샌드박스를 사용하여 BigQuery 사용해 보기
BigQuery 샌드박스를 사용하면 BigQuery 기능을 무료로 탐색하여 BigQuery가 니즈에 적합한지 확인할 수 있습니다. BigQuery 샌드박스를 사용하면 신용카드 정보를 제공하거나 프로젝트에 결제 계정을 만들지 않고도 BigQuery를 경험할 수 있습니다. 이미 결제 계정을 만든 경우에도 무료 사용량 등급으로 BigQuery를 무료로 사용할 수 있습니다.
BigQuery 샌드박스를 사용하면 제한된 BigQuery 기능으로 BigQuery를 무료로 학습할 수 있습니다. BigQuery 샌드박스를 사용하여 공개 데이터 세트를 보고 쿼리하여 BigQuery를 평가할 수 있습니다.
Google Cloud BigQuery에 저장되고 Google Cloud 공개 데이터 세트 프로그램을 통해 일반 대중에게 제공되는 공개 데이터 세트를 제공합니다. 공개 데이터 세트 작업에 대한 자세한 내용은 BigQuery 공개 데이터 세트를 참고하세요.
Google Cloud 콘솔에서 이 태스크에 대한 단계별 안내를 직접 수행하려면 둘러보기를 클릭합니다.
시작하기 전에
BigQuery 샌드박스 사용 설정
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
또한 브라우저에 다음 URL을 입력하면 Google Cloud 콘솔에서 BigQuery를 열 수 있습니다.
https://console.cloud.google.com/bigquery
Google Cloud 콘솔은 BigQuery 리소스를 만들어 관리하거나 SQL 쿼리를 실행할 때 사용할 수 있는 그래픽 인터페이스입니다.
Google 계정으로 인증하거나 새 계정을 만듭니다.
시작 페이지에서 다음을 수행합니다.
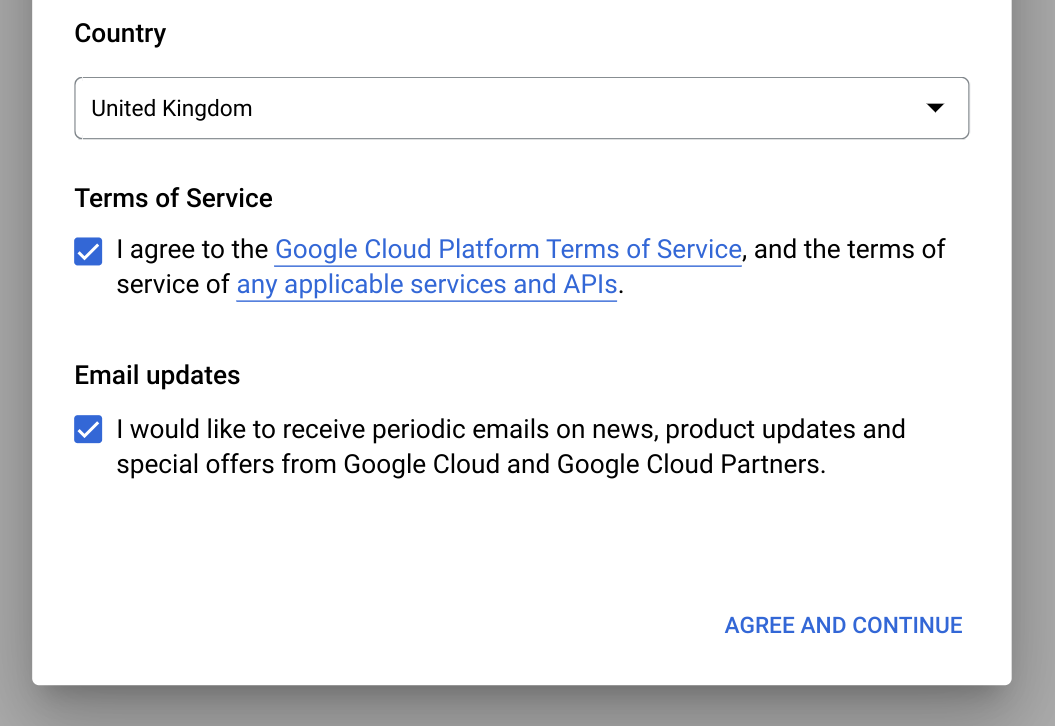
국가에서 국가를 선택합니다.
서비스 약관에서 서비스 약관에 동의하면 체크박스를 선택합니다.
선택사항: 이메일 업데이트에 대한 메시지가 표시되면 이메일 업데이트를 수신하려는 경우 체크박스를 선택합니다.
동의 및 계속하기를 클릭합니다.
프로젝트 만들기를 클릭합니다.
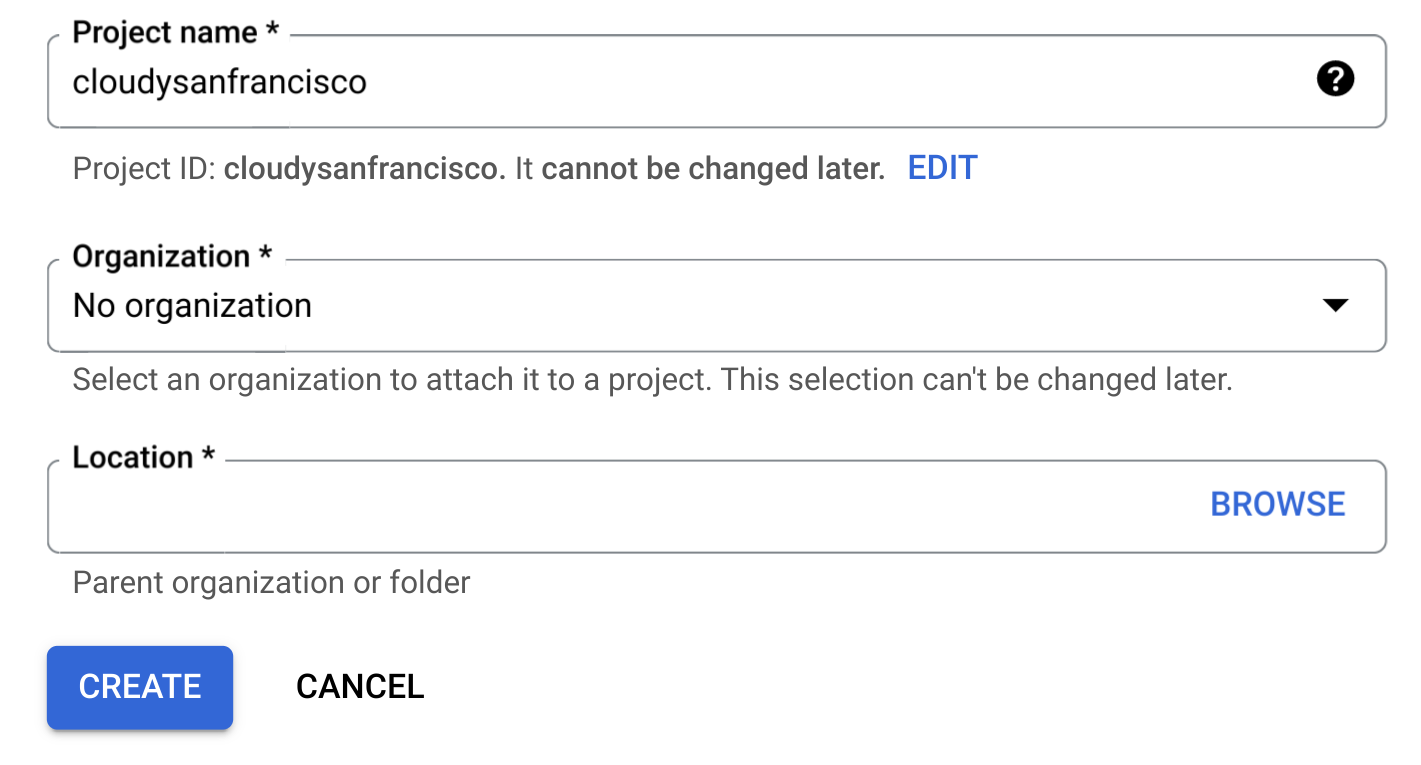
새 프로젝트 페이지에서 다음을 수행합니다.
프로젝트 이름에 프로젝트 이름을 입력합니다.
조직에서 조직을 선택하거나 조직에 속해 있지 않은 경우 조직 없음을 선택합니다. 관리 계정(예: 교육 기관과 연결된 계정)은 조직을 선택해야 합니다.
위치를 선택하라는 메시지가 표시되면 찾아보기를 클릭하고 프로젝트의 위치를 선택합니다.
만들기를 클릭합니다. Google Cloud 콘솔에서 BigQuery 페이지로 다시 리디렉션됩니다.
BigQuery 샌드박스를 사용 설정했습니다. 이제 BigQuery 페이지에 BigQuery 샌드박스 알림이 표시됩니다.

제한사항
BigQuery 샌드박스에는 다음 한도가 적용됩니다.
- 모든 BigQuery 할당량 및 한도가 적용됩니다.
- BigQuery 무료 등급과 동일한 무료 사용량 한도, 즉 매월 활성 스토리지 10GB와 처리된 쿼리 데이터 1TB가 제공됩니다.
- 모든 BigQuery 데이터 세트에는 기본 테이블 만료 시간이 있으며 모든 테이블, 뷰, 파티션은 60일 후에 자동으로 만료됩니다.
BigQuery 샌드박스는 다음을 비롯한 여러 BigQuery 기능을 지원하지 않습니다.
공개 데이터 세트 보기
BigQuery 공개 데이터 세트는 기본적으로 bigquery-public-data라는 프로젝트의 BigQuery Studio에서 사용할 수 있습니다. 이 튜토리얼에서는 NYC Citi Bike 운행 데이터 세트를 쿼리합니다. Citi Bike는 맨해튼, 브루클린, 퀸즈, 저지시티에 자전거 10,000대와 600개의 정차장을 보유한 대규모 자전거 공유 프로그램입니다. 이 데이터 세트에는 2013년 9월 Citi Bike가 설립된 이후의 Citi Bike 운행 정보가 포함되어 있습니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
왼쪽 창에서 탐색기를 클릭합니다.

왼쪽 창이 표시되지 않으면 왼쪽 창 펼치기를 클릭하여 창을 엽니다.
탐색기 창에서 데이터 추가를 클릭합니다.
데이터 추가 대화상자의 필터링 기준 창에서
 공개 데이터 세트를 클릭합니다.
공개 데이터 세트를 클릭합니다.Marketplace 페이지의 Marketplace 검색 필드에
NYC Citi Bike Trips를 입력하여 검색 범위를 좁힙니다.검색 결과에서 NYC Citi Bike Trips를 클릭합니다.
제품 세부정보 페이지에서 데이터 세트 보기를 클릭합니다. 세부정보 탭에서 데이터 세트에 관한 정보를 확인할 수 있습니다.
공개 데이터 세트 쿼리
다음 단계에서는 citibike_trips 테이블을 쿼리하여 NYC Citi Bike Trips 공개 데이터 세트에서 가장 인기 있는 Citi Bike 정거장 100개를 확인합니다.
이 쿼리는 역의 이름과 위치, 해당 역에서 시작된 이동 수를 가져옵니다.
이 쿼리는 ST_GEOGPOINT 함수를 사용하여 각 대여소의 경도 및 위도 매개변수에서 점을 만들고 GEOGRAPHY 열에 해당 점을 반환합니다. GEOGRAPHY 열은 통합된 지리 데이터 뷰어에서 히트맵을 생성하는 데 사용됩니다.
Google Cloud 콘솔에서 BigQuery 페이지를 엽니다.
SQL 쿼리 를 클릭합니다.쿼리 편집기 에서 다음 쿼리를 입력합니다.SELECT start_station_name, start_station_latitude, start_station_longitude, ST_GEOGPOINT(start_station_longitude, start_station_latitude) AS geo_location, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY 1, 2, 3 ORDER BY num_trips DESC LIMIT 100;쿼리가 유효하면 쿼리에서 처리할 데이터양과 함께 체크표시가 나타납니다. 쿼리가 유효하지 않으면 느낌표가 오류 메시지와 함께 표시됩니다.

실행 을 클릭합니다. 가장 인기 있는 방송국은쿼리 결과 섹션에 표시됩니다.
선택사항: 작업 기간과 쿼리 작업에서 처리한 데이터 양을 표시하려면 쿼리 결과 섹션에서 작업 정보 탭을 클릭합니다.
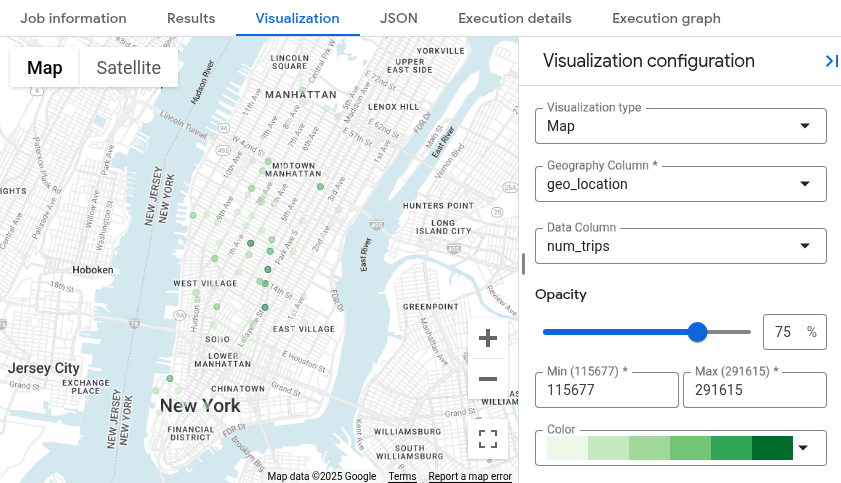
시각화 탭으로 전환합니다. 이 탭은 결과를 빠르게 시각화할 수 있는 지도를 생성합니다.시각화 구성 패널에서 다음을 수행합니다.
- 시각화 유형이 지도로 설정되어 있는지 확인합니다.
- 지역 열이
geo_location로 설정되어 있는지 확인합니다. - 데이터 열에서
num_trips을 선택합니다. - 확대 옵션을 사용하여 맨해튼 지도를 표시합니다.
BigQuery 샌드박스에서 업그레이드
BigQuery 샌드박스를 사용하면 제한된 BigQuery 기능을 무료로 사용해 볼 수 있습니다. 스토리지 용량을 늘리거나 더 많은 쿼리 기능을 사용할 준비가 되었다면 BigQuery 샌드박스에서 업그레이드하세요.
업그레이드하려면 다음 단계를 따르세요.
프로젝트에 결제를 사용 설정합니다.
BigQuery 버전을 살펴보고 적합한 가격 책정 모델을 결정합니다.
BigQuery 샌드박스에서 업그레이드한 후에는 테이블, 뷰, 파티션과 같은 BigQuery 리소스의 기본 만료 시간을 업데이트해야 합니다.
삭제
이 페이지에서 사용한 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 다음 단계를 수행합니다.
프로젝트 삭제
BigQuery 샌드박스를 사용하여 공개 데이터 세트를 쿼리한 경우에는 프로젝트에 결제가 사용 설정되지 않으므로 프로젝트를 삭제하지 않아도 됩니다.
비용이 청구되지 않도록 하는 가장 쉬운 방법은 튜토리얼에서 만든 프로젝트를 삭제하는 것입니다.
프로젝트를 삭제하는 방법은 다음과 같습니다.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
다음 단계
- 무료 사용량 등급에서 BigQuery를 무료로 사용하는 방법에 대한 자세한 내용은 무료 사용량 등급 참조하기
- BigQuery에서 데이터 세트를 만들고, 데이터를 로드하고, 테이블을 쿼리하는 방법을 알아봅니다.