Tersemat dalam tugas kueri, BigQuery menyertakan informasi paket kueri dan waktu diagnostik. Hal ini mirip dengan informasi yang diberikan oleh pernyataan seperti EXPLAIN dalam sistem analisis dan database lain. Informasi ini dapat diambil dari respons API metode seperti jobs.get.
Untuk kueri yang berjalan lama, BigQuery akan memperbarui statistik ini secara berkala. Update ini terjadi secara mandiri pada tingkat polling status tugas, tetapi biasanya tidak akan terjadi lebih sering dari setiap 30 detik. Selain itu, tugas kueri yang tidak menggunakan resource eksekusi, seperti permintaan uji coba atau hasil yang dapat disajikan dari hasil yang di-cache, tidak akan menyertakan informasi diagnostik tambahan, meskipun mungkin ada statistik lain.
Latar belakang
Saat menjalankan tugas kueri, BigQuery mengonversi pernyataan SQL deklaratif menjadi grafik eksekusi, yang dipecah menjadi serangkaian tahap kueri, yang terdiri dari kumpulan yang lebih terperinci langkah-langkah eksekusi. BigQuery memanfaatkan arsitektur paralel yang sangat terdistribusi untuk menjalankan kueri ini. Stage akan membuat model unit tugas yang dapat dijalankan oleh banyak worker potensial secara paralel. Tahapan berkomunikasi satu sama lain menggunakan arsitektur acak terdistribusi yang cepat.
Dalam paket kueri, istilah unit tugas dan worker digunakan untuk menyampaikan informasi secara khusus tentang paralelisme. Di bagian lain dalam BigQuery, Anda mungkin menemukan istilah slot, yaitu representasi abstrak dari beberapa faset eksekusi kueri, termasuk komputasi, memori, dan resource I/O. Statistik tugas tingkat teratas memberikan perkiraan biaya kueri tertentu menggunakan estimasi totalSlotMs kueri menggunakan penghitungan terpisah ini.
Properti penting lainnya dari arsitektur eksekusi kueri adalah bersifat dinamis. Artinya, paket kueri dapat diubah saat kueri sedang berjalan. Stage yang diperkenalkan saat kueri berjalan sering digunakan untuk meningkatkan distribusi data di seluruh worker kueri. Dalam paket kueri di mana proses tersebut berlangsung, stage ini biasanya dilabeli sebagai Stage partisi ulang.
Selain paket kueri, tugas kueri juga mengekspos linimasa eksekusi, yang menyediakan akuntansi unit tugas yang telah selesai, tertunda, dan aktif dalam pekerja kueri. Kueri dapat memiliki beberapa tahap dengan pekerja aktif secara bersamaan, dan linimasa dimaksudkan untuk menampilkan progres kueri secara keseluruhan.
Melihat informasi dengan Google Cloud console
Di konsolGoogle Cloud , Anda dapat melihat detail paket kueri untuk kueri yang telah selesai dengan mengklik tombol Execution Details (di dekat tombol Results).
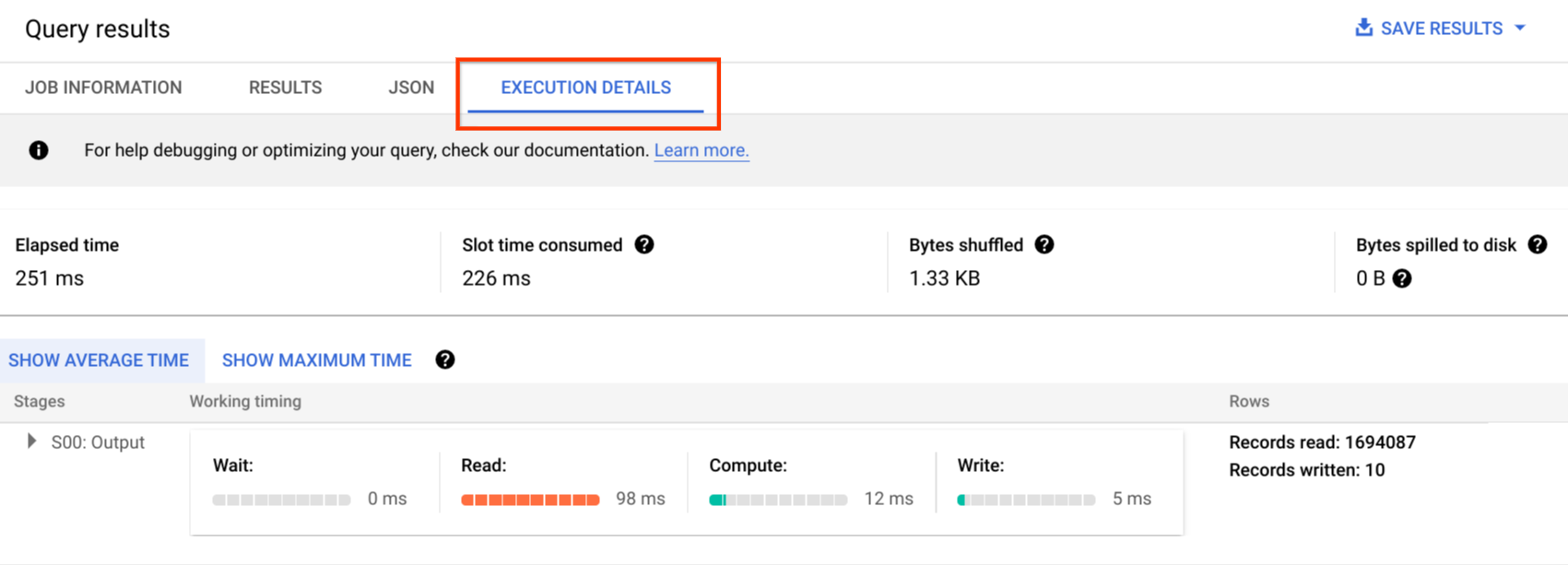
Informasi paket kueri
Dalam respons API, paket kueri direpresentasikan sebagai daftar stage kueri. Setiap item dalam daftar menunjukkan statistik ringkasan per stage, informasi langkah yang mendetail, dan klasifikasi pengaturan waktu stage. Tidak semua detail dirender dalam konsol Google Cloud , tetapi semuanya dapat tersedia dalam respons API.
Ringkasan stage
Kolom ringkasan untuk setiap stage dapat mencakup hal berikut:
| Kolom API | Deskripsi |
|---|---|
id |
ID numerik unik untuk stage. |
name |
Nama ringkasan sederhana untuk stage. steps dalam stage memberikan detail tambahan tentang langkah-langkah eksekusi. |
status |
Status eksekusi stage. Status yang mungkin termasuk PENDING, RUNNING, COMPLETE, FAILED, dan CANCELLED. |
inputStages |
Daftar ID yang membentuk grafik dependensi stage. Misalnya, stage JOIN sering memerlukan dua stage dependen yang menyiapkan data di sisi kiri dan kanan hubungan JOIN. |
startMs |
Stempel waktu, dalam epoch milidetik, yang merepresentasikan kapan worker pertama dalam stage memulai eksekusi. |
endMs |
Stempel waktu, dalam epoch milidetik, yang merepresentasikan kapan worker terakhir menyelesaikan eksekusi. |
steps |
Daftar langkah-langkah eksekusi yang lebih mendetail dalam stage. Lihat bagian berikutnya untuk mengetahui informasi selengkapnya. |
recordsRead |
Ukuran input stage sebagai jumlah catatan, di semua worker stage. |
recordsWritten |
Ukuran output stage sebagai jumlah catatan, di semua worker stage. |
parallelInputs |
Jumlah unit tugas yang dapat diparalelkan untuk stage. Bergantung pada stage dan kueri, jumlah ini dapat mewakili jumlah segmen kolom dalam tabel, atau jumlah partisi dalam shuffle perantara. |
completedParallelInputs |
Jumlah unit tugas dalam stage yang telah diselesaikan. Untuk sebagian kueri, tidak semua input dalam satu stage harus diselesaikan agar stage tersebut dapat diselesaikan. |
shuffleOutputBytes |
Merepresentasikan total byte yang ditulis di semua worker dalam stage kueri. |
shuffleOutputBytesSpilled |
Kueri yang mengirimkan data signifikan antar-stage mungkin perlu kembali ke transmisi berbasis disk. Statistik byte yang dialihkan menunjukkan berapa banyak data yang dialihkan ke disk. Bergantung pada algoritma pengoptimalan sehingga tidak bersifat deterministik untuk kueri tertentu. |
Klasifikasi pengaturan waktu per stage
Stage kueri menyediakan klasifikasi pengaturan waktu stage, baik dalam bentuk relatif maupun absolut. Karena setiap stage eksekusi merepresentasikan tugas yang dilakukan oleh satu atau beberapa worker independen, informasi diberikan dalam waktu rata-rata dan kasus terburuk. Waktu ini menunjukkan performa rata-rata untuk semua worker dalam satu stage serta performa worker paling lambat longtail untuk klasifikasi tertentu. Waktu rata-rata dan waktu maksimum selanjutnya dibagi menjadi representasi absolut dan relatif. Untuk statistik berbasis rasio, data diberikan sebagai hasil bagi dari waktu terlama yang dihabiskan oleh worker mana pun di segmen mana pun.
Konsol Google Cloud menampilkan pengaturan waktu stage menggunakan representasi pengaturan waktu relatif.
Informasi pengaturan waktu stage dilaporkan sebagai berikut:
| Pengaturan waktu relatif | Pengaturan waktu absolut | Numerator rasio |
|---|---|---|
waitRatioAvg |
waitMsAvg |
Waktu yang dihabiskan oleh worker rata-rata yang menunggu dijadwalkan. |
waitRatioMax |
waitMsMax |
Waktu yang dihabiskan oleh worker paling lambat yang menunggu dijadwalkan. |
readRatioAvg |
readMsAvg |
Waktu yang dihabiskan rata-rata worker untuk membaca data input. |
readRatioMax |
readMsMax |
Waktu yang dihabiskan worker paling lambat untuk membaca data input. |
computeRatioAvg |
computeMsAvg |
Waktu yang dihabiskan oleh rata-rata worker yang terikat ke CPU. |
computeRatioMax |
computeMsMax |
Waktu yang dihabiskan oleh worker paling lambat yang terikat oleh CPU. |
writeRatioAvg |
writeMsAvg |
Waktu yang dihabiskan oleh worker rata-rata untuk menulis data output. |
writeRatioMax |
writeMsMax |
Waktu yang dihabiskan worker paling lambat untuk menulis data output. |
Ringkasan langkah
Langkah-langkah berisi operasi yang dijalankan oleh setiap worker dalam satu stage, yang ditampilkan sebagai daftar operasi yang diurutkan. Setiap operasi langkah memiliki kategori, dengan beberapa operasi memberikan informasi yang lebih mendetail. Kategori operasi yang ada dalam paket kueri mencakup hal berikut:
| Kategori langkah | Deskripsi |
|---|---|
READ |
Pembacaan satu atau beberapa kolom dari tabel input atau dari shuffle tingkat menengah. Hanya enam belas kolom pertama yang dibaca yang ditampilkan dalam detail-detail langkah. |
WRITE |
Penulisan satu atau beberapa kolom ke tabel output atau ke shuffle tingkat menengah. Untuk output yang dipartisi HASH dari suatu stage, ini juga mencakup kolom yang digunakan sebagai kunci partisi. |
COMPUTE |
Evaluasi ekspresi dan fungsi SQL. |
FILTER |
Digunakan oleh klausa WHERE, OMIT IF, dan HAVING. |
SORT |
Operasi ORDER BY yang mencakup kunci kolom dan urutan pengurutan. |
AGGREGATE |
Menerapkan agregasi untuk klausa seperti GROUP BY atau COUNT, dan lain-lain. |
LIMIT |
Menerapkan klausa LIMIT. |
JOIN |
Menerapkan gabungan untuk klausa seperti JOIN, dan lainnya; mencakup jenis gabungan dan kemungkinan kondisi gabungan. |
ANALYTIC_FUNCTION |
Pemanggilan fungsi jendela (juga dikenal sebagai "fungsi analisis"). |
USER_DEFINED_FUNCTION |
Pemanggilan ke fungsi yang ditentukan pengguna. |
Memahami detail langkah
BigQuery menyediakan Detail langkah yang menjelaskan apa yang dilakukan setiap langkah dalam suatu tahap. Memahami langkah-langkah dalam tahap diperlukan untuk mengidentifikasi sumber masalah performa kueri.
Untuk menemukan detail langkah untuk suatu tahap, ikuti langkah-langkah berikut:
Di panel Hasil kueri, klik Grafik eksekusi.
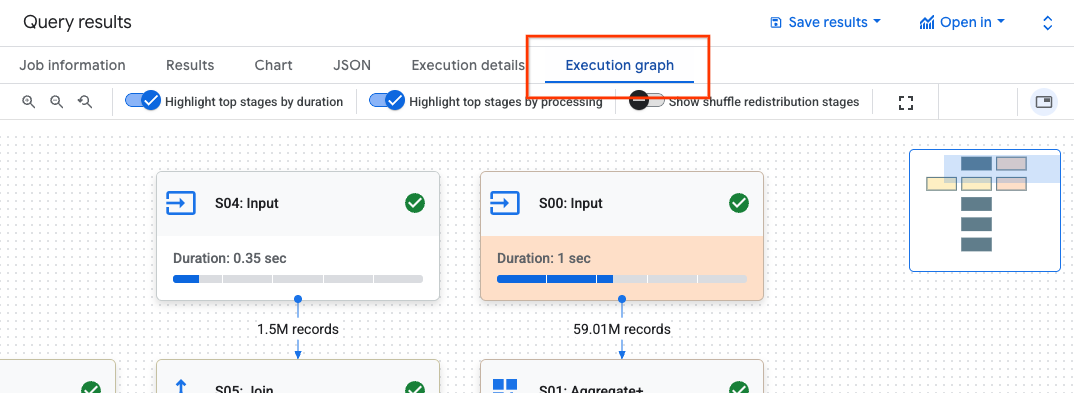
Klik tahap yang Anda minati untuk membuka panel dengan informasi tahap.
Di panel dengan informasi tahap, buka bagian Detail langkah.
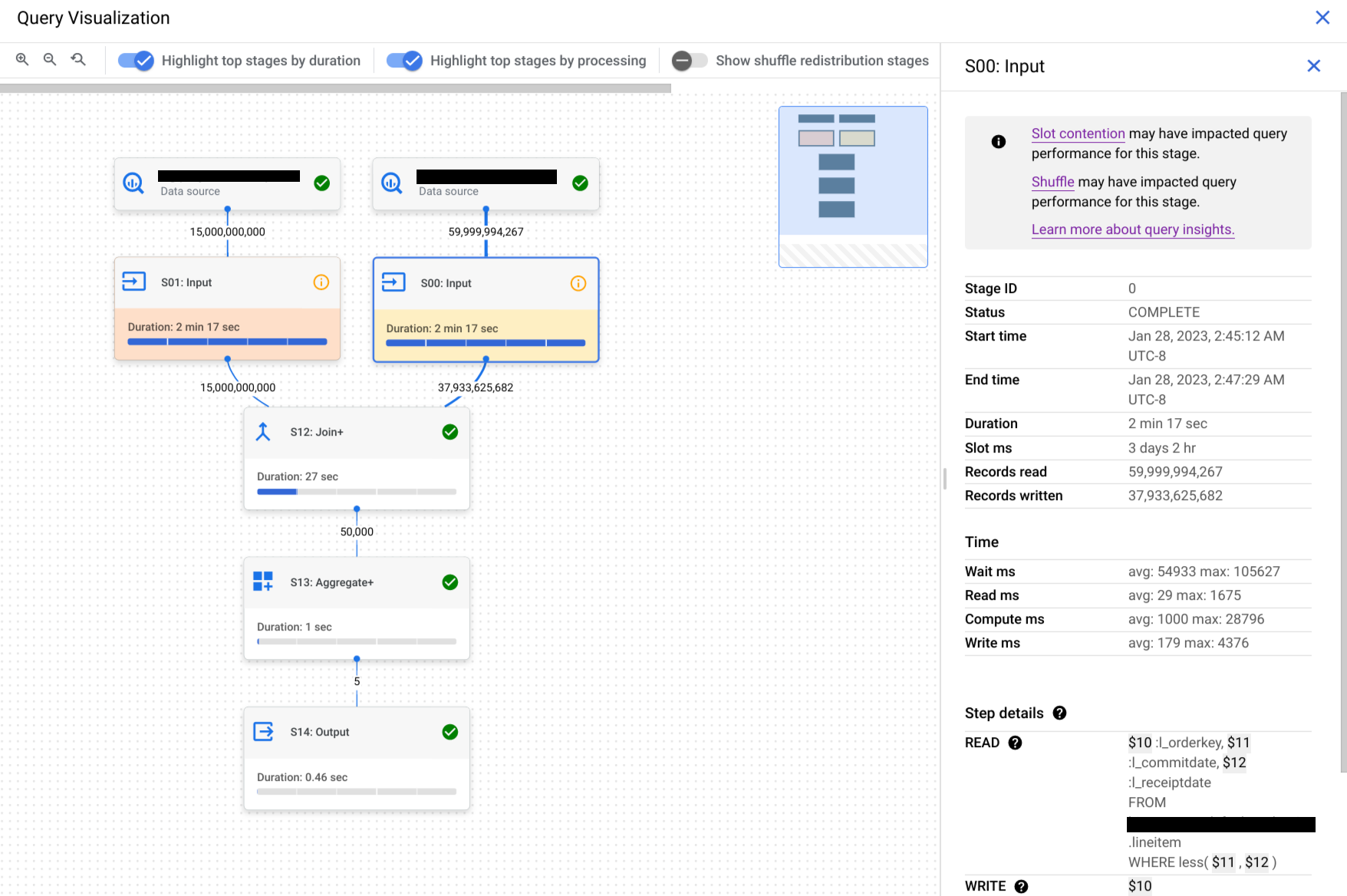
Setiap langkah terdiri dari sub-langkah yang menjelaskan tindakan yang dilakukan dalam langkah tersebut. Sublangkah menggunakan variabel untuk menjelaskan hubungan antar-langkah. Variabel dimulai dengan tanda dolar yang diikuti dengan angka unik.
Berikut adalah contoh detail langkah dari tahap dengan variabel yang dibagikan di antara langkah-langkah:
READ $30:l_orderkey, $31:l_quantity FROM lineitem AGGREGATE GROUP BY $100 := $30 $70 := SUM($31) WRITE $100, $70 TO __stage00_output BY HASH($100)
Detail langkah contoh melakukan hal berikut:
Tahap ini membaca kolom
l_orderkeydanl_quantitydari tabellineitemmenggunakan variabel$30dan$31.Tahap ini diagregasi pada variabel
$30dan$31, yang menyimpan agregasi ke dalam variabel$100dan$70.Tahap ini menulis hasil variabel
$100dan$70untuk diacak. Tahap ini menggunakan$100untuk mengurutkan hasil tahap dalam pengacakan.
BigQuery mungkin memangkas detail langkah jika grafik eksekusi kueri cukup kompleks sehingga memberikan detail langkah tahap yang lengkap akan menyebabkan masalah ukuran payload saat mengambil informasi kueri.
Memahami langkah-langkah dengan Teks kueri
Untuk mendapatkan dukungan selama pratinjau, kirim email ke bq-query-inspector-feedback@google.com.
Memahami hubungan antara langkah-langkah tahap dengan kueri bisa jadi sulit. Bagian Teks kueri menunjukkan bagaimana beberapa langkah terkait dengan teks kueri asli.
Bagian Teks kueri menandai berbagai bagian teks kueri asli dan menampilkan langkah-langkah yang dipetakan kembali ke teks kueri yang langsung mendahului teks kueri asli yang ditandai. Hanya langkah-langkah tepat di atas bagian yang ditandai dari teks kueri asli yang berlaku untuk teks kueri yang ditandai.
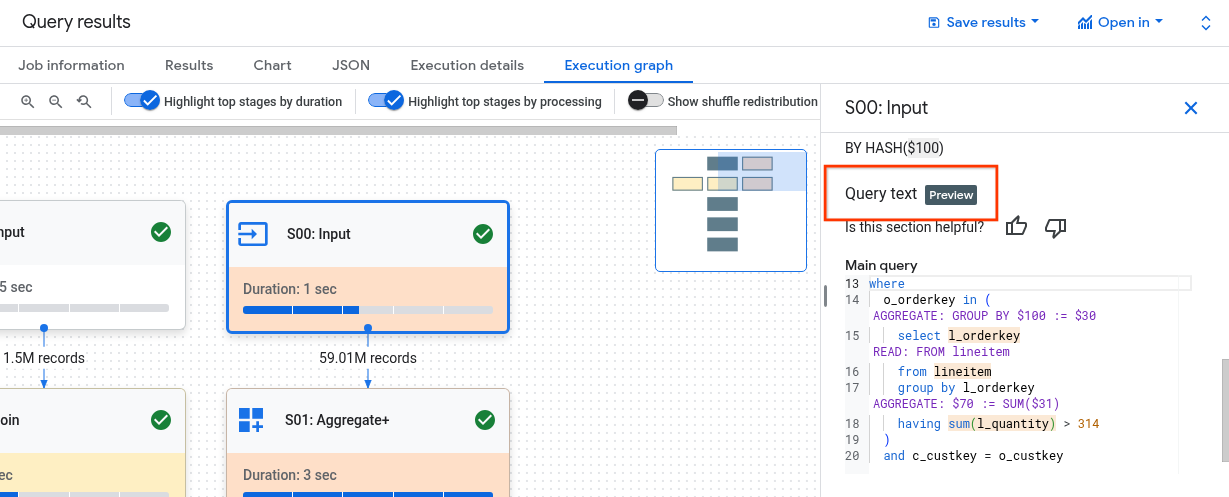
Contoh screenshot menunjukkan pemetaan berikut:
Langkah
AGGREGATE: GROUP BY $100 := $30dipetakan kembali ke teks kueriselect l_orderkey.Langkah
READ: FROM lineitemdipetakan kembali ke teks kueriselect ... from lineitem.Langkah
AGGREGATE: $70 := SUM($31)dipetakan kembali ke teks kuerisum(l_quantity).
Tidak semua langkah dapat dipetakan kembali ke teks kueri.
Jika kueri menggunakan tampilan, dan jika langkah-langkah tahap memiliki pemetaan ke teks kueri tampilan, bagian Teks kueri menampilkan nama tampilan dan teks kueri tampilan dengan pemetaannya. Namun, jika tampilan dihapus, atau jika Anda kehilangan bigquery.tables.get izin IAM ke tampilan, bagian Teks kueri tidak akan menampilkan pemetaan langkah-langkah tahap untuk tampilan.
Menafsirkan dan mengoptimalkan langkah-langkah
Bagian berikut menjelaskan cara menafsirkan langkah-langkah dalam rencana kueri dan memberikan cara untuk mengoptimalkan kueri Anda.
READ langkah
Langkah READ berarti bahwa suatu tahap mengakses data untuk diproses. Data dapat
dibaca langsung dari tabel yang dirujuk dalam kueri, atau dari memori pengacakan.
Saat data dari tahap sebelumnya dibaca, BigQuery membaca data dari memori shuffle. Jumlah data yang dipindai memengaruhi biaya saat menggunakan slot on-demand dan memengaruhi performa saat menggunakan reservasi.
Potensi masalah performa
- Pemindaian besar tabel yang tidak berpartisi: jika kueri hanya memerlukan sebagian kecil data, hal ini mungkin menunjukkan bahwa pemindaian tabel tidak efisien. Membuat partisi dapat menjadi strategi pengoptimalan yang baik.
- Pemindaian tabel besar dengan rasio filter kecil: hal ini menunjukkan bahwa filter tidak secara efektif mengurangi data yang dipindai. Pertimbangkan untuk merevisi kondisi filter.
- Byte pengacakan yang meluap ke disk: hal ini menunjukkan bahwa data tidak disimpan secara efektif menggunakan teknik pengoptimalan seperti pengelompokan, yang dapat mempertahankan data serupa dalam cluster.
Optimalkan
- Pemfilteran yang ditargetkan: gunakan klausa
WHEREsecara strategis untuk memfilter data yang tidak relevan sedini mungkin dalam kueri. Hal ini mengurangi jumlah data yang perlu diproses oleh kueri. - Partisi dan pengelompokan: BigQuery menggunakan partisi dan pengelompokan tabel untuk menemukan segmen data tertentu secara efisien.
Pastikan tabel Anda dipartisi dan dikelompokkan berdasarkan pola kueri umum Anda untuk meminimalkan data yang dipindai selama langkah
READ. - Pilih kolom yang relevan: hindari penggunaan pernyataan
SELECT *. Sebagai gantinya, pilih kolom tertentu atau gunakanSELECT * EXCEPTuntuk menghindari pembacaan data yang tidak perlu. - Tampilan terwujud: tampilan terwujud dapat melakukan pra-penghitungan dan menyimpan agregasi yang sering digunakan, sehingga berpotensi mengurangi kebutuhan untuk membaca tabel dasar selama langkah
READuntuk kueri yang menggunakan tampilan tersebut.
COMPUTE langkah
Pada langkah COMPUTE, BigQuery melakukan tindakan berikut pada data Anda:
- Mengevaluasi ekspresi dalam
SELECT,WHERE,HAVING, dan klausa lainnya dalam kueri, termasuk kalkulasi, perbandingan, dan operasi logis. - Mengeksekusi fungsi SQL bawaan dan fungsi yang ditentukan pengguna.
- Memfilter baris data berdasarkan kondisi dalam kueri.
Optimalkan
Paket kueri dapat mengungkapkan hambatan dalam langkah COMPUTE. Cari tahap
dengan komputasi yang ekstensif atau jumlah baris yang diproses dalam jumlah besar.
- Korelasikan langkah
COMPUTEdengan volume data: jika suatu tahap menunjukkan komputasi yang signifikan dan memproses data dalam volume besar, maka tahap tersebut mungkin merupakan kandidat yang baik untuk dioptimalkan. - Data miring: untuk tahap saat maksimum komputasi jauh lebih tinggi daripada rata-rata komputasi, hal ini menunjukkan bahwa tahap tersebut menghabiskan waktu yang tidak proporsional untuk memproses beberapa slice data. Pertimbangkan untuk melihat distribusi data guna mengetahui apakah ada skew data.
- Pertimbangkan jenis data: gunakan jenis data yang sesuai untuk kolom Anda. Misalnya, menggunakan bilangan bulat, tanggal dan waktu, serta stempel waktu, bukan string, dapat meningkatkan performa.
WRITE langkah
Langkah-langkah WRITE terjadi untuk data perantara dan output akhir.
- Menulis ke memori pengacakan: dalam kueri multi-tahap, langkah
WRITEsering kali melibatkan pengiriman data yang diproses ke tahap lain untuk diproses lebih lanjut. Hal ini umum terjadi pada memori pengacakan, yang menggabungkan atau mengagregasi data dari beberapa sumber. Data yang ditulis selama tahap ini biasanya merupakan hasil perantara, bukan output akhir. - Output akhir: hasil kueri ditulis ke tujuan atau tabel sementara.
Partisi Hash
Saat tahap dalam rencana kueri menulis data ke output yang dipartisi hash, BigQuery akan menulis kolom yang disertakan dalam output dan kolom yang dipilih sebagai kunci partisi.
Optimalkan
Meskipun langkah WRITE itu sendiri mungkin tidak dioptimalkan secara langsung, memahami perannya dapat membantu Anda mengidentifikasi potensi hambatan pada tahap awal:
- Minimalkan data yang ditulis: berfokus pada pengoptimalan tahap sebelumnya dengan pemfilteran dan agregasi untuk mengurangi jumlah data yang ditulis selama langkah ini.
Partisi: penulisan sangat diuntungkan dari partisi tabel. Jika data yang Anda tulis terbatas pada partisi tertentu, BigQuery dapat melakukan penulisan yang lebih cepat.
Jika pernyataan DML memiliki klausa
WHEREdengan kondisi statis terhadap kolom partisi tabel, BigQuery hanya akan mengubah partisi tabel yang relevan.Trade-off denormalisasi: denormalisasi terkadang dapat menghasilkan set hasil yang lebih kecil pada langkah
WRITEmenengah. Namun, ada kekurangan seperti peningkatan penggunaan penyimpanan dan tantangan konsistensi data.
JOIN langkah
Pada langkah JOIN, BigQuery menggabungkan data dari dua sumber data.
Gabungan dapat mencakup kondisi gabungan. Penggabungan memerlukan banyak resource. Saat menggabungkan data berukuran besar di BigQuery, kunci gabungan diacak secara terpisah agar sejajar di slot yang sama, sehingga gabungan dilakukan secara lokal di setiap slot.
Paket kueri untuk langkah JOIN biasanya mengungkapkan detail berikut:
- Pola gabungan: menunjukkan jenis gabungan yang digunakan. Setiap jenis menentukan jumlah baris dari tabel gabungan yang disertakan dalam set hasil.
- Gabungkan kolom: ini adalah kolom yang digunakan untuk mencocokkan baris di antara sumber data. Pilihan kolom sangat penting untuk performa gabungan.
Pola gabungan
- Penggabungan siaran: saat satu tabel, biasanya yang lebih kecil, dapat dimuat dalam memori di satu node atau slot pekerja, BigQuery dapat menyiarkannya ke semua node lain untuk melakukan penggabungan secara efisien. Cari
JOIN EACH WITH ALLdi detail langkah. - Hash join: saat tabel berukuran besar atau gabungan siaran tidak sesuai, gabungan hash mungkin digunakan. BigQuery menggunakan operasi hash dan shuffle
untuk mengacak tabel kiri dan kanan sehingga kunci yang cocok
berada di slot yang sama untuk melakukan gabungan lokal. Penggabungan hash adalah operasi yang mahal karena data perlu dipindahkan, tetapi memungkinkan pencocokan baris yang efisien di seluruh hash. Cari
JOIN EACH WITH EACHdi detail langkah. - Self join: antipola SQL saat tabel digabungkan ke dirinya sendiri.
- Cross join: antipola SQL yang dapat menyebabkan masalah performa yang signifikan karena menghasilkan data output yang lebih besar daripada input.
- Gabungan miring: distribusi data di seluruh kunci gabungan dalam satu tabel sangat miring dan dapat menyebabkan masalah performa. Cari kasus saat waktu komputasi maksimum jauh lebih besar daripada waktu komputasi rata-rata dalam rencana kueri. Untuk mengetahui informasi selengkapnya, lihat Gabungan kardinalitas tinggi dan Ketidakseimbangan partisi.
Proses Debug
- Volume data besar: jika rencana kueri menunjukkan sejumlah besar data yang diproses selama langkah
JOIN, selidiki kondisi gabungan dan kunci gabungan. Pertimbangkan untuk memfilter atau menggunakan kunci gabungan yang lebih selektif. - Distribusi data miring: menganalisis distribusi data kunci gabungan. Jika satu tabel sangat miring, pelajari strategi seperti memisahkan kueri atau melakukan prapenyaringan.
- Join kardinalitas tinggi: join yang menghasilkan baris yang jauh lebih banyak daripada jumlah baris input kiri dan kanan dapat mengurangi performa kueri secara drastis. Hindari gabungan yang menghasilkan sejumlah besar baris.
- Urutan tabel yang salah: Pastikan Anda telah memilih jenis
penggabungan yang sesuai, seperti
INNERatauLEFT, dan mengurutkan tabel dari yang terbesar hingga yang terkecil berdasarkan persyaratan kueri Anda.
Optimalkan
- Kunci gabungan selektif: untuk kunci gabungan, gunakan
INT64, bukanSTRING, jika memungkinkan. PerbandinganSTRINGlebih lambat daripada perbandinganINT64karena membandingkan setiap karakter dalam string. Bilangan bulat hanya memerlukan satu perbandingan. - Memfilter sebelum menggabungkan: menerapkan filter klausa
WHEREpada setiap tabel sebelum penggabungan. Hal ini mengurangi jumlah data yang terlibat dalam operasi penggabungan. - Hindari fungsi pada kolom gabungan: hindari pemanggilan fungsi pada kolom gabungan. Sebagai gantinya, standarisasi data tabel Anda selama proses penyerapan atau pasca-penyerapan menggunakan pipeline SQL ELT. Pendekatan ini menghilangkan kebutuhan untuk mengubah kolom gabungan secara dinamis, yang memungkinkan penggabungan yang lebih efisien tanpa mengorbankan integritas data.
- Hindari self-join: self-join biasanya digunakan untuk menghitung hubungan yang bergantung pada baris. Namun, self-join berpotensi melipatgandakan jumlah baris output, sehingga menyebabkan masalah performa. Daripada mengandalkan self-join, pertimbangkan untuk menggunakan fungsi jendela (analitik).
- Tabel besar terlebih dahulu: meskipun pengoptimal kueri SQL dapat menentukan tabel mana yang harus berada di sisi gabungan mana, urutkan tabel gabungan Anda dengan tepat. Praktik terbaiknya adalah menempatkan tabel terbesar terlebih dahulu, diikuti dengan tabel terkecil, lalu dengan ukuran yang menurun.
- Denormalisasi: dalam beberapa kasus, denormalisasi tabel secara strategis (menambahkan data redundan) dapat menghilangkan penggabungan sepenuhnya. Namun, pendekatan ini memiliki pertimbangan terkait penyimpanan dan konsistensi data.
- Mempartisi dan mengelompokkan: mempartisi tabel berdasarkan kunci gabungan dan mengelompokkan data yang ditempatkan bersama dapat mempercepat gabungan secara signifikan dengan memungkinkan BigQuery menargetkan partisi data yang relevan.
- Mengoptimalkan penggabungan condong: untuk menghindari masalah performa yang terkait dengan penggabungan condong, pra-filter data dari tabel sedini mungkin atau bagi kueri menjadi dua kueri atau lebih.
AGGREGATE langkah
Pada langkah AGGREGATE, BigQuery menggabungkan dan mengelompokkan data.
Proses Debug
- Detail tahap: periksa jumlah baris input dan baris output dari agregasi, dan ukuran pengacakan untuk menentukan seberapa besar pengurangan data yang dicapai langkah agregasi dan apakah pengacakan data terlibat.
- Ukuran pengacakan: ukuran pengacakan yang besar dapat menunjukkan bahwa sejumlah besar data dipindahkan di seluruh node pekerja selama agregasi.
- Periksa distribusi data: pastikan data didistribusikan secara merata di seluruh partisi. Distribusi data yang miring dapat menyebabkan workload yang tidak seimbang pada langkah agregasi.
- Tinjau agregasi: analisis klausa agregasi untuk mengonfirmasi bahwa klausa tersebut diperlukan dan efisien.
Optimalkan
- Pengelompokan: kelompokkan tabel Anda pada kolom yang sering digunakan dalam klausa
GROUP BY,COUNT, atau agregasi lainnya. - Partisi: pilih strategi partisi yang sesuai dengan pola kueri Anda. Sebaiknya gunakan tabel berpartisi berdasarkan waktu penyerapan untuk mengurangi jumlah data yang dipindai selama penggabungan.
- Lakukan agregasi lebih awal: jika memungkinkan, lakukan agregasi lebih awal di pipeline kueri. Hal ini dapat mengurangi jumlah data yang perlu diproses selama agregasi.
- Pengoptimalan pengacakan: jika pengacakan menjadi hambatan, pelajari cara meminimalkannya. Misalnya, denormalisasi tabel atau gunakan pengelompokan untuk menempatkan data yang relevan.
Kasus ekstrem
- Agregat DISTINCT: kueri dengan agregat
DISTINCTdapat memerlukan banyak komputasi, terutama pada set data besar. Pertimbangkan alternatif sepertiAPPROX_COUNT_DISTINCTuntuk mendapatkan perkiraan hasil. - Jumlah grup yang besar: jika kueri menghasilkan sejumlah besar grup, kueri tersebut dapat menggunakan sejumlah besar memori. Dalam kasus tersebut, pertimbangkan untuk membatasi jumlah grup atau menggunakan strategi agregasi yang berbeda.
REPARTITION langkah
REPARTITION dan COALESCE adalah teknik pengoptimalan yang diterapkan BigQuery secara langsung ke data yang diacak dalam kueri.
REPARTITION: operasi ini bertujuan untuk menyeimbangkan kembali distribusi data di seluruh node pekerja. Misalkan setelah pengacakan, satu worker node memiliki data dalam jumlah yang sangat besar. LangkahREPARTITIONmendistribusikan ulang data secara lebih merata, sehingga mencegah satu pekerja menjadi hambatan. Hal ini sangat penting untuk operasi yang intensif secara komputasi seperti penggabungan.COALESCE: langkah ini terjadi saat Anda memiliki banyak bucket kecil data setelah pengacakan. LangkahCOALESCEmenggabungkan bucket ini menjadi bucket yang lebih besar, sehingga mengurangi overhead yang terkait dengan pengelolaan banyak potongan data kecil. Hal ini dapat sangat bermanfaat saat menangani set hasil perantara yang sangat kecil.
Jika Anda melihat langkah-langkah REPARTITION atau COALESCE dalam rencana kueri, bukan berarti ada masalah dengan kueri Anda. Hal ini sering kali menandakan bahwa BigQuery secara proaktif mengoptimalkan distribusi data untuk performa yang lebih baik. Namun, jika Anda melihat operasi ini berulang kali, hal ini mungkin menunjukkan bahwa data Anda pada dasarnya miring atau kueri Anda menyebabkan pengacakan data yang berlebihan.
Optimalkan
Untuk mengurangi jumlah langkah REPARTITION, coba lakukan hal berikut:
- Distribusi data: pastikan tabel Anda dipartisi dan dikelompokkan secara efektif. Data yang terdistribusi dengan baik mengurangi kemungkinan ketidakseimbangan yang signifikan setelah pengacakan.
- Struktur kueri: menganalisis kueri untuk mengetahui potensi sumber kemiringan data. Misalnya, apakah ada filter atau gabungan yang sangat selektif yang menyebabkan subset kecil data diproses pada satu pekerja?
- Strategi penggabungan: lakukan eksperimen dengan berbagai strategi penggabungan untuk melihat apakah strategi tersebut menghasilkan distribusi data yang lebih seimbang.
Untuk mengurangi jumlah langkah COALESCE, coba lakukan hal berikut:
- Strategi agregasi: pertimbangkan untuk melakukan agregasi lebih awal di pipeline kueri. Hal ini dapat membantu mengurangi jumlah set hasil perantara kecil yang dapat menyebabkan langkah-langkah
COALESCE. - Volume data: jika Anda menangani set data yang sangat kecil,
COALESCEmungkin tidak menjadi masalah yang signifikan.
Jangan terlalu mengoptimalkan. Pengoptimalan prematur dapat membuat kueri Anda menjadi lebih rumit tanpa memberikan manfaat yang signifikan.
Penjelasan untuk kueri gabungan
Kueri gabungan memungkinkan Anda mengirim pernyataan
kueri ke sumber data eksternal menggunakan fungsi EXTERNAL_QUERY.
Kueri gabungan tunduk pada teknik pengoptimalan yang dikenal sebagai pushdown SQL dan rencana kueri menunjukkan operasi yang di-pushdown ke sumber data eksternal, jika ada. Misalnya, jika Anda menjalankan kueri berikut:
SELECT id, name
FROM EXTERNAL_QUERY("<connection>", "SELECT * FROM company")
WHERE country_code IN ('ee', 'hu') AND name like '%TV%'
Rencana kueri akan menampilkan langkah-langkah tahap berikut:
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, country_code
FROM (
/*native_query*/
SELECT * FROM company
)
WHERE in(country_code, 'ee', 'hu')
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
Dalam rencana ini, table_for_external_query_$_0(...) mewakili fungsi
EXTERNAL_QUERY. Dalam tanda kurung, Anda dapat melihat kueri yang dijalankan
sumber data eksternal. Berdasarkan hal itu, Anda dapat melihat bahwa:
- Sumber data eksternal hanya menampilkan 3 kolom yang dipilih.
- Sumber data eksternal hanya menampilkan baris yang
country_code-nya adalah'ee'atau'hu'. - Operator
LIKEtidak didorong ke bawah dan dievaluasi oleh BigQuery.
Sebagai perbandingan, jika tidak ada pushdown, paket kueri akan menampilkan langkah-langkah tahap berikut:
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, description, country_code, primary_address, secondary address
FROM (
/*native_query*/
SELECT * FROM company
)
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
Kali ini, sumber data eksternal menampilkan semua kolom dan semua baris dari tabel company, dan BigQuery melakukan pemfilteran.
Metadata linimasa
Linimasa kueri melaporkan progres pada waktu tertentu, yang menyediakan tampilan snapshot progres kueri secara keseluruhan. Linimasa direpresentasikan sebagai serangkaian contoh yang melaporkan detail berikut:
| Kolom | Deskripsi |
|---|---|
elapsedMs |
Milidetik berlalu sejak awal eksekusi kueri. |
totalSlotMs |
Representasi kumulatif slot milidetik yang digunakan oleh kueri. |
pendingUnits |
Total unit tugas yang dijadwalkan dan menunggu eksekusi. |
activeUnits |
Total unit tugas aktif yang sedang diproses oleh pekerja. |
completedUnits |
Total unit tugas yang telah diselesaikan saat menjalankan kueri ini. |
Contoh kueri
Kueri berikut menghitung jumlah baris dalam set data publik Shakespeare dan memiliki jumlah bersyarat kedua yang membatasi hasil pada baris yang merujuk ke 'hamlet':
SELECT
COUNT(1) as rowcount,
COUNTIF(corpus = 'hamlet') as rowcount_hamlet
FROM `publicdata.samples.shakespeare`
Klik Execution details untuk melihat paket kueri:
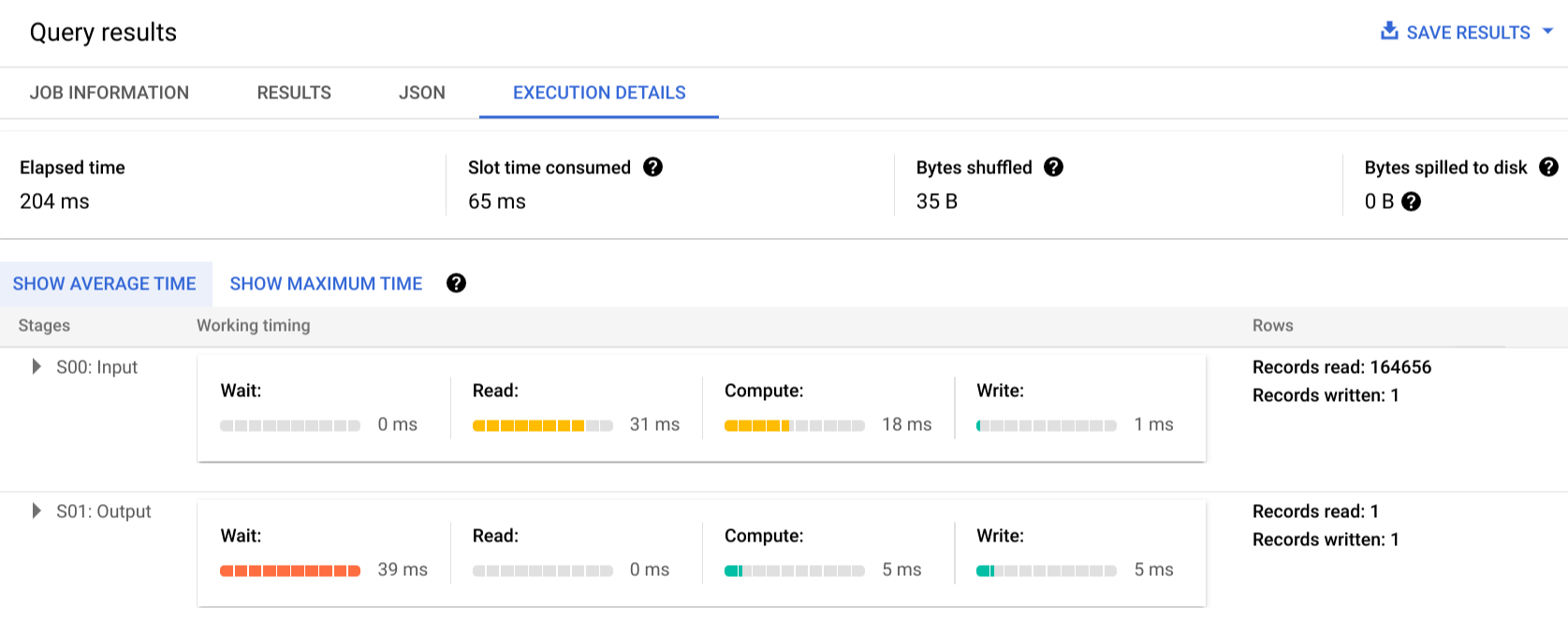
Indikator warna menunjukkan pengaturan waktu relatif untuk semua langkah di seluruh stage.
Untuk mempelajari lebih lanjut langkah-langkah stage eksekusi, klik untuk meluaskan detail stage tersebut:
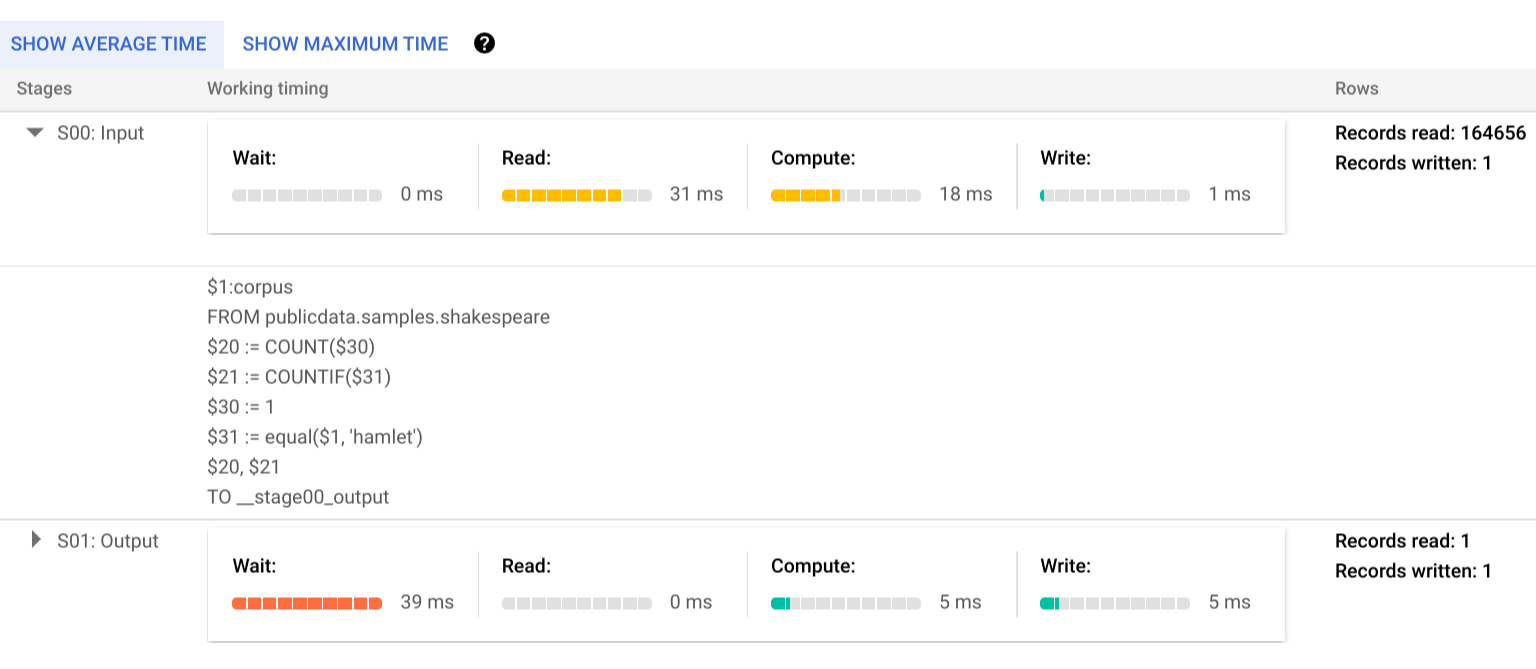
Dalam contoh ini, waktu terlama di segmen mana pun adalah waktu yang dihabiskan oleh satu worker di Stage 01 untuk menunggu Stage 00 selesai. Hal ini karena Stage 01 bergantung pada input Stage 00, dan tidak dapat dimulai hingga stage pertama menulis output-nya dalam mode shuffle menengah.
Pelaporan error
Tugas kueri mungkin saja gagal di tengah eksekusi. Karena informasi paket diperbarui secara berkala, Anda dapat mengamati di bagian mana kegagalan terjadi dalam grafik eksekusi. Dalam konsol Google Cloud , tahap yang berhasil atau gagal diberi label dengan tanda centang atau tanda seru di samping nama tahap.
Untuk mengetahui informasi lebih lanjut tentang cara menafsirkan dan mengatasi error, lihat panduan pemecahan masalah.
Representasi contoh API
Informasi paket kueri disematkan dalam informasi respons tugas, dan Anda dapat mengambilnya dengan memanggil jobs.get.
Misalnya, kutipan respons JSON berikut untuk tugas yang menampilkan contoh kueri hamlet menunjukkan paket kueri dan informasi linimasa.
"statistics": {
"creationTime": "1576544129234",
"startTime": "1576544129348",
"endTime": "1576544129681",
"totalBytesProcessed": "2464625",
"query": {
"queryPlan": [
{
"name": "S00: Input",
"id": "0",
"startMs": "1576544129436",
"endMs": "1576544129465",
"waitRatioAvg": 0.04,
"waitMsAvg": "1",
"waitRatioMax": 0.04,
"waitMsMax": "1",
"readRatioAvg": 0.32,
"readMsAvg": "8",
"readRatioMax": 0.32,
"readMsMax": "8",
"computeRatioAvg": 1,
"computeMsAvg": "25",
"computeRatioMax": 1,
"computeMsMax": "25",
"writeRatioAvg": 0.08,
"writeMsAvg": "2",
"writeRatioMax": 0.08,
"writeMsMax": "2",
"shuffleOutputBytes": "18",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "164656",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$1:corpus",
"FROM publicdata.samples.shakespeare"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$20 := COUNT($30)",
"$21 := COUNTIF($31)"
]
},
{
"kind": "COMPUTE",
"substeps": [
"$30 := 1",
"$31 := equal($1, 'hamlet')"
]
},
{
"kind": "WRITE",
"substeps": [
"$20, $21",
"TO __stage00_output"
]
}
]
},
{
"name": "S01: Output",
"id": "1",
"startMs": "1576544129465",
"endMs": "1576544129480",
"inputStages": [
"0"
],
"waitRatioAvg": 0.44,
"waitMsAvg": "11",
"waitRatioMax": 0.44,
"waitMsMax": "11",
"readRatioAvg": 0,
"readMsAvg": "0",
"readRatioMax": 0,
"readMsMax": "0",
"computeRatioAvg": 0.2,
"computeMsAvg": "5",
"computeRatioMax": 0.2,
"computeMsMax": "5",
"writeRatioAvg": 0.16,
"writeMsAvg": "4",
"writeRatioMax": 0.16,
"writeMsMax": "4",
"shuffleOutputBytes": "17",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "1",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$20, $21",
"FROM __stage00_output"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$10 := SUM_OF_COUNTS($20)",
"$11 := SUM_OF_COUNTS($21)"
]
},
{
"kind": "WRITE",
"substeps": [
"$10, $11",
"TO __stage01_output"
]
}
]
}
],
"estimatedBytesProcessed": "2464625",
"timeline": [
{
"elapsedMs": "304",
"totalSlotMs": "50",
"pendingUnits": "0",
"completedUnits": "2"
}
],
"totalPartitionsProcessed": "0",
"totalBytesProcessed": "2464625",
"totalBytesBilled": "10485760",
"billingTier": 1,
"totalSlotMs": "50",
"cacheHit": false,
"referencedTables": [
{
"projectId": "publicdata",
"datasetId": "samples",
"tableId": "shakespeare"
}
],
"statementType": "SELECT"
},
"totalSlotMs": "50"
},
Menggunakan informasi eksekusi
Paket kueri BigQuery memberikan informasi tentang cara layanan mengeksekusi kueri, tetapi sifat layanan yang terkelola membatasi bisa tidaknya beberapa detail ditindaklanjuti secara langsung. Banyak pengoptimalan terjadi secara otomatis dengan menggunakan layanan ini, yang dapat berbeda dengan lingkungan lain karena penyesuaian, penyediaan, dan pemantauan dapat memerlukan staf khusus yang berpengetahuan luas.
Untuk mengetahui teknik tertentu yang dapat meningkatkan eksekusi dan performa kueri, lihat dokumentasi praktik terbaik. Statistik paket dan linimasa kueri dapat membantu Anda memahami apakah tahap tertentu mendominasi penggunaan resource. Misalnya, stage JOIN yang menghasilkan baris output yang jauh lebih banyak daripada baris input dapat mengindikasikan peluang untuk memfilter lebih awal dalam kueri.
Selain itu, informasi linimasa dapat membantu mengidentifikasi apakah kueri tertentu lambat secara terpisah atau karena efek dari kueri lain yang menangani resource yang sama. Jika Anda mengamati bahwa jumlah unit aktif tetap terbatas selama masa aktif kueri, tetapi jumlah unit tugas yang diantrekan tetap tinggi, hal ini dapat mewakili kasus ketika pengurangan jumlah kueri serentak dapat secara signifikan meningkatkan waktu eksekusi secara keseluruhan untuk kueri tertentu.