Migrar do IBM Netezza
Este documento apresenta orientações avançadas sobre como migrar do Netezza para o BigQuery. Ele descreve as principais diferenças de arquitetura entre o Netezza e o BigQuery e descreve os outros recursos que o BigQuery oferece. Ela também mostra como repensar os modelo de dados e os processos existentes de extração, transformação e carregamento (ETL, na sigla em inglês) para maximizar os benefícios do BigQuery.
Este documento é destinado a arquitetos corporativos, DBAs, desenvolvedores de aplicativos e profissionais de segurança de TI que querem migrar do Netezza para o BigQuery e resolver desafios técnicos no processo de migração. Este documento apresenta detalhes sobre as seguintes fases do processo de migração:
- Exportação de dados
- Como ingerir dados
- Uso de ferramentas de terceiros
Também é possível usar tradução de SQL em lote para migrar os scripts SQL em massa ou a tradução de SQL interativo para traduzir consultas ad hoc. O IBM Netezza SQL/NZPLSQL é compatível com as duas ferramentas em pré-lançamento.
Comparação da arquitetura
O Netezza é um sistema avançado para armazenar e analisar grandes volumes de dados. Porém, um sistema como o Netezza exige grandes investimentos em hardware, manutenção e licenciamento. Isso pode ser difícil de escalonar devido a desafios no gerenciamento de nós, volume de dados por origem e custos de arquivamento. Com o Netezza, a capacidade de armazenamento e processamento é limitada por dispositivos de hardware. Quando o uso máximo é alcançado, o processo de extensão da capacidade do dispositivo é complexo e, às vezes, nem mesmo é possível.
Com o BigQuery, você não precisa gerenciar a infraestrutura nem precisa de um administrador de banco de dados. O BigQuery é um data warehouse sem servidor e totalmente gerenciado em escala de petabytes que pode analisar bilhões de linhas, sem um índice, em dezenas de segundos. Como o BigQuery compartilha a infraestrutura do Google, é possível carregar cada consulta em paralelo e executá-la em dezenas de milhares de servidores simultaneamente. As seguintes tecnologias principais são os diferenciais do BigQuery:
- Armazenamento em colunas. Os dados são armazenados em colunas em vez de linhas, o que possibilita alcançar uma taxa de compactação e uma capacidade de verificação muito altas.
- Arquitetura de árvore. As consultas são despachadas e os resultados são agregados em milhares de máquinas em poucos segundos.
Arquitetura do Netezza
O Netezza é um dispositivo acelerado por hardware acompanhado de uma camada de abstração de dados de software. A camada de abstração de dados gerencia a distribuição de dados no dispositivo e otimiza as consultas distribuindo o processamento de dados entre as CPUs e FPGAs subjacentes.
Os modelos Netezza TwinFin e Striper chegaram ao fim do suporte em junho de 2019.
O diagrama a seguir ilustra as camadas de abstração de dados no Netezza:
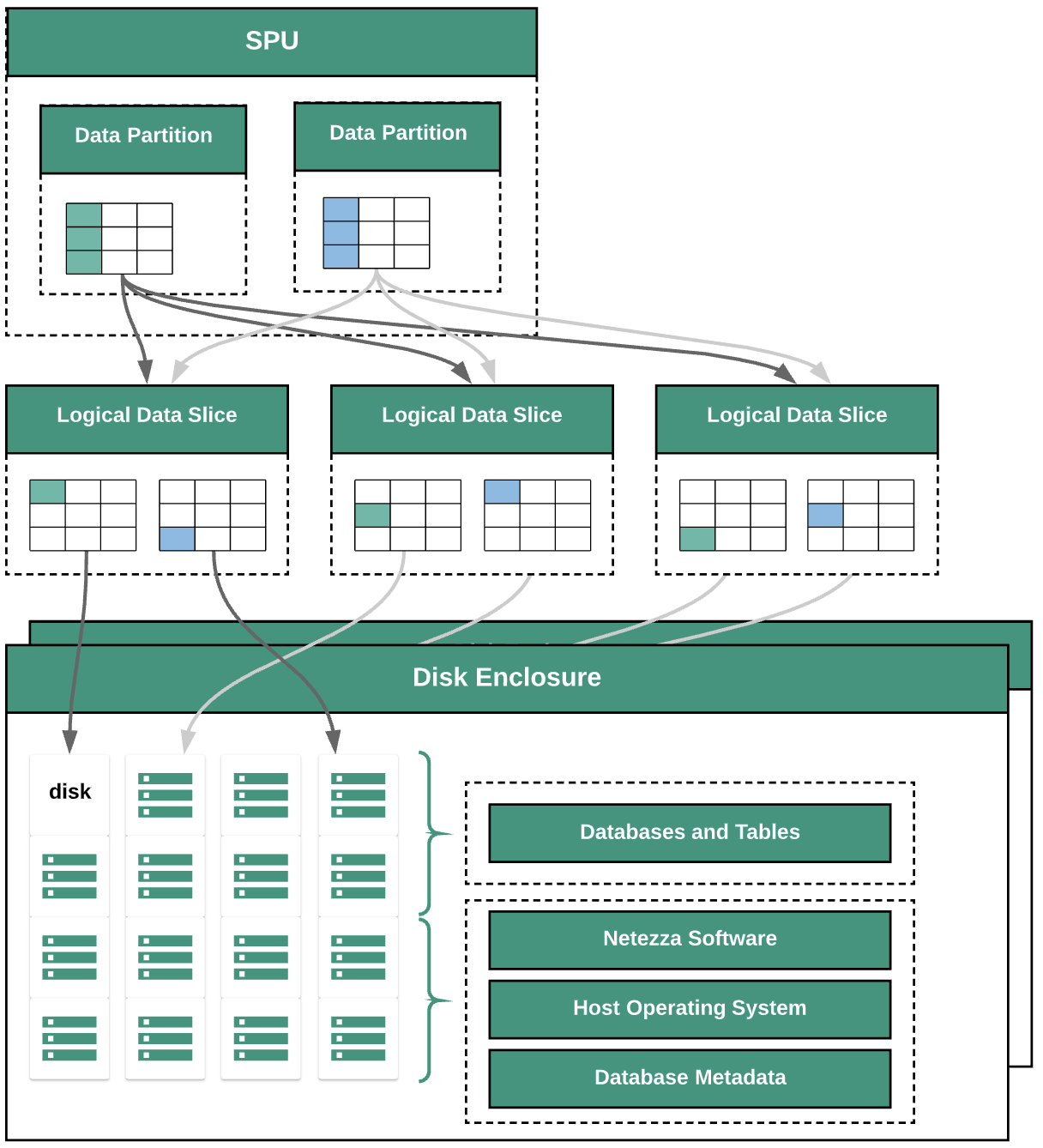
O diagrama mostra as seguintes camadas de abstração de dados:
- Estrutura do disco. O espaço físico dentro do dispositivo em que os discos são montados
- Discos. As unidades físicas nos locais de armazenamento em disco armazenam os bancos de dados e as tabelas.
- Frações de dados. Representação lógica dos dados salvos em um disco.
Os dados são distribuídos entre as fatias de dados usando uma chave de distribuição. É possível
monitorar o status das frações de dados usando comandos
nzds. - Partições de dados. Representação lógica de uma fração de dados gerenciada por unidades de processamento de snippets (SPUs, na sigla em inglês; link em inglês) específicas. Cada SPU é proprietária de uma ou mais partições de dados, contendo os dados do usuário que a SPU é responsável pelo processamento durante as consultas.
Todos os componentes do sistema são conectados por uma malha de rede. O dispositivo Netezza executa um protocolo personalizado com base nos endereços IP.
Arquitetura do BigQuery
O BigQuery é um armazenamento de dados corporativo totalmente gerenciado que ajuda a gerenciar e analisar dados com recursos integrados, como aprendizado de máquina, análise geoespacial e business intelligence. Para mais informações, consulte O que é o BigQuery?
O BigQuery lida com armazenamento e computação para fornecer um repositório de dados durável e respostas de alto desempenho a consultas de análise. Para mais informações, consulte a explicação do BigQuery.
Para informações sobre preços do BigQuery, consulte Noções básicas sobre preços do escalonamento rápido e simples do BigQuery.
Pré-migração
Para garantir uma migração bem-sucedida de data warehouses, comece a planejar sua estratégia de migração antecipadamente, no cronograma do seu projeto. Para informações sobre como planejar sistematicamente seu trabalho de migração, consulte O que e como migrar: o framework de migração.
Planejamento de capacidade do BigQuery
A capacidade de processamento de análise no BigQuery é medida em slots. Um Slot do BigQuery é a unidade proprietária do Google para capacidade de computação, RAM e rede necessária para executar consultas SQL. O BigQuery calcula automaticamente quantos slots são necessários para cada consulta, dependendo do tamanho e da complexidade dela.
Para executar consultas no BigQuery, selecione um dos seguintes modelos de preços:
- Sob demanda. O modelo de preços padrão, em que você é cobrado pelo número de bytes processados por cada consulta.
- Preços baseados em capacidade. Você compra
slots, que são CPUs virtuais. Quando você compra slots, está comprando uma capacidade de
processamento dedicada que pode ser usada para executar consultas. Os slots estão
disponíveis nos seguintes planos de compromisso:
- Anual. Você se compromete com os 365 dias.
- Três anos. Você se compromete com um período de 365 x 3 dias.
Um slot do BigQuery compartilha algumas semelhanças com as SPUs do Netezza, como CPU, memória e processamento de dados. Porém, elas não representam a mesma unidade de medida. As SPUs do Netezza têm um mapeamento fixo para os componentes de hardware subjacentes, enquanto o slot do BigQuery representa uma CPU virtual usada para executar consultas. Para ajudar na estimativa de slots, recomendamos configurar o monitoramento do BigQuery usando o Cloud Monitoring e analisar seus registros de auditoria usando o BigQuery. Para visualizar a utilização de slots do BigQuery, também é possível usar ferramentas como Looker Studio ou Looker. Monitorar e analisar regularmente a utilização de slots ajuda a estimar o número total de slots de que sua organização precisa à medida que seu uso do Google Cloudaumenta.
Por exemplo, suponha que você reserve inicialmente 2.000 slots do BigQuery para executar 50 consultas de complexidade média simultaneamente. Se as consultas levarem mais de algumas horas para serem executadas e os painéis mostrarem uma alta utilização de slots, talvez suas consultas não estejam otimizadas ou talvez você precise de mais Slots do BigQuery para ter compatibilidade com suas cargas de trabalho. Para comprar slots por conta própria em compromissos anuais ou de três anos, é possível criar reservas do BigQuery usando o console Google Cloud ou a ferramenta de linha de comando bq. Se você assinou um contrato off-line para adquirir o plano de preços baseado em capacidade, ele pode ter diferenças em relação aos detalhes descritos nesta página.
Para informações sobre como controlar os custos de armazenamento e processamento de consultas no BigQuery, consulte Otimizar cargas de trabalho.
Segurança em Google Cloud
As seções a seguir descrevem controles de segurança comuns do Netezza e como proteger o data warehouse em um ambiente Google Cloud .
Gerenciamento de identidade e acesso
O banco de dados Netezza contém um conjunto de recursos de controle de acesso (em inglês) totalmente integrados que permite que os usuários acessem os recursos para os quais estão autorizados.
O acesso ao Netezza é controlado pela rede para o dispositivo Netezza gerenciando as contas de usuário do Linux que podem fazer login no sistema operacional. O acesso ao banco de dados, objetos e tarefas do Netezza é gerenciado usando as contas de usuário do banco de dados do Netezza que podem estabelecer conexões SQL com o sistema.
O BigQuery usa o serviço Identity and Access Management (IAM) do Google para gerenciar o acesso aos recursos. Os tipos de recursos disponíveis no BigQuery são organizações, projetos, conjuntos de dados, tabelas e visualizações. Na hierarquia de políticas de IAM, conjuntos de dados são recursos filhos de projetos. Uma tabela herda permissões do conjunto de dados que a contém.
Para conceder acesso a um recurso, você atribui um ou mais papéis a um usuário, um grupo ou uma conta de serviço. Os papéis da organização e do projeto controlam o acesso para executar jobs ou gerenciar o projeto, enquanto os papéis do conjunto de dados controlam o acesso para visualizar ou modificar os dados dentro de um projeto.
O IAM fornece os seguintes tipos de papéis:
- Papéis predefinidos. Para oferecer suporte a casos de uso comuns e padrões de controle de acesso.
- Papéis básicos. Incluem os papéis "Proprietário", "Editor" e "Leitor". Os papéis básicos fornecem acesso granular a um serviço específico e são gerenciados por Google Cloud.
- Papéis personalizados. Fornecem acesso granular conforme uma lista de permissões especificada pelo usuário
Quando você atribui papéis predefinidos e básicos a um usuário, as permissões concedidas são uma combinação das permissões de cada papel individual.
Segurança no nível da linha
A segurança de vários níveis é um modelo de segurança abstrato que o Netezza usa para definir regras que controlam o acesso do usuário a tabelas seguras por linha (RSTs, na sigla em inglês; link em inglês). Uma tabela com segurança no nível das linhas é uma tabela de banco de dados com identificadores de segurança em linhas para filtrar usuários que não tenham os privilégios adequados. Os resultados retornados nas consultas variam de acordo com os privilégios do usuário que fez a consulta.
Para garantir a segurança na linha no BigQuery, use visualizações autorizadas e políticas de acesso na linha. Para mais informações sobre como projetar e implementar essas políticas, consulte Introdução à segurança no nível da linha do BigQuery.
Criptografia de dados
Os dispositivos Netezza usam unidades de criptografia própria (SEDs, na sigla em inglês; link em inglês) para melhorar a segurança e a proteção dos dados armazenados no dispositivo. Os SEDs criptografam dados quando são gravados no disco. Cada disco tem uma chave de criptografia de disco (DEK, na sigla em inglês), que é definida na fábrica e armazenada no disco. O disco usa a DEK para criptografar os dados durante a gravação e, em seguida, para descriptografar os dados quando eles são lidos no disco. A operação do disco, a criptografia e descriptografia dele são transparentes aos usuários que leem e gravam dados. Esse modo de criptografia e descriptografia padrão é chamado de modo de limpeza segura.
No modo de limpeza segura, você não precisa de uma chave de autenticação ou senha para descriptografar e ler dados. As SEDs oferecem recursos aprimorados para uma limpeza fácil e rápida em situações em que os discos precisam ser reutilizados ou retornados por motivos de garantia ou suporte.
O Netezza usa criptografia simétrica. Se os dados forem criptografados no nível do campo, a função de descriptografia a seguir poderá ajudar a ler e exportar dados:
varchar = decrypt(varchar text, varchar key [, int algorithm [, varchar IV]]); nvarchar = decrypt(nvarchar text, nvarchar key [, int algorithm[, varchar IV]]);
Todos os dados armazenados no BigQuery são criptografados em repouso. Para você controlar a criptografia, use as chaves de criptografia gerenciadas pelo cliente (CMEK, na sigla em inglês) para o BigQuery. Com as CMEK, em vez de o Google gerenciar as chaves de criptografia de chave que protegem os dados, você controla e gerencia as chaves de criptografia de chave no Cloud Key Management Service. Veja mais informações em Criptografia em repouso.
Comparativo de mercado do desempenho
Para acompanhar o progresso e a melhoria ao longo do processo de migração, é importante estabelecer um desempenho de referência do ambiente Netezza no estado atual. Para estabelecer o valor de referência, selecione um conjunto de consultas de representação que sejam capturadas dos aplicativos de consumo (como Tableau ou Cognos).
| Ambiente | Netezza | BigQuery |
|---|---|---|
| Tamanho dos dados | Tamanho TB | - |
| Consulta 1: nome (verificação completa da tabela) | mm:ss.ms | - |
| Consulta 2: nome | mm:ss.ms | - |
| Consulta 3: nome | mm:ss.ms | - |
| Total | mm:ss.ms | - |
Configuração básica do projeto
Antes de provisionar recursos de armazenamento para migração de dados, você precisa concluir a configuração do projeto.
- Para configurar projetos e ativar o IAM no nível do projeto, consulte Google Cloud Framework bem estruturado.
- Para projetar recursos básicos de uma implantação em nuvem pronta para empresas, consulte Design da zona de destino no Google Cloud.
- Para saber mais sobre a governança de dados e os controles necessários ao migrar seu data warehouse local para o BigQuery, consulte Visão geral de segurança e governança de dados.
Conectividade de rede
É necessária uma conexão de rede confiável e segura entre o data center local (em que a instância do Netezza está em execução) e o ambiente Google Cloud. Para informações sobre como proteger sua conexão, consulte Introdução à governança de dados no BigQuery. Quando você faz o upload de extrações de dados, a largura de banda da rede pode ser um fator limitante. Para informações sobre como atender aos requisitos de transferência de dados, consulte Como aumentar a largura de banda da rede.
Tipos e propriedades de dados compatíveis
Os tipos de dados do Netezza são diferentes dos tipos de dados do BigQuery. Para informações sobre os tipos de dados do BigQuery, consulte Tipos de dados. Para ver uma comparação detalhada entre os tipos de dados do Netezza e do BigQuery, consulte o Guia de tradução do SQL do IBM Netezza.
Comparação do SQL
O SQL de dados do Netezza consiste em DDL, DML e linguagem de controle de dados (DCL, na sigla em inglês) exclusivas, que são diferentes do GoogleSQL. O GoogleSQL está em conformidade com o padrão SQL 2011 e tem extensões que aceitam consultas aninhadas e dados repetidos. Se você estiver usando o SQL legado do BigQuery, consulte Funções e operadores do SQL legado. Para ver uma comparação detalhada entre o Netezza, o BigQuery SQL e funções, consulte o Guia de tradução do SQL do IBM Netezza.
Para ajudar na migração de código SQL, use conversão de SQL em lote para migrar seu código SQL em massa, ou tradução SQL interativa para traduzir consultas ad-hoc.
Comparação das funções
É importante entender como as funções do Netezza são mapeadas para
as funções do BigQuery. Por exemplo, a função Months_Between do Netezza
gera um decimal, enquanto a função DateDiff
do BigQuery gera um número inteiro. Portanto, você precisa usar uma
função UDF personalizada para gerar o tipo de dados
correto. Para ver uma comparação detalhada entre as funções do Netezza SQL e do GoogleSQL, consulte o
Guia de tradução SQL do IBM Netezza.
Migração de dados
Para migrar dados do Netezza para o BigQuery, exporte dados do Netezza, transfira e organize os dados no Google Cloude, em seguida, carregue os dados no BigQuery. Nesta seção, apresentamos uma visão geral de alto nível do processo de migração de dados. Para uma descrição detalhada do processo de migração de dados, consulte Processo de migração de dados e esquema. Para uma comparação detalhada entre os tipos de dados compatíveis com o Netezza e o BigQuery, consulte o Guia de tradução do SQL do IBM Netezza.
Exportar dados do Netezza
Para analisar os dados das tabelas de banco de dados do Netezza, recomendamos que você exporte para uma tabela externa no formato CSV. Para mais informações, consulte Como descarregar dados em um sistema cliente remoto (em inglês). Também é possível ler dados usando sistemas de terceiros, como o Informatica (ou ETL personalizado) usando conectores JDBC/ODBC para produzir arquivos CSV.
O Netezza só permite a exportação de arquivos simples não compactados (CSV) para cada tabela.
Porém, se você estiver exportando tabelas grandes, o CSV não compactado pode ficar muito
grande. Se possível, converta o CSV em um formato compatível com esquemas, como
Parquet, Avro ou ORC, o que resulta em arquivos de exportação menores com maior
confiabilidade. Se o CSV for o único formato disponível, recomendamos que você compacte
os arquivos de exportação para reduzir o tamanho do arquivo antes de fazer upload para Google Cloud.
Reduzir o tamanho do arquivo ajuda a agilizar o upload e aumenta a
confiabilidade da transferência. Se você transferir arquivos para o Cloud Storage, poderá
usar a flag --gzip-local em um
comando gcloud storage cp, que
compacta os arquivos antes de fazer upload deles.
Transferência e preparo de dados
Depois que os dados são exportados, eles precisam ser transferidos e preparados no Google Cloud. Há várias opções para transferir os dados, dependendo da quantidade de dados que você está transferindo e da largura de banda de rede disponível. Para mais informações, consulte Visão geral do esquema e da transferência de dados.
Ao usar a CLI do Google Cloud, é possível automatizar e carregar a transferência de arquivos para o Cloud Storage em paralelo. Limite os tamanhos dos arquivos a 4 TB (descompactados) para acelerar o carregamento no BigQuery. No entanto, é preciso exportar o esquema com antecedência. Essa é uma boa oportunidade para otimizar o BigQuery usando o particionamento e o clustering.
Use gcloud storage bucket create
para criar os buckets de preparo para armazenamento dos dados exportados e gcloud storage cp para transferir os
arquivos de exportação de dados para os buckets do Cloud Storage.
A CLI gcloud executa automaticamente a operação de cópia usando uma combinação de multithreading e multiprocessamento.
Como carregar dados no BigQuery
Depois que os dados são organizados no Google Cloud, há várias opções para carregar os dados no BigQuery. Para mais informações, consulte Carregar o esquema e os dados no BigQuery.
Ferramentas e suporte de parceiros
Receba suporte para parceiros na sua jornada de migração. Para ajudar na migração de código SQL, use a tradução de SQL em lote para migrar o código SQL em massa.
Muitos Google Cloud parceiros também oferecem serviços de migração de data warehouse. Para conferir uma lista de parceiros e as soluções que eles oferecem, consulte Trabalhar com um parceiro com experiência no BigQuery.
Pós-migração
Depois que a migração de dados for concluída, será possível começar a otimizar o uso de Google Cloud para atender às necessidades dos negócios. Isso inclui usar as ferramentas de exploração e visualização doGoogle Cloudpara gerar insights para as partes interessadas da empresa, otimizar consultas de baixo desempenho ou desenvolver um programa para ajudar na adoção do usuário.
Conectar-se às APIs do BigQuery pela Internet
Veja no diagrama a seguir como um aplicativo externo pode se conectar ao BigQuery usando a API:
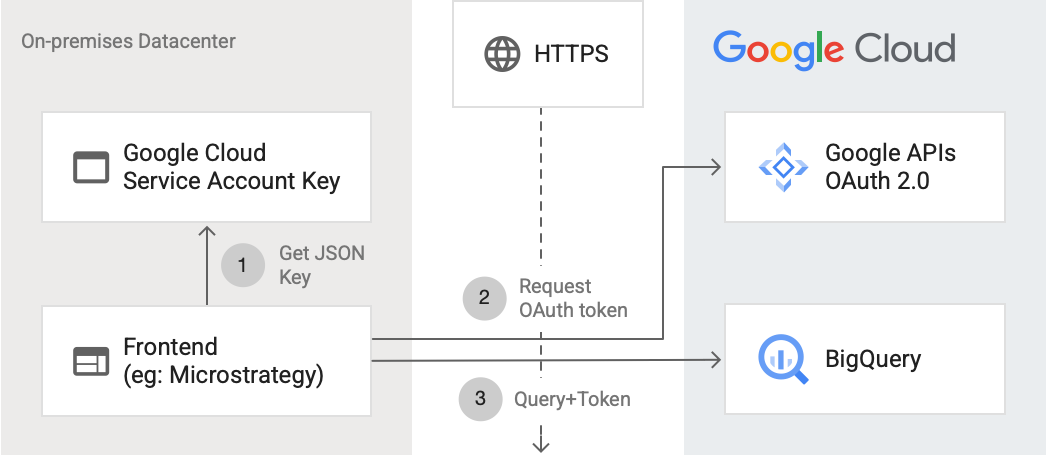
O diagrama mostra as seguintes etapas:
- Em Google Cloud, uma conta de serviço é criada com permissões do IAM. A chave da conta de serviço é gerada no formato JSON e copiada para o servidor de front-end (por exemplo, MicroStrategy).
- O front-end lê a chave e solicita um token OAuth das APIs do Google no HTTPS.
- Em seguida, o front-end enviará solicitações do BigQuery com o token para o BigQuery.
Para mais informações, consulte Como autorizar solicitações de API.
Como otimizar para o BigQuery
O GoogleSQL está em conformidade com o SQL 2011 padrão e tem extensões que aceitam a consulta de dados aninhados e repetidos. A otimização de consultas para o BigQuery é essencial para melhorar o desempenho e o tempo de resposta.
Como substituir a função Months_Between no BigQuery por UDF
O Netezza trata os dias de um mês como 31. A UDF personalizada a seguir recria a função Netezza com precisão aproximada, que pode ser chamada nas consultas:
CREATE TEMP FUNCTION months_between(date_1 DATE, date_2 DATE) AS ( CASE WHEN date_1 = date_2 THEN 0 WHEN EXTRACT(DAY FROM DATE_ADD(date_1, INTERVAL 1 DAY)) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(date_1,date_2, MONTH) WHEN EXTRACT(DAY FROM date_1) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(DATE_ADD(date_1, INTERVAL -1 DAY), date_2, MONTH) + 1/31 ELSE date_diff(date_1, date_2, MONTH) - 1 + ((EXTRACT(DAY FROM date_1) + (31 - EXTRACT(DAY FROM date_2))) / 31) END );
Migrar os procedimentos armazenados do Netezza
Se você usar procedimentos armazenados do Netezza em cargas de trabalho de ETL para criar tabelas de fatos, será necessário migrar esses procedimentos armazenados para consultas SQL compatíveis com o BigQuery. O Netezza usa a linguagem de script NZPLSQL para trabalhar com procedimentos armazenados. O NZPLSQL é baseado na linguagem PL/pgSQL do Postgres. Para mais informações, consulte o Guia de tradução do SQL do IBM Netezza.
UDF personalizada para emular Netezza ASCII
A UDF personalizada a seguir para o BigQuery corrige erros de codificação nas colunas:
CREATE TEMP FUNCTION ascii(X STRING) AS (TO_CODE_POINTS(x)[ OFFSET (0)]);
A seguir
- Saiba como otimizar cargas de trabalho para otimização geral de desempenho e redução de custos.
- Saiba como otimizar o armazenamento no BigQuery.
- Consulte o guia de tradução do SQL do IBM Netezza.