Questo documento descrive i tipi di eventi che possono essere visualizzati come annotazioni sui grafici. Un evento è un'attività, come un riavvio o un arresto anomalo, che influisce sul funzionamento di un sistema. La visualizzazione degli eventi può aiutarti a correlare i dati provenienti da origini diverse durante la risoluzione di un problema.
Per ogni evento vengono forniti link a riferimenti o documentazione per la risoluzione dei problemi, nonché informazioni su come eseguire query sull'evento. Ad esempio, quando gli eventi vengono identificati analizzando i log, viene fornita una query adatta per l'utilizzo con Logs Explorer o con un criterio di avviso basato su log.
Per aggiungere annotazioni ai grafici, configura la dashboard o la scheda che li mostra. Ad esempio, puoi configurare la maggior parte delle dashboard elencate nella pagina Dashboard della Google Cloud console in modo da mostrare gli eventi. Analogamente, puoi configurare alcune schede Osservabilità specifiche per i servizi, come quelle per Compute Engine e Google Kubernetes Engine, per mostrare gli eventi. Per informazioni sulla configurazione, consulta Mostrare gli eventi in una dashboard.
Lo screenshot seguente mostra un grafico che indica diversi eventi identificati analizzando le voci di log e un evento relativo allo stato del servizio:
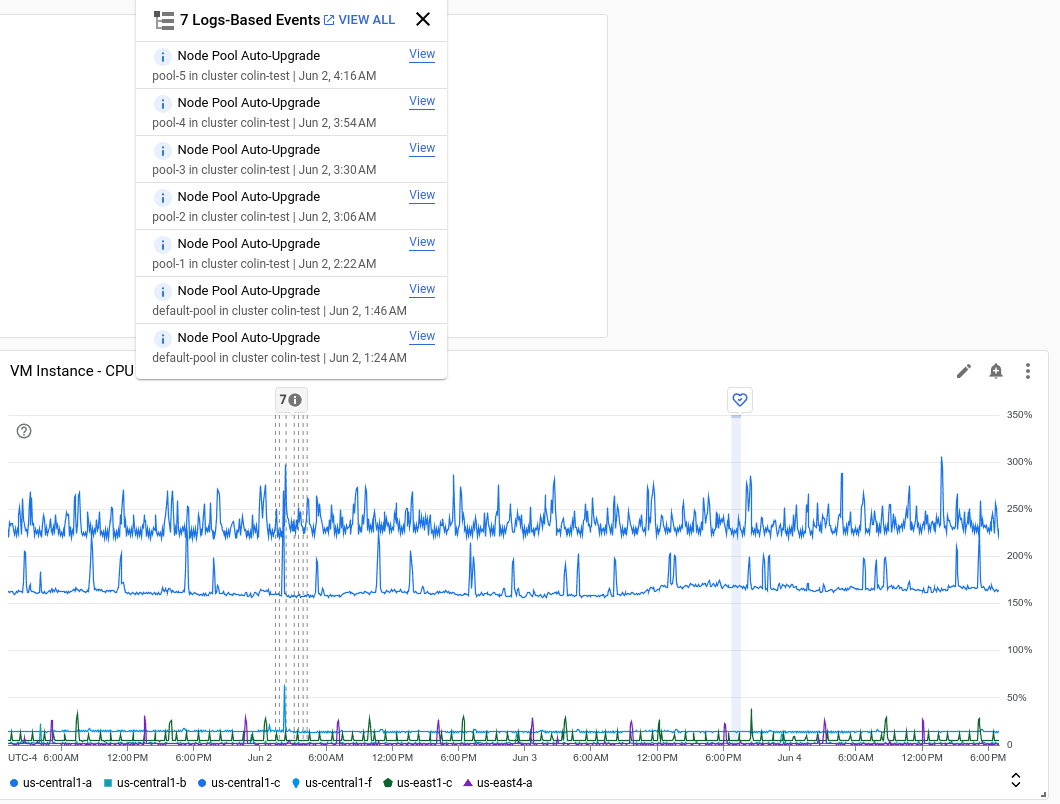
Ogni annotazione può elencare più eventi. Nello screenshot precedente è elencato un evento per un deployment GKE.
Tipi di eventi di avviso
Questa sezione descrive i tipi di eventi di avviso che possono essere visualizzati in una dashboard.
Avviso aperto
Gli eventi di apertura degli avvisi ti aiutano a correlare i dati visualizzati sul grafico al momento di apertura degli incidenti. Un evento di apertura dell'avviso viene visualizzato quando si verificano le seguenti condizioni:
- L'incidente corrispondente è stato aperto durante l'intervallo di tempo specificato dalla dashboard.
- L'incidente corrispondente non è chiuso.
Non vengono mostrate annotazioni per gli incidenti aperti al di fuori dell'intervallo di tempo specificato dalla dashboard. Analogamente, un evento di apertura dell'avviso non viene visualizzato quando l'incidente corrispondente è stato aperto e poi chiuso nell'intervallo di tempo specificato dalla dashboard.
La descrizione comando per un evento di apertura dell'avviso include quanto segue:
- Nome del criterio di avviso.
- Informazioni di riepilogo, se disponibili. Ad esempio, queste informazioni potrebbero includere la soglia e il valore misurato.
- La durata dell'incidente e la data e l'ora in cui è stato aperto.
- Etichette delle metriche e delle risorse. La descrizione comando potrebbe non mostrare tutte le etichette.
- Un pulsante Visualizza che apre la pagina Dettagli dell'incidente.
Tipi di eventi di Google Kubernetes Engine
Questa sezione descrive i tipi di eventi di Google Kubernetes Engine che possono essere visualizzati in una dashboard.
Workload GKE patchato o aggiornato
Questo tipo di evento ti aiuta a risolvere i problemi relativi al deployment del carico di lavoro GKE o alle modifiche di statefulset, poiché questi eventi possono essere correlati a regressioni delle prestazioni o ad altri problemi di prestazioni. Questo tipo di evento viene visualizzato quando un workload viene creato, aggiornato o eliminato.
Se vuoi creare un criterio di avviso basato su log per questo tipo di evento, utilizza la seguente query:
log_id(cloudaudit.googleapis.com%2Factivity)
resource.type=k8s_cluster protoPayload.methodName=(
io.k8s.apps.v1.deployments.create OR io.k8s.apps.v1.deployments.patch OR
io.k8s.apps.v1.deployments.update OR io.k8s.apps.v1.deployments.delete OR
io.k8s.apps.v1.statefulsets.create OR io.k8s.apps.v1.statefulsets.patch OR
io.k8s.apps.v1.statefulsets.update OR io.k8s.apps.v1.statefulsets.delete OR
io.k8s.apps.v1.daemonsets.create OR io.k8s.apps.v1.daemonsets.patch OR
io.k8s.apps.v1.daemonsets.update OR io.k8s.apps.v1.daemonsets.delete
)
-protoPayload.authenticationInfo.principalEmail=("system:addon-manager" OR "system:serviceaccount:kube-system:namespace-controller")
-protoPayload.request.metadata.namespace=(kube-system OR gmp-system OR gmp-public OR gke-gmp-system OR istio-system)
-protoPayload.response.metadata.namespace=(kube-system OR gmp-system OR gmp-public OR gke-gmp-system OR istio-system)
-protoPayload.resourceName=~"namespaces/(kube-system|gmp-system|gmp-public|gke-gmp-system|istio-system)"
Per ulteriori informazioni, consulta la panoramica del deployment dei carichi di lavoro e Visualizzare le metriche di osservabilità.
Arresto anomalo di un pod GKE
Questo tipo di evento ti aiuta a identificare e risolvere i problemi relativi agli arresti anomali dei pod GKE. Gli arresti anomali dei pod possono essere causati da esaurimento della memoria o da un errore dell'applicazione. Questo tipo di evento viene visualizzato quando si verifica una delle seguenti condizioni:
- Lo stato del pod è
CrashLoopBackoff - Il pod termina con un codice di uscita diverso da zero.
- Il pod termina con una condizione di esaurimento della memoria.
- Il pod viene rimosso.
- Il probe di idoneità/attività non va a buon fine.
Se vuoi creare un criterio di avviso basato su log per questo tipo di evento, utilizza la seguente query:
(
log_id(events)
(
(resource.type=k8s_pod jsonPayload.reason=(BackOff OR Unhealthy OR Killing OR Evicted)) OR
(resource.type=k8s_node jsonPayload.reason=OOMKilling)
)
severity=WARNING
) OR (
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=k8s_cluster
(protoPayload.methodName=io.k8s.core.v1.pods.eviction.create OR
(protoPayload.methodName=io.k8s.core.v1.pods.delete
protoPayload.response.status.containerStatuses.state.terminated.exitCode:*
-protoPayload.response.status.containerStatuses.state.terminated.exitCode=0
)
)
)
Per informazioni sulla risoluzione dei problemi, consulta Risoluzione dei problemi: CrashLoopBackOff.
Impossibile pianificare un pod GKE
Questo tipo di evento ti aiuta a identificare e risolvere i problemi relativi ai pod che non possono essere pianificati su un nodo. Questo tipo di evento viene mostrato quando la pianificazione dei pod non riesce per uno dei seguenti motivi:
- CPU del nodo insufficiente.
- Memoria del nodo insufficiente.
- Nessun nodo per contaminazioni o tolleranze.
- Nodi al limite massimo di pod.
- Node pool con dimensioni massime.
Se vuoi creare un criterio di avviso basato su log per questo tipo di evento, utilizza la seguente query:
(
log_id(events) resource.type=k8s_pod jsonPayload.reason=(NotTriggerScaleUp OR FailedScheduling)
) OR (
log_id(container.googleapis.com/cluster-autoscaler-visibility)
resource.type=k8s_cluster jsonPayload.noDecisionStatus.noScaleUp:*
)
Per informazioni sulla risoluzione dei problemi, consulta Risoluzione dei problemi: pod non pianificabile.
Impossibile creare un container GKE
Questo tipo di evento consente di identificare e risolvere i problemi di creazione di un container GKE. La creazione dei container potrebbe non riuscire per motivi quali montaggi dei volumi non riusciti o errori di pull delle immagini.
Se vuoi creare un criterio di avviso basato su log per questo tipo di evento, utilizza la seguente query:
log_id(events) resource.type=k8s_pod jsonPayload.reason=(Failed OR FailedMount) severity=WARNING
Per informazioni sulla risoluzione dei problemi relativi ai tiri delle immagini, consulta Risolvere i problemi relativi ai tiri delle immagini.
Scale up e scale down del gestore della scalabilità automatica dei pod
Questo evento ti consente di visualizzare le ridimensionamenti di Horizontal Pod Autoscaler, che aumentano o diminuiscono il numero di pod in esecuzione per un carico di lavoro. Per ulteriori informazioni, consulta la sezione Scalabilità automatica pod orizzontale.
Se vuoi creare un criterio di avviso basato su log per questo tipo di evento, utilizza la seguente query:
resource.type=k8s_cluster log_id(events) jsonPayload.involvedObject.kind=HorizontalPodAutoscaler jsonPayload.reason=SuccessfulRescale
Scale up e scale down del gestore della scalabilità automatica del cluster
Questo evento ti consente di sapere quando il gestore della scalabilità automatica del cluster aumenta o diminuisce il numero di nodi in un pool di nodi del tuo cluster. Per ulteriori informazioni, consulta Informazioni sulla scalabilità automatica dei cluster e Visualizzazione degli eventi di scalabilità automatica del cluster.
Se vuoi creare un criterio di avviso basato su log per questo tipo di evento, utilizza la seguente query:
(resource.type=k8s_cluster log_id(container.googleapis.com%2Fcluster-autoscaler-visibility) jsonPayload.decision:*)
Creazione ed eliminazione di cluster
Questo evento monitora le azioni di creazione ed eliminazione del cluster GKE. Per ulteriori informazioni, consulta Creare un cluster Autopilot, Creare un cluster zonale e Eliminare un cluster.
Se vuoi creare un criterio di avviso basato su log per questo tipo di evento, utilizza la seguente query:
resource.type=gke_cluster log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(
google.container.v1alpha1.ClusterManager.CreateCluster OR
google.container.v1beta1.ClusterManager.CreateCluster OR
google.container.v1.ClusterManager.CreateCluster OR
google.container.v1alpha1.ClusterManager.DeleteCluster OR
google.container.v1beta1.ClusterManager.DeleteCluster OR
google.container.v1.ClusterManager.DeleteCluster
)
operation.first=true
Aggiornamento del cluster
Questo evento monitora gli aggiornamenti del cluster GKE. Gli aggiornamenti includono upgrade automatici delle versioni del piano di controllo, oltre ad upgrade manuali e modifiche alla configurazione del cluster. Per ulteriori informazioni, consulta Eseguire l'upgrade manuale di un cluster o di un pool di nodi e Upgrade di cluster standard.
Se vuoi creare un criterio di avviso basato su log per questo tipo di evento, utilizza la seguente query:
resource.type=gke_cluster log_id(cloudaudit.googleapis.com%2Factivity)
(
protoPayload.methodName=(
google.container.internal.ClusterManagerInternal.PatchCluster OR
google.container.internal.ClusterManagerInternal.UpdateClusterInternal OR
google.container.internal.ClusterManagerInternal.UpdateCluster
)
) OR (
protoPayload.methodName=(
google.container.v1beta1.ClusterManager.UpdateCluster OR
google.container.v1.ClusterManager.UpdateCluster
)
operation.first=true
)
protoPayload.metadata.operationType=(UPGRADE_MASTER OR REPAIR_CLUSTER OR UPDATE_CLUSTER)
Aggiornamento del node pool
Questo evento monitora gli aggiornamenti del pool di nodi GKE. Gli aggiornamenti includono upgrade automatici delle versioni del pool di nodi, oltre ad upgrade manuali, modifiche alla configurazione e ridimensionamenti. Per ulteriori informazioni, consulta Eseguire l'upgrade manuale di un cluster o di un pool di nodi e Upgrade di cluster standard.
Se vuoi creare un criterio di avviso basato su log per questo tipo di evento, utilizza la seguente query:
resource.type=gke_nodepool log_id(cloudaudit.googleapis.com%2Factivity)
(
protoPayload.methodName=(
google.container.internal.ClusterManagerInternal.UpdateClusterInternal OR
google.container.internal.ClusterManagerInternal.RepairNodePool
)
) OR (
protoPayload.methodName=(
google.container.v1beta1.ClusterManager.UpdateNodePool OR
google.container.v1.ClusterManager.UpdateNodePool OR
google.container.v1beta1.ClusterManager.SetNodePoolSize OR
google.container.v1.ClusterManager.SetNodePoolSize OR
google.container.v1beta1.ClusterManager.SetNodePoolManagement OR
google.container.v1.ClusterManager.SetNodePoolManagement OR
google.container.v1beta1.ClusterManager.SetNodePoolAutoscaling OR
google.container.v1.ClusterManager.SetNodePoolAutoscaling
)
operation.first=true
)
Tipi di eventi Cloud Run
Questa sezione descrive i tipi di eventi Cloud Run che possono essere visualizzati in una dashboard.
Deployment di Cloud Run
Questo tipo di evento ti aiuta a identificare e risolvere i problemi di deployment di Cloud Run. Il deployment potrebbe non riuscire per motivi come account di servizio eliminato, autorizzazioni errate, importazione di un contenitore non riuscita o avvio di un contenitore non riuscito.
Se vuoi creare un criterio di avviso basato su log per questo tipo di evento, utilizza la seguente query:
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=cloud_run_revision protoPayload.methodName=google.cloud.run.v1.Services.ReplaceService
Per informazioni sulla risoluzione dei problemi, consulta Risoluzione dei problemi: problemi di Cloud Run.
Tipi di eventi Cloud SQL
Questa sezione descrive i tipi di eventi Cloud SQL che possono essere visualizzati in una dashboard.
Failover di Cloud SQL
Questo tipo di evento ti aiuta a identificare quando si verificano failover manuali o automatici. Un failover si verifica in caso di errore di un'istanza o una zona e l'istanza in standby diventa la nuova istanza principale. Durante un failover, Cloud SQL passa automaticamente all'erogazione dei dati dall'istanza in standby.
Se vuoi creare un criterio di avviso basato su log per questo tipo di evento, utilizza la seguente query:
resource.type=cloudsql_database
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=cloudsql.instances.failover
operation.last=true
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=cloudsql.instances.autoFailover
)
)
Per ulteriori informazioni, consulta Informazioni sull'alta disponibilità.
Avvio o arresto di Cloud SQL
Questo tipo di evento consente di identificare un'istanza Cloud SQL avviata, interrotta o riavviata manualmente. Quando un'istanza viene arrestata, vengono arrestate anche tutte le connessioni, i file aperti e le operazioni in esecuzione.
Se vuoi creare un criterio di avviso basato su log per questo tipo di evento, utilizza la seguente query:
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=cloudsql_database protoPayload.methodName=cloudsql.instances.update operation.last=true protoPayload.metadata.intents.intent=(START_INSTANCE OR STOP_INSTANCE)
Per ulteriori informazioni, consulta Informazioni sull'alta disponibilità e Avvio, arresto e riavvio di istanze.
Spazio di archiviazione Cloud SQL
Questo tipo di evento ti aiuta a identificare gli eventi relativi allo spazio di archiviazione di Cloud SQL, tra cui quando lo spazio di archiviazione del database è esaurito e quando un database viene arrestato perché ha raggiunto la capacità di archiviazione. I database che raggiungono la capacità di archiviazione e che non hanno l'archiviazione automatica abilitata potrebbero essere arrestati per evitare il danneggiamento dei dati.
Se vuoi creare un criterio di avviso basato su log per questo tipo di evento, utilizza la seguente query:
resource.type=cloudsql_database
(
(
(log_id(cloudsql.googleapis.com%2Fpostgres.log) OR log_id(cloudsql.googleapis.com%2Fmysql.err))
textPayload=~"No space left on device"
severity=(ERROR OR EMERGENCY)
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=cloudsql.instances.databaseShutdownOutOfStorage
)
)
Tipi di eventi Compute Engine
Questa sezione descrive i tipi di eventi Compute Engine che possono essere visualizzati in una dashboard.
Terminazioni delle macchine virtuali
Questo tipo di evento ti aiuta a identificare le terminazioni delle macchine virtuali (VM), inclusi gli arresti e le reimpostazioni attivati manualmente, le terminazioni del sistema operativo guest, quelle delle operazioni di manutenzione e gli errori dell'host.
Se vuoi creare un criterio di avviso basato su log per questo tipo di evento, utilizza la seguente query:
resource.type=gce_instance
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(
beta.compute.instances.reset OR v1.compute.instances.reset OR
beta.compute.instances.stop OR v1.compute.instances.stop
)
operation.first=true
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=(
compute.instances.hostError OR
compute.instances.guestTerminate OR
compute.instances.terminateOnHostMaintenance
)
)
)
Per ulteriori informazioni, consulta Arrestare e avviare una VM e Risoluzione dei problemi di arresto e riavvio delle VM.
Errore di avvio dell'istanza VM
Questo evento monitora gli errori di avvio delle istanze VM di Compute Engine. L'evento mostra errori di avvio dovuti a problemi di disponibilità, esaurimento dello spazio IP, quota superata o errori di integrità della Shielded VM.
Se vuoi creare un criterio di avviso basato su log per questo tipo di evento, utilizza la seguente query:
resource.type=gce_instance
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(beta.compute.instances.insert OR v1.compute.instances.insert)
protoPayload.status.message=(ZONE_RESOURCE_POOL_EXHAUSTED OR IP_SPACE_EXHAUSTED OR QUOTA_EXCEEDED)
) OR (
log_id(compute.googleapis.com%2Fshielded_vm_integrity)
severity="ERROR"
)
)
Errore del sistema operativo guest dell'istanza VM
Questo evento monitora errori specifici del sistema operativo guest delle istanze VM di Compute Engine, così come vengono registrati dai log della console seriale. Gli errori rilevati riguardano disco pieno, montaggio del file system non riuscito e problemi di mancato avvio che attivano la modalità di emergenza di Linux.
Affinché questi eventi siano visibili, devi abilitare il logging dell'output della porta seriale in Cloud Logging impostando serial-port-logging-enable=true nella VM o nei metadati del progetto. Per ulteriori informazioni, consulta
Attivare e disattivare il logging dell'output della porta seriale.
Se vuoi creare un criterio di avviso basato su log per questo tipo di evento, utilizza la seguente query:
resource.type=gce_instance
log_id(serialconsole.googleapis.com%2Fserial_port_1_output)
textPayload=~("No space left on device" OR "Failed to mount" OR "You are in emergency mode")
Aggiornamento del gruppo di istanze gestite
Questo tipo di evento ti aiuta a identificare quando il gruppo di istanze gestite (MIG) è stato aggiornato. Ad esempio, sono state aggiunte o rimosse VM oppure il limite di dimensioni è stato aggiornato. Per ulteriori informazioni, consulta la pagina relativa all'applicazione automatica degli aggiornamenti di configurazione delle VM in un gruppo di istanze gestite.
Se vuoi creare un criterio di avviso basato su log per questo tipo di evento, utilizza la seguente query:
resource.type=gce_instance_group_manager log_id(cloudaudit.googleapis.com%2Factivity) operation.first=true protoPayload.methodName=(beta.compute.instanceGroupManagers.patch OR v1.compute.instanceGroupManagers.patch)
Per ulteriori informazioni, consulta Utilizzare le istanze gestite e Risolvere i problemi relativi ai gruppi di istanze gestite.
Gestore della scalabilità automatica del gruppo di istanze gestite
Questo evento monitora le decisioni di scalabilità prese dal gestore della scalabilità automatica di un gruppo di istanze gestite. Queste decisioni potrebbero includere modifiche alle dimensioni consigliate per un gruppo di istanze gestite o una modifica dello stato del gestore della scalabilità automatica stesso. Per ulteriori informazioni, consulta Gruppi di istanze a scalabilità automatica.
Se vuoi creare un criterio di avviso basato su log per questo tipo di evento, utilizza la seguente query:
resource.type=autoscaler log_id(cloudaudit.googleapis.com%2Fsystem_event) protoPayload.methodName=(compute.autoscalers.resize OR compute.autoscalers.changeStatus)
Tipi di eventi di Personalized Service Health
Questa sezione descrive i tipi di stato del servizio personalizzato che possono essere visualizzati in una dashboard.
Google Cloud incidente
Quando risolvi i problemi, ti consigliamo di distinguere tra i guasti causati da un servizio di tua proprietà e quelli causati da un servizioGoogle Cloud che utilizzi. Quando attivi le annotazioni di Personalized Service Health in una dashboard, puoi visualizzare le interruzioni o gli eventi relativi allo stato del servizio per i Google Cloud servizi. Per un elenco dei servizi integrati con il monitoraggio del servizio, consulta Prodotti Google supportati.
A differenza di altri tipi di eventi, Google Cloud gli incidenti non vengono identificati analizzando le voci dei log. Se vuoi ricevere una notifica quando si verificano questi eventi, crea un criterio di avviso. Puoi selezionare un criterio di avviso preconfigurato utilizzando le opzioni nella pagina Dashboard di Service Health. Per ulteriori informazioni, consulta la guida rapida: configurare un avviso.
Il monitoraggio identifica gli Google Cloud incidenti inviando una richiesta all'API Service Health e filtrando poi la risposta in base agli incidenti pertinenti ai dati visualizzati. La richiesta ha la seguente configurazione:
L'enumerazione
Relevanceè impostata suRELATED,IMPACTEDoPARTIALLY_RELATED. Questa limitazione garantisce che la dashboard mostri solo gli eventi relativi ai Google Cloud servizi utilizzati dalGoogle Cloud progetto.L'enumerazione
DetailedStatenon è impostata suFALSE_POSITIVE.
Le annotazioni di Service Health vengono visualizzate con un'ora di inizio e una durata. La durata viene visualizzata modificando il colore di sfondo del grafico. La descrizione comando di un Google Cloud incidente identifica quanto segue:
- Il Google Cloud servizio.
- Indica se l'incidente è aperto o risolto.
- Data e ora di inizio dell'evento.
- Chip che mostrano il numero di prodotti e località interessati. Per elencare i prodotti o le località interessati, posiziona il cursore sul chip corrispondente.
- Un pulsante Visualizza che, se selezionato, apre la pagina dei dettagli dell'incidente.
Per informazioni su come inviare una richiesta all'API Service Health, consulta Verificare la presenza di interruzioni con Service Health.
Per informazioni sulla risoluzione dei problemi, vedi Risolvere i problemi comuni in Service Health.
Tipi di eventi di controllo di uptime
Questa sezione descrive i tipi di eventi di controllo di uptime che possono essere visualizzati in una dashboard.
Errore del controllo di uptime
Questo tipo di evento ti aiuta a identificare gli errori del controllo di uptime delle regioni configurate.
Se vuoi creare un criterio di avviso basato su log per questo tipo di evento, utilizza la seguente query:
log_id(monitoring.googleapis.com%2Fuptime_checks) ( resource.type=uptime_url OR resource.type=gce_instance OR resource.type=gae_app OR resource.type=k8s_service OR resource.type=servicedirectory_service OR resource.type=cloud_run_revision OR resource.type=aws_ec2_instance OR resource.type=aws_elb_load_balancer ) labels.uptime_result_type=UptimeCheckResult severity=NOTICE
Per informazioni sulla risoluzione dei problemi, consulta Risolvere i problemi relativi ai monitor sintetici e ai controlli di uptime.
Tipi di eventi dell'agente per SAP
Questa sezione descrive i tipi di eventi di Agent for SAP che possono essere visualizzati in una dashboard.
Disponibilità SAP
Questo tipo di evento ti aiuta a identificare gli eventi relativi alla disponibilità dell'agente per SAP. Questi eventi vengono attivati quando la disponibilità di SAP HANA, SAP NetWeaver o Pacemaker Cluster cambia.
Se vuoi creare un criterio di avviso basato su log per questo tipo di evento, utilizza la seguente query:
log_id(google-cloud-sap-agent) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) jsonPayload.metricEvent=true jsonPayload.metric=(workload.googleapis.com/sap/hana/service OR workload.googleapis.com/sap/hana/availability OR workload.googleapis.com/sap/nw/service OR workload.googleapis.com/sap/nw/availability OR workload.googleapis.com/sap/cluster/nodes OR workload.googleapis.com/sap/cluster/resources)
SAP Backint
Questo tipo di evento ti aiuta a identificare gli eventi correlati a Agent for SAP Backint. Qualsiasi backup o ripristino Backint scrive un evento con i dettagli del successo o dell'errore oltre alle statistiche sul trasferimento. I backup e i recuperi dei log vengono visualizzati solo in caso di errore, mentre i backup e i recuperi dei dati vengono visualizzati sia in caso di successo che di errore.
log_id(google-cloud-sap-agent-backint) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) (jsonPayload.fileType=data OR (jsonPayload.fileType=log AND jsonPayload.success=false)) jsonPayload.message=SAP_BACKINT_FILE_TRANSFER
Operazioni SAP
Questo tipo di evento ti aiuta a identificare gli eventi correlati alle operazioni dell'agente per SAP. Questi eventi vengono attivati quando lo stato di replica di SAP HANA cambia.
Se vuoi creare un criterio di avviso basato su log per questo tipo di evento, utilizza la seguente query:
log_id(google-cloud-sap-agent) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) jsonPayload.metricEvent=true jsonPayload.metric=workload.googleapis.com/sap/hana/ha/replication
Passaggi successivi
Per scoprire come mostrare gli eventi nelle dashboard, consulta Mostrare gli eventi in una dashboard.