Questo tutorial descrive come eseguire il deployment e gestire un sistema di database Microsoft SQL Server in due regioni Google Cloud come soluzione di disaster recovery (DR) e come effettuare il failover da un'istanza di database non funzionante a una che opera normalmente. Ai fini di questo documento, con emergenza si intende un evento in cui un database primario non funziona o non è disponibile.
Un database primario può non funzionare quando la regione in cui si trova non funziona o diventa inaccessibile. Anche se una regione è disponibile e funziona normalmente, un database primario può non funzionare a causa di un errore di sistema. In questi casi, il disaster recovery è il processo di messa a disposizione di un database secondario per i client per un'elaborazione continua.
Questo tutorial è rivolto ad architetti, amministratori e database engineer.
Informazioni sul disaster recovery
In Google Cloud, il disaster recovery (DR) è un processo che garantisce la continuità dell'elaborazione, in particolare quando una regione non funziona o diventa inaccessibile. Per i sistemi come quello di gestione di database, devi implementare il DR eseguendo il deployment del sistema in almeno due regioni. Con questa configurazione, se una regione non è più disponibile, il sistema continua a funzionare.
Disaster recovery del sistema di database
Il processo di rendere disponibile un database secondario quando l'istanza del database primario non funziona è definito disaster recovery del database (o DR del database). Per informazioni più dettagliate su questo argomento, consulta Disaster recovery per Microsoft SQL Server. Idealmente, lo stato del database secondario è coerente con quello del database primario nel momento in cui questo non è più disponibile oppure se nel database secondario manca solo un piccolo insieme di transazioni recenti del database primario.
Architettura del disaster recovery
Per Microsoft SQL Server, il seguente diagramma mostra un'architettura minima che supporta il DR del database.
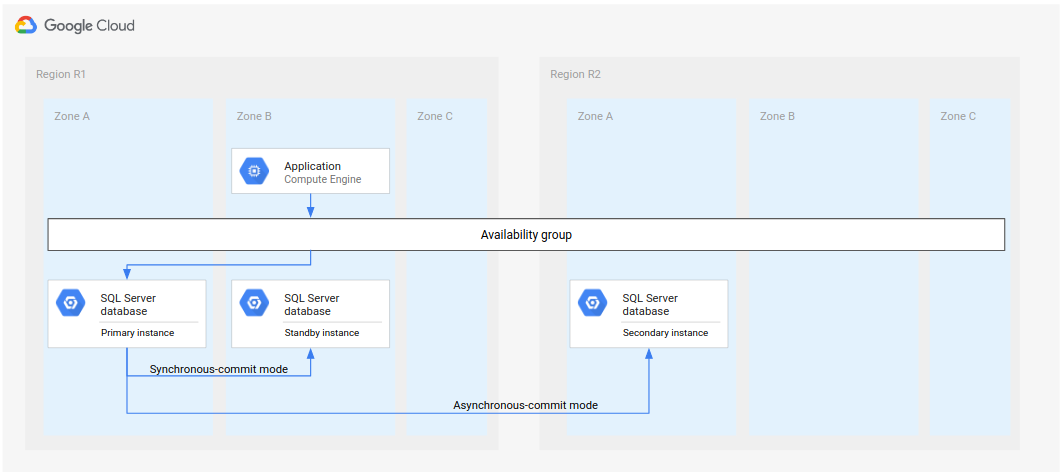
Figura 1. Architettura del disaster recovery standard con Microsoft SQL Server.
Questa architettura funziona nel seguente modo:
- Due istanze di Microsoft SQL Server (una primaria e una in standby) si trovano nella stessa regione (R1), ma in zone diverse (zone A e B). Le due istanze in R1 coordinano i loro stati utilizzando la modalità commit sincrono. La modalità sincrona viene utilizzata perché supporta un'elevata affidabilità e mantiene uno stato dei dati coerente.
- Un'istanza di Microsoft SQL Server (l'istanza secondaria o di disaster recovery) si trova in una seconda regione (R2). Per il DR, l'istanza secondaria in R2 si sincronizza con l'istanza primaria in R1 utilizzando la modalità di commit asincrono. La modalità asincrona viene utilizzata per le sue prestazioni (non rallenta l'elaborazione del processo di commit nell'istanza primaria).
Nel diagramma precedente, l'architettura mostra un gruppo di disponibilità. Il gruppo di disponibilità, se utilizzato con un listener, fornisce la stessa stringa di connessione ai client se questi sono gestiti dai seguenti elementi:
- L'istanza primaria
- L'istanza in standby (dopo un errore di zona)
- L'istanza secondaria (dopo un errore nella regione e dopo che l'istanza secondaria è diventata la nuova istanza primaria)
In una variante dell'architettura sopra riportata, esegui il deployment delle due istanze situate nella prima regione (R1) nella stessa zona. Questo approccio potrebbe migliorare le prestazioni, ma non è altamente affidabile. Per avviare il processo di DR potrebbe essere necessaria un'interruzione del servizio in una singola zona.
Processo di disaster recovery di base
Il processo di DR inizia quando una regione non è più disponibile e viene eseguito il failover del database primario per riprendere l'elaborazione in un'altra regione operativa. Il processo di DR definisce i passaggi operativi da seguire, manualmente o automaticamente, per mitigare l'errore della regione e stabilire un'istanza primaria in esecuzione in una regione disponibile.
Un processo di base di DR del database prevede i seguenti passaggi:
- La prima regione (R1), in cui è in esecuzione l'istanza del database primaria, diventa non disponibile.
- Il team operativo riconosce e conferma formalmente l'emergenza e decide se è necessario eseguire un failover.
- Se questo è il caso, l'istanza del database secondaria nella seconda regione (R2) diventa la nuova istanza primaria.
- I client riprendono l'elaborazione nel nuovo database primario e accedono all'istanza primaria in R2.
Sebbene questo processo di base ristabilisca un database primario funzionante, non consente di creare un'architettura di DR completa in cui la nuova istanza primaria disponga di un'istanza di database in standby e secondaria.
Processo di disaster recovery completo
Un processo di DR completo implica l'aggiunta di passaggi al processo di DR di base per stabilire un'architettura di DR completa dopo l'esecuzione di un failover. Il seguente diagramma mostra un'architettura di DR del database completo.
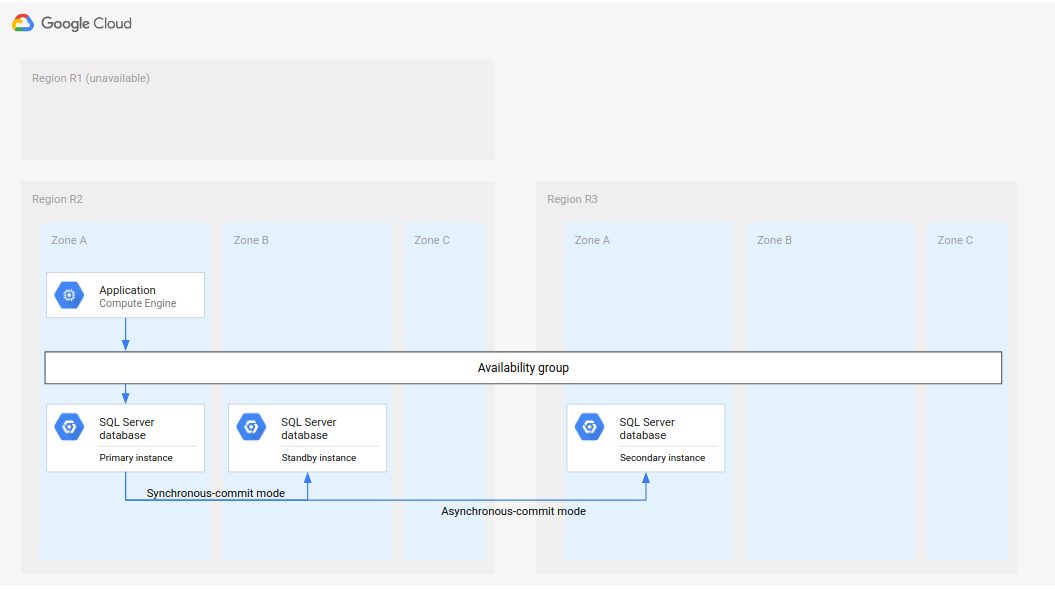
Figura 2. Disaster recovery con una regione con istanza primaria non disponibile (R1).
L'architettura di DR del database completo funziona nel seguente modo:
- La prima regione (R1), in cui è in esecuzione l'istanza del database primaria, diventa non disponibile.
- Il team operativo riconosce e conferma formalmente l'emergenza e decide se è necessario eseguire un failover.
- Se questo è il caso, l'istanza del database secondaria nella seconda regione (R2) diventa l'istanza primaria.
- Un'altra istanza secondaria, la nuova istanza in standby, viene creata, avviata in R2 e aggiunta all'istanza primaria. L'istanza in standby si trova in una zona diversa rispetto all'istanza primaria. Il database primario è ora costituito da due istanze (primaria e in standby) ad alta affidabilità.
- In una terza regione (R3), viene creata e avviata una nuova istanza di database secondaria (in standby). Questa istanza secondaria è collegata in modo asincrono alla nuova istanza primaria in R2. A questo punto, l'architettura di disaster recovery originale viene ricreata e resa operativa.
Ripristino di una regione recuperata
Una volta ripristinata la prima regione (R1), questa può ospitare il nuovo database secondario. Se R1 diventa disponibile in tempo, puoi implementare il passaggio 5 del processo di disaster recovery completo in R1 anziché in R3 (la terza regione). In questo caso, non è necessaria una terza regione.
Il seguente diagramma mostra l'architettura nel caso in cui R1 sia disponibile per tempo.
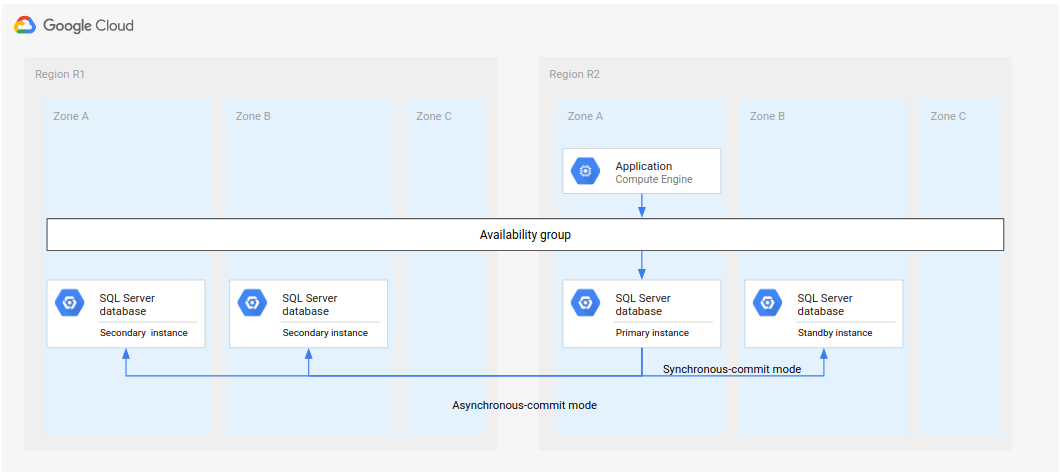
Figura 3. Il disaster recovery dopo l'errore della regione R1 diventa di nuovo disponibile.
In questa architettura, i passaggi di ripristino sono gli stessi descritti in precedenza in Processo di disaster recovery completo, con la differenza che R1, e non R3, diventa la località in cui si trovano le istanze secondarie.
Selezione di una versione di SQL Server
Questo tutorial supporta le seguenti versioni di Microsoft SQL Server:
- SQL Server 2016 Enterprise Edition
- SQL Server 2017 Enterprise Edition
- SQL Server 2019 Enterprise Edition
- SQL Server 2022 Enterprise Edition
Il tutorial utilizza la funzionalità dei gruppi di disponibilità AlwaysOn in SQL Server.
Se non hai bisogno di un database primario Microsoft SQL Server ad alta affidabilità e una singola istanza di database è sufficiente come istanza primaria, puoi utilizzare le seguenti versioni di SQL Server:
- SQL Server 2016 Standard Edition
- SQL Server 2017 Standard Edition
- SQL Server 2019 Standard Edition
- SQL Server 2022 Standard Edition
Le versioni 2016, 2017, 2019 e 2022 di SQL Server sono dotate di Microsoft SQL Server Management Studio installato nell'immagine; non devi quindi installare il programma separatamente. Tuttavia, in un ambiente di produzione, ti consigliamo di installare un'istanza di Microsoft SQL Server Management Studio su una VM separata in ogni regione. Se configuri un ambiente ad alta affidabilità, devi installare Microsoft SQL Server Management Studio una volta per ciascuna zona per assicurarti che rimanga disponibile laddove una zona non fosse più accessibile.
Configurazione di Microsoft SQL Server per il DR multiregionale
Questa sezione utilizza le seguenti immagini per Microsoft SQL Server:
sql-ent-2016-win-2016per Microsoft SQL Server 2016 Enterprise Editionsql-ent-2017-win-2016per Microsoft SQL Server 2017 Enterprise Editionsql-ent-2019-win-2019per Microsoft SQL Server 2019 Enterprise Editionsql-ent-2022-win-2022per Microsoft SQL Server 2022 Enterprise Edition
Per un elenco completo delle immagini, consulta Immagini.
Configura un cluster ad alta affidabilità con due istanze
Per configurare un'architettura di DR del database multiregionale per SQL Server, devi prima
creare un cluster ad alta affidabilità con due istanze in una regione. Un'istanza
fungerà da istanza primaria e l'altra da istanza secondaria. Per
eseguire questo passaggio, segui le istruzioni riportate in
Configurazione dei gruppi di disponibilità AlwaysOn di SQL Server.
Questo tutorial utilizza us-central1 per la regione primaria (indicata come R1).
Prima di iniziare, esamina le seguenti considerazioni:
Se hai seguito i passaggi descritti in Configurazione dei gruppi di disponibilità AlwaysOn di SQL Server, avrai creato due istanze SQL Server nella stessa regione (
us-central1) e avrai eseguito il deployment di un'istanza SQL Server primaria (node-1) inus-central1-ae di un'istanza in standby (node-2) inus-central1-b.Sebbene per questo tutorial venga implementata l'architettura indicata nella Figura 4, ti consigliamo di configurare un domain controller in più di una zona. Questo approccio garantisce che venga stabilita un'architettura di database ad alta affidabilità che sia abilitata per il DR. Ad esempio, se si verifica un'interruzione del servizio in una zona, questa non diventa un single point of failure per l'architettura sottoposta a deployment.
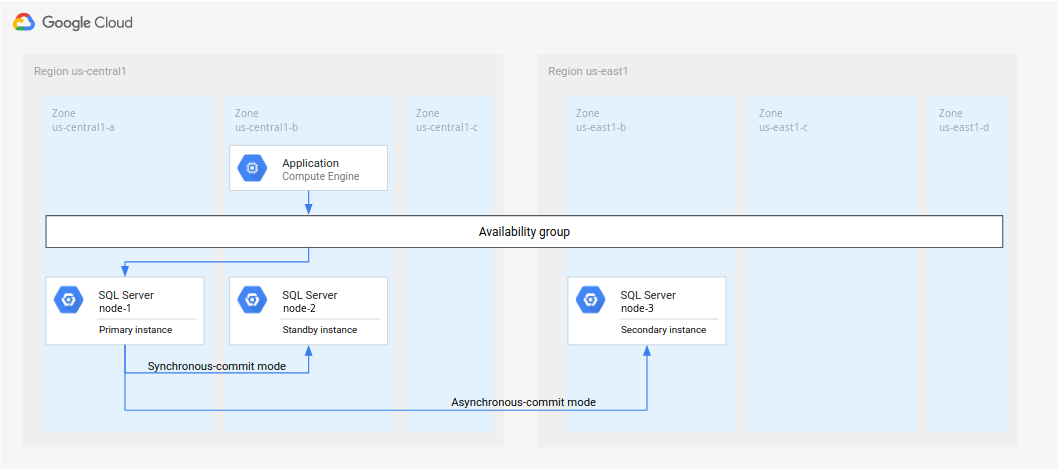
Immagine 4. Architettura di disaster recovery standard implementata in questo tutorial.
Aggiungi un'istanza secondaria per il disaster recovery
Successivamente, imposta una terza istanza SQL Server (un'istanza secondaria
denominata node-3) e configura la rete come segue:
Crea uno script di specializzazione per i nodi del cluster di failover di Windows Server. Lo script installa la funzionalità Windows necessaria e crea le regole firewall per WSFC e SQL Server. Formatta anche il disco di dati e crea cartelle di dati e log per SQL Server:
cat << "EOF" > specialize-node.ps1 $ErrorActionPreference = "stop" # Install required Windows features Install-WindowsFeature Failover-Clustering -IncludeManagementTools Install-WindowsFeature RSAT-AD-PowerShell # Open firewall for WSFC netsh advfirewall firewall add rule name="Allow SQL Server health check" dir=in action=allow protocol=TCP localport=59997 # Open firewall for SQL Server netsh advfirewall firewall add rule name="Allow SQL Server" dir=in action=allow protocol=TCP localport=1433 # Open firewall for SQL Server replication netsh advfirewall firewall add rule name="Allow SQL Server replication" dir=in action=allow protocol=TCP localport=5022 # Format data disk Get-Disk | Where partitionstyle -eq 'RAW' | Initialize-Disk -PartitionStyle MBR -PassThru | New-Partition -AssignDriveLetter -UseMaximumSize | Format-Volume -FileSystem NTFS -NewFileSystemLabel 'Data' -Confirm:$false # Create data and log folders for SQL Server md d:\Data md d:\Logs EOF
Inizializza le seguenti variabili:
VPC_NAME=
VPC_NAMESUBNET_NAME=SUBNET_NAMEREGION=us-east1 PD_SIZE=200 MACHINE_TYPE=n2-standard-8Dove:
VPC_NAME: il nome della tua VPCSUBNET_NAME: il nome della subnet per la regioneus-east1
Crea un'istanza SQL Server:
gcloud compute instances create node-3 \ --zone $REGION-b \ --machine-type $MACHINE_TYPE \ --subnet $SUBNET_NAME \ --image-family sql-ent-2022-win-2022 \ --image-project windows-sql-cloud \ --tags wsfc,wsfc-node \ --boot-disk-size 50 \ --boot-disk-type pd-ssd \ --boot-disk-device-name "node-3" \ --create-disk=name=node-3-datadisk,size=$PD_SIZE,type=pd-ssd,auto-delete=no \ --metadata enable-wsfc=true \ --metadata-from-file=sysprep-specialize-script-ps1=specialize-node.ps1Imposta una password Windows per la nuova istanza SQL Server:
Nella console Google Cloud , vai alla pagina Compute Engine.
Nella colonna Connetti per il
node-3del cluster Compute Engine, seleziona l'elenco a discesa Imposta password di Windows.Imposta il nome utente e la password. Appuntali entrambi per utilizzarli in un secondo momento.
Fai clic su RDP per connetterti all'istanza
node-3.Inserisci il nome utente e la password del passaggio precedente, quindi fai clic su Ok.
Aggiungi l'istanza al dominio Windows:
Fai clic con il tasto destro del mouse sul pulsante Start (o premi Win+X) e poi su Windows PowerShell (amministratore).
Conferma il comando di elevazione facendo clic su Sì.
Unisci il computer al dominio Active Directory ed esegui il riavvio:
Add-Computer -Domain
DOMAIN -RestartSostituisci
DOMAINcon il nome DNS del tuo dominio Active Directory.Attendi circa 1 minuto per il completamento del riavvio.
Aggiungi l'istanza secondaria al cluster di failover
Aggiungi l'istanza secondaria (node-3) al cluster di failover Windows:
Connettiti alle istanze
node-1onode-2utilizzando RDP e accedi come utente amministratore.Apri una finestra PowerShell come utente amministratore e imposta le variabili per l'ambiente del cluster in questo tutorial:
$node3 = "node-3" $nameWSFC = "
SQLSRV_CLUSTER" # Name of clusterSostituisci
SQLSRV_CLUSTERcon il nome del cluster SQL Server.Aggiungi l'istanza secondaria al cluster:
Get-Cluster | WHERE Name -EQ $nameWSFC | Add-ClusterNode -NoStorage -Name $node3L'esecuzione di questo comando potrebbe richiedere del tempo. Poiché il processo può smettere di rispondere e può non essere in grado di riavviarsi automaticamente, premi di tanto in tanto
Enter.Nel nodo, attiva la funzionalità di alta affidabilità di AlwaysOn:
Enable-SqlAlwaysOn -ServerInstance $node3 -Force
Il nodo fa ora parte del cluster di failover.
Aggiungi l'istanza secondaria al gruppo di disponibilità esistente
Aggiungi l'istanza SQL Server (l'istanza secondaria) e il database al gruppo di disponibilità:
Connettiti a
node-3utilizzando Remote Desktop. Accedi con il tuo account utente di dominio.Apri SQL Server Configuration Manager.
Nel riquadro di navigazione, seleziona Servizi SQL Server.
Nell'elenco dei servizi, fai clic con il tasto destro del mouse su SQL Server (MSSQLSERVER) e seleziona Proprietà.
In Accedi come, modifica l'account:
- Nome account:
DOMAIN\sql_serverdoveDOMAINè il nome NetBIOS del tuo dominio Active Directory. - Password: inserisci la password scelta in precedenza per l'account di dominio sql_server.
- Nome account:
Fai clic su Ok.
Quando ti viene chiesto di riavviare SQL Server, seleziona Sì.
In uno dei tre nodi dell'istanza
node-1,node-2onode-3, apri Microsoft SQL Server Management Studio e connettiti all'istanza primarianode-1.- Vai a Esplora oggetti.
- Seleziona l'elenco a discesa Connetti.
- Seleziona Motore del database.
- Nell'elenco a discesa Nome server, seleziona
node-1. Se il cluster non è elencato, inseriscilo nel campo.
Fai clic su Nuova query.
Incolla il seguente comando per aggiungere un indirizzo IP al listener utilizzato per il nodo e fai clic su Esegui:
ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY LISTENER 'bookshelf' (ADD IP
('LOAD_BALANCER_IP_ADDRESS', '255.255.255.0'))Sostituisci
LOAD_BALANCER_IP_ADDRESScon l'indirizzo IP del bilanciatore del carico nella regioneus-east1.In Esplora oggetti, espandi prima il nodo Alta affidabilità di AlwaysOn, poi Gruppi di disponibilità.
Fai clic con il tasto destro del mouse sul gruppo di disponibilità denominato
bookshelf-age seleziona quindi Aggiungi replica.Nella pagina Introduzione, fai clic prima sul nodo Alta affidabilità di AlwaysOn e successivamente su Gruppi di disponibilità.
Nella pagina Connetti a repliche, fai clic su Connetti per collegarti alla replica secondaria esistente
node-2.Nella pagina Specifica repliche, fai clic su Aggiungi replica e aggiungi il nuovo nodo
node-3. Non selezionare Failover automatico perché questa azione causa un commit sincrono. Questa configurazione oltrepassa i confini delle regioni e per questo non è consigliabile.Nella pagina Seleziona la sincronizzazione dei dati, fai clic su Seeding automatico.
Poiché non è presente alcun listener, la pagina Convalida genera un avviso che puoi ignorare.
Completa i passaggi della procedura guidata.
La modalità di failover per node-1 e node-2 è automatica,
mentre per node-3 è manuale. Questa differenza è un modo per distinguere l'alta affidabilità dal disaster recovery.
Il gruppo di disponibilità è ora pronto. Hai configurato due nodi per l'alta affidabilità e un terzo nodo per il disaster recovery.
Simulazione di un disaster recovery
In questa sezione, testerai l'architettura del disaster recovery per questo tutorial e valuterai le implementazioni facoltative del DR.
Simula un'interruzione del servizio ed esegui un failover DR
Simula un errore o un'interruzione del servizio nella regione primaria:
In Microsoft SQL Server Management Studio su
node-1, connettiti anode-1.Crea una tabella. Dopo aver aggiunto le repliche nei passaggi successivi, verifica che la replica funzioni controllando se questa tabella è presente.
USE bookshelf GO CREATE TABLE dbo.TestTable_Before_DR (ID INT NOT NULL) GOIn Cloud Shell, arresta entrambi i server nella regione primaria
us-central1:gcloud compute instances stop node-2 --zone us-central1-b --quiet gcloud compute instances stop node-1 --zone us-central1-a --quiet
In Microsoft SQL Server Management Studio su
node-3, connettiti anode-3.Esegui un failover e imposta la modalità di disponibilità su commit sincrono. Poiché il nodo si trova in modalità di commit asincrono è necessario forzare un failover.
ALTER AVAILABILITY GROUP [bookshelf-ag] FORCE_FAILOVER_ALLOW_DATA_LOSS GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-3' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GOPuoi riprendere l'elaborazione.
node-3è ora l'istanza primaria.(Facoltativo) Crea una nuova tabella in
node-3. Dopo averle sincronizzate con la nuova istanza primaria, controlla che le repliche contengano questa tabella.USE bookshelf GO CREATE TABLE dbo.TestTable_After_DR (ID INT NOT NULL) GO
Anche se in questo momento node-3 è l'istanza primaria, ti consigliamo di tornare
alla regione originale o di configurare una nuova istanza secondaria e un'istanza in standby
per ricreare un'architettura di DR completo. La sezione successiva
mostra queste opzioni.
(Facoltativo) Ricrea un'architettura di DR che replichi completamente le transazioni
Questo caso d'uso riguarda un errore in cui tutte le transazioni vengono replicate dal database primario a quello secondario prima che si verifichi un errore nel database primario. In questo scenario ideale, non viene perso alcun dato e lo stato del database secondario è coerente con quello del database primario nel momento in cui si è verificato l'errore.
In questo scenario, puoi ricreare un'architettura di DR completo in due modi:
- Ripristina l'istanza primaria e quella in standby originali (se disponibili).
- Crea un'istanza secondaria e una in standby nuove per
node-3nel caso in cui le corrispettive originali non siano disponibili.
Approccio 1: ripristina l'istanza primaria e quella in standby originali
In Cloud Shell, avvia l'istanza primaria (la meno recente) e quella in standby originali:
gcloud compute instances start node-1 --zone us-central1-a --quiet gcloud compute instances start node-2 --zone us-central1-b --quietIn Microsoft SQL Server Management Studio, aggiungi nuovamente
node-1enode-2come repliche secondarie:Su
node-3, aggiungi i due server in modalità di commit asincrono:USE [master] GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (FAILOVER_MODE = MANUAL) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (FAILOVER_MODE = MANUAL) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GOSu
node-1, riavvia la sincronizzazione dei database:USE [master] GO ALTER DATABASE [bookshelf] SET HADR RESUME; GOSu
node-2, riavvia la sincronizzazione dei database:USE [master] GO ALTER DATABASE [bookshelf] SET HADR RESUME; GO
Imposta di nuovo
node-1come istanza primaria:In
node-3, modifica la modalità di disponibilità dinode-1in commit sincrono. L'istanzanode-1diventa di nuovo l'istanza primaria.USE [master] GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GOIn
node-1, impostanode-1come nodo primario e gli altri due nodi come secondari:USE [master] GO -- Node 1 becomes primary ALTER AVAILABILITY GROUP [bookshelf-ag] FORCE_FAILOVER_ALLOW_DATA_LOSS; GO -- Node 2 has synchronous commit ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GO -- Node 3 has asynchronous commit ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-3' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO
Una volta eseguiti correttamente tutti i comandi, node-1 è il nodo principale, mentre gli altri nodi sono
quelli secondari, come mostrato nel seguente diagramma.
Approccio 2: configura un'istanza primaria e una in standby nuove
È probabile che non sia possibile ripristinare le istanze primarie e in standby
originali dall'errore, che il ripristino richieda troppo tempo o che la regione
non sia accessibile. Un approccio prevede il mantenimento di node-3 come istanza primaria e dopodiché
la creazione di un'istanza in standby e secondaria nuove, come mostrato nel seguente diagramma.
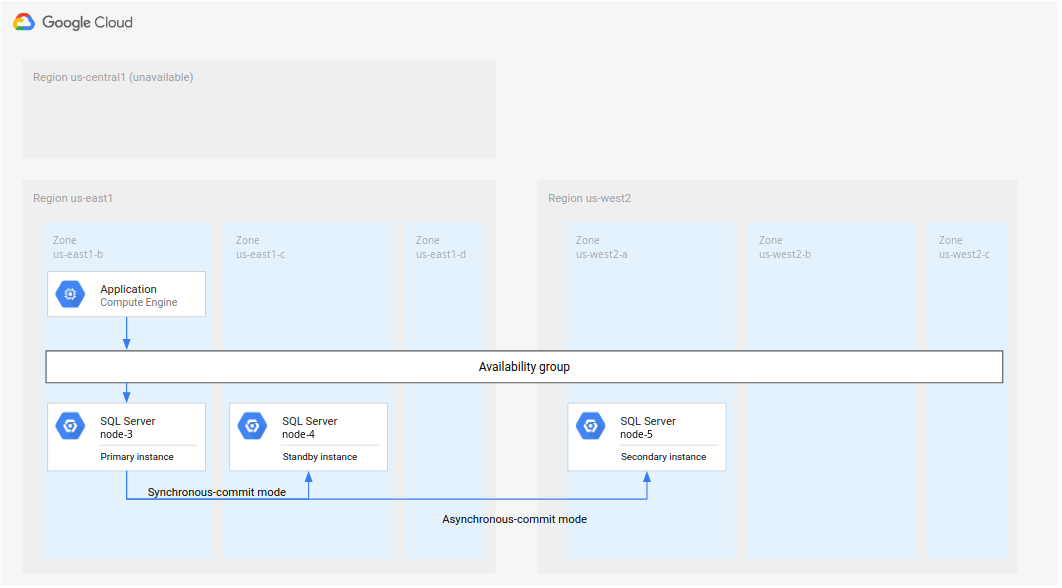
Figura 5. Disaster recovery con regione dell'istanza primaria originale R1 non disponibile.
Questa implementazione richiede di eseguire questi passaggi:
Mantieni
node-3come istanza primaria inus-east1.Aggiungi una nuova istanza in standby (
node-4) in un'altra zona inus-east1. Questo passaggio imposta il nuovo deployment come altamente affidabile.Crea una nuova istanza secondaria (
node-5) in una regione separata, ad esempious-west2. Questo passaggio configura il nuovo deployment per il disaster recovery. Il deployment complessivo è ora completato. L'architettura del database supporta completamente l'alta affidabilità e il disaster recovery.
(Facoltativo) Esegui un'operazione di ripristino quando mancano le transazioni
Un errore non ideale si verifica quando una o più transazioni impegnate sull'istanza primaria non vengono replicate nell'istanza secondaria nel point of failure (noto anche come errore grave). In caso di failover, tutte le transazioni impegnate che non vengono replicate vengono perse.
Per testare i passaggi di failover per questo scenario, devi generare un errore grave. L'approccio migliore per generare un errore grave è il seguente:
- Modifica la rete in modo che non sia presente alcuna connettività tra l'istanza primaria e quella secondaria.
- Modifica in qualche modo l'istanza primaria, ad esempio aggiungendo una tabella o inserendo alcuni dati.
- Segui il processo di failover descritto in precedenza in modo che l'istanza secondaria diventi la nuova istanza primaria.
I passaggi per il processo di failover sono identici a quelli dello scenario ideale, tranne per il fatto che la tabella aggiunta all'istanza primaria dopo l'interruzione della connettività di rete non è visibile nell'istanza secondaria.
L'unica opzione per gestire un errore grave è rimuovere le repliche
(node-1 e node-2) dal gruppo di disponibilità e sincronizzarle
di nuovo. La sincronizzazione ne modifica lo stato in modo che corrisponda
a quello dell'istanza secondaria. Eventuali transazioni non replicate prima dell'errore vengono perse.
Per aggiungere node-1 come istanza secondaria, puoi seguire i passaggi
svolti in precedenza per l'aggiunta di node-3 (consulta
Aggiungi l'istanza secondaria al cluster di failover)
con la seguente differenza: node-3 ora è l'istanza primaria,
non node-1. Devi sostituire qualsiasi istanza di
node-3 con il nome del server che aggiungi al gruppo di disponibilità. Se
riutilizzi la stessa VM (node-1 e node-2), non devi
aggiungere il server al cluster di failover di Windows Server; ma solo l'istanza SQL Server
al gruppo di disponibilità.
A questo punto, node-3 è l'istanza primaria e node-1 e
node-2 sono le istanze secondarie. Ora è possibile eseguire l'opzione di riserva su node-1,
impostare node-2 come istanza in standby e node-3
come istanza secondaria. Il sistema ora ha lo stesso stato di prima dell'errore.
Failover automatico
L'esecuzione di un failover automatico a un'istanza secondaria che funge da istanza primaria può creare problemi. Una volta che l'istanza primaria originale diventa di nuovo disponibile, può verificarsi una situazione di split-brain se alcuni client accedono all'istanza secondaria mentre altri scrivono all'istanza primaria ripristinata. In questo caso, è possibile che l'istanza primaria e quella secondaria vengano aggiornate in parallelo e che i relativi stati divergano. Per evitare questa situazione, questo tutorial fornisce istruzioni per un failover manuale in cui puoi decidere se eseguire il failover (o quando).
Se implementi un failover automatico, devi assicurarti che solo una delle istanze configurate sia quella primaria e possa essere modificata. Qualsiasi istanza in standby o secondaria non deve fornire l'accesso in scrittura a nessun client (tranne l'istanza primaria per la replica dello stato). Inoltre, devi evitare una rapida catena di failover che si susseguono in un breve lasso di tempo. Ad esempio, un failover ogni cinque minuti non sarebbe una strategia di disaster recovery affidabile. Per le procedure di failover automatico, puoi implementare misure di salvaguardia contro scenari problematici come questi e, se necessario, coinvolgere anche un amministratore di database per le decisioni complesse.
Architettura di deployment alternativa
Questo tutorial configura un'architettura di disaster recovery con un'istanza secondaria che diventa l'istanza primaria in un failover, come mostrato nel diagramma seguente.
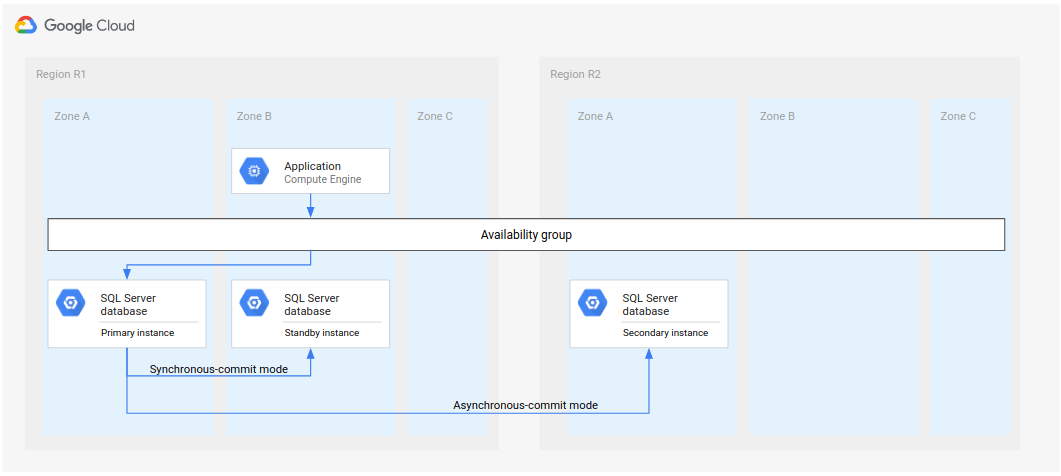
Immagine 6. Architettura di disaster recovery standard che utilizza Microsoft SQL Server.
Ciò significa che in caso di failover, il deployment risultante dispone di una singola istanza finché non sarà possibile un'operazione di ripristino o finché non configuri un'istanza in standby (per l'alta affidabilità) e una secondaria (per il DR).
Un'architettura di deployment alternativa prevede la configurazione di due istanze secondarie. Entrambe le istanze sono repliche dell'istanza primaria. In caso di failover, puoi riconfigurare una delle istanze secondarie come istanza in standby. I seguenti diagrammi mostrano l'architettura di deployment prima e dopo un failover.

Immagine 7. Architettura di disaster recovery standard con due istanze secondarie.
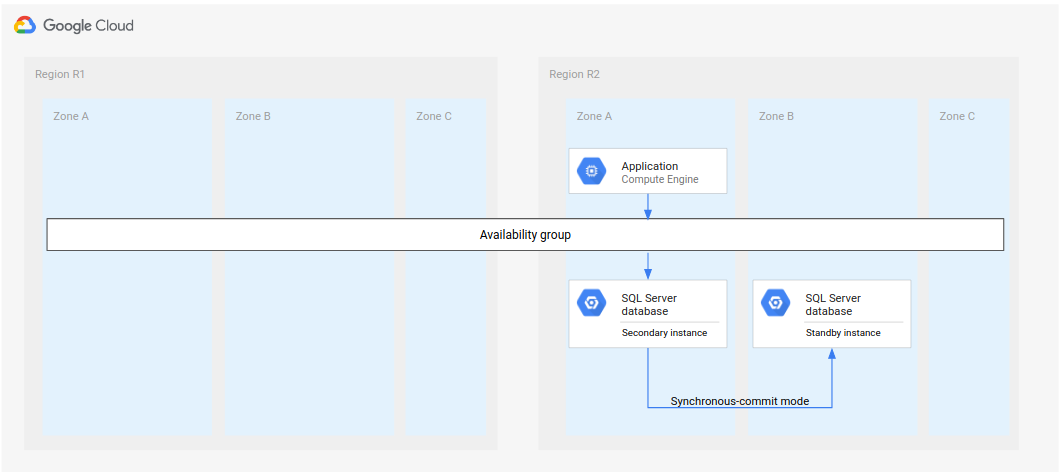
Immagine 8. Architettura di disaster recovery standard con due istanze secondarie dopo il failover.
Anche se devi comunque impostare una delle due istanze secondarie come istanza in standby (Figura 8), questo processo è molto più rapido rispetto alla creazione e alla configurazione da zero di una nuova istanza in standby.
Puoi anche risolvere il DR con una configurazione analoga a questa architettura che utilizza due istanze secondarie. Oltre ad avere due istanze secondarie in una seconda regione (Figura 7), puoi eseguire il deployment di altre due in una terza regione. Questa configurazione ti consente di creare in modo efficiente un'architettura di deployment di alta affidabilità e di disaster recovery dopo un errore nella regione primaria.