リージョン ディスクを使用した高可用性サービスの構築
このセクションでは、リージョン Persistent Disk またはHyperdisk Balanced High Availability ディスクを使用して HA サービスを構築する方法について説明します。
設計上の考慮事項
HA サービスの設計を開始する前に、アプリケーション、ファイル システム、オペレーティング システムの特性を理解しておく必要があります。これらの特性は設計の基本であり、さまざまなアプローチが排除されます。たとえば、アプリケーションレベルのレプリケーションをサポートしていないアプリケーションの場合、対応する設計オプションが適用できないことがあります。
同様に、アプリケーション、ファイル システム、またはオペレーティング システムにクラッシュに対する耐性がない場合、リージョン Persistent Disk またはHyperdisk Balanced High Availability ディスク、またはゾーンディスク スナップショットを使用できない場合があります。クラッシュに対する耐性は、クラッシュ前にディスクに保存済みのデータを消失、破損することなく、突然の終了から復旧すること、と定義されます。
高可用性の設計をする際は、次の点を考慮してください。
- Hyperdisk Balanced High Availability、リージョン Persistent Disk 、またはその他のソリューションの使用がアプリケーションに与える影響
- ディスク書き込みのパフォーマンス。
- サービスの目標復旧時間 - ゾーン停止からのサービス復旧にかけられる時間と SLA の要件。
- 復元力と信頼性の高いサービス アーキテクチャを構築するための費用。
- リージョン固有の考慮事項の詳細については、地域とリージョンをご覧ください。
費用に関しては、同期的および非同期的なアプリケーション レプリケーションのために次のオプションを使用します。
データベースと VM の 2 つのインスタンスの使用。この場合、以下の項目により費用の合計額が決定されます。
- VM インスタンスの費用
- Persistent Disk またはHyperdisk の費用
- アプリケーションのレプリケーションを維持するための費用
同期的に複製されたディスクを持つ単一の VM を使用する。リージョン Persistent Disk または Hyperdisk Balanced の高可用性ディスクで高可用性を実現するには、前のオプションと同じ VM インスタンスとディスク コンポーネントを使用するとともに、同期的に複製されたディスクも使用します。 リージョン Persistent Disk と Hyperdisk Balanced 高可用性ディスクは 2 つのゾーンで複製されるため、ゾーンディスクと比べてバイトあたりのコストが倍になります。
ただし、同期的に複製されたディスクの使用でメンテナンス費用を削減できる場合があります。これは、アプリケーションのレプリケーションを維持せずとも自動的に 2 つのレプリカにデータが書き込まれるためです。
フェイルオーバーが必要になるまで、セカンダリ VM を起動しないでください。 VM をアクティブなスタンバイ VM として維持するのではなくフェイルオーバー時にセカンダリ VM オンデマンドを起動するだけで、さらにホスト費用を削減できます。
費用、パフォーマンス、復元力の比較
次の表は、さまざまなサービス アーキテクチャの費用、パフォーマンス、復元力に関するトレードオフを示しています。
| HA サービス アーキテクチャ |
ゾーンディスク スナップショット |
アプリケーション レベル 同期 |
アプリケーション レベル 非同期 |
リージョン ディスク |
|---|---|---|---|---|
| アプリケーション、VM、ゾーン障害からの保護 * | ||||
| アプリケーションの破損の軽減(例: アプリケーションのクラッシュの耐性) | † | † | ||
| 費用 | $ |
$$
|
$$
|
$1.5x~$$
|
| アプリケーションのパフォーマンス |
|
|
|
|
| RPO 要件が低いアプリケーション向け(データ損失に対する耐性が非常に低い) |
|
|
|
|
| 障害からのストレージ復旧時間# |
|
|
|
|
*リージョン ディスクやスナップショットを使用するだけでは、障害や破損からの保護、緩和はできません。アプリケーション、ファイル システムなどのソフトウェア コンポーネントがクラッシュ整合性を持つ必要があるか、なんらかの静止を使用する必要があります。
† アプリケーションを複製することで、破損リスクが軽減されるアプリケーションもあります。たとえば、MySQL プライマリ アプリケーションが破損しても、レプリカ VM インスタンスは破損しません。詳しくは、アプリケーションのドキュメントをご覧ください。
‡ データ損失とは、永続ストレージに保存されたデータの回復不能な消失を意味します。保存されていないデータはすべて失われます。
# フェイルオーバーのパフォーマンスには、フェイルオーバー後のファイル システムのチェック、アプリケーションの復旧および読み込みは含まれません。
リージョン ディスクを使用した HA データベース サービスの構築
このセクションでは、リージョン Persistent Disk と Hyperdisk Balanced の高可用性ディスクで Compute Engine を使用して、ステートフルなデータベース サービス(MySQL、Postgres など)向けの HA ソリューションを構築する全体的なコンセプトについて説明します。
たとえば、 Google Cloudで広範囲に停止が発生した場合、リージョン全体が使用できなくなると、アプリケーションを使用できなくなる可能性があります。必要に応じて、可用性をさらに高めるためにクロスリージョン レプリケーションの手法または非同期レプリケーション を検討してください。
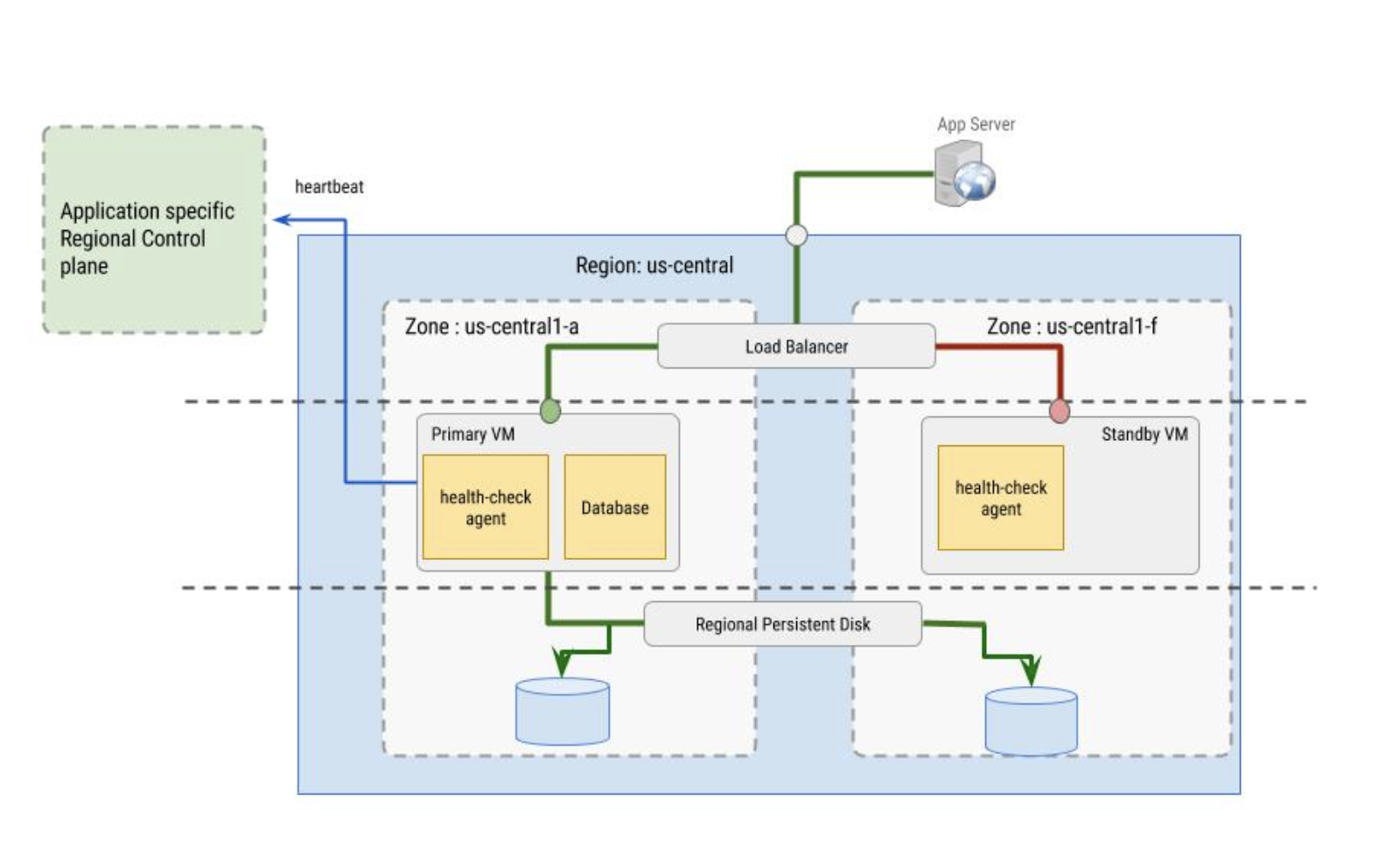
通常、データベース HA の構成には少なくとも 2 つの VM インスタンスが必要です。これらの VM インスタンスは可能であれば、以下のとおり、1 つ以上のマネージド インスタンス グループに所属するインスタンスにします。
- プライマリ ゾーン内のプライマリ VM インスタンス
- セカンダリ ゾーン内のスタンバイ VM インスタンス
プライマリ VM インスタンスには、ブートディスクとリージョン ディスクの少なくとも 2 つのディスクがあります。リージョン ディスクには、システム停止に備えて別のゾーンに保存する必要があるデータベースのデータとその他の変更可能なデータが含まれます。
スタンバイ VM インスタンスでは、オペレーティング システムのアップグレードなど、構成関連の停止から復旧するための別のブートディスクが必要です。また、フェイルオーバー中はブートディスクを別の VM に強制接続できません。
プライマリ VM インスタンスとスタンバイ VM インスタンスは、ヘルスチェック シグナルに基づいてプライマリ VM に転送されるトラフィックに対してロードバランサを使用します。データの障害復旧シナリオでは、他のフェイルオーバー構成の概要を示しています。目的のシナリオによっては、こちらの方が適している場合があります。
データベース レプリケーションの課題
次の表は、アプリケーション同期レプリケーションと準同期レプリケーション(MySQL など)の設定と管理に関する一般的な課題と、リージョン Persistent Disk と Hyperdisk Balanced の高可用性ディスクを用いた同期ディスク レプリケーションとの比較を示しています。
| 課題 | アプリケーション同期 または準同期レプリケーション |
同期ディスク レプリケーション |
|---|---|---|
| プライマリ レプリカとフェイルオーバー レプリカ間の安定したレプリケーションの維持。 | インスタンスが HA モードから外れる原因はいくつかあります。
|
ストレージ障害は、 リージョン Persistent Disk と Hyperdisk Balanced の高可用性ディスクによって処理されます。この処理は、ディスクのパフォーマンスに変動が生じる可能性を除いて、アプリケーションに対して透過的に行われます。 アプリケーションや VM の問題を特定し、フェイルオーバーをトリガーするユーザー定義のヘルスチェックが必要です。 |
| エンドツーエンドのフェイルオーバー時間が必要以上に長い。 | フェイルオーバー オペレーションにかかる時間に上限はありません。すべてのトランザクションがリプレイされる(上記ステップ 2)まで待機すると、スキーマとデータベースの負荷によっては相当な時間がかかる可能性があります。 | リージョン Persistent Disk と Hyperdisk Balanced 高可用性ディスクは同期レプリケーションを提供するため、フェイルオーバー時間は以下のレイテンシの合計時間に制限されます。
|
| スプリット ブレイン | スプリット ブレインを回避するには、どちらの手法でも、プライマリが 1 度に 1 つしか存在しないようにするためのプロビジョニングが必要となります。 | |
ディスクに対する読み取り / 書き込みオペレーションのシーケンス
読み取りと書き込みシーケンス、つまりデータがディスクに読み書きされる順序を決定する際に、作業の大部分は VM 内のディスク ドライバによって行われます。ユーザーはレプリケーションのセマンティクスを処理する必要はなく、通常どおりファイル システムを操作できます。基盤ドライバが読み取りと書き込みのシーケンスを処理します。
デフォルトでは、リージョン Persistent Disk またはHyperdisk Balanced High Availability を使用する Compute Engine VM は完全レプリケーション モードで動作します。このモードでは、ディスクからの読み取りまたは書き込みのリクエストが両方のレプリカに送信されます。
完全レプリケーション モードでは、次の処理が発生します。
- 書き込み時、書き込みリクエストは両方のレプリカへの書き込みを試行し、両方の書き込みが成功したことを確認します。
- 読み取り時、VM は両方のレプリカに読み取りリクエストを送信し、成功したレプリカからの結果を返します。読み取りリクエストがタイムアウトすると、別の読み取りリクエストが送信されます。
レプリカが処理に遅れ、読み取りまたは書き込みリクエストの完了の確認応答に失敗した場合、レプリカの状態が更新されます。
ヘルスチェック
ロードバランサによって使用されるヘルスチェックは、ヘルスチェック エージェントによって実装されます。ヘルスチェック エージェントは、次の 2 つの目的で使用します。
- ヘルスチェック エージェントは、プライマリ VM とセカンダリ VM 内に置かれ、VM インスタンスをモニタリングし、ロードバランサと通信してトラフィックを誘導します。この方法は、インスタンス グループを使用して構成すると最適に機能します。
- ヘルスチェック エージェントは、アプリケーション固有のリージョンのコントロール プレーンと同期し、コントロール プレーンの動作に基づいてフェイルオーバーを決定します。コントロール プレーンは、稼働状況をモニタリングされている VM インスタンスとは異なるゾーンにある必要があります。
ヘルスチェック エージェント自体はフォールト トレラントである必要があります。たとえば下の図では、ゾーン us-central1-a にあるプライマリ VM インスタンスからコントロール プレーンは分離されていて、スタンバイ VM もゾーン us-central1-f にあります。
次のステップ
- リージョン ディスクの作成と管理の方法を確認する。
- 非同期レプリケーションの詳細を確認する。
- マルチライター モードのディスク用に SQL Server フェイルオーバー クラスタ インスタンスを構成する方法を確認する。
- Google Cloudでスケーラブルで復元性の高いウェブ アプリケーションを構築する方法の詳細を知る。
- 障害復旧計画ガイドを確認する。