Persistent Disk ボリュームまたは Google Cloud Hyperdisk ボリュームの健全性を確認するには、ディスク パフォーマンス ステータスの指標を確認します。この指標は、ディスク パフォーマンスが Compute Engine 内の有害なイベントの影響を受けている可能性があるかどうかを示します。
ディスク パフォーマンス ステータスに影響する問題は、プロジェクトの Personal Service Health(PSH)ダッシュボードまたは Google Cloud Service Health ダッシュボードにも表示される場合があります。
このドキュメントでは、ディスク パフォーマンス ステータスと、この指標をパフォーマンスの問題のトラブルシューティングに使用する方法について説明します。
ディスクの健全性を確認するタイミング
ディスクのパフォーマンスの問題に気付いた場合は、ディスク パフォーマンス ステータスの指標を参照してディスクの健全性を確認します。ディスク パフォーマンス ステータスの指標は毎分更新され、直前の 1 分間のディスク パフォーマンスを表します。ディスクの健全性を確認する手順については、ディスク パフォーマンス ステータスを表示するをご覧ください。
次の表に、ディスク パフォーマンス ステータスの有効な値を示します。
| ステータス | 意味 |
|---|---|
Healthy |
ディスク パフォーマンスは想定どおりです。 |
Degraded |
一時的に I/O レイテンシが想定よりも高くなる可能性があります。 |
Severely degraded |
I/O レイテンシが高いか、その他のエラーが発生しています。 |
パフォーマンス ステータスが Healthy でない場合は、各ステータスの意味を参照して次のステップに進みます。
パフォーマンス ステータスが Healthy の場合、ディスクは正常に動作しています。パフォーマンスの問題を引き起こしている他の原因を調べる必要があります。アプリケーションまたはオペレーティング システムのエラーがないか確認し、ディスクを正しく最適化してください。最適化のガイドラインについては、Hyperdisk を最適化すると Persistent Disk を最適化するをご覧ください。
ディスクの健全性と他のディスク パフォーマンス指標の関係
パフォーマンス ステータスの指標で示されるディスクの健全性は、Google の視点から見たディスクの内部ステータスを示します。ディスクのステータスが Degraded または Severely Degraded の場合、根本原因は常に Compute Engine インフラストラクチャ内にあります。
通常は、ワークロードを修正しても、ディスクの健全性を変化させることはできません。ただし、まれにワークロードの変更が原因で内部的な問題が生じることがあります。その場合は、ワークロードを修正することで問題を軽減できる可能性があります。
使用可能な他のディスク パフォーマンス指標については、ディスク パフォーマンス指標を確認するをご覧ください。
ディスク パフォーマンス ステータスに影響しないシナリオ
ディスク パフォーマンス ステータスは、次の要因で生じるパフォーマンスの問題とは無関係です。
- ディスク最適化が不完全または不十分
- ディスクやマシンタイプに関連付けられたパフォーマンスの上限(選択したマシンタイプがワークロードのパフォーマンス要件を満たせない場合)
- ワークロード トラフィックによるディスクの負荷の増加
- ユーザー、アプリケーション、またはオペレーティング システムのエラー
- ディスクの空き容量不足または破損
- Hyperdisk または Extreme Persistent Disk ボリュームで、IOPS またはスループットが十分にプロビジョニングされていない
このような状況では、お客様の側で、ディスクの最適化、ワークロードのスケールアップ、マシンタイプの変更、容量 / IOPS / スループットの追加プロビジョニングなどによってパフォーマンスを改善する必要があります。
Cloud Monitoring でディスクの健全性を表示する
ディスクの健全性を表示するには、Metrics Explorer でグラフを作成します。
必要なロールと権限
ディスク パフォーマンス ステータスの指標を確認するために必要な権限を取得するには、プロジェクトに対する次の IAM ロールを付与するように管理者に依頼してください。
ロールの付与については、プロジェクト、フォルダ、組織に対するアクセス権の管理をご覧ください。
必要な権限は、カスタムロールや他の事前定義ロールから取得することもできます。
Metrics Explorer でグラフを作成する
グラフを作成するには、メニュードリブン インターフェースまたは PromQL を使用してクエリを作成します。
メニュー形式インターフェース
1 つ以上のディスクの健全性をグラフで表示する手順は次のとおりです。
-
Google Cloud コンソールで、leaderboard [Metrics Explorer] のページに移動します。
検索バーを使用してこのページを検索する場合は、小見出しが [Monitoring] である結果を選択します。
- Google Cloud コンソールのツールバーで、 Google Cloud プロジェクトを選択します。App Hub の構成には、App Hub ホスト プロジェクトまたはアプリ対応フォルダの管理プロジェクトを選択します。
- [指標] 要素の [指標を選択] メニューを開いてフィルタバーに「
VM Instance」と入力し、サブメニューを使用して特定のリソースタイプと指標を選択します。- [有効なリソース] メニューで、[VM インスタンス] を選択します。
- [有効な指標カテゴリ] メニューで、[Instance] を選択します。
- [有効な指標] メニューで、[Disk performance status] を選択します。
- [適用] をクリックします。
compute.googleapis.com/instance/disk/performance_statusです。 クエリ結果から時系列を削除するフィルタを追加するには、[フィルタ] 要素を使用します。
- データの表示方法を構成します。
集計を無効にします。[集計] 要素で、最初のメニューが [未集計] に、2 つ目のメニューが [なし] に設定されていることを確認します。
特定のディスクの健全性を表示するには、device_nameでフィルタします。
グラフの構成の詳細については、Metrics Explorer 使用時の指標の選択をご覧ください。
PromQL
クエリエディタを開く: PromQL クエリを作成するの手順に沿って操作します。
クエリエディタにクエリを入力します。たとえば、特定のディスクのパフォーマンス ステータスを表示するには、次のクエリを入力します。
last_over_time
(compute_googleapis_com:instance_disk_performance_status
{monitored_resource="gce_instance",
project_id ="PROJECT_ID",
device_name="DISK_NAME"}[${__interval}])
DISK_NAME は、ディスク名に置き換えます(例: disk-1)。
結果をグラフで表示すると、ディスクごとに 3 本の線(考えられるステータスごとに 1 本ずつ)が表示されます。同様に、クエリ結果をテーブルで表示すると、ディスクごとに 3 つの行がテーブルに表示されます。
PromQL を使ってクエリを作成した場合、各行の値は 1 または 0 になります。メニューを使って作成されたクエリの場合、値は 100% または 0 になります。
現時点で正常なディスクは、値が 100% または 1 である線と行によって表されます。
たとえば、次のスクリーンショットは、ステータスが Healthy である a-test-VM という名前のディスクのグラフを示しています。
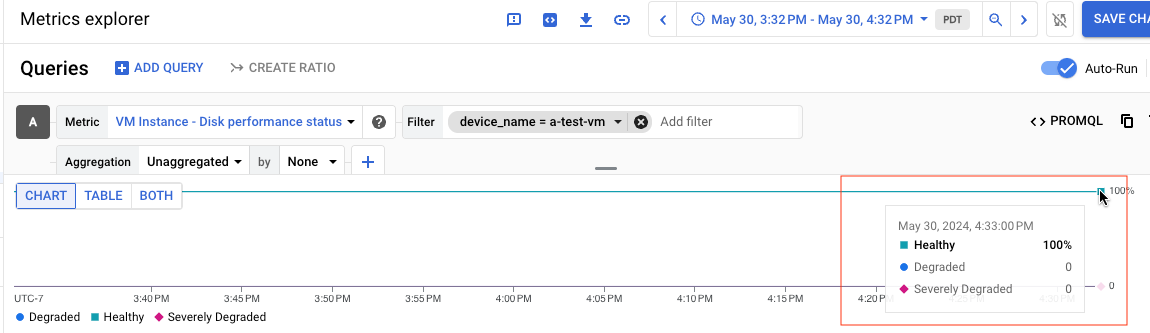
クエリ結果をテーブルとして表示する場合、Healthy のディスクの結果は次の例のようになります。
| performance_status | value |
|---|---|
Healthy |
1 |
Degraded |
0 |
Severely Degraded |
0 |
次のスクリーンショットは、ステータスが Degraded である replica-23509 という名前のディスクのグラフを示しています。
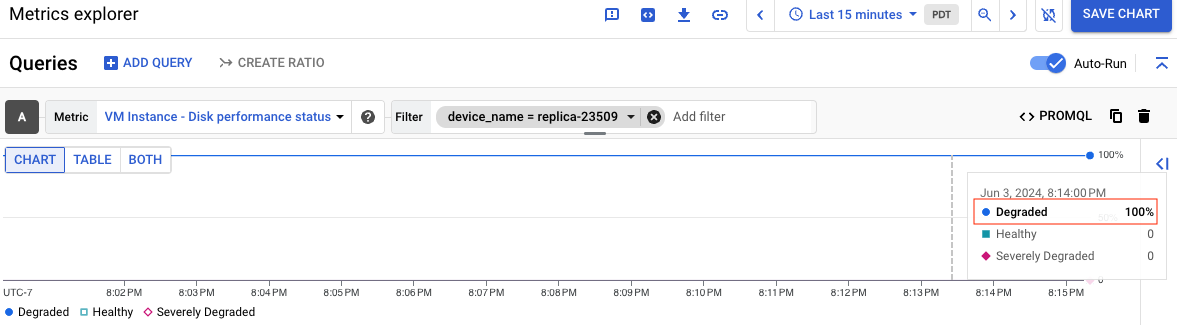
各パフォーマンス ステータスの意味については、各ステータスの意味をご覧ください。グラフを作成した後は、後で使用できるようにダッシュボードに保存できます。
小数値の結果
次のテーブルのようにクエリに小数値の結果が含まれている場合、通常は選択した表示期間が長かったことが原因です。その結果、時間の経過とともに変化したデータが Cloud Monitoring によって集約されました。Healthy ステータスの値が 77% の場合は、選択した表示期間の 77% でディスクのステータスが Healthy だったことを意味します。
| performance_status | value |
|---|---|
Healthy |
77% |
Degraded |
23% |
Severely Degraded |
0 |
ディスクの健全性をより細かく表示するには、表示期間を数時間または数分に設定します。
各ステータスの意味
このセクションでは、各ステータスの意味と、追加の対応が必要になる場合について説明します。
Healthy
Healthy ステータスは、Google から見てディスクが正常に動作していることを示します。
Healthy であるディスクにパフォーマンスの問題がある場合は、サポートへの問い合わせをご遠慮ください。代わりに、下記の提案に基づいてディスクのトラブルシューティングを行ってください。
- レイテンシやキューの深さといったディスク パフォーマンス指標を確認します。
- ワークロードのログと指標を参照して、異常やボトルネックが発生していないか確認します。
- Persistent Disk を使用している場合は、プロビジョニングされた容量がディスクのパフォーマンス要件を満たしていることを確認します。Hyperdisk ボリュームまたは Extreme Persistent Disk ボリュームを使用している場合は、十分な IOPS とスループットがプロビジョニングされていることを確認します。
- ガイドラインに沿ってディスクが最適化されていることを確認します。詳細については、Hyperdisk を最適化すると Persistent Disk を最適化するをご覧ください。
Degraded
ディスクのステータスが Degraded の場合、通常はサポートにお問い合わせいただく必要はありません。Degraded status は通常、Compute Engine インフラストラクチャの正常な内部メンテナンスによって発生します。
ステータスが Degraded の間は、ディスクのパフォーマンスへの影響は気付かない程度にとどまる可能性があります。パフォーマンスの問題と Degraded ステータスが時間的に関連している場合も、パフォーマンスの問題が Degraded ステータスと無関係な可能性があります。
まれなケースとしてパフォーマンスの問題が Degraded ステータスによって生じたとしても、影響は一時的です。ディスクのステータスは数分以内に Healthy に戻ります。
ディスクにパフォーマンスの問題がない場合は、Degraded ステータスを無視してかまいません。
パフォーマンスの問題が発生した場合の対処方法
ディスクのパフォーマンス ステータスが Degraded で、パフォーマンスの問題が発生している場合は、次の操作を行います。
- PSH ダッシュボードで、ディスクに影響するインシデントが表示されるかどうかを確認します。インシデントが表示される場合は、Google がその既知の問題の解決に取り組んでいるため、サポートへのお問い合わせをご遠慮ください。
- 既知の問題が表示されない場合は、パフォーマンスの問題が自然に解決されるまで 5 分以上お待ちください。
5 分が経過してもパフォーマンスの問題が解決されず、ステータスが
Degradedのままである場合は、ディスクの最適化が不十分なためにパフォーマンスの問題が発生していないことを確認します。たとえば、ディスクのレイテンシとキューの深さを確認します。パフォーマンスの問題とDegradedステータスは無関係で、偶然にタイミングが一致しただけの可能性もあります。詳細については、ディスクの指標とパフォーマンスの最適化に関するガイドラインを確認してください。パフォーマンスの問題が解決せず、以下の条件がすべて満たされている場合は、サポートにお問い合わせください。
- ディスクのステータスが 5 分以上
Degradedになっている - ディスクを最適化し、ボトルネックやアプリケーションの過負荷などの他の問題がないことを確認したため、ワークロードの問題ではないという相応の確信がある
- PSH ダッシュボードにアラートが表示されない
- ディスクのステータスが 5 分以上
Degraded ステータスを直接の対象としたアラートを作成することはおすすめしません。代わりに、より上位のアプリケーション ステータスに対するアラートを作成し、この指標を使用して問題をデバッグすることをおすすめします。
Severely Degraded
パフォーマンス ステータスが Severely Degraded であるディスクにはパフォーマンスの問題があります。この問題はインシデントまたはエラーが原因で発生する場合があり、PSH ダッシュボードまたは Google Cloud Service Health ダッシュボードにすでに表示されている可能性があります。
必要なご対応
ディスクのパフォーマンス ステータスが Severely Degraded の場合は、次の操作を行います。
- PSH ダッシュボードと一般的な Google Cloud ヘルス ダッシュボードで、ディスクに影響を与えているインシデントが表示されないか確認します。インシデントが表示される場合は、Google がその既知の問題の解決に取り組んでいるため、サポートへのお問い合わせをご遠慮ください。
- どちらのダッシュボードにも既知の問題が表示されない場合は、サポートにお問い合わせください。
ディシジョン ツリー
次の図は、これまでのセクションの情報に基づき、ディスクにパフォーマンスの問題がある場合に行うべき手順を示しています。

フローチャートで示されているように、サポートへの問い合わせが必要となるのは、ディスクのステータスが Severely Degraded であり、PSH と Cloud サービスのダッシュボードに既知のアラートが表示されない場合のみです。ディスクが Degraded の場合は、次の条件がすべて満たされている場合にのみ、サポートにお問い合わせください。
- ディスクが 5 分以上
Degradedになっている - ワークロードのエラーや構成ミス(ネットワークの問題など)の可能性を除外した
- アプリケーション、ワークロード、またはディスクのレベルで追加の最適化を実行できない
- ディスクのすべての指標を確認した
- ワークロードと仮想マシン(VM)のログを確認した
次のステップ
- Metrics Explorer でグラフを作成する方法と、グラフにフィルタを追加してクエリ結果を絞り込む方法の詳細を確認する。
- Personal Service Health ダッシュボードと Google Service Health で、進行中および過去のサービスヘルス イベントを確認する。
- パフォーマンスの最適化のガイドラインについて、Hyperdisk を最適化すると Persistent Disk を最適化するを参照する。