En este documento, se describe cómo escalar un grupo de instancias administrado (MIG) según la capacidad de entrega de un balanceador de cargas de aplicaciones externo o un balanceador de cargas de aplicaciones interno. Esto significa que el ajuste de escala automático agrega o quita instancias de VM del grupo cuando el balanceador de cargas indica que el grupo alcanzó una fracción configurable de su plenitud, en donde su plenitud se define como la capacidad objetivo del modo de balanceo seleccionado del grupo de instancias del backend.
También puedes escalar un MIG según su uso de CPU o las métricas de Monitoring.
Limitaciones
Puedes ajustar automáticamente la escala de un grupo de instancias administrado según la capacidad de entrega de un balanceador de cargas de aplicaciones externo y un balanceador de cargas de aplicaciones interno. No se admiten otros tipos de balanceadores de cargas.
Antes de comenzar
- Revisa las limitaciones del escalador automático.
- Lee acerca de los aspectos básicos del escalador automático.
-
Si aún no lo hiciste, configura la autenticación.
La autenticación verifica tu identidad para acceder a los servicios y las APIs de Google Cloud . Para ejecutar código o muestras desde un entorno de desarrollo local, puedes autenticarte en Compute Engine seleccionando una de las siguientes opciones:
Select the tab for how you plan to use the samples on this page:
Console
When you use the Google Cloud console to access Google Cloud services and APIs, you don't need to set up authentication.
gcloud
-
Instala Google Cloud CLI. Después de la instalación, inicializa Google Cloud CLI ejecutando el siguiente comando:
gcloud initSi usas un proveedor de identidad externo (IdP), primero debes acceder a gcloud CLI con tu identidad federada.
- Set a default region and zone.
REST
Para usar las muestras de la API de REST en esta página en un entorno de desarrollo local, debes usar las credenciales que proporciones a gcloud CLI.
Instala Google Cloud CLI. Después de la instalación, inicializa Google Cloud CLI ejecutando el siguiente comando:
gcloud initSi usas un proveedor de identidad externo (IdP), primero debes acceder a gcloud CLI con tu identidad federada.
Para obtener más información, consulta Autentícate para usar REST en la documentación de autenticación de Google Cloud .
Escalamiento según la capacidad de entrega de balanceo de cargas de HTTP(S)
Compute Engine proporciona compatibilidad para el balanceo de cargas dentro de tus grupos de instancias. Puedes usar el ajuste de escala automático junto con el balanceo de cargas si configuras un escalador automático que escala según la carga de las instancias.
Un balanceador de cargas de HTTP(S) interno o externo distribuye las solicitudes a los servicios de backend según su mapa de URL. El balanceador de cargas puede tener uno o más servicios de backend, cada uno de los cuales admite grupos de instancias o grupos de extremos de red (NEG). Cuando los backends son grupos de instancias, el balanceador de cargas de HTTP(S) ofrece dos modos de balanceo:
UTILIZATIONyRATE. ConUTILIZATION, puedes especificar un objetivo máximo para el uso de backend promedio de las instancias en el grupo de instancias. ConRATE, debes especificar una cantidad objetivo de solicitudes por segundo por instancia o por grupo. (solo los grupos de instancias zonales admiten la especificación de una tasa máxima para todo el grupo. (Los grupos de instancias administrados regionales no admiten la definición de una tasa máxima por grupo).El modo de balanceo y la capacidad objetivo que especificas definen las condiciones en las que Google Cloud determina cuándo una VM de backend está a máxima capacidad. Google Cloud intenta enviar tráfico a las VMs en buen estado que tienen capacidad restante. Si todas las VM ya están al máximo de capacidad, se excede el uso o la tasa de destino.
Cuando conectas un escalador automático a un backend de grupo de instancias de un balanceador de cargas de HTTP(S), el escalador automático escala el grupo de instancias administrado para mantener una fracción de la capacidad de entrega del balanceo de cargas.
Por ejemplo, supongamos que la capacidad de entrega de balanceo de cargas de un grupo de instancias administrado se define como 100 RPS por instancia. Si creas un escalador automático con la política de balanceo de cargas HTTP(S) y lo configuras para mantener un nivel de uso objetivo de 0.8 o del 80%, el escalador automático agrega o quita instancias del grupo de instancias administrado a fin de mantener el 80% de la capacidad de servicio, o las 80 RPS por instancia.
El diagrama siguiente muestra cómo el escalador automático interactúa con un grupo de instancias administrado y un servicio de backend:
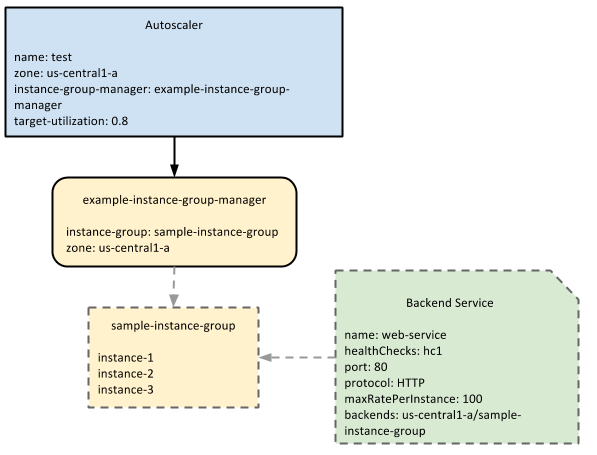
El escalador automático observa la capacidad de entrega del grupo de instancias administrado, que se define en el servicio de backend, y escala según el uso objetivo. En este ejemplo, la capacidad de entrega se mide en el valor maxRatePerInstance.Configuración de balanceo de cargas aplicable
Puedes establecer una de las tres opciones para la capacidad de entrega del balanceo de cargas. Cuando creas el backend por primera vez, puedes elegir entre el uso máximo del backend, las solicitudes máximas por segundo por instancia o las solicitudes máximas por segundo de todo el grupo. El ajuste de escala automático solo funciona con el uso máximo del backend y las solicitudes máximas por segundo o instancia porque el valor de esta configuración se puede controlar mediante la adición o eliminación de instancias. Por ejemplo, si configuras un backend para que procese 10 solicitudes por segundo por instancia y el escalador automático está configurado para mantener el 80% de esa frecuencia, este mecanismo puede agregar o quitar instancias cuando cambia la cantidad de solicitudes por segundo por instancia.
El ajuste de escala automático no funciona con solicitudes máximas por grupo porque esta configuración es independiente de la cantidad de instancias en el grupo de instancias. El balanceador de cargas envía de manera continua la cantidad máxima de solicitudes por grupo al grupo de instancias, independientemente de cuántas instancias haya en el grupo.
Por ejemplo, si configuras el backend para manejar 100 solicitudes máximas por grupo por segundo, el balanceador de cargas envía 100 solicitudes por segundo al grupo, ya sea que el grupo tenga dos instancias o 100 instancias. Debido a que no se puede ajustar este valor, el ajuste de escala automático no funciona con una configuración de balanceo de cargas que usa la cantidad máxima de solicitudes por segundo por grupo.
Habilita el ajuste de escala automático según la capacidad de entrega de balanceo de cargas
Console
- Ve a la página Grupos de instancias en la Google Cloud consola.
- Si tienes un grupo de instancias, selecciónalo y, luego, haz clic en Editar. Si no tienes un grupo de instancias, haz clic en Crear grupo de instancias.
- Haz clic en Tamaño del grupo y ajuste de escala automático para expandir la sección.
- En la lista Modo de ajuste de escala automático, asegúrate de que esté seleccionada la opción Activado: agrega y quita instancias del grupo.
- Especifica la cantidad mínima y máxima de instancias que deseas que el escalador automático cree en este grupo.
- En la sección Indicadores de ajuste de escala automático, haz clic en Agregar un indicador.
- Establece el Tipo de indicador en Uso del balanceo de cargas de HTTP.
Ingresa el valor del Uso objetivo de balanceo de cargas HTTP en porcentaje. Por ejemplo, para un uso de balanceo de cargas HTTP del 60%, ingresa
60.Puedes usar el campo Período de inicialización para establecer el período de inicialización, que le indica al escalador automático cuánto tarda tu aplicación en inicializarse. Especificar un período de inicialización preciso mejora las decisiones de escalador automático. Por ejemplo, cuando se escala horizontalmente, el escalador automático ignora los datos de las VMs que aún se están inicializando, ya que es posible que estas aún no representen el uso normal de tu aplicación. El período de inicialización predeterminado es de 60 segundos.
Guarda los cambios.
gcloud
Para habilitar un escalador automático que se ajuste a la capacidad de entrega, usa el subcomando
set-autoscaling. Por ejemplo, el siguiente comando crea un escalador automático que escala el grupo de instancias de destino administrado para mantener el 60% de la capacidad de entrega. Además del parámetro--target-load-balancing-utilization, también se requiere el parámetro--max-num-replicascuando se crea un escalador automático:gcloud compute instance-groups managed set-autoscaling example-managed-instance-group \ --max-num-replicas 20 \ --target-load-balancing-utilization 0.6 \ --cool-down-period 90Puedes usar la marca
--cool-down-periodpara establecer el período de inicialización, que le indica al escalador automático cuánto tarda tu aplicación en inicializarse. Especificar un período de inicialización preciso mejora las decisiones de escalador automático. Por ejemplo, cuando se escala horizontalmente, el escalador automático ignora los datos de las VMs que aún se están inicializando, ya que es posible que estas aún no representen el uso normal de tu aplicación. El período de inicialización predeterminado es de 60 segundos.Puedes verificar que el escalador automático se creó de manera correcta con el subcomando
instance-groups managed describe:gcloud compute instance-groups managed describe example-managed-instance-group
Para obtener una lista de los comandos y las marcas
gclouddisponibles, consulta la referencia degcloud.REST
A fin de crear un escalador automático, usa el método
autoscalers.insertpara un MIG zonal o el métodoregionAutoscalers.insertpara un MIG regional.En el siguiente ejemplo, se crea un escalador automático para un MIG zonal:
POST https://compute.googleapis.com/compute/v1/projects/PROJECT_ID/zones/ZONE/autoscalers/
El cuerpo de tu solicitud debe contener los campos
name,targetyautoscalingPolicy.autoscalingPolicydebe definirloadBalancingUtilization.Puedes usar el campo
coolDownPeriodSecpara establecer el período de inicialización, que le indica al escalador automático cuánto tarda tu aplicación en inicializarse. Especificar un período de inicialización preciso mejora las decisiones de escalador automático. Por ejemplo, cuando se escala horizontalmente, el escalador automático ignora los datos de las VMs que aún se están inicializando, ya que es posible que estas aún no representen el uso normal de tu aplicación. El período de inicialización predeterminado es de 60 segundos.{ "name": "example-autoscaler", "target": "zones/us-central1-f/instanceGroupManagers/example-managed-instance-group", "autoscalingPolicy": { "maxNumReplicas": 20, "loadBalancingUtilization": { "utilizationTarget": 0.8 }, "coolDownPeriodSec": 90 } }Para obtener más información sobre cómo habilitar el ajuste de escala automático según la capacidad de entrega de balanceo de cargas, completa el instructivo sobre el Ajuste de escala automático global de un servicio web en Compute Engine.
¿Qué sigue?
- Obtén más información sobre cómo administrar los escaladores automáticos.
- Descubre cómo los escaladores automáticos toman decisiones.
- Obtén información sobre cómo usar varios indicadores de ajuste de escala automático para escalar tu grupo.
Salvo que se indique lo contrario, el contenido de esta página está sujeto a la licencia Atribución 4.0 de Creative Commons, y los ejemplos de código están sujetos a la licencia Apache 2.0. Para obtener más información, consulta las políticas del sitio de Google Developers. Java es una marca registrada de Oracle o sus afiliados.
Última actualización: 2025-10-19 (UTC)
-