Carga datos de Amazon S3 en BigQuery
Puedes cargar datos de Amazon S3 a BigQuery con el conector del Servicio de transferencia de datos de BigQuery para Amazon S3. Con el Servicio de transferencia de datos de BigQuery, puedes programar trabajos de transferencia recurrentes que agreguen tus datos más recientes de Amazon S3 a BigQuery.
Antes de comenzar
Antes de crear una transferencia de datos de Amazon S3:
- Verifica si completaste todas las acciones necesarias para habilitar el Servicio de transferencia de datos de BigQuery
- Crea un conjunto de datos de BigQuery para almacenar tus datos.
- Crea la tabla de destino para tu transferencia de datos y especifica la definición de esquema. La tabla de destino debe seguir las reglas de nombres de las tablas. Los nombres de las tablas de destino también admiten parámetros.
- Recupera tu URI de Amazon S3, tu ID de clave de acceso y tu clave de acceso secreta. Si deseas obtener más información sobre cómo administrar las claves de acceso, consulta la documentación de AWS.
- Si quieres configurar las notificaciones de ejecución de transferencias para Pub/Sub, debes tener los permisos
pubsub.topics.setIamPolicy. Los permisos de Pub/Sub no son necesarios si solo configuras las notificaciones por correo electrónico. Para obtener más información, consulta la sección sobre notificaciones de ejecución del Servicio de transferencia de datos de BigQuery.
Limitaciones
Las transferencias de datos de Amazon S3 están sujetas a las siguientes limitaciones:
- La parte del bucket en el URI de Amazon S3 no admite el uso de parámetros.
- Las transferencias de datos de Amazon S3 con el parámetro disposición de escritura establecido en
WRITE_TRUNCATEtransferirán todos los archivos coincidentes a Google Cloud durante cada ejecución. Esto puede generar costos adicionales de transferencia de datos salientes de Amazon S3. Para obtener más información sobre qué archivos se transfieren durante una ejecución, consulta Impacto de la coincidencia de prefijos frente a la coincidencia de comodines. - No se admiten las transferencias de las regiones de AWS GovCloud (
us-gov). - No se admiten las transferencias de datos a ubicaciones de BigQuery Omni.
Según el formato de los datos de origen de Amazon S3, puede haber limitaciones adicionales. Para obtener más información, consulta:
El tiempo de intervalo mínimo entre transferencias de datos recurrentes es de 1 hora. El intervalo predeterminado para una transferencia de datos recurrente es de 24 horas.
Permisos necesarios
Antes de crear una transferencia de datos de Amazon S3, haz lo siguiente:
Asegúrate de que la persona que crea la transferencia de datos tenga los siguientes permisos obligatorios en BigQuery:
- Los permisos
bigquery.transfers.updatepara crear la transferencia de datos - Los permisos
bigquery.datasets.getybigquery.datasets.updateen el conjunto de datos de destino
La función predefinida de IAM
bigquery.adminincluye los permisosbigquery.transfers.update,bigquery.datasets.updateybigquery.datasets.get. Para obtener más información sobre los roles de IAM en el Servicio de transferencia de datos de BigQuery, consulta Control de acceso.- Los permisos
Consulta la documentación de Amazon S3 y asegúrate de tener configurados los permisos necesarios para habilitar la transferencia de datos. Como mínimo, los datos de origen de Amazon S3 deben estar sujetos a la política administrada de AWS
AmazonS3ReadOnlyAccess.
Configura una transferencia de datos de Amazon S3
Para crear una transferencia de datos de Amazon S3:
Console
Ve a la página Transferencia de datos en la Google Cloud consola.
Haz clic en Crear transferencia.
En la página Crear transferencia, sigue estos pasos:
En la sección Tipo de fuente (Source type), elige Amazon S3 como Fuente (Source).

En la sección Nombre de la configuración de transferencia (Transfer config name), en Nombre visible (Display name), ingresa el nombre de la transferencia, como
My Transfer. El nombre de la transferencia puede ser cualquier valor que te permita identificarla con facilidad si es necesario hacerle modificaciones más tarde.
En la sección Opciones de programación, haz lo siguiente:
Selecciona una opción en Frecuencia de repetición. Si seleccionas Horas, Días, Semanas o Meses, también debes especificar una frecuencia. También puedes seleccionar Personalizado para crear una frecuencia de repetición más específica. Si seleccionas Según demanda, esta transferencia de datos se ejecuta solo cuando activas la transferencia de forma manual.
Si corresponde, selecciona Comenzar ahora o Comenzar a la hora definida y detalla una fecha de inicio y una hora de ejecución.
En la sección Configuración de destino, en Conjunto de datos de destino, elige el conjunto de datos que creaste para almacenar tus datos.
En la sección Detalles de fuente de datos (Data source details):
- En Tabla de destino, ingresa el nombre de la tabla que creaste para almacenar los datos en BigQuery. Los nombres de las tablas de destino admiten parámetros.
- En URI de Amazon S3, ingresa el URI con el formato
s3://mybucket/myfolder/.... Los URI también admiten parámetros. - En ID de clave de acceso, ingresa el ID de tu clave de acceso.
- En Clave de acceso secreta, ingresa tu clave de acceso secreta.
- En Formato de archivo, elige el formato de datos (CSV, Avro, Parquet, ORC o JSON delimitados por línea nueva).
- En Disposición de escritura, elige una de las siguientes opciones:
WRITE_APPENDpara agregar incrementalmente datos nuevos a tu tabla de destino existente.WRITE_APPENDes el valor predeterminado para Preferencia de escritura.WRITE_TRUNCATEpara reemplazar los datos en la tabla de destino durante cada ejecución de transferencia de datos.
Si quieres obtener más información sobre cómo el Servicio de transferencia de datos de BigQuery transfiere datos con
WRITE_APPENDoWRITE_TRUNCATE, consulta Transferencia de datos para transferencias de Amazon S3. Para obtener más información del campowriteDisposition, consultaJobConfigurationLoad.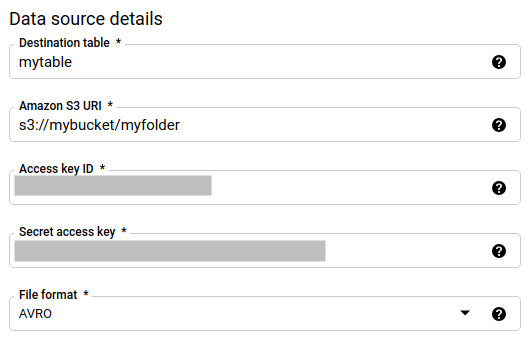
En la sección Opciones de transferencia: todos los formatos, sigue estos pasos:
- En Cantidad de errores permitidos, ingresa un número entero para la cantidad máxima de registros erróneos que se pueden ignorar.
- En Tipos de destino decimales, ingresa una lista separada por comas de tipos de datos de SQL posibles en los que se puedan convertir los valores decimales de origen (opcional). El tipo de datos SQL que se selecciona para la conversión depende de las siguientes condiciones:
- El tipo de datos seleccionado para la conversión será el primer tipo de datos de la siguiente lista que admite la precisión y el escalamiento de los datos fuente, en este orden: NUMERIC, BIGNUMERIC y STRING.
- Si ninguno de los tipos de datos enumerados admitirá la precisión y el escalamiento, se selecciona el tipo de datos que admite el rango más amplio en la lista especificada. Se arrojará un error si un valor excede el rango admitido cuando se leen los datos fuente.
- El tipo de datos STRING admite todos los valores de precisión y escalamiento.
- Si este campo se deja vacío, el tipo de datos predeterminado será "NUMERIC,STRING" para ORC y "NUMERIC" para los otros formatos de archivo.
- Este campo no puede contener tipos de datos duplicados.
- Se ignora el orden de los tipos de datos que enumeras en este campo.

Si eliges los formatos de archivo CSV o JSON, en la sección JSON, CSV, marca Ignorar valores desconocidos (Ignore unknown values) para aceptar las filas con valores que no coinciden con el esquema. Los valores desconocidos se ignoran. En los archivos CSV, esta opción ignora los valores adicionales al final de una línea.

Si elegiste CSV como formato de archivo, en la sección CSV ingresa cualquier opción de CSV adicional para cargar datos.

En el menú Cuenta de servicio, selecciona una cuenta de servicio de aquellas que están asociadas con tu Google Cloud proyecto. Puedes asociar una cuenta de servicio con tu transferencia de datos en lugar de usar tus credenciales de usuario. Para obtener más información sobre cómo usar cuentas de servicio con transferencias de datos, consulta Usa cuentas de servicio.
- Si accediste con una identidad federada, se requiere una cuenta de servicio para crear una transferencia de datos. Si accediste con una Cuenta de Google, la cuenta de servicio para dicha transferencia de datos es opcional.
- La cuenta de servicio debe tener los permisos necesarios.
De forma opcional, en la sección Opciones de notificación, haz lo siguiente:
- Haz clic en el botón de activación para habilitar las notificaciones por correo electrónico. Si habilitas esta opción, el administrador de transferencias recibirá una notificación por correo electrónico cuando falle la ejecución de una transferencia de datos.
- En Selecciona un tema de Pub/Sub, elige el nombre de tu tema o haz clic en Crear un tema para crear uno. Con esta opción, se configuran las notificaciones de ejecución de Pub/Sub para tu transferencia de datos.
Haz clic en Guardar.
bq
Ingresa el comando bq mk y suministra la marca de creación de transferencias --transfer_config.
bq mk \ --transfer_config \ --project_id=project_id \ --data_source=data_source \ --display_name=name \ --target_dataset=dataset \ --service_account_name=service_account \ --params='parameters'
Donde:
- project_id: Opcional El ID de tu proyecto Google Cloud
Si no se proporciona
--project_idpara especificar un proyecto en particular, se usa el proyecto predeterminado. - data_source: Obligatorio. La fuente de datos,
amazon_s3. - display_name: Obligatorio. El nombre visible de la configuración de transferencia de datos. El nombre de la transferencia puede ser cualquier valor que te permita identificarla con facilidad si es necesario hacerle modificaciones más tarde.
- dataset: Obligatorio. El conjunto de datos de destino para la configuración de transferencia de datos.
- service_account: el nombre de la cuenta de servicio que se usa para autenticar tu transferencia de datos. La cuenta de servicio debe ser propiedad del mismo
project_idque se usa para crear la transferencia de datos y debe tener todos los permisos necesarios. parameters: Obligatorio. Los parámetros de la configuración de transferencia creada en formato JSON. Por ejemplo:
--params='{"param":"param_value"}'Los siguientes son los parámetros para una transferencia de Amazon S3:- destination_table_name_template: Obligatorio. El nombre de la tabla de destino.
data_path: Obligatorio. El URI de Amazon S3, en el siguiente formato:
s3://mybucket/myfolder/...Los URI también admiten parámetros.
access_key_id: Obligatorio. Tu ID de clave de acceso.
secret_access_key: Obligatorio. Tu clave de acceso secreta.
file_format: Opcional Indica el tipo de archivos que deseas transferir:
CSV,JSON,AVRO,PARQUEToORC. El valor predeterminado esCSV.write_disposition: Opcional
WRITE_APPENDtransferirá solo los archivos que se modificaron desde la ejecución correcta anterior.WRITE_TRUNCATEtransferirá todos los archivos coincidentes, incluidos los que se transfirieron en una ejecución anterior. El valor predeterminado esWRITE_APPEND.max_bad_records: Opcional La cantidad de registros erróneos permitidos. El predeterminado es
0.decimal_target_types: Opcional Es una lista separada por comas de tipos de datos de SQL posibles en los que se pueden convertir los valores decimales de origen. Si no se proporciona este campo, el tipo de datos predeterminado será "NUMERIC,STRING" para ORC y "NUMERIC" para los otros formatos de archivo.
ignore_unknown_values: Opcional y, también, ignorado si file_format no es
JSONniCSV. Indica si se deben ignorar los valores desconocidos en tus datos.field_delimiter: Opcional y solo se aplica cuando
file_formatesCSV. El carácter que separa los campos. El valor predeterminado es una coma.skip_leading_rows: Opcional y solo se aplica cuando file_format es
CSV. Indica la cantidad de filas de encabezado que no deseas importar. El valor predeterminado es0.allow_quoted_newlines: Opcional y solo se aplica cuando file_format es
CSV. Indica si se permiten saltos de líneas dentro de los campos entre comillas.allow_jagged_rows: Opcional y solo se aplica cuando file_format es
CSV. Indica si se aceptan filas a las que les faltan columnas opcionales finales. Los valores que faltan se completarán con valores NULL.
Por ejemplo, con el siguiente comando se crea una transferencia de datos de Amazon S3 llamada My Transfer con un valor data_path de s3://mybucket/myfile/*.csv, el conjunto de datos de destino mydataset y el CSV como file_format. Este ejemplo incluye valores no predeterminados para los parámetros opcionales asociados con el file_format CSV.
La transferencia de datos se crea en el proyecto predeterminado:
bq mk --transfer_config \
--target_dataset=mydataset \
--display_name='My Transfer' \
--params='{"data_path":"s3://mybucket/myfile/*.csv",
"destination_table_name_template":"MyTable",
"file_format":"CSV",
"write_disposition":"WRITE_APPEND",
"max_bad_records":"1",
"ignore_unknown_values":"true",
"field_delimiter":"|",
"skip_leading_rows":"1",
"allow_quoted_newlines":"true",
"allow_jagged_rows":"false"}' \
--data_source=amazon_s3
Después de ejecutar el comando, recibirás un mensaje como el siguiente:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
Sigue las instrucciones y pega el código de autenticación en la línea de comandos.
API
Usa el método projects.locations.transferConfigs.create y suministra una instancia del recurso TransferConfig.
Java
Antes de probar este ejemplo, sigue las instrucciones de configuración para Java incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para Java.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
Impacto de la coincidencia de prefijos frente a la coincidencia de comodines
La API de Amazon S3 admite la coincidencia de prefijos, pero no la coincidencia de comodines. Todos los archivos de Amazon S3 que coincidan con un prefijo se transferirán a Google Cloud. Sin embargo, solo los que coincidan con el URI de Amazon S3 en la configuración de transferencia se cargarán en BigQuery. Esto podría provocar un exceso en los costos de transferencia de datos salientes de Amazon S3 para los archivos que se transfieren pero no se cargan en BigQuery.
A modo de ejemplo, considera esta ruta de datos:
s3://bucket/folder/*/subfolder/*.csv
Junto con estos archivos en la ubicación de origen:
s3://bucket/folder/any/subfolder/file1.csv
s3://bucket/folder/file2.csv
Esto hará que todos los archivos de Amazon S3 con el prefijo s3://bucket/folder/ se transfieran a Google Cloud. En este ejemplo, se transferirán file1.csv y file2.csv.
Sin embargo, solo los archivos que coincidan con s3://bucket/folder/*/subfolder/*.csv se cargarán en BigQuery. En este ejemplo, solo se cargarán file1.csv en BigQuery.
Soluciona problemas con la configuración de una transferencia
Si tienes problemas para configurar tu transferencia de datos, consulta Problemas de transferencia de Amazon S3.
¿Qué sigue?
- Para obtener una introducción a las transferencias de datos de Amazon S3, consulta la página sobre la descripción general de las transferencias de Amazon S3.
- Si deseas obtener una descripción general del Servicio de transferencia de datos de BigQuery, consulta la página sobre la introducción al Servicio de transferencia de datos de BigQuery.
- Para obtener información sobre el uso de las transferencias de datos (por ejemplo, cómo obtener información sobre una configuración de transferencia, mostrar distintas configuraciones o visualizar su historial de ejecuciones), consulta Trabaja con transferencias.
- Obtén más información sobre cómo cargar datos con operaciones entre nubes.