El autoescalado añade automáticamente VMs (escalado horizontal) o elimina VMs (escalado vertical) de tu grupo de instancias gestionado (MIG). En este documento se explica cómo determina un escalador automático cuándo escalar tus MIGs.
Cómo calculan los autoescaladores el tamaño recomendado y cómo influyen en el tamaño objetivo
Cuando configuras un autoescalador para un MIG, este monitoriza constantemente el grupo y define el tamaño recomendado del grupo como el número de instancias de máquina virtual (VM) necesarias para atender la carga máxima durante el periodo de estabilización.
El tamaño recomendado está limitado por el número mínimo y máximo de instancias que hayas definido en la política de autoescalado.
Si tu política de ajuste automático de escala incluye controles de reducción de tamaño, el tamaño recomendado se verá aún más limitado por estos controles.
Si habilitas el autoescalado predictivo, el escalador automático usará los patrones históricos de uso de CPU para predecir la carga futura y definirá el tamaño recomendado del grupo en función de su predicción.
La respuesta del MIG al tamaño recomendado por el autoescalador depende de cómo configures el mode del autoescalador:
ON. El MIG define el tamaño objetivo como el tamaño recomendado y, a continuación, Compute Engine escala automáticamente el MIG para alcanzar el tamaño objetivo.ONLY_SCALE_OUT. El tamaño objetivo de un MIG solo se puede aumentar en respuesta a un aumento del tamaño recomendado.OFF. El tamaño de destino no se ve afectado por el tamaño recomendado. Sin embargo, el tamaño recomendado se sigue calculando.
Si se elimina la configuración del autoescalador, no se calcula ningún tamaño recomendado.
Diferencias entre las métricas de utilización objetivo y real
Cuando se usa una política de autoescalado con señales basadas en métricas, puede que observes que, en los grupos de instancias más pequeños, la utilización real del grupo de instancias y la utilización objetivo parecen estar muy alejadas. Esto se debe a que un escalador automático siempre actúa de forma conservadora redondeando hacia arriba o hacia abajo cuando interpreta los datos de utilización y determina cuántas instancias debe añadir o eliminar. De esta forma, el escalador automático no añadirá un número insuficiente de recursos ni eliminará demasiados.
Por ejemplo, si defines un objetivo de uso de 0,7 y tu aplicación lo supera, el autoescalador puede determinar que añadir 1,5 instancias de máquina virtual (VM) reduciría el uso a un valor cercano a 0,7. Como no puedes añadir 1,5 instancias de VM, el autoescalador redondea al alza y añade dos instancias. Esto podría reducir la utilización media de la CPU a un valor inferior a 0,7, pero asegura que tu aplicación tenga recursos suficientes para admitirla.
Del mismo modo, si el escalador automático determina que eliminar 1,5 instancias de VM aumentaría tu utilización demasiado cerca de 0,7, eliminará solo una instancia.
En los grupos más grandes con más instancias de VM, el uso se divide entre un mayor número de instancias, y añadir o quitar instancias de VM provoca una diferencia menor entre el uso real y el uso previsto.
Si usas el autoescalado basado en programaciones con otra señal de autoescalado, es posible que una programación activa requiera más VMs de las que necesitas. En estas situaciones, el uso real es inferior al uso previsto porque la programación del autoescalado determina el tamaño recomendado del grupo de instancias.
Retrasos en el escalado horizontal
Cuando configuras el autoescalado, especificas un periodo de inicialización que refleja el tiempo que tardan tus VMs en inicializarse. El autoescalador solo recomienda aumentar la escala si la utilización media de las instancias que no se están inicializando es superior a la utilización objetivo.
Si asigna un valor al periodo de inicialización que es significativamente más largo que el tiempo que tarda una instancia en inicializarse, es posible que el autoescalador ignore datos de utilización legítimos y que subestime el tamaño necesario de su grupo.
Retrasos en el escalado
Para reducir el tamaño, el autoescalador calcula el tamaño objetivo recomendado del grupo en función de la carga máxima de los últimos 10 minutos o del periodo de inicialización que hayas definido (el que sea más largo). Esta duración se denomina periodo de estabilización.
Observar el uso durante el periodo de estabilización ayuda a la herramienta de adaptación dinámica a hacer lo siguiente:
- Asegúrate de que la información de uso recogida del grupo de instancias sea estable.
- Evita que un escalador automático añada o quite instancias continuamente a un ritmo excesivo.
- Elimina instancias de forma segura determinando que el tamaño del grupo más pequeño es suficiente para admitir la carga máxima del periodo de estabilización.
- Si tu aplicación tarda más de 10 minutos en inicializarse en una VM nueva, el grupo usará el periodo de inicialización como periodo de estabilización. De esta forma, la herramienta de ajuste automático de escala tiene en cuenta el tiempo que se tarda en recuperar la capacidad de servicio a la hora de decidir si elimina una VM.
El periodo de estabilización puede parecer un retraso en el escalado horizontal, pero en realidad es una función integrada del escalado automático. El periodo de estabilización también asegura que, si se añade una instancia nueva al grupo de instancias gestionado, la instancia complete su periodo de inicialización o se ejecute durante al menos 10 minutos antes de poder eliminarse.
Periodos de inicialización: se ignoran los periodos de inicialización de las instancias nuevas al decidir si se debe reducir el tamaño de un grupo.
La purga de conexiones está provocando retrasos
Si el grupo forma parte de un servicio backend que tiene habilitado el drenaje de conexiones, pueden pasar hasta 60 segundos adicionales después de que haya transcurrido la duración del drenaje de conexiones antes de que se elimine la instancia de VM.
Controles de reducción de tamaño
Cuando configuras los controles de reducción de tamaño de la herramienta de adaptación dinámica, controlas la velocidad de reducción. El autoescalador nunca reduce la escala más rápido que la tasa que hayas configurado:

- Cuando la carga disminuye, la herramienta de autoescalado mantiene el tamaño del grupo en el nivel necesario para atender la carga máxima observada en el periodo de estabilización. Esto funciona igual con y sin controles de reducción.
- Un autoescalador sin controles de reducción solo mantiene las instancias necesarias para gestionar la carga observada recientemente. Una vez transcurrido el periodo de estabilización, el escalador automático elimina todas las instancias innecesarias en un solo paso. Si la carga disminuye de repente, el tamaño del grupo de instancias puede reducirse drásticamente.
- Un escalador automático con controles de reducción limita el número de instancias de VM que se pueden eliminar en un periodo configurado (en este caso, 10 VMs en 20 minutos). Esto ralentiza la tasa de reducción de instancias.
- Cuando se produce un nuevo pico de carga, el escalador automático añade nuevas instancias para gestionar la carga. Sin embargo, debido a un tiempo de inicialización prolongado, las nuevas VMs no están listas para atender la carga. Con los controles de reducción, se mantuvo la capacidad anterior, lo que permitió que las VMs existentes atendieran el pico.
Puedes controlar la tasa de reducción configurando la reducción máxima permitida del escalador automático en un periodo de tiempo, concretamente:
- Reducción máxima permitida (
maxScaledInReplicas: número o porcentaje de instancias de VM). Número de instancias que tu carga de trabajo puede perder (a partir del tamaño máximo del grupo) en el periodo de tiempo anterior especificado. Usa este parámetro para limitar la reducción de tu grupo y poder seguir atendiendo un pico de carga probable hasta que empiecen a funcionar más instancias. Cuanto menor sea la reducción máxima permitida, más lento será el ritmo de reducción. - Ventana de tiempo final (
timeWindowSecsegundos). Tiempo durante el cual es probable que se produzca un pico de carga después de un descenso temporal y durante el cual no quieres que el tamaño de tu grupo aumente más allá de la reducción máxima permitida. Use este parámetro para definir el periodo durante el cual el escalador automático buscará el tamaño máximo suficiente para atender la carga histórica. La herramienta de ajuste automático de escala no reducirá el tamaño por debajo de la reducción máxima permitida restada del tamaño máximo observado en el periodo anterior. Con una ventana de tiempo de seguimiento más larga, el escalador automático tiene en cuenta más picos de carga históricos, lo que hace que el escalado sea más conservador y estable.
Cuando configuras los controles de reducción de tamaño, la herramienta de adaptación dinámica limita las operaciones de reducción de tamaño a la reducción máxima permitida a partir del tamaño máximo observado en el periodo anterior. El escalador automático sigue estos pasos:
- Monitoriza continuamente el tamaño máximo histórico observado en la ventana temporal de seguimiento.
- Usa la reducción máxima permitida para calcular el tamaño de reducción restringido (tamaño máximo:
maxScaledInReplicas). - Define el tamaño recomendado del grupo como el tamaño de reducción de escala restringido. Por ejemplo, si un auto escalador cambia el tamaño de un grupo de instancias a 20 VMs, pero las restricciones de reducción solo permiten reducirlo a 40 VMs, el tamaño recomendado se establece en 40 VMs.
Con los controles de reducción de tamaño, la herramienta de adaptación dinámica monitoriza continuamente el tamaño máximo de un grupo de instancias en el periodo de tiempo anterior configurado para identificar el tamaño suficiente para atender la carga histórica. La herramienta de adaptación dinámica no reduce el tamaño más allá de la reducción máxima permitida medida a partir del tamaño máximo observado:

Por ejemplo, en el diagrama anterior, los controles de reducción se han configurado para que se puedan reducir hasta 20 VMs en un periodo de 30 minutos:
- Cuando la carga disminuye, el autoescalador elimina 20 VMs, que es la reducción máxima permitida configurada en los controles de reducción.
- A medida que la carga aumenta y disminuye, el escalador automático monitoriza constantemente la ventana de tiempo de los últimos 30 minutos para determinar el tamaño máximo suficiente para atender la carga histórica. Este tamaño máximo se usa como base para los controles de reducción para limitar la tasa de reducción. Si, en los últimos 30 minutos, el tamaño máximo fue de 70 VMs y la reducción máxima permitida es de 20 VMs, el escalador automático puede reducir el tamaño a 50 VMs. Si el tamaño actual es de 65 VMs, el escalador automático solo puede eliminar 15 VMs.
- A medida que disminuye la carga, el escalador automático sigue eliminando instancias de VM, pero limita la tasa a un máximo de 20 VMs del tamaño máximo del grupo de instancias medido en los últimos 30 minutos.
La reducción máxima permitida del tamaño del grupo puede producirse de golpe, por lo que debes configurar la reducción máxima permitida para que tu aplicación pueda permitirse perder ese número de instancias a la vez. Usa el parámetro de reducción máxima permitida para indicar cuánta reducción de la capacidad de servicio puede tolerar tu aplicación.
Al limitar el número de instancias de VM que puede eliminar el autoescalado y aumentar el periodo de tiempo de retardo observado, las aplicaciones con picos de carga y tiempos de inicialización largos deberían experimentar una mayor disponibilidad. En concreto, el tamaño del grupo de instancias no se reduce de forma abrupta en respuesta a una disminución significativa de la carga, sino que se reduce gradualmente con el tiempo. Si la carga aumenta poco después de que se haya producido una reducción, el número restante de VMs debería poder absorber el pico dentro de tu tolerancia. Además, se deben iniciar menos máquinas virtuales para atender el pico de forma suficiente.
Puedes configurar los controles de reducción de escala para el autoescalado de MIGs zonales y regionales. La configuración es la misma en ambos casos. Los controles de reducción funcionan con grupos de cualquier tamaño.
Controles de reducción de tamaño frente a la estabilización de la herramienta de ajuste automático de escala
Configurar los controles de reducción no significa desactivar el mecanismo de estabilización integrado del autoescalador. La herramienta de adaptación dinámica siempre mantiene el tamaño del grupo de instancias en el nivel necesario para atender la carga máxima observada durante el periodo de estabilización. Los controles de reducción de tamaño te ofrecen un mecanismo adicional para controlar la velocidad a la que se cambia el tamaño de un grupo de instancias.
| Autoscalador integrado: Periodo de estabilización |
Controles de ampliación: Ventana de tiempo final |
|
|---|---|---|
| ¿Se puede configurar? | No, no se puede configurar | Sí, se puede configurar |
| ¿Qué se monitoriza? | Monitoriza la carga máxima de los últimos 10 minutos o del periodo de inicialización, el que sea más largo. | Monitoriza el tamaño máximo del grupo de instancias en el periodo anterior definido por el periodo de tiempo final |
| ¿Cómo puede ayudarme? | Asegura que el tamaño del grupo de instancias siga siendo suficiente para atender la carga máxima que se ha observado durante los últimos 10 minutos o el periodo de inicialización, el que sea más largo. | Asegura que el tamaño del grupo de instancias no se reduzca en más instancias de VM de las que tu carga de trabajo puede tolerar al gestionar picos de carga durante un periodo especificado. |
Controles de reducción de tamaño con el modo de autoescalado
Hay dos situaciones similares, pero ligeramente diferentes, en las que tu MIG no se escala automáticamente y quieres activar el escalado automático. Dependen de si configuras el autoescalado por primera vez o de si el autoescalado está configurado, pero restringido o desactivado temporalmente.
Configurar el autoescalador por primera vez
Si tienes un MIG sin autoescalado y configuras el autoescalado desde cero, la herramienta de autoescalado usará el tamaño actual del MIG como punto de partida. Antes de reducir el número de instancias, la herramienta de ajuste automático utiliza el periodo de estabilización y, a continuación, los controles de reducción para limitar la tasa de reducción:

Cambiar el modo de la herramienta de adaptación dinámica
Con el modo de autoescalado, puedes desactivar o restringir temporalmente las actividades de autoescalado. La configuración del autoescalador se mantiene y este sigue realizando cálculos en segundo plano mientras está desactivado o restringido. El autoescalador tiene en cuenta los controles de reducción en sus cálculos en segundo plano cuando está en modo desactivado o restringido. Todas las actividades de autoescalado se reanudan con los cálculos más recientes cuando vuelves a activar el autoescalado o cuando levantas la restricción:

- La herramienta de adaptación dinámica activada se comporta como de costumbre (con controles de reducción en este caso).
- Si desactivas la herramienta de adaptación dinámica, seguirá calculando el tamaño recomendado del grupo de instancias en función de la carga. Los cálculos del escalador automático siguen teniendo en cuenta los controles de reducción. Sin embargo, el autoescalador no aplica los cálculos de tamaño cuando está DESACTIVADO. El tamaño del grupo de instancias se mantiene constante hasta que el autoescalador vuelve a estar ACTIVADO.
- Cuando vuelvas a activar el autoescalador, se aplicará inmediatamente el tamaño calculado anteriormente. Esto permite escalar más rápido al tamaño correcto. Si vuelves a habilitar la herramienta de ajuste automático de escala, se puede producir un ajuste de escala abrupto (en este caso, de 80 a 40 instancias de VM). Es seguro porque los cálculos en segundo plano ya tienen en cuenta los controles de reducción.
Autoescalado predictivo
Para obtener información sobre el autoescalado predictivo, incluido cómo funciona, consulta Escalar en función de las predicciones.
Preparar la detención de instancias
Cuando la herramienta de escalado automático reduce el número de instancias, determina cuántas instancias de VM debe eliminar. La herramienta de escalado automático prioriza las instancias de VM que se van a eliminar en función de varios factores, entre los que se incluyen los siguientes:
- Máquinas virtuales que no se están ejecutando por algún motivo.
- Máquinas virtuales que están experimentando o tienen programados cambios disruptivos (por ejemplo, actualización, reinicio o sustitución).
- Máquinas virtuales que aún no se han actualizado a la versión prevista de la plantilla de instancia.
- Máquinas virtuales que tienen la señal de escalado automático más baja. Por ejemplo, si configuras tu MIG para que se escale en función del uso de la CPU y el grupo necesita reducirse, el escalador automático intentará eliminar las VMs que tengan el menor uso de la CPU.
Antes de detener una instancia, puede que quieras asegurarte de que realice determinadas tareas, como cerrar las conexiones existentes, apagar correctamente las aplicaciones o los servidores de aplicaciones, subir registros, etc. Puedes indicar a tu instancia que realice estas tareas mediante una secuencia de comandos de cierre. Se ejecuta una secuencia de comandos de cierre con el mejor esfuerzo posible durante el breve periodo que transcurre entre el momento en que se realiza la solicitud de detención y el momento en que se detiene la instancia. Durante este periodo, Compute Engine intenta ejecutar el script de cierre para realizar las tareas que hayas incluido en él.
Esto resulta especialmente útil si usas el balanceo de carga con tu grupo de instancias gestionado. Si tu instancia deja de estar en buen estado, el balanceador de carga puede tardar un tiempo en reconocer que la instancia no está en buen estado, lo que hará que el balanceador de carga siga enviando nuevas solicitudes a la instancia. Con una secuencia de comandos de cierre, la instancia puede informar de que no está en buen estado mientras se cierra, de modo que el balanceador de carga pueda dejar de enviar tráfico a la instancia. Para obtener más información sobre las comprobaciones del estado de balanceo de carga, consulta la descripción general de las comprobaciones del estado.
Para obtener más información sobre las secuencias de comandos de cierre, consulta Secuencias de comandos de cierre.
Para obtener más información sobre el cierre de instancias, consulta la documentación sobre cómo detener o eliminar una instancia.
Monitorizar gráficos y registros de escalado automático
Compute Engine proporciona varios gráficos y registros que te permiten monitorizar el comportamiento de tu grupo de instancias gestionado en cualquier momento.
Puedes acceder a los gráficos y registros en la Google Cloud consola.
- En la consola, ve a la página Grupos de instancias. Google Cloud
- Haga clic en el nombre del grupo de instancias gestionado que quiera ver.
- En la página del grupo de instancias gestionado, selecciona la pestaña Monitorización.
Los gráficos de monitorización muestran la evolución de las siguientes métricas:
- Tamaño del grupo
- Uso de la herramienta de adaptación dinámica
- Uso de CPU
- E/S de disco (bytes)
- E/S de disco (operaciones)
- Bytes de red
- Paquetes de red
Una descripción emergente situada junto al título de cada gráfico proporciona detalles contextuales adicionales sobre la métrica que se muestra.
En la parte inferior de la página, se encuentra el panel Registros, donde puedes ver una lista de los registros de eventos de tu grupo de instancias gestionado. Para ver los registros, haz clic en la flecha para desplegar.
Todos los gráficos y registros están vinculados a un único periodo que puedes personalizar con el selector de periodo. Si haces clic en cualquier gráfico y lo arrastras, puedes ampliar un evento concreto y analizar los gráficos y los registros del periodo seleccionado.
Monitorizar el autoescalado predictivo
Compute Engine proporciona un gráfico para monitorizar las predicciones del escalador automático. Para ver este gráfico, haga clic en el título Tamaño del grupo del primer gráfico y seleccione Autoescalado predictivo.
Si el autoescalado está habilitado, puedes ver cómo las predicciones de la herramienta de autoescalado determinan el tamaño de tu grupo de instancias. Si el autoescalado no está habilitado, puedes ver las predicciones de la herramienta de adaptación dinámica y usarlas para tomar decisiones sobre el tamaño de tu grupo.
Utiliza la siguiente información para entender este gráfico.
- La línea azul indica el número de instancias del grupo de instancias gestionado.
- La línea verde muestra el número de instancias que predice el escalado automático.
- Si la línea verde está por debajo de la azul, significa que hay una gran cantidad de capacidad disponible y que es probable que tus instancias de VM no se estén utilizando lo suficiente.
- Si la línea verde está por encima de la azul, significa que queda poca capacidad (o ninguna) y que debes añadir más instancias al grupo de instancias.
- Las líneas horizontales rojas discontinuas indican el número mínimo y máximo de instancias permitidas en el grupo de instancias.
Ver mensajes de estado
Cuando el escalador automático tiene problemas para escalar, devuelve un mensaje de advertencia o de error. Puede consultar estos mensajes de estado de dos formas.
Ver mensajes de estado en la página Grupos de instancias
Puedes ver los mensajes de estado directamente en la página Grupos de instancias de la Google Cloud console.
- En la consola, ve a la página Grupos de instancias. Google Cloud
Busca los grupos de instancias que tengan el icono de precaución delante de su nombre.
Por ejemplo:
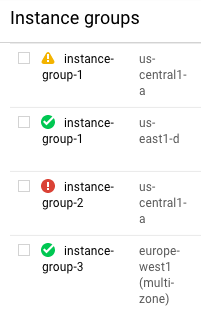
Mantén el puntero sobre un icono de estado para ver los detalles del mensaje de estado.
Ver mensajes de estado en la página de resumen del grupo de instancias
Puedes ir directamente a la página de resumen de un grupo de instancias específico para ver los mensajes de estado relevantes.
- En la consola, ve a la página Grupos de instancias. Google Cloud
- Haga clic en el grupo de instancias del que quiera ver los mensajes de estado.
- En la página del grupo de instancias, consulta el mensaje de estado debajo del nombre del grupo de instancias.
Mensajes de estado devueltos con frecuencia
Cuando el escalador automático tiene problemas para escalar, devuelve un mensaje de advertencia o de error. A continuación, se indican algunos de los mensajes que se devuelven con frecuencia y su significado.
All instances in the instance group are unhealthy (not in RUNNING state). If this is an error, check the instances.- Todas las instancias del grupo de instancias tienen un estado distinto de
RUNNING. Si es así, puedes ignorar este mensaje. Si no es intencionado, soluciona los problemas del grupo de instancias. The number of instances has reached the maxNumReplicas. The autoscaler cannot add more instances.- Cuando creaste el escalador automático, indicaste el número máximo de instancias que puede tener el grupo de instancias. La herramienta de adaptación dinámica está intentando escalar horizontalmente el grupo de instancias para satisfacer la demanda, pero ha alcanzado el
maxNumReplicas. Para obtener información sobre cómo actualizarmaxNumReplicasa un número mayor, consulta Actualizar una herramienta de escalado automático .
The monitoring metric that was specified does not exist or does not have the required labels. Check the metric.Estás usando el autoescalado con una métrica de Cloud Monitoring, pero la métrica que has proporcionado no existe, no tiene las etiquetas necesarias o el agente de servicio de Compute Engine no puede acceder a ella.
- En función de si la métrica es estándar o personalizada, se requieren etiquetas diferentes. Para obtener más información, consulta la documentación sobre Escalar en función de una métrica de monitorización.
- Verifica que el agente de servicio de Compute Engine tenga el rol de gestión de identidades y accesos
compute.serviceAgent. Para añadirlo, consulta los requisitos previos de Autoscaler.
- Verifica que el agente de servicio de Compute Engine tenga el rol de gestión de identidades y accesos
Quota for some resources is exceeded. Increase the quota or delete resources to free up more quota.Puedes consultar información sobre la cuota disponible en la página Cuota de la consola de Google Cloud .
Autoscaling does not work with an HTTP/S load balancer configured for maxRate.El balanceo de carga del grupo de instancias se está realizando con la configuración
maxRate, pero el autoescalador no admite este modo. Cambia la configuración o inhabilita el autoescalado. Para obtener más información sobremaxRate, consulta las restricciones y directrices en la documentación sobre balanceo de carga.The autoscaler is configured to scale based on a load balancing signal but the instance group has not received any queries from the load balancer. Check that the load balancing configuration is working.El grupo de instancias está balanceando la carga, pero no tiene consultas entrantes. Es posible que el servicio esté inactivo, en cuyo caso no hay de qué preocuparse. Sin embargo, este mensaje también puede deberse a un error de configuración. Por ejemplo, un grupo de instancias con escalado automático puede ser el destino de más de un balanceador de carga, lo que no se admite. Para ver una lista completa de directrices, consulta la sección Restricciones y directrices de la documentación sobre el balanceo de carga.