Load and query data
Get started with BigQuery by creating a dataset, loading data into a table, and querying the table.
To follow step-by-step guidance for this task directly in the Google Cloud console, click Guide me:
Before you begin
Before you can explore BigQuery, you must sign in to Google Cloud console and create a project. If you don't enable billing in your project, then all of the data you upload will be in the BigQuery sandbox. The sandbox makes it possible for you to learn BigQuery at no charge while working with a limited set of BigQuery features. For more information, see Enable the BigQuery sandbox.- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
- Optional: If you select an existing project, make sure that you enable the BigQuery API. The BigQuery API is automatically enabled in new projects.
Create a BigQuery dataset
Use the Google Cloud console to create a dataset to store the data. You create your dataset in the US multi-region location. For information on BigQuery regions and multi-regions, see Locations.
- In the Google Cloud console, open the BigQuery page. Go to BigQuery
- In the
Explorer pane, click your project name. - Click View actions.
- Select Create dataset.
- On the Create dataset page, do the following:
- For Dataset ID, enter
babynames. - For Location type, select Multi-region, and then choose
US (multiple regions in United States). The public datasets are
stored in the
usmulti-region location. For simplicity, store your dataset in the same location. - Leave the remaining default settings as they are, and click
Create dataset .
Download the file that contains the source data
The file that you're downloading contains approximately 7 MB of data about popular baby names. It's provided by the US Social Security Administration.For more information about the data, see the Social Security Administration's Background information for popular names.
Download the US Social Security Administration's data by opening the following URL in a new browser tab:
https://www.ssa.gov/OACT/babynames/names.zipExtract the file.
For more information about the dataset schema, see the zip file's
NationalReadMe.pdffile.To see what the data looks like, open the
yob2024.txtfile. This file contains comma-separated values for name, assigned sex at birth, and number of children with that name. The file has no header row.Note the location of the
yob2024.txtfile so that you can find it later.
Load data into a table
Next, load the data into a new table.
- In the
Explorer pane, expand your project name. - Next to the babynames dataset, click View actions and select Open.
- Click
Create
table.
Unless otherwise indicated, use the default values for all settings.
- On the Create table page, do the following:
- In the Source section, for
Create table from , choose Upload from the list. - In the Select file field, click Browse.
- Navigate to and open your local
yob2024.txtfile, and click Open. - From the
File format list, choose CSV. - In the Destination section, in the
Table field, enternames_2024. - In the Schema section, click the
Edit as text toggle, and paste the following schema definition into the text field: - Click
Create table .Wait for BigQuery to create the table and load the data.
name:string,assigned_sex_at_birth:string,count:integerPreview table data
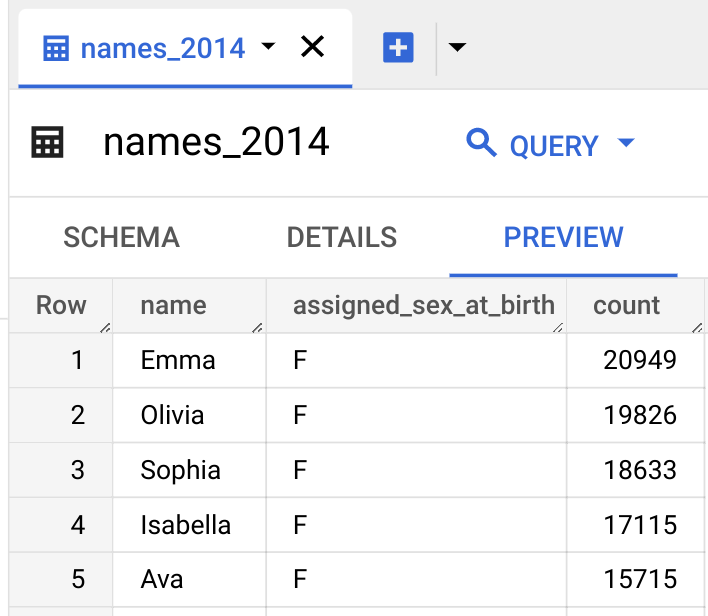
To preview the table data, follow these steps:
- In the
Explorer pane, expand your project andbabynamesdataset, and then select thenames_2024table. - Click the
Preview tab. BigQuery displays the first few rows of the table.
Query table data
Next, query the table.
- Next to the names_2024 tab, click the SQL query option. A new editor tab opens.
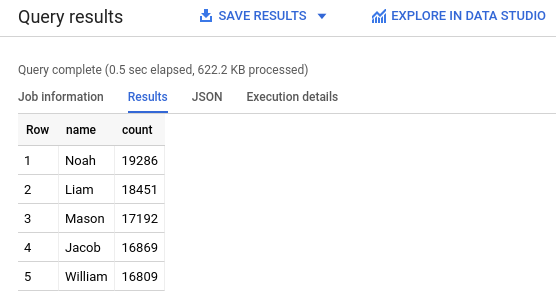
- In the query editor, paste the following query. This query retrieves the
top five names for babies born in the US that were assigned male at birth in
2024.
SELECT name, count FROM `babynames.names_2024` WHERE assigned_sex_at_birth = 'M' ORDER BY count DESC LIMIT 5; - Click
Run . The results are displayed in the Query results section.
You have successfully queried a table in a public dataset and then loaded your sample data into BigQuery using the Google Cloud console.
Clean up
To avoid incurring charges to your Google Cloud account for the resources used on this page, follow these steps.
- In the Google Cloud console, open the BigQuery page. Go to BigQuery
- In the Explorer pane, click the
babynamesdataset that you created. - Expand the View actions option and click Delete.
- In the Delete dataset dialog, confirm the delete command: type the word
deleteand then click Delete.
What's next
- To learn more about loading data into BigQuery, see Introduction to loading data.
- To learn more about querying data, see Overview of BigQuery analytics.
- To learn how to load a JSON file with nested and repeated data, see Loading nested and repeated JSON data.
- To learn more about accessing BigQuery programmatically, see the REST API reference or the BigQuery client libraries page.