Créer des services à haute disponibilité à l'aide de disques régionaux
Cette section explique comment créer des services à haute disponibilité avecdes disques persistants régionaux oudes disques Hyperdisk équilibrés à haute disponibilité.
Considérations de conception
Avant de commencer à concevoir un service à haute disponibilité, vous devez connaître les caractéristiques de l'application, du système de fichiers et du système d'exploitation. Ces caractéristiques constituent la base du travail de conception et peuvent vous aider à écarter certaines approches. Par exemple, si une application n'est pas compatible avec la réplication au niveau de l'application, les options de conception correspondantes deviennent alors non applicables.
De même, si l'application, le système de fichiers ou le système d'exploitation ne tolèrent pas les plantages, l'utilisationd'un disque persistant régional oud'un disque Hyperdisk équilibré à haute définition, ou même d'instantanés de disque zonaux, ne sont pas forcément des options. La tolérance aux plantages est définie comme la capacité à se remettre d'une interruption soudaine sans perdre ni corrompre les données déjà validées sur un disque avant le plantage.
Tenez compte des points suivants lorsque vous concevez pour la haute disponibilité :
- L'effet sur l'application de l'utilisation d'un disque Hyperdisk équilibré à haute disponibilité, d'un disque persistant régional ou d'autres solutions.
- Performances d'écriture sur disque.
- L'objectif de temps de récupération du service : la vitesse à laquelle votre service doit se remettre d'une panne de zone, ainsi que les exigences du contrat de niveau de service.
- Le coût de la conception d'une architecture de service résiliente et fiable.
- Pour en savoir plus sur les considérations spécifiques à la région, consultez Zones géographiques et régions.
En termes de coût, utilisez les options suivantes pour la réplication d'applications synchrone et asynchrone :
Utilisez deux instances de la base de données et de la VM. Dans ce cas, les éléments suivants déterminent le coût total :
- Coût des instances de VM
- Coûtsde disques Persistent Disk ou Hyperdisk
- Coûts liés à la gestion de la réplication des applications
Utilisez une VM unique avec des disques répliqués de manière synchrone. Pour obtenir une haute disponibilité avec un disque persistant régionalou un disque Hyperdisk équilibré à haute disponibilité, utilisez les mêmes composants d'instances de VM et de disques que l'option précédente, mais incluez également un disque répliqué de manière synchrone. Les disques persistants régionaux et les disques Hyperdisk équilibrés à haute disponibilité coûtent deux fois plus cher par octet que les disques zonaux, car ils sont répliqués dans deux zones.
Toutefois, le fait d'utiliser des disques répliqués de manière synchrone peut réduire vos coûts de maintenance, car les données sont automatiquement écrites sur deux instances répliquées sans avoir à gérer la réplication des applications.
Ne démarrez pas la VM secondaire avant que le basculement ne soit nécessaire. Pour réduire encore plus les coûts de l'hôte, démarrez la VM secondaire à la demande pendant le basculement plutôt que de la maintenir en tant que VM de secours active.
Comparer les coûts, les performances et la résilience
Le tableau suivant présente les compromis en termes de coût, de performances et de résilience pour les différentes architectures de service.
| Architecture de service à haute disponibilité |
Instantanés de disques zonaux |
Réplication synchrone au niveau de l'application |
Réplication asynchrone au niveau de l'application |
Disques régionaux |
|---|---|---|---|---|
| Protège contre les pannes d'application, de VM et de zone* | ||||
| Atténue la corruption des applications (ex. : intolérance aux plantages d'applications) | † | † | ||
| Coût | $ |
$$
|
$$
|
$1.5x - $$
|
| Performances des applications |
|
|
|
|
| Adapté aux applications ayant un RPO peu exigeant (tolérance très faible à la perte de données) |
|
|
|
|
| Délai de récupération du stockage après un sinistre# |
|
|
|
|
* L'utilisation de disques ou d'instantanés régionaux ne suffit pas à empêcher les échecs et les corruptions, ni à les atténuer. Votre application, votre système de fichiers et éventuellement d'autres composants logiciels doivent tolérer les plantages ou utiliser un processus de suspension.
† La réplication de certaines applications permet de limiter dans une certaine mesure la corruption d'applications. Par exemple, la corruption de l'application principale MySQL n'entraîne pas la corruption de ses instances de VM dupliquées. Pour en savoir plus, consultez la documentation de l'application concernée.
‡ La perte de données est la perte irréversible de données validées sur une stockage persistant. Les données non validées sont elles aussi perdues.
# Les performances de basculement n'incluent pas la vérification du système de fichiers ni la récupération et le chargement de l'application après le basculement.
Créer des services de base de données à haute disponibilité à l'aide de disques régionaux
Cette section présente les concepts de base qui vous aideront à créer des solutions à haute disponibilité pour les services de bases de données avec état (MySQL, Postgres, etc.) en utilisant Compute Engine avec desdisques persistants régionaux et des disques Hyperdisk équilibrés à haute disponibilité.
En cas de pannes importantes dans Google Cloud, par exemple si une région entière devient indisponible, votre application peut devenir indisponible. En fonction de vos besoins, envisagez d'utiliser des techniques de réplication interrégionale ou la réplication asynchrone pour obtenir une disponibilité encore plus élevée.
Les configurations de base de données à haute disponibilité comportent généralement au moins deux instances de VM. De préférence, ces instances de VM font partie d'un ou de plusieurs groupes d'instances gérés :
- Une instance de VM principale dans la zone principale
- Une instance de VM de secours dans une zone secondaire
Une instance de VM principale comporte au moins deux disques : un disque de démarrage et un disque régional. Le disque régional contient des données de base de données et toutes les autres données modifiables devant être conservées dans une autre zone en cas de panne.
Pour pouvoir se remettre d'une panne de configuration potentiellement causée par la mise à jour d'un système d'exploitation, une instance de VM de secours a besoin d'un disque de démarrage distinct. De plus, vous ne pouvez pas forcer l'association d'un disque de démarrage à une autre VM lors d'un basculement.
Les instances de VM principale et de secours sont configurées pour utiliser un équilibreur de charge. Le trafic est alors dirigé vers la VM principale en suivant les signaux émis par la vérification de l'état. Le scénario de reprise après sinistre pour les données décrit d'autres configurations de basculement qui pourraient être mieux adaptées à votre propre scénario.
Difficultés liées à la réplication des base de données
Le tableau suivant répertorie les problèmes courants liés à la configuration et à la gestion de la réplication synchrone ou semi-synchrone des applications (comme MySQL), et les compare à la réplication de disques synchrone avec ledisque persistant régional et le disque Hyperdisk équilibré à haute disponibilité.
| Défis | Réplication synchrone ou semi-synchrone des applications |
Réplication synchrone des disques |
|---|---|---|
| Maintenir une réplication stable entre l'instance dupliquée principale et l'instance dupliquée de basculement | Plusieurs problèmes peuvent survenir et empêcher l'instance de VM de rester en mode haute disponibilité :
|
Les échecs de stockage sont gérés par des disques persistants régionaux et des disques Hyperdisk équilibrés à haute disponibilité. Cela se produit de manière transparente pour l'application, à l'exception d'une éventuelle fluctuation des performances du disque. Des vérifications de l'état paramétrées par l'utilisateur doivent permettre de révéler tout problème au niveau des applications ou des VM, et de déclencher un basculement. |
| Le délai total de basculement est plus long que souhaité. | Le temps nécessaire à l'opération de basculement n'a pas de limite supérieure. Le temps nécessaire à la répétition des transactions (étape 2 ci-dessus) peut être extrêmement long selon le schéma et la charge de la base de données. | Les disques Persistent Disk régionaux et les Hyperdisk équilibrés à haute disponibilité fournissent une réplication synchrone. Le temps de basculement est donc limité par la somme des latences suivantes :
|
| Split-brain | Pour les deux approches, il est nécessaire de prendre des dispositions pour garantir la présence d'une seule instance principale à la fois afin d'éviter tout problème de split-brain. | |
Séquence d'opérations de lecture et d'écriture sur les disques
Pour déterminer les séquences de lecture/écriture, ou l'ordre dans lequel les données sont lues et écrites sur le disque, la majeure partie du travail est effectuée par le pilote de disque de votre VM. En tant qu'utilisateur, vous n'avez pas à vous soucier de la sémantique de réplication et vous pouvez interagir avec le système de fichiers comme d'habitude. Le pilote sous-jacent gère la séquence de lecture et d'écriture.
Par défaut, une VM Compute Engine avec undisque persistant régional ouun disque Hyperdisk équilibré à haute disponibilité fonctionne en mode de réplication complète, où les requêtes de lecture ou d'écriture depuis le disque sont envoyées aux deux instances répliquées.
En mode de réplication complète, voici ce qui se produit :
- Lors de l'écriture, une requête d'écriture tente d'écrire sur les deux instances répliquées et renvoie une confirmation lorsque les deux écritures réussissent.
- Lors de la lecture, la VM envoie une requête de lecture aux deux instances répliquées et renvoie les résultats de celle qui a réussi. Si la requête de lecture expire, une autre requête de lecture est envoyée.
Si une instance répliquée prend du retard ou ne parvient pas à confirmer que les requêtes de lecture ou d'écriture ont abouti, l'état de l'instance répliquée est mis à jour.
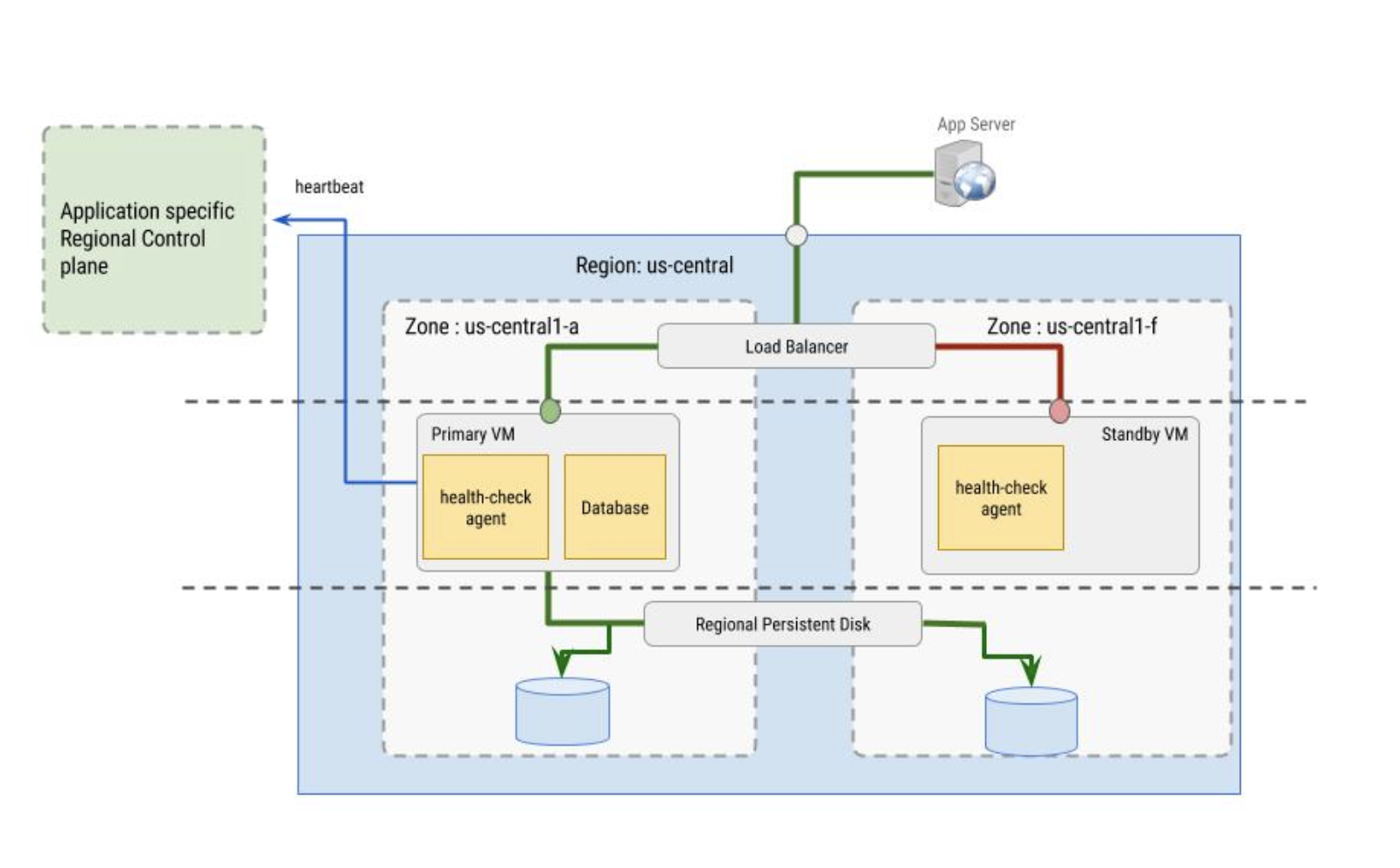
Vérifications d'état
Les vérifications de l'état utilisées par l'équilibreur de charge sont mises en œuvre par l'agent de vérification de l'état. L'agent de vérification de l'état remplit deux fonctions :
- L'agent de vérification de l'état réside dans les VM principale et secondaire. Il surveille les instances de VM et communique avec l'équilibreur de charge afin de diriger le trafic. Cela fonctionne mieux lorsqu'il est configuré avec des groupes d'instances.
- L'agent de vérification de l'état est synchronisé avec le plan de contrôle régional propre à l'application, et se base sur le comportement de ce dernier pour prendre des décisions liées au basculement. Le plan de contrôle doit se trouver dans une zone différente de l'instance de VM dont il surveille l'état.
L'agent de vérification de l'état doit être tolérant aux pannes. Dans l'image qui suit, notez par exemple que le plan de contrôle est distinct de l'instance de VM principale qui réside dans la zone us-central1-a, et de la VM de secours qui réside dans la zone us-central1-f.
Étapes suivantes
- Découvrez comment créer et gérer des disques régionaux.
- En savoir plus sur la réplication asynchrone.
- Découvrez comment configurer une instance de cluster de basculement SQL Server pour des disques en mode écriture simultanée.
- Découvrez comment créer des applications Web évolutives et résilientes sur Google Cloud.
- Consultez le Guide de planification de reprise après sinistre.