This tutorial shows you how to import an Open Neural Network Exchange (ONNX) model that's trained with scikit-learn. You import the model into a BigQuery dataset and use it to make predictions using a SQL query.
ONNX provides a uniform format that is designed to represent any machine learning (ML) framework. BigQuery ML support for ONNX lets you do the following:
- Train a model using your favorite framework.
- Convert the model into the ONNX model format.
- Import the ONNX model into BigQuery and make predictions using BigQuery ML.
Objectives
- Create and train a model using scikit-learn.
- Convert the model to ONNX format using sklearn-onnx.
- Use the
CREATE MODELstatement to import the ONNX model into BigQuery. - Use the
ML.PREDICTfunction to make predictions with the imported ONNX model.
Costs
In this document, you use the following billable components of Google Cloud:
To generate a cost estimate based on your projected usage,
use the pricing calculator.
When you finish the tasks that are described in this document, you can avoid continued billing by deleting the resources that you created. For more information, see Clean up.
Before you begin
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Ensure that you have the necessary permissions to perform the tasks in this document.
Required roles
If you create a new project, you're the project owner, and you're granted all of the required Identity and Access Management (IAM) permissions that you need to complete this tutorial.
If you're using an existing project, do the following.
Make sure that you have the following role or roles on the project:
- BigQuery Studio Admin (
roles/bigquery.studioAdmin) - Storage Object Creator (
roles/storage.objectCreator)
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
- Click Grant access.
-
In the New principals field, enter your user identifier. This is typically the email address for a Google Account.
- In the Select a role list, select a role.
- To grant additional roles, click Add another role and add each additional role.
- Click Save.
For more information about IAM permissions in BigQuery, see IAM permissions.
Optional: Train a model and convert it to ONNX format
The following code samples show you how to train a classification model with
scikit-learn and how to convert the resulting pipeline into ONNX format. This
tutorial uses a prebuilt example model that's stored at
gs://cloud-samples-data/bigquery/ml/onnx/pipeline_rf.onnx. You don't have to
complete these steps if you're using the sample model.
Train a classification model with scikit-learn
Use the following sample code to create and train a scikit-learn pipeline on the Iris dataset. For instructions about installing and using scikit-learn, see the scikit-learn installation guide.
import numpy
from sklearn.datasets import load_iris
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
data = load_iris()
X = data.data[:, :4]
y = data.target
ind = numpy.arange(X.shape[0])
numpy.random.shuffle(ind)
X = X[ind, :].copy()
y = y[ind].copy()
pipe = Pipeline([('scaler', StandardScaler()),
('clr', RandomForestClassifier())])
pipe.fit(X, y)
Convert the pipeline into an ONNX model
Use the following sample code in sklearn-onnx to convert the scikit-learn
pipeline into an ONNX model that's named pipeline_rf.onnx.
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
# Disable zipmap as it is not supported in BigQuery ML.
options = {id(pipe): {'zipmap': False}}
# Define input features. scikit-learn does not store information about the
# training dataset. It is not always possible to retrieve the number of features
# or their types. That's why the function needs another argument called initial_types.
initial_types = [
('sepal_length', FloatTensorType([None, 1])),
('sepal_width', FloatTensorType([None, 1])),
('petal_length', FloatTensorType([None, 1])),
('petal_width', FloatTensorType([None, 1])),
]
# Convert the model.
model_onnx = convert_sklearn(
pipe, 'pipeline_rf', initial_types=initial_types, options=options
)
# And save.
with open('pipeline_rf.onnx', 'wb') as f:
f.write(model_onnx.SerializeToString())
Upload the ONNX model to Cloud Storage
After you save your model, do the following:
- Create a Cloud Storage bucket to store the model.
- Upload the ONNX model to your Cloud Storage bucket.
Create a dataset
Create a BigQuery dataset to store your ML model.
Console
In the Google Cloud console, go to the BigQuery page.
In the Explorer pane, click your project name.
Click View actions > Create dataset
On the Create dataset page, do the following:
For Dataset ID, enter
bqml_tutorial.For Location type, select Multi-region, and then select US (multiple regions in United States).
Leave the remaining default settings as they are, and click Create dataset.
bq
To create a new dataset, use the
bq mk command
with the --location flag. For a full list of possible parameters, see the
bq mk --dataset command
reference.
Create a dataset named
bqml_tutorialwith the data location set toUSand a description ofBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Instead of using the
--datasetflag, the command uses the-dshortcut. If you omit-dand--dataset, the command defaults to creating a dataset.Confirm that the dataset was created:
bq ls
API
Call the datasets.insert
method with a defined dataset resource.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Before trying this sample, follow the BigQuery DataFrames setup instructions in the BigQuery quickstart using BigQuery DataFrames. For more information, see the BigQuery DataFrames reference documentation.
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up ADC for a local development environment.
Import the ONNX model into BigQuery
The following steps show you how to import the sample ONNX model from
Cloud Storage by using a CREATE MODEL statement.
To import the ONNX model into your dataset, select one of the following options:
Console
In the Google Cloud console, go to the BigQuery Studio page.
In the query editor, enter the following
CREATE MODELstatement.CREATE OR REPLACE MODEL `bqml_tutorial.imported_onnx_model` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='BUCKET_PATH')
Replace
BUCKET_PATHwith the path to the model that you uploaded to Cloud Storage. If you're using the sample model, replaceBUCKET_PATHwith the following value:gs://cloud-samples-data/bigquery/ml/onnx/pipeline_rf.onnx.When the operation is complete, you see a message similar to the following:
Successfully created model named imported_onnx_model.Your new model appears in the Resources panel. Models are indicated by the model icon:
 If you select the new model in the Resources panel, information
about the model appears adjacent to the Query editor.
If you select the new model in the Resources panel, information
about the model appears adjacent to the Query editor.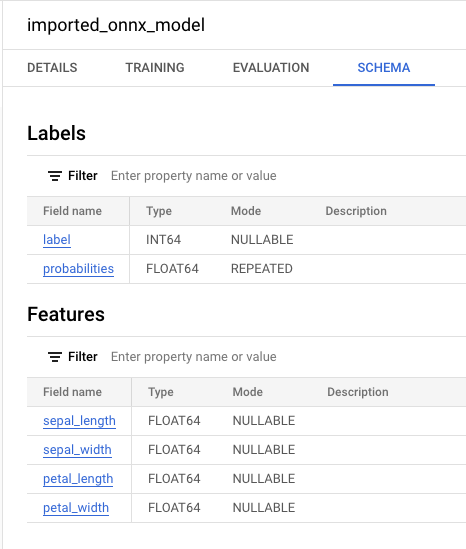
bq
Import the ONNX model from Cloud Storage by entering the following
CREATE MODELstatement.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.imported_onnx_model` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='BUCKET_PATH')"
Replace
BUCKET_PATHwith the path to the model that you uploaded to Cloud Storage. If you're using the sample model, replaceBUCKET_PATHwith the following value:gs://cloud-samples-data/bigquery/ml/onnx/pipeline_rf.onnx.When the operation is complete, you see a message similar to the following:
Successfully created model named imported_onnx_model.After you import the model, verify that the model appears in the dataset.
bq ls -m bqml_tutorial
The output is similar to the following:
tableId Type --------------------- ------- imported_onnx_model MODEL
BigQuery DataFrames
Before trying this sample, follow the BigQuery DataFrames setup instructions in the BigQuery quickstart using BigQuery DataFrames. For more information, see the BigQuery DataFrames reference documentation.
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up ADC for a local development environment.
Import the model by using the ONNXModel object.
For more information about importing ONNX models into BigQuery,
including format and storage requirements, see The CREATE MODEL statement for
importing ONNX models.
Make predictions with the imported ONNX model
After importing the ONNX model, you use the ML.PREDICT function to make
predictions with the model.
The query in the following steps uses imported_onnx_model to make predictions
using input data from the iris table in the ml_datasets public dataset. The
ONNX model expects four FLOAT values as input:
sepal_lengthsepal_widthpetal_lengthpetal_width
These inputs match the initial_types that were defined when you converted the
model into ONNX format.
The outputs include the label and probabilities columns, and the columns
from the input table. label represents the predicted class label.
probabilities is an array of probabilities representing probabilities for
each class.
To make predictions with the imported ONNX model, choose one of the following options:
Console
Go to the BigQuery Studio page.
In the query editor, enter this query that uses the
ML.PREDICTfunction.SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.imported_onnx_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.iris` ) )
The query results are similar to the following:
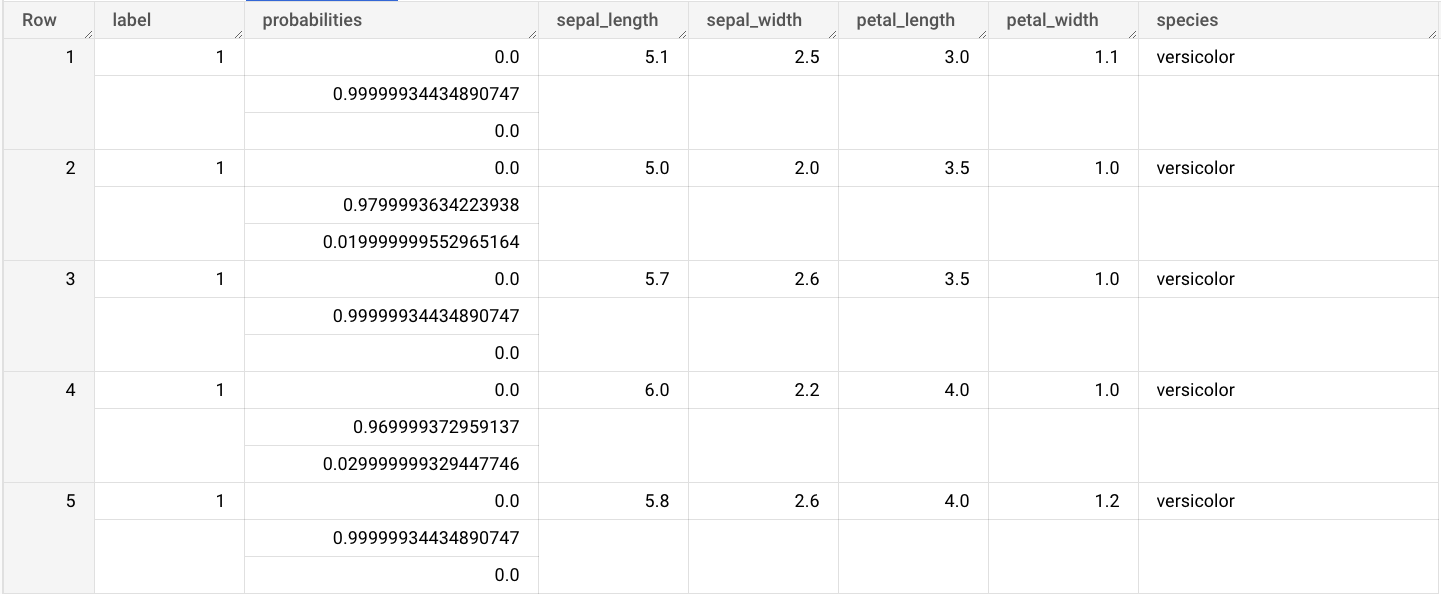
bq
Run the query that uses ML.PREDICT.
bq query --use_legacy_sql=false \ 'SELECT * FROM ML.PREDICT( MODEL `example_dataset.imported_onnx_model`, (SELECT * FROM `bigquery-public-data.ml_datasets.iris`))'
BigQuery DataFrames
Before trying this sample, follow the BigQuery DataFrames setup instructions in the BigQuery quickstart using BigQuery DataFrames. For more information, see the BigQuery DataFrames reference documentation.
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up ADC for a local development environment.
Use the predict function to run the ONNX model.
The result is similar to the following:
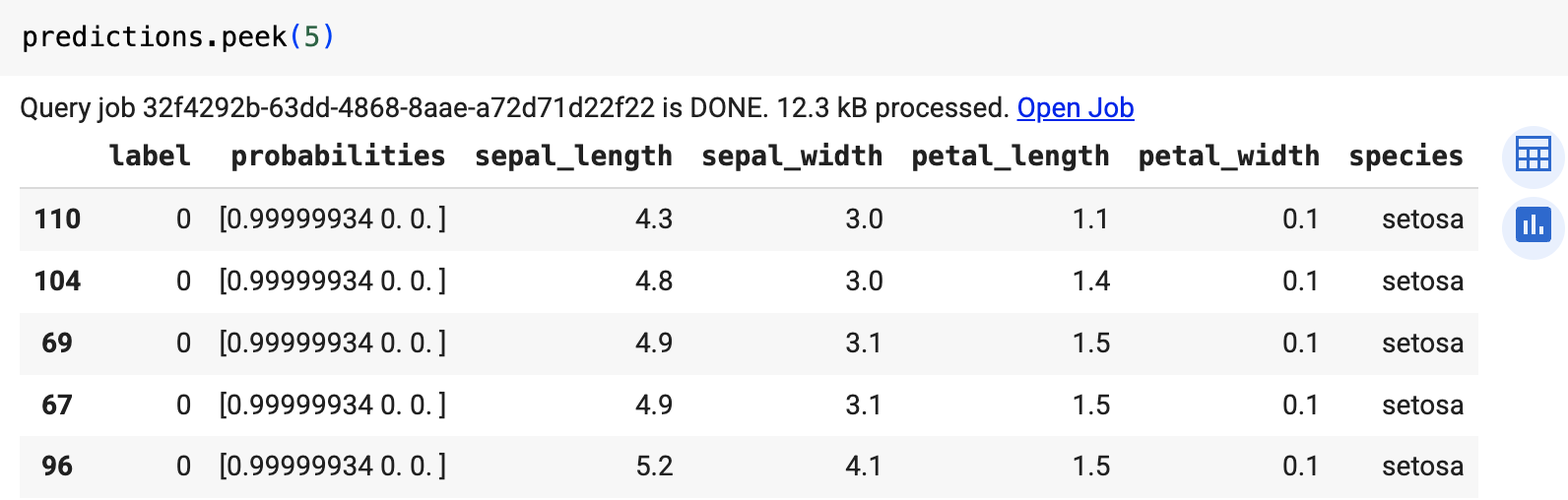
Clean up
To avoid incurring charges to your Google Cloud account for the resources used in this tutorial, either delete the project that contains the resources, or keep the project and delete the individual resources.
Delete the project
Console
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
gcloud
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Delete individual resources
Alternatively, to remove the individual resources used in this tutorial, do the following:
Optional: Delete the dataset.
What's next
- For more information about importing ONNX models, see
The
CREATE MODELstatement for ONNX models. - For more information about available ONNX converters and tutorials, see Converting to ONNX format.
- For an overview of BigQuery ML, see Introduction to BigQuery ML.
- To get started using BigQuery ML, see Create machine learning models in BigQuery ML.