Programmazione delle query
Questa pagina descrive come programmare query ricorrenti in BigQuery.
Puoi pianificare l'esecuzione delle query su base ricorrente. Le query pianificate devono essere scritte in GoogleSQL, che può includere istruzioni in Data Definition Language (DDL) e Data Manipulation Language (DML). Puoi organizzare i risultati della query per data e ora parametrizzando la stringa di query e la tabella di destinazione.
Quando crei o aggiorni la pianificazione di una query, l'ora pianificata per la query viene convertita dall'ora locale in UTC. Il fuso orario UTC non è interessato dall'ora legale.
Prima di iniziare
- Le query pianificate utilizzano funzionalità di BigQuery Data Transfer Service. Verifica di aver completato tutte le azioni richieste in Attivazione di BigQuery Data Transfer Service.
- Concedi i ruoli IAM (Identity and Access Management) che forniscono agli utenti le autorizzazioni necessarie per eseguire ogni attività descritta in questo documento.
- Se prevedi di specificare una chiave di crittografia gestita dal cliente (CMEK), assicurati che il tuo service account disponga delle autorizzazioni per criptare e decriptare e di disporre dell'ID risorsa chiave Cloud KMS necessario per utilizzare CMEK. Per informazioni su come funzionano le CMEK con BigQuery Data Transfer Service, vedi Specifica la chiave di crittografia con le query pianificate.
Autorizzazioni obbligatorie
Per pianificare una query, devi disporre delle seguenti autorizzazioni IAM:
Per creare il trasferimento, devi disporre delle autorizzazioni
bigquery.transfers.updateebigquery.datasets.getoppure delle autorizzazionibigquery.jobs.create,bigquery.transfers.getebigquery.datasets.get.Per eseguire una query pianificata, devi disporre di:
- Autorizzazioni
bigquery.datasets.getsul set di dati di destinazione bigquery.jobs.create
- Autorizzazioni
Per modificare o eliminare una query pianificata, devi disporre delle autorizzazioni
bigquery.transfers.update e bigquery.transfers.get oppure dell'autorizzazione
bigquery.jobs.create e della proprietà della query pianificata.
Il ruolo IAM
BigQuery Admin (roles/bigquery.admin)
predefinito include le autorizzazioni necessarie per
pianificare o modificare una query.
Per saperne di più sui ruoli IAM in BigQuery, consulta Ruoli e autorizzazioni predefiniti.
Per creare o aggiornare le query pianificate eseguite da un account di servizio, devi avere accesso a questoaccount di serviziot. Per ulteriori informazioni sulla concessione agli utenti del ruolo account di serviziot, consulta Ruolo Utente service account. Per selezionare un account di servizio nell'interfaccia utente delle query pianificate della consoleGoogle Cloud , devi disporre delle seguenti autorizzazioni IAM:
iam.serviceAccounts.listper elencare i service account.iam.serviceAccountUserper assegnare un account di servizio a una query pianificata.
Opzioni di configurazione
Le sezioni seguenti descrivono le opzioni di configurazione.
Stringa di query
La stringa di query deve essere valida e scritta in GoogleSQL. Ogni esecuzione di una query pianificata può ricevere i seguenti parametri di query.
Per testare manualmente una stringa di query con i parametri @run_time e @run_date
prima di pianificare una query, utilizza lo strumento a riga di comando bq.
Parametri disponibili
| Parametro | Tipo GoogleSQL | Valore |
|---|---|---|
@run_time |
TIMESTAMP |
Rappresentato in ora UTC. Per le query programmate regolarmente, run_time rappresenta l'ora di esecuzione prevista. Ad esempio, se la query pianificata è impostata su "ogni 24 ore", la differenza run_time tra due query consecutive è esattamente di 24 ore, anche se l'ora di esecuzione effettiva potrebbe variare leggermente. |
@run_date |
DATE |
Rappresenta una data di calendario logica. |
Esempio
Il parametro @run_time fa parte della stringa di query in questo esempio, che
interroga un set di dati pubblico denominato hacker_news.stories.
SELECT @run_time AS time, title, author, text FROM `bigquery-public-data.hacker_news.stories` LIMIT 1000
Tabella di destinazione
Se la tabella di destinazione per i risultati non esiste quando configuri la query pianificata, BigQuery tenta di crearla.
Se utilizzi una query DDL o DML, nella console Google Cloud scegli la Località di elaborazione o la regione. La località di elaborazione è necessaria per le query DDL o DML che creano la tabella di destinazione.
Se la tabella di destinazione esiste e utilizzi la WRITE_APPEND
preferenza di scrittura, BigQuery aggiunge i dati
alla tabella di destinazione e tenta di mappare lo schema.
BigQuery consente automaticamente l'aggiunta e il riordino dei campi e
gestisce i campi facoltativi mancanti. Se lo schema della tabella cambia così tanto
tra le esecuzioni che BigQuery non riesce a elaborare le modifiche
automaticamente, la query pianificata non va a buon fine.
Le query possono fare riferimento a tabelle di progetti e set di dati diversi. Quando configuri la query pianificata, non è necessario includere il set di dati di destinazione nel nome della tabella. Specifichi il set di dati di destinazione separatamente.
Il set di dati e la tabella di destinazione per una query pianificata devono trovarsi nello stesso progetto della query pianificata.
Preferenza di scrittura
La preferenza di scrittura selezionata determina la modalità di scrittura dei risultati della query in una tabella di destinazione esistente.
WRITE_TRUNCATE: se la tabella esiste, BigQuery sovrascrive i dati della tabella.WRITE_APPEND: se la tabella esiste, BigQuery aggiunge i dati alla tabella.
Se utilizzi una query DDL o DML, non puoi utilizzare l'opzione di preferenza di scrittura.
La creazione, il troncamento o l'aggiunta di una tabella di destinazione avviene solo se BigQuery è in grado di completare correttamente la query. Le azioni di creazione, troncamento o aggiunta vengono eseguite come un unico aggiornamento atomico al termine del job.
Clustering
Le query pianificate possono creare il clustering solo su nuove tabelle, quando la tabella viene
creata con un'istruzione DDL CREATE TABLE AS SELECT. Consulta la sezione
Creazione di una tabella in cluster da un risultato di query
nella pagina Utilizzo delle istruzioni del linguaggio di definizione dei dati.
Opzioni di partizionamento
Le query pianificate possono creare tabelle di destinazione partizionate o non partizionate. Il partizionamento è disponibile nella console Google Cloud , nello strumento a riga di comando bq e nei metodi di configurazione dell'API. Se utilizzi una query DDL o DML con il partizionamento, lascia vuoto il campo di partizionamento della tabella di destinazione.
Puoi utilizzare i seguenti tipi di partizionamento delle tabelle in BigQuery:
- Partizionamento per intervallo di numeri interi:
Tabelle partizionate in base a intervalli di valori in una colonna
INTEGERspecifica. - Partizionamento delle colonne per unità di tempo: tabelle partizionate in base a una colonna
TIMESTAMP,DATEoDATETIME. - Partizionamento per tempo di importazione: Tabelle partizionate per tempo di importazione. BigQuery assegna automaticamente le righe alle partizioni in base all'ora in cui BigQuery inserisce i dati.
Per creare una tabella partizionata utilizzando una query pianificata nella consoleGoogle Cloud , utilizza le seguenti opzioni:
Per utilizzare il partizionamento dell'intervallo di numeri interi, lascia vuoto il campo di partizionamento della tabella di destinazione.
Per utilizzare il partizionamento delle colonne per unità di tempo, specifica il nome della colonna nel campo Campo di partizionamento della tabella di destinazione quando configuri una query pianificata.
Per utilizzare il partizionamento in base all'ora di importazione, lascia vuoto il campo di partizionamento della tabella di destinazione e indica il partizionamento delle date nel nome della tabella di destinazione. Ad esempio,
mytable${run_date}. Per saperne di più, vedi Sintassi dei modelli di parametri.
Parametri disponibili
Quando configuri la query pianificata, puoi specificare come partizionare la tabella di destinazione con i parametri di runtime.
| Parametro | Tipo di modello | Valore |
|---|---|---|
run_time |
Timestamp formattato | In orario UTC, in base alla pianificazione. Per le query programmate regolarmente, run_time rappresenta l'ora di esecuzione prevista. Ad esempio, se la query pianificata è impostata su "ogni 24 ore", la differenza run_time tra due query consecutive è esattamente di 24 ore, anche se il tempo di esecuzione effettivo può variare leggermente.Vedi TransferRun.runTime. |
run_date |
Stringa di data | La data del parametro run_time nel seguente formato: %Y-%m-%d; ad esempio, 2018-01-01. Questo formato è compatibile con le tabelle partizionate per data di importazione. |
Sistema di modelli
Le query pianificate supportano i parametri di runtime nel nome della tabella di destinazione con una sintassi di modelli.
Sintassi dei modelli di parametri
La sintassi dei modelli supporta i modelli di stringhe di base e l'offset temporale. I parametri sono indicati nei seguenti formati:
{run_date}{run_time[+\-offset]|"time_format"}
| Parametro | Purpose |
|---|---|
run_date |
Questo parametro viene sostituito dalla data nel formato YYYYMMDD. |
run_time |
Questo parametro supporta le seguenti proprietà:
|
- Non sono consentiti spazi vuoti tra run_time, offset e formato dell'ora.
- Per includere parentesi graffe letterali nella stringa, puoi eseguirne l'escape come
'\{' and '\}'. - Per includere virgolette letterali o una barra verticale in time_format, ad esempio
"YYYY|MM|DD", puoi eseguirne l'escape nella stringa di formato come:'\"'o'\|'.
Esempi di modelli di parametri
Questi esempi mostrano la specifica dei nomi delle tabelle di destinazione con diversi formati di ora e l'offset del tempo di esecuzione.| run_time (UTC) | Parametro basato su modello | Nome della tabella di destinazione di output |
|---|---|---|
| 2018-02-15 00:00:00 | mytable |
mytable |
| 2018-02-15 00:00:00 | mytable_{run_time|"%Y%m%d"} |
mytable_20180215 |
| 2018-02-15 00:00:00 | mytable_{run_time+25h|"%Y%m%d"} |
mytable_20180216 |
| 2018-02-15 00:00:00 | mytable_{run_time-1h|"%Y%m%d"} |
mytable_20180214 |
| 2018-02-15 00:00:00 | mytable_{run_time+1.5h|"%Y%m%d%H"}
o mytable_{run_time+90m|"%Y%m%d%H"} |
mytable_2018021501 |
| 2018-02-15 00:00:00 | {run_time+97s|"%Y%m%d"}_mytable_{run_time+97s|"%H%M%S"} |
20180215_mytable_000137 |
utilizza un service account
Puoi configurare una query pianificata per l'autenticazione come account di servizio. Un account di servizio è un account speciale associato al tuo progetto Google Cloud . Il account di servizio può eseguire job, come query programmate o pipeline di elaborazione batch, con le proprie credenziali di servizio anziché con le credenziali di un utente finale.
Scopri di più sull'autenticazione con i service account in Introduzione all'autenticazione.
Puoi configurare la query pianificata con un service account. Se hai eseguito l'accesso con un'identità federata, è necessario un account di servizio per creare un trasferimento. Se hai eseguito l'accesso con un Account Google, il account di servizio per il trasferimento è facoltativo.
Puoi aggiornare una query pianificata esistente con le credenziali di un account di servizio con lo strumento a riga di comando bq o la console. Google Cloud Per ulteriori informazioni, vedi Aggiornare le credenziali delle query pianificate.
Specifica la chiave di crittografia con le query pianificate
Puoi specificare le chiavi di crittografia gestite dal cliente (CMEK) per criptare i dati per un'esecuzione del trasferimento. Puoi utilizzare una chiave CMEK per supportare i trasferimenti da query pianificate.Quando specifichi una CMEK con un trasferimento, BigQuery Data Transfer Service la applica a qualsiasi cache su disco intermedia dei dati importati, in modo che l'intero flusso di lavoro di trasferimento dei dati sia conforme alla CMEK.
Non puoi aggiornare un trasferimento esistente per aggiungere una chiave CMEK se il trasferimento non è stato originariamente creato con una chiave CMEK. Ad esempio, non puoi modificare una tabella di destinazione che originariamente era criptata per impostazione predefinita in modo che ora sia criptata con CMEK. Al contrario, non puoi modificare una tabella di destinazione criptata con CMEK in modo che abbia un tipo di crittografia diverso.
Puoi aggiornare una CMEK per un trasferimento se la configurazione del trasferimento è stata originariamente creata con una crittografia CMEK. Quando aggiorni una CMEK per una configurazione di trasferimento, BigQuery Data Transfer Service la propaga alle tabelle di destinazione alla successiva esecuzione del trasferimento, durante la quale BigQuery Data Transfer Service sostituisce le CMEK obsolete con la nuova CMEK. Per saperne di più, vedi Aggiornare un trasferimento.
Puoi anche utilizzare le chiavi predefinite del progetto. Quando specifichi una chiave predefinita del progetto con un trasferimento, BigQuery Data Transfer Service utilizza la chiave predefinita del progetto come chiave predefinita per qualsiasi nuova configurazione di trasferimento.
Configurare le query pianificate
Per una descrizione della sintassi della pianificazione, vedi
Formattazione della pianificazione.
Per informazioni dettagliate sulla sintassi della pianificazione, consulta Risorsa: TransferConfig.
Console
Apri la pagina BigQuery nella console Google Cloud .
Esegui la query che ti interessa. Quando i risultati ti soddisfano, fai clic su Pianifica.
Le opzioni della query pianificata si aprono nel riquadro Nuova query pianificata.
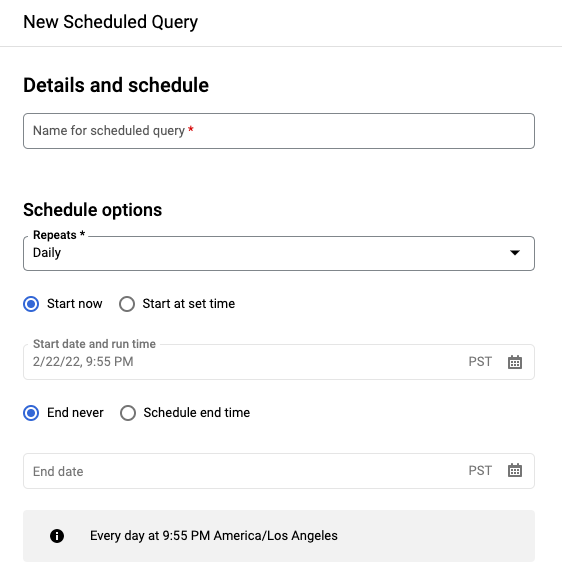
Nel riquadro Nuova query programmata:
- In Nome della query pianificata, inserisci un nome come
My scheduled query. Il nome della query programmata può essere qualsiasi valore che puoi identificare in un secondo momento se devi modificare la query. (Facoltativo) Per impostazione predefinita, l'esecuzione della query è pianificata quotidianamente. Puoi modificare la programmazione predefinita selezionando un'opzione dal menu a discesa Ripeti:
Per specificare una frequenza personalizzata, seleziona Personalizzata, quindi inserisci una specifica dell'ora in stile Cron nel campo Pianificazione personalizzata, ad esempio
every mon 23:30oevery 6 hours. Per informazioni dettagliate sulle pianificazioni valide, inclusi gli intervalli personalizzati, consulta il camposchedulein Risorsa:TransferConfig.
Per modificare l'ora di inizio, seleziona l'opzione Inizia all'ora impostata, inserisci la data e l'ora di inizio selezionate.
Per specificare un'ora di fine, seleziona l'opzione Ora di fine della programmazione, inserisci la data di fine e l'ora selezionate.
Per salvare la query senza una pianificazione, in modo da poterla eseguire on demand in un secondo momento, seleziona On demand nel menu Ripeti.
- In Nome della query pianificata, inserisci un nome come
Per una query GoogleSQL
SELECT, seleziona l'opzione Imposta una tabella di destinazione per i risultati della query e fornisci le seguenti informazioni sul set di dati di destinazione.- Per Nome set di dati, scegli il set di dati di destinazione appropriato.
- In Nome tabella, inserisci il nome della tabella di destinazione.
Per Preferenza di scrittura per tabella di destinazione, scegli Aggiungi alla tabella per aggiungere i dati alla tabella o Sovrascrivi tabella per sovrascrivere la tabella di destinazione.

Scegli il tipo di località.
Se hai attivato la tabella di destinazione per i risultati della query, puoi selezionare Selezione automatica della località per selezionare automaticamente la località in cui si trova la tabella di destinazione.
In caso contrario, scegli la località in cui si trovano i dati su cui viene eseguita la query.
Opzioni avanzate:
(Facoltativo) CMEK Se utilizzi chiavi di crittografia gestite dal cliente, puoi selezionare Chiave gestita dal cliente in Opzioni avanzate. Viene visualizzato un elenco di CMEK disponibili tra cui scegliere. Per informazioni su come funzionano le chiavi di crittografia gestite dal cliente (CMEK) con BigQuery Data Transfer Service, vedi Specifica la chiave di crittografia con le query pianificate.
Eseguire l'autenticazione come account di servizio Se hai uno o più service account associati al tuo progetto Google Cloud , puoi associare un account di servizio alla query pianificata anziché utilizzare le tue credenziali utente. In Credenziali query pianificata, fai clic sul menu per visualizzare un elenco dei tuoi service account disponibili. Se hai eseguito l'accesso come identità federata, è necessario un account di servizio.

Configurazioni aggiuntive:
(Facoltativo) Seleziona Invia notifiche email per consentire le notifiche via email degli errori nell'esecuzione dei trasferimenti.
(Facoltativo) In Argomento Pub/Sub, inserisci il nome dell'argomento Pub/Sub, ad esempio:
projects/myproject/topics/mytopic.
Fai clic su Salva.
bq
Opzione 1: utilizza il comando bq query.
Per creare una query pianificata, aggiungi le opzioni destination_table (o
target_dataset), --schedule e --display_name al comando
bq query.
bq query \ --display_name=name \ --destination_table=table \ --schedule=interval
Sostituisci quanto segue:
name. Il nome visualizzato della query pianificata. Il nome visualizzato può essere qualsiasi valore che puoi identificare in un secondo momento se devi modificare la query.table. La tabella di destinazione per i risultati della query.--target_datasetè un modo alternativo per denominare il set di dati di destinazione per i risultati della query, se utilizzato con query DDL e DML.- Utilizza
--destination_tableo--target_dataset, ma non entrambi.
interval. Se utilizzato conbq query, trasforma una query in una query programmata ricorrente. È necessaria una pianificazione per la frequenza di esecuzione della query. Per informazioni dettagliate sulle pianificazioni valide, inclusi gli intervalli personalizzati, consulta il camposchedulein Risorsa:TransferConfig. Esempi:--schedule='every 24 hours'--schedule='every 3 hours'--schedule='every monday 09:00'--schedule='1st sunday of sep,oct,nov 00:00'
Flag facoltativi:
--project_idè l'ID progetto. Se--project_idnon è specificato, viene utilizzato il progetto predefinito.--replacesovrascrive la tabella di destinazione con i risultati della query dopo ogni esecuzione della query pianificata. Tutti i dati esistenti vengono cancellati. Per le tabelle non partizionate, viene cancellato anche lo schema.--append_tableaggiunge i risultati alla tabella di destinazione.Per le query DDL e DML, puoi anche fornire il flag
--locationper specificare una regione particolare per l'elaborazione. Se--locationnon è specificato, viene utilizzata la posizione Google Cloud più vicina.
Ad esempio, il seguente comando crea una query pianificata denominata
My Scheduled Query utilizzando la query SELECT 1 from mydataset.test.
La tabella di destinazione è mytable nel set di dati mydataset. La query pianificata
viene creata nel progetto predefinito:
bq query \
--use_legacy_sql=false \
--destination_table=mydataset.mytable \
--display_name='My Scheduled Query' \
--schedule='every 24 hours' \
--replace=true \
'SELECT
1
FROM
mydataset.test'
Opzione 2: utilizza il comando bq mk.
Le query pianificate sono un tipo di trasferimento. Per pianificare una query, puoi utilizzare lo strumento a riga di comando bq per creare una configurazione di trasferimento.
Per essere pianificate, le query devono essere nel dialetto StandardSQL.
Inserisci il comando bq mk e fornisci i seguenti flag obbligatori:
--transfer_config--data_source--target_dataset(facoltativo per le query DDL e DML)--display_name--params
Flag facoltativi:
--project_idè l'ID progetto. Se--project_idnon è specificato, viene utilizzato il progetto predefinito.--scheduleindica la frequenza con cui vuoi che venga eseguita la query. Se--schedulenon è specificato, il valore predefinito è "ogni 24 ore" in base all'ora di creazione.Per le query DDL e DML, puoi anche fornire il flag
--locationper specificare una regione particolare per l'elaborazione. Se--locationnon è specificato, viene utilizzata la posizione Google Cloud più vicina.--service_account_nameserve per autenticare la query programmata con unaccount di serviziot anziché con il tuo account utente personale.--destination_kms_keyspecifica l'ID risorsa chiave per la chiave se utilizzi una chiave di crittografia gestita dal cliente (CMEK) per questo trasferimento. Per informazioni su come funzionano le CMEK con BigQuery Data Transfer Service, vedi Specifica la chiave di crittografia con le query pianificate.
bq mk \ --transfer_config \ --target_dataset=dataset \ --display_name=name \ --params='parameters' \ --data_source=data_source
Sostituisci quanto segue:
dataset. Il set di dati di destinazione per la configurazione del trasferimento.- Questo parametro è facoltativo per le query DDL e DML. È obbligatorio per tutte le altre query.
name. Il nome visualizzato per la configurazione del trasferimento. Il nome visualizzato può essere qualsiasi valore che puoi identificare in un secondo momento se devi modificare la query.parameters. Contiene i parametri per la configurazione del trasferimento creata in formato JSON. Ad esempio:--params='{"param":"param_value"}'.- Per una query pianificata, devi fornire il parametro
query. - Il parametro
destination_table_name_templateè il nome della tabella di destinazione.- Questo parametro è facoltativo per le query DDL e DML. È obbligatorio per tutte le altre query.
- Per il parametro
write_disposition, puoi scegliereWRITE_TRUNCATEper troncare (sovrascrivere) la tabella di destinazione oWRITE_APPENDper aggiungere i risultati della query alla tabella di destinazione.- Questo parametro è facoltativo per le query DDL e DML. È obbligatorio per tutte le altre query.
- Per una query pianificata, devi fornire il parametro
data_source. L'origine dati:scheduled_query.- (Facoltativo) Il flag
--service_account_nameserve per l'autenticazione con unaccount di serviziot anziché con un account utente individuale. - (Facoltativo)
--destination_kms_keyspecifica l'ID risorsa chiave per la chiave Cloud KMS, ad esempioprojects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name.
Ad esempio, il seguente comando crea una configurazione di trasferimento delle query pianificato
denominata My Scheduled Query utilizzando la query SELECT 1
from mydataset.test. La tabella di destinazione mytable viene troncata per ogni
scrittura e il set di dati di destinazione è mydataset. La query pianificata viene creata nel progetto predefinito ed esegue l'autenticazione come account di servizio:
bq mk \
--transfer_config \
--target_dataset=mydataset \
--display_name='My Scheduled Query' \
--params='{"query":"SELECT 1 from mydataset.test","destination_table_name_template":"mytable","write_disposition":"WRITE_TRUNCATE"}' \
--data_source=scheduled_query \
--service_account_name=abcdef-test-sa@abcdef-test.iam.gserviceaccount.com
La prima volta che esegui il comando, ricevi un messaggio simile al seguente:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
Segui le istruzioni nel messaggio e incolla il codice di autenticazione nella riga di comando.
API
Utilizza il metodo projects.locations.transferConfigs.create e fornisci un'istanza della risorsa TransferConfig.
Java
Prima di provare questo esempio, segui le istruzioni di configurazione di Java nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Java.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Python
Prima di provare questo esempio, segui le istruzioni di configurazione di Python nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Python.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Configurare le query pianificate con un account di servizio
Java
Prima di provare questo esempio, segui le istruzioni di configurazione di Java nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Java.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Python
Prima di provare questo esempio, segui le istruzioni di configurazione di Python nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Python.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Visualizzare lo stato della query pianificata
Console
Per visualizzare lo stato delle query pianificate, fai clic su Pianificazione nel menu di navigazione e filtra per Query pianificata. Fai clic su una query pianificata per visualizzare maggiori dettagli.
bq
Le query pianificate sono un tipo di trasferimento. Per visualizzare i dettagli di una query pianificata, puoi prima utilizzare lo strumento a riga di comando bq per elencare le configurazioni di trasferimento.
Inserisci il comando bq ls e fornisci il flag di trasferimento
--transfer_config. Sono necessari anche i seguenti flag:
--transfer_location
Ad esempio:
bq ls \
--transfer_config \
--transfer_location=us
Per mostrare i dettagli di una singola query pianificata, inserisci il comando bq show e fornisci transfer_path per la query pianificata o la configurazione del trasferimento.
Ad esempio:
bq show \
--transfer_config \
projects/862514376110/locations/us/transferConfigs/5dd12f26-0000-262f-bc38-089e0820fe38
API
Utilizza il metodo projects.locations.transferConfigs.list e fornisci un'istanza della risorsa TransferConfig.
Java
Prima di provare questo esempio, segui le istruzioni di configurazione di Java nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Java.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Python
Prima di provare questo esempio, segui le istruzioni di configurazione di Python nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Python.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Aggiornare le query pianificate
Console
Per aggiornare una query pianificata:
- Nel menu di navigazione, fai clic su Query pianificate o Pianificazione.
- Nell'elenco delle query pianificate, fai clic sul nome della query da modificare.
- Nella pagina Dettagli query pianificata che si apre, fai clic su Modifica.
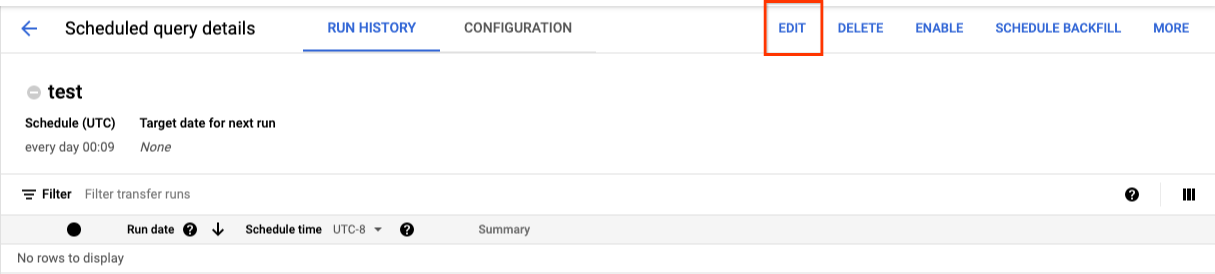
- (Facoltativo) Modifica il testo della query nel riquadro di modifica della query.
- Fai clic su Pianifica query e poi seleziona Aggiorna query pianificata.
- (Facoltativo) Modifica altre opzioni di pianificazione per la query.
- Fai clic su Aggiorna.
bq
Le query pianificate sono un tipo di trasferimento. Per aggiornare la query pianificata, puoi utilizzare lo strumento a riga di comando bq per creare una configurazione di trasferimento.
Inserisci il comando bq update con il flag --transfer_config
obbligatorio.
Flag facoltativi:
--project_idè l'ID progetto. Se--project_idnon è specificato, viene utilizzato il progetto predefinito.--scheduleindica la frequenza con cui vuoi che venga eseguita la query. Se--schedulenon è specificato, il valore predefinito è "ogni 24 ore" in base all'ora di creazione.--service_account_nameha effetto solo se è impostato anche--update_credentials. Per ulteriori informazioni, vedi Aggiornare le credenziali delle query pianificate.--target_dataset(facoltativo per le query DDL e DML) è un modo alternativo per denominare il set di dati di destinazione per i risultati della query, se utilizzato con le query DDL e DML.--display_nameè il nome della query pianificata.--paramsi parametri per la configurazione del trasferimento creata in formato JSON. Ad esempio: --params='{"param":"param_value"}'.--destination_kms_keyspecifica l'ID risorsa chiave per la chiave Cloud KMS se utilizzi una chiave di crittografia gestita dal cliente (CMEK) per questo trasferimento. Per informazioni su come funzionano le chiavi di crittografia gestite dal cliente (CMEK) con BigQuery Data Transfer Service, vedi Specifica la chiave di crittografia con le query pianificate.
bq update \ --target_dataset=dataset \ --display_name=name \ --params='parameters' --transfer_config \ RESOURCE_NAME
Sostituisci quanto segue:
dataset. Il set di dati di destinazione per la configurazione del trasferimento. Questo parametro è facoltativo per le query DDL e DML. È obbligatorio per tutte le altre query.name. Il nome visualizzato per la configurazione del trasferimento. Il nome visualizzato può essere qualsiasi valore che puoi identificare in un secondo momento se devi modificare la query.parameters. Contiene i parametri per la configurazione del trasferimento creata in formato JSON. Ad esempio:--params='{"param":"param_value"}'.- Per una query pianificata, devi fornire il parametro
query. - Il parametro
destination_table_name_templateè il nome della tabella di destinazione. Questo parametro è facoltativo per le query DDL e DML. È obbligatorio per tutte le altre query. - Per il parametro
write_disposition, puoi scegliereWRITE_TRUNCATEper troncare (sovrascrivere) la tabella di destinazione oWRITE_APPENDper aggiungere i risultati della query alla tabella di destinazione. Questo parametro è facoltativo per le query DDL e DML. È obbligatorio per tutte le altre query.
- Per una query pianificata, devi fornire il parametro
- (Facoltativo)
--destination_kms_keyspecifica l'ID risorsa chiave per la chiave Cloud KMS, ad esempioprojects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name. RESOURCE_NAME: il nome della risorsa del trasferimento (detta anche configurazione del trasferimento). Se non conosci il nome della risorsa del trasferimento, trovalo con:bq ls --transfer_config --transfer_location=location.
Ad esempio, il seguente comando aggiorna una configurazione di trasferimento delle query pianificato
denominata My Scheduled Query utilizzando la query SELECT 1
from mydataset.test. La tabella di destinazione mytable viene troncata per ogni scrittura e il set di dati di destinazione è mydataset:
bq update \
--target_dataset=mydataset \
--display_name='My Scheduled Query' \
--params='{"query":"SELECT 1 from mydataset.test","destination_table_name_template":"mytable","write_disposition":"WRITE_TRUNCATE"}'
--transfer_config \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
API
Utilizza il metodo projects.transferConfigs.patch e fornisci il nome risorsa del trasferimento utilizzando il parametro transferConfig.name. Se non conosci il nome della risorsa del trasferimento, utilizza il comando
bq ls --transfer_config --transfer_location=location
per elencare tutti i trasferimenti o chiama il metodo
projects.locations.transferConfigs.list
e fornisci l'ID progetto utilizzando il parametro parent.
Java
Prima di provare questo esempio, segui le istruzioni di configurazione di Java nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Java.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Python
Prima di provare questo esempio, segui le istruzioni di configurazione di Python nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Python.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Aggiornare le query pianificate con limitazioni di proprietà
Se provi ad aggiornare una query pianificata di cui non sei proprietario, l'aggiornamento potrebbe non riuscire e potresti visualizzare il seguente messaggio di errore:
Cannot modify restricted parameters without taking ownership of the transfer configuration.
Il proprietario della query programmata è l'utente associato alla query programmata o l'utente che ha accesso alaccount di serviziot associato alla query programmata. L'utente associato può essere visualizzato nei dettagli di configurazione della query pianificata. Per informazioni su come aggiornare la query pianificata per acquisire la proprietà, consulta Aggiornare le credenziali della query pianificata. Per concedere agli utenti l'accesso a unaccount di serviziot, devi disporre del ruolo Utente service account.
I parametri con limitazioni per le query pianificate del proprietario sono:
- Il testo della query
- Il set di dati di destinazione
- Il modello del nome della tabella di destinazione
Aggiorna le credenziali della query pianificata
Se stai pianificando una query esistente, potrebbe essere necessario aggiornare le credenziali utente nella query. Le credenziali vengono aggiornate automaticamente per le nuove query pianificate.
Ecco alcune altre situazioni che potrebbero richiedere l'aggiornamento delle credenziali:
- Vuoi eseguire query sui dati di Google Drive in una query pianificata.
Quando provi a programmare la query, ricevi l'errore INVALID_USER:
Error code 5 : Authentication failure: User Id not found. Error code: INVALID_USERIDQuando tenti di aggiornare la query, viene visualizzato il seguente errore relativo ai parametri con limitazioni:
Cannot modify restricted parameters without taking ownership of the transfer configuration.
Console
Per aggiornare le credenziali esistenti di una query pianificata:
Fai clic sul pulsante ALTRO e seleziona Aggiorna credenziali.
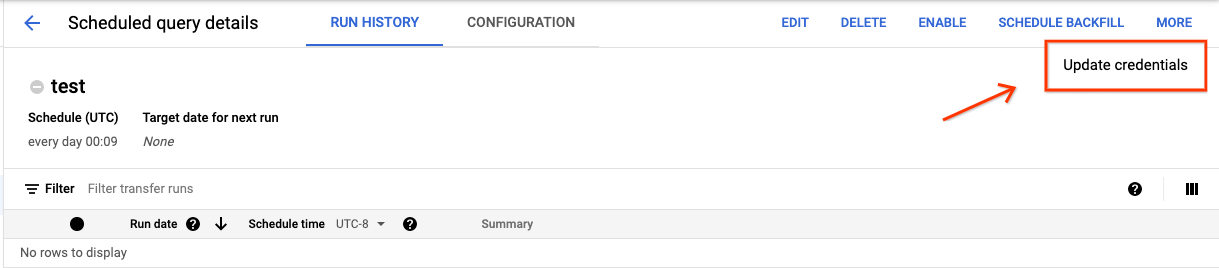
Attendi 10-20 minuti affinché la modifica diventi effettiva. Potresti dover svuotare la cache del browser.
bq
Le query pianificate sono un tipo di trasferimento. Per aggiornare le credenziali di una query pianificata, puoi utilizzare lo strumento a riga di comando bq per aggiornare la configurazione del trasferimento.
Inserisci il comando bq update e fornisci il flag di trasferimento
--transfer_config. Sono necessari anche i seguenti flag:
--update_credentials
Flag facoltativo:
--service_account_nameserve per autenticare la query programmata con unaccount di serviziot anziché con il tuo account utente personale.
Ad esempio, il seguente comando aggiorna una configurazione di trasferimento delle query pianificato per l'autenticazione comeaccount di serviziot:
bq update \
--update_credentials \
--service_account_name=abcdef-test-sa@abcdef-test.iam.gserviceaccount.com \
--transfer_config \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
Java
Prima di provare questo esempio, segui le istruzioni di configurazione di Java nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Java.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Python
Prima di provare questo esempio, segui le istruzioni di configurazione di Python nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Python.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Configurare un'esecuzione manuale nelle date storiche
Oltre a pianificare l'esecuzione di una query in futuro, puoi anche attivare
l'esecuzione immediata manualmente. L'esecuzione immediata è necessaria se la query utilizza il parametro run_date e si sono verificati problemi durante un'esecuzione precedente.
Ad esempio, ogni giorno alle 09:00 esegui una query su una tabella di origine per le righe che corrispondono
alla data corrente. Tuttavia, noti che i dati non sono stati aggiunti alla tabella di origine
negli ultimi tre giorni. In questa situazione, puoi impostare l'esecuzione della query sui dati storici all'interno di un intervallo di date specificato. La query viene eseguita utilizzando
combinazioni di parametri run_date e run_time che corrispondono alle date che hai
configurato nella query pianificata.
Dopo aver configurato una query pianificata, ecco come puoi eseguirla utilizzando un intervallo di date storiche:
Console
Dopo aver fatto clic su Pianifica per salvare la query pianificata, puoi fare clic sul pulsante Query pianificate per visualizzare l'elenco delle query pianificate. Fai clic su un nome visualizzato per visualizzare i dettagli della pianificazione della query. In alto a destra nella pagina, fai clic su Pianifica riempimento per specificare un intervallo di date storico.
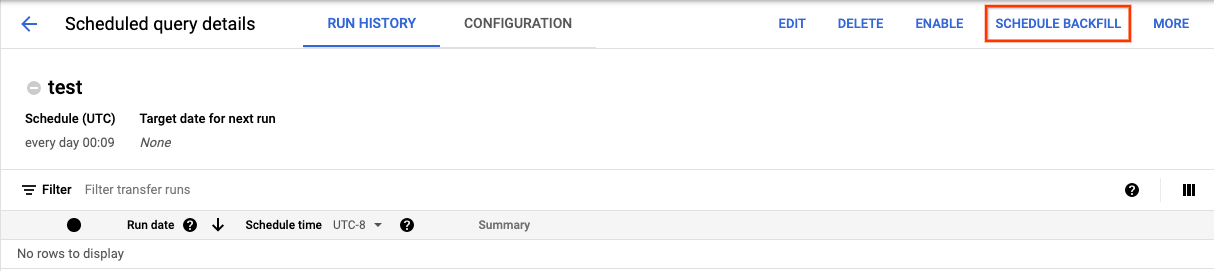
Le durate scelte rientrano tutte nell'intervallo selezionato, inclusa la prima data ed esclusa l'ultima.
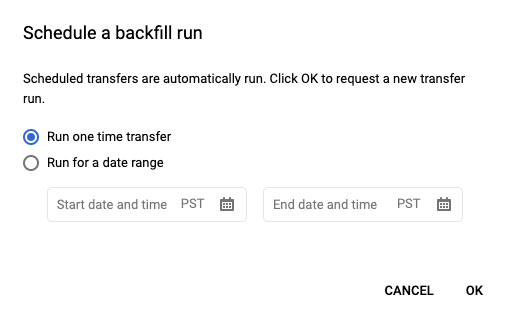
Esempio 1
La query programmata è impostata per essere eseguita alle ore every day 09:00 del fuso orario del Pacifico. Mancano
i dati del 1°, 2 e 3 gennaio. Scegli il seguente intervallo di date
storico:
Start Time = 1/1/19
End Time = 1/4/19
La query viene eseguita utilizzando i parametri run_date e run_time che corrispondono
ai seguenti orari:
- 1/1/19 09:00 ora del Pacifico
- 1/2/19 09:00 ora del Pacifico
- 1/3/19 09:00 ora del Pacifico
Esempio 2
La query programmata è impostata per essere eseguita alle ore every day 23:00 del fuso orario del Pacifico. Mancano
i dati del 1°, 2 e 3 gennaio. Scegli i seguenti intervalli di date storiche (le date successive vengono scelte perché l'UTC ha una data diversa alle 23:00 del fuso orario del Pacifico):
Start Time = 1/2/19
End Time = 1/5/19
La query viene eseguita utilizzando i parametri run_date e run_time che corrispondono
ai seguenti orari:
- 2/1/19 06:00 UTC o 1/1/2019 23:00 ora del Pacifico
- 3/1/19 06:00 UTC o 2/1/2019 23:00 ora del Pacifico
- 4/1/19 06:00 UTC o 3/1/2019 23:00 ora del Pacifico
Dopo aver configurato le esecuzioni manuali, aggiorna la pagina per visualizzarle nell'elenco delle esecuzioni.
bq
Per eseguire manualmente la query su un intervallo di date storico:
Inserisci il comando bq mk e fornisci il flag di esecuzione del trasferimento
--transfer_run. Sono necessari anche i seguenti flag:
--start_time--end_time
bq mk \ --transfer_run \ --start_time='start_time' \ --end_time='end_time' \ resource_name
Sostituisci quanto segue:
start_timeeend_time. Timestamp che terminano con Z o contengono un offset del fuso orario valido. Esempi:- 2017-08-19T12:11:35.00Z
- 2017-05-25T00:00:00+00:00
resource_name. Il nome risorsa della query pianificata (o del trasferimento). Il nome della risorsa è noto anche come configurazione del trasferimento.
Ad esempio, il seguente comando pianifica un backfill per la risorsa query pianificata (o la configurazione del trasferimento):
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7.
bq mk \
--transfer_run \
--start_time 2017-05-25T00:00:00Z \
--end_time 2017-05-25T00:00:00Z \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
Per ulteriori informazioni, vedi bq mk --transfer_run.
API
Utilizza il metodo projects.locations.transferConfigs.scheduleRun e fornisci un percorso della risorsa TransferConfig.
Java
Prima di provare questo esempio, segui le istruzioni di configurazione di Java nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Java.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Python
Prima di provare questo esempio, segui le istruzioni di configurazione di Python nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Python.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Configurare gli avvisi per le query pianificate
Puoi configurare criteri di avviso per le query pianificate in base alle metriche del conteggio delle righe. Per saperne di più, consulta Configurare gli avvisi con query pianificate.
Eliminare le query pianificate
Console
Per eliminare una query pianificata nella pagina Query programmate della console Google Cloud :
- Nel menu di navigazione, fai clic su Query pianificate.
- Nell'elenco delle query pianificate, fai clic sul nome della query pianificata che vuoi eliminare.
Nella pagina Dettagli query programmata, fai clic su Elimina.
In alternativa, puoi eliminare una query pianificata nella pagina Pianificazione della console Google Cloud :
- Nel menu di navigazione, fai clic su Pianificazione.
- Nell'elenco delle query pianificate, fai clic sul menu Azioni per la query pianificata che vuoi eliminare.
Seleziona Elimina.

Java
Prima di provare questo esempio, segui le istruzioni di configurazione di Java nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Java.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Python
Prima di provare questo esempio, segui le istruzioni di configurazione di Python nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Python.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configurare l'autenticazione per le librerie client.
Disattivare o attivare le query pianificate
Per mettere in pausa le esecuzioni pianificate di una query selezionata senza eliminare la pianificazione, puoi disattivarla.
Per disattivare una pianificazione per una query selezionata:
- Nel menu di navigazione della console Google Cloud , fai clic su Pianificazione.
- Nell'elenco delle query pianificate, fai clic sul menu Azioni per la query pianificata che vuoi disattivare.
Seleziona Disable (Disattiva).

Per attivare una query pianificata disattivata, fai clic sul menu Azioni per la query pianificata che vuoi attivare e seleziona Attiva.
Quote
Le query programmate vengono sempre eseguite come job di query batch e sono soggette alle stesse quote e limiti di BigQuery delle query manuali.
Anche se usano funzionalità di BigQuery Data Transfer Service, le query programmate non sono trasferimenti e non sono quindi soggette alla quota dei job di caricamento.
L'identità utilizzata per eseguire la query determina le quote applicate. Questo dipende dalla configurazione della query pianificata:
Credenziali del creator (impostazione predefinita): se non specifichi un account di servizio, la query programmata viene eseguita utilizzando le credenziali dell'utente che l'ha creata. Il job della query viene fatturato al progetto del creator ed è soggetto alle quote dell'utente e del progetto.
Credenziali dell'account di servizio: se configuri la query pianificata in modo che utilizzi un service account, viene eseguita utilizzando le credenziali del service account. In questo caso, il job viene comunque fatturato al progetto contenente la query pianificata, ma l'esecuzione è soggetta alle quote dell'account di servizio specificato.
Prezzi
Le query programmate hanno lo stesso prezzo delle query BigQuery manuali.
Aree geografiche supportate
Le query pianificate sono supportate nelle seguenti località.
Regioni
La tabella seguente elenca le regioni delle Americhe in cui è disponibile BigQuery.| Descrizione della regione | Nome regione | Dettagli |
|---|---|---|
| Columbus, Ohio | us-east5 |
|
| Dallas | us-south1 |
|
| Iowa | us-central1 |
|
| Las Vegas | us-west4 |
|
| Los Angeles | us-west2 |
|
| Messico | northamerica-south1 |
|
| Montréal | northamerica-northeast1 |
|
| Virginia del Nord | us-east4 |
|
| Oregon | us-west1 |
|
| Salt Lake City | us-west3 |
|
| San Paolo | southamerica-east1 |
|
| Santiago | southamerica-west1 |
|
| Carolina del Sud | us-east1 |
|
| Toronto | northamerica-northeast2 |
|
| Descrizione della regione | Nome regione | Dettagli |
|---|---|---|
| Delhi | asia-south2 |
|
| Hong Kong | asia-east2 |
|
| Giacarta | asia-southeast2 |
|
| Melbourne | australia-southeast2 |
|
| Mumbai | asia-south1 |
|
| Osaka | asia-northeast2 |
|
| Seul | asia-northeast3 |
|
| Singapore | asia-southeast1 |
|
| Sydney | australia-southeast1 |
|
| Taiwan | asia-east1 |
|
| Tokyo | asia-northeast1 |
| Descrizione della regione | Nome regione | Dettagli |
|---|---|---|
| Belgio | europe-west1 |
|
| Berlino | europe-west10 |
|
| Finlandia | europe-north1 |
|
| Francoforte | europe-west3 |
|
| Londra | europe-west2 |
|
| Madrid | europe-southwest1 |
|
| Milano | europe-west8 |
|
| Paesi Bassi | europe-west4 |
|
| Parigi | europe-west9 |
|
| Stoccolma | europe-north2 |
|
| Torino | europe-west12 |
|
| Varsavia | europe-central2 |
|
| Zurigo | europe-west6 |
|
| Descrizione della regione | Nome regione | Dettagli |
|---|---|---|
| Dammam | me-central2 |
|
| Doha | me-central1 |
|
| Tel Aviv | me-west1 |
| Descrizione della regione | Nome regione | Dettagli |
|---|---|---|
| Johannesburg | africa-south1 |
Più regioni
La tabella seguente elenca le multiregioni in cui è disponibile BigQuery.| Descrizione multiregionale | Nome multiregionale |
|---|---|
| Data center all'interno degli stati membri dell'Unione Europea1 | EU |
| Data center negli Stati Uniti2 | US |
1 I dati che si trovano nella multiregione EU vengono archiviati solo in una delle seguenti località: europe-west1 (Belgio) o europe-west4 (Paesi Bassi).
La posizione esatta in cui i dati vengono archiviati ed elaborati viene determinata automaticamente da BigQuery.
2 I dati che si trovano nella multiregione US vengono archiviati solo in una delle seguenti località: us-central1 (Iowa),
us-west1 (Oregon) o us-central2 (Oklahoma). La posizione esatta in cui i dati vengono archiviati ed elaborati viene determinata automaticamente da BigQuery.
Passaggi successivi
- Per un esempio di query pianificata che utilizza un account di servizio e include i parametri
@run_datee@run_time, vedi Creazione di snapshot delle tabelle con una query pianificata.