Outils d'analyse programmatiques
Ce document décrit plusieurs manières d'écrire et d'exécuter du code pour analyser des données gérées dans BigQuery.
Bien que SQL soit un langage de requête puissant, les langages de programmation tels que Python, Java ou R fournissent des syntaxes et de nombreuses fonctions statistiques intégrées que les analystes de données pourraient trouver plus expressives et plus faciles à manipuler pour certains types d'opérations d'analyse de données.
De même, bien que les tableurs soient largement utilisés, d'autres environnements de programmation, tels que les notebooks, peuvent parfois offrir un environnement plus flexible pour effectuer certaines opérations d'analyse et d'exploration de données complexes.
Notebooks Colab Enterprise
Vous pouvez utiliser des notebooks Colab Enterprise dans BigQuery pour effectuer des workflows d'analyse et de machine learning (ML) à l'aide de SQL, de Python et d'autres packages et d'API courants. Notebooks propose une collaboration et une gestion améliorées avec les options suivantes :
- Partager des notebooks avec des utilisateurs et des groupes spécifiques à l'aide d'Identity and Access Management (IAM)
- Examiner l'historique des versions de notebook.
- Rétablir ou créer une branche à partir de versions précédentes d'un notebook
Les notebooks sont des composants de code BigQuery Studio fournis par Dataform, mais ils ne sont pas visibles dans Dataform. Les requêtes enregistrées sont également des éléments de code. Tous les éléments de code sont stockés dans une région par défaut. La mise à jour de la région par défaut modifie la région pour tous les composants de code créés par la suite.
Les fonctionnalités de notebook ne sont disponibles que dans la console Google Cloud .
Les notebooks dans BigQuery offrent les avantages suivants :
- Les DataFrames BigQuery sont intégrés aux notebooks, aucune configuration n'est requise. BigQuery DataFrames est une API Python que vous pouvez utiliser pour analyser des données BigQuery à grande échelle à l'aide de pandas DataFrame et de scikit-learn.
- Développement de code assisté par l'IA générative Gemini.
- Saisie semi-automatique des instructions SQL, comme dans l'éditeur BigQuery.
- Possibilité d'enregistrer, de partager et de gérer des versions de notebooks.
- Possibilité d'utiliser matplotlib, seaborn et d'autres bibliothèques populaires pour visualiser des données à tout moment de votre workflow.
- La possibilité d'écrire et d'exécuter du code SQL dans une cellule pouvant référencer des variables Python de votre notebook.
- Visualisation interactive des DataFrames permettant l'agrégation et la personnalisation.
Vous pouvez commencer à utiliser les notebooks en vous servant des modèles de la galerie de notebooks. Pour en savoir plus, consultez Créer un notebook à l'aide de la galerie de notebooks.
BigQuery DataFrames
BigQuery DataFrames est un ensemble de bibliothèques Python Open Source qui vous permettent d'exploiter le traitement des données BigQuery à l'aide d'API Python connues. BigQuery DataFrames met en œuvre les API pandas et scikit-learn en envoyant le traitement à BigQuery via la conversion SQL. Cette conception vous permet d'utiliser BigQuery pour explorer et traiter des téraoctets de données, mais aussi pour entraîner des modèles de ML, le tout avec les API Python.
BigQuery DataFrames offre les avantages suivants :
- Plus de 750 API pandas et scikit-learn mises en œuvre via une conversion SQL transparente vers les API BigQuery et BigQuery ML
- Exécution différée des requêtes pour améliorer les performances
- Extension des transformations de données à l'aide de fonctions Python définies par l'utilisateur pour permettre de traiter des données dans le cloud. Ces fonctions sont automatiquement déployées en tant que fonctions distantes BigQuery.
- L'intégration à Vertex AI afin d'utiliser des modèles Gemini pour la génération de texte
Autres solutions d'analyse programmatique
Les solutions d'analyse programmatiques suivantes sont également disponibles dans BigQuery.
Notebooks Jupyter
Jupyter est une application Web Open Source qui permet de publier des notebooks contenant du code en direct, des descriptions textuelles et des visualisations. Les data scientists, les spécialistes du machine learning et les étudiants utilisent couramment cette plate-forme pour des tâches telles que le nettoyage et la transformation de données, la simulation numérique, la modélisation statistique, la visualisation de données et le ML.
Les notebooks Jupyter reposent sur le kernel IPython, un puissant shell interactif qui est capable d'interagir directement avec BigQuery à l'aide des commandes magiques IPython pour BigQuery. Vous pouvez également accéder à BigQuery à partir de vos instances de notebooks Jupyter en installant l'une des bibliothèques clientes BigQuery disponibles. Vous pouvez visualiser des données SIG BigQuery à l'aide de notebooks Jupyter via l'extension GeoJSON. Pour plus de détails sur l'intégration de BigQuery, reportez-vous au tutoriel Visualiser des données BigQuery dans un notebook Jupyter.
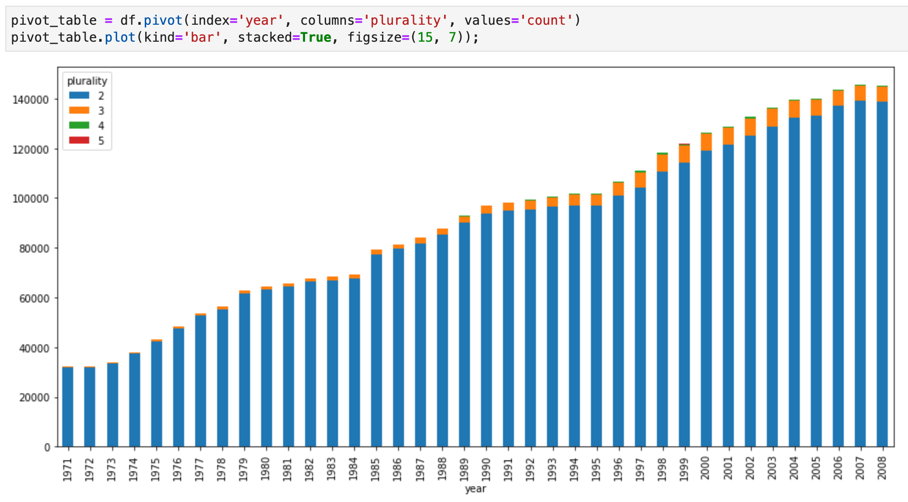
JupyterLab est une interface utilisateur Web permettant de gérer des documents et activités, par exemple des notebooks Jupyter, des éditeurs de texte, des terminaux et des composants personnalisés. Avec JupyterLab, vous pouvez organiser plusieurs documents et activités côte à côte dans votre espace de travail à l'aide d'onglets et de séparateurs.
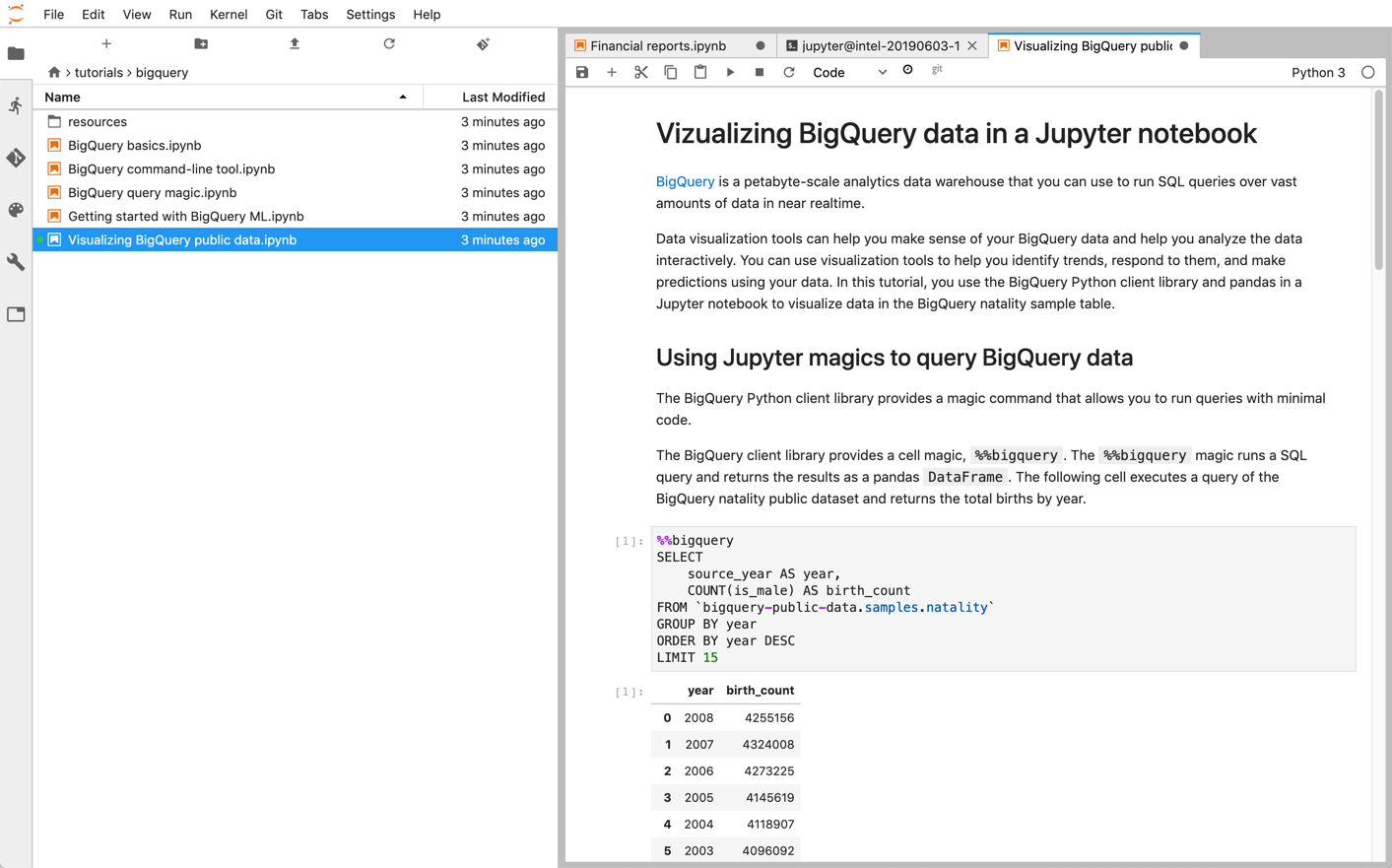
Vous pouvez déployer des notebooks Jupyter et des environnements JupyterLab surGoogle Cloud à l'aide de l'un des produits suivants :
- Les instances Vertex AI Workbench, un service offrant un environnement JupyterLab intégré dans lequel les développeurs de solutions de machine learning et les data scientists peuvent utiliser certains des derniers frameworks de data science et de machine learning. Vertex AI Workbench est intégré à d'autres produits de données Google Cloud tels que BigQuery, ce qui facilite le passage de l'ingestion de données au prétraitement et à l'exploration, puis à la modélisation de l'entraînement et du déploiement. Pour en savoir plus, consultez la présentation des instances Vertex AI Workbench.
- Dataproc, un service cloud rapide, convivial et entièrement géré qui vous permet d'exécuter des clusters Apache Spark et Apache Hadoop de manière simple et économique. Vous pouvez installer des notebooks Jupyter et JupyterLab sur un cluster Dataproc à l'aide du composant Jupyter facultatif. Ce composant fournit un noyau Python permettant d'exécuter du code PySpark. Par défaut, Dataproc configure automatiquement les notebooks pour les enregistrer dans Cloud Storage, ce qui permet aux autres clusters d'accéder aux mêmes fichiers. Lorsque vous migrez vos notebooks existants vers Dataproc, vérifiez que leurs dépendances sont bien prises en compte par les versions Cloud Dataproc compatibles. Si vous avez besoin d'installer un logiciel personnalisé, vous pouvez envisager de créer une image personnalisée Dataproc, d'écrire vos propres actions d'initialisation ou de spécifier des conditions requises personnalisées pour le package python. Pour commencer, consultez le tutoriel Installer et exécuter un notebook Jupyter sur un cluster Dataproc.
Apache Zeppelin
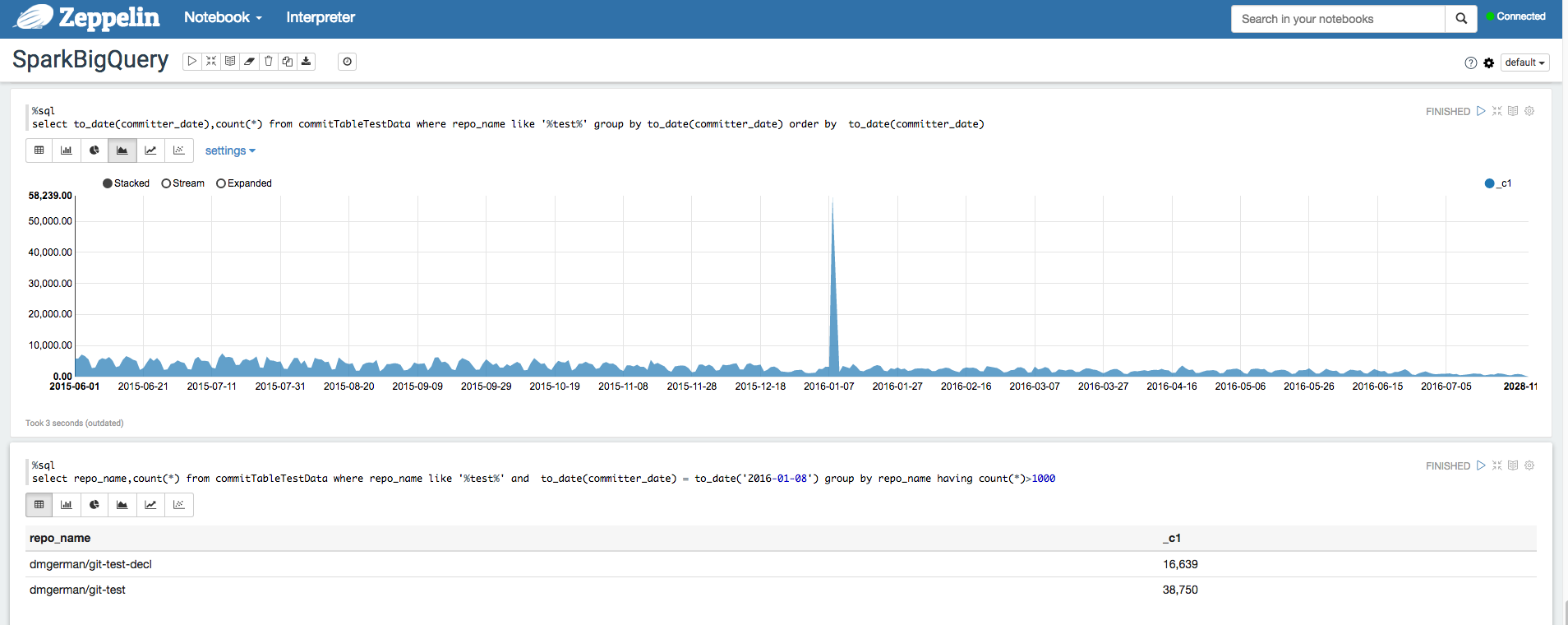
Apache Zeppelin est un projet Open Source qui propose des notebooks Web pour l'analyse de données.
Vous pouvez déployer une instance d'Apache Zeppelin sur Dataproc en installant le composant Zeppelin facultatif.
Par défaut, les notebooks sont enregistrés dans Cloud Storage, dans le bucket de préproduction Dataproc (spécifié par l'utilisateur ou créé automatiquement lors de la création du cluster). Vous pouvez modifier l'emplacement du notebook en ajoutant la propriété zeppelin:zeppelin.notebook.gcs.dir lors de la création du cluster. Pour plus d'informations sur l'installation et la configuration d'Apache Zeppelin, consultez le guide du composant Zeppelin.
Pour obtenir un exemple, consultez la page Analyser des ensembles de données BigQuery à l'aide de l'interpréteur BigQuery pour Apache Zeppelin.
Apache Hadoop, Apache Spark et Apache Hive
Dans le cadre de la migration de votre pipeline d'analyse de données, il se peut que vous souhaitiez migrer certains anciens jobs Apache Hadoop, Apache Spark et Apache Hive qui doivent traiter directement des données hébergées dans votre entrepôt de données. Par exemple, vous pouvez avoir besoin d'extraire des caractéristiques pour vos charges de travail de machine learning.
Dataproc vous permet de déployer des clusters Hadoop et Spark entièrement gérés de manière efficace et économique. Dataproc s'intègre aux connecteurs BigQuery Open Source. Ces connecteurs utilisent l'API BigQuery Storage, qui transmet les données en parallèle directement depuis BigQuery via gRPC.
Lorsque vous migrez vos charges de travail Hadoop et Spark existantes vers Dataproc, vous pouvez vérifier que les dépendances des charges de travail sont bien prises en compte par les versions de Dataproc compatibles. Si vous avez besoin d'installer un logiciel personnalisé, vous pouvez envisager de créer une image Dataproc personnalisée, d'écrire vos propres actions d'initialisation ou de spécifier des conditions requises personnalisées pour le package Python.
Pour commencer, consultez les guides de démarrage rapide de Dataproc et les exemples de code de connecteur BigQuery.
Apache Beam
Apache Beam est un framework Open Source qui fournit de nombreuses primitives de fenêtrage et d'analyse de sessions, ainsi qu'un écosystème de connecteurs de sources et de récepteurs, parmi lesquels un connecteur pour BigQuery. Apache Beam permet de transformer et d'enrichir des données en mode flux (temps réel) et lot (historique) avec un niveau identique de fiabilité et d'expressivité.
Dataflow est un service entièrement géré permettant d'exécuter des jobs Apache Beam à grande échelle. L'approche sans serveur de Dataflow permet d'éliminer les coûts opérationnels grâce à la gestion automatique des besoins de performances, de scaling, de disponibilité, de sécurité et de conformité. Vous pouvez ainsi vous concentrer sur la programmation plutôt que sur la gestion des clusters de serveurs.
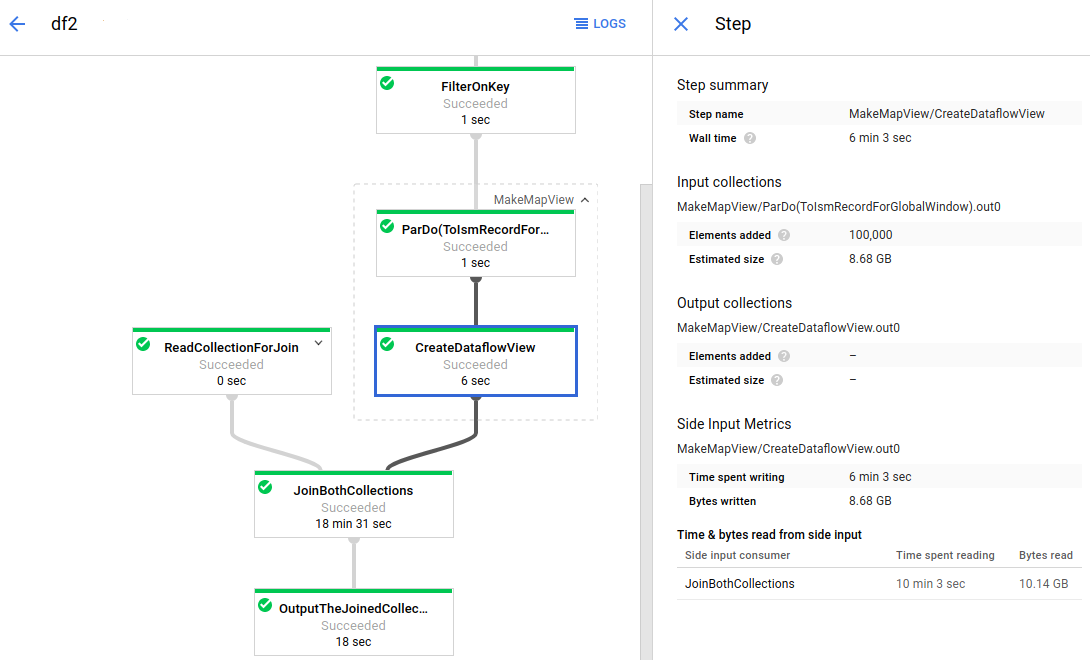
Pour envoyer des tâches Dataflow, vous pouvez utiliser l'interface de ligne de commande, le SDK Java ou le SDK Python.
Si vous souhaitez migrer vos requêtes et pipelines de données depuis d'autres frameworks vers Apache Beam et Dataflow, consultez la section sur le modèle de programmation Apache Beam et la documentation Dataflow officielle.
Autres ressources
BigQuery offre un large éventail de bibliothèques clientes dans plusieurs langages de programmation, tels que Java, Go, Python, JavaScript, PHP et Ruby. Certains frameworks d'analyse de données tels que pandas fournissent des plug-ins qui interagissent directement avec BigQuery. Pour obtenir des exemples pratiques, consultez le tutoriel Visualiser des données BigQuery dans un notebook Jupyter.
Enfin, si vous préférez écrire vos programmes dans un environnement de shell, vous pouvez utiliser l'outil de ligne de commande bq.