Introduzione a BigQuery Omni
Con BigQuery Omni, puoi eseguire analisi BigQuery sui dati archiviati in Amazon Simple Storage Service (Amazon S3) o Azure Blob Storage utilizzando le tabelle BigLake.
Molte organizzazioni archiviano i dati in più cloud pubblici. Spesso questi dati finiscono per essere isolati in silos, perché è difficile ottenere insight trasversali su tutti i dati. Vuoi poter analizzare i dati con uno strumento di dati multicloud che sia economico, veloce e non crei un overhead aggiuntivo di governance dei dati decentralizzata. Utilizzando BigQuery Omni, riduciamo questi attriti con un'interfaccia unificata.
Per eseguire l'analisi BigQuery sui dati esterni, devi prima connetterti ad Amazon S3 o ad Archiviazione BLOB. Se vuoi eseguire query su dati esterni, devi creare una tabella BigLake che faccia riferimento ai dati di Amazon S3 o Blob Storage.
Strumenti BigQuery Omni
Puoi utilizzare i seguenti strumenti BigQuery Omni per eseguire analisi BigQuery sui tuoi dati esterni:
- Join cross-cloud: esegui una query direttamente da una regione BigQuery che può unire i dati di una regione BigQuery Omni.
- Viste materializzate cross-cloud: utilizza le repliche delle viste materializzate per replicare continuamente i dati dalle regioni BigQuery Omni. Supporta il filtro dei dati.
- Trasferimento cross-cloud utilizzando
SELECT: esegui una query utilizzando l'istruzioneCREATE TABLE AS SELECToINSERT INTO SELECTin una regione BigQuery Omni e sposta il risultato in una regione BigQuery. - Trasferimento cross-cloud utilizzando
LOAD: utilizza le istruzioniLOAD DATAper caricare i dati direttamente da Amazon Simple Storage Service (Amazon S3) o Archiviazione BLOB di Azure in BigQuery
La tabella seguente descrive le funzionalità chiave di ogni strumento cross-cloud:
| Join cross-cloud | Vista materializzata cross-cloud | Trasferimento cross-cloud utilizzando SELECT |
Trasferimento cross-cloud utilizzando LOAD |
|
|---|---|---|---|---|
| Utilizzo suggerito | Esegui query sui dati esterni per un utilizzo una tantum, in cui puoi unirli a tabelle locali o unire dati tra due regioni BigQuery Omni diverse, ad esempio tra le regioni AWS e Azure Blob Storage. Utilizza i join cross-cloud se i dati non sono di grandi dimensioni e se la memorizzazione nella cache non è un requisito fondamentale | Configura query ripetute o pianificate per trasferire continuamente i dati esterni in modo incrementale, dove la memorizzazione nella cache è un requisito fondamentale. Ad esempio, per gestire una dashboard | Esegui query sui dati esterni per un utilizzo una tantum, da una regione BigQuery Omni a una regione BigQuery, dove i controlli manuali come la memorizzazione nella cache e l'ottimizzazione delle query sono un requisito fondamentale e se utilizzi query complesse non supportate da join cross-cloud o viste materializzate cross-cloud | Esegui la migrazione di set di dati di grandi dimensioni così come sono, senza la necessità di filtrarli, utilizzando query pianificate per spostare i dati non elaborati |
| Supporta il filtraggio prima dello spostamento dei dati | Sì. Si applicano limiti a determinati operatori di query. Per ulteriori informazioni, vedi Limitazioni del join cross-cloud. | Sì. Si applicano limiti a determinati operatori di query, come le funzioni di aggregazione e l'operatore UNION |
Sì. Nessun limite per gli operatori di query | No |
| Limitazioni delle dimensioni del trasferimento | 60 GB per trasferimento (ogni sottoquery a una regione remota produce un trasferimento) | Nessun limite | 60 GB per trasferimento (ogni sottoquery a una regione remota produce un trasferimento) | Nessun limite |
| Compressione del trasferimento dei dati | Compressione del cavo | A colonne | Compressione del cavo | Compressione del cavo |
| Memorizzazione nella cache | Non supportata | Supportato con tabelle abilitate alla cache con viste materializzate | Non supportata | Non supportata |
| Prezzi del traffico in uscita | Costo del traffico in uscita da AWS e intercontinentale | Costo del traffico in uscita da AWS e intercontinentale | Costo del traffico in uscita da AWS e intercontinentale | Costo del traffico in uscita da AWS e intercontinentale |
| Utilizzo di Compute per il trasferimento dei dati | Utilizza slot nella regione di origine AWS o Azure Blob Storage (prenotazione o on demand) | Non utilizzata | Utilizza slot nella regione di origine AWS o Azure Blob Storage (prenotazione o on demand) | Non utilizzata |
| Utilizzo del calcolo per il filtraggio | Utilizza slot nella regione di origine AWS o Azure Blob Storage (prenotazione o on demand) | Utilizza gli slot nella regione AWS o Azure Blob Storage di origine (prenotazione o on demand) per il calcolo di viste materializzate e metadati locali | Utilizza slot nella regione di origine AWS o Azure Blob Storage (prenotazione o on demand) | Non utilizzata |
| Trasferimento incrementale | Non supportata | Supportato per le viste materializzate non aggregate | Non supportata | Non supportata |
Puoi anche prendere in considerazione le seguenti alternative per trasferire i dati da Amazon Simple Storage Service (Amazon S3) o Azure Blob Storage a Google Cloud:
- Storage Transfer Service: trasferisci dati tra l'archiviazione di oggetti e file su Google Cloud e Amazon Simple Storage Service (Amazon S3) o Azure Blob Storage.
- BigQuery Data Transfer Service: configura il trasferimento automatico dei dati in BigQuery in base a pianificazioni gestite. Supporta una varietà di origini ed è adatto alla migrazione dei dati. BigQuery Data Transfer Service non supporta il filtraggio.
Architettura
L'architettura di BigQuery separa il calcolo dall'archiviazione, consentendo a BigQuery di fare lo scale out in base alle esigenze per gestire carichi di lavoro molto grandi. BigQuery Omni estende questa architettura eseguendo il motore di query BigQuery in altri cloud. Di conseguenza, non devi spostare fisicamente i dati nell'archivio BigQuery. Il trattamento avviene dove si trovano già i dati.
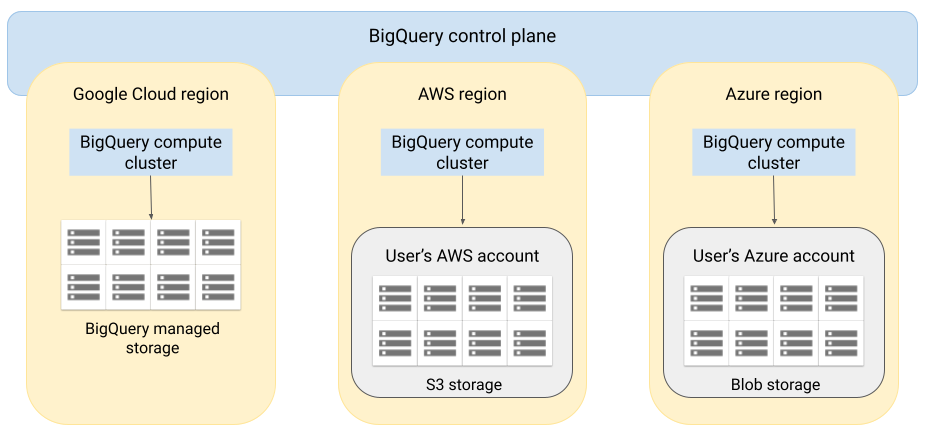
I risultati della query possono essere restituiti a Google Cloud tramite una connessione protetta, ad esempio per essere visualizzati nella console Google Cloud . In alternativa, puoi scrivere i risultati direttamente nei bucket Amazon S3 o in Blob Storage. In questo caso, non viene eseguito alcun movimento cross-cloud dei risultati della query.
BigQuery Omni utilizza ruoli IAM AWS standard o entità di Azure Active Directory per accedere ai dati nel tuo abbonamento. Deleghi l'accesso in lettura o scrittura a BigQuery Omni e puoi revocare l'accesso in qualsiasi momento.
Flusso di dati durante l'esecuzione di query sui dati
La seguente immagine descrive come si spostano i dati tra Google Cloud e AWS o Azure per le seguenti query:
SELECTestratto contoCREATE EXTERNAL TABLEestratto conto

- Il control plane di BigQuery riceve i job di query da te tramite la consoleGoogle Cloud , lo strumento a riga di comando bq, un metodo API o una libreria client.
- Il piano di controllo BigQuery invia i job di query per l'elaborazione al piano dati BigQuery su AWS o Azure.
- Il piano dati BigQuery riceve la query dal control plane tramite una connessione VPN.
- Il piano dati BigQuery legge i dati delle tabelle dal bucket Amazon S3 o da Blob Storage.
- Il piano dati BigQuery esegue il job di query sui dati della tabella. L'elaborazione dei dati delle tabelle avviene nella regione AWS o Azure specificata.
- Il risultato della query viene trasmesso dal piano dati al piano di controllo tramite la connessione VPN.
- Il control plane di BigQuery riceve i risultati del job di query per mostrarli in risposta al job di query. Questi dati vengono conservati per un massimo di 24 ore.
- Il risultato della query ti viene restituito.
Per saperne di più, consulta Eseguire query sui dati Amazon S3 e Dati di Blob Storage.
Flusso di dati durante l'esportazione
L'immagine seguente descrive il modo in cui i dati vengono spostati tra Google Cloud e AWS
o Azure durante un'istruzione EXPORT DATA.

- Il control plane di BigQuery riceve i job di query di esportazione da te tramite la console Google Cloud , lo strumento a riga di comando bq, un metodo API o una libreria client. La query contiene il percorso di destinazione per il risultato della query nel bucket Amazon S3 o in Blob Storage.
- Il piano di controllo BigQuery invia i job di query di esportazione per l'elaborazione al piano dati BigQuery (su AWS o Azure).
- Il piano dati BigQuery riceve la query di esportazione dal piano di controllo tramite la connessione VPN.
- Il piano dati BigQuery legge i dati delle tabelle dal bucket Amazon S3 o da Blob Storage.
- Il piano dati BigQuery esegue il job di query sui dati della tabella. L'elaborazione dei dati delle tabelle avviene nella regione AWS o Azure specificata.
- BigQuery scrive il risultato della query nel percorso di destinazione specificato nel bucket Amazon S3 o in Blob Storage.
Per saperne di più, consulta Esportazione dei risultati di una query in Amazon S3 e Blob Storage.
Vantaggi
Rendimento. Puoi ottenere informazioni più rapidamente, perché i dati non vengono copiati tra i cloud e le query vengono eseguite nella stessa regione in cui si trovano i dati.
Costo. Risparmi sui costi di trasferimento dei dati in uscita perché i dati non vengono spostati. Non sono previsti costi aggiuntivi per il tuo account AWS o Azure correlati all'analisi BigQuery Omni, perché le query vengono eseguite su cluster gestiti da Google. Ti vengono addebitati solo i costi per l'esecuzione delle query, utilizzando il modello di prezzo di BigQuery.
Sicurezza e governance dei dati. Gestisci i dati nel tuo abbonamento AWS o Azure. Non è necessario spostare o copiare i dati non elaborati dal cloud pubblico. Tutti i calcoli vengono eseguiti nel servizio multitenant BigQuery, che viene eseguito nella stessa regione dei tuoi dati.
Architettura serverless. Come il resto di BigQuery, BigQuery Omni è un'offerta serverless. Google esegue il deployment e gestisce i cluster che eseguono BigQuery Omni. Non devi eseguire il provisioning di risorse o gestire cluster.
Facilità di gestione. BigQuery Omni fornisce un'interfaccia di gestione unificata tramite Google Cloud. BigQuery Omni può utilizzare il tuo account Google Cloud e i tuoi progetti BigQuery esistenti. Puoi scrivere una query GoogleSQL nella console Google Cloud per eseguire query sui dati in AWS o Azure e visualizzare i risultati nella console Google Cloud .
Trasferimento cross-cloud. Puoi caricare i dati nelle tabelle BigQuery standard dai bucket S3 e dall'archiviazione blob. Per saperne di più, consulta Trasferire dati da Amazon S3 e Trasferire dati da Archiviazione BLOB a BigQuery.
Memorizzazione nella cache dei metadati per le prestazioni
Puoi utilizzare i metadati memorizzati nella cache per migliorare il rendimento delle query sulle tabelle BigLake che fanno riferimento ai dati Amazon S3. È particolarmente utile nei casi in cui lavori con un numero elevato di file o se i dati sono partizionati in Apache Hive.
BigQuery utilizza CMETA come sistema di metadati distribuito per gestire in modo efficiente le tabelle di grandi dimensioni. CMETA fornisce metadati granulari a livello di colonna e blocco, accessibili tramite le tabelle di sistema. Questo sistema contribuisce a migliorare le prestazioni delle query ottimizzando l'accesso e l'elaborazione dei dati. Per accelerare ulteriormente le prestazioni delle query su tabelle di grandi dimensioni, BigQuery gestisce una cache dei metadati. I job di aggiornamento CMETA mantengono aggiornata questa cache.I metadati includono nomi di file, informazioni di partizionamento e metadati fisici di file come i conteggi di righe. Puoi scegliere se abilitare o meno la memorizzazione nella cache dei metadati in una tabella. Le query con un numero elevato di file e con filtri di partizione Apache Hive traggono il massimo vantaggio dalla memorizzazione nella cache dei metadati.
Se non abiliti la memorizzazione nella cache dei metadati, le query sulla tabella devono leggere l'origine dati esterna per ottenere i metadati dell'oggetto. La lettura di questi dati aumenta la latenza delle query; l'elenco di milioni di file dall'origine dati esterna può richiedere diversi minuti. Se abiliti la memorizzazione nella cache dei metadati, le query possono evitare di elencare i file dall'origine dati esterna e possono partizionare ed eliminare i file più rapidamente.
La memorizzazione nella cache dei metadati si integra anche con il controllo delle versioni degli oggetti Cloud Storage. Quando la cache viene compilata o aggiornata, acquisisce i metadati in base alla versione live degli oggetti Cloud Storage in quel momento. Di conseguenza, le query con memorizzazione nella cache dei metadati abilitata leggono i dati corrispondenti alla versione specifica dell'oggetto memorizzato nella cache, anche se le versioni più recenti diventano attive in Cloud Storage. L'accesso ai dati di qualsiasi versione dell'oggetto aggiornata successivamente in Cloud Storage richiede un aggiornamento della cache dei metadati.
Esistono due proprietà che controllano questa funzionalità:
- Massima obsolescenza specifica quando le query utilizzano i metadati memorizzati nella cache.
- La modalità di memorizzazione nella cache dei metadati specifica la modalità di raccolta dei metadati.
Quando la memorizzazione nella cache dei metadati è abilitata, specifichi l'intervallo massimo di obsolescenza dei metadati accettabile per le operazioni sulla tabella. Ad esempio, se specifichi un intervallo di 1 ora, le operazioni sulla tabella utilizzano i metadati memorizzati nella cache se sono stati aggiornati nell'ultima ora. Se i metadati memorizzati nella cache sono più vecchi, l'operazione ripristina il recupero dei metadati da Amazon S3. Puoi specificare un intervallo di inattività compreso tra 30 minuti e 7 giorni.
Quando abiliti la memorizzazione nella cache dei metadati per BigLake o le tabelle degli oggetti, BigQuery attiva i job di aggiornamento della generazione dei metadati. Puoi scegliere di aggiornare la cache automaticamente o manualmente:
- Per gli aggiornamenti automatici, la cache viene aggiornata a un intervallo definito dal sistema, in genere tra 30 e 60 minuti. L'aggiornamento automatico della cache è un buon approccio se i file in Amazon S3 vengono aggiunti, eliminati o modificati a intervalli casuali. Se devi controllare la tempistica dell'aggiornamento, ad esempio per attivarlo alla fine di un job di estrazione, trasformazione e caricamento, utilizza l'aggiornamento manuale.
Per gli aggiornamenti manuali, esegui la procedura di sistema
BQ.REFRESH_EXTERNAL_METADATA_CACHEper aggiornare la cache dei metadati in base a una pianificazione che soddisfi i tuoi requisiti. L'aggiornamento manuale della cache è un buon approccio se i file in Amazon S3 vengono aggiunti, eliminati o modificati a intervalli noti, ad esempio come output di una pipeline.Se esegui più aggiornamenti manuali simultanei, solo uno andrà a buon fine.
La cache dei metadati scade dopo 7 giorni se non viene aggiornata.
Gli aggiornamenti manuali e automatici della cache vengono eseguiti con
priorità query INTERACTIVE.
Utilizzare le prenotazioni BACKGROUND
Se scegli di utilizzare gli aggiornamenti automatici, ti consigliamo di creare una
prenotazione e poi un
assegnazione con un BACKGROUND tipo di job
per il progetto che esegue i job di aggiornamento della cache dei metadati. Con le prenotazioni BACKGROUND, i job di aggiornamento utilizzano un pool di risorse dedicato che impedisce ai job di aggiornamento di competere con le query degli utenti e di non riuscire potenzialmente se non sono disponibili risorse sufficienti.
L'utilizzo di un pool di slot condiviso non comporta costi aggiuntivi, mentre l'utilizzo delle prenotazioni BACKGROUND offre prestazioni più coerenti allocando un pool di risorse dedicato e migliora l'affidabilità dei job di aggiornamento e l'efficienza complessiva delle query in BigQuery.
Prima di impostare i valori dell'intervallo di obsolescenza e della modalità di memorizzazione nella cache dei metadati, valuta la loro interazione. Considera i seguenti esempi:
- Se aggiorni manualmente la cache dei metadati per una tabella e imposti
l'intervallo di obsolescenza su 2 giorni, devi eseguire la
procedura di sistema
BQ.REFRESH_EXTERNAL_METADATA_CACHEogni 2 giorni o meno se vuoi che le operazioni sulla tabella utilizzino i metadati memorizzati nella cache. - Se aggiorni automaticamente la cache dei metadati per una tabella e imposti l'intervallo di obsolescenza su 30 minuti, è possibile che alcune operazioni sulla tabella vengano lette da Amazon S3 se l'aggiornamento della cache dei metadati richiede più tempo rispetto alla finestra di 30-60 minuti.
Per trovare informazioni sui job di aggiornamento dei metadati, esegui una query sulla
visualizzazione INFORMATION_SCHEMA.JOBS,
come mostrato nell'esempio seguente:
SELECT * FROM `region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT` WHERE job_id LIKE '%metadata_cache_refresh%' AND creation_time > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 6 HOUR) ORDER BY start_time DESC LIMIT 10;
Per ulteriori informazioni, consulta la sezione Memorizzazione nella cache dei metadati.
Tabelle abilitate alla cache con viste materializzate
Puoi utilizzare le viste materializzate sulle tabelle abilitate alla cache dei metadati di Amazon Simple Storage Service (Amazon S3) per migliorare le prestazioni e l'efficienza durante l'esecuzione di query sui dati strutturati archiviati in Amazon S3. Queste viste materializzate funzionano come le viste materializzate sulle tabelle di archiviazione gestite da BigQuery, inclusi i vantaggi di aggiornamento automatico e ottimizzazione intelligente.
Per rendere disponibili i dati Amazon S3 in una vista materializzata in una regione BigQuery supportata per i join, crea una replica della vista materializzata. Puoi creare repliche della vista materializzata solo su viste materializzate autorizzate.
Limitazioni
Oltre alle limitazioni per le tabelle BigLake, si applicano le seguenti limitazioni a BigQuery Omni, che include le tabelle BigLake basate su dati di Amazon S3 e Blob Storage:
- L'utilizzo dei dati in una delle regioni BigQuery Omni non è supportato dalle versioni Standard ed Enterprise Plus. Per ulteriori informazioni sulle versioni, vedi Introduzione alle versioni di BigQuery.
- Le visualizzazioni
OBJECT_PRIVILEGES,STREAMING_TIMELINE_BY_*,TABLE_SNAPSHOTS,TABLE_STORAGE,TABLE_CONSTRAINTS,KEY_COLUMN_USAGE,CONSTRAINT_COLUMN_USAGEePARTITIONSINFORMATION_SCHEMAnon sono disponibili per le tabelle BigLake basate su dati di Amazon S3 e Blob Storage. - Le viste materializzate non sono supportate per l'archiviazione BLOB.
- Le UDF JavaScript non sono supportate.
Le seguenti istruzioni SQL non sono supportate:
- Istruzioni BigQuery ML.
- Istruzioni Data Definition Language (DDL)
che richiedono dati gestiti in BigQuery. Ad esempio, sono supportati
CREATE EXTERNAL TABLE,CREATE SCHEMAoCREATE RESERVATION, ma nonCREATE TABLE. - Istruzioni DML (Data Manipulation Language).
Si applicano le seguenti limitazioni per l'esecuzione di query e la lettura delle tabelle temporanee di destinazione:
- L'interrogazione delle tabelle temporanee di destinazione con l'istruzione
SELECTnon è supportata.
- L'interrogazione delle tabelle temporanee di destinazione con l'istruzione
Le query pianificate sono supportate solo tramite il metodo API o CLI. L'opzione Tabella di destinazione è disabilitata per le query. Sono consentite solo query
EXPORT DATA.L'API BigQuery Storage non è disponibile nelle regioni BigQuery Omni.
Se la query utilizza la clausola
ORDER BYe ha una dimensione del risultato superiore a 256 MB, la query non va a buon fine. Per risolvere il problema, riduci le dimensioni del risultato o rimuovi la clausolaORDER BYdalla query. Per ulteriori informazioni sulle quote di BigQuery Omni, consulta Quote e limiti.L'utilizzo delle chiavi di crittografia gestite dal cliente (CMEK) con set di dati e tabelle esterne non è supportato.
Prezzi
Per informazioni sui prezzi e sulle offerte a tempo limitato in BigQuery Omni, consulta la pagina Prezzi di BigQuery Omni.
Quote e limiti
Per informazioni sulle quote di BigQuery Omni, consulta la sezione Quote e limiti.
Se il risultato della query è superiore a 20 GiB, valuta la possibilità di esportarlo in Amazon S3 o Blob Storage. Per informazioni sulle quote per l'API BigQuery Connection, consulta API BigQuery Connection.
Località
BigQuery Omni elabora le query nella stessa località del set di dati che contiene le tabelle che stai interrogando. Dopo aver creato il set di dati, la posizione non può essere modificata. I tuoi dati si trovano all'interno del tuo account AWS o Azure. Le regioni BigQuery Omni supportano i prezzi per le prenotazioni della versione Enterprise e per il computing on demand (analisi). Per ulteriori informazioni sulle versioni, vedi Introduzione alle versioni di BigQuery.
| Descrizione della regione | Nome regione | Regione BigQuery colocalizzata | |
|---|---|---|---|
| AWS | |||
| AWS - Stati Uniti orientali (Virginia del Nord) | aws-us-east-1 |
us-east4 |
|
| AWS - US West (Oregon) | aws-us-west-2 |
us-west1 |
|
| AWS - Asia Pacifico (Seul) | aws-ap-northeast-2 |
asia-northeast3 |
|
| AWS - Asia Pacifico (Sydney) | aws-ap-southeast-2 |
australia-southeast1 |
|
| AWS - Europe (Irlanda) | aws-eu-west-1 |
europe-west1 |
|
| AWS - Europe (Frankfurt) | aws-eu-central-1 |
europe-west3 |
|
| Azure | |||
| Azure - Stati Uniti orientali 2 | azure-eastus2 |
us-east4 |
|
Passaggi successivi
- Scopri come connetterti ad Amazon S3 e a Blob Storage.
- Scopri come creare tabelle BigLake Amazon S3 e Blob Storage.
- Scopri come eseguire query sulle tabelle BigLake di Amazon S3 e Blob Storage.
- Scopri come unire le tabelle BigLake Amazon S3 e Blob Storage con le tabelle BigQuery utilizzando le unioni cross-cloud. Google Cloud
- Scopri come esportare i risultati di una query in Amazon S3 e Blob Storage.
- Scopri come trasferire i dati da Amazon S3 e da Archiviazione BLOB a BigQuery.
- Scopri di più sulla configurazione del perimetro dei Controlli di servizio VPC.
- Scopri come specificare la tua posizione.