Receba estatísticas de desempenho de consultas
O gráfico de execução de uma consulta é uma representação visual dos passos que o BigQuery realiza para executar a consulta. Este documento descreve como usar o gráfico de execução de consultas para diagnosticar problemas de desempenho de consultas e ver estatísticas de desempenho de consultas.
O BigQuery oferece um forte desempenho de consultas, mas também é um sistema distribuído complexo com muitos fatores internos e externos que podem afetar a velocidade das consultas. A natureza declarativa do SQL também pode ocultar a complexidade da execução de consultas. Isto significa que, quando as suas consultas são executadas mais lentamente do que o previsto ou do que as execuções anteriores, compreender o que aconteceu pode ser um desafio.
O gráfico de execução de consultas oferece uma interface gráfica dinâmica para inspecionar o plano de consulta e os detalhes de desempenho da consulta. Pode rever o gráfico de execução de consultas para qualquer consulta em execução ou concluída.
Também pode usar o gráfico de execução de consultas para obter estatísticas de desempenho para consultas. As estatísticas de desempenho oferecem sugestões de melhor esforço para ajudar a melhorar o desempenho das consultas. Uma vez que o desempenho das consultas tem várias facetas, as estatísticas de desempenho podem fornecer apenas uma imagem parcial do desempenho geral das consultas.
Autorizações necessárias
Para usar o gráfico de execução de consultas, tem de ter as seguintes autorizações:
bigquery.jobs.getbigquery.jobs.listAll
Estas autorizações estão disponíveis através das seguintes funções predefinidas de gestão de identidade e de acesso (IAM) do BigQuery:
roles/bigquery.adminroles/bigquery.resourceAdminroles/bigquery.resourceEditorroles/bigquery.resourceViewer
Estrutura do gráfico de execução
O gráfico de execução de consultas fornece uma vista gráfica do plano de consulta na consola. Cada caixa representa uma fase no plano de consulta como as seguintes:
- Entrada: ler dados de uma tabela ou selecionar colunas específicas
- Juntar: unir dados de duas tabelas com base na condição
JOIN - Agregado: realizar cálculos como
SUM - Ordenar: ordenar os resultados
As fases são compostas por
passos
que descrevem as operações individuais que cada trabalhador numa fase
executa. Pode clicar numa fase para a abrir e ver os respetivos passos. As etapas também incluem informações de tempo relativas e absolutas.
Os nomes das fases resumem os passos que os clientes realizam. Por exemplo, uma fase com join no nome significa que o passo principal na fase é uma operação JOIN. Os nomes das fases que terminam com + significam que
executam passos importantes adicionais. Por exemplo, uma fase com JOIN+ no nome significa que a fase executa uma operação de junção e outros passos importantes.
As linhas que ligam as etapas representam a troca de dados intermediários entre as etapas. O BigQuery armazena os dados intermediários na memória de mistura enquanto as fases estão a ser executadas. Os números nas extremidades indicam o número estimado de linhas trocadas entre as fases. A quota de memória de mistura está correlacionada com o número de espaços atribuídos à conta. Se a quota de aleatorização for excedida, a memória de aleatorização pode ser transferida para o disco e fazer com que o desempenho das consultas diminua drasticamente.
Veja estatísticas de desempenho de consultas
Consola
Siga estes passos para ver as estatísticas de desempenho das consultas:
Abra a página do BigQuery na Google Cloud consola.
No painel esquerdo, clique em Explorador:

Se não vir o painel do lado esquerdo, clique em Expandir painel do lado esquerdo para o abrir.
No painel Explorador, clique em Histórico de tarefas.
Clique em Histórico pessoal ou Histórico do projeto.
Na lista de tarefas, identifique a tarefa de consulta que lhe interessa. Clique em Ações e escolha Ver tarefa no editor.
Selecione o separador Gráfico de execução para ver uma representação gráfica de cada fase da consulta:
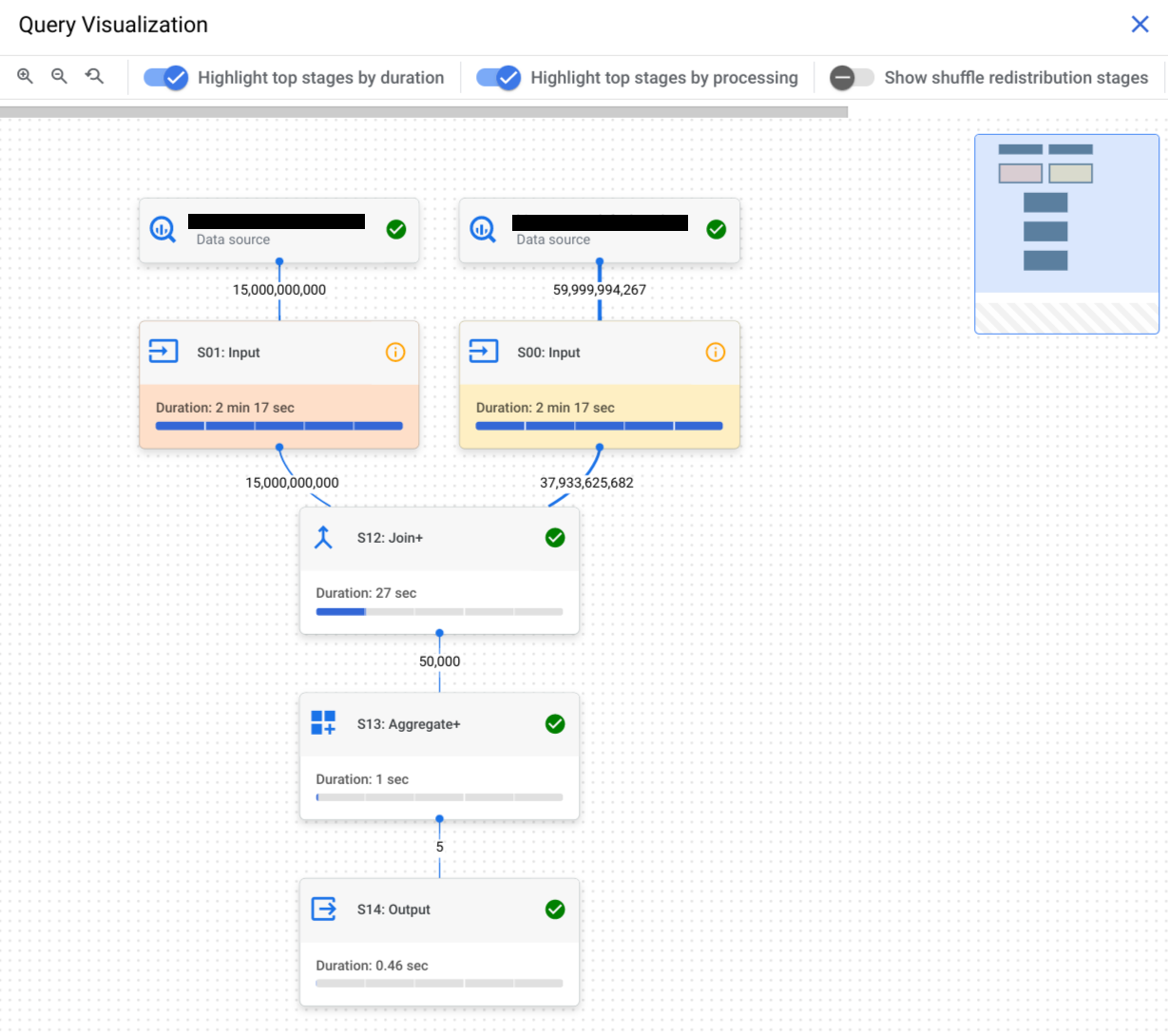
Para determinar se uma fase da consulta tem estatísticas de desempenho, observe o ícone apresentado. As fases que têm um ícone de informações têm estatísticas de desempenho. As fases que têm um ícone de verificação não têm.
Clique numa fase para abrir o painel de detalhes da fase, onde pode ver as seguintes informações:
- Informações do plano de consulta para a fase.
- Os passos executados na fase.
- Quaisquer estatísticas de desempenho aplicáveis.
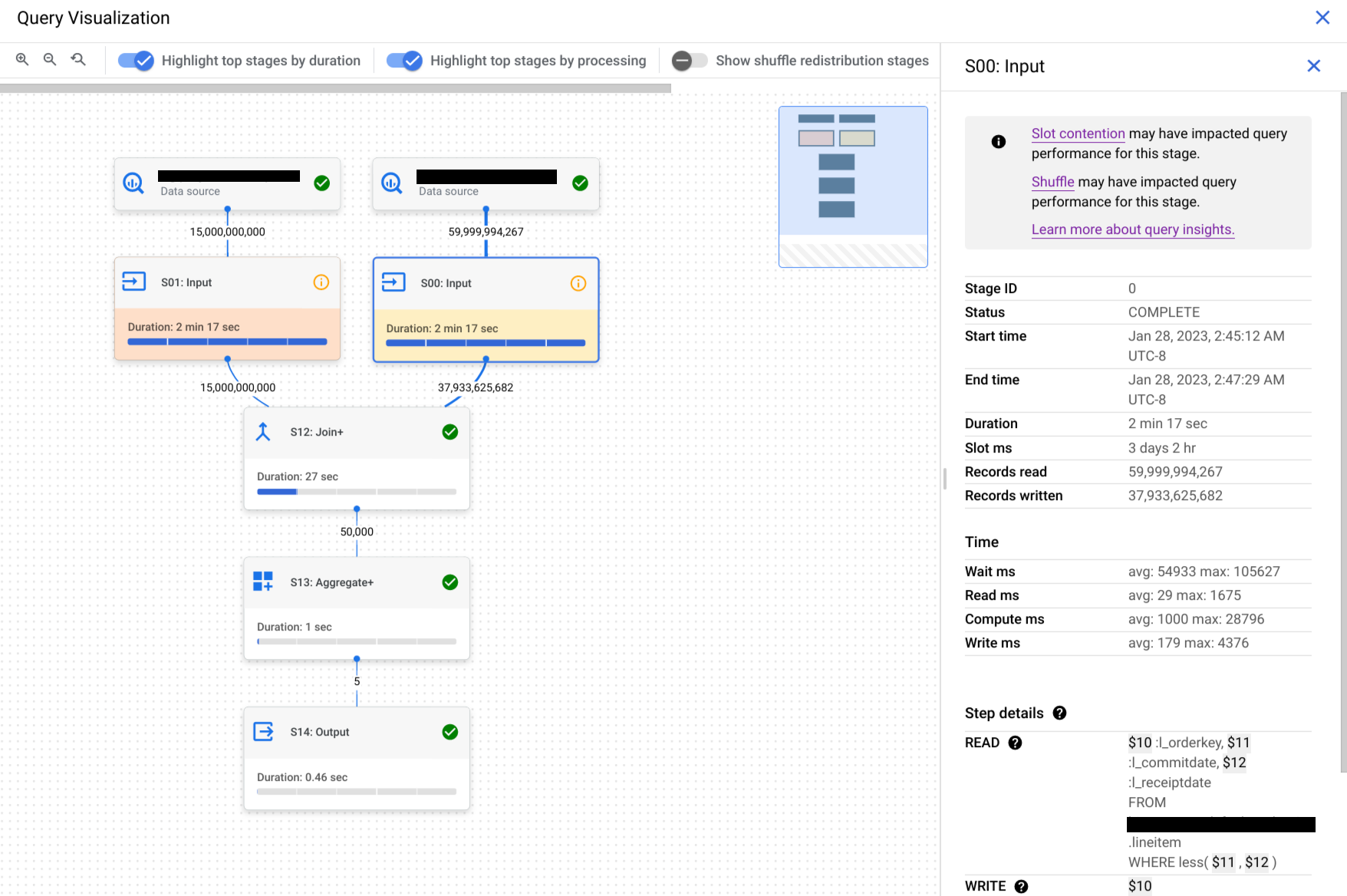
Opcional: se estiver a inspecionar uma consulta em execução, clique em Sincronizar para atualizar o gráfico de execução de modo a refletir o estado atual da consulta.

Opcional: para realçar as principais fases pela duração das fases no gráfico, clique em Realçar principais fases por duração.

Opcional: para realçar as principais fases por tempo de intervalo usado no gráfico, clique em Realçar principais fases por processamento.

Opcional: para incluir fases de redistribuição aleatória no gráfico, clique em Mostrar fases de redistribuição aleatória.

Use esta opção para mostrar as fases de repartição e união ocultadas no gráfico de execução predefinido.
As fases de repartição e união são introduzidas enquanto a consulta está a ser executada e são usadas para melhorar a distribuição de dados entre os trabalhadores que processam a consulta. Uma vez que estas fases não estão relacionadas com o texto da consulta, são ocultadas para simplificar o plano de consulta apresentado.
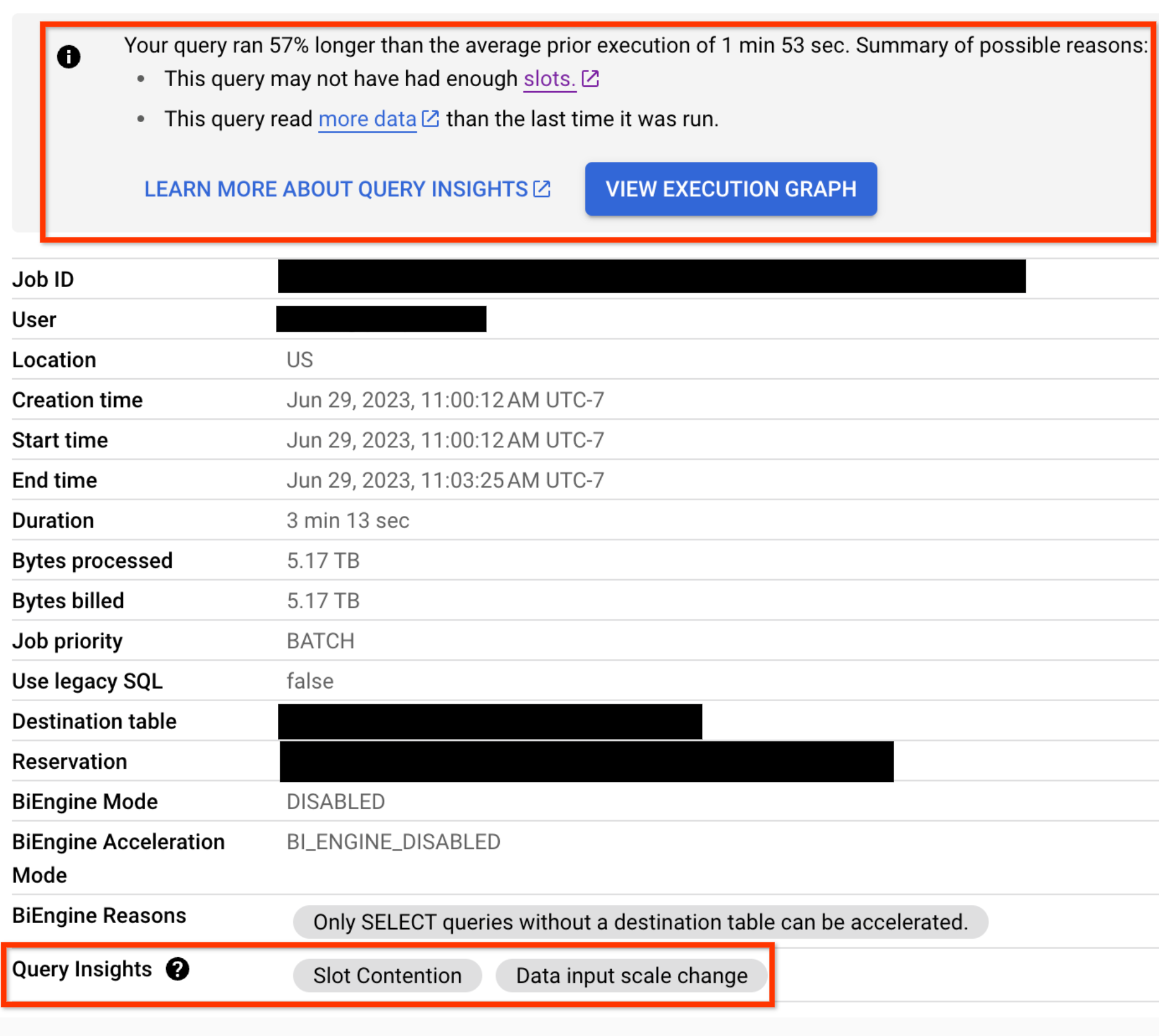
Para qualquer consulta que tenha problemas de regressão de desempenho, as estatísticas de desempenho também são apresentadas no separador Informações do trabalho para a consulta:
SQL
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, introduza a seguinte declaração:
SELECT `bigquery-public-data`.persistent_udfs.job_url( project_id || ':us.' || job_id) AS job_url, query_info.performance_insights FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS_BY_PROJECT WHERE DATE(creation_time) >= CURRENT_DATE - 30 -- scan 30 days of query history AND job_type = 'QUERY' AND state = 'DONE' AND error_result IS NULL AND statement_type != 'SCRIPT' AND EXISTS ( -- Only include queries which had performance insights SELECT 1 FROM UNNEST( query_info.performance_insights.stage_performance_standalone_insights ) WHERE slot_contention OR insufficient_shuffle_quota UNION ALL SELECT 1 FROM UNNEST( query_info.performance_insights.stage_performance_change_insights ) WHERE input_data_change.records_read_diff_percentage IS NOT NULL );
Clique em Executar.
Para mais informações sobre como executar consultas, consulte o artigo Execute uma consulta interativa.
API
Pode obter estatísticas de desempenho das consultas num formato não gráfico chamando o método da API jobs.list e inspecionando as informações JobStatistics2 devolvidas.
Interprete as estatísticas de desempenho das consultas
Use esta secção para saber mais sobre o que significam as estatísticas de desempenho e como resolvê-las.
As estatísticas de desempenho destinam-se a dois públicos:
Analistas: executam consultas num projeto. Tem interesse em saber por que motivo uma consulta que executou anteriormente está a ser executada inesperadamente mais lentamente e em receber sugestões sobre como melhorar o desempenho de uma consulta. Tem as autorizações descritas em Autorizações necessárias.
Administradores do data lake ou do armazém de dados: gere os recursos e as reservas do BigQuery da sua organização. Tem as autorizações associadas à função de administrador do BigQuery.
Cada uma das secções seguintes fornece orientações sobre o que pode fazer para resolver uma estatística de desempenho que recebe, com base na função que desempenha.
Contenção de espaços
Quando executa uma consulta, o BigQuery tenta dividir o trabalho necessário para a consulta em tarefas. Uma tarefa é uma única fatia de dados que é introduzida e produzida numa fase. Um único espaço seleciona uma tarefa e executa essa fatia de dados para a fase. Idealmente, os slots do BigQuery executam estas tarefas em paralelo para alcançar um elevado desempenho. A contenção de espaços ocorre quando a sua consulta tem muitas tarefas prontas para começar a ser executadas, mas o BigQuery não consegue obter espaços disponíveis suficientes para as executar.
O que fazer se for um analista
Reduza os dados que está a processar na sua consulta seguindo as orientações em Reduza os dados processados nas consultas.
O que fazer se for administrador
Aumente a disponibilidade de ranhuras ou diminua a utilização de ranhuras tomando as seguintes medidas:
- Se usar os preços a pedido do BigQuery, as suas consultas usam um conjunto de slots partilhado. Pondere mudar para os preços de análise baseados na capacidade comprando reservas. As reservas permitem-lhe reservar espaços dedicados para as consultas da sua organização.
Se estiver a usar reservas do BigQuery, certifique-se de que existem slots suficientes na reserva atribuída ao projeto que estava a executar a consulta. A reserva pode não ter espaços suficientes nestes cenários:
- Existem outras tarefas que estão a consumir as vagas de reserva. Pode usar os gráficos de recursos de administrador para ver como a sua organização está a usar a reserva.
- A reserva não tem slots atribuídos suficientes para executar consultas com rapidez suficiente. Pode usar o estimador de ranhuras para obter uma estimativa da dimensão das suas reservas para processar eficientemente as tarefas das suas consultas.
Para o resolver, pode experimentar uma das seguintes soluções:
- Adicione mais espaços (espaços de base ou espaços de reserva máximos) a essa reserva.
- Crie uma reserva adicional e atribua-a ao projeto que está a executar a consulta.
- Distribua as consultas que exigem muitos recursos ao longo do tempo numa reserva ou em diferentes reservas.
Certifique-se de que as tabelas que está a consultar estão agrupadas. O clustering ajuda a garantir que o BigQuery consegue ler rapidamente colunas com dados correlacionados.
Certifique-se de que as tabelas que está a consultar estão divididas em partições. Para tabelas não particionadas, o BigQuery lê a tabela inteira. A partição das tabelas ajuda a garantir que consulta apenas o subconjunto das tabelas nas quais tem interesse.
Quota de aleatorização insuficiente
Antes de executar a consulta, o BigQuery divide a lógica da consulta em fases. Os slots do BigQuery executam as tarefas para cada fase. Quando um espaço conclui a execução das tarefas de uma fase, armazena os resultados intermédios na mistura. As fases subsequentes na sua consulta leem dados da mistura aleatória para continuar a execução da consulta. A quota de aleatorização insuficiente ocorre quando tem mais dados que precisam de ser escritos na aleatorização do que a capacidade de aleatorização disponível.
O que fazer se for um analista
Tal como na contenção de slots, reduzir a quantidade de dados que a sua consulta processa pode reduzir a utilização da mistura. Para o fazer, siga as orientações em Reduza os dados processados nas consultas.
Determinadas operações em SQL tendem a fazer uma utilização mais extensiva da mistura aleatória, especialmente as operações JOIN e as cláusulas GROUP BY.
Sempre que possível, reduzir a quantidade de dados nestas operações pode reduzir a utilização da mistura.
O que fazer se for administrador
Reduza a contenção da quota de aleatorização tomando as seguintes medidas:
- Tal como na contenção de slots, se usar os preços a pedido do BigQuery, as suas consultas usam um conjunto de slots partilhado. Pondere mudar para os preços de análise baseados na capacidade comprando reservas. As reservas oferecem-lhe horários dedicados e capacidade de aleatorização para as consultas dos seus projetos.
Se estiver a usar reservas do BigQuery, os slots incluem capacidade de mistura dedicada. Se a sua reserva estiver a executar algumas consultas que usam extensivamente a aleatorização, isto pode fazer com que outras consultas executadas em paralelo não tenham capacidade de aleatorização suficiente. Pode identificar os trabalhos que usam extensivamente a capacidade de aleatorização consultando a coluna
period_shuffle_ram_usage_rationa vistaINFORMATION_SCHEMA.JOBS_TIMELINE.Para o resolver, pode experimentar uma ou mais das seguintes soluções:
- Adicionar mais horários a essa reserva.
- Crie uma reserva adicional e atribua-a ao projeto que está a executar a consulta.
- Distribua as consultas com grande volume de aleatorização ao longo do tempo numa reserva ou em diferentes reservas.
Alteração da escala de entrada de dados
A obtenção desta estatística de desempenho indica que a sua consulta está a ler, pelo menos, 50% mais dados para uma determinada tabela de entrada do que na última vez que executou a consulta. Pode usar o histórico de alterações da tabela para ver se o tamanho de alguma das tabelas usadas na consulta aumentou recentemente.
O que fazer se for um analista
Reduza os dados que está a processar na sua consulta seguindo as orientações em Reduza os dados processados nas consultas.
Junção de elevada cardinalidade
Quando uma consulta contém uma união com chaves não únicas em ambos os lados da união, o tamanho da tabela de saída pode ser consideravelmente maior do que o tamanho de qualquer uma das tabelas de entrada. Esta estatística indica que a proporção de linhas de saída para linhas de entrada é elevada e oferece informações sobre estas contagens de linhas.
O que fazer se for um analista
Verifique as condições de junção para confirmar se o aumento no tamanho da tabela de saída é esperado. Evite usar junções cruzadas.
Se tiver de usar uma junção cruzada, experimente usar uma cláusula GROUP BY para pré-agregar os resultados ou use uma função de janela. Para mais informações, consulte o artigo
Reduza os dados antes de usar um JOIN.
Desvio de partição
Para enviar feedback ou pedir apoio técnico relativamente a esta funcionalidade, envie um email para
bq-query-inspector-feedback@google.com.
A distribuição de dados distorcida pode fazer com que as consultas sejam executadas lentamente. Quando uma consulta está a ser executada, o BigQuery divide os dados em pequenas partições para processamento paralelo. A distorção ocorre quando os dados são distribuídos de forma desigual por estas partições, muitas vezes devido a valores que ocorrem com frequência nas chaves de junção ou de agrupamento, o que faz com que algumas partições sejam significativamente maiores do que outras. Uma vez que um único espaço processa uma partição inteira e não pode partilhar o trabalho, uma partição demasiado grande pode tornar o processamento mais lento, causar erros de "recurso excedido" e, em casos extremos, falhar o espaço.
Enquanto executa uma operação JOIN, o BigQuery divide os dados
nos lados esquerdo e direito da união com base nas chaves de união. Se uma partição for demasiado grande, o BigQuery tenta reequilibrar os dados. Se a
distribuição desigual for demasiado grave para ser totalmente reequilibrada, é adicionada uma estatística detalhada de distribuição desigual da partição à
fase JOIN no gráfico de execução.
Identifique a assimetria de partições
Use o separador Gráfico de execução no BigQuery Studio para saber em que fase da consulta está a ocorrer a distorção da partição. A estatística é sinalizada no palco. A partir dos detalhes da fase, pode determinar a parte relevante do texto da consulta e as tabelas que estão a ser processadas. Para mais informações, consulte o artigo Compreenda os passos com texto de consulta.
Exemplo
A consulta seguinte junta as informações do repositório às informações do ficheiro. A variação pode ocorrer se alguns repositórios tiverem muito mais ficheiros do que outros.
SELECT r.repo_name, COUNT(f.path) AS file_count
FROM `bigquery-public-data.github_repos.sample_repos` AS r
JOIN `bigquery-public-data.github_repos.sample_files` AS f
ON r.repo_name = f.repo_name
WHERE r.watch_count > 10
GROUP BY r.repo_name
A chave de junção é repo_name. Na tabela sample_repos, espera-se que repo_name seja único. No entanto, na tabela sample_files, repo_name pode aparecer muitas vezes. Se alguns valores de repo_name aparecerem com uma frequência desproporcionada em sample_files, isto cria uma distorção dos dados.
Para confirmar se existe uma distorção dos dados, analise a distribuição da chave de junção na tabela maior (sample_files neste caso). Execute a seguinte consulta para avaliar a distribuição de repo_name:
SELECT repo_name, COUNT(*) AS occurrences
FROM `bigquery-public-data.github_repos.sample_files`
GROUP BY repo_name
ORDER BY occurrences DESC
Para tabelas muito grandes, use a função APPROX_TOP_COUNT
para estimar eficientemente os valores mais frequentes.
SELECT APPROX_TOP_COUNT(repo_name, 100)
FROM `bigquery-public-data.github_repos.sample_files`
Se as contagens dos principais valores forem ordens de magnitude superiores às dos outros, existe uma distorção dos dados.
Mitigue a distorção da partição
Pode usar as seguintes estratégias para resolver a distorção da partição:
- Filtre os dados antecipadamente. Reduza a quantidade de dados processados aplicando filtros o mais cedo possível na sua consulta. Isto pode diminuir o número de linhas associadas a chaves com desvio antes de chegarem a operações como
JOINouGROUP BY. Divida a consulta para isolar as teclas com desvio. Se a distorção for causada por alguns valores de chave específicos, semelhantes ao campo
repo_nameno exemplo anterior, considere dividir a consulta. Processe os dados das chaves enviesadas separadamente do resto dos dados e, em seguida, combine os resultados comUNION ALL.Exemplo: isolar uma chave usada com frequência.
-- Query for the skewed key SELECT r.repo_name, COUNT(f.path) AS file_count FROM `bigquery-public-data.github_repos.sample_repos` AS r JOIN `bigquery-public-data.github_repos.sample_files` AS f ON r.repo_name = f.repo_name WHERE r.watch_count > 10 AND r.repo_name = 'popular_repo' GROUP BY r.repo_name UNION ALL -- Query for all other keys SELECT r.repo_name, COUNT(f.path) AS file_count FROM `bigquery-public-data.github_repos.sample_repos` AS r JOIN `bigquery-public-data.github_repos.sample_files` AS f ON r.repo_name = f.repo_name WHERE r.watch_count > 10 AND r.repo_name != 'popular_repo' GROUP BY r.repo_nameTrate os valores
NULLe predefinidos: uma causa comum de distorção é um grande número de linhas com valoresNULLou de strings vazias nas colunas principais. Se não precisar destas linhas para análise, filtre-as com uma cláusulaWHEREantes deJOINouGROUP BY.Reordenar operações: em consultas com várias junções, a ordem pode ser importante. Se possível, faça junções que reduzam significativamente as contagens de linhas mais cedo na consulta.
Use funções aproximadas: para agregações em dados enviesados, considere se um resultado aproximado é aceitável. As funções como
APPROX_COUNT_DISTINCTsão mais tolerantes à distorção de dados do que as funções exatas comoCOUNT(DISTINCT).
Interprete as informações da fase de consulta
Além de usar as estatísticas de desempenho de consultas, também pode usar as seguintes diretrizes quando estiver a rever os detalhes da fase de consulta para ajudar a determinar se existe um problema com uma consulta:
- Se o valor Wait ms de uma ou mais fases for elevado em comparação com as execuções anteriores da consulta:
- Verifique se tem ranhuras suficientes disponíveis para acomodar a sua carga de trabalho. Caso contrário, faça o equilíbrio de carga quando executar consultas com utilização intensiva de recursos para que não compitam entre si.
- Se o valor de Wait ms for superior ao que tem sido para apenas uma fase, consulte a fase anterior para ver se foi introduzido um gargalo aí. Aspetos como alterações substanciais aos dados ou ao esquema das tabelas envolvidas na consulta podem afetar o desempenho da consulta.
- Se o valor de Shuffle output bytes para uma fase for elevado em comparação com as execuções anteriores da consulta ou com uma fase anterior, avalie os passos processados nessa fase para ver se algum cria quantidades inesperadamente grandes de dados. Uma causa comum para isto é quando um passo processa um
INNER JOINem que existem chaves duplicadas em ambos os lados da junção. Esta ação pode devolver uma quantidade inesperadamente grande de dados. - Use o gráfico de execução para analisar as principais fases por duração e processamento. Considere a quantidade de dados que produzem e se é proporcional ao tamanho das tabelas referenciadas na consulta. Se não for o caso, reveja os passos nessas fases para ver se algum deles pode produzir uma quantidade inesperada de dados provisórios.
O que se segue?
- Reveja as diretrizes de otimização de consultas para ver sugestões sobre como melhorar o desempenho das consultas.