取得查詢效能洞察資料
查詢的執行圖表會以視覺化方式呈現 BigQuery 執行查詢的步驟。本文說明如何使用查詢執行圖診斷查詢效能問題,以及如何查看查詢效能深入分析。
BigQuery 的查詢效能十分優異,但也是複雜的分散式系統,許多內外部因素都會影響查詢速度。SQL 的宣告式性質也可能隱藏查詢執行的複雜度。也就是說,當查詢的執行速度比預期慢,或比先前的執行速度慢時,瞭解發生了什麼事可能是一項挑戰。
查詢執行圖表提供動態圖形介面,可檢查查詢計畫和查詢效能詳細資料。您可以查看任何執行中或已完成查詢的查詢執行圖。
您也可以使用查詢執行圖,取得查詢的效能洞察資料。效能深入分析會提供最佳效能建議,協助您提高查詢效能。由於查詢效能涉及多個層面,效能深入分析可能只會顯示查詢效能的局部資訊,而非整體情況。
所需權限
如要使用查詢執行圖表,您必須具備下列權限:
bigquery.jobs.getbigquery.jobs.listAll
您可以透過下列 BigQuery 預先定義的 Identity and Access Management (IAM) 角色取得這些權限:
roles/bigquery.adminroles/bigquery.resourceAdminroles/bigquery.resourceEditorroles/bigquery.resourceViewer
執行圖結構
查詢執行圖表會以圖形呈現主控台中的查詢計畫。每個方塊代表查詢計畫中的一個階段,例如:
- 輸入:從表格讀取資料或選取特定欄
- 彙整:根據
JOIN條件合併兩個資料表的資料 - 匯總:執行
SUM等計算 - 排序:排列結果順序
階段由「步驟」組成,說明每個工作站在階段中執行的個別作業。按一下階段即可開啟並查看步驟。階段也包含相對和絕對時間碼資訊。階段名稱會歸納使用者執行的步驟。舉例來說,如果階段名稱包含「join」,表示該階段的主要步驟是 JOIN 作業。如果階段名稱結尾有 +,表示該階段會執行額外的重要步驟。舉例來說,如果階段名稱包含 JOIN+,表示該階段會執行聯結作業和其他重要步驟。
連接階段的線條代表階段間的中介資料交換。BigQuery 會在階段執行時,將中繼資料儲存在重組記憶體中。邊緣的數字表示各階段之間交換的預估列數。Shuffle 記憶體配額與分配給帳戶的運算單元數量相關。如果超過重組配額,重組記憶體可能會溢出到磁碟,導致查詢效能大幅降低。
查看查詢成效洞察
主控台
如要查看查詢成效洞察,請按照下列步驟操作:
在 Google Cloud 控制台中開啟 BigQuery 頁面。
在左側窗格中,按一下「Explorer」:

如果沒有看到左側窗格,請按一下「展開左側窗格」圖示 開啟窗格。
在「Explorer」窗格中,按一下「Job history」(工作記錄)。
按一下「個人記錄」或「專案記錄」。
在工作清單中找出感興趣的查詢工作。按一下 「動作」,然後選擇「在編輯器中查看工作」。
選取「執行圖」分頁,即可查看查詢各階段的圖形表示法:

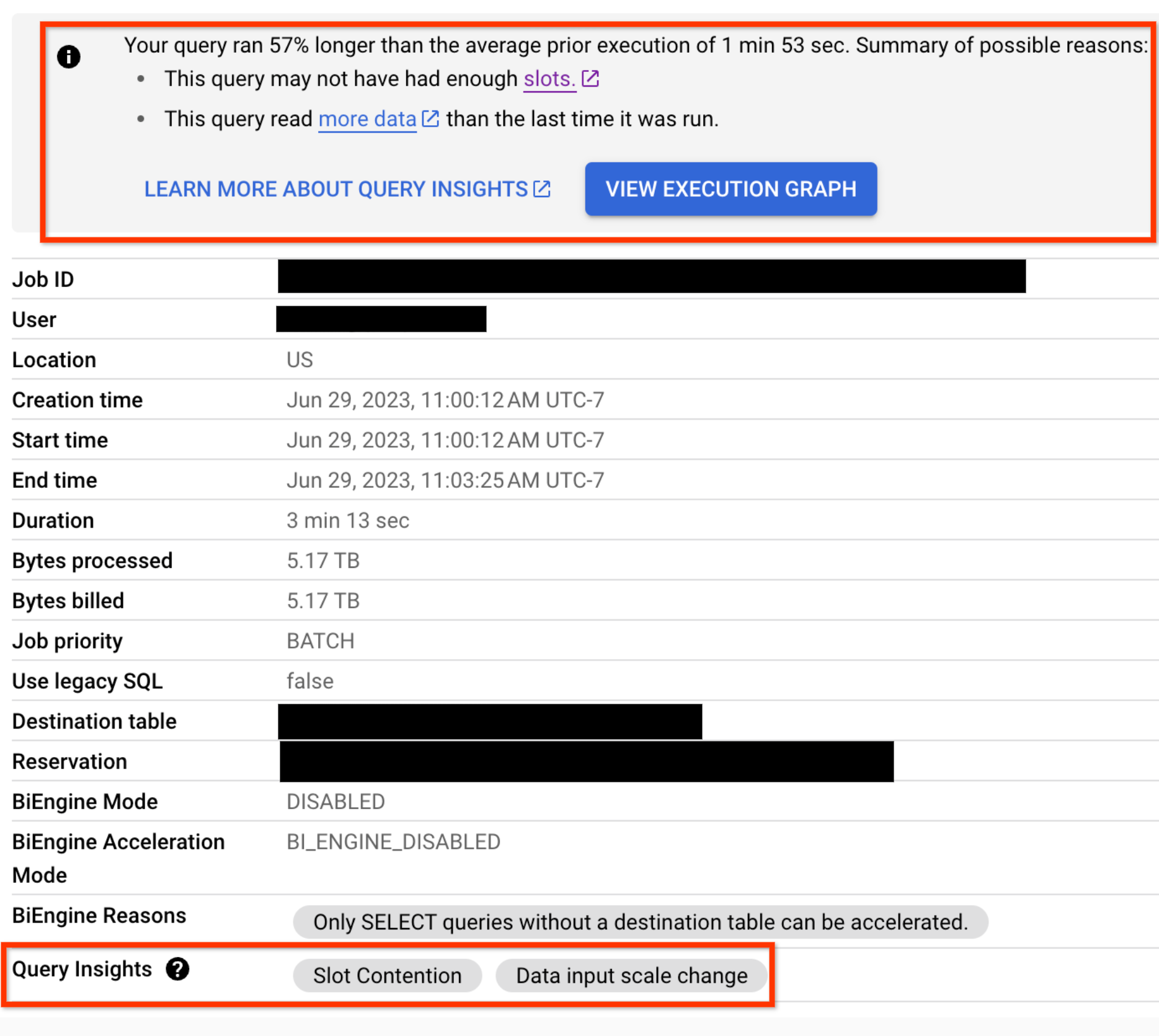
如要判斷查詢階段是否有效能洞察,請查看顯示的圖示。如果階段有 資訊圖示,表示有可用的效能洞察資料。有勾號圖示的階段則不會。
按一下階段即可開啟階段詳細資料窗格,查看下列資訊:

選用:如要檢查正在執行的查詢,請按一下「同步」,更新執行圖表,反映查詢的目前狀態。

選用:如要在圖表上醒目顯示持續時間最長的階段,請按一下「醒目顯示持續時間最長的階段」。

選用:如要在圖表中醒目顯示使用最多時段的階段,請按一下「醒目顯示處理時間最長的階段」。

選用:如要在圖表中加入重組重新分配階段,請按一下「顯示重組重新分配階段」。

使用這個選項可顯示預設執行圖中隱藏的重新分割和合併階段。
查詢執行期間會引進重新分割和合併階段,用來改善處理查詢的工作站之間的資料分布狀況。由於這些階段與查詢文字無關,因此系統會隱藏這些階段,簡化顯示的查詢計畫。
如果查詢有成效回歸問題,查詢的「工作資訊」分頁也會顯示成效深入分析:
SQL
前往 Google Cloud 控制台的「BigQuery」頁面。
在查詢編輯器中輸入下列陳述式:
SELECT `bigquery-public-data`.persistent_udfs.job_url( project_id || ':us.' || job_id) AS job_url, query_info.performance_insights FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS_BY_PROJECT WHERE DATE(creation_time) >= CURRENT_DATE - 30 -- scan 30 days of query history AND job_type = 'QUERY' AND state = 'DONE' AND error_result IS NULL AND statement_type != 'SCRIPT' AND EXISTS ( -- Only include queries which had performance insights SELECT 1 FROM UNNEST( query_info.performance_insights.stage_performance_standalone_insights ) WHERE slot_contention OR insufficient_shuffle_quota UNION ALL SELECT 1 FROM UNNEST( query_info.performance_insights.stage_performance_change_insights ) WHERE input_data_change.records_read_diff_percentage IS NOT NULL );
按一下「執行」。
如要進一步瞭解如何執行查詢,請參閱「執行互動式查詢」。
API
您可以呼叫 jobs.list API 方法,並檢查傳回的 JobStatistics2 資訊,以非圖形格式取得查詢成效洞察資料。
解讀查詢成效洞察資料
請參閱本節,進一步瞭解效能洞察資料的意義,以及如何解決相關問題。
成效洞察資訊適用於兩類使用者:
分析師:在專案中執行查詢。您想瞭解先前執行的查詢為何執行速度變慢,並取得提升查詢效能的訣竅。您具備「必要權限」一節所述的權限。
資料湖或資料倉儲管理員:管理貴機構的 BigQuery 資源和預留空間。您具備與 BigQuery 管理員角色相關聯的權限。
以下各節將根據您的角色,提供如何因應收到的成效洞察資訊。
運算單元爭用情況
執行查詢時,BigQuery 會嘗試將查詢所需的工作分解為工作。工作是指輸入和輸出階段的單一資料切片。單一時段會擷取一項工作,並執行該階段的資料切片。理想情況下,BigQuery slot 會平行執行這些工作,以達到高效能。當查詢有許多準備執行的工作,但 BigQuery 無法取得足夠的可用運算單元來執行這些工作時,就會發生運算單元爭用情形。
分析師的處理方式
請按照「減少查詢處理的資料量」一文中的操作說明,減少查詢處理的資料量。
如果您是管理員
採取下列行動,增加運算單元可用性或減少運算單元用量:
- 如果您使用 BigQuery 的以量計價方案,查詢會使用共用的運算單元集區。建議您改為購買預訂,並採用以容量為準的分析價格。您可以透過預留項目,為貴機構的查詢預留專屬運算單元。
如果您使用 BigQuery 預留項目,請確認指派給執行查詢專案的預留項目有足夠的運算單元。在下列情況下,預留項目可能沒有足夠的運算單元:
如要解決這個問題,請嘗試下列任一方法:
- 為該預留項目新增更多運算單元 (基準運算單元或預留項目的運算單元數量上限)。
- 建立額外預留項目,並指派給執行查詢的專案。
- 分散耗用大量資源的查詢,無論是在保留項目內的時間範圍,還是不同的保留項目之間。
確認您查詢的資料表是叢集資料表。叢集有助於確保 BigQuery 能快速讀取具有相關資料的資料欄。
請確認您查詢的資料表已分區。如果是未經分割的資料表,BigQuery 會讀取整個資料表。分區資料表可確保您只查詢感興趣的資料表子集。
重組配額不足
執行查詢前,BigQuery 會將查詢邏輯分解為階段。BigQuery 運算單元會執行每個階段的作業。運算單元完成階段工作的執行作業後,會將中間結果儲存在 shuffle 中。查詢中的後續階段會從隨機播放讀取資料,繼續執行查詢。如果需要寫入重組的資料量超過重組容量,就會發生重組配額不足的情況。
分析師的處理方式
與時段爭用類似,減少查詢處理的資料量可能會降低隨機播放的使用量。如要減少查詢處理的資料量,請按照「減少查詢處理的資料量」一文中的操作說明進行。
SQL 中的某些作業會大量使用 Shuffle,尤其是 JOIN 作業和 GROUP BY 子句。盡可能減少這些作業中的資料量,或許就能減少隨機重組的使用量。
如果您是管理員
採取下列動作,減少隨機播放配額爭用情形:
- 與運算單元爭用類似,如果您使用 BigQuery 的以量計價方案,查詢會使用共用的運算單元集區。建議您改為購買預訂,並採用以容量為準的分析價格。預留項目可為專案查詢提供專屬運算單元和重組容量。
如果您使用 BigQuery 預留項目,運算單元會提供專屬的隨機重組容量。如果保留項目正在執行大量使用 Shuffle 的查詢,可能會導致平行執行的其他查詢無法取得足夠的 Shuffle 容量。如要找出大量使用隨機重組容量的工作,請查詢
INFORMATION_SCHEMA.JOBS_TIMELINE檢視區塊中的period_shuffle_ram_usage_ratio資料欄。如要解決這個問題,請嘗試下列一或多個解決方案:
- 在該預訂項目中新增更多運算單元。
- 建立額外預留項目,並指派給執行查詢的專案。
- 將需要大量重組的查詢分散到一段時間內 (在預留項目中),或分散到不同預留項目中。
資料輸入規模調整
如果看到這項成效洞察資料,表示查詢讀取特定輸入資料表的資料量,比上次執行查詢時至少多出 50%。您可以查看資料表變更記錄,瞭解查詢中使用的任何資料表大小是否最近有所增加。
分析師的處理方式
請按照「減少查詢處理的資料量」一文中的操作說明,減少查詢處理的資料量。
高基數聯結
如果查詢包含彙整,且彙整兩側都有非專屬索引鍵,輸出資料表的大小可能會遠大於任一輸入資料表。這項洞察資訊表示輸出資料列與輸入資料列的比率偏高,並提供這些資料列的計數資訊。
分析師的處理方式
檢查聯結條件,確認輸出表格大小增加是預期行為。避免使用交叉聯結。如果必須使用交叉聯結,請嘗試使用 GROUP BY 子句預先匯總結果,或使用窗型函式。詳情請參閱「減少使用 JOIN 前的資料量」。
分區偏差
如要提供意見或要求這項功能的支援服務,請傳送電子郵件至 bq-query-inspector-feedback@google.com。
資料分布不均可能會導致查詢速度緩慢。查詢執行時,BigQuery 會將資料分割成小分區,以便平行處理。如果資料在這些分區中分布不均,通常是因為聯結或分組鍵中經常出現值,導致某些分區明顯大於其他分區,就會發生資料傾斜。由於單一運算單元會處理整個分區,且無法共用工作,因此過大的分區可能會導致處理速度變慢、發生「超出資源限制」錯誤,甚至在極端情況下造成運算單元毀損。
執行 JOIN 作業時,BigQuery 會根據聯結鍵,將聯結左右兩側的資料分區。如果分割區過大,BigQuery 會嘗試重新平衡資料。如果傾斜程度過於嚴重,無法完全重新平衡,執行圖表的 JOIN 階段就會新增分區傾斜深入分析。
找出分區偏斜
在 BigQuery Studio 中使用「執行圖表」分頁,找出查詢的哪個階段發生分割區傾斜。系統會在該階段標示這項洞察資料。從階段詳細資料中,您可以判斷查詢文字的相關部分和正在處理的資料表。詳情請參閱「瞭解查詢文字的步驟」。
示例
以下查詢會將存放區資訊與檔案資訊聯結。如果某些存放區的檔案數量遠多於其他存放區,就可能發生偏斜。
SELECT r.repo_name, COUNT(f.path) AS file_count
FROM `bigquery-public-data.github_repos.sample_repos` AS r
JOIN `bigquery-public-data.github_repos.sample_files` AS f
ON r.repo_name = f.repo_name
WHERE r.watch_count > 10
GROUP BY r.repo_name
彙整索引鍵為 repo_name。在 sample_repos 資料表中,repo_name 應為不重複的值。不過,在 sample_files 表格中,repo_name 可能會出現多次。如果 sample_files 中出現的幾個 repo_name 值不成比例地頻繁,就會造成資料偏斜。
如要確認是否有資料傾斜,請分析較大資料表中的聯結鍵 (本例中為 sample_files) 分布情形。執行下列查詢來評估 repo_name 的分布情形:
SELECT repo_name, COUNT(*) AS occurrences
FROM `bigquery-public-data.github_repos.sample_files`
GROUP BY repo_name
ORDER BY occurrences DESC
如果是非常大的資料表,請使用 APPROX_TOP_COUNT 函式,有效估算最常出現的值。
SELECT APPROX_TOP_COUNT(repo_name, 100)
FROM `bigquery-public-data.github_repos.sample_files`
如果前幾名的值數量比其他值大上好幾個數量級,就表示資料有偏斜。
降低分區偏差
您可以採用下列策略來解決分割區偏斜問題:
- 盡早篩選資料。在查詢中盡早套用篩選器,減少處理的資料量。這可減少與傾斜鍵相關聯的資料列數量,避免資料列達到
JOIN或GROUP BY等作業。 分割查詢,找出傾斜的鍵。如果偏差是由幾個特定鍵值所造成,類似於上述範例中的
repo_name欄位,請考慮分割查詢。將傾斜鍵的資料與其餘資料分開處理,然後使用UNION ALL合併結果。範例:隔離常用金鑰。
-- Query for the skewed key SELECT r.repo_name, COUNT(f.path) AS file_count FROM `bigquery-public-data.github_repos.sample_repos` AS r JOIN `bigquery-public-data.github_repos.sample_files` AS f ON r.repo_name = f.repo_name WHERE r.watch_count > 10 AND r.repo_name = 'popular_repo' GROUP BY r.repo_name UNION ALL -- Query for all other keys SELECT r.repo_name, COUNT(f.path) AS file_count FROM `bigquery-public-data.github_repos.sample_repos` AS r JOIN `bigquery-public-data.github_repos.sample_files` AS f ON r.repo_name = f.repo_name WHERE r.watch_count > 10 AND r.repo_name != 'popular_repo' GROUP BY r.repo_name處理
NULL和預設值:如果主要資料欄中含有大量NULL或空字串值的資料列,就可能導致資料偏斜。如果不需要這些資料列進行分析,請在JOIN或GROUP BY前使用WHERE子句篩除這些資料列。重新排序作業:在有多個聯結的查詢中,順序可能很重要。 如有可能,請在查詢中較早執行聯結,大幅減少資料列數。
使用近似函式:如要匯總偏移資料,請考慮是否可接受近似結果。相較於
COUNT(DISTINCT)等精確函式,APPROX_COUNT_DISTINCT等函式對資料偏斜的容許度較高。
解讀查詢階段資訊
除了使用查詢效能深入分析,您也可以在查看查詢階段詳細資料時,參考下列指引來判斷查詢是否有問題:
- 如果一或多個階段的「等待時間 (毫秒)」值高於先前的查詢執行次數:
- 確認是否有足夠的時段可供工作負載使用。如果沒有,請在執行耗用大量資源的查詢時進行負載平衡,避免查詢彼此競爭。
- 如果「等待時間 (毫秒)」值高於單一階段的值,請查看前一階段,瞭解是否出現瓶頸。如果查詢中涉及的資料表資料或結構定義有大幅變更,可能會影響查詢效能。
- 如果某個階段的「Shuffle output bytes」(隨機輸出位元組) 值高於先前的查詢執行作業,或高於前一個階段,請評估該階段處理的步驟,查看是否有任何步驟產生大量資料。其中一個常見原因是步驟處理
INNER JOIN時,聯結兩側都有重複的鍵。這可能會傳回大量非預期資料。 - 使用執行圖表,依時間長度和處理程序查看頂端階段。請考量這些資料產生的資料量,以及是否與查詢中參照的資料表大小相符。如果不是,請檢查這些階段的步驟,看看是否有任何步驟可能會產生非預期的暫時資料量。
後續步驟
- 如需提升查詢效能的訣竅,請參閱查詢最佳化指南。