BigQuery Storage Write API 简介
BigQuery Storage Write API 是适用于 BigQuery 的统一数据注入 API。它将流式注入和批量加载整合到一个高性能 API 中。您可以使用 Storage Write API 实时地将记录流式传输到 BigQuery 中,也可以批量处理任意数量的记录并在单个原子操作中提交记录。
使用 Storage Write API 的优势
正好传送一次语义。Storage Write API 支持通过使用流偏移量实现正好传送一次语义。与 tabledata.insertAll 方法不同,如果客户端在附加记录时提供流偏移量,则 Storage Write API 绝不会在一个流中写入两条偏移量相同的消息。
流级事务。您可以将数据写入流并以单个事务的形式提交数据。如果提交操作失败,您可以安全地重试操作。
跨流事务。多个工作器可以创建自己的流以便独立处理数据。当所有工作器都完成后,您可以将所有流作为事务提交。
高效协议。与旧的 insertAll 方法相比,Storage Write API 更高效,因为它使用 gRPC 流式传输而不是 REST over HTTP。Storage Write API 还支持协议缓冲区二进制格式和 Apache Arrow 列式格式,这两种格式比 JSON 更高效。写入请求是异步的,同时保证了排序。
架构更新检测。如果底层表架构在客户端进行流式传输时发生更改,则 Storage Write API 会通知客户端。客户端可以决定是使用更新后的架构重新连接,还是继续向现有连接写入数据。
成本更低。Storage Write API 的费用远低于旧版 insertAll 流式 API。此外,您每月可以免费注入高达 2 TiB 的数据。
所需权限
如需使用 Storage Write API,您必须具有 bigquery.tables.updateData 权限。
以下预定义的 Identity and Access Management (IAM) 角色包含 bigquery.tables.updateData 权限:
bigquery.dataEditorbigquery.dataOwnerbigquery.admin
如需详细了解 BigQuery 中的 IAM 角色和权限,请参阅预定义的角色和权限。
身份验证范围
使用 Storage Write API 需要以下 OAuth 范围之一:
https://www.googleapis.com/auth/bigqueryhttps://www.googleapis.com/auth/cloud-platformhttps://www.googleapis.com/auth/bigquery.insertdata
如需了解详情,请参阅身份验证概览。
Storage Write API 概览
Storage Write API 中的核心抽象为流。系统通过流将数据写入 BigQuery 表。多个流可以并发写入同一个表。
默认流
Storage Write API 提供默认流,适用于数据不断到达的流式场景。它具有以下特征:
- 写入默认流的数据可立即用于查询。
- 默认流支持“至少一次”语义。
- 您无需明确创建默认流。
如果您要从旧版 tabledata.insertall API 进行迁移,请考虑使用默认流。它可提供类似的写入语义,并且具备更高的数据弹性和更少的扩缩限制。
API 流:
AppendRows(循环)
如需了解详情和相关的示例代码,请参阅使用默认流实现“至少一次”语义。
应用创建的流
如果您需要以下任一行为,则可以明确创建流:
- 通过使用流偏移量实现“正好一次”写入语义。
- 支持其他 ACID 属性。
通常,应用创建的流可以更好地控制功能,但代价是会增加复杂性。
创建流时,您需要指定一个类型。 该类型控制写入流的数据在 BigQuery 中何时可见以供读取。
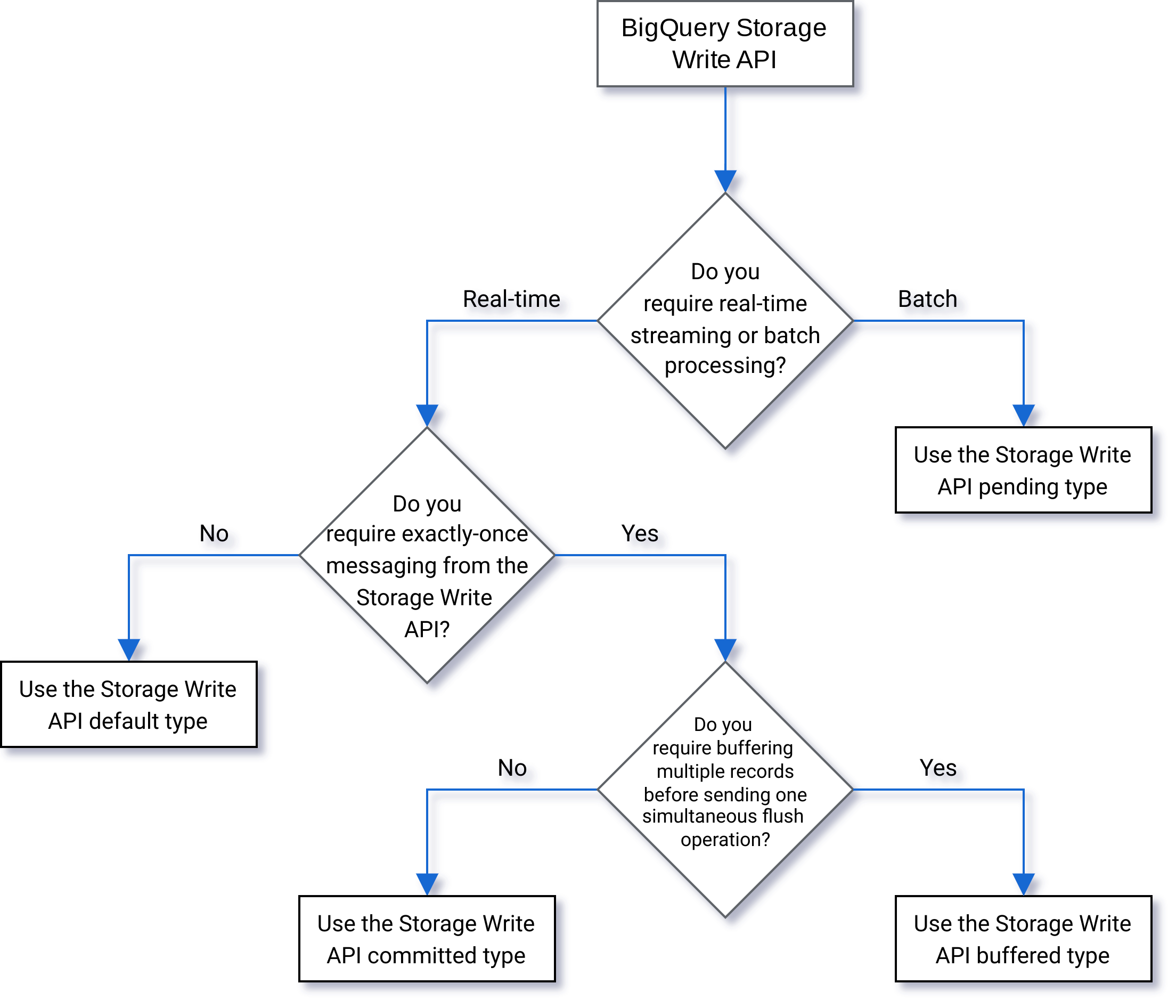
待处理类型
在待处理类型中,在您提交流之前,记录会一直缓冲在待处理状态。提交流后,所有待处理数据都可供读取。提交属于原子操作。此类型适用于批量工作负载,作为 BigQuery 加载作业的替代方案。如需了解详情,请参阅使用 Storage Write API 批量加载数据。
API 流:
已提交类型
在已提交类型中,当您将记录写入流时,记录便立即可供读取。此类型适用于需要最短读取延迟时间的流式工作负载。默认流使用“至少一次”方式的承诺类型。 如需了解详情,请参阅使用已提交类型实现“正好一次”语义。
API 流:
已缓冲类型
已缓冲类型是一种高级类型,除了与 Apache Beam BigQuery I/O 连接器搭配使用以外,通常不应该使用此类型。如果您希望确保一些小批量的记录一并显示出来,请使用已提交类型并在一个请求中发送每个批次。在此类型中,提供行级提交,并且记录会缓冲,直到您通过刷新流提交行。
API 流:
选择类型
以下流程图可帮助您确定哪种类型最适合您的工作负载:
API 详细信息
使用 Storage Write API 时,请考虑以下事项:
AppendRows
AppendRows 方法会将一个或多个记录附加到流。首次调用 AppendRows 时,必须在调用中包含流名称以及数据架构(将其指定为 DescriptorProto)。或者,如果您以 Apache Arrow 格式注入数据,可以在首次调用 AppendRows 时添加序列化的 Arrow 架构。最佳做法是在每个 AppendRows 调用中发送一批行。请勿一次发送一行。
Proto 缓冲区处理
协议缓冲区提供了一种与语言和平台无关的可扩展机制,用于以向前兼容和向后兼容的方式序列化结构化数据。它们的优势在于它们提供紧凑的数据存储和快速高效的解析。如需详细了解协议缓冲区,请参阅协议缓冲区概览。
如果要直接使用 API 和预定义的协议缓冲区消息,则协议缓冲区消息不能使用 package 说明符,并且所有嵌套或枚举类型都必须在顶级根消息中定义。不允许引用外部消息。如需查看示例,请参阅 sample_data.proto。
Java 和 Go 客户端支持任意协议缓冲区,因为客户端库已将协议缓冲区架构标准化。
Apache Arrow 处理
如需就此功能提供反馈或请求支持,请联系 bq-write-api-feedback@google.com。Apache Arrow 是一种通用的列式格式,也是用于数据处理的多语言工具箱。Apache Arrow 提供了一种独立于语言的列式内存格式,用于存储扁平数据和分层数据,可针对现代硬件上的高效分析操作进行整理。如需详细了解 Apache Arrow,请参阅 Apache Arrow。
Storage Write API 支持使用 AppendRowsRequest 类中的序列化 Arrow 架构和数据进行 Arrow 注入。Python 客户端库内置了对 Apache Arrow 注入的支持。其他语言可能需要调用原始 AppendRows API 来以 Apache Arrow 格式注入数据。
FinalizeWriteStream
FinalizeWriteStream 方法会最终完成流,完成流之后便不能再向其附加新数据。此方法在 Pending 类型中是必需的,在 Committed 和 Buffered 类型中是可选的。默认流不支持此方法。
错误处理
如果发生错误,返回的 google.rpc.Status 可能会在错误详情中包含 StorageError。查看 StorageErrorCode 以找出具体的错误类型。如需详细了解 Google API 错误模型,请参阅错误。
连接
Storage Write API 是使用双向连接的 gRPC API。AppendRows 方法会创建与流的连接。您可以在默认流上打开多个连接。这些附加操作是异步的,可让您同时发送一系列写入。每个双向连接上的响应消息到达的顺序与请求相同。
应用创建的流只能有一个活跃连接。最佳做法是限制活跃连接数,并使用一个连接进行尽可能多的数据写入。 在 Java 或 Go 中使用默认流时,您可以使用 Storage Write API 多路复用将数据写入具有共享连接的多个目标表。
通常,单个连接支持至少 1 MBps 的吞吐量。上限则取决于多个因素,例如网络带宽、数据架构和服务器负载。当连接达到吞吐量上限时,传入请求可能会被拒绝或排入队列,直到运行中的请求数量减少。如果您需要更多吞吐量,请创建更多连接。
如果 gRPC 连接长时间保持空闲状态,则 BigQuery 会关闭该连接。如果发生这种情况,则响应代码为 HTTP 409。如果服务器重启或者其他原因,gRPC 连接也会予以关闭。如果发生连接错误,请创建新连接。 如果连接关闭,Java 和 Go 客户端库会自动重新连接。
客户端库支持
Storage Write API 的客户端库支持多种编程语言,并公开基于 gRPC 的底层 API 构造。此 API 利用了双向流式传输等高级功能,可能需要额外的开发工作才能支持。为此,此 API 提供了一些更高级别的抽象,可简化这些交互并减少开发者的顾虑。我们建议您尽可能利用这些其他库抽象。
本部分详细介绍了除生成的 API 之外还为开发者提供了其他功能的语言和库。
如需查看与 Storage Write API 相关的代码示例,请参阅所有 BigQuery 代码示例。
Java 客户端
Java 客户端库提供了以下两个写入器对象:
StreamWriter:接受协议缓冲区格式的数据。JsonStreamWriter:接受 JSON 格式的数据并将其转换为协议缓冲区,然后再通过网络发送数据。JsonStreamWriter还支持自动架构更新。如果表架构发生更改,写入者会自动重新连接到新架构,从而使客户端可以使用新架构发送数据。
编程模型对于这两个写入器都是类似的。主要区别在于载荷格式的设置方式。
写入者对象会管理 Storage Write API 连接。写入者对象会自动清理请求,向请求添加区域路由标头,并且能够在发生连接错误后重新连接。如果您直接使用 gRPC API,则您必须自行处理这些细节。
Go 客户端
Go 客户端使用客户端-服务器架构通过 proto2 对协议缓冲区格式的消息进行编码。如需详细了解如何使用 Go 客户端和示例代码,请参阅 Go 文档。
Python 客户端
Python 客户端是封装 gRPC API 的较低级别的客户端。如需使用此客户端,您必须以协议缓冲区的形式发送数据,并遵循指定类型的 API 流。
避免在 Python 中使用动态 proto 消息生成,因为该库的性能不达标。
如需详细了解如何将协议缓冲区与 Python 结合使用,请参阅 Python 教程中的协议缓冲区基础知识。
您还可以使用 Apache Arrow 注入格式作为替代协议,通过 Storage Write API 注入数据。如需了解详情,请参阅使用 Apache Arrow 格式注入数据。
NodeJS 客户端
NodeJS 客户端库接受 JSON 输入,并提供自动重新连接支持。如需详细了解如何使用客户端,请参阅相关文档。
处理不可用的情况
虽然使用指数退避算法进行重试可以在一定程度上缓解随机错误和服务暂时不可用的情况,但为了避免在长时不可用期间丢失行,则需要您进行更多的考量。特别是您需要考虑,如果客户端一直无法插入某一行,该怎么办?
对此问题的回答取决于您的要求。例如,如果将 BigQuery 用于操作分析并且如果出现一些缺失的行是可接受的,那么您的客户端可以在几次重试后放弃重试并舍弃这些数据。但是,如果每一行都对业务至关重要(例如财务数据),那么您将需要制定相应的策略来保留数据,直到之后可以成功插入这些数据。
处理永久性错误的一种常见方法是将行发布到 Pub/Sub 主题,以供日后评估和可能执行的插入。另一种常见方法是在客户端上暂时保留数据。这两种方法都可以使客户端保持未屏蔽状态,同时确保可以在恢复可用性后插入所有行。
将数据流式插入到分区表
Storage Write API 支持将数据流式插入到分区表。
流式插入数据时,数据最初放在 __UNPARTITIONED__ 分区中。在收集到足够的未分区数据后,BigQuery 会对数据进行重新分区,并将其放入相应的分区中。但是,没有服务等级协议(SLA) 定义数据移出 __UNPARTITIONED__ 分区所需的时间。
对于注入时间分区表和时间单位列分区表,查询可通过使用某一伪列(_PARTITIONTIME 或 _PARTITIONDATE,具体取决于您的首选数据类型)过滤掉 __UNPARTITIONED__ 分区中的 NULL 值,从查询中排除未分区的数据。
提取时间分区
当您将数据流式插入到注入时间分区表时,Storage Write API 会根据当前系统世界协调时间 (UTC) 推断目标分区。
如果您要将数据流式插入每日分区表,则可以通过在请求中添加分区修饰器来替换推断出的日期。在 tableID 参数中添加修饰器。例如,您可以使用table1$20250601分区修饰器将数据流式插入到 table1 表中与 2025-06-01 对应的分区:
在使用分区修饰器进行流式插入时,您可以将数据流式插入到日期介于当前日期之前 31 天至之后 16 天之间的分区。如需将数据写入到日期在这些范围之外的分区,请改为使用加载作业或查询作业,相关说明请参阅将数据写入特定分区。
使用分区修饰器进行流式插入仅适用于具有默认流的每日分区表,不适用于每小时、每月或每年分区表,也不适用于应用创建的流。
时间单位列分区
当您将数据流式插入到时间单位列分区表时,BigQuery 会根据表的预定义 DATE、DATETIME 或 TIMESTAMP 分区列的值自动将数据放入正确的分区。如果分区列所引用的数据介于过去 10 年到未来 1 年之间,您可以将数据流式插入到时间单位列分区表中。
整数范围分区
当您将数据流式插入到整数范围分区表时,BigQuery 会根据表的预定义INTEGER分区列的值自动将数据放入正确的分区。
Fluent Bit Storage Write API 输出插件
Fluent Bit Storage Write API 输出插件可自动执行将 JSON 记录注入 BigQuery 的过程,从而无需您编写代码。借助此插件,您只需配置兼容的输入插件并设置配置文件,即可开始流式插入数据。Fluent Bit 是一款开源的跨平台日志处理器和转发器,它使用输入和输出插件来处理不同类型的数据源和接收器。
此插件支持以下功能:
- 使用默认类型的“至少一次”语义。
- 使用已提交类型的“正好一次”语义。
- 在指示反压时,对默认流进行动态伸缩。
Storage Write API 项目指标
如需了解使用 Storage Write API 监控数据注入的指标,请使用 INFORMATION_SCHEMA.WRITE_API_TIMELINE 视图或参阅 Google Cloud 指标。
对最近流式插入的数据使用数据操纵语言 (DML)
您可以使用数据操纵语言 (DML)(例如 UPDATE、DELETE 或 MERGE 语句)来修改 BigQuery Storage Write API 最近写入 BigQuery 表的行。最近的写入是指最近 30 分钟内发生的写入。
如需详细了解如何使用 DML 修改流式插入的数据,请参阅使用数据操纵语言。
限制
- 对于针对最近流式插入的数据运行变更 DML 语句的支持不会扩展到使用 insertAll Streaming API 流式插入的数据。
- 不支持在多语句事务中针对最近流式插入的数据运行变更 DML 语句。
Storage Write API 配额
如需了解 Storage Write API 配额和限制,请参阅 BigQuery Storage Write API 配额和限制。
您可以在 Google Cloud 控制台的“配额”页面中监控并发连接和吞吐量配额用量。
计算吞吐量
假设您的目标是从 1 亿个端点收集日志,并且每分钟会创建 1,500 个日志记录。然后,您可以将吞吐量估计为 100 million * 1,500 / 60 seconds = 2.5 GB per second。您必须提前确保有足够的配额来处理此吞吐量。
Storage Write API 价格
如需了解价格,请参阅数据提取价格。
用例示例
假设有流水线处理来自端点日志的事件数据。这些事件是连续生成的,并且需要尽快在 BigQuery 中进行查询。由于数据新鲜度对于此应用场景至关重要,因此 Storage Write API 是将数据注入到 BigQuery 的最佳选择。为使这些端点尽量精简,建议的架构会将这些事件发送到 Pub/Sub,之后由 Dataflow 的流式处理流水线直接将这些事件流式传输到 BigQuery。
此架构存在的主要可靠性问题是如何处理无法将记录插入 BigQuery 的情况。如果每条记录都很重要并且不能丢失,那么您将需要先缓冲数据,然后再尝试插入。在上述建议的架构中,Pub/Sub 可以充当缓冲区的角色并提供消息保留功能。Dataflow 流水线应配置为通过截断的指数退避算法重试 BigQuery 流式插入。Pub/Sub 作为缓冲区的容量耗尽(例如在 BigQuery 长时间不可用或网络故障等情况下)后,客户端就必须保留数据,并且客户端需要一种机制来确保在可用性恢复后能够继续插入保留的记录。如需详细了解如何处理这种情况,请参阅 Google Pub/Sub 可靠性指南博文。
需要处理的另一个失败情况是中毒记录。中毒记录是 BigQuery 拒绝的记录(因为记录无法插入且不可重试),或者是在达到重试次数上限后未成功插入的记录。这两种类型的记录都应由 Dataflow 流水线存储在“死信队列”中,以进一步调查。
如果需要“正好一次”语义,请在已提交类型下创建写入流,并使用客户端提供的记录偏移量。这样可以避免重复,因为只有在偏移量值与下一个附加偏移量匹配时才会执行写入操作。如果未提供偏移量,则表示记录会附加到流的当前末尾处,重试失败的记录可能会导致记录在流中多次出现。
如果不需要“正好一次”保证,写入默认流可实现更高的吞吐量,也不会计入创建写入数据流的配额限制。
估算网络的吞吐量,并提前确保您有足够的配额来提供相应吞吐量。
如果您的工作负载以非常不均匀的速率生成或处理数据,请尝试消除客户端上的所有负载峰值,并以恒定的吞吐量流式传输到 BigQuery。这样可以简化容量规划。但如果无法做到这一点,请确保准备好应对在短暂高峰期吞吐量超过配额时出现的 429(资源耗尽)错误。
如需查看有关如何使用 Storage Write API 的详细示例,请参阅使用 Storage Write API 流式插入数据。