Penskalaan otomatis akan otomatis menambahkan VM (menyebarkan skala) atau menghapus VM (menurunkan skala) grup instance terkelola (MIG). Dokumen ini menjelaskan cara autoscaler menentukan waktu untuk menskalakan MIG Anda.
Cara autoscaler menghitung ukuran yang direkomendasikan dan memengaruhi ukuran target
Saat Anda mengonfigurasi autoscaler untuk MIG, autoscaler secara konstan memantau grup dan menetapkan ukuran yang direkomendasikan untuk grup ke jumlah instance virtual machine (VM) yang diperlukan untuk menyalurkan beban puncak selama periode stabilisasi.
Ukuran yang direkomendasikan dibatasi oleh jumlah instance minimum dan maksimum yang Anda tetapkan dalam kebijakan penskalaan otomatis.
Jika kebijakan penskalaan otomatis Anda mencakup kontrol penurunan skala, ukuran yang direkomendasikan akan dibatasi lebih lanjut oleh kontrol penurunan skala.
Jika Anda mengaktifkan penskalaan otomatis prediktif, autoscaler akan menggunakan histori pola pemakaian CPU untuk memperkirakan beban di masa mendatang, dan akan menetapkan ukuran yang direkomendasikan grup berdasarkan prediksinya.
Respons MIG terhadap ukuran yang direkomendasikan autoscaler bergantung pada cara Anda mengonfigurasi mode autoscaler:
ON. MIG menetapkan ukuran targetnya ke ukuran yang direkomendasikan, lalu Compute Engine secara otomatis menyebarkan skala MIG untuk memenuhi ukuran targetnya.ONLY_SCALE_OUT. Ukuran target MIG hanya dapat ditingkatkan sebagai respons terhadap peningkatan ukuran yang direkomendasikan.OFF. Ukuran target tidak terpengaruh oleh ukuran yang direkomendasikan. Namun, ukuran yang direkomendasikan tetap dihitung.
Jika konfigurasi autoscaler dihapus, tidak ada ukuran yang direkomendasikan yang akan dihitung.
Kesenjangan antara metrik pemakaian target dan pemakaian aktual
Saat menggunakan kebijakan penskalaan otomatis dengan sinyal berbasis metrik, Anda mungkin melihat bahwa, untuk grup instance yang lebih kecil, pemakaian aktual dari grup instance dan pemakaian target mungkin tampak berselisih jauh. Hal ini karena autoscaler selalu bertindak secara konservatif dengan membulatkan ke atas atau ke bawah saat menafsirkan data pemakaian dan menentukan jumlah instance yang akan ditambahkan atau dihapus. Hal ini mencegah autoscaler menambahkan jumlah resource yang tidak memadai atau menghapus terlalu banyak resource.
Misalnya, jika Anda menetapkan target pemakaian sebesar 0,7 dan aplikasi melebihi target pemakaian, autoscaler mungkin menentukan bahwa menambahkan 1,5 instance virtual machine (VM) akan mengurangi pemakaian hingga mendekati 0,7. Karena Anda tidak dapat menambahkan 1,5 instance VM, autoscaler akan membulatkan ke atas dan menambahkan dua instance. Hal ini dapat mengurangi rata-rata pemakaian CPU ke nilai di bawah 0,7, tetapi memastikan bahwa aplikasi Anda memiliki cukup resource untuk mendukungnya.
Demikian pula, jika autoscaler menentukan bahwa penghapusan 1,5 instance VM akan meningkatkan pemakaian Anda hingga terlalu mendekati 0,7, sehingga hanya akan menghapus satu instance.
Untuk grup yang lebih besar dengan lebih banyak instance VM, pemakaiannya dibagi berdasarkan jumlah instance yang lebih besar, dan penambahan atau penghapusan instance VM akan mengurangi kesenjangan antara pemakaian aktual dan pemakaian target.
Jika Anda menggunakan penskalaan otomatis berbasis jadwal dengan sinyal penskalaan otomatis lain, jadwal aktif mungkin memerlukan lebih banyak VM daripada kebutuhan pemakaian Anda. Dalam situasi ini, pemakaian aktual Anda lebih rendah daripada pemakaian target karena jadwal penskalaan otomatis menentukan ukuran grup instance yang direkomendasikan.
Penundaan dalam penyebaran skala
Saat mengonfigurasi penskalaan otomatis, Anda menentukan periode inisialisasi yang mencerminkan durasi waktu yang diperlukan VM untuk melakukan inisialisasi. Autoscaler hanya merekomendasikan penyebaran skala jika pemakaian rata-rata dari instance yang tidak melakukan inisialisasi lebih besar dari pemakaian target.
Jika Anda menetapkan nilai periode inisialisasi yang secara signifikan lebih lama daripada waktu yang diperlukan suatu instance untuk diinisialisasi, autoscaler mungkin akan mengabaikan data pemakaian yang sah, dan mungkin meremehkan ukuran grup yang diperlukan.
Penundaan dalam penurunan skala
Untuk tujuan penurunan skala, autoscaler akan menghitung ukuran target grup yang direkomendasikan berdasarkan beban puncak selama 10 menit terakhir atau selama periode inisialisasi yang Anda tetapkan, yang lebih dari 10 menit. Durasi ini disebut sebagai periode stabilisasi.
Mengamati pemakaian selama periode stabilisasi akan membantu autoscaler:
- Pastikan informasi pemakaian yang dikumpulkan dari grup instance stabil.
- Cegah perilaku saat autoscaler terus menambahkan atau menghapus instance dengan kecepatan yang berlebihan.
- Hapus instance secara aman dengan menentukan bahwa ukuran grup yang lebih kecil sudah cukup untuk mendukung beban puncak dari periode stabilisasi.
- Jika aplikasi Anda memerlukan waktu lebih dari 10 menit untuk diinisialisasi di VM baru, grup akan menggunakan periode inisialisasi sebagai periode stabilisasi. Tindakan ini memastikan bahwa keputusan autoscaler untuk menghapus VM memperhitungkan waktu yang diperlukan untuk mendapatkan kembali kapasitas penyaluran.
Periode stabilisasi mungkin muncul sebagai penundaan dalam penurunan skala, tetapi sebenarnya ini adalah fitur bawaan dari penskalaan otomatis. Periode stabilisasi juga memastikan bahwa jika instance baru ditambahkan ke grup instance terkelola, instance akan menyelesaikan periode inisialisasi atau berjalan setidaknya selama 10 menit sebelum memenuhi syarat untuk dihapus.
Periode inisialisasi untuk instance baru akan diabaikan saat memutuskan apakah akan melakukan penurunan skala dalam grup atau tidak.
Pengosongan koneksi yang menyebabkan penundaan
Jika grup adalah bagian dari layanan backend yang telah mengaktifkan pengosongan koneksi, diperlukan waktu tambahan hingga 60 detik setelah durasi pengosongan koneksi berlalu sebelum instance VM dihapus.
Kontrol penurunan skala
Saat mengonfigurasi kontrol penurunan skala autoscaler, Anda mengontrol kecepatan penurunan skala. Autoscaler tidak pernah menurunkan skala lebih cepat daripada laju yang Anda konfigurasi:

- Saat beban menurun, autoscaler mempertahankan ukuran untuk grup pada tingkat yang diperlukan untuk menyalurkan beban puncak yang diamati dalam (periode stabilisasi). Ini berfungsi sama dengan dan tanpa kontrol penurunan skala.
- Autoscaler tanpa kontrol penurunan skala hanya mempertahankan cukup instance yang diperlukan untuk menangani beban yang baru diamati. Setelah periode stabilisasi, autoscaler akan menghapus semua instance yang tidak diperlukan dalam satu langkah. Dengan penurunan beban yang tiba-tiba, hal ini dapat menyebabkan penurunan ukuran grup instance secara drastis.
- Autoscaler dengan kontrol penurunan skala membatasi jumlah instance VM yang dapat dihapus dalam jangka waktu yang telah dikonfigurasi (di sini, 10 VM dalam waktu 20 menit). Tindakan ini memperlambat laju pengurangan instance.
- Dengan lonjakan beban baru, autoscaler menambahkan instance baru untuk menangani beban. Namun, karena waktu inisialisasi yang lama, VM baru belum siap menyalurkan beban. Dengan kontrol penurunan skala, kapasitas sebelumnya dipertahankan, sehingga VM yang ada dapat menyalurkan lonjakan.
Anda mengontrol laju penurunan skala dengan mengonfigurasi pengurangan maksimum yang diizinkan untuk Autoscaler selama periode waktu tambahan, khususnya:
- Pengurangan maksimum yang diizinkan (
maxScaledInReplicas: jumlah atau % instance VM). Jumlah instance yang dapat hilang dari workload Anda (dari ukuran puncak grup) dalam periode waktu tambahan yang ditentukan. Gunakan parameter ini untuk membatasi seberapa banyak grup yang dapat diskalakan turun agar Anda masih dapat menyalurkan kemungkinan lonjakan beban sampai lebih banyak instance mulai menyalurkan. Makin rendah pengurangan maksimum yang diizinkan, makin lambat laju penurunan skala. - Periode waktu tambahan (
timeWindowSec: detik). Waktu saat lonjakan beban cenderung mengikuti penurunan sementara dan saat Anda tidak ingin ukuran grup diskalakan turun melebihi pengurangan maksimum yang diizinkan. Gunakan parameter ini untuk menentukan jangka waktu saat autoscaler akan mencari ukuran puncak yang cukup untuk menyalurkan beban historis. Autoscaler tidak akan mengubah ukuran di bawah pengurangan maksimum yang diizinkan yang dikurangi dari ukuran puncak yang diamati pada periode waktu tambahan. Dengan periode waktu tambahan yang lebih lama, autoscaler akan mempertimbangkan lebih banyak beban puncak historis, sehingga penurunan skala menjadi lebih konservatif dan stabil.
Saat Anda menetapkan kontrol penurunan skala, autoscaler akan membatasi operasi penurunan skala hingga ke pengurangan maksimum yang diizinkan dari ukuran puncak yang diamati pada periode waktu tambahan. Autoscaler menggunakan langkah-langkah berikut:
- Terus memantau ukuran puncak historis yang teramati pada periode waktu tambahan.
- Menggunakan pengurangan maksimum yang diizinkan untuk menghitung ukuran penurunan skala yang dibatasi (ukuran puncak:
maxScaledInReplicas) - Menetapkan ukuran yang direkomendasikan grup ke ukuran penurunan skala yang dibatasi. Misalnya, jika autoscaler akan mengubah ukuran grup instance menjadi 20 VM tetapi batasan penurunan skala hanya mengizinkan penurunan skala hingga 40 VM, ukuran yang direkomendasikan akan ditetapkan ke 40 VM.
Dengan kontrol penurunan skala, autoscaler terus memantau ukuran puncak grup instance dalam jangka waktu tambahan yang dikonfigurasi untuk mengidentifikasi ukuran yang memadai untuk menyalurkan beban historis. Autoscaler tidak menurunkan skala melebihi pengurangan maksimum yang diizinkan yang diukur dari ukuran puncak yang diamati:

Misalnya, pada diagram di atas, kontrol penurunan skala dikonfigurasi untuk pengurangan maksimum yang diizinkan sebesar 20 VM dalam periode waktu tambahan 30 menit:
- Saat beban turun, autoscaler akan menghapus 20 VM, yang merupakan pengurangan maksimum yang diizinkan yang dikonfigurasi dalam kontrol penurunan skala.
- Seiring kenaikan dan penurunan beban, autoscaler terus-menerus memantau periode waktu tambahan 30 menit terakhir agar ukuran puncak yang cukup dapat menyalurkan beban historis. Ukuran puncak ini digunakan sebagai dasar bagi kontrol penurunan skala untuk membatasi laju penurunan skala. Jika, dalam 30 menit terakhir, ukuran puncak adalah 70 VM dan pengurangan maksimum yang diizinkan ditetapkan di angka 20 VM, autoscaler dapat menurunkan skala menjadi 50 VM. Jika ukurannya saat ini adalah 65 VM, autoscaler hanya dapat menghapus 15 VM.
- Saat beban berkurang, autoscaler akan terus menghapus instance VM, tetapi membatasi lajunya hingga maksimal 20 VM dari ukuran grup instance puncak yang diukur dalam 30 menit terakhir.
Pengurangan ukuran grup maksimum yang diizinkan dapat terjadi sekaligus, sehingga Anda harus mengonfigurasi pengurangan maksimum yang diizinkan agar aplikasi dapat kehilangan instance sebanyak itu sekaligus. Gunakan parameter pengurangan maksimum yang diizinkan untuk menunjukkan seberapa besar pengurangan kapasitas penyaluran yang dapat ditoleransi oleh aplikasi Anda.
Dengan membatasi jumlah instance VM yang dapat dihapus oleh penskalaan otomatis dan dengan menambah periode waktu tambahan yang diamati, aplikasi dengan lonjakan beban dan waktu inisialisasi yang panjang akan mengalami peningkatan ketersediaan. Secara khusus, ukuran grup instance tidak turun secara tiba-tiba sebagai respons terhadap penurunan beban yang signifikan, melainkan menurun secara bertahap dari waktu ke waktu. Jika lonjakan beban terjadi segera setelah penskalaan turun, jumlah VM yang tersisa masih dapat menyerap lonjakan tersebut dalam toleransi Anda. Selain itu, VM yang lebih sedikit harus dimulai agar dapat melayani lonjakan secara memadai.
Anda dapat mengonfigurasi kontrol penskalaan turun untuk penskalaan otomatis MIG zona maupun regional. Konfigurasi tersebut sama untuk kedua kasus. Kontrol penskalaan turun berfungsi untuk semua ukuran grup.
Kontrol penurunan skala versus stabilisasi autoscaler
Mengonfigurasi kontrol penskalaan turun tidak berarti menonaktifkan mekanisme stabilisasi bawaan autoscaler. Autoscaler selalu mempertahankan ukuran grup instance pada tingkat yang diperlukan untuk menyalurkan beban puncak, yang diamati selama periode stabilisasi. Kontrol penskalaan turun memberi Anda mekanisme tambahan untuk mengontrol laju saat ukuran grup instance diubah.
| Autoscaler bawaan: Periode stabilisasi |
Kontrol penskalaan turun: Periode waktu tambahan |
|
|---|---|---|
| Dapat dikonfigurasi? | Tidak, tidak dapat dikonfigurasi | Ya, dapat dikonfigurasi |
| Apa yang dipantau? | Memantau beban puncak selama 10 menit sebelumnya atau periode inisialisasi, mana saja yang lebih lama. | Memantau ukuran puncak grup instance dalam periode sebelumnya yang ditetapkan oleh periode waktu tambahan |
| Bagaimana cara ini membantu? | Memastikan bahwa ukuran grup instance tetap memadai untuk menyalurkan beban puncak yang diamati selama 10 menit terakhir atau periode inisialisasi, mana saja yang lebih lama. | Memastikan bahwa ukuran grup instance tidak dikurangi oleh lebih banyak instance VM daripada yang dapat ditoleransi oleh workload Anda saat menangani lonjakan beban selama jangka waktu yang ditentukan. |
Kontrol penurunan skala dengan mode autoscaler
Ada dua skenario serupa yang sedikit berbeda saat MIG Anda tidak diskalakan otomatis dan Anda ingin mengaktifkan penskalaan otomatis. Hal ini bergantung pada apakah Anda mengonfigurasi penskalaan otomatis untuk pertama kalinya atau apakah penskalaan otomatis dikonfigurasi tetapi dibatasi atau dinonaktifkan sementara.
Mengonfigurasi autoscaler untuk pertama kalinya
Jika Anda memiliki MIG yang tidak diskalakan otomatis dan mengonfigurasi penskalaan otomatis dari awal, autoscaler akan menggunakan ukuran MIG saat ini sebagai titik awal. Sebelum melakukan penurunan skala, autoscaler menggunakan periode stabilisasi, lalu menggunakan kontrol penurunan skala untuk membatasi laju penurunan skala:

Mengubah mode autoscaler
Dengan mode penskalaan otomatis, Anda dapat menonaktifkan atau membatasi aktivitas penskalaan otomatis untuk sementara. Konfigurasi autoscaler tetap dipertahankan dan autoscaler akan terus melakukan penghitungan latar belakang saat autoscaler nonaktif atau dibatasi. Autoscaler memperhitungkan kontrol penurunan skala dalam penghitungan latar belakangnya saat berada dalam mode nonaktif atau dibatasi. Semua aktivitas penskalaan otomatis dilanjutkan menggunakan penghitungan terbaru saat Anda mengaktifkan kembali penskalaan otomatis atau saat Anda mencabut pembatasan:

- Autoscaler yang di-AKTIF-kan akan berperilaku seperti biasa (dalam kasus ini dengan kontrol penurunan skala).
- Saat Anda MENONAKTIFKAN autoscaler, autoscaler akan tetap menghitung ukuran grup instance yang direkomendasikan berdasarkan beban. Perhitungan autoscaler masih mempertimbangkan kontrol penurunan skala. Namun, autoscaler tidak menerapkan penghitungan ukuran saat autoscaler NONAKTIF. Ukuran grup instance tetap konstan hingga autoscaler kembali AKTIF.
- Saat Anda MENGAKTIFKAN lagi autoscaler, ukuran yang dihitung sebelumnya akan langsung diterapkan. Hal ini memungkinkan penskalaan yang lebih cepat ke ukuran yang tepat. Mengaktifkan kembali autoscaler dapat menyebabkan penurunan skala yang tiba-tiba (di sini dari 80 menjadi 40 instance VM). Cara ini aman karena penghitungan latar belakang sudah mempertimbangkan kontrol penurunan skala.
Penskalaan otomatis prediktif
Untuk mempelajari penskalaan otomatis prediktif, termasuk cara kerjanya, lihat Penskalaan berdasarkan prediksi.
Mempersiapkan untuk menghentikan instance
Saat melakukan penskalaan turun, autoscaler akan menentukan jumlah instance VM yang akan dihapus. Autoscaler memprioritaskan instance VM yang akan dihapus berdasarkan beberapa faktor, termasuk hal berikut:
- VM yang tidak berjalan karena alasan apa pun.
- VM yang sedang menjalani atau dijadwalkan mengalami perubahan yang mengganggu—misalnya, refresh, mulai ulang, atau ganti.
- VM yang belum diupdate ke versi template instance yang diinginkan.
- VM yang memiliki sinyal penskalaan otomatis terendah. Misalnya, jika Anda mengonfigurasi MIG untuk diskalakan berdasarkan pemakaian CPU, dan grup perlu menurunkan skala, maka autoscaler akan mencoba menghapus VM yang memiliki pemakaian CPU terendah.
Sebelum instance dihentikan, sebaiknya pastikan instance tersebut melakukan tugas tertentu, seperti menutup koneksi apa pun yang ada, menonaktifkan aplikasi atau server aplikasi dengan baik, mengupload log, dan sebagainya. Anda dapat memerintahkan instance untuk melakukan tugas-tugas tersebut menggunakan skrip shutdown. Skrip shutdown berjalan berdasarkan upaya terbaik, dalam periode singkat antara saat permintaan penghentian dibuat hingga instance benar-benar dihentikan. Selama periode ini, Compute Engine akan mencoba menjalankan skrip shutdown Anda untuk melakukan tugas apa pun yang Anda berikan dalam skrip.
Hal ini sangat berguna jika Anda menggunakan load balancing dengan grup instance terkelola. Jika instance Anda tidak responsif, mungkin perlu waktu beberapa saat agar load balancer mengenali bahwa instance tersebut tidak responsif, yang menyebabkan load balancer terus mengirim permintaan baru ke instance. Dengan skrip shutdown, instance dapat melaporkan bahwa instance tidak responsif saat sedang dimatikan sehingga load balancer dapat berhenti mengirimkan traffic ke instance. Untuk mengetahui informasi selengkapnya tentang health check load balancing, lihat ringkasan health check.
Untuk mengetahui informasi selengkapnya tentang skrip shutdown, lihat Skrip shutdown.
Untuk mengetahui informasi selengkapnya tentang penonaktifan instance, baca dokumentasi tentang menghentikan atau menghapus instance.
Memantau diagram dan log penskalaan otomatis
Compute Engine menyediakan beberapa diagram dan log yang dapat Anda gunakan untuk memantau perilaku grup instance terkelola kapan saja.
Anda dapat mengakses diagram dan log di konsol Google Cloud .
- Di konsol Google Cloud , buka halaman Instance groups.
- Klik nama grup instance terkelola yang ingin Anda lihat.
- Pada halaman grup instance terkelola, pilih tab Monitoring.
Diagram pemantauan menampilkan perkembangan metrik berikut:
- Ukuran grup
- Pemakaian autoscaler
- Pemakaian CPU
- I/O Disk (byte)
- I/O Disk (operasi)
- Byte jaringan
- Paket jaringan
Tooltip di samping judul setiap diagram memberikan detail kontekstual tambahan tentang metrik yang ditampilkan.
Panel Logs tersedia di bagian bawah halaman, tempat Anda dapat menemukan daftar log peristiwa untuk grup instance terkelola. Untuk melihat log, klik panah peluas.
Semua diagram dan log terikat pada satu jangka waktu yang dapat Anda sesuaikan dengan pemilih rentang waktu. Dengan mengklik dan menarik diagram, Anda dapat memperbesar peristiwa tertentu dan menganalisis grafik serta log dalam rentang waktu yang dipilih.
Memantau penskalaan otomatis prediktif
Compute Engine menyediakan diagram untuk memantau prediksi autoscaler. Untuk melihat diagram ini, klik judul Group size pada diagram pertama, lalu pilih Predictive autoscaling.
Jika penskalaan otomatis diaktifkan, Anda dapat melihat cara prediksi autoscaler menentukan ukuran grup instance Anda. Jika penskalaan otomatis tidak diaktifkan, Anda tetap dapat melihat prediksi autoscaler dan menggunakannya untuk membuat keputusan terkait ukuran grup.
Gunakan informasi berikut untuk memahami diagram ini.
- Garis biru menunjukkan jumlah instance dalam grup instance terkelola.
- Garis hijau menunjukkan jumlah instance yang diprediksi oleh autoscaler.
- Jika garis hijau berada di bawah garis biru, berarti ada sejumlah besar kapasitas yang tersedia dan tingkat pemakaian instance VM Anda kemungkinan rendah.
- Jika garis hijau berada di atas garis biru, berarti hanya ada sedikit, atau mungkin tidak ada, kapasitas yang tersisa. Anda harus menambahkan lebih banyak instance ke grup instance.
- Garis merah horizontal putus-putus menunjukkan jumlah instance minimum dan maksimum yang diizinkan dalam grup instance Anda.
Melihat pesan status
Jika autoscaler mengalami masalah dalam penskalaan, autoscaler akan menampilkan pesan peringatan atau pesan error. Anda dapat meninjau pesan status ini dengan salah satu dari dua cara berikut.
Melihat pesan status di halaman Instance groups
Anda dapat melihat pesan status secara langsung di halaman Instance groups di Google Cloud console.
- Di konsol Google Cloud , buka halaman Instance groups.
Cari grup instance yang memiliki ikon peringatan sebelum namanya.
Contoh:
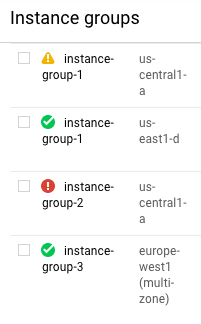
Arahkan kursor ke ikon status untuk mendapatkan detail pesan status.
Melihat pesan status di halaman ringkasan Instance groups
Anda dapat langsung membuka halaman ringkasan grup instance tertentu untuk melihat pesan status yang relevan.
- Di konsol Google Cloud , buka halaman Instance groups.
- Klik grup instance tempat Anda ingin melihat pesan statusnya.
- Di halaman grup instance tersebut, lihat pesan status di bawah nama grup instance.
Pesan status yang biasa ditampilkan
Jika autoscaler mengalami masalah dalam penskalaan, autoscaler akan menampilkan pesan peringatan atau pesan error. Berikut beberapa pesan yang umumnya ditampilkan serta artinya.
All instances in the instance group are unhealthy (not in RUNNING state). If this is an error, check the instances.- Semua instance dalam grup instance memiliki status selain
RUNNING. Jika ini disengaja, Anda dapat mengabaikan pesan ini. Jika hal ini tidak disengaja, pecahkan masalah grup instance. The number of instances has reached the maxNumReplicas. The autoscaler cannot add more instances.- Saat membuat autoscaler, Anda menyatakan jumlah instance maksimum yang dapat dimiliki grup instance. Autoscaler saat ini mencoba menyebarkan skala grup instance untuk memenuhi permintaan, tetapi telah mencapai
maxNumReplicas. Untuk informasi tentang cara mengupdatemaxNumReplicaske jumlah yang lebih besar, lihat Mengupdate autoscaler. The monitoring metric that was specified does not exist or does not have the required labels. Check the metric.Anda melakukan penskalaan otomatis menggunakan metrik Cloud Monitoring, tetapi metrik yang Anda berikan tidak ada, tidak memiliki label yang diperlukan, atau tidak dapat diakses oleh Agen Layanan Compute Engine.
- Bergantung pada apakah metrik tersebut merupakan metrik standar atau kustom, label yang berbeda diperlukan. Baca dokumentasi untuk Penskalaan berdasarkan metrik Monitoring untuk mengetahui informasi selengkapnya.
- Verifikasi bahwa Agen Layanan Compute Engine memiliki peran IAM
compute.serviceAgent. Untuk menambahkannya, lihat Prasyarat autoscaler.
- Verifikasi bahwa Agen Layanan Compute Engine memiliki peran IAM
Quota for some resources is exceeded. Increase the quota or delete resources to free up more quota.Anda bisa mendapatkan informasi tentang kuota yang tersedia di halaman Quota di konsol Google Cloud .
Autoscaling does not work with an HTTP/S load balancer configured for maxRate.Grup instance sedang menjalani load balancing menggunakan konfigurasi
maxRatetetapi autoscaler tidak mendukung mode ini. Ubah konfigurasi atau nonaktifkan penskalaan otomatis. Untuk mempelajarimaxRatelebih lanjut, baca Pembatasan dan panduan dalam dokumentasi load balancing.The autoscaler is configured to scale based on a load balancing signal but the instance group has not received any queries from the load balancer. Check that the load balancing configuration is working.Grup instance sedang menjalani load balancing tetapi grup tidak memiliki kueri yang masuk. Layanan mungkin mengalami periode tidak ada aktivitas, sehingga tidak ada yang perlu dikhawatirkan. Namun, pesan ini juga dapat disebabkan oleh kesalahan konfigurasi; misalnya, grup instance dengan penskalaan otomatis mungkin menjadi target lebih dari satu load balancer, yang tidak didukung. Untuk mengetahui daftar lengkap panduan, lihat Pembatasan dan panduan dalam dokumentasi load balancing.