Este documento explica o ciclo de vida de uma instância do Compute Engine, abordando os vários estados que ela pode passar, da criação à exclusão. Para saber como verificar o estado de uma ou mais instâncias, consulte o seguinte:
Ao entender o ciclo de vida de uma instância, é possível fazer o seguinte de maneira mais eficaz:
Resolver problemas de instâncias.
Gerenciar recursos de instância.
Planejar migrações de instâncias.
Estados de instância
Uma instância de computação pode passar por diferentes estados como parte do ciclo de vida. Ao criar uma instância, o Compute Engine provisiona recursos para iniciá-la. Depois disso, a instância passa para o preparo e se prepara para a primeira inicialização. Depois que a instância é iniciada, ela é considerada em execução. Uma instância em execução pode ser interrompida e reiniciada, ou suspensa e retomada, repetidamente, até ser excluída.
O diagrama a seguir mostra os diferentes estados que o Compute Engine pode definir para uma instância:
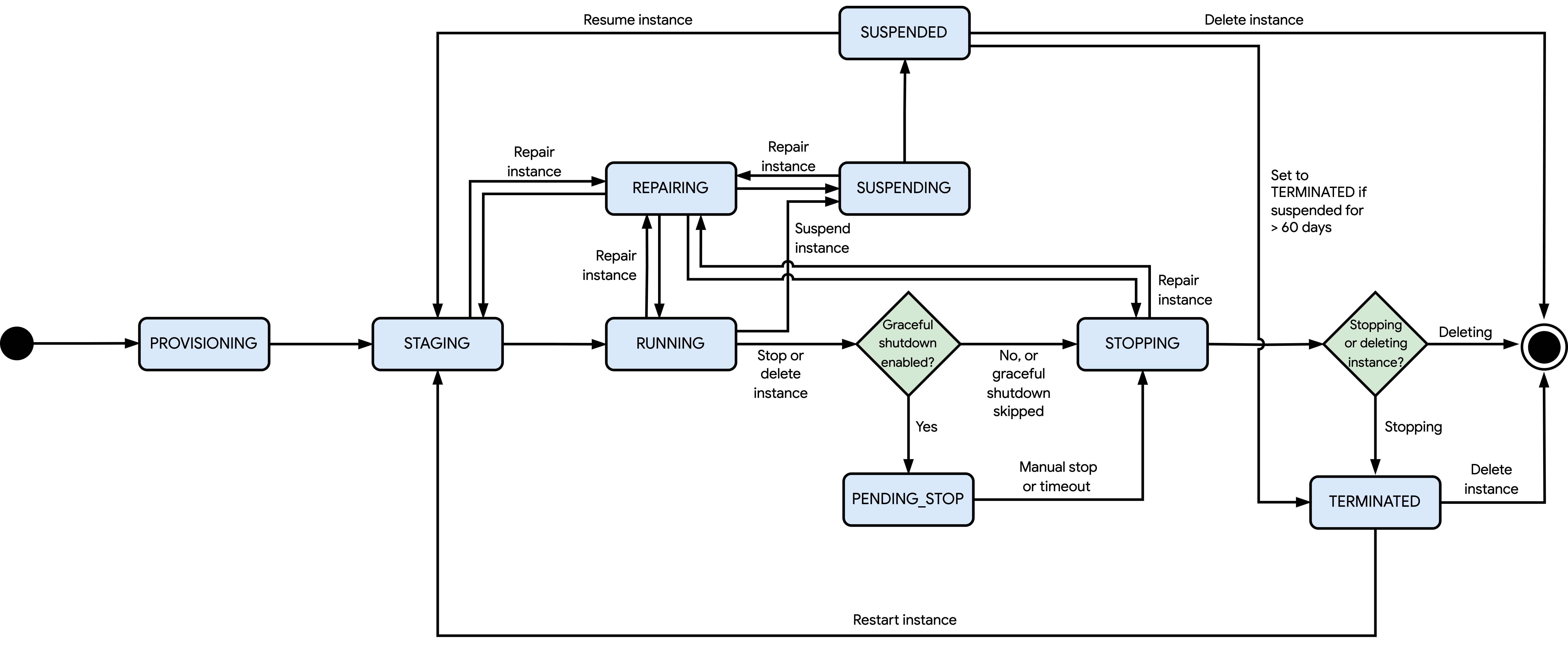
Os estados mostrados no diagrama anterior são os seguintes:
PENDING: depois de criar uma VM independente de início flexível com um tempo de espera (requestValidForDuration) de 90 segundos ou mais, o estado da VM muda paraPENDING. Nesse estado, o Compute Engine tenta adquirir os recursos necessários para iniciar a VM até que o tempo de espera termine. Se o Compute Engine adquirir os recursos dentro desse período e você tiver cota suficiente para eles, o estado da VM mudará paraPROVISIONING. Caso contrário, você vai encontrar um erro e o Compute Engine vai excluir a VM de início flexível. Você pode excluir a VM de início flexível antes do fim do tempo de espera se não precisar mais dela.PROVISIONING: depois de criar, reiniciar ou retomar uma instância, o Compute Engine aloca recursos para ela.STAGING: o Compute Engine está preparando a instância para a primeira inicialização por um dos seguintes motivos:O Compute Engine ainda está criando e configurando a instância.
Você ou uma operação programada solicitaram a reinicialização ou retomada da instância.
Nesse estado, a instância ainda não está em execução.
RUNNING: o Compute Engine está inicializando a instância ou ela está em execução. Nesse estado, é possível interromper, suspender ou excluir a instância. Além disso, o Compute Engine pode interromper ou excluir a instância para operações programadas ou corrigir a instância se ocorrer um erro de hardware e ela fizer parte de um grupo gerenciado de instâncias (MIG).PENDING_STOP: a instância está sendo desligada normalmente. Esse processo de encerramento acontece apenas se você tiver ativado o encerramento normal e tiver solicitado a interrupção ou exclusão da instância, ou se o Compute Engine estiver fazendo isso automaticamente para uma interrupção ou exclusão programada. O estado da instância muda paraSTOPPINGquando uma das seguintes situações acontece:Você encerra manualmente o desligamento normal.
O período de desligamento normal expira. Se ainda houver tarefas em execução, o Compute Engine vai forçar o encerramento delas.
STOPPING: a instância está encerrando o SO convidado, o que acontece nos seguintes cenários:Você ou uma operação programada pediram para parar ou excluir a instância.
Ocorreu um erro de hardware.
A menos que você configure a instância para ignorar o encerramento do SO convidado, o tempo de encerramento depende do tipo de instância. No entanto, se a instância for interrompida devido a um erro de hardware, o tempo de desligamento poderá ser diferente da duração esperada. Depois que o SO convidado é desligado e com base na operação em execução, o Compute Engine faz uma das seguintes ações:
O Compute Engine conclui a operação de interrupção e muda o estado da instância para
TERMINATED.O Compute Engine exclui a instância e todos os recursos anexados.
TERMINATED: o Compute Engine concluiu a operação de interrupção. Os recursos anexados permanecem anexados, a menos que você os desanexe. Nesse estado, a instância permanece interrompida até que você a reinicie ou exclua. Se você solicitar a reinicialização da instância, mas o Compute Engine não puder alocar os recursos solicitados, a solicitação de reinicialização vai falhar e a instância permanecerá no estadoTERMINATED. Caso contrário, a solicitação de reinicialização será bem-sucedida e o estado da instância mudará paraPROVISIONING.REPAIRING: o Compute Engine está reparando a instância. O Compute Engine repara uma instância se ela encontrar um erro interno ou se o servidor host da instância estiver indisponível devido à manutenção. Enquanto uma instância está em reparo, acontece o seguinte:Não é possível usar a instância.
O contrato de nível de serviço (SLA) não cobre a instância.
Se o Compute Engine reparar a instância, ele vai retornar o estado da instância ao estado original antes do início da operação de reparo. Esse estado pode ser
STAGING,RUNNING,SUSPENDINGouSTOPPING. Se a instância estiver configurada para reiniciar automaticamente (automaticRestart) após a conclusão da operação de reparo, você poderá interromper a instância durante o processo de reparo. Essa ação impede que a instância seja reiniciada automaticamente após a conclusão do reparo, deixando a instância no estadoTERMINATED.SUSPENDING: o Compute Engine iniciou a operação de suspensão da instância depois que você solicitou a suspensão. Nesse estado, só é possível aguardar a conclusão da operação de suspensão.SUSPENDED: o Compute Engine concluiu a operação de suspensão. Nesse estado, é possível retomar ou excluir a instância. Se você solicitar a retomada da instância, mas o Compute Engine não puder alocar os recursos solicitados, a solicitação de retomada vai falhar e a instância vai permanecer no estadoSUSPENDED. Caso contrário, a solicitação de retomada será bem-sucedida e o estado da instância mudará paraPROVISIONING. A instância pode permanecer no estadoSUSPENDEDpor até 60 dias. Depois desse período, o Compute Engine muda o estado da instância paraTERMINATED.
Falha de hardware
Uma instância de computação pode falhar devido a interrupções inesperadas, erros de hardware ou outros problemas do sistema, mas isso é raro. O Google recomenda mitigar falhas de hardware usando volumes de armazenamento permanentes, fazendo backup dos dados com frequência e projetando o sistema para que uma única falha de instância não seja catastrófica. Para mais informações, consulte como projetar sistemas robustos.
Se uma instância falhar, o Compute Engine a reiniciará automaticamente usando o mesmo disco de inicialização, metadados e configurações de instância. Para modificar o comportamento de reinicialização automática de uma instância, consulte Definir a política de manutenção do host para uma instância de computação.
Preços
Você recebe uma cobrança por uma instância de computação da seguinte forma:
Para o uso da CPU, você recebe uma cobrança quando a instância está nos seguintes estados:
RUNNINGPENDING_STOP
Para uso de memória, você recebe cobranças quando a instância está nos seguintes estados:
RUNNINGPENDING_STOPSUSPENDINGSUSPENDED
Para recursos anexados, como discos ou endereços IP externo, você recebe cobranças até que os recursos existam, independente do estado da instância.
Para mais informações, consulte Preços de instâncias de VM.
A seguir
Para conferir o estado de uma ou mais instâncias de computação, faça o seguinte: