Neste tutorial, descrevemos como implantar e gerenciar um sistema de banco de dados do Microsoft SQL Server em duas regiões do Google Cloud como uma solução de recuperação de desastres (DR) e como fazer failover de uma instância de banco de dados com falha para uma instância que opera normalmente. Para os fins deste documento, um desastre é um evento em que um banco de dados primário falha ou fica indisponível.
Um banco de dados primário pode falhar quando a região onde ele está localizado falha ou fica inacessível. Mesmo que uma região esteja disponível e operando normalmente, um banco de dados primário pode falhar por causa de um erro do sistema. Nesses casos, a recuperação de desastres é o processo de disponibilizar um banco de dados secundário para os clientes continuarem o processamento.
Este tutorial se destina a arquitetos de bancos de dados, administradores e engenheiros.
Noções básicas sobre a recuperação de desastres
No Google Cloud, a recuperação de desastres (DR) significa fornecer a continuidade do processamento, especialmente quando uma região falha ou fica inacessível. Para sistemas como o de gerenciamento de banco de dados, implemente a DR implantando o sistema em pelo menos duas regiões. Com essa configuração, o sistema continuará funcionando se uma região ficar indisponível.
Recuperação de desastres do sistema de banco de dados
O processo de disponibilização de um banco de dados secundário quando a instância primária falha é chamado de recuperação de desastres do banco de dados (ou DR do banco de dados). Para uma discussão detalhada sobre esse conceito, consulte Recuperação de desastres para o Microsoft SQL Server. O ideal é que o estado do banco de dados secundário seja consistente com o primário no momento em que o primário fica indisponível, ou que o banco de dados secundário não tenha apenas um pequeno grupo de transações recentes do primário.
Arquitetura de recuperação de desastres
No Microsoft SQL Server, o diagrama a seguir mostra uma arquitetura mínima compatível com a DR do banco de dados.
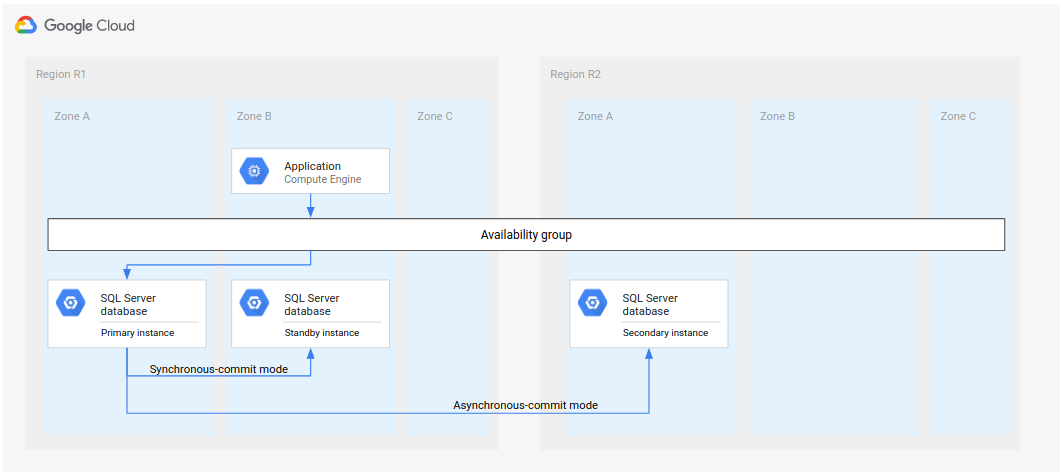
Figura 1. Arquitetura de recuperação de desastres padrão com o Microsoft SQL Server.
Essa arquitetura funciona da seguinte maneira:
- Duas instâncias do Microsoft SQL Server (uma instância primária e uma de espera) estão localizadas na mesma região (R1), mas em zonas diferentes (zonas A e B). As duas instâncias na R1 coordenam os estados usando o modo de confirmação síncrona. O modo síncrono é usado porque aceita alta disponibilidade e mantém um estado de dados consistente.
- Uma instância do Microsoft SQL Server (a instância secundária ou de recuperação de desastres) está localizada em uma segunda região (R2). Para a DR, a instância secundária na R2 é sincronizada com a instância primária na R1 usando o modo de confirmação assíncrona. O modo assíncrono é usado devido ao desempenho, já que ele não desacelera o processamento de confirmação na instância primária.
No diagrama anterior, a arquitetura mostra um grupo de disponibilidade. O grupo de disponibilidade, se usado com um listener, fornecerá a mesma string de conexão aos clientes se eles forem processados por instâncias destes tipos:
- Instância primária
- Instância de espera (após uma falha da zona)
- Instância secundária (após uma falha da região e depois que a instância secundária torna-se a nova instância primária)
Em uma variante da arquitetura acima, você implanta as duas instâncias que estão na primeira região (R1) na mesma zona. Essa abordagem pode melhorar o desempenho, mas não é altamente disponível. Uma única falha da zona pode ser necessária para iniciar o processo de DR.
Processo básico de recuperação de desastres
O processo de DR começa quando uma região fica indisponível e o banco de dados primário faz o failover para retomar o processamento em outra região operacional. O processo de DR determina as etapas operacionais que precisam ser executadas, manual ou automaticamente, para reduzir a falha da região e estabelecer uma instância primária em execução em uma região disponível.
Um processo básico de DR do banco de dados consiste nas seguintes etapas:
- A primeira região (R1), que está executando a instância primária do banco de dados, fica indisponível.
- A equipe de operações reconhece e confirma formalmente o desastre e decide se um failover é necessário.
- Se for necessário um failover, a instância de banco de dados secundária na segunda região (R2) se tornará a nova instância primária.
- Os clientes retomam o processamento no novo banco de dados primário e acessam a instância primária na R2.
Ainda que esse processo básico estabeleça um banco de dados primário de trabalho novamente, ele não estabelece uma arquitetura de DR completa, em que o novo primário tem uma instância de banco de dados de espera e uma secundária.
Processo completo de recuperação de desastres
O processo completo de DR é uma extensão do processo básico porque adiciona etapas para estabelecer uma arquitetura completa de DR após um failover. No diagrama a seguir, mostramos uma arquitetura completa de DR de banco de dados.
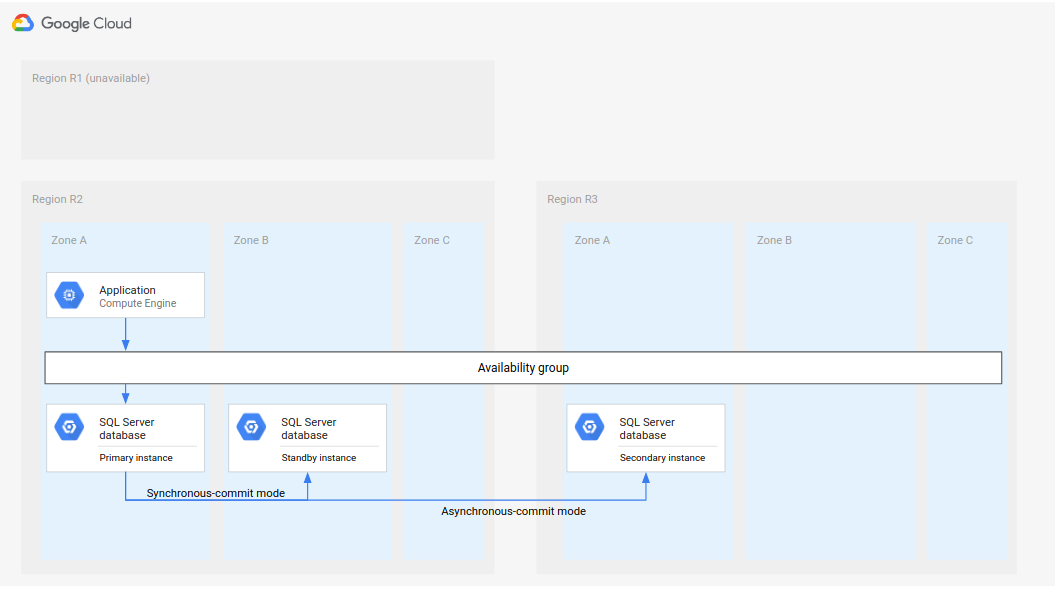
Figura 2. Recuperação de desastres com uma região primária indisponível (R1).
Essa arquitetura completa de DR de banco de dados funciona da seguinte maneira:
- A primeira região (R1), que está executando a instância primária do banco de dados, fica indisponível.
- A equipe de operações reconhece e confirma formalmente o desastre e decide se um failover é necessário.
- Se for necessário um failover, a instância de banco de dados secundária na segunda região (R2) se tornará a instância primária.
- Outra instância secundária, a nova instância de espera, é criada e iniciada na R2 e adicionada à instância primária. A instância de espera está em uma zona diferente da instância primária. Agora, o banco de dados primário consiste em duas instâncias, primária e de espera, que estão altamente disponíveis.
- Em uma terceira região (R3), uma nova instância de banco de dados secundária (de espera) é criada e iniciada. Essa instância secundária é conectada de maneira assíncrona à nova instância primária na R2. Nesse ponto, a arquitetura original de recuperação de desastres é recriada e está operante.
Fallback para uma região recuperada
Depois que a primeira região (R1) voltar a ficar on-line, ela poderá hospedar o novo banco de dados secundário. Se a R1 logo ficar disponível, será possível implementar a etapa 5 do processo de recuperação completo na R1, em vez da R3 (a terceira região). Nesse caso, uma terceira região não é necessária.
No diagrama a seguir, mostramos a arquitetura caso a R1 fique disponível a tempo.
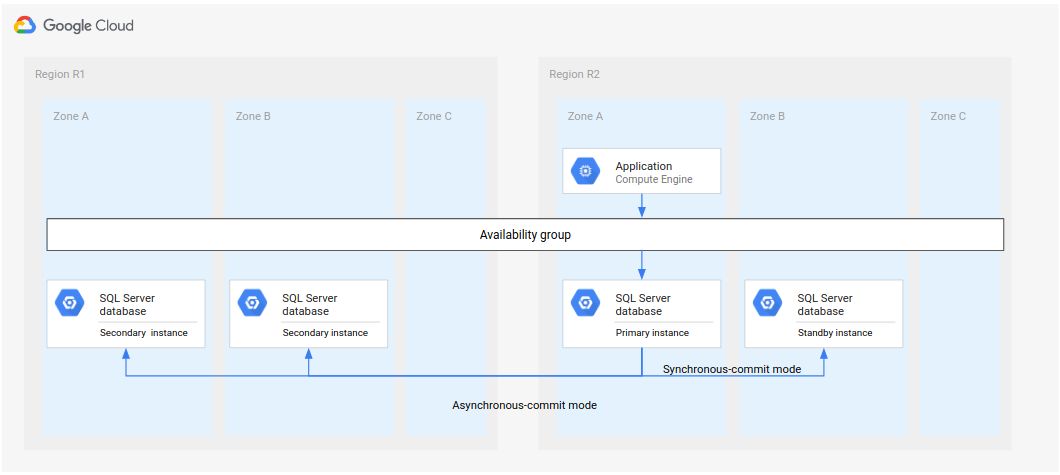
Figura 3. A recuperação de desastres após a região R1 com falha fica disponível novamente.
Nesta arquitetura, as etapas de recuperação são as mesmas descritas anteriormente em Processo completo de recuperação de desastres, com a diferença de que a R1 torna-se o local das instâncias secundárias, em vez da R3.
Como escolher uma edição do SQL Server
Este tutorial considera as seguintes versões do Microsoft SQL Server:
- SQL Server 2016 Enterprise Edition
- SQL Server 2017 Enterprise Edition
- SQL Server 2019 Enterprise Edition
- SQL Server 2022 Enterprise Edition
Neste tutorial, o recurso Grupos de Disponibilidade AlwaysOn é usado no SQL Server.
Se você não precisar de um banco de dados primário do Microsoft SQL Server com alta disponibilidade (HA, na sigla em inglês), e uma instância primária de banco de dados for suficiente, use as seguintes versões do SQL Server:
- SQL Server 2016 Standard Edition
- SQL Server 2017 Standard Edition
- SQL Server 2019 Standard Edition
- SQL Server 2022 Standard Edition
As versões 2016, 2017, 2019 e 2022 do SQL Server têm o Microsoft SQL Server Management Studio instalado na imagem. Você não precisa instalá-lo separadamente. No entanto, em um ambiente de produção, recomendamos instalar uma instância do Microsoft SQL Server Management Studio em uma VM separada em cada região. Se você configurar um ambiente de HA, convém instalar o Microsoft SQL Server Management Studio uma vez em cada zona para garantir que ele continue disponível se outra zona ficar indisponível.
Como configurar o Microsoft SQL Server para DR multirregional
Esta seção usa as seguintes imagens do Microsoft SQL Server:
sql-ent-2016-win-2016para o Microsoft SQL Server 2016 Enterprise Editionsql-ent-2017-win-2016para Microsoft SQL Server 2017 Enterprise Editionsql-ent-2019-win-2019para o Microsoft SQL Server 2019 Enterprise Editionsql-ent-2022-win-2022para o Microsoft SQL Server 2022 Enterprise Edition
Para uma lista completa de imagens, consulte Imagens.
Configurar um cluster de alta disponibilidade de duas instâncias
Para configurar uma arquitetura de DR de banco de dados multirregional para SQL Server,
primeiro crie um cluster de alta disponibilidade (HA, na sigla em inglês) de duas instâncias em uma região. Uma delas
serve como primária e a outra como secundária. Para
realizar esta etapa, siga as instruções em
Como configurar grupos de disponibilidade AlwaysOn do SQL Server.
Neste tutorial, usamos us-central1 para a região primária (chamada de R1).
Antes de começar, leia as considerações a seguir:
Se seguiu as etapas em Como configurar os grupos de disponibilidade SQL Server AlwaysOn, você terá criado duas instâncias SQL Server na mesma região (
us-central1). Você implantou uma instância primária do SQL Server (node-1) emus-central1-ae uma instâncias de espera (node-2) emus-central1-b.Embora você implemente a arquitetura na Figura 4 para este tutorial, é uma prática recomendada configurar um controlador de domínio em mais de uma zona. Essa abordagem garante que você estabeleça uma arquitetura de banco de dados habilitada para HA e DR. Por exemplo, se houver uma interrupção em uma zona, ela não se tornará um ponto único de falha da arquitetura implantada.
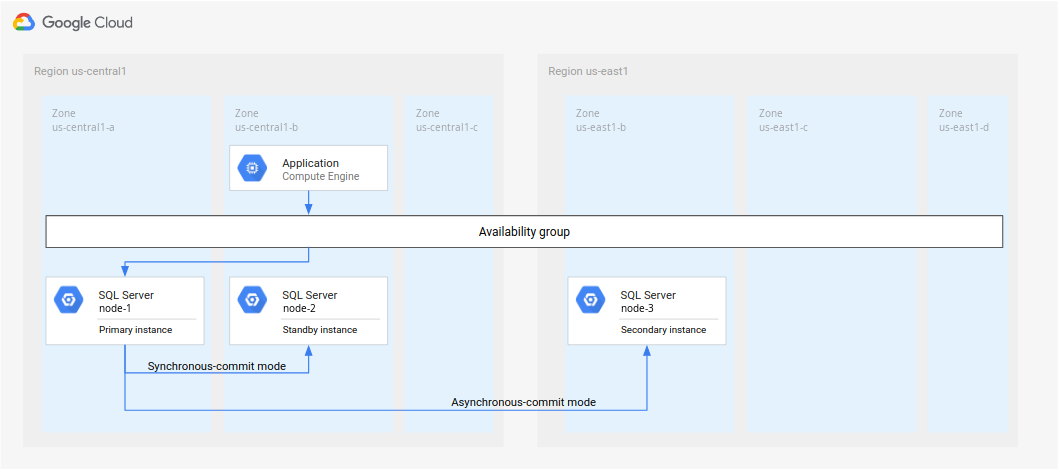
Figura 4. Arquitetura de recuperação de desastres padrão implementada neste tutorial.
Adicionar uma instância secundária para recuperação de desastres
Em seguida, configure uma terceira instância do SQL Server (uma instância secundária que é
chamada node-3) e configure a rede da seguinte maneira:
Crie um script de especialização para os nós do cluster de failover do Windows Server. O script instala o recurso necessário do Windows e cria regras de firewall para o WSFC e o SQL Server. Ele também formata o disco de dados e cria pastas de dados e registros para o SQL Server:
cat << "EOF" > specialize-node.ps1 $ErrorActionPreference = "stop" # Install required Windows features Install-WindowsFeature Failover-Clustering -IncludeManagementTools Install-WindowsFeature RSAT-AD-PowerShell # Open firewall for WSFC netsh advfirewall firewall add rule name="Allow SQL Server health check" dir=in action=allow protocol=TCP localport=59997 # Open firewall for SQL Server netsh advfirewall firewall add rule name="Allow SQL Server" dir=in action=allow protocol=TCP localport=1433 # Open firewall for SQL Server replication netsh advfirewall firewall add rule name="Allow SQL Server replication" dir=in action=allow protocol=TCP localport=5022 # Format data disk Get-Disk | Where partitionstyle -eq 'RAW' | Initialize-Disk -PartitionStyle MBR -PassThru | New-Partition -AssignDriveLetter -UseMaximumSize | Format-Volume -FileSystem NTFS -NewFileSystemLabel 'Data' -Confirm:$false # Create data and log folders for SQL Server md d:\Data md d:\Logs EOF
Inicialize as seguintes variáveis:
VPC_NAME=
VPC_NAMESUBNET_NAME=SUBNET_NAMEREGION=us-east1 PD_SIZE=200 MACHINE_TYPE=n2-standard-8Em que:
VPC_NAME: nome da VPCSUBNET_NAME: nome da sub-rede para a regiãous-east1
Crie uma instância do SQL Server:
gcloud compute instances create node-3 \ --zone $REGION-b \ --machine-type $MACHINE_TYPE \ --subnet $SUBNET_NAME \ --image-family sql-ent-2022-win-2022 \ --image-project windows-sql-cloud \ --tags wsfc,wsfc-node \ --boot-disk-size 50 \ --boot-disk-type pd-ssd \ --boot-disk-device-name "node-3" \ --create-disk=name=node-3-datadisk,size=$PD_SIZE,type=pd-ssd,auto-delete=no \ --metadata enable-wsfc=true \ --metadata-from-file=sysprep-specialize-script-ps1=specialize-node.ps1Defina uma senha do Windows para a nova instância do SQL Server:
No console Google Cloud , acesse a página do Compute Engine.
Na coluna Conectar do cluster do Compute Engine
node-3, selecione a lista suspensa Configurar a senha do Windows .Defina o nome de usuário e a senha. Anote-os para usar mais tarde.
Clique em RDP para se conectar à instância
node-3.Digite o nome de usuário e a senha da etapa anterior e clique em OK.
Adicione a instância ao domínio do Windows:
Clique com o botão direito do mouse no botão Iniciar (ou pressione Win+X) e clique em Windows PowerShell (administrador).
Confirme a elevação do prompt clicando em "Sim".
Associe o computador ao seu domínio do Active Directory e reinicie:
Add-Computer -Domain
DOMAIN -RestartSubstitua
DOMAINpelo nome DNS do seu domínio do Active Directory.Aguarde aproximadamente um minuto para que a reinicialização seja concluída.
Adicionar a instância secundária ao cluster de failover
Em seguida, adicione a instância secundária (node-3) ao cluster de failover do
Windows:
Conecte-se às instâncias
node-1ounode-2usando o RDP e faça login como usuário administrador.Abra uma janela do PowerShell como administrador e defina variáveis para o ambiente do cluster neste tutorial:
$node3 = "node-3" $nameWSFC = "
SQLSRV_CLUSTER" # Name of clusterSubstitua
SQLSRV_CLUSTERpelo nome do cluster do SQL Server.Adicione a instância secundária ao cluster:
Get-Cluster | WHERE Name -EQ $nameWSFC | Add-ClusterNode -NoStorage -Name $node3A execução desse comando pode levar um tempo. Como o processo pode parar de responder e não retornar automaticamente, pressione
Enterocasionalmente.No nó, ative o recurso de alta disponibilidade AlwaysOn:
Enable-SqlAlwaysOn -ServerInstance $node3 -Force
O nó agora faz parte do cluster de failover.
Adicionar a instância secundária ao grupo de disponibilidade atual
Em seguida, adicione a instância do SQL Server (a instância secundária) e o banco de dados ao grupo de disponibilidade:
Conecte-se a
node-3usando a Área de trabalho remota. Faça login com a conta de usuário do domínio.Abra o SQL Server Configuration Manager.
No painel de navegação, selecione Serviços do SQL Server
Na lista de serviços, clique com o botão direito do mouse em SQL Server (MSSQLSERVER) e selecione Propriedades.
Em Fazer logon como, altere a conta:
- Nome da conta:
DOMAIN\sql_serverem queDOMAINé o nome do NetBIOS do seu domínio do Active Directory - Senha: digite a senha escolhida anteriormente para a conta do domínio sql_server.
- Nome da conta:
Clique em OK.
Quando solicitado a reiniciar o SQL Server, selecione Sim.
Em qualquer um dos três nós da instância (
node-1,node-2ounode-3), abra o Microsoft SQL Server Management Studio e conecte-se à instância primária (node-1):- Acesse o Pesquisador de Objetos.
- Selecione a lista suspensa Conectar.
- Selecione Mecanismo do banco de dados.
- Na lista suspensa Nome do servidor, selecione
node-1. Se o cluster não constar na lista, insira-o no campo.
Clique em Nova consulta.
Cole o seguinte comando para adicionar um endereço IP ao listener usado para o nó e clique em Executar:
ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY LISTENER 'bookshelf' (ADD IP
('LOAD_BALANCER_IP_ADDRESS', '255.255.255.0'))Substitua
LOAD_BALANCER_IP_ADDRESSpelo endereço IP do balanceador de carga na regiãous-east1.No Pesquisador de Objetos, expanda o nó Alta Disponibilidade AlwaysOn e, em seguida, expanda o nó Grupos de Disponibilidade.
Clique com o botão direito do mouse no grupo de disponibilidade
bookshelf-age selecione Adicionar Réplica.Na página Introdução, clique no nó Alta Disponibilidade AlwaysOn e depois no nó Grupos de Disponibilidade.
Na página Conectar às Réplicas, clique em Conectar para se conectar à réplica secundária atual
node-2.Na página Especificar Réplicas, clique em Adicionar Réplica e adicione o novo nó
node-3. Não selecione Failover Automático, porque ele gera uma confirmação síncrona. Essa configuração ultrapassa os limites regionais, o que não é recomendado.Na página Selecionar Sincronização de Dados, selecione Propagação automática.
Como não há um listener, a página Validação gera um aviso, que pode ser ignorado.
Conclua as etapas do assistente.
O modo de failover para node-1 e node-2 é automático, enquanto o de node-3
é manual. Essa diferença é uma maneira de distinguir a alta disponibilidade
da recuperação de desastres.
O grupo de disponibilidade agora está pronto. Você configurou dois nós para alta disponibilidade e um terceiro nó para recuperação de desastres.
Como simular uma recuperação de desastres
Nesta seção, você testará a arquitetura de recuperação de desastres deste tutorial e considerará outras implementações de DR.
Simular uma interrupção e executar um failover de DR
Simule uma falha ou interrupção na região primária:
No Microsoft SQL Server Management Studio em
node-1, conecte-se anode-1.Crie uma tabela. Depois de adicionar réplicas nas etapas posteriores, verifique se a réplica funciona confirmando se esta tabela está presente.
USE bookshelf GO CREATE TABLE dbo.TestTable_Before_DR (ID INT NOT NULL) GONo Cloud Shell, desligue os dois servidores na região primária
us-central1:gcloud compute instances stop node-2 --zone us-central1-b --quiet gcloud compute instances stop node-1 --zone us-central1-a --quiet
No Microsoft SQL Server Management Studio em
node-3, conecte-se anode-3.Execute um failover e defina o modo de disponibilidade como confirmação síncrona. É necessário forçar um failover porque o nó está no modo de confirmação assíncrona.
ALTER AVAILABILITY GROUP [bookshelf-ag] FORCE_FAILOVER_ALLOW_DATA_LOSS GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-3' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GOÉ possível retomar o processamento.
node-3agora é a instância primária.(Opcional) Crie uma nova tabela em
node-3. Depois de sincronizar as réplicas com a nova instância primária, verifique se esta tabela foi replicada para as réplicas.USE bookshelf GO CREATE TABLE dbo.TestTable_After_DR (ID INT NOT NULL) GO
Neste momento, node-3 é a instância primária, mas convém voltar à região original
ou configurar uma nova instância secundária e de espera
para recriar uma arquitetura de DR completa novamente. Na próxima seção,
discutiremos essas opções.
Recriar uma arquitetura de DR que replique totalmente as transações (opcional)
Neste caso de uso, resolvemos uma falha em que todas as transações são replicadas do banco de dados primário para o secundário antes da falha no primário. Neste cenário ideal, os dados não são perdidos. O estado do banco de dados secundário está consistente com o primário no ponto de falha.
Neste cenário, é possível recriar uma arquitetura completa de DR de duas maneiras:
- Retornar ao banco de dados primário e de espera originais, se estiverem disponíveis.
- Criar um novo banco de dados de espera e secundário para
node-3, caso o primário e de espera originais não estejam disponíveis.
Abordagem 1: retornar ao banco de dados primário original e de espera
No Cloud Shell, inicie o banco de dados primário original (antigo) e de espera:
gcloud compute instances start node-1 --zone us-central1-a --quiet gcloud compute instances start node-2 --zone us-central1-b --quietNo Microsoft SQL Server Management Studio, adicione
node-1enode-2novamente como réplicas secundárias:Em
node-3, adicione os dois servidores no modo de confirmação assíncrona:USE [master] GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (FAILOVER_MODE = MANUAL) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (FAILOVER_MODE = MANUAL) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GOEm
node-1, comece a sincronizar os bancos de dados novamente:USE [master] GO ALTER DATABASE [bookshelf] SET HADR RESUME; GOEm
node-2, comece a sincronizar os bancos de dados novamente:USE [master] GO ALTER DATABASE [bookshelf] SET HADR RESUME; GO
Torne
node-1o primário novamente:Em
node-3, altere o modo de disponibilidade denode-1para confirmação síncrona. A instâncianode-1se tornará a primária novamente.USE [master] GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GOEm
node-1, alterenode-1para ser o primário e os dois outros nós para serem os secundários:USE [master] GO -- Node 1 becomes primary ALTER AVAILABILITY GROUP [bookshelf-ag] FORCE_FAILOVER_ALLOW_DATA_LOSS; GO -- Node 2 has synchronous commit ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GO -- Node 3 has asynchronous commit ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-3' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO
Depois que todos os comandos forem concluídos, node-1 será o primário, e os outros nós
serão secundários, conforme mostrado no diagrama a seguir.
Abordagem 2: configurar uma nova instância primária e de espera
Talvez não seja possível recuperar as instâncias primária original e de espera
da falha, pode levar muito tempo para recuperá-las ou a região
pode ficar inacessível. Uma abordagem é manter node-3 como a instância primária e
criar uma nova instância de espera e secundária, conforme mostrado no diagrama a seguir.
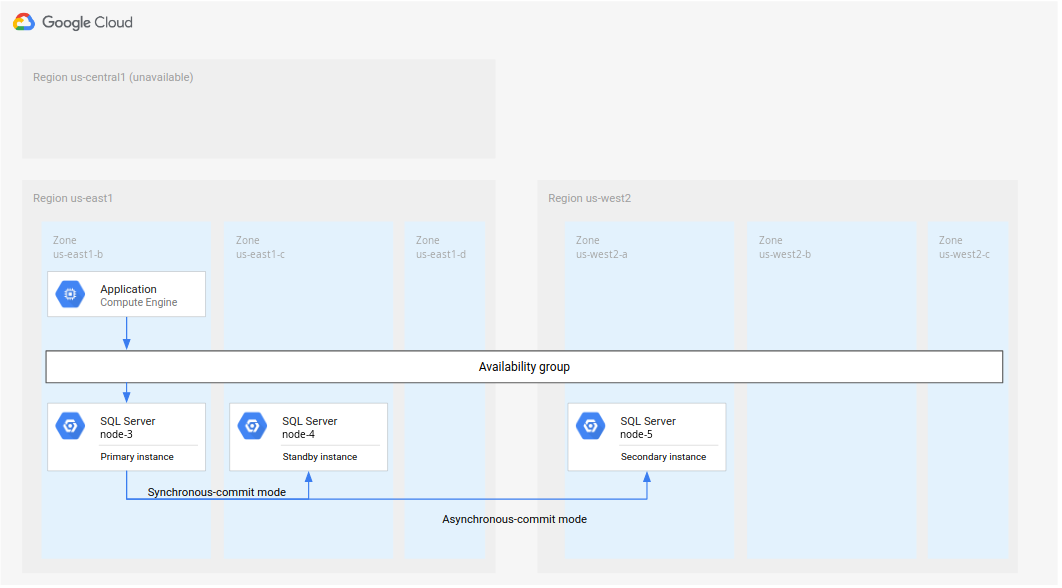
Figura 5. Recuperação de desastres com a região primária original R1 indisponível.
Essa implementação requer que você faça o seguinte:
Mantenha
node-3como instância primária emus-east1.Adicione uma nova instância de espera (
node-4) em uma zona diferente emus-east1. Nesta etapa, a nova implantação é estabelecida como altamente disponível.Crie uma nova instância secundária (
node-5) em uma região separada, por exemplo,us-west2. Nesta etapa, a nova implantação é configurada para recuperação de desastres. A implantação geral foi concluída. A arquitetura de banco de dados é totalmente compatível com HA e DR.
Executar fallback quando as transações estiverem ausentes (opcional)
Uma falha longe do ideal é quando uma ou mais transações confirmadas na instância primária não são replicadas para a secundária no momento da falha (também conhecida como falha grave). Em um failover, todas as transações confirmadas que não são replicadas são perdidas.
Para testar as etapas de failover desse cenário, é preciso gerar uma falha grave. Veja a seguir a melhor abordagem para gerar uma falha grave:
- Altere a rede para que não haja conectividade entre as instâncias primária e secundária.
- Altere a instância primária de alguma maneira. Por exemplo, adicione uma tabela ou insira alguns dados.
- Siga o processo de failover conforme descrito anteriormente para que a instância secundária torne-se a nova primária.
As etapas do processo de failover são idênticas às do cenário ideal. A diferença é que a tabela adicionada à instância primária após a interrupção da conexão de rede não fica visível na instância secundária.
Sua única opção para lidar com uma falha grave é remover as réplicas
(node-1 e node-2) do grupo de disponibilidade e sincronizar as réplicas
novamente. A sincronização altera o estado para corresponder à instância
secundária. Qualquer transação não replicada antes da falha é perdida.
Para adicionar node-1 como uma instância secundária, siga as mesmas etapas
para adicionar node-3 anteriormente (consulte
Adicionar a instância secundária ao cluster de failover
já abordado neste documento), com a seguinte diferença: node-3
agora é a instância primária, e não node-1. É preciso substituir qualquer instância de
node-3 pelo nome do servidor adicionado ao grupo de disponibilidade. Se
você reutilizar a mesma VM (node-1 e node-2), não precisará adicionar
o servidor ao cluster de failover do Windows Server. Adicione apenas a instância do
SQL Server novamente ao grupo de disponibilidade.
Neste momento, node-3 é a instância primária, e node-1 e
node-2 são secundárias. Agora é possível voltar a
node-1 para tornar node-2 a instância de espera e node-3 a
instância secundária. O sistema agora tem o mesmo estado que tinha antes da falha.
Failover automático
Fazer o failover automaticamente para uma instância secundária como primária pode causar problemas. Depois que a instância primária original for disponibilizada novamente, uma situação de dupla personalidade poderá ocorrer se alguns clientes acessarem a instância secundária enquanto outros gravarem na instância primária restaurada. Nesse caso, as instâncias primária e secundária poderão ser atualizadas em paralelo, e os estados delas serão divergentes. Para evitar essa situação, este tutorial apresenta instruções para um failover manual em que você decide se (ou quando) fará o failover.
Se você implementar um failover automático, será preciso garantir que somente uma das instâncias configuradas seja a primária e possa ser modificada. Uma instância de espera ou secundária não pode fornecer acesso de gravação a qualquer cliente (exceto a primária para replicação de estado). Além disso, evite uma cadeia rápida de failovers subsequentes em pouco tempo. Por exemplo, um failover a cada cinco minutos não é uma estratégia confiável para recuperação de desastres. Para processos de failover automatizados, é possível criar proteções contra cenários problemáticos como esses e até envolver um administrador de banco de dados para decisões complexas, se necessário.
Arquitetura de implantação alternativa
Neste tutorial, configuramos uma arquitetura de recuperação de desastres com uma instância secundária que se torna a instância primária em um failover, conforme mostrado no diagrama a seguir.
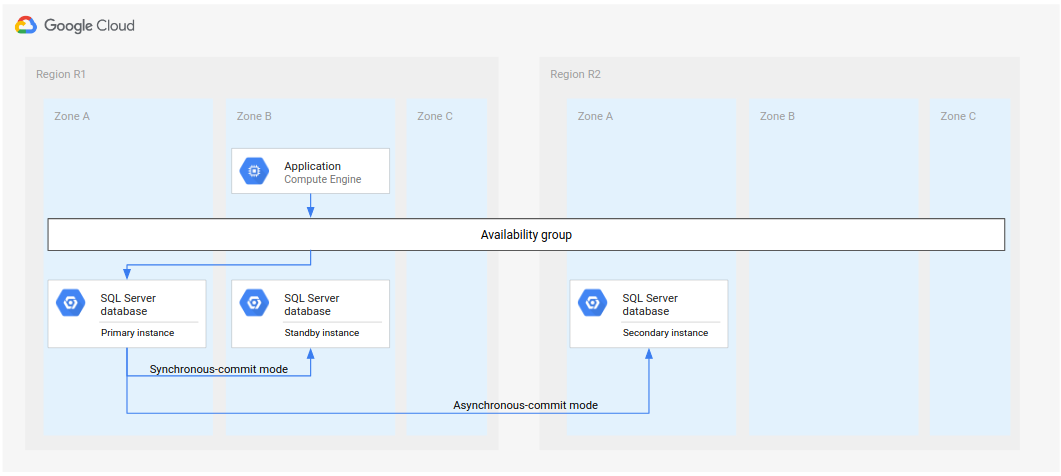
Figura 6. Arquitetura de recuperação de desastres padrão usando o Microsoft SQL Server.
Isso significa que, no caso de um failover, a implantação resultante terá uma instância até que seja possível fazer o fallback, ou até você configurar uma de espera (para HA) e uma secundária (para DR).
Uma arquitetura de implantação alternativa é configurar duas instâncias secundárias. As duas instâncias são réplicas da primária. Se ocorrer um failover, será possível reconfigurar uma das secundárias como espera. Veja no diagrama a seguir a arquitetura de implantação antes e depois de um failover.

Figura 7. Arquitetura de recuperação de desastres padrão com duas instâncias secundárias.
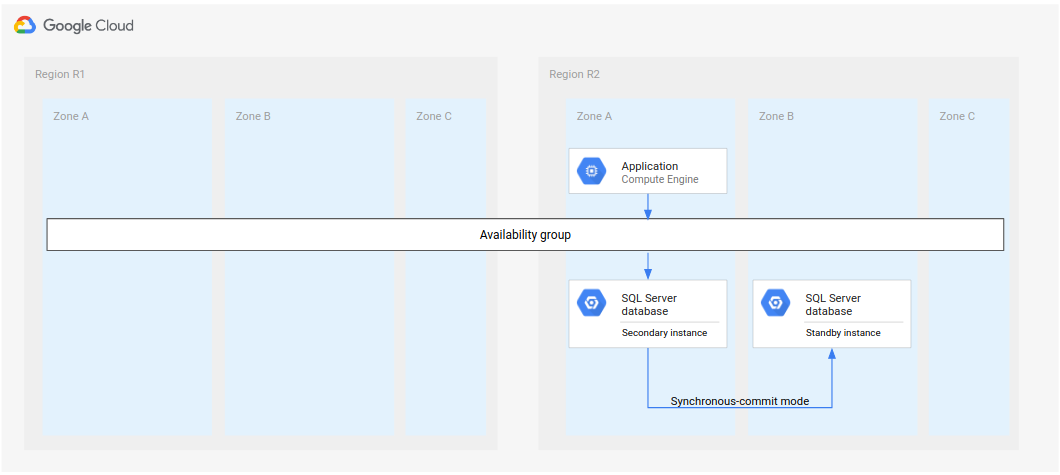
Figura 8. Arquitetura de recuperação de desastres padrão com duas instâncias secundárias após o failover.
Mesmo que ainda seja necessário transformar uma das duas instâncias secundárias em espera (Figura 8), esse processo é muito mais rápido do que criar e configurar uma nova instância de espera do zero.
Também é possível executar a DR com uma configuração análoga a esta arquitetura que usa duas instâncias secundárias. Além de ter duas instâncias secundárias em uma segunda região (Figura 7), é possível implantar outras duas instâncias secundárias em uma terceira região. Essa configuração permite criar com eficiência uma arquitetura de implantação habilitada para HA e DR após uma falha na região primária.