Mengelola rekomendasi partisi dan cluster
Dokumen ini menjelaskan cara kerja pemberi rekomendasi partisi dan cluster, cara melihat rekomendasi dan insight Anda, serta cara menerapkan rekomendasi partisi dan cluster.
Cara kerja pemberi rekomendasi
Pemberi rekomendasi partisi dan cluster BigQuery menghasilkan rekomendasi partisi atau cluster untuk mengoptimalkan tabel BigQuery Anda. Pemberi rekomendasi menganalisis alur kerja di tabel BigQuery Anda dan menawarkan rekomendasi untuk lebih mengoptimalkan alur kerja dan membuat kueri biaya dengan lebih baik menggunakan partisi tabel atau pengelompokan tabel.
Untuk informasi selengkapnya tentang layanan Pemberi rekomendasi, lihat Ringkasan pemberi rekomendasi.
Pemberi rekomendasi partisi dan cluster menggunakan data eksekusi workload project dari 30 hari terakhir untuk menganalisis setiap tabel BigQuery guna menemukan konfigurasi partisi dan pengelompokan yang kurang optimal. Pemberi rekomendasi juga menggunakan machine learning untuk memprediksi seberapa banyak eksekusi workload yang dapat dioptimalkan dengan konfigurasi partisi atau cluster yang berbeda. Jika pemberi rekomendasi mendapati bahwa partisi atau pengelompokan tabel menghasilkan penghematan yang signifikan, pemberi rekomendasi akan menghasilkan rekomendasi. Pemberi rekomendasi pembuatan partisi dan cluster akan menghasilkan jenis rekomendasi berikut:
| Jenis tabel yang ada | Subjenis rekomendasi | Contoh rekomendasi |
|---|---|---|
| Tidak dipartisi, tidak dikelompokkan | Partisi | "Hemat sekitar 64 slot jam per bulan dengan membuat partisi pada column_C by DAY" |
| Tidak dipartisi, tidak dikelompokkan | Cluster | "Hemat sekitar 64 jam slot per bulan dengan membuat cluster pada column_C" |
| Dipartisi, tidak dikelompokkan | Cluster | "Hemat sekitar 64 jam slot per bulan dengan membuat cluster pada column_C" |
Setiap rekomendasi terdiri dari tiga bagian:
- Panduan untuk partisi atau cluster tabel tertentu
- Kolom tertentu dalam tabel untuk melakukan partisi atau cluster
- Estimasi penghematan bulanan untuk penerapan rekomendasi
Untuk menghitung potensi penghematan workload, pemberi rekomendasi mengasumsikan bahwa data histori workload eksekusi dari 30 hari terakhir mewakili workload mendatang.
API pemberi rekomendasi juga menampilkan informasi workload tabel dalam bentuk insight. Insight adalah temuan yang membantu Anda memahami workload project, yang memberikan lebih banyak konteks tentang bagaimana rekomendasi partisi atau cluster dapat meningkatkan biaya workload.
Batasan
Pemberi rekomendasi partisi dan cluster tidak mendukung tabel BigQuery dengan SQL lama. Saat membuat rekomendasi, pemberi rekomendasi mengecualikan kueri legacy SQL dalam analisisnya. Selain itu, menerapkan rekomendasi partisi pada tabel BigQuery dengan legacy SQL akan merusak alur kerja legacy SQL di tabel tersebut.
Sebelum menerapkan rekomendasi partisi, migrasikan alur kerja legacy SQL ke GoogleSQL.
BigQuery tidak mendukung perubahan skema partisi tabel di tempat. Anda hanya dapat mengubah partisi tabel pada salinan tabel. Untuk mengetahui informasi selengkapnya, lihat artikel Menerapkan rekomendasi partisi.
Lokasi
Pemberi rekomendasi partisi dan cluster tersedia di lokasi pemrosesan berikut:
| Deskripsi region | Nama region | Detail | |
|---|---|---|---|
| Asia Pasifik | |||
| Delhi | asia-south2 |
||
| Hong Kong | asia-east2 |
||
| Jakarta | asia-southeast2 |
||
| Mumbai | asia-south1 |
||
| Osaka | asia-northeast2 |
||
| Seoul | asia-northeast3 |
||
| Singapura | asia-southeast1 |
||
| Sydney | australia-southeast1 |
||
| Taiwan | asia-east1 |
||
| Tokyo | asia-northeast1 |
||
| Eropa | |||
| Belgia | europe-west1 |
|
|
| Berlin | europe-west10 |
||
| Multi-region Uni Eropa | eu |
||
| Frankfurt | europe-west3 |
||
| London | europe-west2 |
|
|
| Belanda | europe-west4 |
|
|
| Zürich | europe-west6 |
|
|
| Amerika | |||
| Iowa | us-central1 |
|
|
| Las Vegas | us-west4 |
||
| Los Angeles | us-west2 |
||
| Montréal | northamerica-northeast1 |
|
|
| Northern Virginia | us-east4 |
||
| Oregon | us-west1 |
|
|
| Salt Lake City | us-west3 |
||
| Sao Paulo | southamerica-east1 |
|
|
| Toronto | northamerica-northeast2 |
|
|
| Multi-region AS | us |
||
Sebelum memulai
Izin yang diperlukan
Untuk mendapatkan izin yang diperlukan untuk mengakses rekomendasi partisi dan cluster,
minta administrator untuk memberi Anda
peran IAM BigQuery Partitioning Clustering Recommender Viewer (roles/recommender.bigqueryPartitionClusterViewer).
Untuk mengetahui informasi selengkapnya tentang cara memberikan peran, lihat Mengelola akses ke project, folder, dan organisasi.
Peran bawaan ini berisi izin yang diperlukan untuk mengakses rekomendasi partisi dan cluster. Untuk melihat izin yang benar-benar diperlukan, luaskan bagian Izin yang diperlukan:
Izin yang diperlukan
Izin berikut diperlukan untuk mengakses rekomendasi partisi dan cluster:
-
recommender.bigqueryPartitionClusterRecommendations.get -
recommender.bigqueryPartitionClusterRecommendations.list
Anda mungkin juga bisa mendapatkan izin ini dengan peran khusus atau peran bawaan lainnya.
Untuk mengetahui informasi lebih lanjut tentang peran dan izin IAM di BigQuery, baca Pengantar IAM.
Lihat rekomendasi
Bagian ini menjelaskan cara melihat rekomendasi dan insight partisi dan cluster menggunakan Google Cloud konsol, Google Cloud CLI, atau Recommender API.
Pilih salah satu opsi berikut:
Konsol
Di konsol Google Cloud , buka halaman BigQuery.
Di menu navigasi, klik Rekomendasi.
Tab rekomendasi mencantumkan semua rekomendasi yang tersedia untuk project Anda.
Di panel Optimalkan biaya workload BigQuery, klik Lihat semua.
Tabel rekomendasi biaya mencantumkan semua rekomendasi yang dihasilkan untuk project saat ini. Misalnya, screenshot berikut menunjukkan bahwa pemberi rekomendasi menganalisis tabel
example_table, lalu merekomendasikan pengelompokan kolomexample_columnuntuk menyimpan perkiraan jumlah byte dan slot.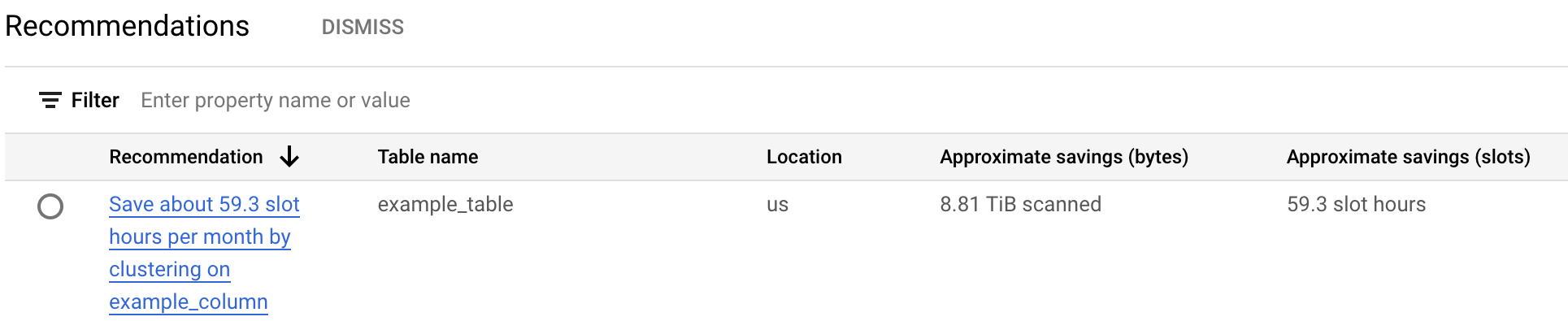
Untuk melihat informasi selengkapnya tentang insight dan rekomendasi tabel, klik rekomendasi.
gcloud
Untuk melihat rekomendasi partisi atau cluster untuk project tertentu, gunakan
perintah gcloud recommender recommendations list:
gcloud recommender recommendations list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--recommender=google.bigquery.table.PartitionClusterRecommender \
--format=FORMAT_TYPE \
Ganti kode berikut:
PROJECT_NAME: nama project yang berisi tabel BigQuery AndaREGION_NAME: region tempat project Anda beradaFORMAT_TYPE: format output gcloud CLI yang didukung—misalnya, JSON
| Properti | Relevan untuk subjenis | Deskripsi |
|---|---|---|
recommenderSubtype |
Partisi atau cluster | Menunjukkan jenis rekomendasi. |
content.overview.partitionColumn |
Partisi | Nama kolom partisi yang direkomendasikan. |
content.overview.partitionTimeUnit |
Partisi | Unit waktu partisi yang direkomendasikan. Misalnya, DAY berarti
rekomendasinya adalah memiliki partisi harian di kolom yang direkomendasikan. |
content.overview.clusterColumns |
Cluster | Nama kolom cluster yang direkomendasikan. |
- Untuk mengetahui informasi selengkapnya tentang kolom lain dalam respons pemberi rekomendasi, lihat Resource REST:
projects.locations.recommendersrecommendation. - Untuk informasi selengkapnya tentang penggunaan Recommender API, lihat Menggunakan API - Rekomendasi.
Untuk melihat insight tabel menggunakan gcloud CLI, gunakan perintah gcloud recommender insights list:
gcloud recommender insights list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--insight-type=google.bigquery.table.StatsInsight \
--format=FORMAT_TYPE \
Ganti kode berikut:
PROJECT_NAME: nama project yang berisi tabel BigQuery AndaREGION_NAME: region tempat project Anda beradaFORMAT_TYPE: format output gcloud CLI yang didukung—misalnya, JSON
| Properti | Relevan untuk subjenis | Deskripsi |
|---|---|---|
content.existingPartitionColumn |
Cluster | Kolom partisi yang ada, jika ada |
content.tableSizeTb |
Semua | Ukuran tabel dalam terabyte |
content.bytesReadMonthly |
Semua | Byte bulanan yang dibaca dari tabel |
content.slotMsConsumedMonthly |
Semua | Slot bulanan dalam milidetik yang terpakai oleh workload yang berjalan di tabel |
content.queryJobsCountMonthly |
Semua | Jumlah tugas bulanan yang berjalan di tabel |
- Untuk mengetahui informasi selengkapnya tentang kolom lain dalam respons insight, lihat Resource REST:
projects.locations.insightTypes.insights. - Untuk informasi selengkapnya tentang penggunaan insight, lihat Menggunakan API - Insight.
REST API
Untuk melihat rekomendasi partisi atau cluster untuk project tertentu, gunakan REST API. Dengan setiap perintah, Anda harus menyediakan token autentikasi, yang bisa Anda dapatkan menggunakan gcloud CLI. Untuk mengetahui informasi lebih lanjut mengenai cara mendapatkan token autentikasi, baca Metode untuk mendapatkan token ID.
Anda dapat menggunakan permintaan curl list untuk melihat semua rekomendasi untuk
project tertentu:
curl
-H "Authorization: Bearer $GCLOUD_AUTH_TOKEN"
-H "x-goog-user-project: PROJECT_NAME" https://recommender.googleapis.com/v1/projects/my-project/locations/us/recommenders/google.bigquery.table.PartitionClusterRecommender/recommendations
Ganti kode berikut:
GCLOUD_AUTH_TOKEN: nama token akses gcloud CLI yang validPROJECT_NAME: nama project yang berisi tabel BigQuery Anda
| Properti | Relevan untuk subjenis | Deskripsi |
|---|---|---|
recommenderSubtype |
Partisi atau cluster | Menunjukkan jenis rekomendasi. |
content.overview.partitionColumn |
Partisi | Nama kolom partisi yang direkomendasikan. |
content.overview.partitionTimeUnit |
Partisi | Unit waktu partisi yang direkomendasikan. Misalnya, DAY berarti
rekomendasinya adalah memiliki partisi harian di kolom yang direkomendasikan. |
content.overview.clusterColumns |
Cluster | Nama kolom cluster yang direkomendasikan. |
- Untuk mengetahui informasi selengkapnya tentang kolom lain dalam respons pemberi rekomendasi, lihat Resource REST:
projects.locations.recommendersrecommendation. - Untuk informasi selengkapnya tentang penggunaan Recommender API, lihat Menggunakan API - Rekomendasi.
Untuk melihat insight tabel menggunakan REST API, jalankan perintah berikut:
curl -H "Authorization: Bearer $GCLOUD_AUTH_TOKEN" -H "x-goog-user-project: PROJECT_NAME" https://recommender.googleapis.com/v1/projects/my-project/locations/us/insightTypes/google.bigquery.table.StatsInsight/insights
Ganti kode berikut:
GCLOUD_AUTH_TOKEN: nama token akses gcloud CLI yang validPROJECT_NAME: nama project yang berisi tabel BigQuery Anda
| Properti | Relevan untuk subjenis | Deskripsi |
|---|---|---|
content.existingPartitionColumn |
Cluster | Kolom partisi yang ada, jika ada |
content.tableSizeTb |
Semua | Ukuran tabel dalam terabyte |
content.bytesReadMonthly |
Semua | Byte bulanan yang dibaca dari tabel |
content.slotMsConsumedMonthly |
Semua | Slot bulanan dalam milidetik yang terpakai oleh workload yang berjalan di tabel |
content.queryJobsCountMonthly |
Semua | Jumlah tugas bulanan yang berjalan di tabel |
- Untuk mengetahui informasi selengkapnya tentang kolom lain dalam respons insight, lihat Resource REST:
projects.locations.insightTypes.insights. - Untuk informasi selengkapnya tentang penggunaan insight, lihat Menggunakan API - Insight.
Melihat rekomendasi dengan INFORMATION_SCHEMA
Anda juga dapat melihat rekomendasi dan insight menggunakan tampilan INFORMATION_SCHEMA
Misalnya, Anda dapat menggunakan tampilan INFORMATION_SCHEMA.RECOMMENDATIONS untuk melihat tiga rekomendasi teratas berdasarkan penghematan slot, seperti yang terlihat dalam contoh berikut:
SELECT
recommender,
target_resources,
LAX_INT64(additional_details.overview.bytesSavedMonthly) / POW(1024, 3) as est_gb_saved_monthly,
LAX_INT64(additional_details.overview.slotMsSavedMonthly) / (1000 * 3600) as slot_hours_saved_monthly,
last_updated_time
FROM
`region-us`.INFORMATION_SCHEMA.RECOMMENDATIONS
WHERE
primary_impact.category = 'COST'
AND
state = 'ACTIVE'
ORDER by
slot_hours_saved_monthly DESC
LIMIT 3;
Hasilnya mirip dengan berikut ini:
+---------------------------------------------------+--------------------------------------------------------------------------------------------------+ | recommender | target_resources | est_gb_saved_monthly | slot_hours_saved_monthly | last_updated_time +---------------------------------------------------+--------------------------------------------------------------------------------------------------+ | google.bigquery.materializedview.Recommender | ["project_resource"] | 140805.38289248943 | 9613.139166666666 | 2024-07-01 13:00:00 | google.bigquery.table.PartitionClusterRecommender | ["table_resource_1"] | 4393.7416711859405 | 56.61476777777777 | 2024-07-01 13:00:00 | google.bigquery.table.PartitionClusterRecommender | ["table_resource_2"] | 3934.07264107652 | 10.499466666666667 | 2024-07-01 13:00:00 +---------------------------------------------------+--------------------------------------------------------------------------------------------------+
Untuk informasi selengkapnya, lihat referensi berikut:
INFORMATION_SCHEMA.RECOMMENDATIONSlihatINFORMATION_SCHEMA.RECOMMENDATIONS_BY_ORGANIZATIONlihatINFORMATION_SCHEMA.INSIGHTSlihat
Menerapkan rekomendasi cluster
Untuk menerapkan rekomendasi cluster, lakukan salah satu hal berikut:
- Menerapkan cluster langsung ke tabel asli
- Menerapkan cluster ke tabel yang disalin
- Menerapkan cluster dalam tampilan terwujud
Menerapkan cluster langsung ke tabel asli
Anda dapat menerapkan rekomendasi cluster langsung ke tabel BigQuery yang ada. Metode ini lebih cepat daripada menerapkan rekomendasi ke tabel yang disalin, tetapi tidak mempertahankan tabel cadangan.
Ikuti langkah-langkah berikut untuk menerapkan spesifikasi pengelompokan baru ke tabel yang tidak dipartisi atau dipartisi.
Pada alat bq, perbarui spesifikasi pengelompokan tabel agar sesuai dengan pengelompokan baru:
bq update --clustering_fields=CLUSTER_COLUMN DATASET.ORIGINAL_TABLE
Ganti yang berikut ini:
CLUSTER_COLUMN: kolom tempat Anda melakukan pengelompokan—misalnya,mycolumnDATASET: nama set data yang berisi tabel—misalnya,mydatasetORIGINAL_TABLE: nama tabel asli—misalnya,mytable
Anda juga dapat memanggil metode API
tables.updateatautables.patchuntuk mengubah spesifikasi pengelompokan.Untuk mengelompokkan semua baris sesuai dengan spesifikasi pengelompokan baru, jalankan pernyataan
UPDATEberikut:UPDATE DATASET.ORIGINAL_TABLE SET CLUSTER_COLUMN=CLUSTER_COLUMN WHERE true
Menerapkan cluster ke tabel yang disalin
Saat menerapkan rekomendasi cluster ke tabel BigQuery, Anda dapat menyalin tabel asli terlebih dahulu, lalu menerapkan rekomendasi tersebut ke tabel yang disalin. Metode ini memastikan data asli Anda dipertahankan jika Anda perlu me-roll back perubahan ke konfigurasi cluster.
Anda dapat menggunakan metode ini untuk menerapkan rekomendasi cluster ke tabel yang tidak dipartisi dan dipartisi.
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, buat tabel kosong dengan metadata yang sama (termasuk spesifikasi cluster) dari tabel asli menggunakan operator
LIKE:CREATE TABLE DATASET.COPIED_TABLE LIKE DATASET.ORIGINAL_TABLE
Ganti kode berikut:
DATASET: nama set data yang berisi tabel—misalnya,mydatasetCOPIED_TABLE: nama untuk tabel yang disalin—misalnya,copy_mytableORIGINAL_TABLE: nama tabel asli Anda—misalnya,mytable
Di konsol Google Cloud , buka Cloud Shell Editor.
Di Cloud Shell Editor, perbarui spesifikasi pengelompokkan dari tabel yang disalin agar sesuai dengan pengelompokan yang direkomendasikan menggunakan perintah
bq update:bq update --clustering_fields=CLUSTER_COLUMN DATASET.COPIED_TABLE
Ganti
CLUSTER_COLUMNdengan kolom yang sedang Anda kelompokkan—misalnya,mycolumn.Anda juga dapat memanggil metode API
tables.updateatautables.patchuntuk mengubah spesifikasi cluster.Di editor kueri, ambil skema tabel dengan konfigurasi partisi dan cluster tabel asli, jika ada partisi atau cluster. Anda dapat mengambil skema dengan melihat tampilan
INFORMATION_SCHEMA.TABLESdari tabel asli:SELECT ddl FROM DATASET.INFORMATION_SCHEMA.TABLES WHERE table_name = 'DATASET.ORIGINAL_TABLE;'
Output-nya adalah pernyataan bahasa definisi data lengkap (DDL) dari ORIGINAL_TABLE, termasuk klausa
PARTITION BY. Untuk mengetahui informasi selengkapnya tentang argumen dalam output DDL Anda, lihat pernyataanCREATE TABLE.Output DDL menunjukkan jenis partisi dalam tabel asli:
Jenis partisi Contoh output Tidak dipartisi Klausa PARTITION BYtidak ada.Dipartisi menurut kolom tabel PARTITION BY c0PARTITION BY DATE(c0)PARTITION BY DATETIME_TRUNC(c0, MONTH)Dipartisi menurut waktu penyerapan PARTITION BY _PARTITIONDATEPARTITION BY DATETIME_TRUNC(_PARTITIONTIME, MONTH)Menyerap data ke dalam tabel yang disalin. Proses yang digunakan didasarkan pada jenis partisi.
- Jika tabel asli tidak dipartisi atau dipartisi oleh kolom tabel,
serap data dari tabel asli ke tabel yang disalin:
INSERT INTO DATASET.COPIED_TABLE SELECT * FROM DATASET.ORIGINAL_TABLE
Jika tabel asli dipartisi menurut waktu penyerapan, ikuti langkah-langkah berikut:
Ambil daftar kolom untuk membentuk ekspresi penyerapan data dengan menggunakan tampilan
INFORMATION_SCHEMA.COLUMNS:SELECT ARRAY_TO_STRING(( SELECT ARRAY( SELECT column_name FROM DATASET.INFORMATION_SCHEMA.COLUMNS WHERE table_name = 'ORIGINAL_TABLE')), ", ")
Output-nya adalah daftar nama kolom yang dipisahkan koma.
Menyerap data dari tabel asli ke tabel yang disalin:
INSERT DATASET.COPIED_TABLE (COLUMN_NAMES, _PARTITIONTIME) SELECT *, _PARTITIONTIME FROM DATASET.ORIGINAL_TABLE
Ganti
COLUMN_NAMESdengan daftar kolom yang merupakan output pada langkah sebelumnya, yang dipisahkan dengan koma—misalnya,col1, col2, col3.
Anda sekarang memiliki tabel salinan yang dikelompokkan dengan data yang sama seperti tabel asli. Pada langkah berikutnya, Anda akan mengganti tabel asli dengan tabel yang baru dikelompokkan.
- Jika tabel asli tidak dipartisi atau dipartisi oleh kolom tabel,
serap data dari tabel asli ke tabel yang disalin:
Mengganti nama tabel asli menjadi tabel cadangan:
ALTER TABLE DATASET.ORIGINAL_TABLE RENAME TO DATASET.BACKUP_TABLE
Ganti
BACKUP_TABLEdengan nama untuk tabel cadangan Anda—misalnya,backup_mytable.Ganti nama tabel salinan menjadi tabel asli:
ALTER TABLE DATASET.COPIED_TABLE RENAME TO DATASET.ORIGINAL_TABLE
Tabel asli Anda sekarang dikelompokkan sesuai dengan rekomendasi cluster.
- Akses dan izin, seperti izin IAM, akses tingkat baris, atau akses tingkat kolom.
- Artefak tabel seperti clone tabel, snapshot tabel, atau indeks penelusuran.
- Status setiap proses tabel yang sedang berlangsung, seperti tampilan terwujud atau tugas apa pun yang dijalankan saat Anda menyalin tabel.
- Kemampuan untuk mengakses data tabel historis menggunakan perjalanan waktu.
- Metadata apa pun yang terkait dengan tabel asli—misalnya,
table_option_listataucolumn_option_list. Untuk mengetahui informasi selengkapnya, lihat Pernyataan bahasa definisi data.
Jika muncul masalah, Anda harus memigrasikan artefak yang terpengaruh secara manual ke tabel baru.
Setelah meninjau tabel yang dikelompokkan, Anda dapat memilih untuk menghapus tabel cadangan dengan perintah berikut:DROP TABLE DATASET.BACKUP_TABLE
Menerapkan cluster dalam tampilan terwujud
Anda dapat membuat tampilan terwujud dari tabel untuk menyimpan data dari tabel asli dengan menerapkan rekomendasi. Menggunakan tampilan terwujud untuk menerapkan rekomendasi memastikan bahwa data yang dikelompokkan terus diperbarui menggunakan pembaruan otomatis. Ada pertimbangan harga saat Anda membuat kueri, mempertahankan, dan menyimpan tampilan terwujud. Untuk mempelajari cara membuat tampilan terwujud yang dikelompokkan, lihat Tampilan terwujud yang dikelompokkan.Menerapkan rekomendasi partisi
Untuk menerapkan rekomendasi partisi, Anda harus menerapkannya ke salinan tabel asli. BigQuery tidak mendukung perubahan skema partisi tabel di tempat, seperti mengubah tabel yang tidak dipartisi menjadi tabel berpartisi, mengubah skema partisi tabel, atau membuat tampilan terwujud dengan skema partisi yang berbeda dari tabel dasar. Anda hanya dapat mengubah partisi tabel pada salinan tabel.
Terapkan rekomendasi partisi ke tabel yang disalin
Saat menerapkan rekomendasi partisi ke tabel BigQuery, Anda harus menyalin tabel asli terlebih dahulu, lalu menerapkan rekomendasi tersebut ke tabel yang disalin. Pendekatan ini memastikan data asli tetap dipertahankan jika Anda perlu me-roll back partisi.
Prosedur berikut menggunakan contoh rekomendasi untuk mempartisi tabel berdasarkan
unit waktu partisi DAY.
Buat tabel yang disalin menggunakan rekomendasi partisi:
CREATE TABLE DATASET.COPIED_TABLE PARTITION BY DATE_TRUNC(PARTITION_COLUMN, DAY) AS SELECT * FROM DATASET.ORIGINAL_TABLE
Ganti kode berikut:
DATASET: nama set data yang berisi tabel—misalnya,mydatasetCOPIED_TABLE: nama untuk tabel yang disalin—misalnya,copy_mytablePARTITION_COLUMN: kolom tempat Anda membuat partisi—misalnya,mycolumn
Untuk informasi selengkapnya tentang cara membuat tabel yang dipartisi, lihat Membuat tabel yang dipartisi.
Mengganti nama tabel asli menjadi tabel cadangan:
ALTER TABLE DATASET.ORIGINAL_TABLE RENAME TO DATASET.BACKUP_TABLE
Ganti
BACKUP_TABLEdengan nama untuk tabel cadangan Anda—misalnya,backup_mytable.Ganti nama tabel salinan menjadi tabel asli:
ALTER TABLE DATASET.COPIED_TABLE RENAME TO DATASET.ORIGINAL_TABLE
Tabel asli Anda kini dipartisi menurut rekomendasi partisi.
- Akses dan izin, seperti izin IAM, akses tingkat baris, atau akses tingkat kolom.
- Artefak tabel seperti clone tabel, snapshot tabel, atau indeks penelusuran.
- Status setiap proses tabel yang sedang berlangsung, seperti tampilan terwujud atau tugas apa pun yang dijalankan saat Anda menyalin tabel.
- Kemampuan untuk mengakses data tabel historis menggunakan perjalanan waktu.
- Metadata apa pun yang terkait dengan tabel asli—misalnya,
table_option_listataucolumn_option_list. Untuk mengetahui informasi selengkapnya, lihat Pernyataan bahasa definisi data. - Kemampuan menggunakan legacy SQL untuk menulis hasil kueri ke dalam tabel yang dipartisi. Penggunaan legacy SQL tidak sepenuhnya didukung dalam tabel yang dipartisi. Salah satu solusinya adalah memigrasikan alur kerja legacy SQL ke GoogleSQL sebelum menerapkan rekomendasi partisi.
Jika muncul masalah, Anda harus memigrasikan artefak yang terpengaruh secara manual ke tabel baru.
Setelah meninjau tabel yang dipartisi, Anda dapat memilih untuk menghapus tabel cadangan dengan perintah berikut:DROP TABLE DATASET.BACKUP_TABLE
Harga
Saat menerapkan rekomendasi ke tabel, Anda dapat dikenai biaya berikut:
- Biaya pemrosesan. Saat menerapkan rekomendasi, Anda akan mengeksekusi kueri bahasa definisi data (DDL) atau bahasa pengolahan data (DML) ke project BigQuery.
- Biaya penyimpanan. Jika Anda menggunakan metode penyalinan tabel, Anda menggunakan penyimpanan tambahan untuk tabel yang disalin (atau cadangan).
Biaya pemrosesan dan penyimpanan standar berlaku, tergantung pada akun penagihan yang terkait dengan project. Untuk informasi lebih lanjut, lihat Harga BigQuery.
Pemecahan masalah
Masalah: Tidak ada rekomendasi yang muncul untuk tabel tertentu.
Rekomendasi partisi mungkin tidak muncul untuk tabel yang memenuhi kriteria berikut:
- Ukuran tabel kurang dari 100 GB.
- Tabel sudah dipartisi atau dikelompokkan.
Rekomendasi cluster mungkin tidak muncul untuk tabel yang memenuhi kriteria berikut:
- Ukuran tabel kurang dari 10 GB.
- Tabel sudah dikelompokkan.
Rekomendasi partisi dan cluster dapat disembunyikan jika:
- Tabel ini memiliki biaya tulis yang tinggi dari operasi bahasa pengolahan data (DML).
- Tabel tidak dibaca dalam 30 hari terakhir.
- Estimasi penghematan bulanan terlalu tidak signifikan (penghematan kurang dari 1 slot jam).