Intégré aux tâches de requête, BigQuery inclut des informations de diagnostic sur le plan et la chronologie de la requête. Ces informations sont similaires à celles fournies par des instructions telles que EXPLAIN dans d'autres systèmes de bases de données et d'analyse. Ces informations peuvent être extraites des réponses d'API de méthodes telles que jobs.get.
BigQuery met régulièrement à jour ces statistiques pour les requêtes de longue durée. Ces mises à jour ont lieu indépendamment de la fréquence d'interrogation de l'état de la tâche. Elles sont généralement effectuées à des intervalles d'au moins 30 secondes. Par ailleurs, les tâches de requête qui n'utilisent pas de ressources d'exécution, telles que les requêtes de simulation ou les résultats pouvant être diffusés à partir de résultats mis en cache, n'incluent pas les informations de diagnostic supplémentaires. Cependant, d'autres statistiques peuvent être incluses.
Expérience
Lorsque BigQuery exécute une tâche de requête, il convertit l'instruction SQL déclarative en un graphe d'exécution divisé en une série de phases de requête. Ces dernières sont composées d'ensembles d'étapes d'exécution plus précis. BigQuery s'appuie sur une architecture parallèle fortement distribuée pour exécuter ces requêtes. Les phases modélisent les unités de travail que de nombreux nœuds de calcul potentiels peuvent exécuter en parallèle. Les phases communiquent entre elles à l'aide d'une architecture de brassage distribuée rapide.
Dans le plan de requête, les termes unités de travail et nœuds de calcul sont utilisés pour transmettre des informations spécifiques sur le parallélisme. Ailleurs dans BigQuery, vous pouvez rencontrer le terme emplacement, qui est une représentation abstraite des multiples attributs de l'exécution de requêtes, comme les ressources de calcul, de mémoire et d'E/S. Les statistiques d'une tâche de niveau supérieur fournissent une estimation du coût de la requête individuelle en utilisant l'estimation totalSlotMs de la requête à l'aide de cette comptabilité abstraite.
Autre caractéristique importante : l'architecture d'exécution des requêtes est dynamique, ce qui signifie que le plan de requête peut être modifié lorsqu'une requête est en cours d'exécution. Les phases introduites lors de l'exécution d'une requête permettent souvent d'améliorer la distribution des données au sein des nœuds de calcul de la requête. Dans les plans de requête où c'est le cas, ces phases sont généralement libellées en tant que phases de répartition.
En plus du plan de requête, les tâches de requête présentent également une chronologie d'exécution, qui fournit le compte des unités de travail réalisées, en attente et actives au sein des nœuds de calcul de la requête. Une requête peut comporter simultanément plusieurs phases avec des nœuds de calcul actifs, et la chronologie permet de montrer la progression globale de la requête.
Afficher des informations avec la console Google Cloud
Dans la console Google Cloud, vous pouvez afficher les détails du plan d'une requête terminée en cliquant sur Détails de l'exécution (près du bouton Résultats).
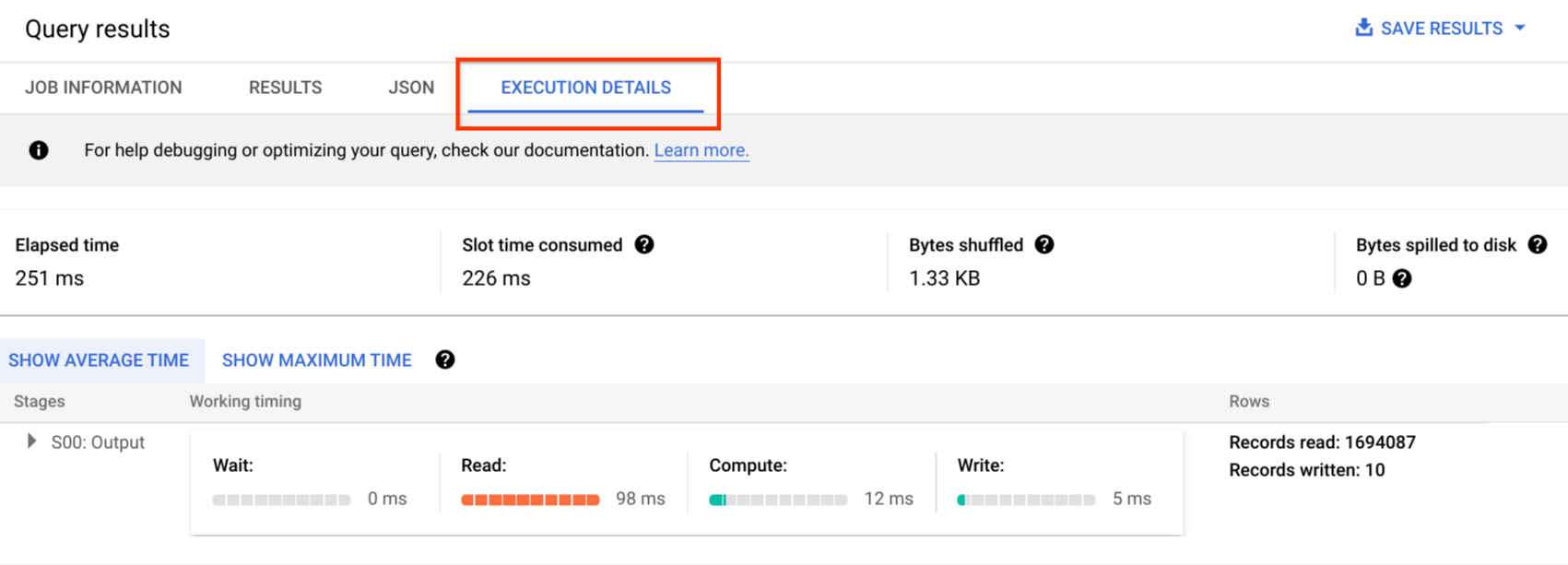
Informations sur le plan de requête
Dans la réponse de l'API, les plans de requête sont représentés sous la forme d'une liste de phases de requête. Chaque élément de la liste affiche des statistiques de présentation par phase, des informations détaillées sur chacune d'elles et une classification de leur durée. Tous les détails ne s'affichent pas dans la console Google Cloud, mais ils peuvent tous être présents dans les réponses de l'API.
Aperçu de la phase
Les champs d'aperçu de chaque phase peuvent inclure les éléments suivants :
| Champ de l'API | Description |
|---|---|
id |
ID numérique unique de la phase. |
name |
Nom simple résumant la phase. Les steps constituant la phase fournissent des informations supplémentaires sur les étapes d'exécution. |
status |
État d'exécution de la phase. Les états possibles incluent PENDING (EN ATTENTE), RUNNING (EN COURS D'EXÉCUTION), COMPLETE (TERMINÉE), FAILED (ÉCHOUÉE) et CANCELLED (ANNULÉE). |
inputStages |
Liste des ID qui forment le graphe de dépendance de la phase. Par exemple, une phase JOIN (jointure) nécessite souvent deux phases dépendantes qui préparent les données à gauche et à droite de la relation JOIN. |
startMs |
Horodatage en millisecondes d'itération qui représente le début de l'exécution du premier nœud de calcul au sein de la phase. |
endMs |
Horodatage en millisecondes d'itération qui représente la fin de l'exécution du dernier nœud de calcul. |
steps |
Liste plus détaillée des étapes d'exécution qui constituent la phase. Consultez la section suivante pour plus d'informations. |
recordsRead |
Taille d'entrée de la phase sous forme de nombre d'enregistrements pour tous les nœuds de calcul de la phase. |
recordsWritten |
Taille de sortie de la phase sous forme de nombre d'enregistrements pour tous les nœuds de calcul de la phase. |
parallelInputs |
Nombre d'unités de travail chargeables en parallèle pour la phase. En fonction de la phase et de la requête, représente le nombre de segments en colonnes dans une table ou le nombre de partitions dans un brassage intermédiaire. |
completedParallelInputs |
Nombre d'unités de travail de la phase qui ont été achevées. Pour certaines requêtes, il n'est pas nécessaire que toutes les entrées d'une phase soient achevées pour que la phase se termine. |
shuffleOutputBytes |
Représente le nombre total d'octets écrits pour tous les nœuds de calcul au sein d'une phase de requête. |
shuffleOutputBytesSpilled |
Les requêtes qui transmettent des données importantes entre les phases peuvent nécessiter un retour vers une transmission sur disque. La statistique d'octets répandus indique la quantité de données répandues sur le disque. Il dépend d'un algorithme d'optimisation. Il n'est donc pas déterministe pour une requête donnée. |
Informations sur les étapes par phase
Les étapes représentent les opérations plus précises que chaque nœud de calcul d'une phase doit exécuter. Elles sont présentées sous la forme d'une liste numérotée d'opérations. Les étapes sont classées par catégories, et certaines opérations fournissent des informations plus détaillées. Les catégories d'opérations présentes dans le plan de requête sont les suivantes :
| Étape | Description |
|---|---|
| READ | Lecture d'une ou plusieurs colonnes d'une table d'entrée ou d'un mélange intermédiaire. Seules les 16 premières colonnes lues sont renvoyées dans les détails de l'étape. |
| WRITE | Écriture d'une ou plusieurs colonnes dans une table de sortie ou un résultat intermédiaire. Pour les sorties d'une phase partitionnées en hachage, cela inclut également les colonnes servant de clé de partition. |
| COMPUTE | Opérations telles que l'évaluation des expressions et les fonctions SQL. |
| FILTER | Opérateur mettant en œuvre les clauses WHERE, OMIT IF et HAVING. |
| SORT | Opération "Trier" ou "Trier par", clés des colonnes et direction comprises. |
| AGGREGATE | Opération d'agrégation, telle que GROUPER PAR ou COMPTER. |
| LIMIT | Opérateur mettant en œuvre la clause LIMIT. |
| JOIN | Opération JOIN qui inclut le type de jointure et les colonnes utilisées. |
| ANALYTIC_FUNCTION | Invocation d'une fonction de fenêtrage (également appelée "fonction analytique"). |
| USER_DEFINED_FUNCTION | Appel d'une fonction définie par l'utilisateur. |
Classification des durées par phase
Les phases de requête fournissent également des classifications de durées des phases, sous forme relative et absolue. Chaque phase d'exécution correspondant à un travail effectué par un ou plusieurs nœuds de calcul, ces informations concernent à la fois la durée moyenne et la durée la moins bonne. Ces durées représentent les performances moyennes de tous les nœuds de calcul d'une phase, ainsi que les exécutions des nœuds de calcul les plus lentes pour une classification donnée. Les durées moyennes et maximales sont en outre divisées en représentations absolues et relatives. Pour les statistiques basées sur les ratios, les données sont fournies sous forme de fraction de la durée la plus longue passée par un nœud de calcul dans un segment quelconque.
La console Google Cloud présente la durée des phases à l'aide de représentations temporelles relatives.
Les informations relatives à la durée des phases sont présentées comme suit :
| Durée relative | Durée absolue | Numérateur de taux |
|---|---|---|
waitRatioAvg |
waitMsAvg |
Temps passé par le nœud de calcul moyen à attendre d'être planifié. |
waitRatioMax |
waitMsMax |
Temps passé par le nœud de calcul le plus lent à attendre d'être planifié. |
readRatioAvg |
readMsAvg |
Temps passé par le nœud de calcul moyen à lire les données d'entrée. |
readRatioMax |
readMsMax |
Temps passé par le nœud de calcul le plus lent à lire les données d'entrée. |
computeRatioAvg |
computeMsAvg |
Temps passé par le nœud de calcul moyen à être lié au processeur. |
computeRatioMax |
computeMsMax |
Temps passé par le nœud de calcul le plus lent à être lié au processeur. |
writeRatioAvg |
writeMsAvg |
Temps passé par le nœud de calcul moyen à écrire les données de sortie. |
writeRatioMax |
writeMsMax |
Temps passé par le nœud de calcul le plus lent à écrire les données de sortie. |
Explication pour les requêtes fédérées
Les requêtes fédérées vous permettent d'envoyer une instruction de requête à une source de données externe à l'aide de la fonction EXTERNAL_QUERY.
Les requêtes fédérées sont soumises à la technique d'optimisation appelée pushdown SQL, et le plan de requête affiche les opérations transmises à la source de données externe, le cas échéant.
Par exemple, si vous exécutez la requête suivante :
SELECT id, name
FROM EXTERNAL_QUERY("<connection>", "SELECT * FROM company")
WHERE country_code IN ('ee', 'hu') AND name like '%TV%'
Le plan de requête affiche les étapes suivantes :
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, country_code
FROM (
/*native_query*/
SELECT * FROM company
)
WHERE in(country_code, 'ee', 'hu')
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
Dans ce plan, table_for_external_query_$_0(...) représente la fonction EXTERNAL_QUERY. La requête exécutée par la source de données externe est entre parenthèses. Sur cette base, vous pouvez constater les éléments suivants :
- Une source de données externe ne renvoie que trois colonnes sélectionnées.
- Une source de données externe ne renvoie que les lignes pour lesquelles
country_codecorrespond à'ee'ou'hu'. - L'opérateur
LIKEn'est pas transmis et est évalué par BigQuery.
À des fins de comparaison, s'il n'y a pas de pushdown, le plan de requête affiche les étapes suivantes :
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, description, country_code, primary_address, secondary address
FROM (
/*native_query*/
SELECT * FROM company
)
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
Cette fois, une source de données externe renvoie toutes les colonnes et toutes les lignes de la table company, et BigQuery effectue le filtrage.
Métadonnées de chronologie
La chronologie de la requête indique les progrès réalisés à des moments précis et fournit des aperçus instantanés de la progression globale de la requête. La chronologie est représentée par une série d'échantillons qui indiquent les informations suivantes :
| Champ | Description |
|---|---|
elapsedMs |
Millisecondes écoulées depuis le début de l'exécution de la requête. |
totalSlotMs |
Représentation cumulée des intervalles de millisecondes utilisés par la requête. |
pendingUnits |
Nombre total d'unités de travail planifiées et en attente d'exécution. |
activeUnits |
Nombre total d'unités de travail actives en cours de traitement par les nœuds de calcul. |
completedUnits |
Nombre total d'unités de travail effectuées lors de l'exécution de cette requête. |
Exemple de requête
La requête suivante compte le nombre de lignes de l'ensemble de données public Shakespeare et comporte un deuxième compteur conditionnel qui limite les résultats aux lignes faisant référence à "hamlet" :
SELECT
COUNT(1) as rowcount,
COUNTIF(corpus = 'hamlet') as rowcount_hamlet
FROM `publicdata.samples.shakespeare`
Cliquez sur Execution details (Détails d'exécution) pour afficher le plan de requête :
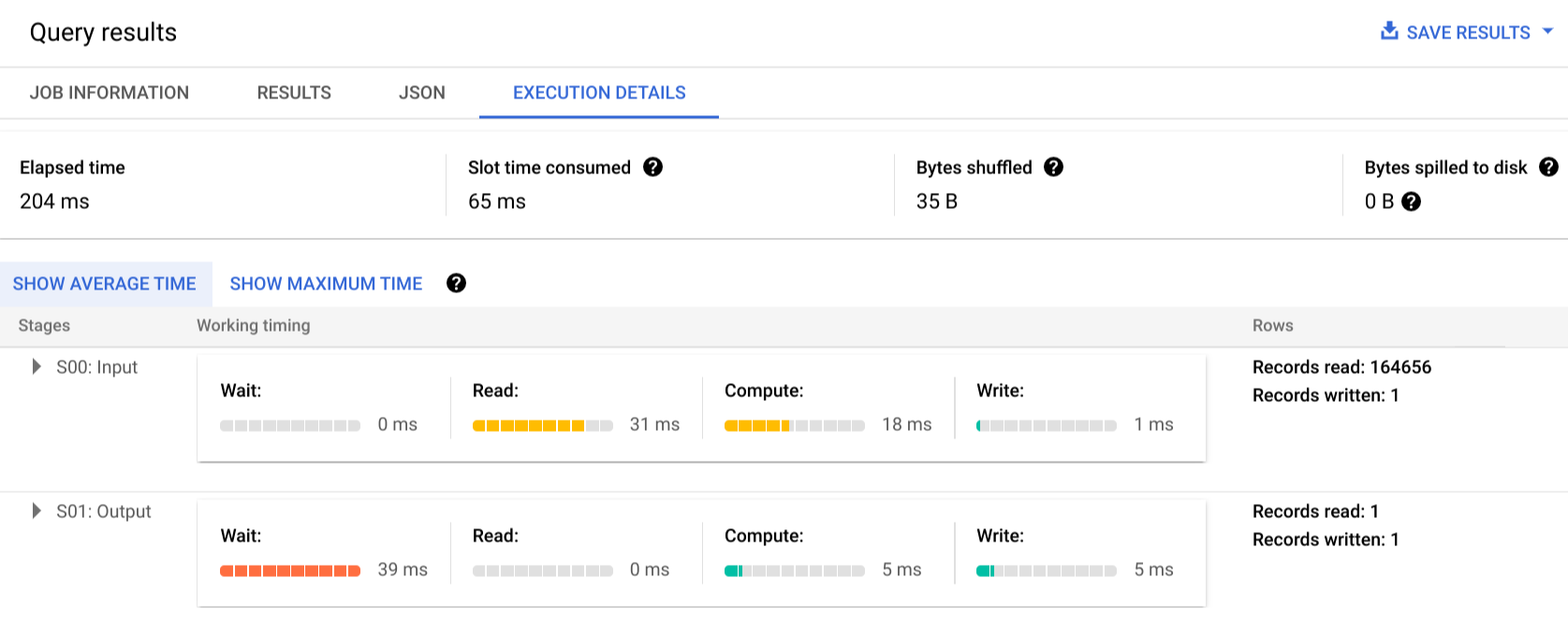
Les indicateurs de couleur affichent les temps relatifs correspondant à chaque étape de chaque phase.
Pour en savoir plus sur les étapes des phases d'exécution, cliquez sur pour développer les détails de la phase :
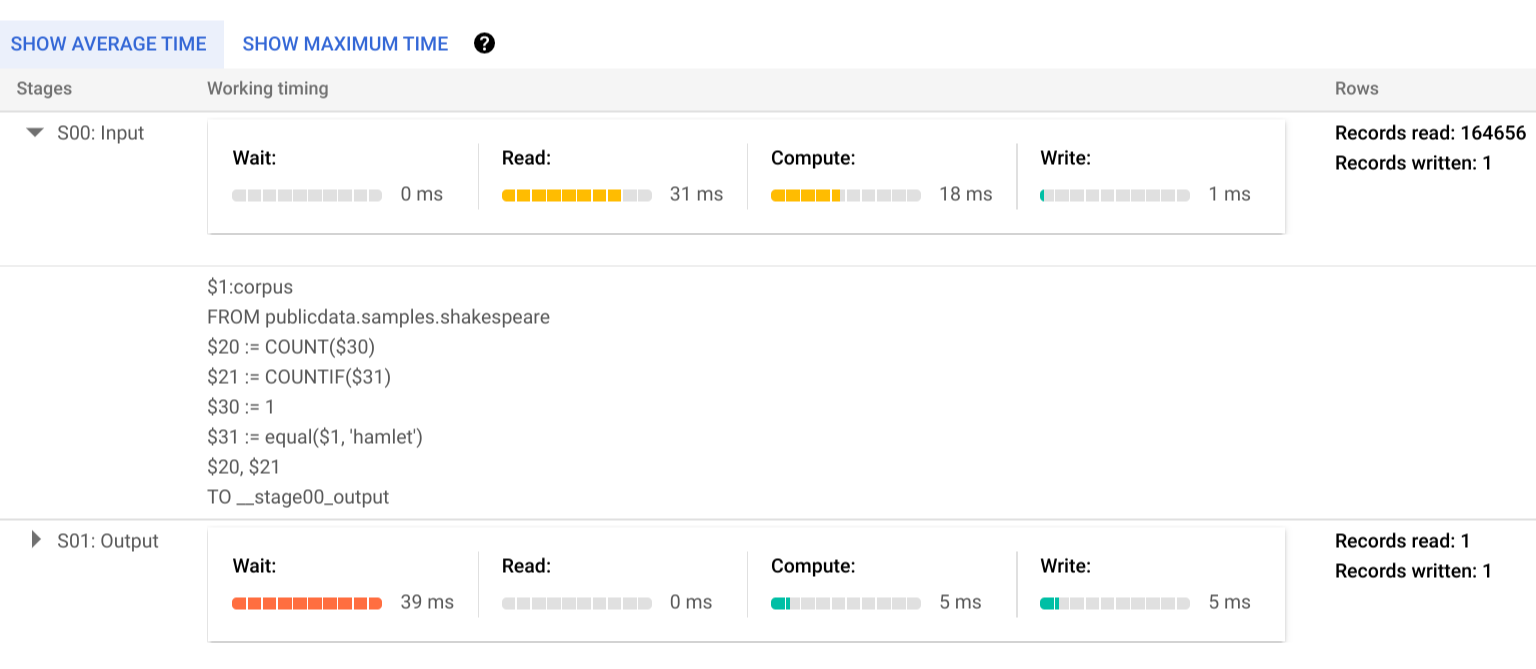
Dans cet exemple, la durée de segment la plus longue correspond au temps passé par le seul nœud de calcul de la phase 01 à attendre que la phase 00 se termine. Cela est dû au fait que la phase 01 est dépendante de l'entrée de la phase 00 et n'a pas pu démarrer tant que la première phase n'avait pas écrit sa sortie en brassage intermédiaire.
Les rapports d'erreur
Il est possible que les tâches de requête échouent en cours d'exécution. Les informations du plan étant régulièrement mises à jour, vous pouvez observer où l'échec a eu lieu sur le graphe d'exécution. Dans la console Google Cloud, les étapes réussies ou échouées sont identifiées par une coche ou un point d'exclamation situés à côté du nom de la phase.
Pour plus d'informations sur l'interprétation et la résolution des erreurs, consultez le guide de dépannage.
Exemple de représentation de l'API
Les informations du plan de requête sont intégrées dans les informations de réponse de la tâche. Elles peuvent être extraites simplement en appelant jobs.get. Par exemple, l'extrait suivant d'une réponse JSON d'une tâche renvoyant l'échantillon de requête "hamlet" affiche à la fois le plan de la requête et les informations sur la chronologie.
"statistics": {
"creationTime": "1576544129234",
"startTime": "1576544129348",
"endTime": "1576544129681",
"totalBytesProcessed": "2464625",
"query": {
"queryPlan": [
{
"name": "S00: Input",
"id": "0",
"startMs": "1576544129436",
"endMs": "1576544129465",
"waitRatioAvg": 0.04,
"waitMsAvg": "1",
"waitRatioMax": 0.04,
"waitMsMax": "1",
"readRatioAvg": 0.32,
"readMsAvg": "8",
"readRatioMax": 0.32,
"readMsMax": "8",
"computeRatioAvg": 1,
"computeMsAvg": "25",
"computeRatioMax": 1,
"computeMsMax": "25",
"writeRatioAvg": 0.08,
"writeMsAvg": "2",
"writeRatioMax": 0.08,
"writeMsMax": "2",
"shuffleOutputBytes": "18",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "164656",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$1:corpus",
"FROM publicdata.samples.shakespeare"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$20 := COUNT($30)",
"$21 := COUNTIF($31)"
]
},
{
"kind": "COMPUTE",
"substeps": [
"$30 := 1",
"$31 := equal($1, 'hamlet')"
]
},
{
"kind": "WRITE",
"substeps": [
"$20, $21",
"TO __stage00_output"
]
}
]
},
{
"name": "S01: Output",
"id": "1",
"startMs": "1576544129465",
"endMs": "1576544129480",
"inputStages": [
"0"
],
"waitRatioAvg": 0.44,
"waitMsAvg": "11",
"waitRatioMax": 0.44,
"waitMsMax": "11",
"readRatioAvg": 0,
"readMsAvg": "0",
"readRatioMax": 0,
"readMsMax": "0",
"computeRatioAvg": 0.2,
"computeMsAvg": "5",
"computeRatioMax": 0.2,
"computeMsMax": "5",
"writeRatioAvg": 0.16,
"writeMsAvg": "4",
"writeRatioMax": 0.16,
"writeMsMax": "4",
"shuffleOutputBytes": "17",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "1",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$20, $21",
"FROM __stage00_output"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$10 := SUM_OF_COUNTS($20)",
"$11 := SUM_OF_COUNTS($21)"
]
},
{
"kind": "WRITE",
"substeps": [
"$10, $11",
"TO __stage01_output"
]
}
]
}
],
"estimatedBytesProcessed": "2464625",
"timeline": [
{
"elapsedMs": "304",
"totalSlotMs": "50",
"pendingUnits": "0",
"completedUnits": "2"
}
],
"totalPartitionsProcessed": "0",
"totalBytesProcessed": "2464625",
"totalBytesBilled": "10485760",
"billingTier": 1,
"totalSlotMs": "50",
"cacheHit": false,
"referencedTables": [
{
"projectId": "publicdata",
"datasetId": "samples",
"tableId": "shakespeare"
}
],
"statementType": "SELECT"
},
"totalSlotMs": "50"
},
Utiliser les informations d'exécution
Les plans de requête BigQuery fournissent des informations sur la manière dont le service exécute les requêtes, mais la nature gérée du service limite la possibilité d'exploiter directement certaines informations. De nombreuses optimisations sont effectuées automatiquement lors de l'utilisation du service, ce qui peut différer d'autres environnements où le réglage, l'approvisionnement et la surveillance nécessitent un personnel spécialisé et qualifié.
Pour connaître les techniques spécifiques susceptibles d'améliorer l'exécution et les performances des requêtes, consultez la documentation sur les bonnes pratiques. Les statistiques du plan et de la chronologie de requête peuvent vous aider à savoir si certaines phases utilisent davantage de ressources. Par exemple, une phase JOIN qui génère beaucoup plus de lignes de sortie que de lignes d'entrée peut indiquer la possibilité de filtrer plus tôt dans la requête.
En outre, les informations de chronologie peuvent permettre de savoir si une requête donnée est lente par elle-même ou à cause des effets d'autres requêtes en concurrence pour les mêmes ressources. Si le nombre d'unités actives reste limité tout au long de la durée de la requête, alors que le nombre d'unités de travail en file d'attente reste élevé, la réduction du nombre de requêtes simultanées peut considérablement améliorer le temps global d'exécution de certaines requêtes.