本教程介绍了如何跨两个 Google Cloud 区域部署和管理 Microsoft SQL Server 数据库系统(一种灾难恢复解决方案),以及如何从发生故障的数据库实例故障切换到正常运行的实例。在本文档中,灾难是主数据库发生故障或不可用的事件。
当主数据库所在的地区发生故障或无法访问时,主数据库可能会发生故障。即使地区可用并正常运行,主数据库也可能由于系统错误而发生故障。在这些情况下,灾难恢复是让辅助数据库可供客户端继续进行处理的过程。
本教程面向数据库架构师、管理员和工程师。
目标
- 使用 Microsoft SQL Server 的 AlwaysOn 可用性组在Google Cloud 上部署多区域灾难恢复环境。
- 模拟灾难事件并执行完整的灾难恢复过程,以验证灾难恢复配置。
费用
在本文档中,您将使用 Google Cloud的以下收费组件:
如需根据您的预计使用量来估算费用,请使用价格计算器。
完成本文档中描述的任务后,您可以通过删除所创建的资源来避免继续计费。如需了解详情,请参阅清理。
准备工作
在本教程中,您需要一个 Google Cloud 项目。您可创建一个新项目,也可选择已创建的项目:
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
了解灾难恢复
在 Google Cloud中,灾难恢复旨在提供进程的连续性,尤其是当某个地区出现故障或无法访问时。对于数据库管理系统等系统,您可在至少两个地区部署系统来实现灾难恢复。使用这种设置时,如果其中一个地区不可用,系统也将继续运行。
数据库系统灾难恢复
在主数据库实例发生故障时启用辅助数据库的过程被称为数据库灾难恢复(即数据库 DR)。如需详细了解此概念,请参阅 Microsoft SQL Server 灾难恢复。理想情况下,在主数据库不可用时,辅助数据库的状态与主数据库一致,或者辅助数据库仅丢失一小部分来自主数据库的近期事务。
灾难恢复架构
针对 Microsoft SQL Server,下图展示了支持数据库灾难恢复的最小架构。
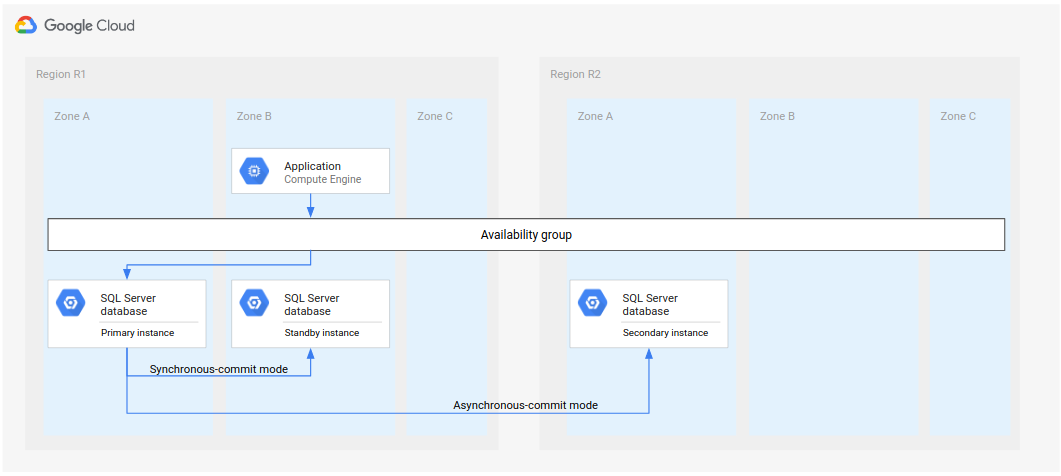
图 1. Microsoft SQL Server 的标准灾难恢复架构。
该架构的工作原理如下:
- Microsoft SQL Server 的两个实例(主实例和备用实例)位于同一地区 (R1),但在不同的区域(区域 A 和 B)中。R1 中的两个实例使用同步提交模式来协调各自的状态。使用同步模式是因为它支持高可用性并维持一致的数据状态。
- Microsoft SQL Server 的其中一个实例(辅助实例或灾难恢复实例)位于第二个地区 (R2) 中。对于灾难恢复,R2 中的辅助实例使用异步提交模式与 R1 中的主实例同步。使用异步模式是因为其性能(它不会减慢主实例中的提交处理速度)。
在上图中,架构展示了可用性组。如果与监听器一起使用,可用性组将向客户端提供相同的连接字符串,前提是由以下实例向客户端提供服务:
- 主实例
- 备用实例(在发生区域故障后)
- 辅助实例(在发生地区故障后,以及辅助实例成为新的主实例后)
在上述架构的一个变体中,您将第一个地区 (R1) 中的两个实例部署到同一区域中。这种方法可能会提高性能,但不提供高可用性;可能一个地区发生服务中断才能启动灾难恢复过程。
基本灾难恢复过程
在某地区不可用,且主数据库故障切换到另一操作地区继续进行处理时,会启动灾难恢复过程。灾难恢复过程会设置必须手动或自动执行的操作步骤,从而减少地区故障并在可用地区中建立正在运行的主实例。
基本的数据库灾难恢复过程包含以下步骤:
- 运行主数据库实例的第一个地区 (R1) 不可用。
- 运营团队识别并正式确认灾难,并确定是否需要故障切换。
- 如果需要故障切换,则第二个区域 (R2) 中的辅助数据库实例用作新的主实例。
- 客户端继续处理新的主数据库,并访问 R2 中的主实例。
虽然这个基本过程会重新创建可正常工作的主数据库,但不创建完整的灾难恢复架构;而在完整架构中,新的主数据库具有备用和辅助数据库实例。
完整灾难恢复过程
完整灾难恢复过程在基本灾难恢复过程的基础上进行了扩展,它在故障切换之后增加了创建完整的灾难恢复架构的步骤。下图展示了完整的数据库灾难恢复架构。
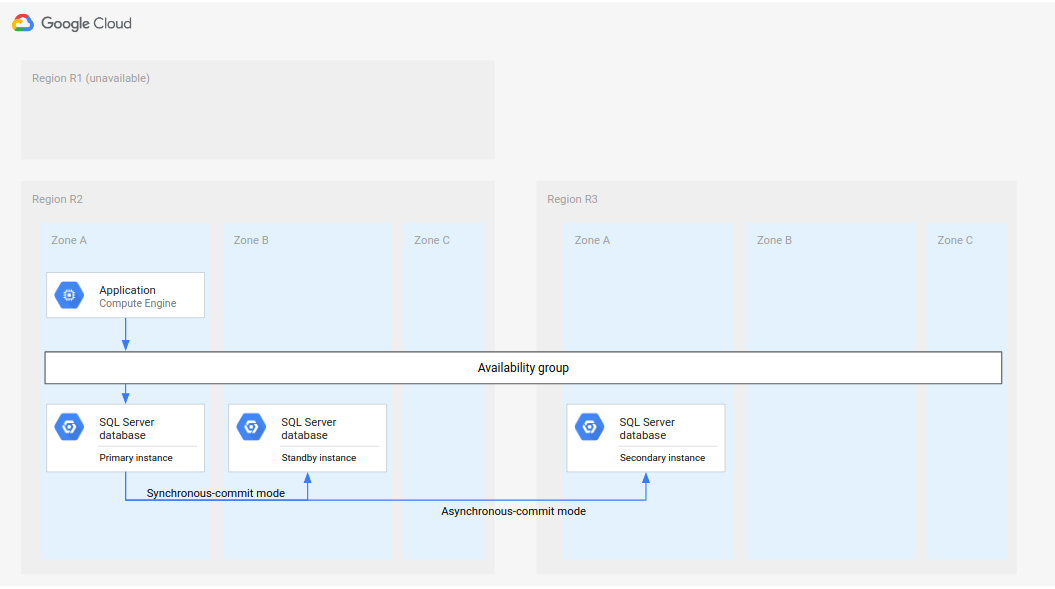
图 2.主地区 (R1) 不可用的灾难恢复。
这种完整的数据库灾难恢复架构的工作原理如下:
- 运行主数据库实例的第一个地区 (R1) 不可用。
- 运营团队识别并正式确认灾难,并确定是否需要故障切换。
- 如果需要故障切换,则第二个地区 (R2) 中的辅助数据库实例用作主实例。
- 在 R2 中创建并启动另一个辅助实例(用作新的备用实例),并将其添加到主实例中。备用实例与主实例位于不同的区域。现在,主数据库由两个高可用性实例(主实例和备用实例)组成。
- 在第三个地区 (R3) 中,创建并启动一个新的辅助(备用)数据库实例。该辅助实例异步连接到 R2 中新的主实例。此时,原始灾难恢复架构将被重新创建且正常运行。
回退到已恢复的地区
第一个区域 (R1) 恢复在线状态后,就可托管新的辅助数据库。如果 R1 很快就变为可用状态,那么您可以在 R1 而不是 R3(第三个区域)中执行完整恢复过程的第 5 步。这样的话,不需要第三个地区。
下图展示了 R1 及时恢复可用时的架构。
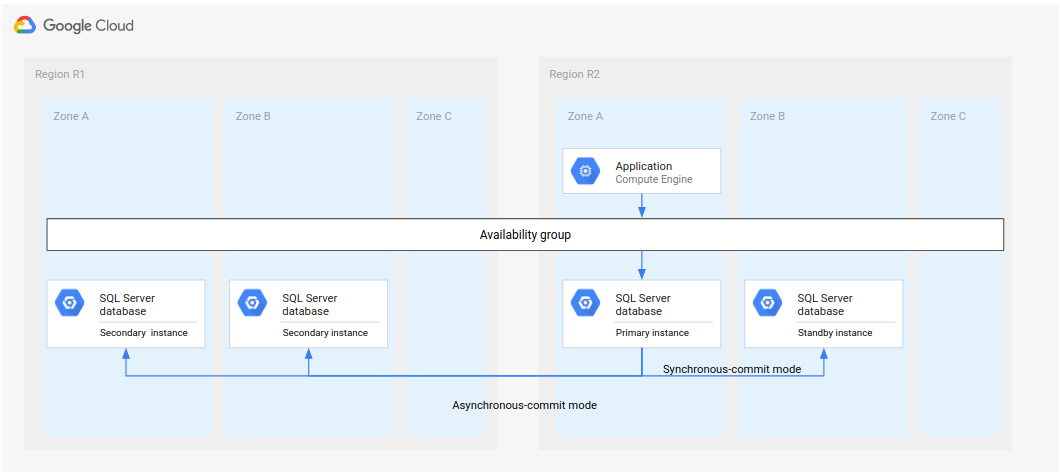
图 3.发生故障的地区 R1 再次变得可用后的灾难恢复。
在此架构中,恢复步骤与之前在完整灾难恢复过程中所述的相同,区别是 R1 变为了辅助实例的位置,而不是 R3。
选择 SQL Server 版本
本教程支持以下版本的 Microsoft SQL Server:
- SQL Server 2016 Enterprise 版本
- SQL Server 2017 Enterprise 版本
- SQL Server 2019 Enterprise 版本
- SQL Server 2022 Enterprise Edition
本教程使用 SQL Server 中的 AlwaysOn 可用性组功能。
如果您不需要高可用性 (HA) Microsoft SQL Server 主数据库,并且使用一个数据库实例作为主数据库实例就已足够,那么可使用以下版本的 SQL Server:
- SQL Server 2016 Standard 版本
- SQL Server 2017 Standard 版本
- SQL Server 2019 Standard 版本
- SQL Server 2022 Standard Edition
SQL Server 的 2016、2017 和 2019 和 2022 版本已在映像中安装 Microsoft SQL Server Management Studio;您不需要单独安装。但在生产环境中,我们建议在每个地区中,您都在一个单独的虚拟机上安装一个 Microsoft SQL Server Management Studio 实例。如果要设置高可用性环境,则应为每个区域安装一次 Microsoft SQL Server Management Studio,确保在另一个区域不可用时它仍然可用。
设置 Microsoft SQL Server 以进行多地区灾难恢复
本部分将以下映像用于 Microsoft SQL Server:
- 对于 Microsoft SQL Server 2016 Enterprise Edition,使用
sql-ent-2016-win-2016 - 对于 Microsoft SQL Server 2017 Enterprise Edition,使用
sql-ent-2017-win-2016 - 对于 Microsoft SQL Server 2019 Enterprise Edition,使用
sql-ent-2019-win-2019 - 对于 Microsoft SQL Server 2022 Enterprise Edition,使用
sql-ent-2022-win-2022
如需查看完整的映像列表,请参阅映像。
设置具有两个实例的高可用性集群
如需为 SQL Server 设置多地区数据库灾难恢复架构,首先要在一个地区创建一个具有两个实例的高可用性 (HA) 集群。其中一个实例充当主实例,另一个实例充当辅助实例。为完成此步骤,请按照配置 SQL Server AlwaysOn 可用性组中的说明进行操作。本教程使用
us-central1作为主区域(称为 R1R1)。在开始之前,请查看以下注意事项:如果您按照配置 SQL Server AlwaysOn 可用性组中的步骤进行操作,则您将在同一区域 (
us-central1) 中创建两个 SQL Server 实例。您将在us-central1-a中部署一个 SQL Server 主实例 (node-1),在us-central1-b中部署一个备用实例 (node-2)。尽管您在本教程中实现了图 4 中的架构,但最佳实践是在多个可用区中设置域控制器。此方法可确保您建立支持高可用性和灾难恢复的数据库架构。例如,如果一个区域发生中断,则该区域不会导致已部署架构出现单点故障。
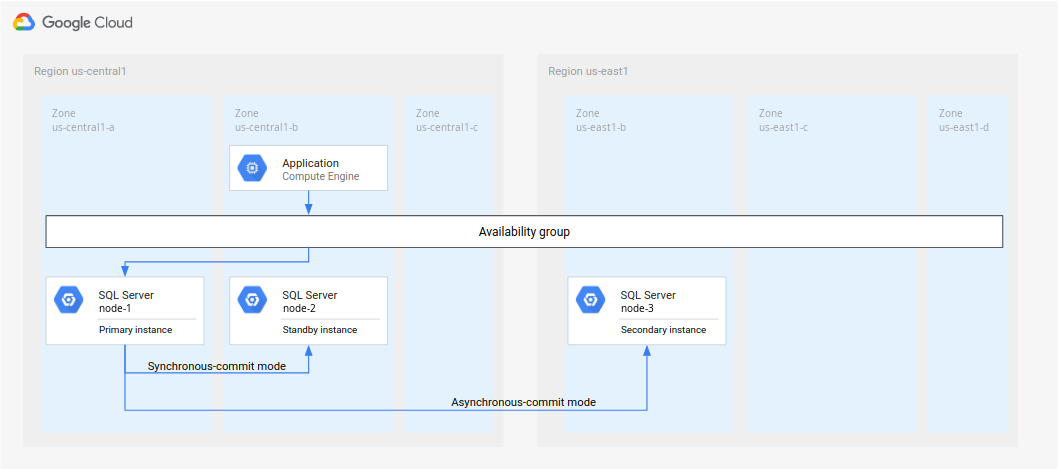
图 4.本教程中实现的标准灾难恢复架构。
添加用于灾难恢复的辅助实例
接下来,设置第三个 SQL Server 实例(名为
node-3的次要实例),并按如下方式配置网络:为 Windows Server 故障切换集群节点创建一个专用脚本。该脚本会安装必要的 Windows 功能,并为 WSFC 和 SQL Server 创建防火墙规则。此外,它还会对数据磁盘格式化,并为 SQL Server 创建数据和日志文件夹:
cat << "EOF" > specialize-node.ps1 $ErrorActionPreference = "stop" # Install required Windows features Install-WindowsFeature Failover-Clustering -IncludeManagementTools Install-WindowsFeature RSAT-AD-PowerShell # Open firewall for WSFC netsh advfirewall firewall add rule name="Allow SQL Server health check" dir=in action=allow protocol=TCP localport=59997 # Open firewall for SQL Server netsh advfirewall firewall add rule name="Allow SQL Server" dir=in action=allow protocol=TCP localport=1433 # Open firewall for SQL Server replication netsh advfirewall firewall add rule name="Allow SQL Server replication" dir=in action=allow protocol=TCP localport=5022 # Format data disk Get-Disk | Where partitionstyle -eq 'RAW' | Initialize-Disk -PartitionStyle MBR -PassThru | New-Partition -AssignDriveLetter -UseMaximumSize | Format-Volume -FileSystem NTFS -NewFileSystemLabel 'Data' -Confirm:$false # Create data and log folders for SQL Server md d:\Data md d:\Logs EOF
初始化以下变量:
VPC_NAME=
VPC_NAMESUBNET_NAME=SUBNET_NAMEREGION=us-east1 PD_SIZE=200 MACHINE_TYPE=n2-standard-8其中:
VPC_NAME:您的 VPC 的名称SUBNET_NAME:您在us-east1区域中的子网的名称
创建一个 SQL Server 实例:
gcloud compute instances create node-3 \ --zone $REGION-b \ --machine-type $MACHINE_TYPE \ --subnet $SUBNET_NAME \ --image-family sql-ent-2022-win-2022 \ --image-project windows-sql-cloud \ --tags wsfc,wsfc-node \ --boot-disk-size 50 \ --boot-disk-type pd-ssd \ --boot-disk-device-name "node-3" \ --create-disk=name=node-3-datadisk,size=$PD_SIZE,type=pd-ssd,auto-delete=no \ --metadata enable-wsfc=true \ --metadata-from-file=sysprep-specialize-script-ps1=specialize-node.ps1为新的 SQL Server 实例设置 Windows 密码:
在 Google Cloud 控制台中,前往 Compute Engine 页面。
在 Compute Engine 集群
node-3的连接列中,选择设置 Windows 密码下拉列表。设置用户名和密码。记下它们供稍后使用。
点击 RDP 连接到
node-3实例。输入上一步中的用户名和密码,然后点击确定。
将实例添加到 Windows 网域:
右键点击开始按钮(或者按 Win+X),然后点击 Windows PowerShell(管理员)。
点击“是”以确认提升权限提示。
将该计算机加入您的 Active Directory 域,然后重启:
Add-Computer -Domain
DOMAIN -Restart将
DOMAIN替换为您的 Active Directory 域的 DNS 名称。等待重启过程完成,大约需要 1 分钟。
将辅助实例添加到故障切换集群
接下来,将辅助实例 (
node-3) 添加到 Windows 故障切换集群:使用 RDP 连接到
node-1或node-2实例,并以管理员用户身份登录。以管理员用户身份打开 PowerShell 窗口,为本教程中的集群环境设置变量:
$node3 = "node-3" $nameWSFC = "
SQLSRV_CLUSTER" # Name of cluster将
SQLSRV_CLUSTER替换为 SQL Server 集群的名称。将辅助实例添加到集群:
Get-Cluster | WHERE Name -EQ $nameWSFC | Add-ClusterNode -NoStorage -Name $node3此命令可能需要一段时间才能运行。该过程可能会停止响应,且可能不会自动返回,因此偶尔需要您按
Enter。在节点中,启用 AlwaysOn 高可用性功能:
Enable-SqlAlwaysOn -ServerInstance $node3 -Force
该节点现已成为故障切换集群的一部分。
将辅助实例添加到现有可用性组
接下来,将 SQL Server 实例(辅助实例)和数据库添加到可用性组:
使用远程桌面连接到
node-3。 使用您的网域用户账号登录。打开 SQL Server 配置管理器。
在导航窗格中,选择 SQL Server 服务
在服务列表中,右键点击 SQL Server (MSSQLSERVER),然后选择属性。
在登录身份下,更改账号:
- 账号名称:
DOMAIN\sql_server,其中DOMAIN是 Active Directory 域的 NetBIOS 名称。 - 密码:输入您之前为 sql_server 网域账号选择的密码。
- 账号名称:
点击确定。
当系统提示您重启 SQL Server 时,请选择是。
在三个实例节点(
node-1、node-2或node-3)中的任何一个节点中,打开 Microsoft SQL Server Management Studio 并连接到主实例node-1。- 转到对象资源管理器。
- 选择连接下拉列表。
- 选择数据库引擎。
- 从服务器名称下拉列表中,选择
node-1。如果未列出集群,请在字段中输入它。
点击新查询。
粘贴以下命令,将 IP 地址添加到用于该节点的监听器,然后点击执行:
ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY LISTENER 'bookshelf' (ADD IP
('LOAD_BALANCER_IP_ADDRESS', '255.255.255.0'))将
LOAD_BALANCER_IP_ADDRESS替换为us-east1区域中的负载均衡器的 IP 地址。在对象资源管理器中,展开 AlwaysOn 高可用性节点,然后展开可用性组节点。
右键点击名为
bookshelf-ag的可用性组,然后选择添加副本。在简介页面上,点击 AlwaysOn 高可用性节点,然后点击可用性组节点。
在连接到副本页面上,点击连接,连接到现有的辅助副本
node-2。在指定副本页面上,点击添加副本 (Add Replica),然后添加新节点
node-3。请勿选中自动故障切换,因为自动故障切换会导致同步提交。此类设置会跨越地区边界,因此我们不建议使用。在选择数据同步页面上,选择自动进行种子设定 (Automatic seeding)。
由于没有监听器,因此验证页面会生成一条警告 - 您可将其忽略。
完成向导步骤。
node-1和node-2的故障切换模式是自动的,而node-3的是手动的。这种差异是区分高可用性与灾难恢复的一种方法。可用性组现已就绪。您配置了两个高可用性节点,还配置了一个灾难恢复节点。
模拟灾难恢复
在本部分中,您将测试本教程的灾难恢复架构,并考虑可选的灾难恢复实现。
模拟中断并执行灾难恢复故障切换
模拟主区域中的故障或服务中断:
在
node-1上的 Microsoft SQL Server Management Studio 中连接到node-1。创建表。在之后的步骤中添加副本后,您可通过检查此表是否存在来验证副本是否有效。
USE bookshelf GO CREATE TABLE dbo.TestTable_Before_DR (ID INT NOT NULL) GO在 Cloud Shell 中,关停主区域
us-central1中的两个服务器:gcloud compute instances stop node-2 --zone us-central1-b --quiet gcloud compute instances stop node-1 --zone us-central1-a --quiet
在
node-3上的 Microsoft SQL Server Management Studio 中连接到node-3。执行故障切换,并将可用性模式设置为“同步提交”。由于节点处于异步提交模式,因此必须强制执行故障切换。
ALTER AVAILABILITY GROUP [bookshelf-ag] FORCE_FAILOVER_ALLOW_DATA_LOSS GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-3' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GO您可以继续处理;
node-3现在是主实例。(可选)在
node-3中创建一个新表。在将副本与新的主实例同步之后,请检查此表是否已复制到副本。USE bookshelf GO CREATE TABLE dbo.TestTable_After_DR (ID INT NOT NULL) GO
虽然此时
node-3是主实例,但我们建议您回退到原始地区或设置新的辅助实例和备用实例,以便重新创建完整的灾难恢复架构。下一部分将讨论这些方案。(可选)重新创建会完全复制事务的灾难恢复架构
此用例解决故障的方式是,在主数据库失败之前,所有事务都从主数据库复制到辅助数据库。在这种理想情况中,没有任何数据丢失。发生故障时,辅助实例的状态与主实例的状态一致。
在此情况下,您可以通过两种方式重新创建完整的灾难恢复架构:
- 回退到原始主实例和原始备用实例(如有)。
- 如果原始主实例和备用实例不可用,请为
node-3创建一个新的备用实例和辅助实例。
方法 1:回退到原始的主实例和备用实例
在 Cloud Shell 中,启动原始(旧)主实例和备用实例:
gcloud compute instances start node-1 --zone us-central1-a --quiet gcloud compute instances start node-2 --zone us-central1-b --quiet在 Microsoft SQL Server Management Studio 中,将
node-1和node-2重新添加为辅助副本:在
node-3上,在异步提交模式下添加两个服务器:USE [master] GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (FAILOVER_MODE = MANUAL) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (FAILOVER_MODE = MANUAL) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO在
node-1上,重新开始同步数据库:USE [master] GO ALTER DATABASE [bookshelf] SET HADR RESUME; GO在
node-2上,重新开始同步数据库:USE [master] GO ALTER DATABASE [bookshelf] SET HADR RESUME; GO
将
node-1重新设置为主实例:在
node-3上,将node-1的可用性模式更改为同步提交。实例node-1再次成为主实例。USE [master] GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GO在
node-1上,将node-1更改为主节点,将其他两个节点更改为辅助节点:USE [master] GO -- Node 1 becomes primary ALTER AVAILABILITY GROUP [bookshelf-ag] FORCE_FAILOVER_ALLOW_DATA_LOSS; GO -- Node 2 has synchronous commit ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GO -- Node 3 has asynchronous commit ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-3' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO
在所有命令成功后,
node-1是主实例,其他节点是次要实例,如下图所示。
方法 2:设置新的主实例和备用实例
您可能无法从故障恢复原始主实例和备用实例,恢复它们需要太长时间,或者该地区无法访问。一种方法是将
node-3保留为主实例,然后创建新的备用实例和新的次要实例,如下图所示。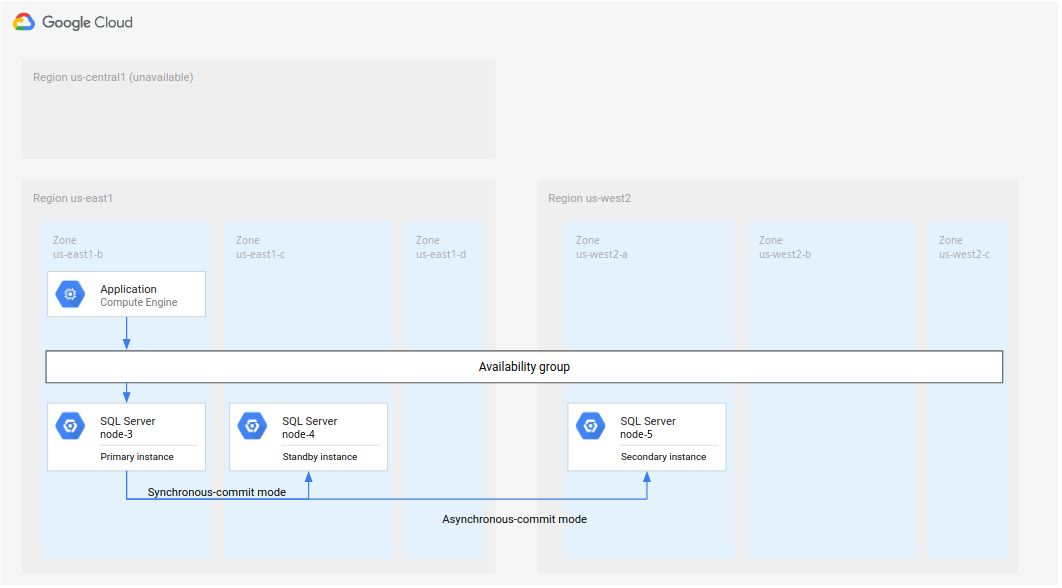
图 5.原始主地区 R1 不可用的灾难恢复
此实现要求您执行以下操作:
在
us-east1中将node-3保留为主实例。在
us-east1中的其他区域中添加新的备用实例 (node-4)。此步骤将创建新的部署作为高可用性部署。在单独的地区(例如
us-west2)中创建一个新的辅助实例 (node-5)。此步骤设置新的灾难恢复部署。整体部署现已完成。数据库架构完全支持高可用性和灾难恢复。
(可选)缺少事务时执行回退
“不太理想的故障”也称为硬故障,它是指在主实例上提交的一个或多个事务不会在出现故障时复制到辅助实例。在故障切换中,所有已提交但未复制的事务都将丢失。
要测试此方案的故障切换步骤,您需要生成一个硬故障。生成硬故障的最佳做法如下:
- 更改网络,使主实例和辅助实例之间断开连接。
- 通过某些方式更改主实例,例如添加表或插入一些数据。
- 按照前面所述的步骤逐步执行故障切换过程,使辅助实例成为新的主实例。
故障切换过程的步骤与理想方案相同,只是在网络连接中断后添加到主实例的表在辅助实例中不可见。
要处理硬故障,您只能从可用性组中删除副本(
node-1和node-2),然后重新同步副本。同步操作会更改其状态以匹配辅助实例。故障前未复制的事务都会丢失。要将
node-1添加为辅助实例,您可以按照与之前添加node-3相同的步骤进行操作(请参阅前面的将辅助实例添加到故障切换集群),但区别在于主实例现在是node-3而不是node-1。您需要将node-3的任何实例替换为您添加到可用性组的服务器的名称。如果您重复使用相同的虚拟机(node-1和node-2),则无需将服务器添加到 Windows Server 故障切换集群中;只需将 SQL Server 实例添加回可用性组。此时,
node-3是主实例,node-1和node-2是辅助实例。现在可以回退到node-1,使node-2成为备用实例,使node-3成为辅助实例。系统现在的状态与故障之前的状态相同。自动故障切换
自动故障切换到作为主实例的辅助实例会引发问题。在原始主实例再次变得可用之后,如果某些客户端访问辅助实例而其他客户端写入已还原的主实例,则可能发生脑裂的情况。在这种情况下,主实例和辅助实例可能会并行更新,而且它们的状态有所不同。为避免这种情况,本教程提供了有关手动故障切换的说明,您可以根据说明确定是否(或何时)进行故障切换。
如果您实现自动故障切换,则必须确保只有一个已配置的实例是主实例且该实例可修改。任何备用实例或辅助实例都不得向任何客户端提供写入权限(状态复制的主实例除外)。此外,您还必须避免在短时间内快速进行后续的故障切换。例如,每 5 分钟进行一次故障切换的这种灾难恢复策略并不可靠。对于自动故障切换过程,您可以采取针对此类问题场景的保护措施;如果需要,甚至可以让数据库管理员帮助做出复杂的决策。
替代的部署架构
本教程将建立一个具有辅助实例的灾难恢复架构,该实例将成为故障切换中的主实例,如下图所示。
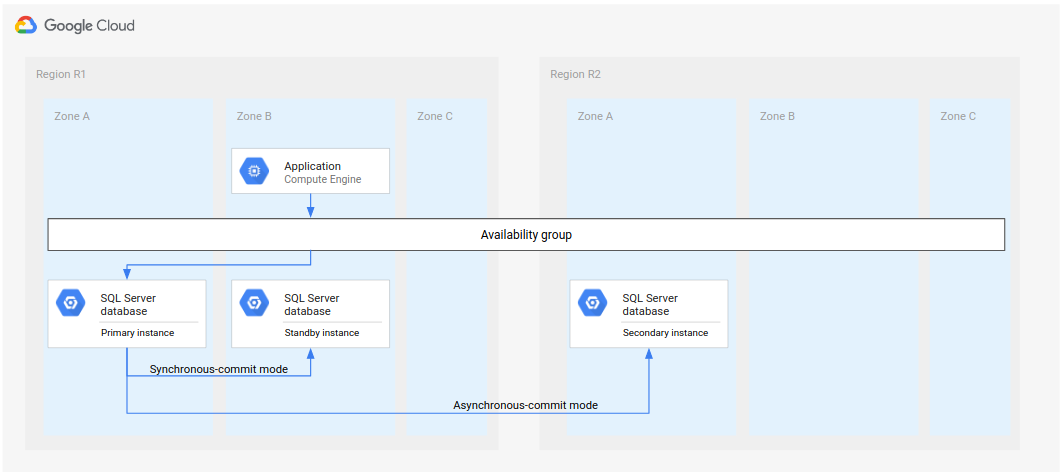
图 6.使用 Microsoft SQL Server 的标准灾难恢复架构。
这意味着在故障切换时,生成的部署直到可执行回退或者您配置备用(针对高可用性)和辅助(针对灾难恢复)实例之前,都只有一个实例。
替代的部署架构是配置两个辅助实例。两个实例都是主实例的副本。如果发生故障切换,您可以将其中一个实例重新配置为备用实例。下图显示了故障切换前后的部署架构。

图 7.具有两个辅助实例的标准灾难恢复架构。
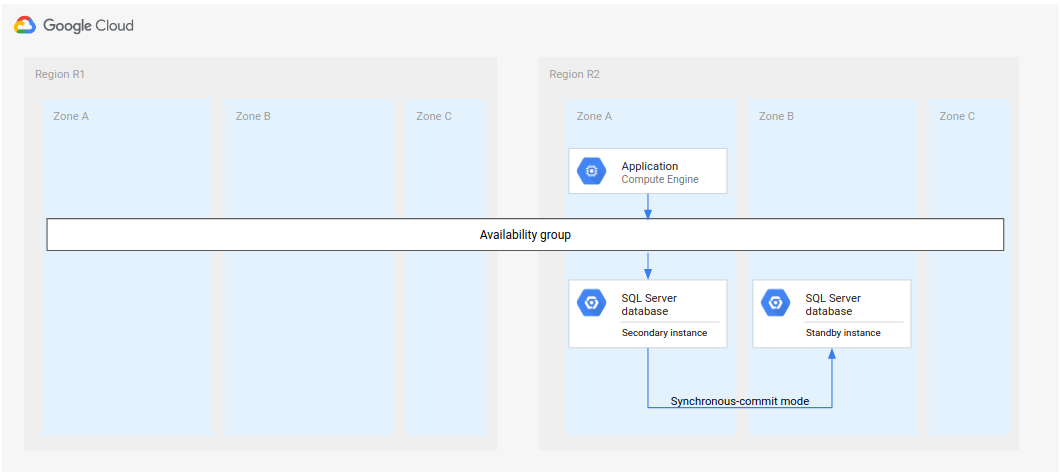
图 8.故障切换后具有两个辅助实例的标准灾难恢复架构。
尽管您仍然必须使用两个备用实例中的其中一个作为备用实例(图 8),但此过程比从头开始创建和配置新的备用实例要快得多。
您还可使用与这种采用两个辅助实例类似的架构来处理灾难恢复。除了第二个地区有两个辅助实例(图 7)之外,您还可以在第三个地区再部署两个辅助实例。借助此设置,您可以在主地区发生故障后高效地创建支持高可用性和灾难恢复的部署架构。
清理
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,请执行以下操作:
删除项目
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
后续步骤
- 探索有关 Google Cloud 的参考架构、图表和最佳做法。查看我们的 Cloud 架构中心。