Questo documento descrive come accedere alle metriche delle macchine virtuali (VM) e visualizzarle. Descrive inoltre come esaminare le metriche delle VM per saperne di più sulle tue VM o risolvere problemi specifici relativi a una VM.
Il monitoraggio delle istanze di macchine virtuali (VM) è essenziale per mantenere le risorse VM. Compute Engine offre una visione generale delle metriche delle VM utilizzando la scheda Osservabilità nella console Google Cloud . Questa scheda fornisce una dashboard predefinita che utilizza i dati di telemetria per monitorare le VM e prendere decisioni informate sulle risorse Compute Engine. Puoi anche personalizzare la dashboard predefinita per visualizzare solo le metriche specifiche che ti interessano.
Tutte le VM dispongono di dati di utilizzo di base dei processi al momento della creazione. Tuttavia, l'installazione di Ops Agent fornisce informazioni più approfondite sul comportamento della VM.
Per saperne di più sulla creazione di una criterio di avviso di monitoraggio, sull'utilizzo di Metrics Explorer o per informazioni generali sul funzionamento del monitoraggio e delle metriche su Google Cloud, consulta la documentazione di Cloud Monitoring.
Prima di iniziare
(Facoltativo) Installa Ops Agent per raccogliere dati più dettagliati dalle istanze Compute Engine.
Per controllare su quali istanze VM è installato Ops Agent:
Nella console Google Cloud , vai a Dashboard di Monitoring.
Seleziona Istanze VM dall'elenco della dashboard.
Fai clic su Elenco per visualizzare le VM come elenco.
Vengono visualizzate tutte le VM del progetto. La colonna Agente mostra lo stato dell'installazione di Ops Agent. Puoi installare o aggiornare l'agente da questa pagina.
(Facoltativo) Per aggiornare la dashboard Predefinita in modo da visualizzare eventi, ad esempio quelli che indicano un aggiornamento a un gruppo di istanze gestite, fai clic su event_available Seleziona eventi e poi completa la finestra di dialogo.
Per saperne di più sugli eventi, vedi Tipi di eventi.
Accedere alle metriche di osservabilità della VM
Accedi alle informazioni per una o più VM utilizzando la scheda Osservabilità nella console Google Cloud . Per impostazione predefinita, una dashboard predefinita mostra le metriche VM. Se vuoi visualizzare solo le metriche specifiche che ti interessano, puoi creare una dashboard personalizzata.
Visualizza le metriche di osservabilità per una singola VM
Le metriche di base della VM, come l'utilizzo della CPU e il traffico di rete, sono disponibili quando crei la VM. Le metriche per l'utilizzo di memoria e processi sono disponibili solo con l'installazione di Ops Agent, l'agente principale per la raccolta dei dati di telemetria dalle istanze Compute Engine.
Per visualizzare le metriche di una singola VM, segui questi passaggi:
Nella console Google Cloud , vai alla pagina Istanze VM.
Seleziona una VM per aprire la pagina Dettagli.
Fai clic sulla scheda Osservabilità per visualizzare le informazioni sulla VM.
(Facoltativo) Reimposta il periodo di tempo predefinito di un'ora e seleziona il periodo di tempo che vuoi monitorare.
(Facoltativo) Per aggiornare la dashboard Predefinita in modo da visualizzare eventi, ad esempio quelli che indicano un aggiornamento a un gruppo di istanze gestite, fai clic su event_available Seleziona eventi e poi completa la finestra di dialogo.
Per saperne di più sugli eventi, vedi Tipi di eventi.
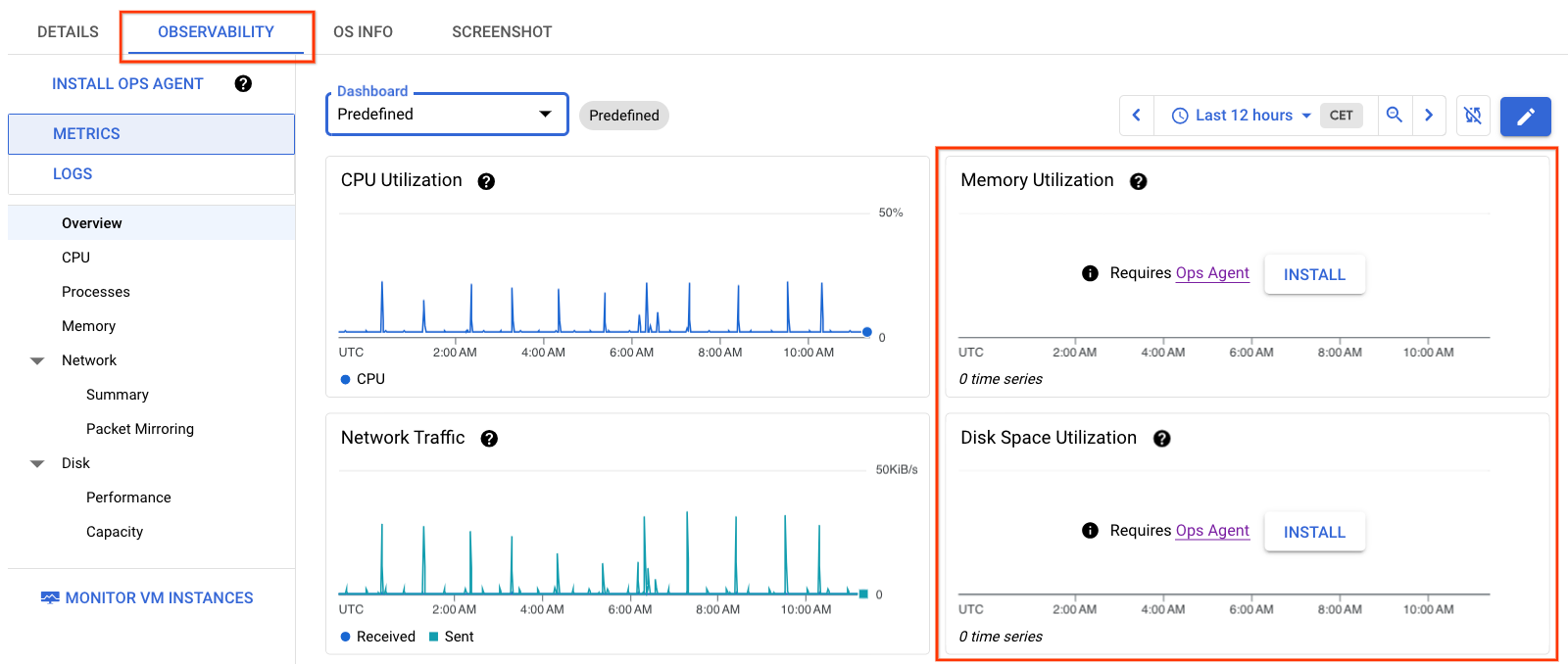
Le informazioni nella Figura 1 mostrano i dettagli della VM senza Ops Agent installato sulla VM. Nota che i grafici Memoria e Utilizzo spazio su disco non contengono dati.
Visualizzare le metriche di osservabilità per più VM
L'osservabilità a livello di parco risorse mostra le metriche per le prime cinque VM con il massimo utilizzo dei processi. Le prime cinque VM elencate variano in base alla metrica. Potresti non visualizzare le stesse cinque VM per ogni processo. Sebbene siano disponibili più dati a livello di parco macchine senza installare l'Ops Agent rispetto alla quantità di dati disponibili per una singola VM, l'installazione dell'agente fornisce più dati per la risoluzione dei problemi futuri.
Per visualizzare le metriche di più VM, segui questi passaggi:
Nella console Google Cloud , vai alla pagina Istanze VM.
Fai clic sulla scheda Osservabilità.
(Facoltativo) Reimposta il periodo di tempo predefinito di un'ora e seleziona il periodo di tempo che vuoi monitorare.
Filtra i risultati in base a una o più delle seguenti opzioni:
- ID
- Nome
- Tipo di macchina
- Zona
- Regione
- Gruppo di istanze
- Etichette
- Stato
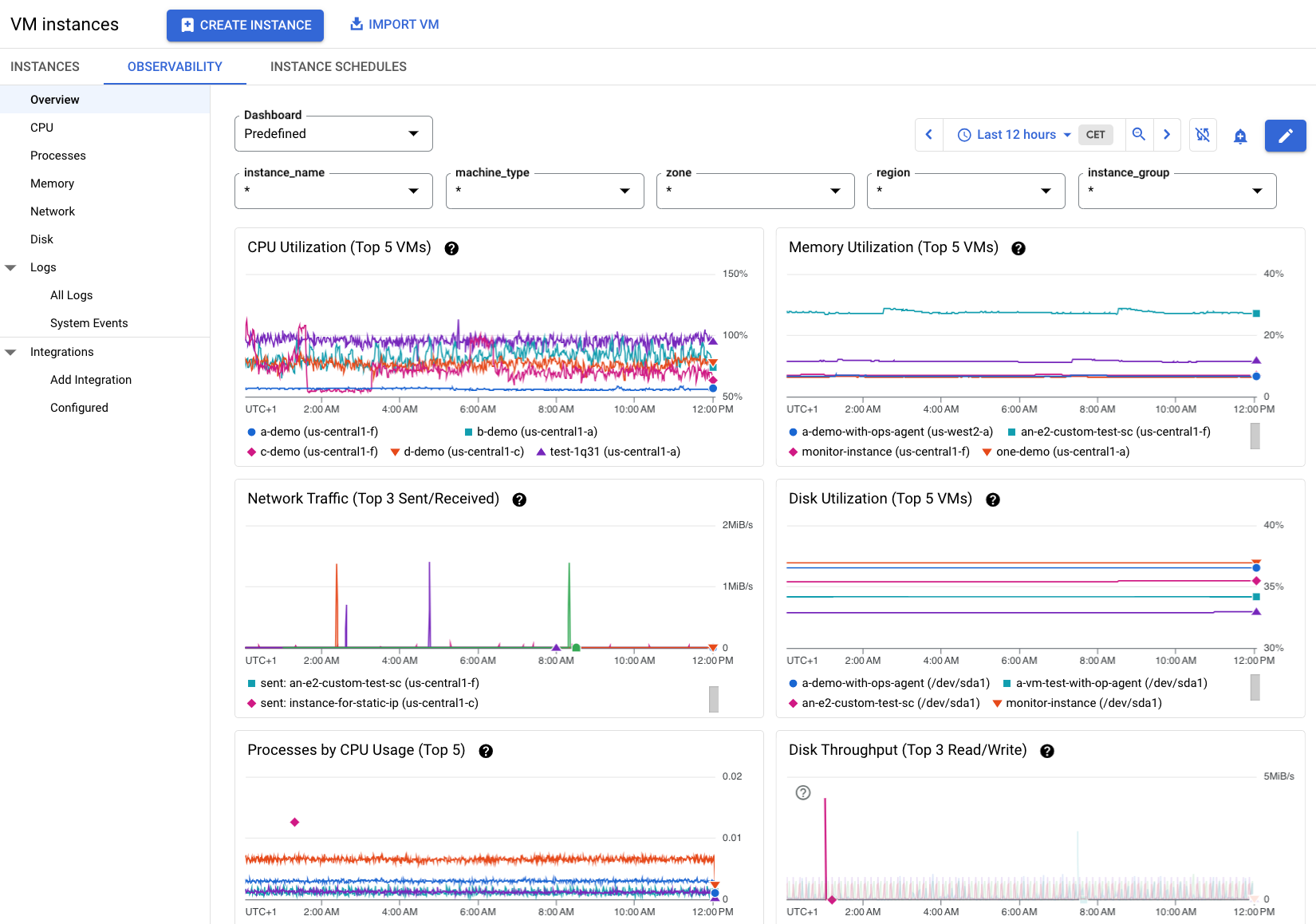
Le informazioni nella Figura 2 mostrano un esempio della scheda Osservabilità quando su più VM di un progetto è installato Ops Agent. Nota che sono disponibili altre metriche su queste VM.
Visualizzare metriche dettagliate per una VM
Ogni metrica del processo della VM è rappresentata da una linea del grafico. Nell'esempio seguente, nella VM uptime-demo è installato Ops Agent. I dati sull'utilizzo della memoria sono disponibili per la risoluzione dei problemi. Se una VM non è elencata nella scheda, filtra per nome VM per trovare una VM specifica.
Per recuperare le informazioni su questa VM o su un'altra delle prime cinque VM dalla scheda Osservabilità:
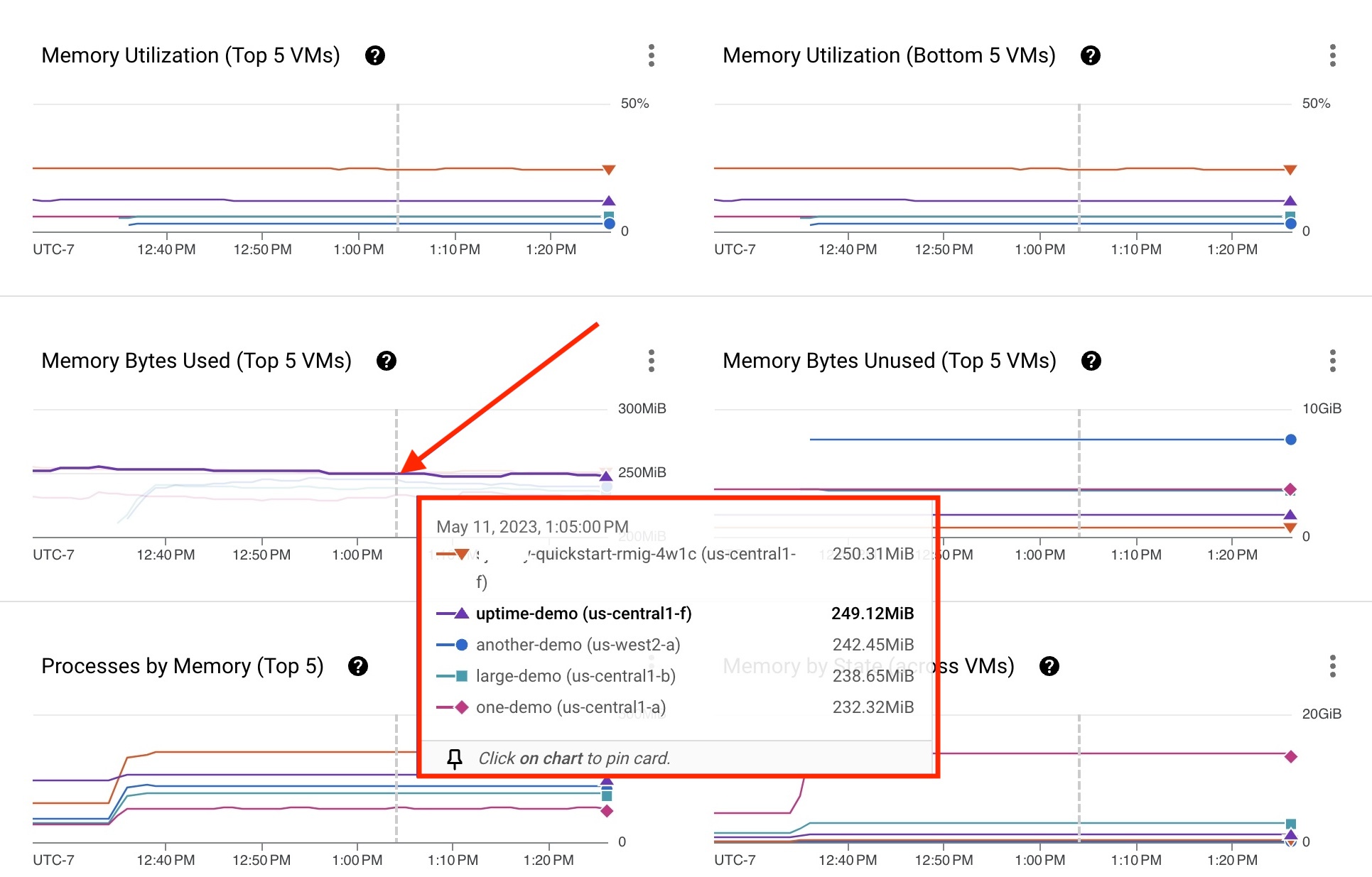
- Tieni il puntatore sopra la linea del grafico di una VM. Viene visualizzata una scheda con un elenco delle prime cinque VM che utilizzano il processo, ognuna delle quali mostra una metrica.
- Per saperne di più sul comportamento della VM, fai clic sulla linea del grafico della VM o su un nome specifico della VM nell'elenco.
La VM uptime-demo visualizzata nella scheda della Figura 3 mostra alcune metriche che potrebbero richiedere una revisione.
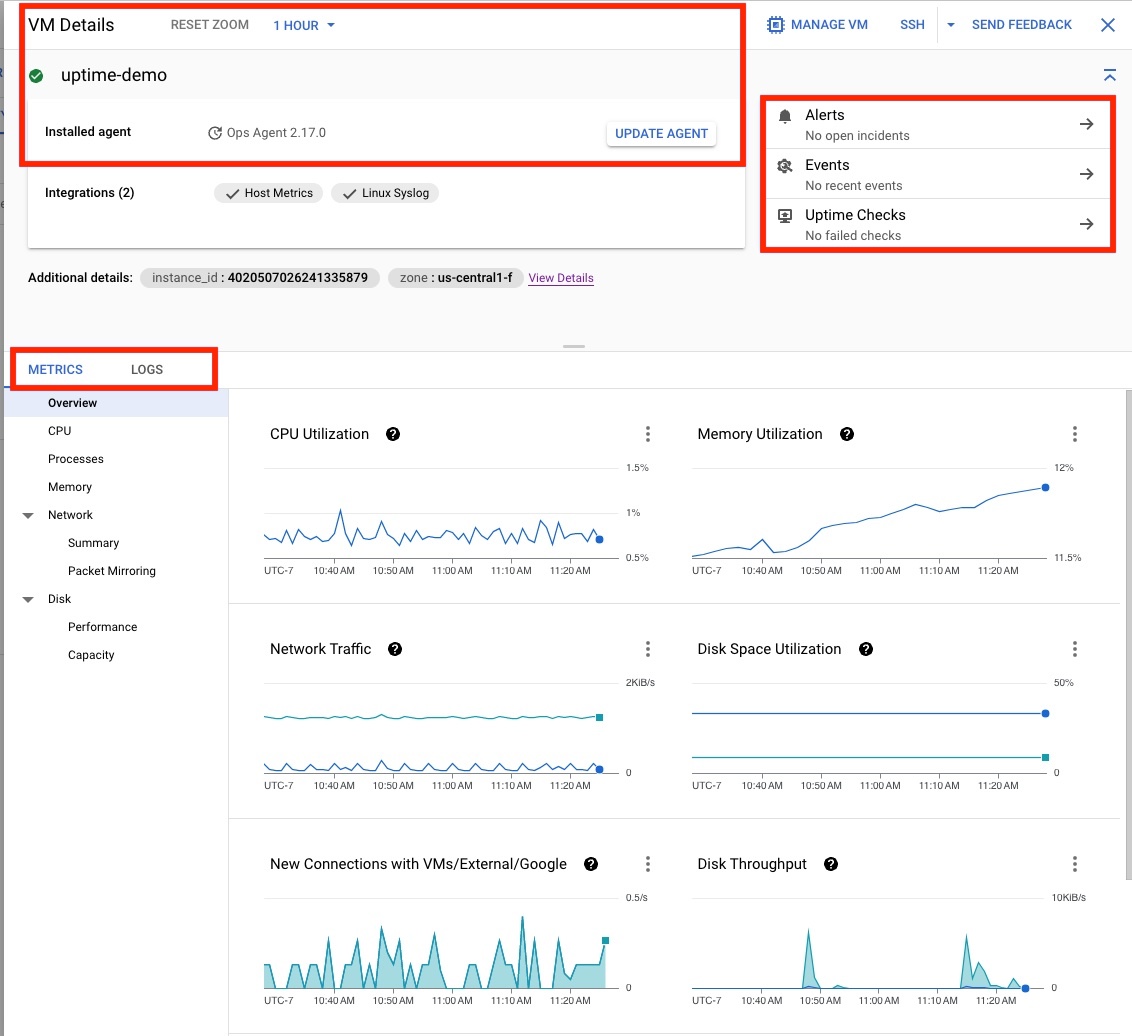
Fai clic sulla VM uptime-demo per aprire la pagina Dettagli VM mostrata nella Figura 4, che fornisce le seguenti informazioni:
- Lo stato dell'agente operativo.
- Le opzioni contestuali per creare avvisi, controllare gli eventi o creare controlli di uptime.
- L'opzione per visualizzare i dettagli delle configurazioni, delle metriche e dei log della VM.
Creare una dashboard personalizzata per visualizzare metriche specifiche
Per impostazione predefinita, la scheda Osservabilità in Compute Engine fornisce una dashboard predefinita che mostra le metriche di base della VM. Per visualizzare solo le metriche specifiche che ti interessano, puoi modificare la dashboard predefinita e salvarla come dashboard personalizzata. Puoi personalizzare ulteriormente la dashboard come preferisci.
Per creare una dashboard personalizzata:
Nella console Google Cloud , vai alla pagina Istanze VM.
Vai alla scheda Osservabilità nel seguente modo:
- Per una singola VM: nella pagina Istanze VM, fai clic sul nome della VM per aprire la pagina Dettagli, quindi fai clic sulla scheda Osservabilità per quella VM.
- Per più VM: nella pagina Istanze VM, fai clic sulla scheda Osservabilità.
Se il menu a discesa Dashboard è abilitato, le dashboard personalizzate sono disponibili. Per modificare una visualizzazione personalizzata, selezionala dal menu a discesa e poi fai clic su nella barra degli strumenti della dashboard.
Altrimenti, per personalizzare la dashboard predefinita, fai clic su nella barra degli strumenti della dashboard.
Compute Engine crea una copia della dashboard predefinita e la apre in modalità di modifica.
Nell'editor puoi aggiungere, modificare, eliminare, riposizionare o ridimensionare le visualizzazioni nel dashboard. Le visualizzazioni sono chiamate collettivamente widget. Per saperne di più sui diversi tipi di widget, consulta Panoramica delle dashboard.
Per aggiungere un widget, fai clic su Aggiungi widget nella barra degli strumenti della dashboard e completa la configurazione.
Ad esempio, per visualizzare i log con i dati delle metriche, fai clic su Aggiungi widget, seleziona Log e poi fai clic su Applica.
Per modificare un widget, posiziona il puntatore sul widget per attivare la barra degli strumenti, fai clic su Modifica widget e poi utilizza la finestra di dialogo Configura widget. Per applicare le modifiche alla dashboard, fai clic su Applica nella barra degli strumenti. Per ignorare le modifiche, fai clic su Annulla.
Per eliminare un widget, posiziona il puntatore sul widget per attivare la barra degli strumenti, fai clic su Altre opzioni del grafico e poi seleziona Elimina.
Per riposizionare un widget, utilizza il puntatore per trascinarlo per l'intestazione in una nuova posizione.
Per ridimensionare un widget, utilizza il puntatore per riposizionare l'angolo destro del widget.
Una volta terminata la modifica della dashboard, fai clic su Salva.
Nella finestra di dialogo di conferma delle modifiche, fai clic su Visualizza dashboard personalizzata per passare alla visualizzazione personalizzata.
Puoi tornare alla visualizzazione predefinita selezionando Predefinita dal menu a discesa Dashboard.
Esamina le metriche delle risorse
Per saperne di più su ciascuna metrica delle risorse, fai clic su ogni processo nel menu della scheda Osservabilità:
- Esplora l'utilizzo di CPU, Processi, Memoria, il traffico di Rete e l'utilizzo del Disco.
- Visualizza i dati dei log cercando Log per identificare e visualizzare gli Eventi di sistema.
- Aggiungi integrazioni di terze parti e verifica la presenza di integrazioni esistenti configurate.
Il resto di questa sezione descrive esempi di come alcuni processi potrebbero influire sui tuoi carichi di lavoro. Queste informazioni presuppongono che Ops Agent sia installato sulle tue VM.
Utilizzo CPU
Un esempio di utilizzo estremo della CPU potrebbe verificarsi quando un server è sottoposto a un carico inaspettatamente elevato, ad esempio quando un sito web registra un improvviso aumento del traffico o quando è in corso un'attività di elaborazione dei dati su larga scala. In queste situazioni, la CPU potrebbe funzionare al 100% della capacità per un periodo di tempo prolungato, il che può causare il rallentamento o la mancata risposta del server.
In questo esempio, il problema è la saturazione. Se l'utilizzo della CPU è al 100%, potrebbe essere accettabile per i tuoi carichi di lavoro, ma ti consigliamo di esaminare altre metriche per capire se è necessario un intervento. In questo caso, ti consigliamo di creare una policy di avviso in modo da ricevere una notifica quando l'utilizzo della CPU di una VM aumenta improvvisamente.
Con le autorizzazioni appropriate, puoi connetterti alle tue VM tramite SSH per esaminare il problema. Tuttavia, se Ops Agent è installato, puoi visualizzare più dati storici per aiutarti a risolvere i problemi.
Utilizzo del processo
Un esempio di comportamento estremo di un processo potrebbe essere quando un processo consuma una quantità eccessiva di risorse come CPU, memoria o I/O del disco, al punto da causare un peggioramento delle prestazioni o persino un arresto anomalo della VM.
Ad esempio, se un processo in esecuzione su una VM presenta una perdita di memoria, potrebbe iniziare a consumare quantità di memoria sempre maggiori nel tempo, fino a causare l'esaurimento della memoria della VM e l'arresto anomalo. Allo stesso modo, se un processo utilizza molto il disco, può causare la saturazione dell'I/O del disco della VM, con conseguente rallentamento dei tempi di risposta per altri processi.
Utilizzo memoria
I database richiedono una grande quantità di memoria per eseguire operazioni come l'indicizzazione, l'ordinamento e l'unione di tabelle.
Un esempio di utilizzo elevato della memoria su una VM si verifica quando esegui un server di database, come Cloud SQL per MySQL o Cloud SQL per PostgreSQL, con un set di dati di grandi dimensioni. Se la memoria disponibile della VM è troppo piccola, il ricaricamento di un set di dati in memoria può causare il rallentamento o l'arresto anomalo del database.
Prestazioni di rete
I problemi di prestazioni di rete sono il risultato di diversi fattori: congestione, limitazioni della larghezza di banda, problemi hardware o software e latenza. Per diagnosticare il problema, monitora le metriche delle prestazioni di rete, risolvi i problemi di hardware e software e analizza i pattern di traffico di rete per identificare e risolvere la causa principale del problema.
Utilizzo del disco
L'utilizzo elevato del disco su una VM si verifica quando viene letta o scritta una grande quantità di dati sul disco virtuale, il che comporta un ritardo nell'accesso al disco e un possibile effetto sulle prestazioni della VM.
Il monitoraggio delle metriche di utilizzo del disco, come le operazioni di I/O del disco al secondo (IOPS), la lunghezza della coda del disco e il tempo di risposta medio del disco, può aiutarti a identificare e diagnosticare problemi di utilizzo elevato del disco su una VM.
Controllare i log e gli eventi di sistema
La pagina Tutti i log fornisce dati di log sulle tue risorse. Ordina per gravità per identificare i problemi e ispezionare il payload.
Gli audit log registrano gli eventi amministrativi che si verificano nelle tue risorse. I log possono indicare cosa è successo per attivare l'evento. Più log vengono registrati e mantenuti nella stessa riga, quindi, ad esempio, se hai 20 log identici, le informazioni vengono archiviate in una riga, anziché in 20 righe separate.
Puoi considerare gli eventi di sistema come un termine generico per gli eventi che si verificano a un livello superiore, ma che potrebbero influire sulle tue risorse Compute Engine. Un evento di sistema si verifica quando viene attivato un errore non correlato a un evento pianificato. Gli eventi di sistema vengono registrati a livello di parco risorse.
Utilizzare le integrazioni di terze parti
Monitoring fornisce integrazioni con applicazioni di terze parti. Queste integrazioni ti consentono di raccogliere dati di telemetria da applicazioni come Apache Web Server, Cloud SQL per MySQL, Memorystore for Redis e altre per i deployment in esecuzione su Compute Engine e GKE. Quando utilizzi Compute Engine, i dati di telemetria di terze parti vengono raccolti da Ops Agent.