Introduction to the BigQuery Storage Write API
The BigQuery Storage Write API is a unified data-ingestion API for BigQuery. It combines streaming ingestion and batch loading into a single high-performance API. You can use the Storage Write API to stream records into BigQuery in real time or to batch process an arbitrarily large number of records and commit them in a single atomic operation.
Advantages of using the Storage Write API
Exactly-once delivery semantics. The Storage Write API supports
exactly-once semantics through the use of stream offsets. Unlike the
tabledata.insertAll method, the Storage Write API never writes two
messages that have the same offset within a stream, if the client provides
stream offsets when appending records.
Stream-level transactions. You can write data to a stream and commit the data as a single transaction. If the commit operation fails, you can safely retry the operation.
Transactions across streams. Multiple workers can create their own streams to process data independently. When all the workers have finished, you can commit all of the streams as a transaction.
Efficient protocol. The Storage Write API is more efficient than
the legacy insertAll method because it uses gRPC streaming rather than REST
over HTTP. The Storage Write API also supports the protocol buffer
binary format and the Apache Arrow columnar format,
which are a more efficient wire format than JSON. Write requests are asynchronous
with guaranteed ordering.
Schema update detection. If the underlying table schema changes while the client is streaming, then the Storage Write API notifies the client. The client can decide whether to reconnect using the updated schema, or continue to write to the existing connection.
Lower cost. The Storage Write API has a significantly lower cost
than the older insertAll streaming API. In addition, you can ingest up to
2 TiB per month for free.
Required permissions
To use the Storage Write API, you must have
bigquery.tables.updateData permissions.
The following predefined Identity and Access Management (IAM) roles include
bigquery.tables.updateData permissions:
bigquery.dataEditorbigquery.dataOwnerbigquery.admin
For more information about IAM roles and permissions in BigQuery, see Predefined roles and permissions.
Authentication scopes
Using the Storage Write API requires one of the following OAuth scopes:
https://www.googleapis.com/auth/bigqueryhttps://www.googleapis.com/auth/cloud-platformhttps://www.googleapis.com/auth/bigquery.insertdata
For more information, see the Authentication Overview.
Overview of the Storage Write API
The core abstraction in the Storage Write API is a stream. A stream writes data to a BigQuery table. More than one stream can write concurrently to the same table.
Default stream
The Storage Write API provides a default stream, designed for streaming scenarios where you have continuously arriving data. It has the following characteristics:
- Data written to the default stream is available immediately for query.
- The default stream supports at-least-once semantics.
- You don't need to explicitly create the default stream.
If you are migrating from the legacy
tabledata.insertall API, consider
using the default stream. It has similar write semantics, with greater data
resiliency and fewer scaling restrictions.
API flow:
AppendRows(loop)
For more information and example code, see Use the default stream for at-least-once semantics.
Application-created streams
You can explicitly create a stream if you need either of the following behaviors:
- Exactly-once write semantics through the use of stream offsets.
- Support for additional ACID properties.
In general, application-created streams give more control over functionality at the cost of additional complexity.
When you create a stream, you specify a type. The type controls when data written to the stream becomes visible in BigQuery for reading.
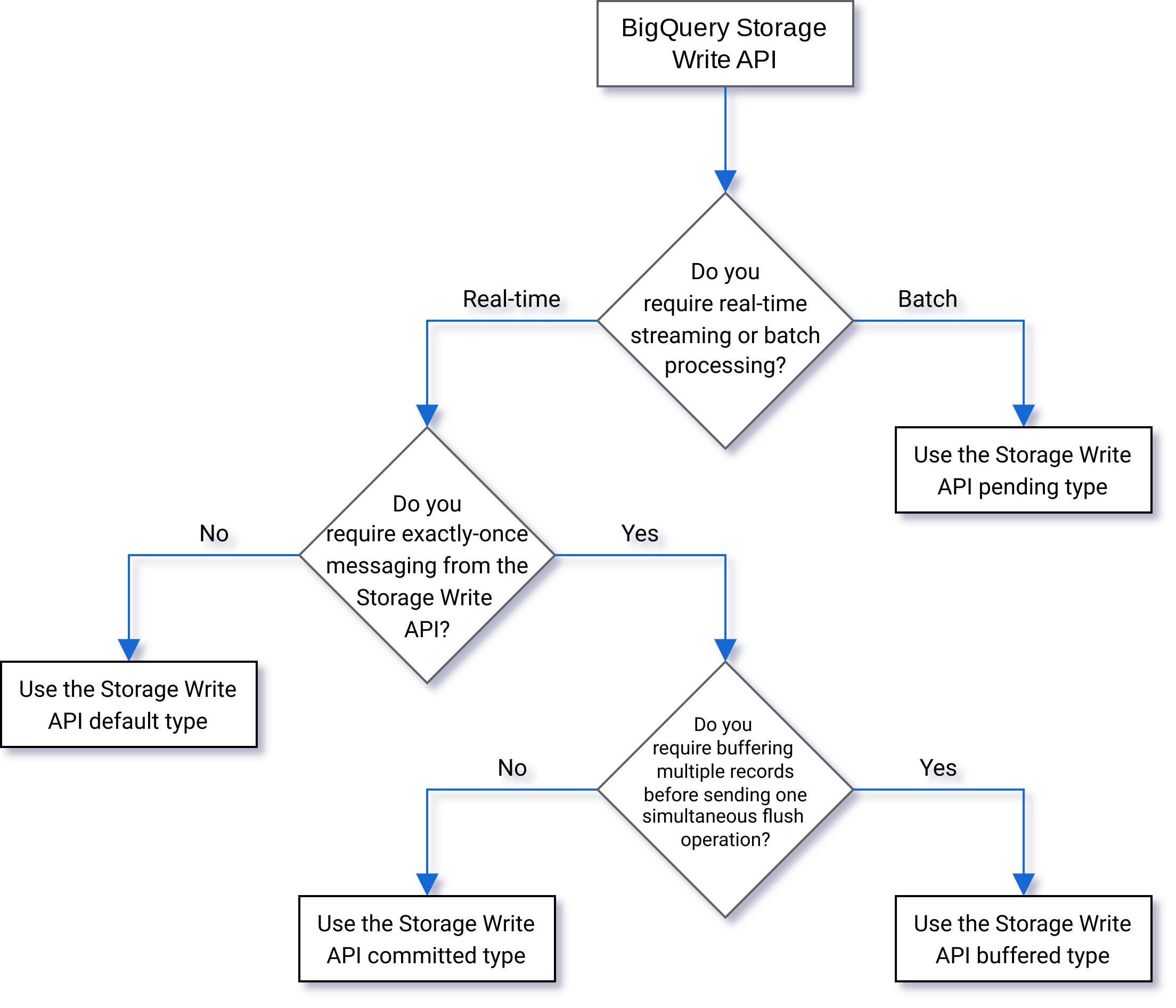
Pending type
In pending type, records are buffered in a pending state until you commit the stream. When you commit a stream, all of the pending data becomes available for reading. The commit is an atomic operation. Use this type for batch workloads, as an alternative to BigQuery load jobs. For more information, see Batch load data using the Storage Write API.
API flow:
Committed type
In committed type, records are available for reading immediately as you write them to the stream. Use this type for streaming workloads that need minimal read latency. The default stream uses an at-least-once form of the committed type. For more information, see Use committed type for exactly-once semantics.
API flow:
CreateWriteStreamAppendRows(loop)FinalizeWriteStream(optional)
Buffered type
Buffered type is an advanced type that should generally not be used, except with the Apache Beam BigQuery I/O connector. If you have small batches that you want to guarantee appear together, use committed type and send each batch in one request. In this type, row-level commits are provided, and records are buffered until the rows are committed by flushing the stream.
API flow:
CreateWriteStreamAppendRows⇒FlushRows(loop)FinalizeWriteStream(optional)
Selecting a type
Use the following flow chart to help you decide which type is best for your workload:
API details
Consider the following when you use the Storage Write API:
AppendRows
The AppendRows method appends one or more records to the stream. The first
call to AppendRows must contain a stream name along with the data schema,
specified as a DescriptorProto. Alternatively,
you can add a serialized arrow schema in the first call to AppendRows if you
are ingesting data in the Apache Arrow format. As a best practice, send a batch of
rows in each AppendRows call. Don't send one row at a time.
Proto Buffer Handling
Protocol buffers provide a language-neutral, platform-neutral, extensible mechanism for serializing structured data in a forward-compatible and backward-compatible way. They are advantageous in that they provide compact data storage with fast and efficient parsing. To learn more about protocol buffers, see Protocol Buffer Overview.
If you are going to consume the API directly with a pre-defined protocol buffer
message, the protocol buffer message cannot use a package specifier, and all
nested or enumeration types must be defined within the top-level root message.
References to external messages are not allowed. For an example, see
sample_data.proto.
The Java and Go clients support arbitrary protocol buffers, because the client library normalizes the protocol buffer schema.
Apache Arrow Handling
To give feedback or request support for this feature, contact bq-write-api-feedback@google.com.
Apache Arrow is a universal columnar format and multi-language toolbox for data
processing. Apache Arrow provides a language-independent column-oriented memory
format for flat and hierarchical data, organized for efficient analytic
operations on modern hardware. To learn more about Apache Arrow, see Apache Arrow.
The Storage Write API supports Arrow ingestion using serialized arrow
schema and data in the AppendRowsRequest class.
The python client library includes built-in support for Apache Arrow
ingestion. Other languages might require calling the raw AppendRows API to
ingest data in the Apache Arrow format.
FinalizeWriteStream
The FinalizeWriteStream method finalizes the stream so that no new data can be
appended to it. This method is required in
Pending type and optional in
Committed and
Buffered types. The default stream does not
support this method.
Error handling
If an error occurs, the returned google.rpc.Status can include a
StorageError in the
error details. Review the
StorageErrorCode for find the specific error type. For
more information about the Google API error model, see
Errors.
Connections
The Storage Write API is a gRPC API that uses bidirectional
connections. The AppendRows method creates a connection to a stream. You can
open multiple connections on the default stream. These appends are asynchronous,
which lets you send a series of writes simultaneously. Response
messages on each bidirectional connection arrive in the same order as the
requests were sent.
Application-created streams can only have a single active connection. As a best practice, limit the number of active connections, and use one connection for as many data writes as possible. When using the default stream in Java or Go, you can use Storage Write API multiplexing to write to multiple destination tables with shared connections.
Generally, a single connection supports at least 1 MBps of throughput. The upper bound depends on several factors, such as network bandwidth, the schema of the data, and server load. When a connection reaches the throughput limit, incoming requests might be rejected or queued until the number of inflight requests goes down. If you require more throughput, create more connections.
BigQuery closes the gRPC connection if the connection remains
idle for too long. If this happens, the response code is HTTP 409. The gRPC
connection can also be closed in the event of a server restart or for other
reasons. If a connection error occurs, create a new connection. The Java and Go
client libraries automatically reconnect if the connection is closed.
Client library support
Client libraries for the Storage Write API exist in multiple programming languages, and expose the underlying gRPC-based API constructs. This API leverages advanced features like bidirectional streaming, which may necessitate additional development work to support. To that end, a number of higher level abstractions are available for this API which simplify those interactions and reduce developer concerns. We recommend leveraging these other library abstractions when possible.
This section provides additional details about languages and libraries where additional capabilities beyond the generated API has been provided to developers.
To see code samples related to the Storage Write API, see All BigQuery code samples.
Java client
The Java client library provides two writer objects:
StreamWriter: Accepts data in protocol buffer format.JsonStreamWriter: Accepts data in JSON format and converts it to protocol buffers before sending it over the wire. TheJsonStreamWriteralso supports automatic schema updates. If the table schema changes, the writer automatically reconnects with the new schema, allowing the client to send data using the new schema.
The programming model is similar for both writers. The main difference is how you format the payload.
The writer object manages a Storage Write API connection. The writer object automatically cleans up requests, adds the regional routing headers to requests, and reconnects after connection errors. If you use the gRPC API directly, you must handle these details.
Go client
The Go client uses a client-server architecture to encode messages within protocol buffer format using proto2. See the Go documentation for details on how to use the Go client, with example code.
Python client
The Python client is a lower-level client that wraps the gRPC API. To use this client, you must send the data as protocol buffers, following the API flow for your specified type.
Avoid using dynamic proto message generation in Python as the performance of that library is substandard.
To learn more about using protocol buffers with Python, read the Protocol buffer basics in Python tutorial.
You can also use the Apache Arrow ingestion format as an alternative protocol to ingest data using the Storage Write API. For more information, see Use the Apache Arrow format to ingest data.
NodeJS client
The NodeJS client library accepts JSON input and provides automatic reconnect support. See the documentation for details on how to use the client.
Handle unavailability
Retrying with exponential backoff can mitigate random errors and brief periods of service unavailability, but to avoid dropping rows during extended unavailability requires more thought. In particular, if a client is persistently unable to insert a row, what should it do?
The answer depends on your requirements. For example, if BigQuery is being used for operational analytics where some missing rows are acceptable, then the client can give up after a few retries and discard the data. If, instead, every row is crucial to the business, such as with financial data, then you need to have a strategy to persist the data until it can be inserted later.
One common way to deal with persistent errors is to publish the rows to a Pub/Sub topic for later evaluation and possible insertion. Another common method is to temporarily persist the data on the client. Both methods can keep clients unblocked while at the same time ensuring that all rows can be inserted once availability is restored.
Stream into partitioned tables
The Storage Write API supports streaming data into partitioned tables.
When the data is streamed, it is initially placed in the __UNPARTITIONED__
partition. After enough unpartitioned data is collected, BigQuery
repartitions the data, placing it into the appropriate partition.
However, there is no service level agreement (SLA) that defines how long it
might take for that data to move out of the __UNPARTITIONED__ partition.
For ingestion-time partitioned and
time-unit column partitioned tables,
unpartitioned data can be excluded from a query by filtering out the NULL
values from the __UNPARTITIONED__ partition by using one of the pseudocolumns
(_PARTITIONTIME or _PARTITIONDATE
depending on your preferred data type).
Ingestion-time partitioning
When you stream to an ingestion-time partitioned table, the Storage Write API infers the destination partition from the current system UTC time.
If you're streaming data into a daily partitioned table, then you can override
the date inference by supplying a partition decorator as part of the request.
Include the decorator in the tableID parameter. For example, you can stream to
the partition corresponding to 2025-06-01 for table table1 using the
table1$20250601 partition decorator.
When streaming with a partition decorator, you can stream to partitions from 31 days in the past to 16 days in the future. To write to partitions for dates outside these bounds, use a load or query job instead, as described in Write data to a specific partition.
Streaming using a partition decorator is only supported for daily partitioned tables with default streams, not for hourly, monthly, or yearly partitioned tables, or application-created streams.
Time-unit column partitioning
When you stream to a time-unit column partitioned table,
BigQuery automatically puts the data into the correct partition
based on the values of the table's predefined DATE, DATETIME, or TIMESTAMP
partitioning column. You can stream data into a time-unit column partitioned
table if the data referenced by the partitioning column is between 10 years in
the past and 1 year in the future.
Integer-range partitioning
When you stream to an integer-range partitioned
table, BigQuery automatically puts the data into the correct
partition based on the values of the table's predefined INTEGER partitioning
column.
Fluent Bit Storage Write API output plugin
The Fluent Bit Storage Write API output plugin automates the process of ingesting JSON records into BigQuery, eliminating the need for you to write code. With this plugin, you only need to configure a compatible input plugin and set up a configuration file to begin streaming data. Fluent Bit is an open-source and cross-platform log processor and forwarder that uses input and output plugins to handle different types of data sources and sinks.
This plugin supports the following:
- At-least-once semantics using the default type.
- Exactly-once semantics using the committed type.
- Dynamic scaling for default streams, when backpressure is indicated.
Storage Write API project metrics
For metrics to monitor your data ingestion with the
Storage Write API, use the
INFORMATION_SCHEMA.WRITE_API_TIMELINE view
or see
Google Cloud metrics.
Use data manipulation language (DML) with recently streamed data
You can use data manipulation language (DML), such as the UPDATE, DELETE, or
MERGE statements, to modify rows that were recently written to a BigQuery
table by the BigQuery Storage Write API. Recent writes are those that occurred
within the last 30 minutes.
For more information about using DML to modify your streamed data, see Using data manipulation language.
Limitations
- Support for running mutating DML statements against recently streamed data does not extend to data streamed using the insertAll streaming API.
- Running mutating DML statements within a multi-statement transaction against recently streamed data is unsupported.
Storage Write API quotas
For information about Storage Write API quotas and limits, see BigQuery Storage Write API quotas and limits.
You can monitor your concurrent connections and throughput quota usage in the Google Cloud console Quotas page.
Calculate throughput
Suppose your goal is to collect logs from 100 million endpoints
creating a 1,500 log record per minute. Then, you can estimate the throughput as
100 million * 1,500 / 60 seconds = 2.5 GB per second.
You must ensure in advance that you have adequate quota to serve this throughput.
Storage Write API pricing
For pricing, see Data ingestion pricing.
Example use case
Suppose that there is a pipeline processing event data from endpoint logs. Events are generated continuously and need to be available for querying in BigQuery as soon as possible. As data freshness is paramount for this use case, the Storage Write API is the best choice to ingest data into BigQuery. A recommended architecture to keep these endpoints lean is sending events to Pub/Sub, from where they are consumed by a streaming Dataflow pipeline which directly streams to BigQuery.
A primary reliability concern for this architecture is how to deal with failing to insert a record into BigQuery. If each record is important and cannot be lost, data needs to be buffered before attempting to insert. In the recommended architecture above, Pub/Sub can play the role of a buffer with its message retention capabilities. The Dataflow pipeline should be configured to retry BigQuery streaming inserts with truncated exponential backoff. After the capacity of Pub/Sub as a buffer is exhausted, for example in the case of prolonged unavailability of BigQuery or a network failure, data needs to be persisted on the client and the client needs a mechanism to resume inserting persisted records once availability is restored. For more information about how to handle this situation, see the Google Pub/Sub Reliability Guide blog post.
Another failure case to handle is that of a poison record. A poison record is either a record rejected by BigQuery because the record fails to insert with a non-retryable error or a record that has not been successfully inserted after the maximum number of retries. Both types of records should be stored in a "dead letter queue" by the Dataflow pipeline for further investigation.
If exactly-once semantics are required, create a write stream in committed type, with record offsets provided by the client. This avoids duplicates, as the write operation is only performed if the offset value matches the next append offset. Not providing an offset means records are appended to the current end of the stream and retrying a failed append could result in the record appearing more than once in the stream.
If exactly-once guarantees are not required, writing to the default stream allows for a higher throughput and also does not count against the quota limit on creating write streams.
Estimate the throughput of your network and ensure in advance that you have an adequate quota to serve the throughput.
If your workload is generating or processing data at a very uneven rate, then
try to smooth out any load spikes on the client and stream into
BigQuery with a constant throughput. This can simplify your
capacity planning. If that is not possible, ensure you are prepared to handle
429 (resource exhausted) errors if and when your throughput goes over quota
during short spikes.
For a detailed example of how to use the Storage Write API, see Stream data using the Storage Write API.
What's next
- Stream data using the Storage Write API
- Batch load data using the Storage Write API
- Supported protocol buffer and Arrow data types
- Storage Write API best practices