Google が推奨する Compute Engine 用のテレメトリー収集ソリューションである Ops エージェントを使用して、仮想マシン(VM)インスタンスから GPU の使用率や GPU メモリなどの指標を追跡できます。Ops エージェントを使用すると、次のように GPU VM を管理できます。
- 事前構成済みのダッシュボードで NVIDIA GPU フリートの状態を可視化する。
- 使用率が低い GPU を特定してワークロードを統合し、費用を最適化する。
- 傾向を見極めてスケーリングを計画し、GPU 容量の拡張や、既存 GPU のアップグレードを行うタイミングを判断する。
- NVIDIA Data Center GPU Manager(DCGM)プロファイリング指標を使用して、GPU 内のボトルネックとパフォーマンスの問題を特定する。
- リソースを自動スケーリングするようにマネージド インスタンス グループ(MIG)を設定する。
- NVIDIA GPU から指標に関するアラートを受け取る。
このドキュメントでは、Ops エージェントを使用して Linux VM で GPU をモニタリングする手順について説明します。また、Linux VM で GPU の使用状況をモニタリングする設定も可能なレポート スクリプトを、GitHub で入手することもできます。compute-gpu-monitoring モニタリング スクリプトをご覧ください。このスクリプトは積極的にはメンテナンスされません。
Windows VM での GPU のモニタリングについては、GPU パフォーマンスのモニタリング(Windows)をご覧ください。
概要
Ops エージェント(バージョン 2.38.0 以降)は、エージェントがインストールされた Linux VM の GPU 使用率と GPU メモリ使用率を自動的に追跡できます。これらの指標は、NVIDIA Management Library(NVML)から取得され、GPU を使用する任意のプロセスの GPU ごとおよびプロセスごとに追跡されます。Ops エージェントによってモニタリングされる指標を表示するには、エージェントの指標: gpu をご覧ください。
NVIDIA Data Center GPU Manager(DCGM)と Ops エージェントのインテグレーションを設定することもできます。このインテグレーションにより、Ops エージェントは GPU のハードウェア カウンタを使用して指標を追跡できます。DCGM を使用すると、GPU のデバイスレベルの指標にアクセスできます。これには、ストリーミング マルチプロセッサ(SM)のブロック使用率、SM 占有率、SM パイプ使用率、PCIe トラフィック レート、NVLink トラフィック レートが含まれます。Ops エージェントによってモニタリングされる指標を表示するには、サードパーティ アプリケーションの指標: NVIDIA の Data Center GPU Manager(DCGM)をご覧ください。
Ops エージェントを使用して GPU 指標を確認するには、次の手順に沿って操作します。
- VM ごとに、要件を満たしていることを確認します。
- VM ごとに、Ops エージェントをインストールします。
- 省略可: VM ごとに、NVIDIA の Data Center GPU Manager(DCGM)インテグレーションを設定します。
- Cloud Monitoring の指標を確認します。
制限事項
- Ops エージェントは、Container-Optimized OS を使用する VM の GPU 使用率は追跡しません。
要件
各 VM で次の要件を満たしていることを確認します。
- 各 VM に GPU が接続されている。
- 各 VM に GPU ドライバがインストールされている。
- 各 VM の Linux オペレーティング システムとバージョンが、Ops エージェントをサポートしている必要があります。Ops エージェントをサポートする Linux オペレーティング システムのリストをご覧ください。
- 各 VM への
sudoアクセス権があることを確認します。
Ops エージェントをインストールする
Ops エージェントのインストール手順は次のとおりです。
以前に
compute-gpu-monitoringモニタリング スクリプトを使用して GPU 使用率を追跡している場合は、Ops エージェントをインストールする前にサービスを無効にします。モニタリング スクリプトを無効にするには、次のコマンドを実行します。sudo systemctl --no-reload --now disable google_gpu_monitoring_agent
最新バージョンの Ops エージェントをインストールします。詳しい手順については、Ops エージェントのインストールをご覧ください。
Ops エージェントをインストールした後、Compute Engine が提供するインストール スクリプトを使用して GPU ドライバをインストールまたはアップグレードする必要がある場合は、制限事項セクションを確認します。
Compute Engine で NVML 指標を確認する
Ops エージェントが Compute Engine Linux VM インスタンスから収集した NVML 指標は、[オブザーバビリティ] タブで確認できます。
単一の VM の指標を表示するには、次の操作を行います。
Google Cloud コンソールで、[VM インスタンス] ページに移動します。
VM を選択して [詳細] ページを開きます。
[オブザーバビリティ] タブをクリックして、VM に関する情報を表示します。
[GPU] クイック フィルタを選択します。
複数の VM の指標を表示するには、次の操作を行います。
Google Cloud コンソールで、[VM インスタンス] ページに移動します。
[オブザーバビリティ] タブをクリックします。
[GPU] クイック フィルタを選択します。
省略可: NVIDIA の Data Center GPU Manager(DCGM)インテグレーションを設定する
また、Ops エージェントは、NVIDIA Data Center GPU Manager(DCGM)をインテグレーションし、ストリーミング マルチプロセッサ(SM)のブロック使用率、SM 占有率、SM パイプ使用率、PCIe トラフィック レート、NVLink トラフィック レートなどの高度な GPU 指標を収集します。
これらの高度な GPU 指標は、NVIDIA の K100 モデル、P4 モデルからは収集されません。
各 VM でこのインテグレーションを設定して使用する方法の詳細な手順については、NVIDIA Data Center GPU Manager(DCGM)をご覧ください。
Cloud Monitoring で DCGM 指標を確認する
Google Cloud コンソールで、[モニタリング] > [ダッシュボード] ページに移動します。
[サンプル ライブラリ] タブを選択します。
[フィルタ] フィールドに [NVIDIA] と入力します。[NVIDIA GPU Monitoring Overview (GCE & GKE)] ダッシュボードが表示されます。
NVIDIA の Data Center GPU Manager(DCGM)インテグレーションを設定している場合は、[NVIDIA の GPU Monitoring Advanced DCGM Metrics (GCE Only)] ダッシュボードも表示されます。
必要なダッシュボードで、[プレビュー] をクリックします。[サンプル ダッシュボードのプレビュー] ページが表示されます。
[サンプル ダッシュボードのプレビュー] ページで、[サンプル ダッシュボードをインポート] をクリックします。
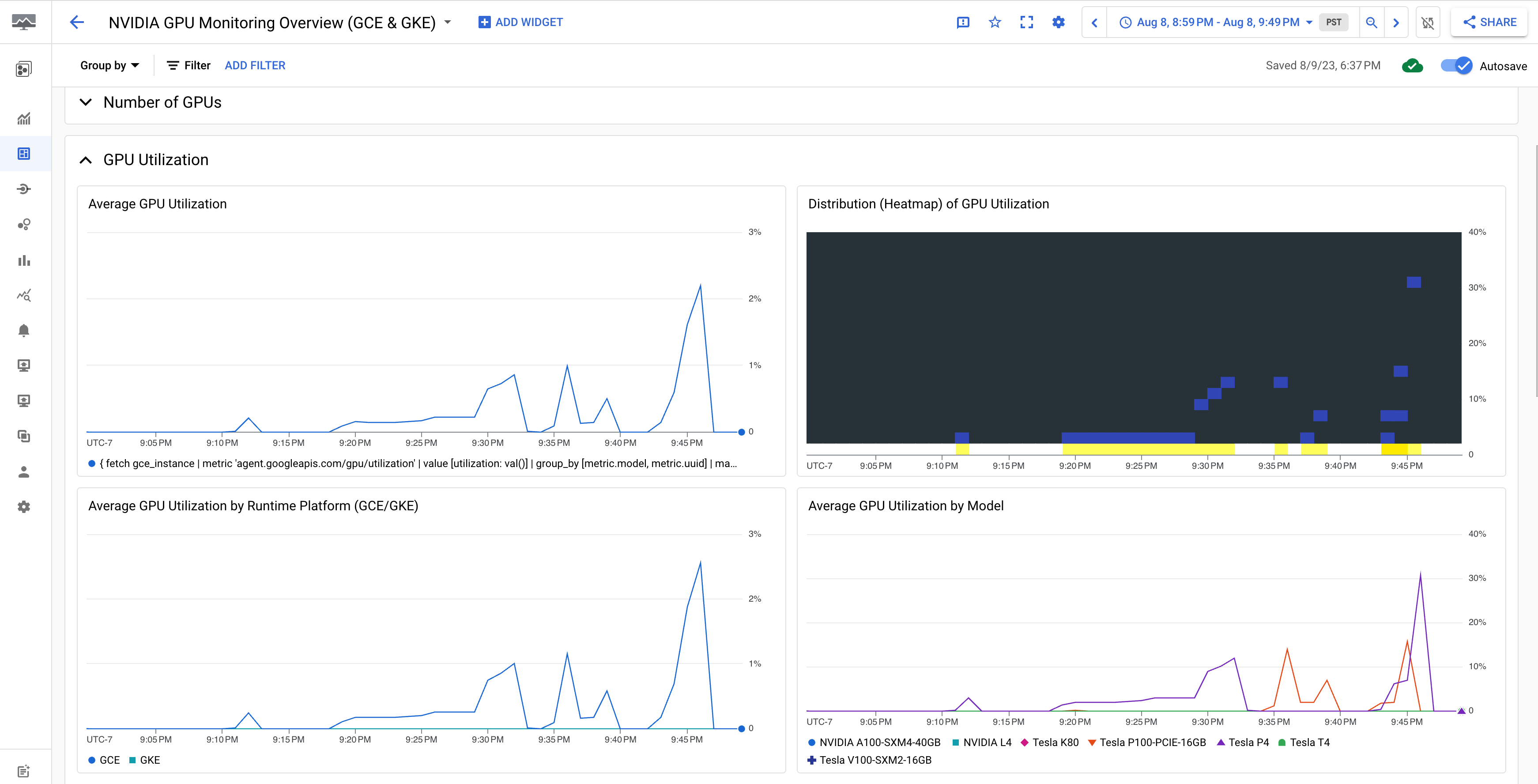
[NVIDIA GPU Monitoring Overview(GCE & GKE)] ダッシュボードには、GPU 使用率、NIC トラフィック レート、GPU メモリ使用量などの GPU 指標が表示されます。
GPU 使用率の表示は次のようになります。
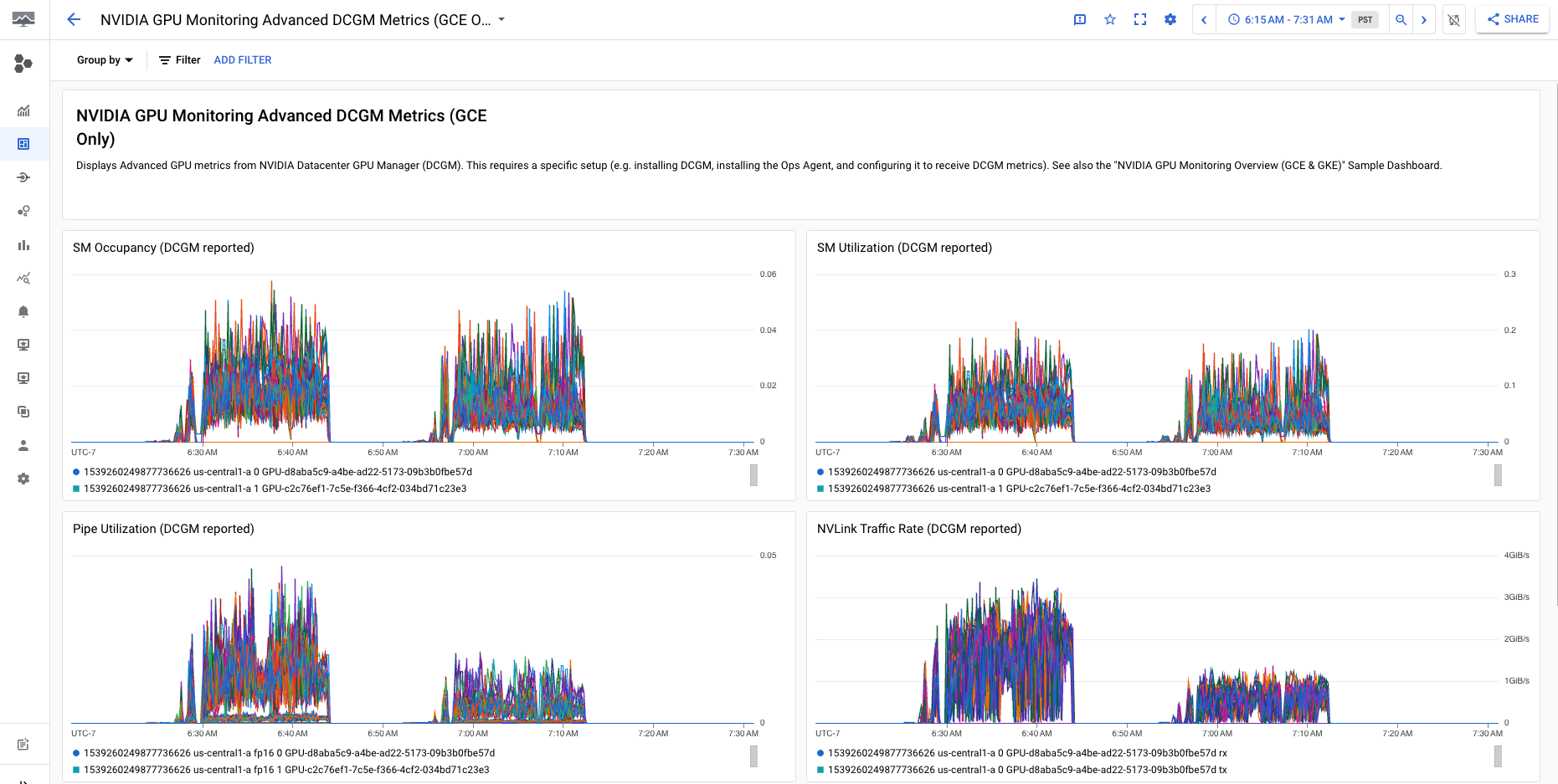
[NVIDIA GPU Monitoring Advanced DCGM Metrics (GCE Only)] ダッシュボードには、SM 使用率、SM 占有率、SM パイプ使用率、PCIe トラフィック レート、NVLink トラフィック レートなどの主要で高度な指標が表示されます。
Advanced DCGM Metric の表示は、次の出力のようになります。
次のステップ
- GPU ホスト メンテナンスを処理するには、GPU ホスト メンテナンス イベントの処理をご覧ください。
- ネットワーク パフォーマンスを改善するには、より高いネットワーク帯域幅を使用するをご覧ください。