Introdução à otimização do desempenho da consulta
Neste documento, apresentamos uma visão geral das técnicas de otimização que podem melhorar o desempenho das consultas no BigQuery. Em geral, as consultas que fazem menos trabalhos têm um desempenho melhor. Elas são executadas mais rapidamente e consomem menos recursos, o que pode resultar em custos menores e menos falhas.
Desempenho da consulta
A avaliação do desempenho da consulta no BigQuery envolve vários fatores:
- dados de entrada e fontes de dados (E/S): quantos bytes a consulta lê?
- comunicação entre nós (ordem aleatória): quantos bytes a consulta passa para o próximo estágio? Quantos bytes a consulta passa para cada slot?
- Computação: de quanto trabalho de CPU a consulta precisa?
- saídas (materialização): quantos bytes a consulta grava?
- Capacidade e simultaneidade: quantos slots estão disponíveis e quantas outras consultas estão em execução ao mesmo tempo?
- Padrões de consulta: as consultas seguem as práticas recomendadas do SQL?
Para avaliar se consultas específicas ou se você está enfrentando contenção de recursos, use o Cloud Monitoring ou os gráficos de recursos administrativos do BigQuery para monitorar como os jobs do BigQuery consomem recursos ao longo do tempo. Se você identificar uma consulta lenta ou que consome muitos recursos, concentre suas otimizações de desempenho nela.
Alguns padrões de consulta, especialmente aqueles gerados por ferramentas de Business Intelligence, podem ser acelerados usando o BigQuery BI Engine. O BI Engine é um serviço rápido de análise na memória que acelera várias consultas SQL no BigQuery armazenando em cache os dados usados com mais frequência de maneira inteligente. O BI Engine está integrado ao BigQuery, o que significa que é possível ter um desempenho melhor sem qualquer modificação de consulta.
Como acontece com qualquer sistema, a otimização para desempenho às vezes envolve contrapartidas. Por exemplo, usar a sintaxe SQL avançada pode, às vezes, introduzir complexidade e reduzir a capacidade de compreensão das consultas para pessoas que não são especialistas em SQL. Gastar tempo com micro-otimizações para cargas de trabalho não críticas também pode desviar os recursos da criação de novos recursos para seus aplicativos ou de fazer otimizações mais impactantes. Portanto, para ajudar você a alcançar o maior retorno possível do investimento, recomendamos concentrar as otimizações nas cargas de trabalho mais importantes para os pipelines de análise de dados.
Otimização de capacidade e simultaneidade
O BigQuery oferece dois modelos de preço para consultas: preços on demand e baseados em capacidade. O modelo on demand oferece um pool de capacidade compartilhado, e o preço é baseado na quantidade de dados processados em cada consulta executada.
O modelo baseado em capacidade é recomendado quando você quer orçar uma despesa mensal consistente ou quando precisa de mais capacidade do que a disponível no modelo sob demanda. Ao usar preços baseados em capacidade, você aloca uma capacidade dedicada de processamento de consultas medida em slots. O custo de todos os bytes processados está incluso no preço baseado em capacidade. Além dos compromissos de slot fixos, é possível usar slots de escalonamento automático, que fornecem capacidade dinâmica com base na carga de trabalho da consulta.
O desempenho das consultas executadas repetidamente nos mesmos dados pode variar. A variação geralmente é maior para consultas que usam slots on demand do que para consultas que usam reservas de slots.
Durante o processamento de consultas SQL, o BigQuery divide em slots a capacidade computacional necessária para executar cada fase de uma consulta. O BigQuery determina automaticamente o número de consultas que podem ser executadas ao mesmo tempo conforme a seguir:
- Modelo sob demanda: número de slots disponíveis no projeto
- Modelo baseado em capacidade: número de slots disponíveis na reserva
As consultas que exigem mais slots do que os disponíveis são enfileiradas até que os recursos de processamento estejam disponíveis. Depois que uma consulta inicia a execução, o BigQuery calcula quantos slots cada fase usa com base no tamanho e na complexidade dela e no número de slots disponíveis. O BigQuery usa uma técnica chamada programação justa para garantir que cada consulta tenha capacidade suficiente para progredir.
O acesso a mais slots nem sempre resulta em um desempenho mais rápido de uma consulta. No entanto, um pool maior de slots pode melhorar o desempenho de consultas grandes ou complexas e o desempenho de cargas de trabalho altamente simultâneas. Para melhorar o desempenho de consultas, modifique suas reservas de slots ou defina um limite maior para o escalonamento automático de slots.
Plano de consulta e cronograma
O BigQuery gera um plano de consulta sempre que você executa uma consulta. É fundamental entender esse plano para uma otimização eficaz das consultas. O plano de consulta contém estatísticas de execução, como bytes lidos e tempo de slot consumido. O plano de consulta também contém detalhes sobre as diferentes fases de execução, o que pode ajudar a diagnosticar e melhorar o desempenho de consultas. O gráfico de execução de consultas contém uma interface gráfica para visualizar o plano de consulta e diagnosticar problemas de desempenho de consultas.
Também é possível usar o método de API jobs.get ou a visualização INFORMATION_SCHEMA.JOBS para recuperar as informações do cronograma e plano de consulta. Essas informações são usadas pelo BigQuery Visualiser, uma ferramenta de código aberto que representa visualmente o fluxo de fases de execução em um job do BigQuery.
Quando o BigQuery executa um job de consulta, ele converte a instrução SQL declarativa em um gráfico de execução. Esse gráfico é dividido em uma série de estágios de consulta, que são compostos por conjuntos mais granulares de etapas de execução. O BigQuery usa uma arquitetura paralela distribuída pesadamente para executar essas consultas. Os estágios do BigQuery modelam as unidades de trabalho que muitos workers em potencial podem executar paralelamente. Os estágios se comunicam entre si por meio da arquitetura aleatória rápida e distribuída.
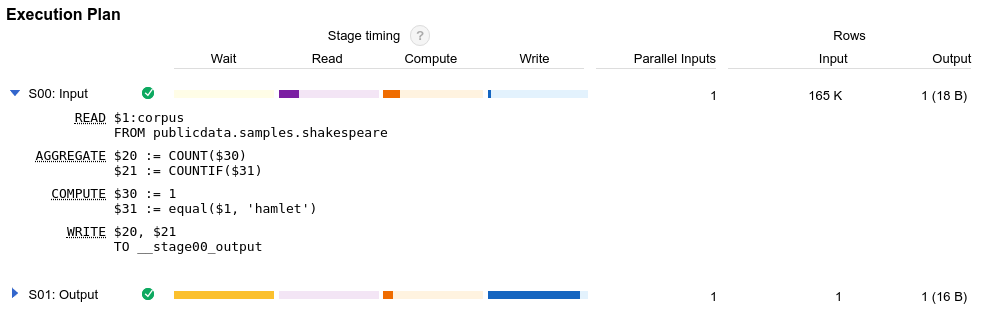
Além do plano de consulta, os jobs de consulta também expõem uma linha do tempo de execução. Ela fornece uma contagem de unidades de trabalho concluídas, pendentes e ativas nos workers de consulta. Uma consulta pode ter vários estágios com workers ativos simultaneamente, de modo que a linha do tempo se destina a mostrar o progresso geral da consulta.
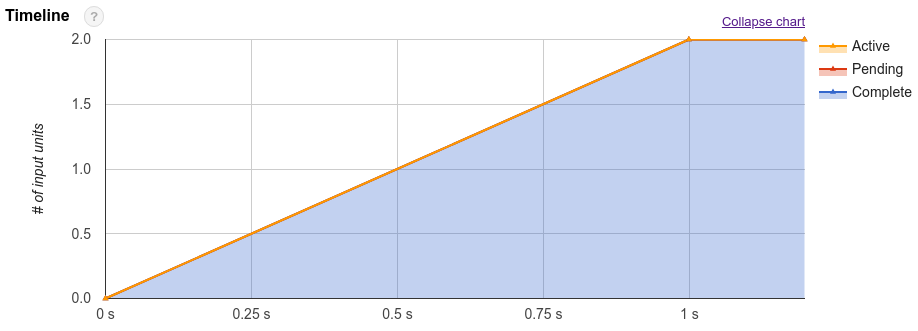
Para estimar o custo computacional de uma consulta, analise o número total de segundos de slot que a consulta consome. Quanto menor o número de segundos de slot, melhor. Isso significa que mais recursos estão disponíveis para outras consultas em execução no mesmo projeto e ao mesmo tempo.
O plano de consulta e as estatísticas da linha do tempo podem ajudar você a entender como o BigQuery executa consultas e se determinados estágios dominam a utilização de recursos. Por exemplo, um cenário JOIN que gere muito mais linhas de saída do que linhas de entrada pode indicar uma oportunidade para filtrar mais cedo na consulta.
No entanto, a natureza gerenciada do serviço limita se alguns detalhes são diretamente úteis. Veja as práticas recomendadas e as técnicas para melhorar a
execução e o desempenho das consultas em
Otimizar a computação de consultas.
A seguir
- Saiba como resolver problemas de execução de consulta usando os registros de auditoria do BigQuery.
- Conheça outras técnicas de controle de custos para o BigQuery.
- Veja metadados quase em tempo real sobre jobs do BigQuery usando a visualização
INFORMATION_SHEMA.JOBS. - Saiba como monitorar o uso do BigQuery usando os relatórios de tabelas do sistema do BigQuery.