Migre do IBM Netezza
Este documento fornece orientações gerais sobre como migrar do Netezza para o BigQuery. Descreve as diferenças arquitetónicas fundamentais entre o Netezza e o BigQuery, bem como as capacidades adicionais que o BigQuery oferece. Também mostra como pode repensar o seu modelo de dados existente e extrair, transformar e carregar (ETL) processos para maximizar as vantagens do BigQuery.
Este documento destina-se a arquitetos empresariais, DBAs, programadores de aplicações e profissionais de segurança de TI que pretendam migrar do Netezza para o BigQuery e resolver desafios técnicos no processo de migração. Este documento fornece detalhes sobre as seguintes fases do processo de migração:
- Exportar dados
- Carregar dados
- Tirar partido de ferramentas de terceiros
Também pode usar a tradução de SQL em lote para migrar os seus scripts SQL em massa ou a tradução de SQL interativa para traduzir consultas ad hoc. O IBM Netezza SQL/NZPLSQL é suportado por ambas as ferramentas em pré-visualização.
Comparação de arquiteturas
O Netezza é um sistema potente que pode ajudar a armazenar e analisar grandes quantidades de dados. No entanto, um sistema como o Netezza requer grandes investimentos em hardware, manutenção e licenciamento. Isto pode ser difícil de dimensionar devido a desafios na gestão de nós, no volume de dados por origem e nos custos de arquivo. Com o Netezza, a capacidade de armazenamento e processamento é limitada por dispositivos de hardware. Quando a utilização máxima é atingida, o processo de extensão da capacidade do dispositivo é elaborado e, por vezes, nem sequer é possível.
Com o BigQuery, não tem de gerir a infraestrutura e não precisa de um administrador de base de dados. O BigQuery é um armazém de dados sem servidor, à escala de petabytes e totalmente gerido que pode analisar milhares de milhões de linhas, sem um índice, em dezenas de segundos. Uma vez que o BigQuery partilha a infraestrutura da Google, pode paralelizar cada consulta e executá-la em dezenas de milhares de servidores em simultâneo. As seguintes tecnologias essenciais diferenciam o BigQuery:
- Armazenamento de colunas. Os dados são armazenados em colunas em vez de linhas, o que permite alcançar uma taxa de compressão e um débito de análise muito elevados.
- Arquitetura de árvores. As consultas são enviadas e os resultados são agregados em milhares de máquinas em poucos segundos.
Arquitetura do Netezza
O Netezza é um dispositivo acelerado por hardware que inclui uma camada de abstração de dados de software. A camada de abstração de dados gere a distribuição de dados no dispositivo e otimiza as consultas distribuindo o processamento de dados entre as CPUs e os FPGAs subjacentes.
Os modelos Netezza TwinFin e Striper atingiram o fim do apoio técnico em junho de 2019.
O diagrama seguinte ilustra as camadas de abstração de dados no Netezza:
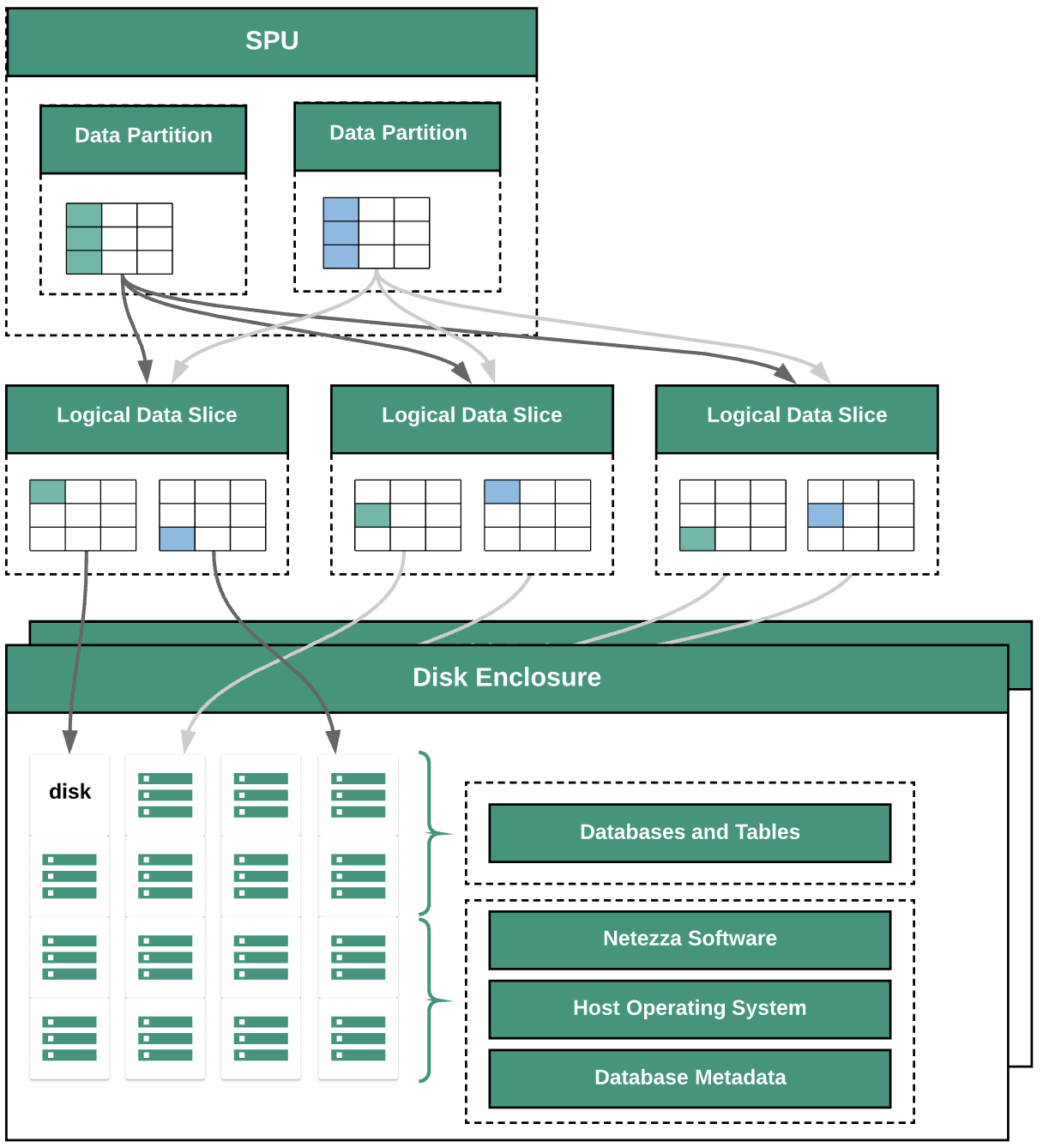
O diagrama mostra as seguintes camadas de abstração de dados:
- Invólucro do disco. O espaço físico no interior do dispositivo onde os discos estão montados.
- Discos. As unidades físicas nos compartimentos de discos armazenam as bases de dados e as tabelas.
- Segmentos de dados. Representação lógica dos dados guardados num disco.
Os dados são distribuídos pelas divisões de dados através de uma chave de distribuição. Pode monitorizar o estado das divisões de dados através de comandos
nzds. - Partições de dados. Representação lógica de uma fatia de dados gerida por unidades de processamento de fragmentos (SPUs) específicas. Cada SPU é proprietária de uma ou mais partições de dados que contêm os dados do utilizador que a SPU é responsável por processar durante as consultas.
Todos os componentes do sistema estão ligados por uma estrutura de rede. O dispositivo Netezza executa um protocolo personalizado com base em endereços IP.
Arquitetura do BigQuery
O BigQuery é um armazém de dados empresariais totalmente gerido que lhe permite gerir e analisar os seus dados com funcionalidades integradas, como aprendizagem automática, análise geoespacial e Business Intelligence. Para mais informações, consulte o artigo O que é o BigQuery?.
O BigQuery processa o armazenamento e os cálculos para oferecer um armazenamento de dados duradouro e respostas de alto desempenho a consultas de estatísticas. Para mais informações, consulte o artigo O BigQuery explicado.
Para informações sobre os preços do BigQuery, consulte o artigo Compreender a escalabilidade rápida e os preços simples do BigQuery.
Pré-migração
Para garantir uma migração bem-sucedida do armazém de dados, comece a planear a sua estratégia de migração no início da cronologia do projeto. Para obter informações sobre como planear sistematicamente o seu trabalho de migração, consulte o artigo O que e como migrar: a estrutura de migração.
Planeamento de capacidade do BigQuery
A taxa de transferência do Analytics no BigQuery é medida em slots. Um slot do BigQuery é a unidade proprietária da Google de computação, RAM e débito da rede necessários para executar consultas SQL. O BigQuery calcula automaticamente quantos slots são necessários para cada consulta, consoante o tamanho e a complexidade da consulta.
Para executar consultas no BigQuery, selecione um dos seguintes modelos de preços:
- A pedido. O modelo de preços predefinido, em que lhe é cobrado o número de bytes processados por cada consulta.
- Preços baseados na capacidade. Compra
slots, que são CPUs virtuais. Quando compra slots, está a comprar capacidade de processamento dedicada que pode usar para executar consultas. Os slots estão disponíveis nos seguintes planos de compromisso:
- Anual. Compromete-se a 365 dias.
- Três anos. Compromete-se a 365*3 dias.
Um slot do BigQuery partilha algumas semelhanças com as SPUs do Netezza, como a CPU, a memória e o tratamento de dados. No entanto, não representam a mesma unidade de medida. As SPUs do Netezza têm um mapeamento fixo para os componentes de hardware subjacentes, enquanto o slot do BigQuery representa uma CPU virtual usada para executar consultas. Para ajudar na estimativa de slots, recomendamos que configure a monitorização do BigQuery através do Cloud Monitoring e analise os seus registos de auditoria através do BigQuery. Para visualizar a utilização de slots do BigQuery, também pode usar ferramentas como o Looker Studio ou o Looker. A monitorização e a análise regulares da utilização de slots ajudam a estimar o número total de slots de que a sua organização precisa à medida que cresce no Google Cloud.
Por exemplo, suponhamos que reserva inicialmente 2000 slots do BigQuery para executar 50 consultas de complexidade média em simultâneo. Se as consultas demorarem sempre mais do que algumas horas a ser executadas e os seus painéis de controlo mostrarem uma utilização elevada de slots, as suas consultas podem não estar otimizadas ou pode precisar de slots adicionais do BigQuery para ajudar a suportar as suas cargas de trabalho. Para comprar slots por si próprio em compromissos anuais ou de três anos, pode criar reservas do BigQuery através da Google Cloud consola ou da ferramenta de linha de comandos bq. Se assinou um contrato offline para a sua compra baseada na capacidade, o seu plano pode desviar-se dos detalhes descritos aqui.
Para obter informações sobre como controlar os custos de armazenamento e processamento de consultas no BigQuery, consulte o artigo Otimize as cargas de trabalho.
Segurança em Google Cloud
As secções seguintes descrevem os controlos de segurança comuns do Netezza e como pode ajudar a proteger o seu armazém de dados num ambiente Google Cloud .
Gestão de identidade e de acesso
A base de dados Netezza contém um conjunto de capacidades de controlo de acesso totalmente integradas que permitem aos utilizadores aceder a recursos para os quais têm autorização.
O acesso ao Netezza é controlado através da rede para o dispositivo Netezza através da gestão das contas de utilizador do Linux que podem iniciar sessão no sistema operativo. O acesso à base de dados, aos objetos e às tarefas do Netezza é gerido através das contas de utilizador da base de dados do Netezza que podem estabelecer ligações SQL ao sistema.
O BigQuery usa o serviço de gestão de identidade e acesso (IAM) da Google para gerir o acesso aos recursos. Os tipos de recursos disponíveis no BigQuery são organizações, projetos, conjuntos de dados, tabelas e vistas. Na hierarquia das políticas de IAM, os conjuntos de dados são recursos subordinados dos projetos. Uma tabela herda as autorizações do conjunto de dados que a contém.
Para conceder acesso a um recurso, atribui uma ou mais funções a um utilizador, um grupo ou uma conta de serviço. As funções de organização e projeto controlam o acesso à execução de tarefas ou à gestão do projeto, enquanto as funções de conjunto de dados controlam o acesso à visualização ou modificação dos dados num projeto.
O IAM fornece os seguintes tipos de funções:
- Funções predefinidas. Para suportar padrões de controlo de acesso e casos de utilização comuns.
- Funções básicas. Incluem as funções de proprietário, editor e leitor. As funções básicas oferecem acesso detalhado a um serviço específico e são geridas por Google Cloud.
- Funções personalizadas. Fornecer acesso detalhado de acordo com uma lista de autorizações especificada pelo utilizador.
Quando atribui funções predefinidas e básicas a um utilizador, as autorizações concedidas são uma união das autorizações de cada função individual.
Segurança ao nível da linha
A segurança de vários níveis é um modelo de segurança abstrato que o Netezza usa para definir regras para controlar o acesso dos utilizadores a tabelas seguras ao nível da linha (RSTs). Uma tabela segura ao nível da linha é uma tabela de base de dados com etiquetas de segurança nas linhas para filtrar os utilizadores que não têm os privilégios adequados. Os resultados devolvidos nas consultas diferem consoante os privilégios do utilizador que faz a consulta.
Para alcançar a segurança ao nível da linha no BigQuery, pode usar vistas autorizadas e políticas de acesso ao nível da linha. Para mais informações sobre como conceber e implementar estas políticas, consulte o artigo Introdução à segurança ao nível da linha do BigQuery.
Encriptação de dados
Os dispositivos Netezza usam unidades de autoencriptação (SEDs) para melhorar a segurança e a proteção dos dados armazenados no dispositivo. Os SEDs encriptam os dados quando são escritos no disco. Cada disco tem uma chave de encriptação de disco (DEK) que é definida na fábrica e armazenada no disco. O disco usa a DEK para encriptar os dados à medida que os escreve e, em seguida, para desencriptar os dados quando são lidos do disco. O funcionamento do disco, bem como a respetiva encriptação e desencriptação, é transparente para os utilizadores que estão a ler e a escrever dados. Este modo de encriptação e desencriptação predefinido é denominado modo de eliminação segura.
No modo de eliminação segura, não precisa de uma chave de autenticação nem de uma palavra-passe para desencriptar e ler dados. Os SEDs oferecem capacidades melhoradas para uma eliminação segura fácil e rápida em situações em que os discos têm de ser reutilizados ou devolvidos por motivos de apoio técnico ou garantia.
O Netezza usa a encriptação simétrica. Se os seus dados estiverem encriptados ao nível do campo, a seguinte função de desencriptação pode ajudar a ler e exportar dados:
varchar = decrypt(varchar text, varchar key [, int algorithm [, varchar IV]]); nvarchar = decrypt(nvarchar text, nvarchar key [, int algorithm[, varchar IV]]);
Todos os dados armazenados no BigQuery são encriptados em repouso. Se quiser controlar a encriptação, pode usar chaves de encriptação geridas pelo cliente (CMEK) para o BigQuery. Com as CMEK, em vez de a Google gerir as chaves de encriptação de chaves que protegem os seus dados, controla e gere as chaves de encriptação de chaves no Cloud Key Management Service. Para mais informações, consulte o artigo Encriptação em repouso.
Testes de referência de desempenho
Para acompanhar o progresso e a melhoria ao longo do processo de migração, é importante estabelecer um desempenho de base para o ambiente Netezza no estado atual. Para estabelecer a base, selecione um conjunto de consultas representativas, que são captadas a partir das aplicações de consumo (como o Tableau ou o Cognos).
| Ambiente | Netezza | BigQuery |
|---|---|---|
| Tamanho dos dados | size TB | - |
| Consulta 1: name (análise completa da tabela) | mm:ss.ms | - |
| Consulta 2: name | mm:ss.ms | - |
| Consulta 3: name | mm:ss.ms | - |
| Total | mm:ss.ms | - |
Configuração do projeto fundamental
Antes de aprovisionar recursos de armazenamento para a migração de dados, tem de concluir a configuração do projeto.
- Para configurar projetos e ativar o IAM ao nível do projeto, consulte o Google Cloud Well-Architected Framework.
- Para criar recursos fundamentais que tornem a sua implementação na nuvem adequada para empresas, consulte o Design da zona de destino no Google Cloud.
- Para saber mais sobre a governação de dados e os controlos de que precisa quando migra o seu armazém de dados no local para o BigQuery, consulte o Resumo da segurança e governação de dados.
Conetividade de rede
É necessária uma ligação de rede fiável e segura entre o centro de dados no local (onde a instância do Netezza está em execução) e o ambiente do Google Cloud. Para obter informações sobre como ajudar a proteger a sua ligação, consulte o artigo Introdução à administração de dados no BigQuery. Quando carrega extratos de dados, a largura de banda da rede pode ser um fator limitativo. Para informações sobre como cumprir os requisitos de transferência de dados, consulte Aumentar a largura de banda da rede.
Tipos de dados e propriedades suportados
Os tipos de dados do Netezza diferem dos tipos de dados do BigQuery. Para ver informações sobre os tipos de dados do BigQuery, consulte Tipos de dados. Para uma comparação detalhada entre os tipos de dados do Netezza e do BigQuery, consulte o guia de tradução de SQL do IBM Netezza.
Comparação de SQL
O SQL de dados do Netezza consiste em DDL, DML e linguagem de controlo de dados (DCL) apenas do Netezza, que são diferentes do GoogleSQL. O GoogleSQL está em conformidade com a norma SQL 2011 e tem extensões que suportam a consulta de dados aninhados e repetidos. Se estiver a usar o SQL antigo do BigQuery, consulte as funções e os operadores do SQL antigo. Para uma comparação detalhada entre o SQL e as funções do Netezza e do BigQuery, consulte o guia de tradução de SQL do IBM Netezza.
Para ajudar na migração do seu código SQL, use a tradução de SQL em lote para migrar o seu código SQL em massa ou a tradução de SQL interativa para traduzir consultas ad hoc.
Comparação de funções
É importante compreender como as funções do Netezza são mapeadas para as funções do BigQuery. Por exemplo, a função Months_Between do Netezza gera um decimal, enquanto a função DateDiff do BigQuery gera um número inteiro. Por conseguinte, tem de usar uma função UDF personalizada para gerar o tipo de dados correto. Para uma comparação detalhada entre as funções do Netezza SQL e do GoogleSQL, consulte o guia de tradução do IBM Netezza SQL.
Migração de dados
Para migrar dados do Netezza para o BigQuery, exporte os dados do Netezza, transfira e prepare os dados no Google Cloude, em seguida, carregue os dados no BigQuery. Esta secção apresenta uma vista geral do processo de migração de dados. Para uma descrição detalhada do processo de migração de dados, consulte o artigo Processo de migração de esquemas e dados. Para uma comparação detalhada entre os tipos de dados suportados do Netezza e do BigQuery, consulte o guia de tradução de SQL do IBM Netezza.
Exporte dados do Netezza
Para explorar dados de tabelas de bases de dados Netezza, recomendamos que os exporte para uma tabela externa no formato CSV. Para mais informações, consulte o artigo Carregar dados para um sistema cliente remoto. Também pode ler dados através de sistemas de terceiros, como o Informatica (ou ETL personalizado), usando conetores JDBC/ODBC para produzir ficheiros CSV.
O Netezza só suporta a exportação de ficheiros simples não comprimidos (CSV) para cada tabela.
No entanto, se estiver a exportar tabelas grandes, o CSV não comprimido pode ficar muito grande. Se possível, considere converter o CSV num formato compatível com esquemas, como
Parquet, Avro ou ORC, o que resulta em ficheiros de exportação mais pequenos com maior
fiabilidade. Se o CSV for o único formato disponível, recomendamos que comprima os ficheiros de exportação para reduzir o tamanho do ficheiro antes de os carregar para o Google Cloud.
A redução do tamanho do ficheiro ajuda a tornar o carregamento mais rápido e aumenta a fiabilidade da transferência. Se transferir ficheiros para o Cloud Storage, pode usar a flag --gzip-local num comando gcloud storage cp, que comprime os ficheiros antes de os carregar.
Transferência e preparação de dados
Após a exportação, os dados têm de ser transferidos e preparados no Google Cloud. Existem várias opções para transferir os dados, consoante a quantidade de dados que está a transferir e a largura de banda da rede disponível. Para mais informações, consulte o artigo Vista geral do esquema e da transferência de dados.
Quando usa a Google Cloud CLI, pode automatizar e paralelizar a transferência de ficheiros para o Cloud Storage. Limite os tamanhos dos ficheiros a 4 TB (não comprimidos) para um carregamento mais rápido no BigQuery. No entanto, tem de exportar o esquema antecipadamente. Esta é uma boa oportunidade para otimizar o BigQuery através da partição e da agrupamento.
Use gcloud storage bucket create
para criar os contentores de preparação para o armazenamento dos dados exportados e use
gcloud storage cp para transferir os
ficheiros de exportação de dados para contentores do Cloud Storage.
A CLI gcloud executa automaticamente a operação de cópia usando uma combinação de multiprocessamento e multithreading.
Carregar dados para o BigQuery
Depois de os dados serem preparados no Google Cloud, existem várias opções para carregar os dados para o BigQuery. Para mais informações, consulte o artigo Carregue o esquema e os dados para o BigQuery.
Ferramentas e apoio técnico para parceiros
Pode receber apoio técnico de parceiros no seu percurso de migração. Para ajudar na migração do código SQL, use a tradução de SQL em lote para migrar o código SQL em massa.
Muitos Google Cloud parceiros também oferecem serviços de migração de armazéns de dados. Para ver uma lista de parceiros e as respetivas soluções, consulte o artigo Trabalhe com um parceiro com experiência no BigQuery.
Após a migração
Após a conclusão da migração de dados, pode começar a otimizar a sua utilização do Google Cloud para resolver necessidades empresariais. Isto pode incluir a utilização das ferramentas de exploração e visualização do Google Analytics para obter estatísticas para as partes interessadas da empresa, otimizar consultas com baixo desempenho ou desenvolver um programa para ajudar na adoção por parte dos utilizadores.Google Cloud
Ligue-se às APIs BigQuery através da Internet
O diagrama seguinte mostra como uma aplicação externa pode estabelecer ligação ao BigQuery através da API:
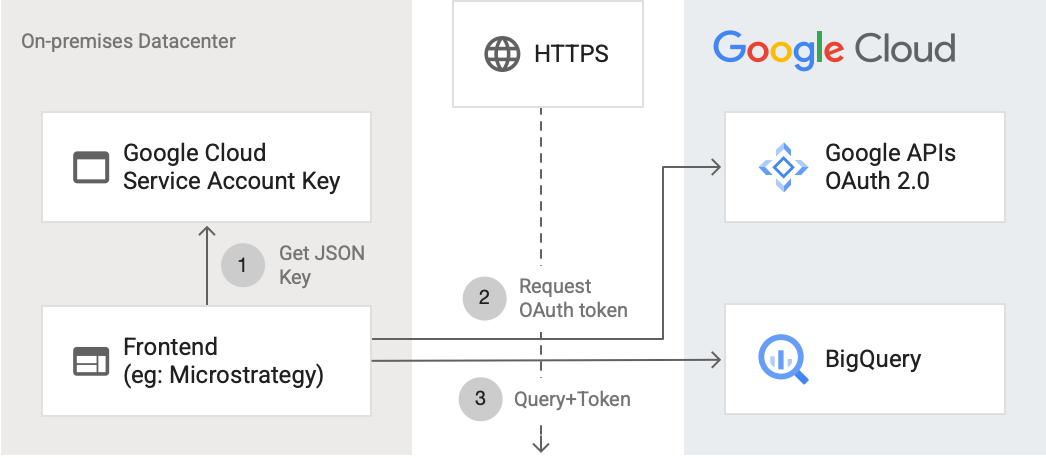
O diagrama mostra os seguintes passos:
- Em Google Cloud, é criada uma conta de serviço com autorizações da IAM. A chave da conta de serviço é gerada no formato JSON e copiada para o servidor de front-end (por exemplo, MicroStrategy).
- O front-end lê a chave e pede um token OAuth às APIs Google através de HTTPS.
- Em seguida, o front-end envia pedidos do BigQuery juntamente com o token para o BigQuery.
Para mais informações, consulte o artigo Autorizar pedidos de API.
Otimizar em função do BigQuery
O GoogleSQL suporta a conformidade com a norma SQL 2011 e tem extensões que suportam a consulta de dados aninhados e repetidos. A otimização das consultas para o BigQuery é fundamental para melhorar o desempenho e o tempo de resposta.
Substituir a função Months_Between no BigQuery por uma UDF
O Netezza trata os dias de um mês como 31. A UDF personalizada seguinte recria a função do Netezza com grande precisão, que pode chamar a partir das suas consultas:
CREATE TEMP FUNCTION months_between(date_1 DATE, date_2 DATE) AS ( CASE WHEN date_1 = date_2 THEN 0 WHEN EXTRACT(DAY FROM DATE_ADD(date_1, INTERVAL 1 DAY)) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(date_1,date_2, MONTH) WHEN EXTRACT(DAY FROM date_1) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(DATE_ADD(date_1, INTERVAL -1 DAY), date_2, MONTH) + 1/31 ELSE date_diff(date_1, date_2, MONTH) - 1 + ((EXTRACT(DAY FROM date_1) + (31 - EXTRACT(DAY FROM date_2))) / 31) END );
Migre procedimentos armazenados do Netezza
Se usar procedimentos armazenados do Netezza em cargas de trabalho de ETL para criar tabelas de factos, tem de migrar estes procedimentos armazenados para consultas SQL compatíveis com o BigQuery. O Netezza usa a linguagem de programação NZPLSQL para trabalhar com procedimentos armazenados. O NZPLSQL baseia-se na linguagem PL/pgSQL do Postgres. Para mais informações, consulte o guia de tradução de SQL do IBM Netezza.
UDF personalizada para emular ASCII do Netezza
A seguinte UDF personalizada para o BigQuery corrige erros de codificação nas colunas:
CREATE TEMP FUNCTION ascii(X STRING) AS (TO_CODE_POINTS(x)[ OFFSET (0)]);
O que se segue?
- Saiba como otimizar cargas de trabalho para a otimização do desempenho geral e a redução de custos.
- Saiba como otimizar o armazenamento no BigQuery.
- Consulte o guia de tradução de SQL do IBM Netezza.