Travailler sur des données de séries temporelles
Ce document explique comment utiliser les fonctions SQL pour assurer l'analyse de séries temporelles.
Introduction
Une série temporelle est une séquence de points de données, chacun composé d'un horodatage et d'une valeur associée à cet horodatage. En général, une série temporelle possède également un identifiant, qui lui attribue un nom unique.
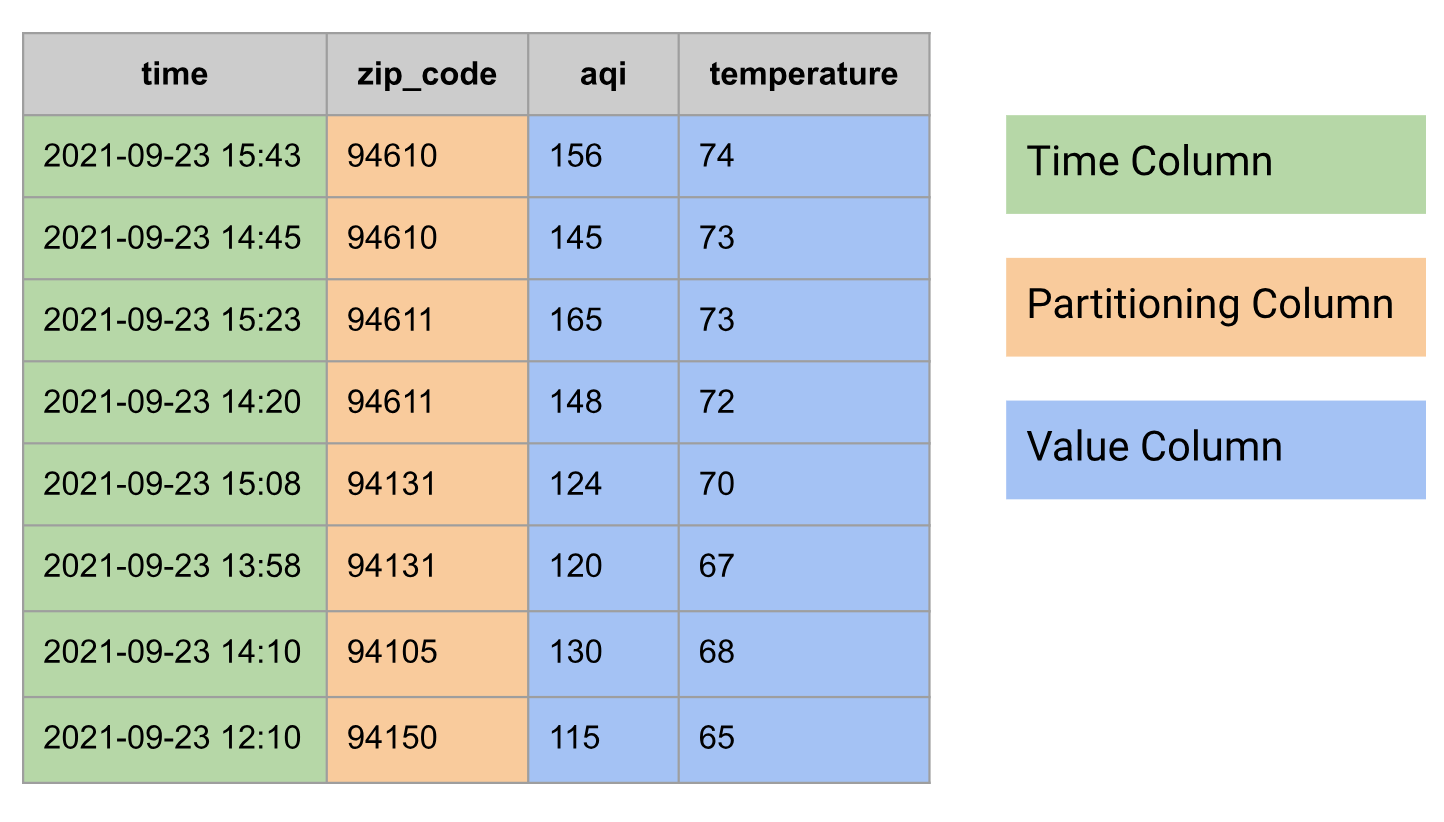
Dans les bases de données relationnelles, une série temporelle est modélisée sous la forme d'une table comportant les groupes de colonnes suivants :
- Colonne Heure
- Peut avoir des colonnes de partitionnement, par exemple un code postal
- Une ou plusieurs colonnes de valeurs, ou un type
STRUCTcombinant plusieurs valeurs, par exemple température et IQA
Voici un exemple de données de séries temporelles modélisées sous forme de table :
Agréger une série temporelle
Dans l'analyse de séries temporelles, l'agrégation temporelle est une agrégation effectuée le long de l'axe de temps.
Vous pouvez effectuer une agrégation de temps dans BigQuery à l'aide de fonctions de binning temporel (TIMESTAMP_BUCKET, DATE_BUCKET et DATETIME_BUCKET). Les fonctions de binning temporel mappent les valeurs de temps d'entrée avec le bucket auquel elles appartiennent.
En règle générale, l'agrégation temporelle est effectuée pour combiner plusieurs points de données d'une fenêtre temporelle en un seul point de données, à l'aide d'une fonction d'agrégation, telle que AVG, MIN, MAX, COUNT ou SUM. Par exemple, la latence moyenne des requêtes sur 15 minutes, les températures minimale et maximale quotidiennes, et le nombre quotidien de trajets en taxi.
Pour les requêtes de cette section, créez une table appelée mydataset.environmental_data_hourly :
CREATE OR REPLACE TABLE mydataset.environmental_data_hourly AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<zip_code INT64, time TIMESTAMP, aqi INT64, temperature INT64>>[
STRUCT(60606, TIMESTAMP '2020-09-08 00:30:51', 22, 66),
STRUCT(60606, TIMESTAMP '2020-09-08 01:32:10', 23, 63),
STRUCT(60606, TIMESTAMP '2020-09-08 02:30:35', 22, 60),
STRUCT(60606, TIMESTAMP '2020-09-08 03:29:39', 21, 58),
STRUCT(60606, TIMESTAMP '2020-09-08 04:33:05', 21, 59),
STRUCT(60606, TIMESTAMP '2020-09-08 05:32:01', 21, 57),
STRUCT(60606, TIMESTAMP '2020-09-08 06:31:14', 22, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 07:31:06', 28, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 08:29:59', 30, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 09:29:34', 31, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 10:31:24', 38, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 11:31:24', 38, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 12:32:38', 38, 57),
STRUCT(60606, TIMESTAMP '2020-09-08 13:29:59', 38, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 14:31:22', 43, 59),
STRUCT(60606, TIMESTAMP '2020-09-08 15:31:38', 42, 63),
STRUCT(60606, TIMESTAMP '2020-09-08 16:34:22', 43, 65),
STRUCT(60606, TIMESTAMP '2020-09-08 17:33:23', 42, 68),
STRUCT(60606, TIMESTAMP '2020-09-08 18:28:47', 36, 69),
STRUCT(60606, TIMESTAMP '2020-09-08 19:30:28', 34, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 20:30:53', 29, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 21:32:28', 27, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 22:31:45', 25, 65),
STRUCT(60606, TIMESTAMP '2020-09-08 23:31:02', 22, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 00:07:11', 60, 74),
STRUCT(94105, TIMESTAMP '2020-09-08 01:07:24', 61, 73),
STRUCT(94105, TIMESTAMP '2020-09-08 02:08:07', 60, 71),
STRUCT(94105, TIMESTAMP '2020-09-08 03:11:05', 69, 69),
STRUCT(94105, TIMESTAMP '2020-09-08 04:07:26', 72, 67),
STRUCT(94105, TIMESTAMP '2020-09-08 05:08:11', 70, 66),
STRUCT(94105, TIMESTAMP '2020-09-08 06:07:30', 68, 65),
STRUCT(94105, TIMESTAMP '2020-09-08 07:07:10', 77, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 08:06:35', 81, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 09:10:18', 82, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 10:08:10', 107, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 11:08:01', 115, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 12:07:39', 120, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 13:06:03', 125, 61),
STRUCT(94105, TIMESTAMP '2020-09-08 14:08:37', 129, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 15:09:19', 150, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 16:06:39', 151, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 17:08:01', 155, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 18:09:23', 154, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 19:08:43', 151, 67),
STRUCT(94105, TIMESTAMP '2020-09-08 20:07:19', 150, 69),
STRUCT(94105, TIMESTAMP '2020-09-08 21:07:37', 148, 72),
STRUCT(94105, TIMESTAMP '2020-09-08 22:08:01', 143, 76),
STRUCT(94105, TIMESTAMP '2020-09-08 23:08:41', 137, 75)
]);
Il est intéressant d'observer les données précédentes : les mesures sont effectuées à des périodes arbitraires, appelées séries temporelles non alignées. L'agrégation constitue l'un des moyens permettant d'aligner une série temporelle.
Obtenir une moyenne sur trois heures
La requête suivante calcule un indice de qualité de l'air (IQA) et la température moyennes sur trois heures pour chaque code postal. La fonction TIMESTAMP_BUCKET effectue l'agrégation des données temporelles en attribuant chaque horodatage à un jour particulier.
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly
GROUP BY zip_code, time
ORDER BY zip_code, time;
/*---------------------+----------+-----+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+-----+-------------+
| 2020-09-08 00:00:00 | 60606 | 22 | 63 |
| 2020-09-08 03:00:00 | 60606 | 21 | 58 |
| 2020-09-08 06:00:00 | 60606 | 27 | 55 |
| 2020-09-08 09:00:00 | 60606 | 36 | 56 |
| 2020-09-08 12:00:00 | 60606 | 40 | 57 |
| 2020-09-08 15:00:00 | 60606 | 42 | 65 |
| 2020-09-08 18:00:00 | 60606 | 33 | 68 |
| 2020-09-08 21:00:00 | 60606 | 25 | 65 |
| 2020-09-08 00:00:00 | 94105 | 60 | 73 |
| 2020-09-08 03:00:00 | 94105 | 70 | 67 |
| 2020-09-08 06:00:00 | 94105 | 75 | 64 |
| 2020-09-08 09:00:00 | 94105 | 101 | 62 |
| 2020-09-08 12:00:00 | 94105 | 125 | 62 |
| 2020-09-08 15:00:00 | 94105 | 152 | 62 |
| 2020-09-08 18:00:00 | 94105 | 152 | 67 |
| 2020-09-08 21:00:00 | 94105 | 143 | 74 |
+---------------------+----------+-----+-------------*/
Obtenir des valeurs minimale et maximale sur trois heures
Dans la requête suivante, vous calculez des températures minimales et maximales sur trois heures pour chaque code postal :
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
MIN(temperature) AS temperature_min,
MAX(temperature) AS temperature_max,
FROM mydataset.environmental_data_hourly
GROUP BY zip_code, time
ORDER BY zip_code, time;
/*---------------------+----------+-----------------+-----------------+
| time | zip_code | temperature_min | temperature_max |
+---------------------+----------+-----------------+-----------------+
| 2020-09-08 00:00:00 | 60606 | 60 | 66 |
| 2020-09-08 03:00:00 | 60606 | 57 | 59 |
| 2020-09-08 06:00:00 | 60606 | 55 | 56 |
| 2020-09-08 09:00:00 | 60606 | 55 | 56 |
| 2020-09-08 12:00:00 | 60606 | 56 | 59 |
| 2020-09-08 15:00:00 | 60606 | 63 | 68 |
| 2020-09-08 18:00:00 | 60606 | 67 | 69 |
| 2020-09-08 21:00:00 | 60606 | 63 | 67 |
| 2020-09-08 00:00:00 | 94105 | 71 | 74 |
| 2020-09-08 03:00:00 | 94105 | 66 | 69 |
| 2020-09-08 06:00:00 | 94105 | 64 | 65 |
| 2020-09-08 09:00:00 | 94105 | 62 | 63 |
| 2020-09-08 12:00:00 | 94105 | 61 | 62 |
| 2020-09-08 15:00:00 | 94105 | 62 | 63 |
| 2020-09-08 18:00:00 | 94105 | 64 | 69 |
| 2020-09-08 21:00:00 | 94105 | 72 | 76 |
+---------------------+----------+-----------------+-----------------*/
Obtenir une moyenne sur trois heures avec l'alignement personnalisé
Lorsque vous effectuez une agrégation de séries temporelles, vous utilisez un alignement spécifique pour les fenêtres de séries temporelles, implicitement ou explicitement. Les requêtes précédentes utilisaient l'alignement implicite, qui génère des buckets qui ont démarré à des horodatages tels que 00:00:00, 03:00:00 et 06:00:00. Pour définir explicitement cet alignement dans la fonction TIMESTAMP_BUCKET, vous allez transmettre un argument facultatif qui spécifie l'origine.
Dans la requête suivante, l'origine est définie sur l'horodatage 2020-01-01 02:00:00. Cela modifie l'alignement et génère des buckets qui commencent à des moments tels que 02:00:00, 05:00:00 et 08:00:00 :
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR, TIMESTAMP '2020-01-01 02:00:00') AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly
GROUP BY zip_code, time
ORDER BY zip_code, time;
/*---------------------+----------+-----+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+-----+-------------+
| 2020-09-07 23:00:00 | 60606 | 23 | 65 |
| 2020-09-08 02:00:00 | 60606 | 21 | 59 |
| 2020-09-08 05:00:00 | 60606 | 24 | 56 |
| 2020-09-08 08:00:00 | 60606 | 33 | 55 |
| 2020-09-08 11:00:00 | 60606 | 38 | 56 |
| 2020-09-08 14:00:00 | 60606 | 43 | 62 |
| 2020-09-08 17:00:00 | 60606 | 37 | 68 |
| 2020-09-08 20:00:00 | 60606 | 27 | 66 |
| 2020-09-08 23:00:00 | 60606 | 22 | 63 |
| 2020-09-07 23:00:00 | 94105 | 61 | 74 |
| 2020-09-08 02:00:00 | 94105 | 67 | 69 |
| 2020-09-08 05:00:00 | 94105 | 72 | 65 |
| 2020-09-08 08:00:00 | 94105 | 90 | 63 |
| 2020-09-08 11:00:00 | 94105 | 120 | 62 |
| 2020-09-08 14:00:00 | 94105 | 143 | 62 |
| 2020-09-08 17:00:00 | 94105 | 153 | 65 |
| 2020-09-08 20:00:00 | 94105 | 147 | 72 |
| 2020-09-08 23:00:00 | 94105 | 137 | 75 |
+---------------------+----------+-----+-------------*/
Agréger une série temporelle avec un remplissage
Parfois, après l'agrégation d'une série temporelle, les données peuvent présenter des écarts qui doivent être complétés avec des valeurs pour une analyse ou une présentation plus approfondies.
La technique utilisée pour remplir ces écarts est appelée remplissage. Dans BigQuery, vous pouvez utiliser la fonction de table GAP_FILL pour le remplissage de séries temporelles manquantes à l'aide de l'une des méthodes de remplissage fournies :
- NULL, également appelée constante
- LOCF (Last Observation Carried Forward), soit la dernière observation reportée
- Linéaire, interpolation linéaire entre les deux points de données voisins
Pour les requêtes de cette section, créez une table appelée mydataset.environmental_data_hourly_with_gaps, qui est basée sur les données utilisées dans la section précédente, mais qui comportent des écarts. Dans la réalité, il est possible que les données n'aient pas de points de données manquants en raison d'un dysfonctionnement à court terme d'une station météorologique.
CREATE OR REPLACE TABLE mydataset.environmental_data_hourly_with_gaps AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<zip_code INT64, time TIMESTAMP, aqi INT64, temperature INT64>>[
STRUCT(60606, TIMESTAMP '2020-09-08 00:30:51', 22, 66),
STRUCT(60606, TIMESTAMP '2020-09-08 01:32:10', 23, 63),
STRUCT(60606, TIMESTAMP '2020-09-08 02:30:35', 22, 60),
STRUCT(60606, TIMESTAMP '2020-09-08 03:29:39', 21, 58),
STRUCT(60606, TIMESTAMP '2020-09-08 04:33:05', 21, 59),
STRUCT(60606, TIMESTAMP '2020-09-08 05:32:01', 21, 57),
STRUCT(60606, TIMESTAMP '2020-09-08 06:31:14', 22, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 07:31:06', 28, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 08:29:59', 30, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 09:29:34', 31, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 10:31:24', 38, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 11:31:24', 38, 56),
-- No data points between hours 12 and 15.
STRUCT(60606, TIMESTAMP '2020-09-08 16:34:22', 43, 65),
STRUCT(60606, TIMESTAMP '2020-09-08 17:33:23', 42, 68),
STRUCT(60606, TIMESTAMP '2020-09-08 18:28:47', 36, 69),
STRUCT(60606, TIMESTAMP '2020-09-08 19:30:28', 34, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 20:30:53', 29, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 21:32:28', 27, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 22:31:45', 25, 65),
STRUCT(60606, TIMESTAMP '2020-09-08 23:31:02', 22, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 00:07:11', 60, 74),
STRUCT(94105, TIMESTAMP '2020-09-08 01:07:24', 61, 73),
STRUCT(94105, TIMESTAMP '2020-09-08 02:08:07', 60, 71),
STRUCT(94105, TIMESTAMP '2020-09-08 03:11:05', 69, 69),
STRUCT(94105, TIMESTAMP '2020-09-08 04:07:26', 72, 67),
STRUCT(94105, TIMESTAMP '2020-09-08 05:08:11', 70, 66),
STRUCT(94105, TIMESTAMP '2020-09-08 06:07:30', 68, 65),
STRUCT(94105, TIMESTAMP '2020-09-08 07:07:10', 77, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 08:06:35', 81, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 09:10:18', 82, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 10:08:10', 107, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 11:08:01', 115, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 12:07:39', 120, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 13:06:03', 125, 61),
STRUCT(94105, TIMESTAMP '2020-09-08 14:08:37', 129, 62),
-- No data points between hours 15 and 18.
STRUCT(94105, TIMESTAMP '2020-09-08 19:08:43', 151, 67),
STRUCT(94105, TIMESTAMP '2020-09-08 20:07:19', 150, 69),
STRUCT(94105, TIMESTAMP '2020-09-08 21:07:37', 148, 72),
STRUCT(94105, TIMESTAMP '2020-09-08 22:08:01', 143, 76),
STRUCT(94105, TIMESTAMP '2020-09-08 23:08:41', 137, 75)
]);
Obtenir une moyenne sur trois heures (avec écarts)
La requête suivante calcule l'IQA et la température moyennes sur trois heures pour chaque code postal :
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly_with_gaps
GROUP BY zip_code, time
ORDER BY zip_code, time;
/*---------------------+----------+-----+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+-----+-------------+
| 2020-09-08 00:00:00 | 60606 | 22 | 63 |
| 2020-09-08 03:00:00 | 60606 | 21 | 58 |
| 2020-09-08 06:00:00 | 60606 | 27 | 55 |
| 2020-09-08 09:00:00 | 60606 | 36 | 56 |
| 2020-09-08 15:00:00 | 60606 | 43 | 67 |
| 2020-09-08 18:00:00 | 60606 | 33 | 68 |
| 2020-09-08 21:00:00 | 60606 | 25 | 65 |
| 2020-09-08 00:00:00 | 94105 | 60 | 73 |
| 2020-09-08 03:00:00 | 94105 | 70 | 67 |
| 2020-09-08 06:00:00 | 94105 | 75 | 64 |
| 2020-09-08 09:00:00 | 94105 | 101 | 62 |
| 2020-09-08 12:00:00 | 94105 | 125 | 62 |
| 2020-09-08 18:00:00 | 94105 | 151 | 68 |
| 2020-09-08 21:00:00 | 94105 | 143 | 74 |
+---------------------+----------+-----+-------------*/
Notez que la sortie présente des écarts à certains intervalles de temps. Par exemple, la série temporelle du code postal 60606 n'a pas de point de données à 2020-09-08 12:00:00, et la série temporelle du code postal 94105 n'a pas de point de données à 2020-09-08 15:00:00.
Obtenir une moyenne sur trois heures (avec remplissage des écarts)
Utilisez la requête de la section précédente et ajoutez la fonction GAP_FILL pour remplir les écarts :
WITH aggregated_3_hr AS (
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly_with_gaps
GROUP BY zip_code, time)
SELECT *
FROM GAP_FILL(
TABLE aggregated_3_hr,
ts_column => 'time',
bucket_width => INTERVAL 3 HOUR,
partitioning_columns => ['zip_code']
)
ORDER BY zip_code, time;
/*---------------------+----------+------+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+------+-------------+
| 2020-09-08 00:00:00 | 60606 | 22 | 63 |
| 2020-09-08 03:00:00 | 60606 | 21 | 58 |
| 2020-09-08 06:00:00 | 60606 | 27 | 55 |
| 2020-09-08 09:00:00 | 60606 | 36 | 56 |
| 2020-09-08 12:00:00 | 60606 | NULL | NULL |
| 2020-09-08 15:00:00 | 60606 | 43 | 67 |
| 2020-09-08 18:00:00 | 60606 | 33 | 68 |
| 2020-09-08 21:00:00 | 60606 | 25 | 65 |
| 2020-09-08 00:00:00 | 94105 | 60 | 73 |
| 2020-09-08 03:00:00 | 94105 | 70 | 67 |
| 2020-09-08 06:00:00 | 94105 | 75 | 64 |
| 2020-09-08 09:00:00 | 94105 | 101 | 62 |
| 2020-09-08 12:00:00 | 94105 | 125 | 62 |
| 2020-09-08 15:00:00 | 94105 | NULL | NULL |
| 2020-09-08 18:00:00 | 94105 | 151 | 68 |
| 2020-09-08 21:00:00 | 94105 | 143 | 74 |
+---------------------+----------+------+-------------*/
La table de sortie contient maintenant une ligne manquante à 2020-09-08 12:00:00 pour le code postal 60606 et à 2020-09-08 15:00:00 pour le code postal 94105, avec les valeurs NULL dans les colonnes de métriques correspondantes. Comme vous n'avez spécifié aucune méthode de remplissage, GAP_FILL a utilisé la méthode de remplissage par défaut, c'est-à-dire NULL.
Compléter les écarts avec le remplissage linéaire et le remplissage LOCF
Dans la requête suivante, la fonction GAP_FILL est utilisée avec la méthode de remplissage des écarts LOCF pour la colonne aqi et l'interpolation linéaire pour la colonne temperature :
WITH aggregated_3_hr AS (
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly_with_gaps
GROUP BY zip_code, time)
SELECT *
FROM GAP_FILL(
TABLE aggregated_3_hr,
ts_column => 'time',
bucket_width => INTERVAL 3 HOUR,
partitioning_columns => ['zip_code'],
value_columns => [
('aqi', 'locf'),
('temperature', 'linear')
]
)
ORDER BY zip_code, time;
/*---------------------+----------+-----+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+-----+-------------+
| 2020-09-08 00:00:00 | 60606 | 22 | 63 |
| 2020-09-08 03:00:00 | 60606 | 21 | 58 |
| 2020-09-08 06:00:00 | 60606 | 27 | 55 |
| 2020-09-08 09:00:00 | 60606 | 36 | 56 |
| 2020-09-08 12:00:00 | 60606 | 36 | 62 |
| 2020-09-08 15:00:00 | 60606 | 43 | 67 |
| 2020-09-08 18:00:00 | 60606 | 33 | 68 |
| 2020-09-08 21:00:00 | 60606 | 25 | 65 |
| 2020-09-08 00:00:00 | 94105 | 60 | 73 |
| 2020-09-08 03:00:00 | 94105 | 70 | 67 |
| 2020-09-08 06:00:00 | 94105 | 75 | 64 |
| 2020-09-08 09:00:00 | 94105 | 101 | 62 |
| 2020-09-08 12:00:00 | 94105 | 125 | 62 |
| 2020-09-08 15:00:00 | 94105 | 125 | 65 |
| 2020-09-08 18:00:00 | 94105 | 151 | 68 |
| 2020-09-08 21:00:00 | 94105 | 143 | 74 |
+---------------------+----------+-----+-------------*/
Dans cette requête, la première ligne avec écarts a la valeur aqi 36, qui provient du point de données précédent de cette série temporelle (code postal 60606) à 2020-09-08 09:00:00. La valeur 62 de temperature est le résultat d'une interpolation linéaire entre les points de données 2020-09-08 09:00:00 et 2020-09-08 15:00:00. L'autre ligne manquante a été créée de la même manière : la valeur aqi 125 a été transférée depuis le point de données précédent de cette série temporelle (code postal 94105), et la valeur de la température 65 est le résultat d'une interpolation linéaire entre les points de données disponibles précédents et suivants.
Aligner une série temporelle avec un remplissage
Les séries temporelles peuvent être alignées ou non alignées. Une série temporelle est alignée lorsque les points de données ne se produisent qu'à intervalles réguliers.
Dans la réalité, au moment de la collecte, les séries temporelles sont rarement alignées et nécessitent généralement un traitement supplémentaire pour les aligner.
Prenons l'exemple des appareils IoT qui envoient leurs métriques à un collecteur centralisé toutes les minutes. Il serait irréaliste de considérer que ces appareils vont tous envoyer leurs métriques exactement aux mêmes horodatages. En règle générale, chaque appareil envoie ses métriques selon la même fréquence (période), mais avec un décalage temporel (alignement) différent. Le diagramme suivant illustre cet exemple. Vous pouvez voir chaque appareil envoyer ses données avec un intervalle d'une minute avec certaines instances de données manquantes (appareil 3 à 9:36:39) et de données retardées (appareil 1 à 9:37:28).

Vous pouvez effectuer un alignement de séries temporelles sur des données non alignées à l'aide de l'agrégation de temps. Cette fonctionnalité est utile si vous souhaitez modifier la période d'échantillonnage de la série temporelle, par exemple pour passer de la période d'échantillonnage d'origine d'une minute à une période de 15 minutes. Vous pouvez aligner les données pour un traitement ultérieur des séries temporelles, par exemple pour les joindre, ou à des fins d'affichage, notamment sous forme de graphique.
Vous pouvez utiliser la fonction de table GAP_FILL avec les méthodes LOCF ou les méthodes de remplissage linéaire pour effectuer un alignement des séries temporelles. L'idée est d'utiliser GAP_FILL avec la période de sortie et l'alignement sélectionnés (contrôlés par l'argument "origin", facultatif). Le résultat de l'opération est une table avec des séries temporelles alignées, dans laquelle les valeurs de chaque point de données sont dérivées de la série temporelle d'entrée à l'aide de la méthode de remplissage utilisée pour cette colonne de valeurs particulière (LOCF ou linéaire).
Créez une table mydataset.device_data qui ressemble à l'illustration précédente :
CREATE OR REPLACE TABLE mydataset.device_data AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<device_id INT64, time TIMESTAMP, signal INT64, state STRING>>[
STRUCT(2, TIMESTAMP '2023-11-01 09:35:07', 87, 'ACTIVE'),
STRUCT(1, TIMESTAMP '2023-11-01 09:35:26', 82, 'ACTIVE'),
STRUCT(3, TIMESTAMP '2023-11-01 09:35:39', 74, 'INACTIVE'),
STRUCT(2, TIMESTAMP '2023-11-01 09:36:07', 88, 'ACTIVE'),
STRUCT(1, TIMESTAMP '2023-11-01 09:36:26', 82, 'ACTIVE'),
STRUCT(2, TIMESTAMP '2023-11-01 09:37:07', 88, 'ACTIVE'),
STRUCT(1, TIMESTAMP '2023-11-01 09:37:28', 80, 'ACTIVE'),
STRUCT(3, TIMESTAMP '2023-11-01 09:37:39', 77, 'ACTIVE'),
STRUCT(2, TIMESTAMP '2023-11-01 09:38:07', 86, 'ACTIVE'),
STRUCT(1, TIMESTAMP '2023-11-01 09:38:26', 81, 'ACTIVE'),
STRUCT(3, TIMESTAMP '2023-11-01 09:38:39', 77, 'ACTIVE')
]);
Voici les données réelles triées par colonne time et device_id :
SELECT * FROM mydataset.device_data ORDER BY time, device_id;
/*-----------+---------------------+--------+----------+
| device_id | time | signal | state |
+-----------+---------------------+--------+----------+
| 2 | 2023-11-01 09:35:07 | 87 | ACTIVE |
| 1 | 2023-11-01 09:35:26 | 82 | ACTIVE |
| 3 | 2023-11-01 09:35:39 | 74 | INACTIVE |
| 2 | 2023-11-01 09:36:07 | 88 | ACTIVE |
| 1 | 2023-11-01 09:36:26 | 82 | ACTIVE |
| 2 | 2023-11-01 09:37:07 | 88 | ACTIVE |
| 1 | 2023-11-01 09:37:28 | 80 | ACTIVE |
| 3 | 2023-11-01 09:37:39 | 77 | ACTIVE |
| 2 | 2023-11-01 09:38:07 | 86 | ACTIVE |
| 1 | 2023-11-01 09:38:26 | 81 | ACTIVE |
| 3 | 2023-11-01 09:38:39 | 77 | ACTIVE |
+-----------+---------------------+--------+----------*/
Le tableau contient les séries temporelles de chaque appareil avec deux colonnes de métriques :
signal: niveau du signal tel qu'observé par l'appareil au moment de l'échantillonnage, représenté par une valeur entière comprise entre0et100.state: état de l'appareil au moment de l'échantillonnage, représenté sous forme de chaîne libre.
Dans la requête suivante, la fonction GAP_FILL permet d'aligner la série temporelle selon des intervalles d'une minute. Notez que l'interpolation linéaire est utilisée pour calculer les valeurs de la colonne signal, tandis que c'est le remplissage LOCF qui permet de renseigner la colonne state. Pour cet exemple de données, l'interpolation linéaire est un choix approprié pour calculer les valeurs de sortie.
SELECT *
FROM GAP_FILL(
TABLE mydataset.device_data,
ts_column => 'time',
bucket_width => INTERVAL 1 MINUTE,
partitioning_columns => ['device_id'],
value_columns => [
('signal', 'linear'),
('state', 'locf')
]
)
ORDER BY time, device_id;
/*---------------------+-----------+--------+----------+
| time | device_id | signal | state |
+---------------------+-----------+--------+----------+
| 2023-11-01 09:36:00 | 1 | 82 | ACTIVE |
| 2023-11-01 09:36:00 | 2 | 88 | ACTIVE |
| 2023-11-01 09:36:00 | 3 | 75 | INACTIVE |
| 2023-11-01 09:37:00 | 1 | 81 | ACTIVE |
| 2023-11-01 09:37:00 | 2 | 88 | ACTIVE |
| 2023-11-01 09:37:00 | 3 | 76 | INACTIVE |
| 2023-11-01 09:38:00 | 1 | 81 | ACTIVE |
| 2023-11-01 09:38:00 | 2 | 86 | ACTIVE |
| 2023-11-01 09:38:00 | 3 | 77 | ACTIVE |
+---------------------+-----------+--------+----------*/
La table de sortie contient une série temporelle alignée pour chaque colonne d'appareil et de valeur (signal et state), calculée à l'aide des méthodes de remplissage spécifiées dans l'appel de fonction.
Définir une jointure sur des données de séries temporelles
Vous pouvez joindre des données de séries temporelles à l'aide d'une jointure fenêtrée ou d'une jointure AS OF.
Jointure fenêtrée
Il peut arriver que vous deviez joindre deux tables, ou davantage, comportant des données de séries temporelles. Prenons l'exemple des deux tables suivantes :
mydataset.sensor_temperatures, qui contient les données de température signalées par chaque capteur toutes les 15 secondes.mydataset.sensor_fuel_rates, qui contient le taux de consommation de carburant mesuré par chaque capteur toutes les 15 secondes.
Pour créer ces tables, exécutez les requêtes suivantes :
CREATE OR REPLACE TABLE mydataset.sensor_temperatures AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, ts TIMESTAMP, temp FLOAT64>>[
(1, TIMESTAMP '2020-01-01 12:00:00.063', 37.1),
(1, TIMESTAMP '2020-01-01 12:00:15.024', 37.2),
(1, TIMESTAMP '2020-01-01 12:00:30.032', 37.3),
(2, TIMESTAMP '2020-01-01 12:00:01.001', 38.1),
(2, TIMESTAMP '2020-01-01 12:00:15.082', 38.2),
(2, TIMESTAMP '2020-01-01 12:00:31.009', 38.3)
]);
CREATE OR REPLACE TABLE mydataset.sensor_fuel_rates AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, ts TIMESTAMP, rate FLOAT64>>[
(1, TIMESTAMP '2020-01-01 12:00:11.016', 10.1),
(1, TIMESTAMP '2020-01-01 12:00:26.015', 10.2),
(1, TIMESTAMP '2020-01-01 12:00:41.014', 10.3),
(2, TIMESTAMP '2020-01-01 12:00:08.099', 11.1),
(2, TIMESTAMP '2020-01-01 12:00:23.087', 11.2),
(2, TIMESTAMP '2020-01-01 12:00:38.077', 11.3)
]);
Voici les données réelles des tables :
SELECT * FROM mydataset.sensor_temperatures ORDER BY sensor_id, ts;
/*-----------+---------------------+------+
| sensor_id | ts | temp |
+-----------+---------------------+------+
| 1 | 2020-01-01 12:00:00 | 37.1 |
| 1 | 2020-01-01 12:00:15 | 37.2 |
| 1 | 2020-01-01 12:00:30 | 37.3 |
| 2 | 2020-01-01 12:00:01 | 38.1 |
| 2 | 2020-01-01 12:00:15 | 38.2 |
| 2 | 2020-01-01 12:00:31 | 38.3 |
+-----------+---------------------+------*/
SELECT * FROM mydataset.sensor_fuel_rates ORDER BY sensor_id, ts;
/*-----------+---------------------+------+
| sensor_id | ts | rate |
+-----------+---------------------+------+
| 1 | 2020-01-01 12:00:11 | 10.1 |
| 1 | 2020-01-01 12:00:26 | 10.2 |
| 1 | 2020-01-01 12:00:41 | 10.3 |
| 2 | 2020-01-01 12:00:08 | 11.1 |
| 2 | 2020-01-01 12:00:23 | 11.2 |
| 2 | 2020-01-01 12:00:38 | 11.3 |
+-----------+---------------------+------*/
Pour vérifier le taux de consommation de carburant à la température indiquée par chaque capteur, vous pouvez joindre les deux séries temporelles.
Bien que les données des deux séries temporelles ne soient pas alignées, elles sont échantillonnées au même intervalle (15 secondes). Par conséquent, ces données sont parfaitement adaptées à la jointure fenêtrée. Utilisez les fonctions de binning temporel pour aligner les horodatages utilisés comme clés de jointure.
Les requêtes suivantes illustrent comment chaque horodatage peut être attribué à des fenêtres de 15 secondes à l'aide de la fonction TIMESTAMP_BUCKET :
SELECT *, TIMESTAMP_BUCKET(ts, INTERVAL 15 SECOND) ts_window
FROM mydataset.sensor_temperatures
ORDER BY sensor_id, ts;
/*-----------+---------------------+------+---------------------+
| sensor_id | ts | temp | ts_window |
+-----------+---------------------+------+---------------------+
| 1 | 2020-01-01 12:00:00 | 37.1 | 2020-01-01 12:00:00 |
| 1 | 2020-01-01 12:00:15 | 37.2 | 2020-01-01 12:00:15 |
| 1 | 2020-01-01 12:00:30 | 37.3 | 2020-01-01 12:00:30 |
| 2 | 2020-01-01 12:00:01 | 38.1 | 2020-01-01 12:00:00 |
| 2 | 2020-01-01 12:00:15 | 38.2 | 2020-01-01 12:00:15 |
| 2 | 2020-01-01 12:00:31 | 38.3 | 2020-01-01 12:00:30 |
+-----------+---------------------+------+---------------------*/
SELECT *, TIMESTAMP_BUCKET(ts, INTERVAL 15 SECOND) ts_window
FROM mydataset.sensor_fuel_rates
ORDER BY sensor_id, ts;
/*-----------+---------------------+------+---------------------+
| sensor_id | ts | rate | ts_window |
+-----------+---------------------+------+---------------------+
| 1 | 2020-01-01 12:00:11 | 10.1 | 2020-01-01 12:00:00 |
| 1 | 2020-01-01 12:00:26 | 10.2 | 2020-01-01 12:00:15 |
| 1 | 2020-01-01 12:00:41 | 10.3 | 2020-01-01 12:00:30 |
| 2 | 2020-01-01 12:00:08 | 11.1 | 2020-01-01 12:00:00 |
| 2 | 2020-01-01 12:00:23 | 11.2 | 2020-01-01 12:00:15 |
| 2 | 2020-01-01 12:00:38 | 11.3 | 2020-01-01 12:00:30 |
+-----------+---------------------+------+---------------------*/
Vous pouvez utiliser ce concept pour associer les données de taux de consommation de carburant aux températures rapportées par chaque capteur :
SELECT
t1.sensor_id AS sensor_id,
t1.ts AS temp_ts,
t1.temp AS temp,
t2.ts AS rate_ts,
t2.rate AS rate
FROM mydataset.sensor_temperatures t1
LEFT JOIN mydataset.sensor_fuel_rates t2
ON TIMESTAMP_BUCKET(t1.ts, INTERVAL 15 SECOND) =
TIMESTAMP_BUCKET(t2.ts, INTERVAL 15 SECOND)
AND t1.sensor_id = t2.sensor_id
ORDER BY sensor_id, temp_ts;
/*-----------+---------------------+------+---------------------+------+
| sensor_id | temp_ts | temp | rate_ts | rate |
+-----------+---------------------+------+---------------------+------+
| 1 | 2020-01-01 12:00:00 | 37.1 | 2020-01-01 12:00:11 | 10.1 |
| 1 | 2020-01-01 12:00:15 | 37.2 | 2020-01-01 12:00:26 | 10.2 |
| 1 | 2020-01-01 12:00:30 | 37.3 | 2020-01-01 12:00:41 | 10.3 |
| 2 | 2020-01-01 12:00:01 | 38.1 | 2020-01-01 12:00:08 | 11.1 |
| 2 | 2020-01-01 12:00:15 | 38.2 | 2020-01-01 12:00:23 | 11.2 |
| 2 | 2020-01-01 12:00:31 | 38.3 | 2020-01-01 12:00:38 | 11.3 |
+-----------+---------------------+------+---------------------+------*/
Jointure AS OF
Pour cette section, utilisez la table mydataset.sensor_temperatures et créez une table que vous nommerez mydataset.sensor_location.
La table mydataset.sensor_temperatures contient les données de température de différents capteurs, transmises toutes les 15 secondes :
SELECT * FROM mydataset.sensor_temperatures ORDER BY sensor_id, ts;
/*-----------+---------------------+------+
| sensor_id | ts | temp |
+-----------+---------------------+------+
| 1 | 2020-01-01 12:00:00 | 37.1 |
| 1 | 2020-01-01 12:00:15 | 37.2 |
| 1 | 2020-01-01 12:00:30 | 37.3 |
| 2 | 2020-01-01 12:00:45 | 38.1 |
| 2 | 2020-01-01 12:01:01 | 38.2 |
| 2 | 2020-01-01 12:01:15 | 38.3 |
+-----------+---------------------+------*/
Pour créer mydataset.sensor_location, exécutez la requête suivante :
CREATE OR REPLACE TABLE mydataset.sensor_locations AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, ts TIMESTAMP, location GEOGRAPHY>>[
(1, TIMESTAMP '2020-01-01 11:59:47.063', ST_GEOGPOINT(-122.022, 37.406)),
(1, TIMESTAMP '2020-01-01 12:00:08.185', ST_GEOGPOINT(-122.021, 37.407)),
(1, TIMESTAMP '2020-01-01 12:00:28.032', ST_GEOGPOINT(-122.020, 37.405)),
(2, TIMESTAMP '2020-01-01 07:28:41.239', ST_GEOGPOINT(-122.390, 37.790))
]);
/*-----------+---------------------+------------------------+
| sensor_id | ts | location |
+-----------+---------------------+------------------------+
| 1 | 2020-01-01 11:59:47 | POINT(-122.022 37.406) |
| 1 | 2020-01-01 12:00:08 | POINT(-122.021 37.407) |
| 1 | 2020-01-01 12:00:28 | POINT(-122.02 37.405) |
| 2 | 2020-01-01 07:28:41 | POINT(-122.39 37.79) |
+-----------+---------------------+------------------------*/
Définissez maintenant une jointure entre les données de mydataset.sensor_temperatures et celles de mydataset.sensor_location.
Dans ce scénario, vous ne pouvez pas utiliser de jointure fenêtrée, car les données de température et la date d'emplacement ne sont pas consignées selon le même intervalle.
Pour effectuer cette opération dans BigQuery, vous pouvez transformer les données d'horodatage en plage, à l'aide du type de données RANGE. La plage représente la validité temporelle d'une ligne et fournit les heures de début et de fin de validité de la ligne.
Utilisez la fonction de fenêtrage LEAD pour trouver le point de données suivant de la série temporelle par rapport au point de données actuel, qui est également la limite finale de la validité temporelle de la ligne actuelle. Les requêtes suivantes le prouvent, en convertissant les données de localisation en plages de validité :
WITH locations_ranges AS (
SELECT
sensor_id,
RANGE(ts, LEAD(ts) OVER (PARTITION BY sensor_id ORDER BY ts ASC)) AS ts_range,
location
FROM mydataset.sensor_locations
)
SELECT * FROM locations_ranges ORDER BY sensor_id, ts_range;
/*-----------+--------------------------------------------+------------------------+
| sensor_id | ts_range | location |
+-----------+--------------------------------------------+------------------------+
| 1 | [2020-01-01 11:59:47, 2020-01-01 12:00:08) | POINT(-122.022 37.406) |
| 1 | [2020-01-01 12:00:08, 2020-01-01 12:00:28) | POINT(-122.021 37.407) |
| 1 | [2020-01-01 12:00:28, UNBOUNDED) | POINT(-122.02 37.405) |
| 2 | [2020-01-01 07:28:41, UNBOUNDED) | POINT(-122.39 37.79) |
+-----------+--------------------------------------------+------------------------*/
Vous pouvez maintenant associer les données de températures (à gauche) aux données de localisation (à droite) :
WITH locations_ranges AS (
SELECT
sensor_id,
RANGE(ts, LEAD(ts) OVER (PARTITION BY sensor_id ORDER BY ts ASC)) AS ts_range,
location
FROM mydataset.sensor_locations
)
SELECT
t1.sensor_id AS sensor_id,
t1.ts AS temp_ts,
t1.temp AS temp,
t2.location AS location
FROM mydataset.sensor_temperatures t1
LEFT JOIN locations_ranges t2
ON RANGE_CONTAINS(t2.ts_range, t1.ts)
AND t1.sensor_id = t2.sensor_id
ORDER BY sensor_id, temp_ts;
/*-----------+---------------------+------+------------------------+
| sensor_id | temp_ts | temp | location |
+-----------+---------------------+------+------------------------+
| 1 | 2020-01-01 12:00:00 | 37.1 | POINT(-122.022 37.406) |
| 1 | 2020-01-01 12:00:15 | 37.2 | POINT(-122.021 37.407) |
| 1 | 2020-01-01 12:00:30 | 37.3 | POINT(-122.02 37.405) |
| 2 | 2020-01-01 12:00:01 | 38.1 | POINT(-122.39 37.79) |
| 2 | 2020-01-01 12:00:15 | 38.2 | POINT(-122.39 37.79) |
| 2 | 2020-01-01 12:00:31 | 38.3 | POINT(-122.39 37.79) |
+-----------+---------------------+------+------------------------*/
Combiner et diviser des données de plage
Dans cette section, combinez les données de plage comprenant des plages qui se chevauchent et divisez les données de plage en plages plus petites.
Combiner les données de plage
Les tables contenant des valeurs de plage peuvent comporter des plages qui se chevauchent. Dans la requête suivante, les périodes capturent l'état des capteurs à des intervalles d'environ cinq minutes :
CREATE OR REPLACE TABLE mydataset.sensor_metrics AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, duration RANGE<DATETIME>, flow INT64, spins INT64>>[
(1, RANGE<DATETIME> "[2020-01-01 12:00:01, 2020-01-01 12:05:23)", 10, 1),
(1, RANGE<DATETIME> "[2020-01-01 12:05:12, 2020-01-01 12:10:46)", 10, 20),
(1, RANGE<DATETIME> "[2020-01-01 12:10:27, 2020-01-01 12:15:56)", 11, 4),
(1, RANGE<DATETIME> "[2020-01-01 12:16:00, 2020-01-01 12:20:58)", 11, 9),
(1, RANGE<DATETIME> "[2020-01-01 12:20:33, 2020-01-01 12:25:08)", 11, 8),
(2, RANGE<DATETIME> "[2020-01-01 12:00:19, 2020-01-01 12:05:08)", 21, 31),
(2, RANGE<DATETIME> "[2020-01-01 12:05:08, 2020-01-01 12:10:30)", 21, 2),
(2, RANGE<DATETIME> "[2020-01-01 12:10:22, 2020-01-01 12:15:42)", 21, 10)
]);
La requête suivante sur la table montre plusieurs plages qui se chevauchent :
SELECT * FROM mydataset.sensor_metrics;
/*-----------+--------------------------------------------+------+-------+
| sensor_id | duration | flow | spins |
+-----------+--------------------------------------------+------+-------+
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:05:23) | 10 | 1 |
| 1 | [2020-01-01 12:05:12, 2020-01-01 12:10:46) | 10 | 20 |
| 1 | [2020-01-01 12:10:27, 2020-01-01 12:15:56) | 11 | 4 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:20:58) | 11 | 9 |
| 1 | [2020-01-01 12:20:33, 2020-01-01 12:25:08) | 11 | 8 |
| 2 | [2020-01-01 12:00:19, 2020-01-01 12:05:08) | 21 | 31 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:10:30) | 21 | 2 |
| 2 | [2020-01-01 12:10:22, 2020-01-01 12:15:42) | 21 | 10 |
+-----------+--------------------------------------------+------+-------*/
Pour certaines des plages qui se chevauchent, la valeur de la colonne flow est identique.
Par exemple, les lignes 1 et 2 se chevauchent, et ont également les mêmes relevés flow. Vous pouvez combiner ces deux lignes pour réduire le nombre de lignes dans la table. Vous pouvez utiliser la fonction de table RANGE_SESSIONIZE pour rechercher des plages qui se chevauchent avec chaque ligne, puis fournir une colonne session_range supplémentaire contenant une plage correspondant à l'union de toutes les plages qui se chevauchent. Pour afficher les plages de sessions pour chaque ligne, exécutez la requête suivante :
SELECT sensor_id, session_range, flow
FROM RANGE_SESSIONIZE(
# Input data.
(SELECT sensor_id, duration, flow FROM mydataset.sensor_metrics),
# Range column.
"duration",
# Partitioning columns. Ranges are sessionized only within these partitions.
["sensor_id", "flow"],
# Sessionize mode.
"OVERLAPS")
ORDER BY sensor_id, session_range;
/*-----------+--------------------------------------------+------+
| sensor_id | session_range | flow |
+-----------+--------------------------------------------+------+
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:10:46) | 10 |
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:10:46) | 10 |
| 1 | [2020-01-01 12:10:27, 2020-01-01 12:15:56) | 11 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:25:08) | 11 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:25:08) | 11 |
| 2 | [2020-01-01 12:00:19, 2020-01-01 12:05:08) | 21 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:15:42) | 21 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:15:42) | 21 |
+-----------+--------------------------------------------+------*/
Notez que pour un sensor_id ayant la valeur 2, la limite de fin de la première ligne possède la même valeur date/heure que la limite de début de la deuxième ligne. Toutefois, étant donné que les limites de fin sont exclusives, les lignes ne se chevauchent pas (uniquement se correspondent) et ne se trouvent donc pas dans les mêmes plages de sessions. Si vous souhaitez placer ces deux lignes dans les mêmes plages de session, utilisez le mode de session MEETS.
Pour combiner les plages, regroupez les résultats par session_range et par colonnes de partitionnement (sensor_id et flow) :
SELECT sensor_id, session_range, flow
FROM RANGE_SESSIONIZE(
(SELECT sensor_id, duration, flow FROM mydataset.sensor_metrics),
"duration",
["sensor_id", "flow"],
"OVERLAPS")
GROUP BY sensor_id, session_range, flow
ORDER BY sensor_id, session_range;
/*-----------+--------------------------------------------+------+
| sensor_id | session_range | flow |
+-----------+--------------------------------------------+------+
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:10:46) | 10 |
| 1 | [2020-01-01 12:10:27, 2020-01-01 12:15:56) | 11 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:25:08) | 11 |
| 2 | [2020-01-01 12:00:19, 2020-01-01 12:05:08) | 21 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:15:42) | 21 |
+-----------+--------------------------------------------+------*/
Enfin, ajoutez la colonne spins aux données de session en les agrégeant avec SUM.
SELECT sensor_id, session_range, flow, SUM(spins) as spins
FROM RANGE_SESSIONIZE(
TABLE mydataset.sensor_metrics,
"duration",
["sensor_id", "flow"],
"OVERLAPS")
GROUP BY sensor_id, session_range, flow
ORDER BY sensor_id, session_range;
/*-----------+--------------------------------------------+------+-------+
| sensor_id | session_range | flow | spins |
+-----------+--------------------------------------------+------+-------+
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:10:46) | 10 | 21 |
| 1 | [2020-01-01 12:10:27, 2020-01-01 12:15:56) | 11 | 4 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:25:08) | 11 | 17 |
| 2 | [2020-01-01 12:00:19, 2020-01-01 12:05:08) | 21 | 31 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:15:42) | 21 | 12 |
+-----------+--------------------------------------------+------+-------*/
Diviser les données de plage
Vous pouvez également diviser une plage en plages plus petites. Pour cet exemple, utilisez le tableau suivant avec des données de plage :
/*-----------+--------------------------+------+-------+
| sensor_id | duration | flow | spins |
+-----------+--------------------------+------+-------+
| 1 | [2020-01-01, 2020-12-31) | 10 | 21 |
| 1 | [2021-01-01, 2021-12-31) | 11 | 4 |
| 2 | [2020-04-15, 2021-04-15) | 21 | 31 |
| 2 | [2021-04-15, 2021-04-15) | 21 | 12 |
+-----------+--------------------------+------+-------*/
Divisez maintenant les plages d'origine en intervalles de trois mois :
WITH sensor_data AS (
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, duration RANGE<DATE>, flow INT64, spins INT64>>[
(1, RANGE<DATE> "[2020-01-01, 2020-12-31)", 10, 21),
(1, RANGE<DATE> "[2021-01-01, 2021-12-31)", 11, 4),
(2, RANGE<DATE> "[2020-04-15, 2021-04-15)", 21, 31),
(2, RANGE<DATE> "[2021-04-15, 2022-04-15)", 21, 12)
])
)
SELECT sensor_id, expanded_range, flow, spins
FROM sensor_data, UNNEST(GENERATE_RANGE_ARRAY(duration, INTERVAL 3 MONTH)) AS expanded_range;
/*-----------+--------------------------+------+-------+
| sensor_id | expanded_range | flow | spins |
+-----------+--------------------------+------+-------+
| 1 | [2020-01-01, 2020-04-01) | 10 | 21 |
| 1 | [2020-04-01, 2020-07-01) | 10 | 21 |
| 1 | [2020-07-01, 2020-10-01) | 10 | 21 |
| 1 | [2020-10-01, 2020-12-31) | 10 | 21 |
| 1 | [2021-01-01, 2021-04-01) | 11 | 4 |
| 1 | [2021-04-01, 2021-07-01) | 11 | 4 |
| 1 | [2021-07-01, 2021-10-01) | 11 | 4 |
| 1 | [2021-10-01, 2021-12-31) | 11 | 4 |
| 2 | [2020-04-15, 2020-07-15) | 21 | 31 |
| 2 | [2020-07-15, 2020-10-15) | 21 | 31 |
| 2 | [2020-10-15, 2021-01-15) | 21 | 31 |
| 2 | [2021-01-15, 2021-04-15) | 21 | 31 |
| 2 | [2021-04-15, 2021-07-15) | 21 | 12 |
| 2 | [2021-07-15, 2021-10-15) | 21 | 12 |
| 2 | [2021-10-15, 2022-01-15) | 21 | 12 |
| 2 | [2022-01-15, 2022-04-15) | 21 | 12 |
+-----------+--------------------------+------+-------*/
Dans la requête précédente, chaque plage d'origine a été divisée en plages plus petites, avec une largeur définie sur INTERVAL 3 MONTH. Toutefois, les plages de trois mois ne sont pas alignées sur une origine commune. Pour aligner ces plages sur une origine commune 2020-01-01, exécutez la requête suivante :
WITH sensor_data AS (
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, duration RANGE<DATE>, flow INT64, spins INT64>>[
(1, RANGE<DATE> "[2020-01-01, 2020-12-31)", 10, 21),
(1, RANGE<DATE> "[2021-01-01, 2021-12-31)", 11, 4),
(2, RANGE<DATE> "[2020-04-15, 2021-04-15)", 21, 31),
(2, RANGE<DATE> "[2021-04-15, 2022-04-15)", 21, 12)
])
)
SELECT sensor_id, expanded_range, flow, spins
FROM sensor_data
JOIN UNNEST(GENERATE_RANGE_ARRAY(RANGE<DATE> "[2020-01-01, 2022-12-31)", INTERVAL 3 MONTH)) AS expanded_range
ON RANGE_OVERLAPS(duration, expanded_range);
/*-----------+--------------------------+------+-------+
| sensor_id | expanded_range | flow | spins |
+-----------+--------------------------+------+-------+
| 1 | [2020-01-01, 2020-04-01) | 10 | 21 |
| 1 | [2020-04-01, 2020-07-01) | 10 | 21 |
| 1 | [2020-07-01, 2020-10-01) | 10 | 21 |
| 1 | [2020-10-01, 2021-01-01) | 10 | 21 |
| 1 | [2021-01-01, 2021-04-01) | 11 | 4 |
| 1 | [2021-04-01, 2021-07-01) | 11 | 4 |
| 1 | [2021-07-01, 2021-10-01) | 11 | 4 |
| 1 | [2021-10-01, 2022-01-01) | 11 | 4 |
| 2 | [2020-04-01, 2020-07-01) | 21 | 31 |
| 2 | [2020-07-01, 2020-10-01) | 21 | 31 |
| 2 | [2020-10-01, 2021-01-01) | 21 | 31 |
| 2 | [2021-01-01, 2021-04-01) | 21 | 31 |
| 2 | [2021-04-01, 2021-07-01) | 21 | 31 |
| 2 | [2021-04-01, 2021-07-01) | 21 | 12 |
| 2 | [2021-07-01, 2021-10-01) | 21 | 12 |
| 2 | [2021-10-01, 2022-01-01) | 21 | 12 |
| 2 | [2022-01-01, 2022-04-01) | 21 | 12 |
| 2 | [2022-04-01, 2022-07-01) | 21 | 12 |
+-----------+--------------------------+------+-------*/
Dans la requête précédente, la ligne contenant la plage [2020-04-15, 2021-04-15) est divisée en cinq plages, en commençant par la plage [2020-04-01, 2020-07-01). Notez que la limite de départ s'étend désormais au-delà de la limite de départ d'origine, afin de s'aligner sur l'origine commune. Si vous ne souhaitez pas que la limite de début s'étende au-delà de la limite de début d'origine, vous pouvez restreindre la condition JOIN :
WITH sensor_data AS (
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, duration RANGE<DATE>, flow INT64, spins INT64>>[
(1, RANGE<DATE> "[2020-01-01, 2020-12-31)", 10, 21),
(1, RANGE<DATE> "[2021-01-01, 2021-12-31)", 11, 4),
(2, RANGE<DATE> "[2020-04-15, 2021-04-15)", 21, 31),
(2, RANGE<DATE> "[2021-04-15, 2022-04-15)", 21, 12)
])
)
SELECT sensor_id, expanded_range, flow, spins
FROM sensor_data
JOIN UNNEST(GENERATE_RANGE_ARRAY(RANGE<DATE> "[2020-01-01, 2022-12-31)", INTERVAL 3 MONTH)) AS expanded_range
ON RANGE_CONTAINS(duration, RANGE_START(expanded_range));
/*-----------+--------------------------+------+-------+
| sensor_id | expanded_range | flow | spins |
+-----------+--------------------------+------+-------+
| 1 | [2020-01-01, 2020-04-01) | 10 | 21 |
| 1 | [2020-04-01, 2020-07-01) | 10 | 21 |
| 1 | [2020-07-01, 2020-10-01) | 10 | 21 |
| 1 | [2020-10-01, 2021-01-01) | 10 | 21 |
| 1 | [2021-01-01, 2021-04-01) | 11 | 4 |
| 1 | [2021-04-01, 2021-07-01) | 11 | 4 |
| 1 | [2021-07-01, 2021-10-01) | 11 | 4 |
| 1 | [2021-10-01, 2022-01-01) | 11 | 4 |
| 2 | [2020-07-01, 2020-10-01) | 21 | 31 |
| 2 | [2020-10-01, 2021-01-01) | 21 | 31 |
| 2 | [2021-01-01, 2021-04-01) | 21 | 31 |
| 2 | [2021-04-01, 2021-07-01) | 21 | 31 |
| 2 | [2021-07-01, 2021-10-01) | 21 | 12 |
| 2 | [2021-10-01, 2022-01-01) | 21 | 12 |
| 2 | [2022-01-01, 2022-04-01) | 21 | 12 |
| 2 | [2022-04-01, 2022-07-01) | 21 | 12 |
+-----------+--------------------------+------+-------*/
Vous constatez maintenant que la plage [2020-04-15, 2021-04-15) a été divisée en 4 plages, en commençant par la plage [2020-07-01, 2020-10-01).
Bonnes pratiques pour le stockage des données
Pour stocker des données de séries temporelles, il est important de prendre en compte les schémas de requête utilisés sur les tables dans lesquelles les données sont stockées. En règle générale, lorsque vous interrogez des données de séries temporelles, vous pouvez filtrer les données selon une période spécifique.
Pour optimiser ces modèles d'utilisation, il est recommandé de stocker les données de séries temporelles dans des tables partitionnées, avec des données partitionnées par la colonne Heure ou Heure d'ingestion. Cela peut considérablement améliorer les performances de requête des données de séries temporelles, car BigQuery peut ainsi éliminer les partitions qui ne contiennent pas les données interrogées.
Vous pouvez activer le clustering sur l'heure, la plage ou l'une des colonnes de partitionnement pour améliorer davantage les performances de temps de requête.