Tutorial ini menjelaskan cara men-deploy dan mengelola sistem database Microsoft SQL Server di dua region sebagai solusi pemulihan dari bencana (DR) dan cara melakukan failover dari instance database yang gagal ke instance yang beroperasi normal. Google Cloud Untuk tujuan dokumen ini, bencana adalah peristiwa ketika database utama gagal atau tidak tersedia.
Database utama dapat gagal jika region tempat database tersebut berada gagal atau menjadi tidak dapat diakses. Meskipun region tersedia dan beroperasi secara normal, database utama dapat gagal karena error sistem. Dalam kasus ini, pemulihan bencana adalah proses penyediaan database sekunder untuk klien agar pemrosesan dapat dilanjutkan.
Tutorial ini ditujukan untuk arsitek, administrator, dan engineer database.
Memahami pemulihan dari bencana (disaster recovery)
Di Google Cloud, pemulihan dari bencana (DR) berfokus pada penyediaan keberlangsungan pemrosesan, terutama saat region gagal atau tidak dapat diakses. Untuk sistem seperti sistem pengelolaan database, Anda menerapkan DR dengan men-deploy sistem di setidaknya dua region. Dengan penyiapan ini, sistem akan terus beroperasi jika satu region tidak tersedia.
Pemulihan dari bencana (disaster recovery) sistem database
Proses menyediakan database sekunder saat instance database utama gagal disebut pemulihan bencana database (atau DR database). Untuk pembahasan mendetail tentang konsep ini, lihat Pemulihan dari bencana (disaster recovery) untuk Microsoft SQL Server. Idealnya, status database sekunder konsisten dengan database utama pada saat database utama tidak tersedia, atau database sekunder hanya kehilangan serangkaian kecil transaksi terbaru dari database utama.
Arsitektur pemulihan dari bencana (disaster recovery)
Untuk Microsoft SQL Server, diagram berikut menunjukkan arsitektur minimal yang mendukung DR database.
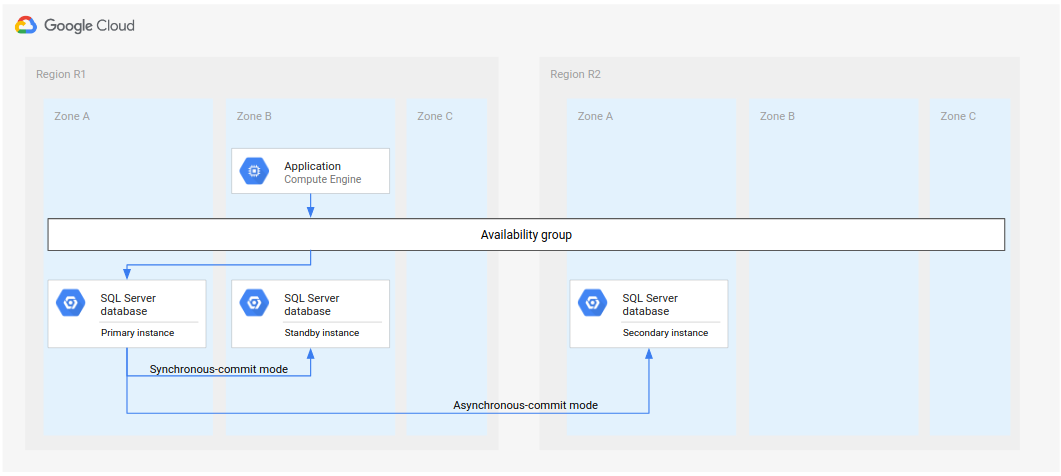
Gambar 1. Arsitektur pemulihan dari bencana standar dengan Microsoft SQL Server.
Arsitektur ini berfungsi sebagai berikut:
- Dua instance Microsoft SQL Server (instance utama dan instance standby) terletak di region yang sama (R1), tetapi zona yang berbeda (zona A dan B). Dua instance di R1 mengoordinasikan statusnya menggunakan mode synchronous-commit. Mode sinkron digunakan karena mendukung ketersediaan tinggi dan mempertahankan status data yang konsisten.
- Satu instance Microsoft SQL Server (instance sekunder atau pemulihan bencana) terletak di region kedua (R2). Untuk DR, instance sekunder di R2 disinkronkan dengan instance utama di R1 menggunakan mode asynchronous-commit. Mode asinkron digunakan karena performa (tidak memperlambat pemrosesan commit di instance utama).
Dalam diagram sebelumnya, arsitektur menunjukkan grup ketersediaan. Grup ketersediaan, jika digunakan dengan pendengar, memberikan string koneksi yang sama kepada klien jika klien dilayani oleh berikut ini:
- Instance utama
- Instance standby (setelah kegagalan zona)
- Instance sekunder (setelah kegagalan region dan setelah instance sekunder menjadi instance utama baru)
Dalam varian arsitektur di atas, Anda men-deploy dua instance yang berada di region pertama (R1) ke zona yang sama. Pendekatan ini dapat meningkatkan performa, tetapi tidak memiliki ketersediaan tinggi; pemadaman layanan satu zona mungkin diperlukan untuk memulai proses DR.
Proses pemulihan dari bencana (disaster recovery) dasar
Proses DR dimulai saat region menjadi tidak tersedia dan database utama gagal melanjutkan pemrosesan di region operasional lain. Proses DR menetapkan langkah-langkah operasional yang harus dilakukan, baik secara manual maupun otomatis, untuk mengurangi kegagalan region dan menetapkan instance utama yang berjalan di region yang tersedia.
Proses DR database dasar terdiri dari langkah-langkah berikut:
- Region pertama (R1), yang menjalankan instance database utama, menjadi tidak tersedia.
- Tim operasi mengenali dan secara resmi mengonfirmasi bencana, dan memutuskan apakah failover diperlukan.
- Jika failover diperlukan, instance database sekunder di region kedua (R2) akan dibuat sebagai instance utama baru.
- Klien melanjutkan pemrosesan di database utama baru dan mengakses instance utama di R2.
Meskipun proses dasar ini menetapkan kembali database utama yang berfungsi, proses ini tidak membuat arsitektur DR yang lengkap, di mana database utama yang baru memiliki instance database sekunder dan standby.
Proses pemulihan dari bencana (disaster recovery) lengkap
Proses DR yang lengkap memperluas proses DR dasar dengan menambahkan langkah-langkah untuk membuat arsitektur DR lengkap setelah failover. Diagram berikut menunjukkan arsitektur DR database yang lengkap.
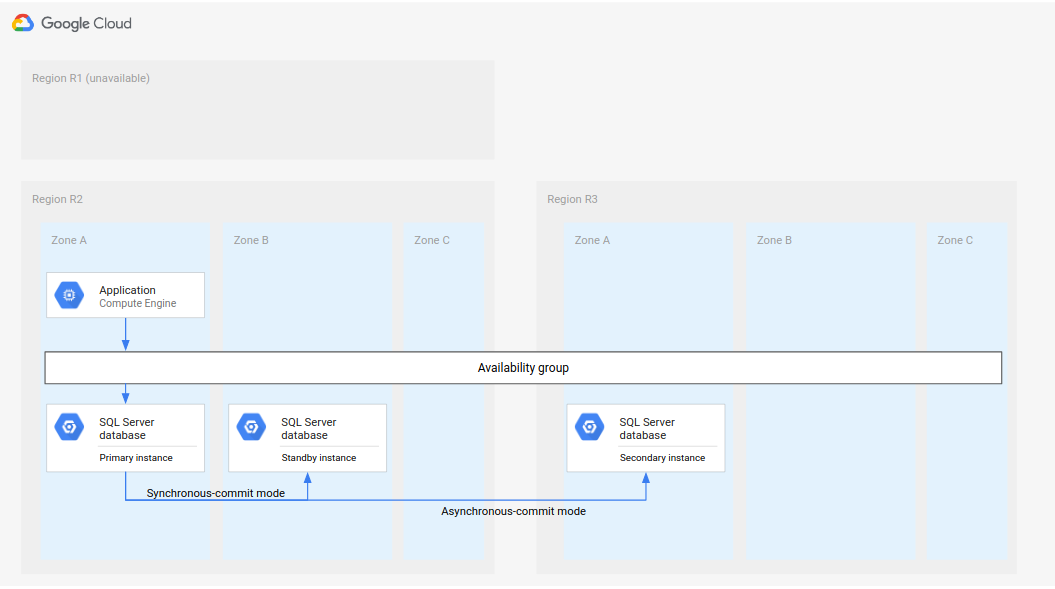
Gambar 2. Pemulihan dari bencana (disaster recovery) dengan region utama (R1) yang tidak tersedia.
Arsitektur DR database yang lengkap ini berfungsi sebagai berikut:
- Region pertama (R1), yang menjalankan instance database utama, menjadi tidak tersedia.
- Tim operasi mengenali dan secara resmi mengonfirmasi bencana, dan memutuskan apakah failover diperlukan.
- Jika failover diperlukan, instance database sekunder di region kedua (R2) akan dibuat sebagai instance utama.
- Instance sekunder lain, yaitu instance standby baru, dibuat dan dimulai di R2 serta ditambahkan ke instance utama. Instance standby berada di zona yang berbeda dengan instance utama. Database utama kini terdiri dari dua instance (utama dan standby) yang sangat tersedia.
- Di region ketiga (R3), instance database sekunder (standby) baru dibuat dan dimulai. Instance sekunder ini terhubung secara asinkron ke instance utama baru di R2. Pada tahap ini, arsitektur pemulihan dari bencana yang asli dibuat ulang dan dapat dioperasikan.
Penggantian ke region yang dipulihkan
Setelah region pertama (R1) diaktifkan kembali, region tersebut dapat menghosting database sekunder baru. Jika R1 tersedia cukup cepat, Anda dapat menerapkan langkah 5 dalam proses pemulihan lengkap di R1, bukan R3 (region ketiga). Dalam kasus ini, wilayah ketiga tidak diperlukan.
Diagram berikut menunjukkan arsitektur jika R1 tersedia tepat waktu.
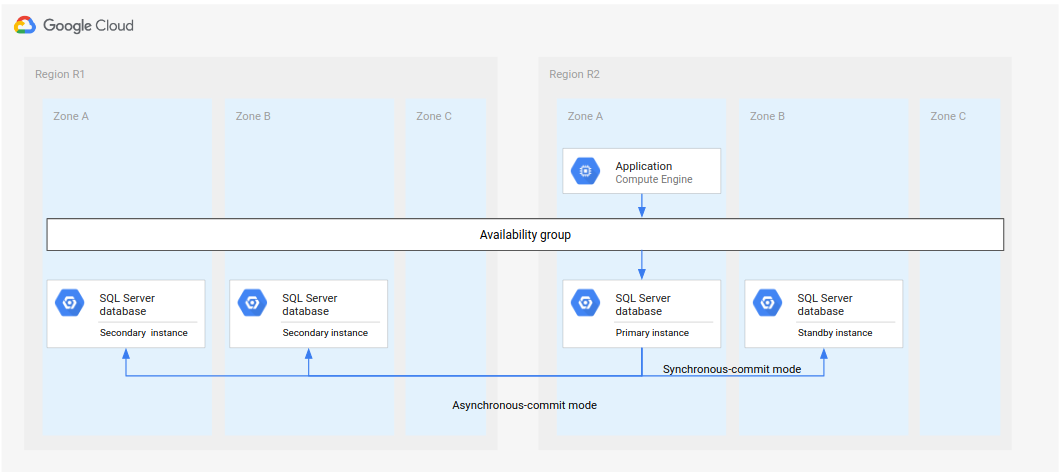
Gambar 3. Pemulihan dari bencana setelah region R1 yang gagal tersedia kembali.
Dalam arsitektur ini, langkah-langkah pemulihannya sama dengan yang diuraikan sebelumnya dalam Proses pemulihan dari bencana (disaster recovery) lengkap dengan perbedaan, yaitu R1 menjadi lokasi untuk instance sekunder, bukan R3.
Memilih edisi SQL Server
Tutorial ini mendukung versi Microsoft SQL Server berikut:
- SQL Server 2016 Enterprise Edition
- SQL Server 2017 Enterprise Edition
- SQL Server 2019 Enterprise Edition
- SQL Server 2022 Enterprise Edition
Tutorial ini menggunakan fitur Grup Ketersediaan AlwaysOn di SQL Server.
Jika Anda tidak memerlukan database utama Microsoft SQL Server dengan ketersediaan tinggi (HA), dan satu instance database sudah cukup sebagai database utama, Anda dapat menggunakan versi SQL Server berikut:
- SQL Server 2016 Standard Edition
- SQL Server 2017 Standard Edition
- SQL Server 2019 Standard Edition
- SQL Server 2022 Standard Edition
SQL Server versi 2016, 2017, 2019, dan 2022 telah menginstal Microsoft SQL Server Management Studio di image; Anda tidak perlu menginstalnya secara terpisah. Namun, dalam lingkungan produksi, sebaiknya Anda menginstal satu instance Microsoft SQL Server Management Studio di VM terpisah di setiap region. Jika Anda menyiapkan lingkungan HA, Anda harus menginstal Microsoft SQL Server Management Studio satu kali untuk setiap zona guna memastikan ketersediaannya jika zona lain tidak tersedia.
Menyiapkan Microsoft SQL Server untuk DR multi-regional
Bagian ini menggunakan image berikut untuk Microsoft SQL Server:
sql-ent-2016-win-2016untuk Microsoft SQL Server 2016 Enterprise Editionsql-ent-2017-win-2016untuk Microsoft SQL Server 2017 Enterprise Editionsql-ent-2019-win-2019untuk Microsoft SQL Server 2019 Enterprise Editionsql-ent-2022-win-2022untuk Microsoft SQL Server 2022 Enterprise Edition
Untuk daftar lengkap image, lihat Gambar.
Menyiapkan cluster ketersediaan tinggi dengan dua instance
Untuk menyiapkan arsitektur DR database multi-regional untuk SQL Server, Anda harus
membuat cluster ketersediaan tinggi (HA) dua instance di suatu region terlebih dahulu. Satu instance
berfungsi sebagai yang utama, dan instance lainnya berfungsi sebagai yang sekunder. Untuk menyelesaikan langkah ini, ikuti petunjuk di Mengonfigurasi Grup Ketersediaan AlwaysOn SQL Server.
Tutorial ini menggunakan us-central1 untuk region utama (disebut sebagai R1).
Sebelum memulai, tinjau pertimbangan berikut:
Jika mengikuti langkah-langkah dalam Mengonfigurasi grup ketersediaan AlwaysOn SQL Server, Anda akan membuat dua instance SQL Server di region yang sama (
us-central1). Anda akan men-deploy instance SQL Server utama (node-1) dius-central1-a, dan instance standby (node-2) dius-central1-b.Meskipun Anda menerapkan arsitektur dalam Gambar 4 untuk tutorial ini, sebaiknya siapkan pengontrol domain di lebih dari satu zona. Pendekatan ini memastikan Anda membuat arsitektur database yang mendukung HA dan DR. Misalnya, jika terjadi pemadaman layanan di satu zona, zona tersebut tidak akan menjadi satu titik kegagalan untuk arsitektur yang di-deploy.
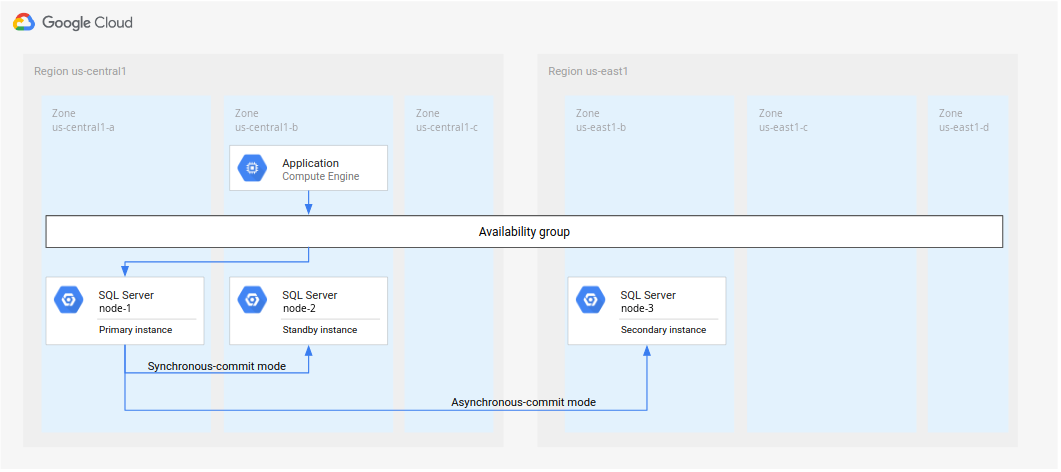
Gambar 4. Arsitektur pemulihan dari bencana standar yang diterapkan dalam tutorial ini.
Menambahkan instance sekunder untuk pemulihan dari bencana (disaster recovery)
Selanjutnya, Anda menyiapkan instance SQL Server ketiga (instance sekunder yang
bernama node-3), dan mengonfigurasi jaringan sebagai berikut:
Buat skrip spesialisasi untuk node Windows Server Failover Cluster. Skrip ini menginstal fitur Windows yang diperlukan serta membuat aturan firewall untuk WSFC dan SQL Server. Skrip ini juga memformat disk data dan membuat folder data dan log untuk SQL Server:
cat << "EOF" > specialize-node.ps1 $ErrorActionPreference = "stop" # Install required Windows features Install-WindowsFeature Failover-Clustering -IncludeManagementTools Install-WindowsFeature RSAT-AD-PowerShell # Open firewall for WSFC netsh advfirewall firewall add rule name="Allow SQL Server health check" dir=in action=allow protocol=TCP localport=59997 # Open firewall for SQL Server netsh advfirewall firewall add rule name="Allow SQL Server" dir=in action=allow protocol=TCP localport=1433 # Open firewall for SQL Server replication netsh advfirewall firewall add rule name="Allow SQL Server replication" dir=in action=allow protocol=TCP localport=5022 # Format data disk Get-Disk | Where partitionstyle -eq 'RAW' | Initialize-Disk -PartitionStyle MBR -PassThru | New-Partition -AssignDriveLetter -UseMaximumSize | Format-Volume -FileSystem NTFS -NewFileSystemLabel 'Data' -Confirm:$false # Create data and log folders for SQL Server md d:\Data md d:\Logs EOF
Lakukan inisialisasi variabel berikut:
VPC_NAME=
VPC_NAMESUBNET_NAME=SUBNET_NAMEREGION=us-east1 PD_SIZE=200 MACHINE_TYPE=n2-standard-8Dengan keterangan:
VPC_NAME: nama VPC AndaSUBNET_NAME: nama subnet Anda untuk regionus-east1
Buat instance SQL Server:
gcloud compute instances create node-3 \ --zone $REGION-b \ --machine-type $MACHINE_TYPE \ --subnet $SUBNET_NAME \ --image-family sql-ent-2022-win-2022 \ --image-project windows-sql-cloud \ --tags wsfc,wsfc-node \ --boot-disk-size 50 \ --boot-disk-type pd-ssd \ --boot-disk-device-name "node-3" \ --create-disk=name=node-3-datadisk,size=$PD_SIZE,type=pd-ssd,auto-delete=no \ --metadata enable-wsfc=true \ --metadata-from-file=sysprep-specialize-script-ps1=specialize-node.ps1Tetapkan sandi Windows untuk instance SQL Server baru:
Di konsol Google Cloud , buka halaman Compute Engine.
Di kolom Connect untuk cluster Compute Engine
node-3, pilih menu drop-down Setel sandi Windows.Tetapkan nama pengguna dan sandi. Catat untuk digunakan nanti.
Klik RDP untuk terhubung ke instance
node-3.Masukkan nama pengguna dan sandi dari langkah sebelumnya, lalu klik OK.
Tambahkan instance ke domain Windows:
Klik kanan tombol Start (atau tekan Win+X), lalu klik Windows PowerShell (Admin).
Konfirmasi perintah elevasi dengan mengklik Ya.
Gabungkan komputer ke domain Active Directory Anda, lalu mulai ulang:
Add-Computer -Domain
DOMAIN -RestartGanti
DOMAINdengan nama DNS domain Active Directory Anda.Tunggu sekitar 1 menit sampai proses mulai ulang selesai.
Menambahkan instance sekunder ke cluster failover
Selanjutnya, tambahkan instance sekunder (node-3) ke cluster failover Windows:
Hubungkan ke instance
node-1ataunode-2menggunakan RDP, dan login sebagai pengguna Administrator.Buka jendela PowerShell sebagai pengguna Administrator dan tetapkan variabel untuk lingkungan cluster dalam tutorial ini:
$node3 = "node-3" $nameWSFC = "
SQLSRV_CLUSTER" # Name of clusterGanti
SQLSRV_CLUSTERdengan nama cluster SQL Server.Tambahkan instance sekunder ke cluster:
Get-Cluster | WHERE Name -EQ $nameWSFC | Add-ClusterNode -NoStorage -Name $node3Perintah ini mungkin memerlukan waktu beberapa saat untuk dijalankan. Karena proses dapat berhenti merespons dan tidak kembali secara otomatis, sesekali tekan
Enter.Di node, aktifkan fitur ketersediaan tinggi AlwaysOn:
Enable-SqlAlwaysOn -ServerInstance $node3 -Force
Node kini menjadi bagian dari cluster failover.
Tambahkan instance sekunder ke grup ketersediaan yang ada
Selanjutnya, tambahkan instance SQL Server (instance sekunder) dan database ke grup ketersediaan:
Hubungkan ke
node-3menggunakan Desktop Jarak Jauh. Login dengan akun pengguna domain Anda.Buka SQL Server Configuration Manager.
Di panel navigasi, pilih SQL Server Services
Di daftar layanan, klik kanan SQL Server (MSSQLSERVER) lalu pilih Properties.
Di bagian Log on as, ubah akun:
- Account name:
DOMAIN\sql_serverdenganDOMAINadalah nama NetBIOS domain Active Directory Anda. - Password: Masukkan sandi yang Anda pilih sebelumnya untuk akun domain sql_server.
- Account name:
Klik Oke.
Saat diminta untuk memulai ulang SQL Server, pilih Yes.
Di salah satu dari tiga node instance
node-1,node-2, ataunode-3, buka Microsoft SQL Server Management Studio dan hubungkan ke instance utama—node-1.- Buka Penjelajah Objek.
- Pilih menu drop-down Hubungkan.
- Pilih Mesin Database.
- Dari menu drop-down Nama Server, pilih
node-1. Jika cluster tidak tercantum, masukkan cluster di kolom.
Click Kueri Baru.
Tempel perintah berikut untuk menambahkan alamat IP ke pemroses yang digunakan untuk node, lalu klik Jalankan:
ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY LISTENER 'bookshelf' (ADD IP
('LOAD_BALANCER_IP_ADDRESS', '255.255.255.0'))Ganti
LOAD_BALANCER_IP_ADDRESSdengan Alamat IP load balancer di regionus-east1.Di Penjelajah Objek, luaskan node AlwaysOn High Availability, lalu luaskan node Availability Groups (Grup Ketersediaan).
Klik kanan grup ketersediaan yang bernama
bookshelf-ag, lalu pilih Tambahkan Replika.Di halaman Introduction, klik node AlwaysOn High Availability, lalu klik node Availability Groups.
Di halaman Connect to Replicas(Hubungkan ke Replika), klik Connect untuk terhubung ke replika sekunder yang ada
node-2.Di halaman Specify Replicas(Tentukan Replika), klik Add Replica(Tambahkan Replika), lalu tambahkan node baru
node-3. Jangan pilih Pengalihan Otomatis karena pengalihan otomatis menyebabkan penerapan sinkron. Konfigurasi semacam itu melintasi batas regional, yang tidak kami rekomendasikan.Di halaman Select Data Synchronization(Pilih Sinkronisasi Data), pilih Automatic seeding(Penyebaran otomatis).
Karena tidak ada pemroses, halaman Validasi akan menghasilkan peringatan, yang dapat Anda abaikan.
Selesaikan langkah-langkah wizard.
Mode failover untuk node-1 dan node-2 adalah otomatis, sedangkan
mode failover untuk node-3 adalah manual. Perbedaan ini adalah salah satu cara untuk membedakan ketersediaan tinggi dari pemulihan dari bencana.
Grup ketersediaan kini sudah siap. Anda mengonfigurasi dua node untuk ketersediaan tinggi dan node ketiga untuk pemulihan dari bencana (disaster recovery).
Menyimulasikan pemulihan dari bencana (disaster recovery)
Di bagian ini, Anda akan menguji arsitektur pemulihan dari bencana untuk tutorial ini dan mempertimbangkan penerapan DR opsional.
Menyimulasikan pemadaman layanan dan mengeksekusi failover DR
Menyimulasikan kegagalan atau pemadaman di region utama:
Di Microsoft SQL Server Management Studio di
node-1, hubungkan kenode-1.Membuat tabel Setelah menambahkan replika di langkah berikutnya, verifikasi bahwa replika tersebut berfungsi dengan memeriksa apakah tabel ini ada.
USE bookshelf GO CREATE TABLE dbo.TestTable_Before_DR (ID INT NOT NULL) GODi Cloud Shell, matikan kedua server di region utama
us-central1:gcloud compute instances stop node-2 --zone us-central1-b --quiet gcloud compute instances stop node-1 --zone us-central1-a --quiet
Di Microsoft SQL Server Management Studio di
node-3, hubungkan kenode-3.Jalankan failover, dan tetapkan mode ketersediaan ke commit sinkron. Failover paksa diperlukan karena node berada dalam mode asynchronous-commit.
ALTER AVAILABILITY GROUP [bookshelf-ag] FORCE_FAILOVER_ALLOW_DATA_LOSS GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-3' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GOAnda dapat melanjutkan pemrosesan;
node-3kini menjadi instance utama.(Opsional) Buat tabel baru di
node-3. Setelah menyinkronkan replika dengan replika utama baru, periksa apakah tabel ini direplikasi ke replika.USE bookshelf GO CREATE TABLE dbo.TestTable_After_DR (ID INT NOT NULL) GO
Meskipun node-3 adalah instance utama pada saat ini, Anda mungkin ingin melakukan
failback ke region asli atau menyiapkan instance sekunder dan instance standby
baru untuk membuat ulang arsitektur DR yang lengkap. Bagian berikutnya akan membahas opsi ini.
(Opsional) Buat ulang arsitektur DR yang mereplikasi transaksi sepenuhnya
Kasus penggunaan ini menangani kegagalan saat semua transaksi direplikasi dari database utama ke database sekunder sebelum database utama gagal. Dalam skenario ideal ini, tidak ada data yang hilang; status sekunder konsisten dengan primer pada saat terjadi kegagalan.
Dalam skenario ini, Anda dapat membuat ulang arsitektur DR yang lengkap dengan dua cara:
- Lakukan penggantian ke primer asli dan siaga asli (jika keduanya tersedia).
- Buat standby dan sekunder baru untuk
node-3jika primer dan standby asli tidak tersedia.
Pendekatan 1: Melakukan penggantian ke region utama dan standby asli
Di Cloud Shell, mulai instance utama (lama) dan standby asli:
gcloud compute instances start node-1 --zone us-central1-a --quiet gcloud compute instances start node-2 --zone us-central1-b --quietDi Microsoft SQL Server Management Studio, tambahkan kembali
node-1dannode-2sebagai replika sekunder:Di
node-3, tambahkan dua server dalam mode asynchronous-commit:USE [master] GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (FAILOVER_MODE = MANUAL) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (FAILOVER_MODE = MANUAL) GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GODi
node-1, mulai sinkronkan database lagi:USE [master] GO ALTER DATABASE [bookshelf] SET HADR RESUME; GODi
node-2, mulai sinkronkan database lagi:USE [master] GO ALTER DATABASE [bookshelf] SET HADR RESUME; GO
Jadikan
node-1sebagai yang utama lagi:Di
node-3, ubah mode ketersediaannode-1menjadi commit sinkron. Instancenode-1menjadi instance utama lagi.USE [master] GO ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-1' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GODi
node-1, ubahnode-1menjadi yang utama dan dua node lainnya menjadi sekunder:USE [master] GO -- Node 1 becomes primary ALTER AVAILABILITY GROUP [bookshelf-ag] FORCE_FAILOVER_ALLOW_DATA_LOSS; GO -- Node 2 has synchronous commit ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-2' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GO -- Node 3 has asynchronous commit ALTER AVAILABILITY GROUP [bookshelf-ag] MODIFY REPLICA ON 'node-3' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO
Setelah semua perintah berhasil, node-1 menjadi yang utama, dan node lainnya
menjadi sekunder, seperti yang ditunjukkan dalam diagram berikut.
Pendekatan 2: Siapkan instance utama dan standby baru
Ada kemungkinan Anda tidak dapat memulihkan instance utama dan standby asli dari kegagalan, atau pemulihannya memerlukan waktu terlalu lama, atau region tidak dapat diakses. Salah satu pendekatannya adalah mempertahankan node-3 sebagai yang utama, lalu
membuat instance standby baru dan instance sekunder baru, seperti yang ditunjukkan dalam diagram berikut.
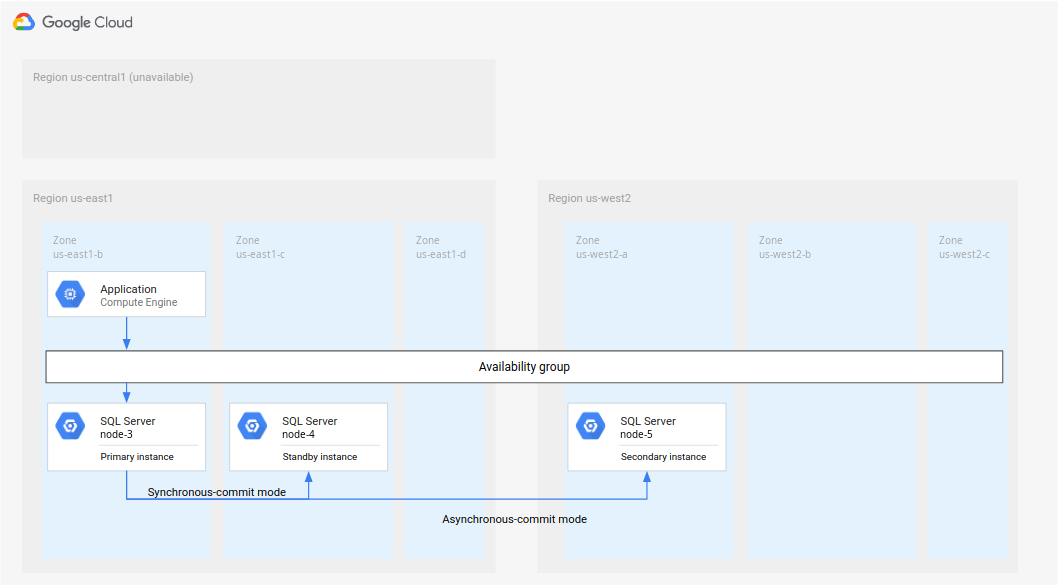
Gambar 5. Pemulihan dari bencana dengan region utama asli R1 yang tidak tersedia.
Penerapan ini mengharuskan Anda melakukan hal berikut:
Tetapkan
node-3sebagai yang utama dius-east1.Tambahkan instance standby baru (
node-4) di zona yang berbeda dius-east1. Langkah ini menetapkan deployment baru sebagai ketersediaan tinggi.Buat instance sekunder baru (
node-5) di region terpisah, misalnya,us-west2. Langkah ini menyiapkan deployment baru untuk pemulihan dari bencana. Deployment keseluruhan kini telah selesai. Arsitektur database sepenuhnya mendukung HA dan DR.
(Opsional) Menjalankan penggantian saat transaksi tidak ada
Kegagalan yang kurang ideal adalah ketika satu atau beberapa transaksi yang di-commit di primer tidak direplikasi ke sekunder pada titik kegagalan (juga dikenal sebagai kegagalan berat). Dalam failover, semua transaksi yang di-commit yang tidak direplikasi akan hilang.
Untuk menguji langkah-langkah failover untuk skenario ini, Anda harus membuat kegagalan yang sulit. Pendekatan terbaik untuk menghasilkan kegagalan yang sulit adalah sebagai berikut:
- Ubah jaringan sehingga tidak ada konektivitas antara instance utama dan sekunder.
- Ubah primer dengan cara tertentu—misalnya, tambahkan tabel atau masukkan beberapa data.
- Lakukan proses failover seperti yang diuraikan sebelumnya sehingga sekunder menjadi primer baru.
Langkah-langkah untuk proses failover identik dengan skenario ideal, kecuali tabel yang ditambahkan ke primer setelah konektivitas jaringan terganggu tidak terlihat di sekunder.
Satu-satunya opsi Anda untuk menangani kegagalan yang sulit adalah menghapus replika
(node-1 dan node-2) dari grup ketersediaan, lalu menyinkronkan
replika lagi. Sinkronisasi mengubah statusnya agar cocok dengan
sekunder. Setiap transaksi yang tidak direplikasi sebelum kegagalan akan hilang.
Untuk menambahkan node-1 sebagai instance sekunder, Anda dapat mengikuti langkah-langkah yang sama
untuk menambahkan node-3 sebelumnya (lihat
Menambahkan instance sekunder ke cluster failover
sebelumnya) dengan perbedaan berikut: node-3 sekarang
menjadi instance utama, bukan node-1. Anda harus mengganti setiap instance
node-3 dengan nama server yang Anda tambahkan ke grup ketersediaan. Jika
Anda menggunakan kembali VM yang sama (node-1 dan node-2), Anda tidak perlu
menambahkan server ke Windows Server Failover Cluster; cukup tambahkan kembali instance SQL Server
ke grup ketersediaan.
Pada titik ini, node-3 adalah primer, dan node-1 serta
node-2 adalah sekunder. Sekarang Anda dapat melakukan penggantian ke
node-1, menjadikan node-2 dalam mode standby, dan menjadikan node-3
sebagai sekunder. Sistem kini memiliki status yang sama dengan yang dimilikinya sebelum kegagalan.
Failover otomatis
Melakukan failover secara otomatis ke instance sekunder sebagai instance utama dapat menimbulkan masalah. Setelah instance utama asli tersedia kembali, situasi split-brain dapat terjadi jika beberapa klien mengakses instance sekunder, sementara yang lain menulis ke instance utama yang dipulihkan. Dalam hal ini, primer dan sekunder mungkin diperbarui secara paralel, dan statusnya berbeda. Untuk menghindari situasi ini, tutorial ini memberikan petunjuk untuk failover manual yang memungkinkan Anda memutuskan apakah (atau kapan) akan melakukan failover.
Jika Anda menerapkan failover otomatis, Anda harus memastikan bahwa hanya salah satu instance yang dikonfigurasi yang menjadi instance utama dan dapat diubah. Setiap instance standby atau sekunder tidak boleh memberikan akses tulis ke klien mana pun (kecuali instance utama untuk replikasi status). Selain itu, Anda harus menghindari rangkaian failover beruntun yang cepat dalam waktu singkat. Misalnya, failover setiap lima menit bukanlah strategi pemulihan dari bencana yang dapat diandalkan. Untuk proses failover otomatis, Anda dapat membangun pengamanan dari skenario bermasalah seperti ini, dan bahkan melibatkan administrator database untuk keputusan yang kompleks, jika diperlukan.
Arsitektur deployment alternatif
Tutorial ini menyiapkan arsitektur pemulihan dari bencana dengan instance sekunder yang menjadi instance primer dalam failover, seperti yang ditunjukkan dalam diagram berikut.
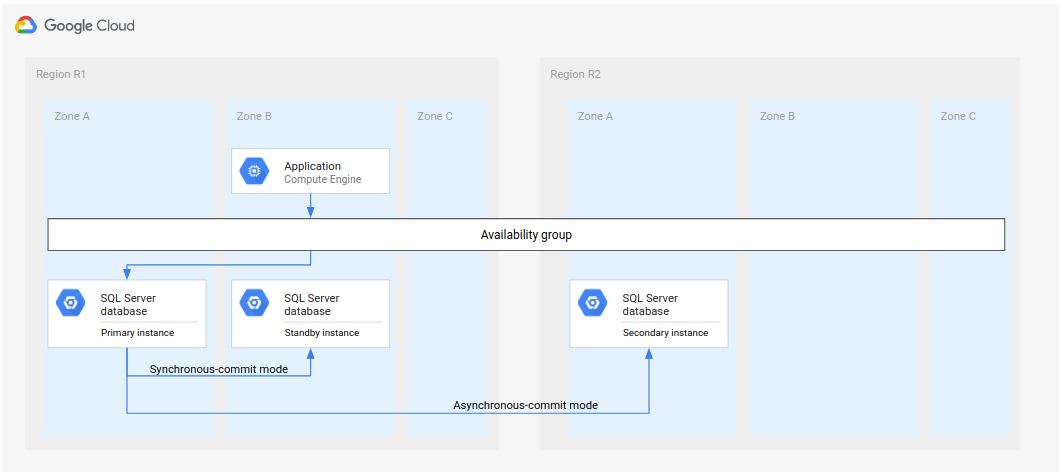
Gambar 6. Arsitektur pemulihan dari bencana standar menggunakan Microsoft SQL Server.
Artinya, jika terjadi failover, deployment yang dihasilkan akan memiliki satu instance hingga penggantian dimungkinkan, atau hingga Anda mengonfigurasi standby (untuk HA) dan sekunder (untuk DR).
Arsitektur deployment alternatif adalah mengonfigurasi dua instance sekunder. Kedua instance adalah replika dari instance utama. Jika terjadi failover, Anda dapat mengonfigurasi ulang salah satu instance sekunder sebagai standby. Diagram berikut menunjukkan arsitektur deployment sebelum dan setelah failover.

Gambar 7. Arsitektur pemulihan dari bencana standar dengan dua instance sekunder.
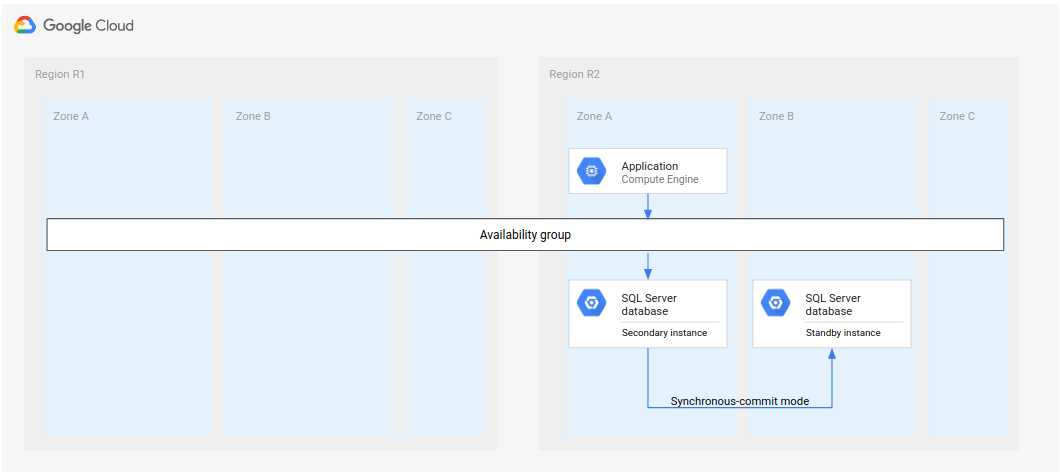
Gambar 8. Arsitektur pemulihan dari bencana standar dengan dua instance sekunder setelah failover.
Meskipun Anda tetap harus menjadikan salah satu dari dua instance sekunder sebagai standby (Gambar 8), proses ini jauh lebih cepat daripada membuat dan mengonfigurasi standby baru dari awal.
Anda juga dapat menangani DR dengan penyiapan yang analog dengan arsitektur ini menggunakan dua instance sekunder. Selain memiliki dua instance sekunder di region kedua (Gambar 7), Anda dapat men-deploy dua instance sekunder lain di region ketiga. Penyiapan ini memungkinkan Anda membuat arsitektur deployment yang mendukung HA dan DR secara efisien setelah terjadi kegagalan region utama.