En este tutorial se describe cómo desplegar y gestionar un sistema de base de datos de Microsoft SQL Server en dos regiones de Google Cloud como solución de recuperación tras desastres y cómo conmutar por error de una instancia de base de datos con errores a una instancia que funcione correctamente. A los efectos de este documento, un desastre es un evento en el que falla o deja de estar disponible una base de datos principal.
Una base de datos principal puede fallar si falla la región en la que se encuentra o si se vuelve inaccesible. Aunque una región esté disponible y funcione con normalidad, una base de datos principal puede fallar debido a un error del sistema. En estos casos, la recuperación ante desastres es el proceso de poner una base de datos secundaria a disposición de los clientes para que puedan seguir procesando datos.
Este tutorial está dirigido a arquitectos, administradores e ingenieros de bases de datos.
Información sobre la recuperación tras fallos
En Google Cloud, la recuperación tras desastres (DR) consiste en proporcionar continuidad de procesamiento, especialmente cuando una región falla o deja de ser accesible. En sistemas como un sistema de gestión de bases de datos, la recuperación ante desastres se implementa desplegando el sistema en al menos dos regiones. Con esta configuración, el sistema sigue funcionando si una región deja de estar disponible.
Recuperación tras fallos de sistemas de bases de datos
El proceso de poner a disposición una base de datos secundaria cuando falla la instancia de la base de datos principal se denomina recuperación ante desastres de la base de datos (o DR de la base de datos). Para obtener información detallada sobre este concepto, consulta Recuperación tras fallos para Microsoft SQL Server. Lo ideal es que el estado de la base de datos secundaria sea coherente con el de la base de datos principal en el momento en que esta deje de estar disponible, o que a la base de datos secundaria solo le falte un pequeño conjunto de transacciones recientes de la base de datos principal.
Arquitectura de recuperación tras fallos
En el caso de Microsoft SQL Server, el siguiente diagrama muestra una arquitectura mínima que admite la recuperación tras fallos de bases de datos.

Imagen 1. Arquitectura de recuperación tras fallos estándar con Microsoft SQL Server.
Esta arquitectura funciona de la siguiente manera:
- Dos instancias de Microsoft SQL Server (una principal y otra de reserva) se encuentran en la misma región (R1), pero en zonas diferentes (A y B). Las dos instancias de R1 coordinan sus estados mediante el modo synchronous-commit. El modo síncrono se usa porque admite una alta disponibilidad y mantiene un estado de datos coherente.
- Una instancia de Microsoft SQL Server (la instancia secundaria o de recuperación tras fallos) se encuentra en una segunda región (R2). En la recuperación ante desastres, la instancia secundaria de R2 se sincroniza con la instancia principal de R1 mediante el modo de confirmación asíncrono. El modo asíncrono se usa por su rendimiento (no ralentiza el procesamiento de las confirmaciones en la instancia principal).
En el diagrama anterior, la arquitectura muestra un grupo de disponibilidad. El grupo de disponibilidad, si se usa con un agente de escucha, proporciona la misma cadena de conexión a los clientes si estos se sirven de lo siguiente:
- La instancia principal
- La instancia de espera (después de un fallo de zona)
- La instancia secundaria (después de un fallo en una región y después de que la instancia secundaria se convierta en la nueva instancia principal)
En una variante de la arquitectura anterior, puede implementar las dos instancias que se encuentran en la primera región (R1) en la misma zona. Este enfoque puede mejorar el rendimiento, pero no ofrece alta disponibilidad, por lo que puede que sea necesario que se produzca una interrupción en una sola zona para iniciar el proceso de recuperación ante desastres.
Proceso básico de recuperación tras fallos
El proceso de recuperación tras fallos se inicia cuando una región deja de estar disponible y la base de datos principal se conmuta por error para reanudar el procesamiento en otra región operativa. El proceso de recuperación ante desastres prescribe los pasos operativos que se deben seguir, ya sea de forma manual o automática, para mitigar el fallo de la región y establecer una instancia principal en ejecución en una región disponible.
Un proceso básico de recuperación ante desastres de una base de datos consta de los siguientes pasos:
- La primera región (R1), que ejecuta la instancia de base de datos principal, deja de estar disponible.
- El equipo de Operaciones reconoce formalmente el desastre y decide si es necesario realizar una conmutación por error.
- Si es necesario realizar una conmutación por error, la instancia de base de datos secundaria de la segunda región (R2) se convierte en la nueva instancia principal.
- Los clientes reanudan el procesamiento en la nueva base de datos principal y acceden a la instancia principal en R2.
Aunque este proceso básico vuelve a establecer una base de datos principal operativa, no establece una arquitectura de recuperación ante desastres completa, en la que la nueva base de datos principal tiene una instancia de base de datos secundaria y otra de reserva.
Completar el proceso de recuperación tras fallos
Un proceso de recuperación ante desastres completo amplía el proceso básico de recuperación ante desastres añadiendo pasos para establecer una arquitectura de recuperación ante desastres completa después de una conmutación por error. En el siguiente diagrama se muestra una arquitectura de recuperación tras desastres de base de datos completa.

Imagen 2. Recuperación tras desastres con una región principal no disponible (R1).
Esta arquitectura completa de recuperación tras desastres de bases de datos funciona de la siguiente manera:
- La primera región (R1), que ejecuta la instancia de base de datos principal, deja de estar disponible.
- El equipo de Operaciones reconoce formalmente el desastre y decide si es necesario realizar una conmutación por error.
- Si es necesario realizar una conmutación por error, la instancia de base de datos secundaria de la segunda región (R2) se convierte en la instancia principal.
- Se crea otra instancia secundaria, la nueva instancia de espera, y se inicia en R2. Después, se añade a la instancia principal. La instancia de espera está en una zona diferente a la de la instancia principal. La base de datos principal ahora consta de dos instancias (principal y de espera) que tienen una alta disponibilidad.
- En una tercera región (R3), se crea y se inicia una nueva instancia de base de datos secundaria (de espera). Esta instancia secundaria está conectada de forma asíncrona a la nueva instancia principal de R2. En este punto, se habrá recreado la arquitectura original de recuperación ante desastres y estará operativa.
Volver a una región recuperada
Una vez que la primera región (R1) vuelva a estar online, podrá alojar la nueva base de datos secundaria. Si R1 está disponible pronto, puedes implementar el paso 5 del proceso de recuperación completo en R1 en lugar de en R3 (la tercera región). En este caso, no es necesario añadir una tercera región.
En el siguiente diagrama se muestra la arquitectura si R1 está disponible a tiempo.
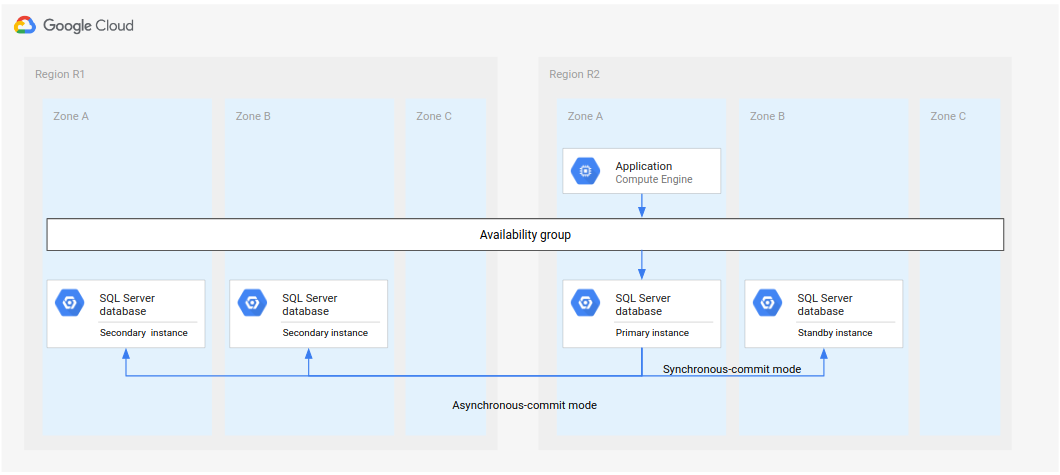
Imagen 3. Recuperación tras fallos después de que la región R1 vuelva a estar disponible.
En esta arquitectura, los pasos de recuperación son los mismos que se han descrito anteriormente en Proceso completo de recuperación tras fallos, con la diferencia de que R1 se convierte en la ubicación de las instancias secundarias en lugar de R3.
Elegir una edición de SQL Server
Este tutorial es compatible con las siguientes versiones de Microsoft SQL Server:
- SQL Server 2016 Enterprise Edition
- SQL Server 2017 Enterprise Edition
- SQL Server 2019 Enterprise Edition
- SQL Server 2022 Enterprise Edition
En el tutorial se usa la función Grupos de disponibilidad AlwaysOn de SQL Server.
Si no necesitas una base de datos principal de Microsoft SQL Server de alta disponibilidad y te basta con una sola instancia de base de datos como principal, puedes usar las siguientes versiones de SQL Server:
- SQL Server 2016 Standard Edition
- SQL Server 2017 Standard Edition
- SQL Server 2019 Standard Edition
- SQL Server 2022 Standard Edition
Las versiones 2016, 2017, 2019 y 2022 de SQL Server tienen instalado Microsoft SQL Server Management Studio en la imagen, por lo que no es necesario instalarlo por separado. Sin embargo, en un entorno de producción, te recomendamos que instales una instancia de Microsoft SQL Server Management Studio en una VM independiente de cada región. Si configura un entorno de alta disponibilidad, debe instalar Microsoft SQL Server Management Studio una vez por cada zona para asegurarse de que siga estando disponible si otra zona deja de estarlo.
Configurar Microsoft SQL Server para la recuperación tras desastres multirregional
En esta sección se usan las siguientes imágenes de Microsoft SQL Server:
sql-ent-2016-win-2016para Microsoft SQL Server 2016 Enterprise Editionsql-ent-2017-win-2016para Microsoft SQL Server 2017 Enterprise Editionsql-ent-2019-win-2019para Microsoft SQL Server 2019 Enterprise Editionsql-ent-2022-win-2022para Microsoft SQL Server 2022 Enterprise Edition
Para ver una lista completa de las imágenes, consulta Imágenes.
Configurar un clúster de alta disponibilidad de dos instancias
Para configurar una arquitectura de recuperación tras desastres de una base de datos multirregional para SQL Server, primero debes crear un clúster de alta disponibilidad (HA) de dos instancias en una región. Una instancia
actúa como principal y la otra como secundaria. Para completar este paso, sigue las instrucciones que se indican en Configurar grupos de disponibilidad AlwaysOn de SQL Server.
En este tutorial se usa us-central1 para la región principal (R1).
Antes de empezar, revisa las siguientes consideraciones:
Si has seguido los pasos que se indican en Configurar grupos de disponibilidad Always On de SQL Server, habrás creado dos instancias de SQL Server en la misma región (
us-central1). Habrás implementado una instancia principal de SQL Server (node-1) enus-central1-ay una instancia de espera (node-2) enus-central1-b.Aunque en este tutorial se implementa la arquitectura de la figura 4, es recomendable configurar un controlador de dominio en más de una zona. De esta forma, te aseguras de establecer una arquitectura de base de datos con alta disponibilidad y recuperación tras fallos. Por ejemplo, si se produce una interrupción en una zona, esa zona no se convierte en un único punto de fallo para la arquitectura implementada.
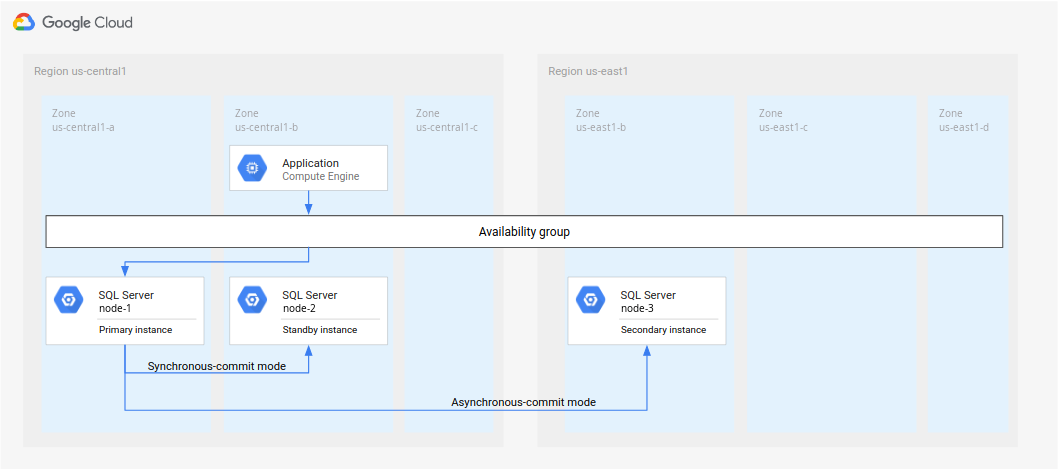
Imagen 4. Arquitectura de recuperación tras fallos estándar implementada en este tutorial.
Añadir una instancia secundaria para la recuperación tras desastres
A continuación, configura una tercera instancia de SQL Server (una instancia secundaria llamada node-3) y configura la red de la siguiente manera:
Crea un script de especialización para los nodos del clúster de conmutación por error de Windows Server. La secuencia de comandos instala la función de Windows necesaria y crea reglas de firewall para WSFC y SQL Server. También formatea el disco de datos y crea carpetas de datos y de registro para SQL Server:
cat << "EOF" > specialize-node.ps1 $ErrorActionPreference = "stop" # Install required Windows features Install-WindowsFeature Failover-Clustering -IncludeManagementTools Install-WindowsFeature RSAT-AD-PowerShell # Open firewall for WSFC netsh advfirewall firewall add rule name="Allow SQL Server health check" dir=in action=allow protocol=TCP localport=59997 # Open firewall for SQL Server netsh advfirewall firewall add rule name="Allow SQL Server" dir=in action=allow protocol=TCP localport=1433 # Open firewall for SQL Server replication netsh advfirewall firewall add rule name="Allow SQL Server replication" dir=in action=allow protocol=TCP localport=5022 # Format data disk Get-Disk | Where partitionstyle -eq 'RAW' | Initialize-Disk -PartitionStyle MBR -PassThru | New-Partition -AssignDriveLetter -UseMaximumSize | Format-Volume -FileSystem NTFS -NewFileSystemLabel 'Data' -Confirm:$false # Create data and log folders for SQL Server md d:\Data md d:\Logs EOF
Inicializa las siguientes variables:
VPC_NAME=
VPC_NAMESUBNET_NAME=SUBNET_NAMEREGION=us-east1 PD_SIZE=200 MACHINE_TYPE=n2-standard-8Donde:
VPC_NAME: nombre de tu VPCSUBNET_NAME: nombre de la subred de la regiónus-east1
Crea una instancia de SQL Server:
gcloud compute instances create node-3 \ --zone $REGION-b \ --machine-type $MACHINE_TYPE \ --subnet $SUBNET_NAME \ --image-family sql-ent-2022-win-2022 \ --image-project windows-sql-cloud \ --tags wsfc,wsfc-node \ --boot-disk-size 50 \ --boot-disk-type pd-ssd \ --boot-disk-device-name "node-3" \ --create-disk=name=node-3-datadisk,size=$PD_SIZE,type=pd-ssd,auto-delete=no \ --metadata enable-wsfc=true \ --metadata-from-file=sysprep-specialize-script-ps1=specialize-node.ps1Define una contraseña de Windows para la nueva instancia de SQL Server:
En la Google Cloud consola, ve a la página Compute Engine.
En la columna Conectar del clúster
node-3de Compute Engine, selecciona la lista desplegable Definir contraseña de Windows.Define el nombre de usuario y la contraseña. Anota estos datos para usarlos más adelante.
Haz clic en RDP para conectarte a la instancia
node-3.Introduce el nombre de usuario y la contraseña del paso anterior y haz clic en Aceptar.
Añade la instancia al dominio de Windows:
Haz clic con el botón derecho en el botón Inicio (o pulsa Win+X) y, a continuación, en Windows PowerShell (administrador).
Confirma la solicitud de elevación haciendo clic en Sí.
Une el ordenador a tu dominio de Active Directory y reinícialo:
Add-Computer -Domain
DOMAIN -RestartSustituye
DOMAINpor el nombre DNS de tu dominio de Active Directory.Espera aproximadamente 1 minuto a que se complete el reinicio.
Añadir la instancia secundaria al clúster de conmutación por error
A continuación, añade la instancia secundaria (node-3) al clúster de conmutación por error de Windows:
Conéctate a las instancias de
node-1onode-2mediante RDP e inicia sesión como administrador.Abre una ventana de PowerShell como usuario administrador y define las variables del entorno de clúster de este tutorial:
$node3 = "node-3" $nameWSFC = "
SQLSRV_CLUSTER" # Name of clusterSustituye
SQLSRV_CLUSTERpor el nombre del clúster de SQL Server.Añade la instancia secundaria al clúster:
Get-Cluster | WHERE Name -EQ $nameWSFC | Add-ClusterNode -NoStorage -Name $node3Este comando puede tardar un poco en ejecutarse. Como el proceso puede dejar de responder y no volver automáticamente, pulsa
Enterde vez en cuando.En el nodo, habilita la función de alta disponibilidad AlwaysOn:
Enable-SqlAlwaysOn -ServerInstance $node3 -Force
El nodo ahora forma parte del clúster de conmutación por error.
Añadir la instancia secundaria al grupo de disponibilidad
A continuación, añade la instancia de SQL Server (la instancia secundaria) y la base de datos al grupo de disponibilidad:
Conéctate a
node-3mediante Escritorio Remoto. Inicia sesión con tu cuenta de usuario del dominio.Abre SQL Server Configuration Manager.
En el panel de navegación, selecciona Servicios de SQL Server.
En la lista de servicios, haz clic con el botón derecho en SQL Server (MSSQLSERVER) y selecciona Propiedades.
En Iniciar sesión como, cambia la cuenta:
- Nombre de cuenta:
DOMAIN\sql_serverdondeDOMAINes el nombre de NetBIOS de tu dominio de Active Directory. - Contraseña: introduce la contraseña que elegiste anteriormente para la cuenta de dominio sql_server.
- Nombre de cuenta:
Haz clic en Aceptar.
Cuando se te pida que reinicies SQL Server, selecciona Sí.
En cualquiera de los tres nodos de instancia
node-1,node-2onode-3, abra Microsoft SQL Server Management Studio y conéctese a la instancia principal (node-1).- Ve al Explorador de objetos.
- Selecciona la lista desplegable Conectar.
- Seleccione Motor de base de datos.
- En la lista desplegable Nombre del servidor, selecciona
node-1. Si el clúster no aparece en la lista, introdúcelo en el campo.
Haz clic en Nueva consulta.
Pega el siguiente comando para añadir una dirección IP al listener que se usa para el nodo y, a continuación, haz clic en Ejecutar:
ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY LISTENER 'bookshelf' (ADD IP
('LOAD_BALANCER_IP_ADDRESS', '255.255.255.0'))Sustituye
LOAD_BALANCER_IP_ADDRESSpor la dirección IP del balanceador de carga de la regiónus-east1.En el Explorador de objetos, expanda el nodo AlwaysOn High Availability (Alta disponibilidad AlwaysOn) y, a continuación, el nodo Availability Groups (Grupos de disponibilidad).
Haga clic con el botón derecho en el grupo de disponibilidad denominado
bookshelf-agy, a continuación, seleccione Agregar réplica.En la página Introducción, haga clic en el nodo Alta disponibilidad AlwaysOn y, a continuación, en el nodo Grupos de disponibilidad.
En la página Conectar a réplicas, haz clic en Conectar para conectarte a la réplica secundaria
node-2.En la página Specify Replicas (Especificar réplicas), haga clic en Add Replica (Añadir réplica) y, a continuación, añada el nuevo nodo
node-3. No selecciones Conmutación por error automática, ya que provoca una confirmación síncrona. Esta configuración cruza las fronteras regionales, por lo que no la recomendamos.En la página Seleccionar sincronización de datos, elija Generación automática.
Como no hay ningún receptor, la página Validación genera una advertencia que puedes ignorar.
Completa los pasos del asistente.
El modo de conmutación por error de node-1 y node-2 es automático, mientras que el de node-3 es manual. Esta diferencia es una forma de distinguir la alta disponibilidad de la recuperación tras desastres.
El grupo de disponibilidad ya está listo. Has configurado dos nodos para la alta disponibilidad y un tercer nodo para la recuperación tras fallos.
Simular una recuperación tras fallos
En esta sección, probarás la arquitectura de recuperación tras fallos de este tutorial y verás implementaciones de recuperación tras fallos opcionales.
Simular una interrupción del servicio y ejecutar una conmutación por error de recuperación tras desastres
Simula un fallo o una interrupción del servicio en la región principal:
En Microsoft SQL Server Management Studio en
node-1, conéctate anode-1.Crea una tabla. Después de añadir réplicas en los pasos posteriores, comprueba que la réplica funciona comprobando si esta tabla está presente.
USE bookshelf GO CREATE TABLE dbo.TestTable_Before_DR (ID INT NOT NULL) GOEn Cloud Shell, apaga ambos servidores de la región principal
us-central1:gcloud compute instances stop node-2 --zone us-central1-b --quiet gcloud compute instances stop node-1 --zone us-central1-a --quiet
En Microsoft SQL Server Management Studio en
node-3, conéctate anode-3.Ejecuta una conmutación por error y define el modo de disponibilidad como synchronous-commit. Es necesario forzar una conmutación por error porque el nodo está en modo de confirmación asíncrona.
ALTER AVAILABILITY GROUP [bookshelf-ag] FORCE_FAILOVER_ALLOW_DATA_LOSS GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-3' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GOPuedes reanudar el procesamiento.
node-3es ahora la instancia principal.(Opcional) Crea una tabla en
node-3. Después de sincronizar las réplicas con la nueva principal, comprueba si esta tabla se ha replicado en las réplicas.USE bookshelf GO CREATE TABLE dbo.TestTable_After_DR (ID INT NOT NULL) GO
Aunque node-3 es la principal en este momento, puede que quieras volver a la región original o configurar una nueva instancia secundaria y una instancia de espera para volver a crear una arquitectura de recuperación ante desastres completa. En la siguiente sección se analizan estas opciones.
(Opcional) Recrear una arquitectura de recuperación tras desastres que replique las transacciones por completo
Este caso práctico aborda un fallo en el que todas las transacciones se replican de la base de datos principal a la secundaria antes de que falle la principal. En este escenario ideal, no se pierden datos y el estado de la secundaria es coherente con el de la principal en el momento del fallo.
En este caso, puedes recrear una arquitectura de recuperación ante desastres completa de dos formas:
- Vuelve a la principal y a la secundaria originales (si están disponibles).
- Crea un dispositivo secundario y otro de reserva para
node-3por si el dispositivo principal y el de reserva originales no están disponibles.
Método 1: Volver a la configuración principal y de espera originales
En Cloud Shell, inicia el servidor principal original (antiguo) y el de reserva:
gcloud compute instances start node-1 --zone us-central1-a --quiet gcloud compute instances start node-2 --zone us-central1-b --quietEn Microsoft SQL Server Management Studio, vuelve a añadir
node-1ynode-2como réplicas secundarias:En
node-3, añade los dos servidores en modo de confirmación asíncrona:USE [master] GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (FAILOVER_MODE = MANUAL) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (FAILOVER_MODE = MANUAL) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GOEn
node-1, vuelve a sincronizar las bases de datos:USE [master] GO ALTER DATABASE [bookshelf] SET HADR RESUME; GOEn
node-2, vuelve a sincronizar las bases de datos:USE [master] GO ALTER DATABASE [bookshelf] SET HADR RESUME; GO
Vuelve a convertir a
node-1en el propietario principal:En
node-3, cambia el modo de disponibilidad denode-1a synchronous-commit. La instancianode-1vuelve a ser la principal.USE [master] GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GOEn
node-1, cambianode-1para que sea el principal y los otros dos nodos para que sean los secundarios:USE [master] GO -- Node 1 becomes primary ALTER AVAILABILITY GROUP [bookshelf-ag] FORCE_FAILOVER_ALLOW_DATA_LOSS; GO -- Node 2 has synchronous commit ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GO -- Node 3 has asynchronous commit ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-3' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO
Una vez que se hayan ejecutado todos los comandos correctamente, node-1 será el nodo principal y los demás nodos serán secundarios, tal como se muestra en el siguiente diagrama.

Opción 2: Configurar un servidor principal y otro de reserva
Es posible que no puedas recuperar las instancias principal y de espera originales tras el fallo, que tardes demasiado en recuperarlas o que no puedas acceder a la región. Una opción es mantener node-3 como instancia principal y, a continuación, crear una instancia secundaria y otra de espera, tal como se muestra en el siguiente diagrama.
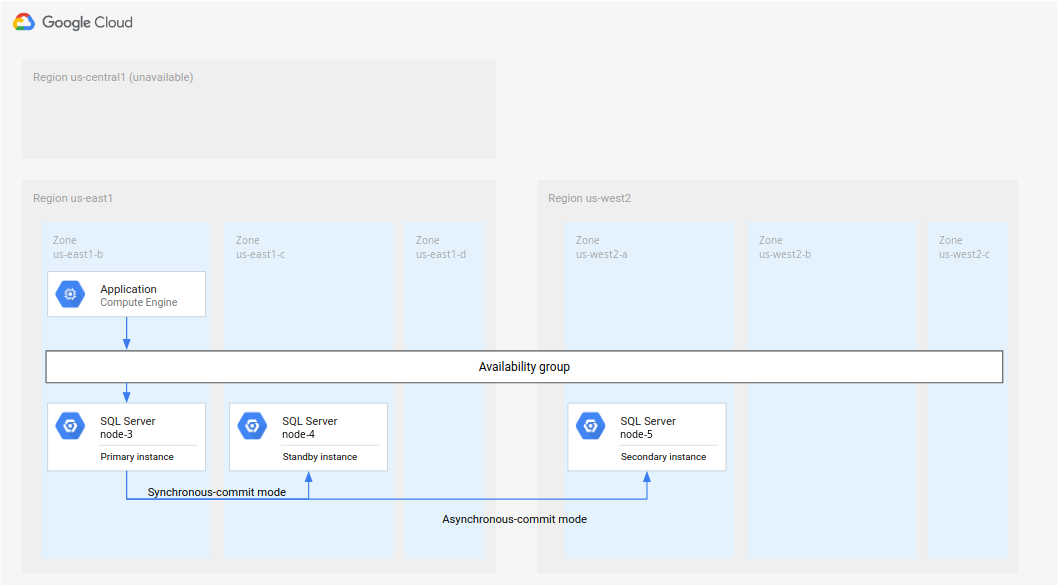
Imagen 5. Recuperación tras desastres con la región principal original R1 no disponible.
Para llevar a cabo esta implementación, debe hacer lo siguiente:
Mantener
node-3como principal enus-east1.Añade una nueva instancia de espera (
node-4) en otra zona deus-east1. Con este paso, la nueva implementación será de alta disponibilidad.Crea una instancia secundaria (
node-5) en otra región, por ejemplo,us-west2. Con este paso se configura la nueva implementación para la recuperación ante desastres. La implementación general ya se ha completado. La arquitectura de la base de datos admite totalmente la alta disponibilidad y la recuperación tras fallos.
(Opcional) Ejecutar una alternativa cuando faltan transacciones
Un fallo menos que ideal se produce cuando una o varias transacciones confirmadas en el servidor principal no se replican en el secundario en el momento del fallo (también conocido como fallo grave). En una conmutación por error, se pierden todas las transacciones confirmadas que no se hayan replicado.
Para probar los pasos de conmutación por error en este caso, debes generar un fallo grave. La mejor forma de generar un error grave es la siguiente:
- Cambia la red para que no haya conectividad entre las instancias principal y secundaria.
- Cambia el contenido principal de alguna forma, por ejemplo, añadiendo una tabla o insertando datos.
- Sigue el proceso de conmutación por error descrito anteriormente para que la secundaria se convierta en la nueva principal.
Los pasos del proceso de conmutación por error son idénticos a los del caso ideal, con la diferencia de que la tabla que se añade a la principal después de que se interrumpa la conectividad de red no se ve en la secundaria.
La única opción que tienes para hacer frente a un error grave es quitar las réplicas (node-1 y node-2) del grupo de disponibilidad y volver a sincronizarlas. La sincronización cambia su estado para que coincida con el
secundario. Se perderá cualquier transacción que no se haya replicado antes del fallo.
Para añadir node-1 como instancia secundaria, puedes seguir los mismos pasos que para añadir node-3 (consulta la sección Añadir la instancia secundaria al clúster de conmutación por error) con la siguiente diferencia: ahora node-3 es la instancia principal, no node-1. Debe sustituir todas las instancias de
node-3 por el nombre del servidor que añada al grupo de disponibilidad. Si vuelves a usar la misma VM (node-1 y node-2), no tienes que añadir el servidor al clúster de conmutación por error de Windows Server. Solo tienes que volver a añadir la instancia de SQL Server al grupo de disponibilidad.
En este punto, node-3 es la principal, y node-1 y node-2 son secundarias. Ahora es posible volver a node-1, poner node-2 en espera y hacer que node-3 sea el secundario. El sistema ahora tiene el mismo estado que antes del fallo.
Conmutación por error automática
Si se conmuta por error automáticamente a una instancia secundaria como principal, pueden surgir problemas. Cuando el dominio de servicio principal original vuelve a estar disponible, se puede producir una situación de cerebro dividido si algunos clientes acceden al secundario mientras que otros escriben en el principal restaurado. En este caso, es posible que el principal y el secundario se actualicen en paralelo y que sus estados diverjan. Para evitar esta situación, en este tutorial se proporcionan instrucciones para realizar una conmutación por error manual en la que tú decides si quieres realizarla o cuándo.
Si implementas una conmutación por error automática, debes asegurarte de que solo una de las instancias configuradas sea la principal y se pueda modificar. Las instancias secundarias o de reserva no deben proporcionar acceso de escritura a ningún cliente (excepto a la instancia principal para la replicación de estado). Además, debes evitar una cadena rápida de conmutaciones por error posteriores en un breve periodo. Por ejemplo, una conmutación por error cada cinco minutos no sería una estrategia de recuperación tras desastres fiable. En los procesos de conmutación por error automatizada, puedes incorporar medidas de protección contra situaciones problemáticas como estas e incluso recurrir a un administrador de bases de datos para tomar decisiones complejas, si es necesario.
Arquitectura de implementación alternativa
En este tutorial se configura una arquitectura de recuperación ante desastres con una instancia secundaria que se convierte en la instancia principal en caso de conmutación por error, tal como se muestra en el siguiente diagrama.

Imagen 6. Arquitectura de recuperación tras fallos estándar con Microsoft SQL Server.
Esto significa que, en caso de conmutación por error, la implementación resultante tendrá una sola instancia hasta que sea posible realizar una conmutación por recuperación o hasta que configures una instancia de espera (para la alta disponibilidad) y una secundaria (para la recuperación ante desastres).
Una arquitectura de implementación alternativa consiste en configurar dos instancias secundarias. Ambas instancias son réplicas de la principal. Si se produce una conmutación por error, puedes volver a configurar una de las secundarias como de espera. En los siguientes diagramas se muestra la arquitectura de implementación antes y después de una conmutación por error.

Imagen 7. Arquitectura de recuperación tras desastres estándar con dos instancias secundarias.

Imagen 8. Arquitectura de recuperación tras desastres estándar con dos instancias secundarias después de la conmutación por error.
Aunque sigues teniendo que convertir una de las dos secundarias en una de reserva (imagen 8), este proceso es mucho más rápido que crear y configurar una de reserva desde cero.
También puedes abordar la recuperación ante desastres con una configuración análoga a esta arquitectura, que utiliza dos instancias secundarias. Además de tener dos secundarias en una segunda región (figura 7), puedes implementar otras dos secundarias en una tercera región. Esta configuración te permite crear de forma eficiente una arquitectura de implementación con alta disponibilidad y recuperación ante desastres después de un fallo en la región principal.