Search indexed data
This page provides examples of searching for table data in BigQuery.
When you index your data, BigQuery can optimize some queries
that use the SEARCH function
or other functions and operators,
such as =, IN, LIKE, and STARTS_WITH.
SQL queries return correct results from all ingested data, even if some of the data isn't indexed yet. However, query performance can be greatly improved with an index. Savings in bytes processed and slot milliseconds are maximized when the number of search results make up a relatively small fraction of the total rows in your table because less data is scanned. To determine whether an index was used for a query, see search index usage.
Create a search index
The following table called Logs is used to show different
ways of using the SEARCH function. This example table is quite small, but in
practice the performance gains you get with SEARCH improve with the size of
the table.
CREATE TABLE my_dataset.Logs (Level STRING, Source STRING, Message STRING) AS ( SELECT 'INFO' as Level, '65.177.8.234' as Source, 'Entry Foo-Bar created' as Message UNION ALL SELECT 'WARNING', '132.249.240.10', 'Entry Foo-Bar already exists, created by 65.177.8.234' UNION ALL SELECT 'INFO', '94.60.64.181', 'Entry Foo-Bar deleted' UNION ALL SELECT 'SEVERE', '4.113.82.10', 'Entry Foo-Bar does not exist, deleted by 94.60.64.181' UNION ALL SELECT 'INFO', '181.94.60.64', 'Entry Foo-Baz created' );
The table looks like the following:
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | | INFO | 181.94.60.64 | Entry Foo-Baz created | +---------+----------------+-------------------------------------------------------+
Create a search index on the Logs table using the default text analyzer:
CREATE SEARCH INDEX my_index ON my_dataset.Logs(ALL COLUMNS);
For more information about search indexes, see Manage search indexes.
Use the SEARCH function
The SEARCH function provides tokenized search on data.
SEARCH is designed to be used with an index to
optimize lookups.
You can use the SEARCH function to search an entire table or restrict your
search to specific columns.
Search an entire table
The following query searches across all columns of the Logs table for the
value bar and returns the rows that contain this value, regardless of
capitalization. Since the search index uses the default text analyzer, you don't
need to specify it in the SEARCH function.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, 'bar');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
The following query searches across all columns of the Logs table for the
value `94.60.64.181` and returns the rows that contain this value. The
backticks allow for an exact search, which is why the last row of the Logs
table which contains 181.94.60.64 is omitted.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
Search a subset of columns
SEARCH makes it easy to specify a subset of columns within which to search for
data. The following query searches the Message column of the Logs table for
the value 94.60.64.181 and returns the rows that contain this value.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Message, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
The following query searches both the Source and Message columns of the
Logs table. It returns the rows that contain the value 94.60.64.181 from
either column.
SELECT * FROM my_dataset.Logs WHERE SEARCH((Source, Message), '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
Exclude columns from a search
If a table table has many columns and you want to search most of them, it may be
easier to specify only the columns to exclude from the search. The following
query searches across all columns of the Logs table except for
the Message column. It returns the rows of any columns other than Message
that contains the value 94.60.64.181.
SELECT * FROM my_dataset.Logs WHERE SEARCH( (SELECT AS STRUCT Logs.* EXCEPT (Message)), '`94.60.64.181`');
+---------+----------------+---------------------------------------------------+ | Level | Source | Message | +---------+----------------+---------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | +---------+----------------+---------------------------------------------------+
Use a different text analyzer
The following example creates a table called contact_info with an index that
uses the NO_OP_ANALYZER
text analyzer:
CREATE TABLE my_dataset.contact_info (name STRING, email STRING) AS ( SELECT 'Kim Lee' AS name, 'kim.lee@example.com' AS email UNION ALL SELECT 'Kim' AS name, 'kim@example.com' AS email UNION ALL SELECT 'Sasha' AS name, 'sasha@example.com' AS email ); CREATE SEARCH INDEX noop_index ON my_dataset.contact_info(ALL COLUMNS) OPTIONS (analyzer = 'NO_OP_ANALYZER');
+---------+---------------------+ | name | email | +---------+---------------------+ | Kim Lee | kim.lee@example.com | | Kim | kim@example.com | | Sasha | sasha@example.com | +---------+---------------------+
The following query searches for Kim in the name column and kim
in the email column.
Since the search index doesn't use the default text analyzer, you must pass the
name of the analyzer to the SEARCH function.
SELECT name, SEARCH(name, 'Kim', analyzer=>'NO_OP_ANALYZER') AS name_Kim, email, SEARCH(email, 'kim', analyzer=>'NO_OP_ANALYZER') AS email_kim FROM my_dataset.contact_info;
The NO_OP_ANALYZER doesn't modify the text, so the SEARCH function only
returns TRUE for exact matches:
+---------+----------+---------------------+-----------+ | name | name_Kim | email | email_kim | +---------+----------+---------------------+-----------+ | Kim Lee | FALSE | kim.lee@example.com | FALSE | | Kim | TRUE | kim@example.com | FALSE | | Sasha | FALSE | sasha@example.com | FALSE | +---------+----------+---------------------+-----------+
Configure text analyzer options
The LOG_ANALYZER and PATTERN_ANALYZER text
analyzers can be
customized by adding a JSON-formatted string to the configuration options. You
can configure text analyzers in the SEARCH
function, the CREATE
SEARCH INDEX DDL
statement,
and the TEXT_ANALYZE
function.
The following example creates a table called complex_table with an index that
uses the LOG_ANALYZER text analyzer. It uses a JSON-formatted string to
configure the analyzer options:
CREATE TABLE dataset.complex_table( a STRING, my_struct STRUCT<string_field STRING, int_field INT64>, b ARRAY<STRING> ); CREATE SEARCH INDEX my_index ON dataset.complex_table(a, my_struct, b) OPTIONS (analyzer = 'LOG_ANALYZER', analyzer_options = '''{ "token_filters": [ { "normalization": {"mode": "NONE"} } ] }''');
The following tables shows examples of calls to the SEARCH function with
different text analyzers and their results. The first table calls the SEARCH
function using the default text analyzer, the LOG_ANALYZER:
| Function call | Returns | Reason |
|---|---|---|
| SEARCH('foobarexample', NULL) | ERROR | The search_terms is `NULL`. |
| SEARCH('foobarexample', '') | ERROR | The search_terms contains no tokens. |
| SEARCH('foobar-example', 'foobar example') | TRUE | '-' and ' ' are delimiters. |
| SEARCH('foobar-example', 'foobarexample') | FALSE | The search_terms isn't split. |
| SEARCH('foobar-example', 'foobar\\&example') | TRUE | The double backslash escapes the ampersand which is a delimiter. |
| SEARCH('foobar-example', R'foobar\&example') | TRUE | The single backslash escapes the ampersand in a raw string. |
| SEARCH('foobar-example', '`foobar&example`') | FALSE | The backticks require an exact match for foobar&example. |
| SEARCH('foobar&example', '`foobar&example`') | TRUE | An exact match is found. |
| SEARCH('foobar-example', 'example foobar') | TRUE | The order of terms doesn't matter. |
| SEARCH('foobar-example', 'foobar example') | TRUE | Tokens are made lower-case. |
| SEARCH('foobar-example', '`foobar-example`') | TRUE | An exact match is found. |
| SEARCH('foobar-example', '`foobar`') | FALSE | Backticks preserve capitalization. |
| SEARCH('`foobar-example`', '`foobar-example`') | FALSE | Backticks don't have special meaning for data_to_search and |
| SEARCH('foobar@example.com', '`example.com`') | TRUE | An exact match is found after the delimiter in data_to_search. |
| SEARCH('a foobar-example b', '`foobar-example`') | TRUE | An exact match is found between the space delimiters. |
| SEARCH(['foobar', 'example'], 'foobar example') | FALSE | No single array entry matches all search terms. |
| SEARCH('foobar=', '`foobar\\=`') | FALSE | The search_terms is equivalent to foobar\=. |
| SEARCH('foobar=', R'`foobar\=`') | FALSE | This is equivalent to the previous example. |
| SEARCH('foobar=', 'foobar\\=') | TRUE | The equals sign is a delimiter in the data and query. |
| SEARCH('foobar=', R'foobar\=') | TRUE | This is equivalent to the previous example. |
| SEARCH('foobar.example', '`foobar`') | TRUE | An exact match is found. |
| SEARCH('foobar.example', '`foobar.`') | FALSE | `foobar.` isn't analyzed because of backticks; it isn't |
| SEARCH('foobar..example', '`foobar.`') | TRUE | `foobar.` isn't analyzed because of backticks; it is followed |
The following table shows examples of calls to the SEARCH function using the
NO_OP_ANALYZER text analyzer and reasons for various return values:
| Function call | Returns | Reason |
|---|---|---|
| SEARCH('foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | TRUE | An exact match is found. |
| SEARCH('foobar', '`foobar`', analyzer=>'NO_OP_ANALYZER') | FALSE | Backticks aren't special characters for NO_OP_ANALYZER. |
| SEARCH('Foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | FALSE | The capitalization doesn't match. |
| SEARCH('foobar example', 'foobar', analyzer=>'NO_OP_ANALYZER') | FALSE | There are no delimiters for NO_OP_ANALYZER. |
| SEARCH('', '', analyzer=>'NO_OP_ANALYZER') | TRUE | There are no delimiters for NO_OP_ANALYZER. |
Other operators and functions
You can perform search index optimizations with several operators, functions, and predicates.
Optimize with operators and comparison functions
BigQuery can optimize some queries that use the
equal operator
(=),
IN operator,
LIKE operator,
or
STARTS_WITH function
to compare string literals with indexed data.
Optimize with string predicates
The following predicates are eligible for search index optimization:
column_name = 'string_literal''string_literal' = column_namestruct_column.nested_field = 'string_literal'string_array_column[OFFSET(0)] = 'string_literal'string_array_column[ORDINAL(1)] = 'string_literal'column_name IN ('string_literal1', 'string_literal2', ...)STARTS_WITH(column_name, 'prefix')column_name LIKE 'prefix%'
Optimize with numeric predicates
If the search index was created with numeric data types, BigQuery
can optimize some queries that use the equal operator (=) or IN operator
with indexed data. The following predicates are eligible for search index
optimization:
INT64(json_column.int64_field) = 1int64_column = 1int64_array_column[OFFSET(0)] = 1int64_column IN (1, 2)struct_column.nested_int64_field = 1struct_column.nested_timestamp_field = TIMESTAMP "2024-02-15 21:31:40"timestamp_column = "2024-02-15 21:31:40"timestamp_column IN ("2024-02-15 21:31:40", "2024-02-16 21:31:40")
Optimize functions that produce indexed data
BigQuery supports search index optimization when certain
functions are applied to indexed data.
If the search index uses the default LOG_ANALYZER text analyzer then you can
apply the
UPPER
or LOWER
functions to the column, such as UPPER(column_name) = 'STRING_LITERAL'.
For JSON scalar string data extracted from an indexed JSON column, you can
apply the
STRING
function or its safe version,
SAFE.STRING.
If the extracted JSON value is not a string, then the STRING function
produces an error and the SAFE.STRING function returns NULL.
For indexed
JSON-formatted STRING (not JSON) data, you can apply the following
functions:
For example, suppose you have the following indexed table called
dataset.person_data with a JSON and a STRING column:
+----------------------------------------------------------------+-----------------------------------------+
| json_column | string_column |
+----------------------------------------------------------------+-----------------------------------------+
| { "name" : "Ariel", "email" : "cloudysanfrancisco@gmail.com" } | { "name" : "Ariel", "job" : "doctor" } |
+----------------------------------------------------------------+-----------------------------------------+
The following queries are eligible for optimization:
SELECT * FROM dataset.person_data WHERE SAFE.STRING(json_column.email) = 'cloudysanfrancisco@gmail.com';
SELECT * FROM dataset.person_data WHERE JSON_VALUE(string_column, '$.job') IN ('doctor', 'lawyer', 'teacher');
Combinations of these functions are also optimized, such as
UPPER(JSON_VALUE(json_string_expression)) = 'FOO'.
Search index usage
To determine whether a search index was used for a query, you can view the
job details or query one of the INFORMATION_SCHEMA.JOBS* views.
View job details
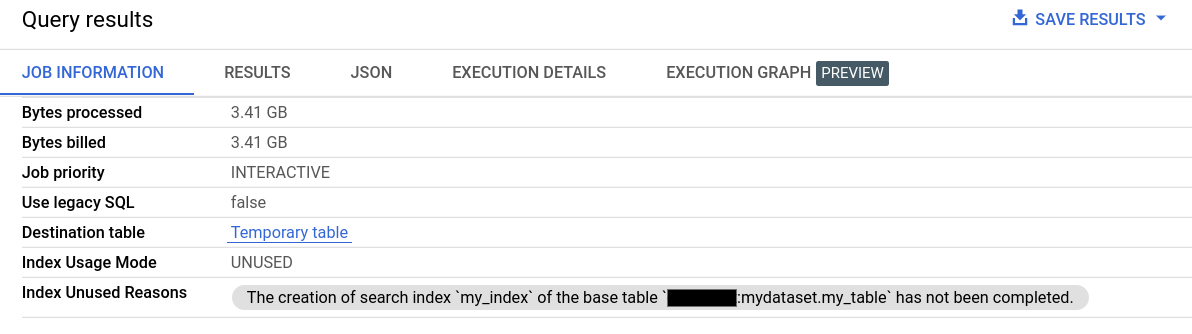
In Job Information of the Query results, the Index Usage Mode and Index Unused Reasons fields provide detailed information on search index usage.
Information on search index usage is also available through the
searchStatistics field
in the Jobs.Get API method. The
indexUsageMode field in searchStatistics indicates whether a search index
was used with the following values:
UNUSED: no search index was used.PARTIALLY_USED: part of the query used search indexes and part did not.FULLY_USED: everySEARCHfunction in the query used a search index.
When indexUsageMode is UNUSED or PARTIALLY_USED, the indexUnusuedReasons
field contains information about why search indexes were not used in the query.
To view searchStatistics for a query, run the bq show command.
bq show --format=prettyjson -j JOB_ID
Example
Suppose you run a query that calls the SEARCH function on data in a table. You
can view the
job details of the query to
find the job ID, then run the bq show command to see more information:
bq show --format=prettyjson --j my_project:US.bquijob_123x456_789y123z456c
The output contains many fields, including searchStatistics, which looks
similar to the following. In this example, indexUsageMode indicates that the
index was not used. The reason is that the table doesn't have a search index. To
solve this problem, create a search index on the
table. See the
indexUnusedReason code field
for a list of all reasons a search index might not be used in a query.
"searchStatistics": {
"indexUnusedReasons": [
{
"baseTable": {
"datasetId": "my_dataset",
"projectId": "my_project",
"tableId": "my_table"
},
"code": "INDEX_CONFIG_NOT_AVAILABLE",
"message": "There is no search index configuration for the base table `my_project:my_dataset.my_table`."
}
],
"indexUsageMode": "UNUSED"
},
Query INFORMATION_SCHEMA views
You can also see search index usage for multiple jobs in a region in the following views:
INFORMATION_SCHEMA.JOBSINFORMATION_SCHEMA.JOBS_BY_USERINFORMATION_SCHEMA.JOBS_BY_FOLDERINFORMATION_SCHEMA.JOBS_BY_ORGANIZATION
The following query shows information about index usage for all search index optimizable queries in the past 7 days:
SELECT job_id, search_statistics.index_usage_mode, index_unused_reason.code, index_unused_reason.base_table.table_id, index_unused_reason.index_name FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS, UNNEST(search_statistics.index_unused_reasons) AS index_unused_reason WHERE end_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP();
The result is similar to the following:
+-----------+----------------------------------------+-----------------------+ | job_id | index_usage_mode | code | table_id | index_name | +-----------+------------------+---------------------+-----------------------+ | bquxjob_1 | UNUSED | BASE_TABLE_TOO_SMALL| my_table | my_index | | bquxjob_2 | FULLY_USED | NULL | my_table | my_index | +-----------+----------------------------------------+-----------------------+
Best practices
The following sections describe best practices for searching.
Search selectively
Searching works best when your search has few results. Make your searches as specific as possible.
ORDER BY LIMIT optimization
Queries that use SEARCH, =, IN, LIKE or STARTS_WITH on a very large
partitioned table can be optimized
when you use an ORDER BY clause on the partitioned field and a LIMIT clause.
For queries that don't contain the SEARCH function, you can use the
other operators and functions to take
advantage of the optimization. The optimization is applied whether or not the
table is indexed. This works well if you're searching for a common term.
For example, suppose the Logs table created earlier
is partitioned on an additional DATE type column
called day. The following query is optimized:
SELECT Level, Source, Message FROM my_dataset.Logs WHERE SEARCH(Message, "foo") ORDER BY day LIMIT 10;
Scope your search
When you use the SEARCH function, only search the columns of the table that
you expect to contain your search terms. This improves performance and
reduces the number of bytes that need to be scanned.
Use backticks
When you use the SEARCH function with the LOG_ANALYZER text analyzer,
enclosing your search query in backticks
forces an exact match. This is helpful
if your search is case-sensitive or contains characters that shouldn't be
interpreted as delimiters. For example, to search for the IP address
192.0.2.1, use `192.0.2.1`. Without the backticks, the search returns
any row that contains the individual tokens 192, 0, 2, and 1, in any
order.