性グループは長方形で示されています。これは、可用性グループがすべて同じ分散型可用性グループに属していることを表しています。可用性グループのような分散型可用性グループはクラウド リソースではないため、ノードなどのリソースには実装されません。
詳しくは、分散型可用性グループをご覧ください。
ログ配布
プライマリ データベースとセカンダリ データベースの状態の差が大きく、RTO と RPO がそれほど厳密でない(RTO の値が低いか、RPO の値が即時でない)場合、SQL Server の可用性機能としてトランザクション ログの配布を利用できます。トランザクション ログファイルには多くの状態変更が含まれるため、状態という点で差が大きくなります。トランザクション ログファイルは非同期に転送され、全体をセカンダリ データベースに適用する必要があるため、時間の点からも違いが大きくなります。
トランザクション ログファイルはプライマリ データベースによって作成され、Cloud Storage などにバックアップされます。すべてのトランザクション ログファイルは、すべてのセカンダリ データベースにコピーされ、適用されます。セカンダリ データベースはプライマリ データベースよりも古くなるため、スタンバイ モードはウォームになります。トランザクション ログに記録されないオブジェクトと変更は、セカンダリ データベースに手動で適用し、完全な同期状態にする必要があります。
SQL Server エージェントは、トランザクション ログの作成、コピー、適用をすべて自動的に行います。ログ配布はデータベースごとに設定する必要があります。可用性グループが複数のデータベースを管理している場合は、できるだけ多くのログ配布プロセスを設定する必要があります。
障害が発生した場合は、自動化されたサポートがないため、障害復旧プロセスを手動で開始する必要があります。また、リスナーによってプライマリ データベースとセカンダリ データベースからクライアント アクセスが抽象化されません。フェイルオーバーの場合、クライアントは障害復旧後に新しいプライマリに接続し、セカンダリから新しいプライマリへのデータベースの役割変更に対応する必要があります。SQL Server インスタンスから独立して個別の抽象化を行うことができます。たとえば、フローティング IP アドレスのベスト プラクティスで説明しているフローティング IP アドレスを使用します。
ログ配布は手動プロセスのため、セカンダリ データベースへのログファイルの適用を意図的に遅らせることもできます(可用性グループや分散型可用性グループの場合は変更がすぐに適用されます)。ユースケースとしては、データ変更のエラーが解決されるまで、プライマリ データベースからセカンダリ データベースへの適用を防ぐ場合が挙げられます。この場合、問題が解決するまで、データ変更エラーが適用されていないセカンダリ データベースをプライマリ データベースにすることも可能です。問題が解決した後は、通常の処理に戻します。
分散型可用性グループと同様に、プライマリ データベースが Linux で実行され、セカンダリ データベースが Linux と Windows 上に存在するようなクロス プラットフォーム ソリューションにもログ配布を使用できます。
次の図は、ログ配布を使用したクロス プラットフォーム環境を示しています。このトポロジでは、分散型可用性グループのようにリージョン間で共通の構成はありません。
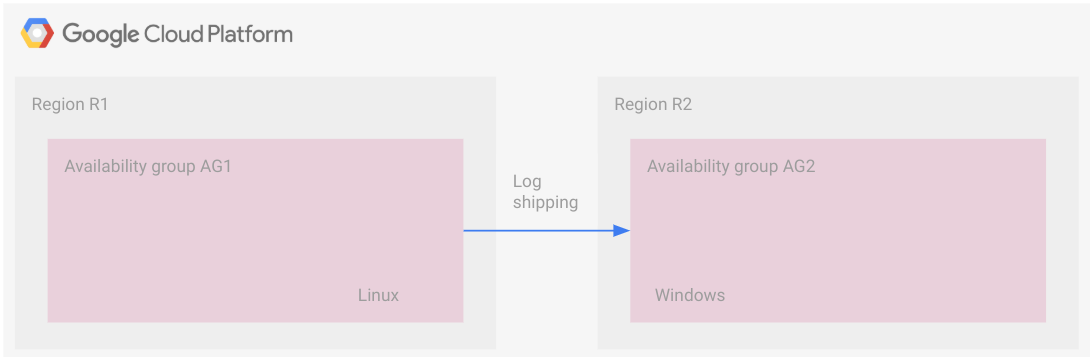
可用性グループは別々のリージョンにあり、1 つは Linux 上で、もう 1 つは Windows 上で実行されています。
SQL Server ログ配布の詳細については、ログ配布について(SQL Server)をご覧ください。
SQL Server の可用性機能を組み合わせる
SQL Server の可用性機能を組み合わせることも可能です。たとえば、前のユースケースでは、異なるオペレーティング システムにインストールされた異なる可用性グループにログ配布を使用しました。
SQL Server の可用性機能の組み合わせとしては、次のようなケースが考えられます。
- 同じオペレーティング システムにインストールされている可用性グループ間でログ配布を使用する。
- FCI を使用するプライマリ可用性グループと、SQL Server のスタンドアロン インスタンスのみを使用するセカンダリ可用性グループを使用する。
- 近くのリージョン間で分散型可用性グループを使用し、異なる大陸にあるリージョン間でログ配布を使用する。
このリストは一部にすぎません。SQL Server の可用性機能の組み合わせは、これ以外にも考えられます。
SQL Server の可用性機能が提供する柔軟性により、前述の要件に従って障害復旧戦略をきめ細かく調整できます。
SQL Server のレプリケーション
一般に、SQL Server のレプリケーションは可用性機能に含まれませんが、このセクションではこの機能を障害復旧に使用する方法について簡単に説明します。
レプリケーション機能は、データベースのレプリカの作成とメンテナンスをサポートします。さまざまなタイプの SQL Server エージェントが連携して変更をキャプチャし、これらの変更を送信してレプリカに適用します。このプロセスは非同期で、通常、レプリカは複製元のデータベースよりも古くなります。
たとえば、本番環境のデータベースのレプリカを作成した場合、障害復旧については、本番環境のデータベースがプライマリ データベースで、レプリカがセカンダリ データベースになります。SQL Server のレプリケーション機能では、障害復旧でデータベースが担う役割を認識できません。レプリケーションには、障害復旧プロセスをサポートする操作(役割の変更など)はありません。クライアント アクセスを抽象化する機能がないため、障害復旧プロセスは SQL Server の機能とは別に実装し、実装した組織によって行う必要があります。
バックアップ ファイルの配布
障害復旧戦略としてバックアップ ファイルを配布する方法もあります。セカンダリ データベースを設定して継続的に更新する標準的な方法は、プライマリ データベースの完全バックアップを作成し、その後は増分バックアップを取得する方法です。すべての増分バックアップは、正しい順序でセカンダリ データベースに適用されます。この方法には、増分バックアップの頻度、バックアップ ファイルの保存場所(グローバルなロケーション、またはロケーション間で実際にコピーされた場所)に応じて、さまざまなバリエーションがあります。
この戦略では、プライマリ データベースからセカンダリ データベースに状態の変更を複製する場合に SQL Server の可用性機能を使用しません。ログ配布で使用される SQL Server エージェントを使用しません。
詳細については、例: バックアップと復元の DR 戦略に関するセクションをご覧ください。
前のセクションで説明したレプリケーション アプローチと比較すると、レプリケーションとバックアップ ファイルの配布には、障害復旧プロセスが SQL Server の機能セットとは別に外部で実装されるという共通点があります。収集した変更を配布するという点では、SQL Server エージェントで自動的に実装できるため、SQL Server のレプリケーションのほうが便利です。
データベースのライフサイクルとアプリのライフサイクルの関係
データベースのフェイルオーバーは、データベースにアクセスするアプリから完全に分離されて独立した状態にあるわけではありません。このため、次の 2 つの問題が発生する可能性があります。
まず、データベースがフェイルオーバーしている間、アプリの実行は継続します。プライマリ データベースが使用不能になってから新しいプライマリ データベースが稼働するまで、アプリはデータベースにまったくアクセスできません。既存の接続は切断され、新しい接続は確立されません。この間、少なくともデータベース アクセスを必要とする機能についてはクライアントにサービスを提供できなくなります。アプリは、新しいプライマリ データベースが利用可能になったことを認識し、通常の処理を再開できるようにする必要があります。
アプリは、データベース以外(メインメモリのキャッシュなど)に状態を保存している場合があります。その場合、アプリはキャッシュの内容が新しいプライマリ データベースと一致している(同期している)ことを確認します。フェイルオーバー中にトランザクションの損失がまったく発生しなかった場合は、メンテナンスを行わなくてもキャッシュの内容が一致している可能性があります。しかし、フェイルオーバー中にトランザクション(データ)の損失が発生した場合、キャッシュの内容は新しいプライマリ データベースと一致していない可能性があります。データベース内のデータの一部がキュー内のメッセージやファイル システム内のファイルに含まれている場合も、同様の状況が発生します。データの一貫性については、データベースの障害復旧と直接関係がないため、このドキュメントで扱いません。
次に、プライマリ データベースが使用できなくなると同時に、1 つ以上のアプリが使用不能になる可能性があります。たとえば、リージョンがオフラインになると、そのリージョンのプライマリ データベースだけでなく、同じリージョンで実行されているアプリケーション システムも使用不能になります。この場合、プライマリ データベース システムだけでなく、アプリも復旧する必要があります。つまり、データベースの障害復旧プロセスだけでなく、アプリの復旧プロセスも開始しなければなりません。復旧したアプリは、新しいプライマリ データベースに接続し、再構成を行う必要があります(たとえば、フローティング IP アドレスなど)。アプリの復旧についても、このドキュメントでは説明しません。
バックアップ / 復元と障害復旧の関係
データベースのバックアップは独立したプロセスで、データベースの障害復旧とは関係ありません。データベースをバックアップする目的は、データベースが消失や破損した場合や、アプリの障害やバグで以前の状態を回復しなければならない場合に、一貫した状態を復元することにあります。
以下では、データベースの障害復旧を実装するための 1 つの手段としてバックアップを使用する方法について説明します。このシナリオでは、セカンダリ データベースを復元できるように、バックアップ ファイルをセカンダリ データベースの場所にコピーします。ただし、バックアップ ファイルは障害復旧の前提条件ではありません。代替手段については、可用性機能に関する前述の説明で紹介しています。
高可用性と障害復旧
高可用性と障害復旧は、データベースが利用できない場合の解決策という点で共通しています。いずれも、プライマリ データベースが使用不能になったときに、セカンダリ データベースを整合性のある新しいプライマリ データベースとして利用できるようにします。
高可用性と障害復旧の違いは単一障害点ドメインです。たとえば、単一ゾーンで障害が発生した場合やノードで障害が発生した場合、高可用性はリージョン内の機能停止に対処します。高可用性ソリューションは、同じリージョン内の別のゾーンに新しいプライマリ データベースを提供します。また、データベースの障害だけでなくノードの障害にも対処します。SQL Server インスタンスが実行されているノードに障害が発生した場合、新しい SQL Server インスタンスが実行されている新しいノードを使用可能にします(Always On フェイルオーバー クラスタ インスタンスを参照)。
障害復旧には少なくとも 2 つのリージョンが関係し、リージョン全体が利用できなくなった場合に対処します。障害復旧では、異なるリージョンに新しいプライマリ データベースを作成できます。
SQL Server の高可用性機能は、高可用性と障害復旧のソリューションを同時にサポートします。単一の可用性グループは、リージョン内だけでなく、リージョン内の複数のゾーンに対応できます。可用性グループには、高可用性を実現するファイルオーバー クラスタ インスタンスを入れることもできます。
SQL Server は、1 つのリージョン内に可用性グループを設定して高可用性とゾーン障害に対応し、リージョン間のログ配布で障害復旧に対処できます。
DR デプロイの選択肢
以降のセクションでは、これまでの説明以外に考えられる障害復旧トポロジについて説明します。このトポロジは、さまざまな RPO と RTO の要件を満たします。このリストはすべてを網羅しているわけではありません。
リージョン内の DR と HA
このデプロイは FCI を含む可用性グループの変形で、3 つのゾーンから構成されるリージョンを使用します。このシナリオでは、ゾーンが単一障害点ドメインになります。
前述のデプロイと異なり、各 FCI は 3 つのノードから構成され、各ノードは異なるゾーンで実行されています。この設定の利点は、1 つまたは 2 つのゾーンで障害が発生しても、障害復旧プロセスを行う必要がないことです。
次の図にこの構成を示します。
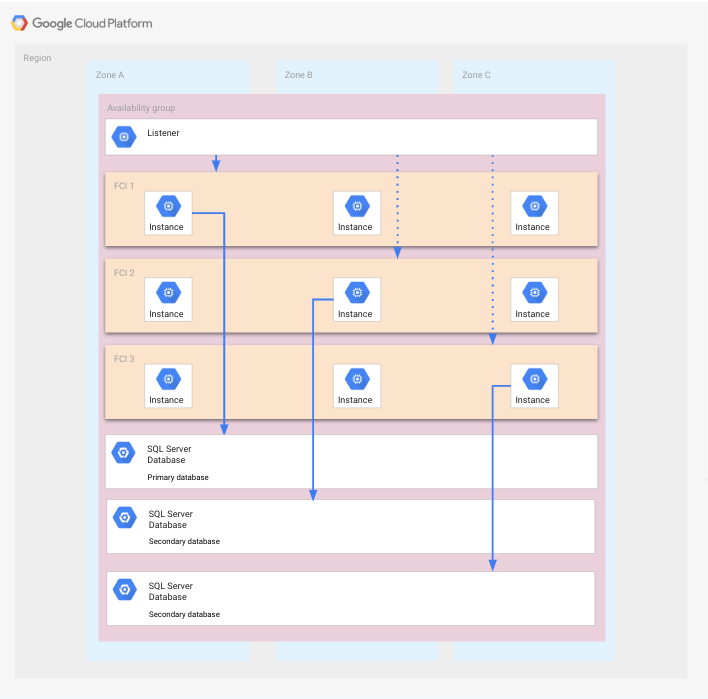
FCI はすべてのゾーンにまたがり、各 FCI には、対応するデータベースにアクセスする実行中の SQL Server インスタンスが存在します。ゾーンに障害が発生したときに起動できる FCI には、実行されていない SQL Server インスタンスが 2 つ残っています。それぞれのデータベースが特定の FCI 内のすべてのノードのディスクを使用するため、データベースがゾーンをまたぐように示されています。わかりやすくするため、アプリは示されていません。
リージョン間 DR: 複数のリージョンにわたる可用性グループ
このシナリオでは、可用性グループが Windows Server フェイルオーバー クラスタ上で実行され、2 つのリージョンにまたがっています。リージョンが単一障害点ドメインとなります。
次の図はこの設定を示しています。

レイテンシに関する潜在的な問題に対処するため、リージョン R1 にレプリカを構成し、同期トランザクションの伝播に使用します。また、リージョン R2 のレプリカは、非同期トランザクションの伝播を使用するように構成されています。
リージョン間 DR: バックアップ ファイル転送
このシナリオでは、バックアップ ファイルの転送を行います。2 つのリージョンの 2 つの可用性グループがリンクされています。各可用性グループには、トランザクションを同期的に受信するレプリカがあり、各リージョンのセカンダリ レプリカはホット スタンバイ構成になっています。
次の図はこの設定を示しています。
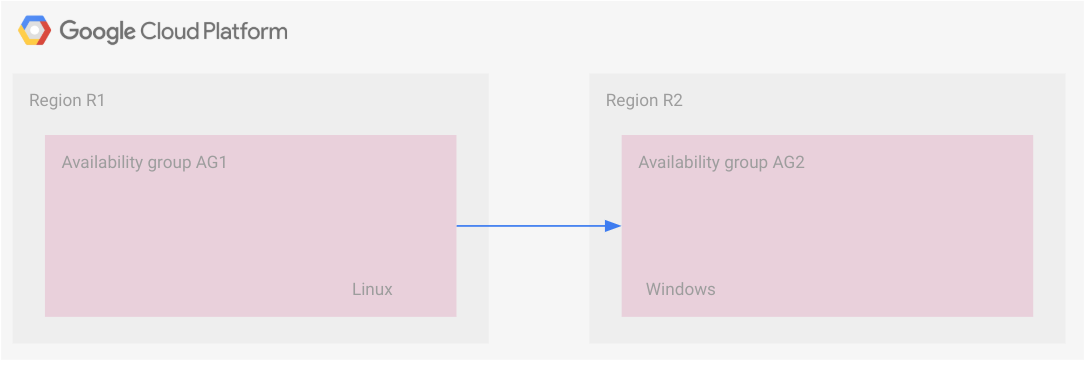
ただし、2 つの可用性グループはバックアップ ファイルの転送で接続されています。可用性グループ AG1 がプライマリ可用性グループ、可用性グループ AG2 がセカンダリ可用性グループです。バックアップ ファイルがセカンダリ可用性グループで使用可能になると、そこに適用されます。このシナリオの詳細については、例: バックアップと復元の DR 戦略をご覧ください。
2 次または 3 次的なトポロジ
1 つのリージョンにプライマリ データベースとセカンダリ データベースの 2 つのデータベースのみが存在している場合、フェイルオーバーの後で、新しいプライマリ データベースが稼働してから新しいセカンダリ データベースの準備ができるまでの間、無保護状態の時間があります。セカンダリ データベースの実行準備ができる前に新しいプライマリ データベースが使用不能になると、ハード ダウンタイムが発生し、新しいプライマリ データベースからしか復元できない状態になります。可用性グループにも同じことが当てはまります。
別のセカンダリ データベースまたは可用性グループを実行している 3 番目の場所を用意することで、フェイルオーバー後の無保護状態を回避できます。この設定では、新しいプライマリ データベースへの割り当てでデータを失わないように、2 つのセカンダリ データベースの片方をセカンダリ データベースのままにしておく必要があります。また、可用性グループにも同じことが当てはまります。
DR ライフサイクル
どの障害復旧ソリューションを選択しても適用される共通のライフサイクル手順があります。
実際の障害復旧の状況では、すべての関係者(アプリのオーナー、運用グループ、データベース管理者)が障害復旧の管理に積極的に参加する必要があります。これらの関係者の間で決定権者(MC ともいいます)を決め、その決定に従う必要があります。さらに、関係者の間で用語と連絡方法を確認しておく必要があります。
フェイルオーバー プロセスの開始を決める
フェイルオーバーを自動的に開始するように設定していない限り、関係者がフェイルオーバーを開始するかどうか決定する必要があります。フェイルオーバーの開始を決める際は、さまざまな関係者の間で綿密な調整を行う必要があります。
フェイルオーバー プロセスの開始を判断する場合、いくつかの要因を検討する必要があります。特に、プライマリ データベースが使用不能になった根本的な原因は重要です。
プライマリ データベースの問題解決に想定される時間よりも障害復旧プロセスのほうが長くなる場合、フェイルオーバーは有効な解決策とはいえません。まず、プライマリ データベースの復元が現実的な選択肢かどうかを評価する必要があります。
障害復旧戦略に十分なテストを行うほど、実装が容易になり、意思決定の際に不確定要素が少なくなります。このため、フェイルオーバー プロセスの判断も容易になります。
フェイルオーバー プロセスの実施
フェイルオーバー プロセスは定期的にテストし、さまざまな関係者に周知させておくのが理想的です。
決定権者は、実際に行われているすべての処理だけでなく、予期せず発生する問題も把握しておく必要があります。決定権者がフェイルオーバー プロセスを推進し、その他の関係者が決定権者のサポートを行います。
ポストモーテムとフェイルオーバー プロセスの改善のため、アクティビティの時間、発生した問題、フェイルオーバー プロセスの手順で起きた問題などを統計情報として記録しておく必要があります。
無保護状態
セカンダリ データベースが 1 つしかない場合は、新しいプライマリ データベースが使用可能になり、稼働状態になってから新しいセカンダリ データベースの準備ができるまでの間、DR による保護はありません。この間にデータベースが使用不能になると、別のデータベースにフェイルオーバーできないため、ハード ダウンタイムが発生する可能性があります。このような状況が生じた場合は、別のプライマリ データベースを設定しなければなりません。RPA は、使用可能なバックアップに基づいて再構築できる最後のポイントになります。
常に保護されるように障害復旧戦略を立てていない限り、無保護状態が発生する可能性があるため、セットアップや環境構成の変更は慎重に行う必要があります。
新しいセカンダリ データベースが稼働するまで新しいプライマリ データベースへアクセスを許可せず、プライマリ データベースからの変更が適用された後すぐにプライマリ データベースへのアクセスを可能にする場合は、このような状況を回避できます。この場合、アプリの無保護状態は回避できますが、障害復旧プロセスが完了するまでに時間がかかります。
スプリット ブレインを回避する
DML オペレーションを実行して、アプリがプライマリ データベースとセカンダリ データベースに同時にアクセスできないようにする必要があります。プライマリ データベースとセカンダリ データベースの同じデータ項目に異なる値が存在すると(スプリット ブレイン)、データに不整合が生じます。プライマリ データベースが実行中に使用不能になり、書き込みオペレーションが受信可能な状態になっている場合、このアーキテクチャは特に重要になります。断続的なネットワーク パーティショニングが原因で使用不能になった場合、パーティショニングが任意の時点で停止し、アプリからアクセス可能な状態になる可能性があります。その時点でフェイルオーバー プロセスが実行されていると、古いプライマリ データベースへの変更が失われる可能性があります。また、一部のアプリが古いプライマリ データベースにアクセスし、他のアプリが新しいプライマリ データベースにアクセスする可能性もあります。
フェイルオーバー プロセスの実行中は、すべてのデータベースでアプリからアクセスが切断されるため、どのデータベースでも状態の変更は発生しません。フェイルオーバー後に書き込み可能なデータベースは 1 つだけ(新しいプライマリ データベース)になります。
完了通知
フェイルオーバー プロセスが完了したら、決定権者からすべての関係者にプロセスの完了を明示的に通知する必要があります。完了後に発生した問題は、フェイルオーバー プロセスではなく、別の事象として通常のプロセスで対応する必要があります。この問題は、フェイルオーバー プロセスに起因する場合も、まったく無関係な場合もあります。ただし、フェイルオーバー プロセスの完了後にこの問題に対処する方法は、フェイルオーバー プロセスの実行中とは異なる場合があります。
事後分析と報告
今後の参考やフェイルオーバー プロセスの改善のため、事後分析をすぐに実施し、重要な要因、調査結果、アクション項目を記録しておく必要があります。
障害復旧イベント、根本原因、実施したすべての処置をまとめた報告書を作成してください。法規制によっては、この報告書の作成が義務付けられている場合があります。
DR のテストと検証
障害復旧は通常の日常業務ではないため、必要なときに適切に機能するように DR ソリューションを定期的にテストする必要があります。
テストの頻度は運用要件によって異なります。また、データベース、アプリ、企業の要件によっても異なります。さらに、ネットワーク構成の変更やインフラストラクチャ コンポーネントの更新など、環境に対する変更が発生した場合は、これらの変更が障害復旧ソリューションに影響がないかどうか、障害復旧のテストを行う必要があります。これらの変更により、障害復旧ソリューションが失敗する場合があります。また、障害復旧プロセスの調整が必要になることもあります。
テストを手動で開始するにはスイッチオーバー プロセスを開始します。あるいは、カオス エンジニアリング アプローチ(詳細はこちらを参照)で自動的に開始することもできます。著しいダウンタイムが予想される場合は、テストを手動で行うと、ビジネスへの影響を最小限に抑えることができます。
テストでは、明確な統計情報を収集することが重要です。たとえば、次のような統計情報を収集します。
- 実際の復旧時間: 実際の復旧時間を測定し、RTO と比較します。
- 実際の復旧時点: 実際の復旧時点を確認し、RPO と比較します。
- 障害検出までの時間: DBA または運用チームがフェイルオーバーの必要性を認識するまでの時間。
- 復旧開始までの時間: 障害が検出されてからフェイルオーバー プロセスが開始するまでの時間。
- 信頼性: フェイルオーバー プロセスがどの程度厳密に実行されたか、あるいは逸脱があるかどうか。調査が必要な予期しない問題が発生し、復旧戦略の変更が必要かどうか。
収集した統計情報に基づいて、RPO と RTO に近づくようにフェイルオーバー プロセスの調整または改善を行います。
例: バックアップと復元の DR 戦略
以下では、バックアップと復元の障害復旧戦略の概要について説明します。このシナリオでは、バックアップと復元の DR 戦略の設定に必要な作業を明確にし、自動化された環境では見えない側面について説明するため、SQL Server の可用性機能の使用を最小限に抑えています。
ユースケース
プライマリ Always On 可用性グループがリージョン R1 に配置され、稼働しています。リージョンをまたぐ保護を実装するため、セカンダリ Always on 可用性グループはリージョン R2 に追加されています。このグループは、フェイルオーバーまたはスイッチオーバーのターゲットとなります。
戦略
障害復旧戦略は、データベースのバックアップに基づいています。最初に完全バックアップが実行され、それ以降は差分バックアップが実行されます。バックアップは、実行時にセカンダリ Always On 可用性グループに適用されます。すべてのバックアップは Cloud Storage バケットに保存されます。
この例では、フェイルオーバーの完了後、R2 にある新しいプライマリ Always On 可用性グループがアクティブになり、R1 にある新しいセカンダリ Always On 可用性グループが稼働状態になるまでの間、無保護状態になりますが、これは許容されています。
各リージョンの Always On 可用性グループが本番環境の Always On 可用性グループとして機能する資格があるため、フォールバックは行われません。
RTO と RPO
この例では、RPO を最大 60 分に定義しているため、差分バックアップが 60 分ごとに行われます。
RTO には明示的な期間が設定されていませんが、できるだけ短い期間にします(即時が最善です)。セカンダリ可用性グループは、ホット スタンバイとして設定する必要があります。ホット スタンバイの場合、すべてのバックアップがすぐに適用されるため、フェイルオーバーでバックアップの適用が遅延することはありません。
DR 戦略の概要
以下では、DR 戦略の概要について説明します。重要なステップに焦点を当てて説明します。
初期設定
- リージョン R2 にセカンダリ Always On 可用性グループを作成します。
- 誤ってスプリット ブレインが発生しないように、セカンダリ可用性グループへのアプリアクセスを禁止します。
- Cloud Storage にバックアップ ファイル バケット B1 を作成し、R1 の Always On 可用性グループの最初の完全バックアップと、R1 の Always On 可用性グループのそれ以降の差分バックアップ(1 時間ごと)を格納します。セカンダリ可用性グループにバックアップを適用するプロセスが正しい順序で処理されるように、差分バックアップに正しい順序を設定する必要があります。たとえば、ファイル名に含まれているタイムスタンプで順序が判別されるように命名規則を設定します。
ローンチ戦略
- 完全バックアップをリージョン R2 のセカンダリ Always On 可用性グループに適用します。
- 差分バックアップが利用可能になったらすぐに、R2 のセカンダリ Always On 可用性グループに適用します。RTO の要件を満たすため、すぐに適用します。
- 最初の完全バックアップとすべての増分バックアップが適用されたら、セカンダリ Always On 可用性グループが使用可能な状態になります。
- プライマリ可用性グループからセカンダリ可用性グループへのスイッチオーバーを行い、DR 戦略をテストします。テスト中は、少なくとも 1 つの増分バックアップを使用できるようにしてください。
フェイルオーバーまたはスイッチオーバーの場合
R2 での基本的なステップは次のとおりです。
- 最新の差分バックアップが R2 のセカンダリ Always On 可用性グループに適用されたことを確認します。
- R2 を新しいプライマリ Always On 可用性グループとして指定します。
- 新しいバケット B2 を作成し、ベースラインとして完全バックアップを作成します。アプリアクセス用に新しいプライマリ可用性グループを開きます。
- 差分バックアップを開始します。
R1 での基本的なステップは次のとおりです。
- バケット B1 は不要になったので削除します。
- R1 の Always On 可用性グループが新しいセカンダリ Always On 可用性グループとして使用可能になったら、アプリによるアクセスを禁止し、データベースからすべてのデータを削除するか、初期状態(空の状態)にリセットします(新規に作成した場合を除く)。
- R2 の新しいプライマリ Always On 可用性グループの完全バックアップを適用し、差分バックアップが利用可能になったらすぐに適用します(バケット B2 に格納されます)。
考えられる改善
フェイルオーバーまたはスイッチオーバーの後に完全バックアップを取得せずに、新しいセカンダリ可用性グループをすばやく設定できるようにすると、DR 戦略を改善できる可能性があります。1 回の完全バックアップとそれに続く差分バックアップの代わりに、完全バックアップを毎週作成し、その週の完全バックアップと以降のすべての差分バックアップを含むバケットを週単位で作成します。新しいプライマリ可用性グループは、フェイルオーバー後にのみ差分バックアップを作成し(完全バックアップは作成しない)、それらをバケットに追加する必要があります。新しいセカンダリ可用性グループは、その週のバケット内のすべてのバックアップを単純に適用します。この週単位のアプローチを使用する場合は、不要なバックアップを削除するためにクリーンアップ戦略やパージ戦略を実装する必要があります。
また、新しいセカンダリ可用性グループが前のプライマリ可用性グループであるという事実から改善策を考えてみましょう。データベースが存在し、再び使用可能になった後に稼働状態になったときに、最後の差分バックアップへのポイントインタイム リカバリを行うと、SQL Server データベースを特定の時点に復元する方法(完全復旧モデル)で説明されているように、最後の完全バックアップから完全に復元する必要がなくなります。このシナリオでは、新しいプライマリ可用性グループが保護されていない時間を短縮し、その期間の作業量を軽減できます。
本番環境のベスト プラクティス
このソリューションでは、Always On 可用性グループの SQL Server インスタンスがスタンドアロン インスタンスか FCI インスタンスかを指定していません。使用されるインスタンスの種類は、実装前に決める必要があります。
フェイルオーバー後、新しいセカンダリ Always On 可用性グループが使用可能になるまで DR で保護されないため、3 つのリージョンに 3 つ目の Always On 可用性グループを設定する必要があります。
また、障害やエラーが確実に検出されるようにモニタリングを実装する必要があります。モニタリングはこのドキュメントの範囲外ですが、実用的な障害復旧ソリューションには不可欠な機能です。
次のステップ
- SQL Server Always On 可用性グループを構成する。
- マルチ サブネットの SQL Server 2016 Always On 可用性グループを Compute Engine にデプロイする。
- SQL Server フェイルオーバー クラスタ インスタンスを構成する。
- Windows Server フェイルオーバー クラスタリングを実行する。
- .NET アプリ用に Cloud Logging、Cloud Monitoring、Error Reporting を有効にする。
- Cloud Monitoring エージェントをインストールする。
- Google Cloud に関するリファレンス アーキテクチャ、図、ベスト プラクティスを確認する。Cloud アーキテクチャ センターをご覧ください。