Neste tutorial, vai usar um modelo de regressão logística binário no BigQuery ML para prever o intervalo de rendimentos de indivíduos com base nos respetivos dados demográficos. Um modelo de regressão logística binária prevê se um valor se enquadra numa de duas categorias, neste caso,se o rendimento anual de um indivíduo é superior ou inferior a 50 000 $.
Este tutorial usa o conjunto de dados
bigquery-public-data.ml_datasets.census_adult_income. Este conjunto de dados contém as informações demográficas e de rendimento dos residentes nos EUA de 2000 e 2010.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Autorizações necessárias
Para criar o modelo com o BigQuery ML, precisa das seguintes autorizações de IAM:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
Para executar a inferência, precisa das seguintes autorizações:
bigquery.models.getDatano modelobigquery.jobs.create
Introdução
Uma tarefa comum na aprendizagem automática é classificar os dados num de dois tipos, conhecidos como etiquetas. Por exemplo, um retalhista pode querer prever se um determinado cliente vai comprar um novo produto com base noutras informações sobre esse cliente. Nesse caso, as duas etiquetas podem ser will buy e won't buy. O retalhista pode criar um conjunto de dados de forma que uma coluna represente ambas as etiquetas e também contenha informações do cliente, como a localização do cliente, as compras anteriores e as preferências comunicadas. Em seguida, o retalhista pode usar um modelo de regressão logística binária que usa estas informações dos clientes para prever que etiqueta representa melhor cada cliente.
Neste tutorial, vai criar um modelo de regressão logística binária que prevê se o rendimento de um participante do censo dos EUA se enquadra num de dois intervalos com base nos atributos demográficos do participante.
Crie um conjunto de dados
Crie um conjunto de dados do BigQuery para armazenar o seu modelo:
Na Google Cloud consola, aceda à página BigQuery.
No painel esquerdo, clique em Explorador:

Se não vir o painel do lado esquerdo, clique em Expandir painel do lado esquerdo para o abrir.
No painel Explorador, clique no nome do projeto.
Clique em Ver ações > Criar conjunto de dados.
Na página Criar conjunto de dados, faça o seguinte:
Para o ID do conjunto de dados, introduza
census.Em Tipo de localização, selecione Várias regiões e, de seguida, EUA (várias regiões nos Estados Unidos).
Os conjuntos de dados públicos são armazenados na
USregião múltipla. Para simplificar, armazene o conjunto de dados na mesma localização.Deixe as restantes predefinições como estão e clique em Criar conjunto de dados.
Examine os dados
Examine o conjunto de dados e identifique as colunas a usar como dados de preparação para o modelo de regressão logística. Selecione 100 linhas da tabela census_adult_income:
SQL
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, execute a seguinte consulta GoogleSQL:
SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, functional_weight FROM `bigquery-public-data.ml_datasets.census_adult_income` LIMIT 100;
Os resultados têm um aspeto semelhante ao seguinte:

DataFrames do BigQuery
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
Os resultados da consulta mostram que a coluna income_bracket na tabela census_adult_income tem apenas um de dois valores: <=50K ou >50K.
Prepare os dados de amostra
Neste tutorial, vai prever o rendimento dos inquiridos do censo com base nos valores das seguintes colunas na tabela census_adult_income:
age: a idade do inquirido.workclass: classe de trabalho realizado. Por exemplo, governo local, privado ou trabalhador por conta própria.marital_statuseducation_num: o nível académico mais elevado do inquirido.occupationhours_per_week: horas trabalhadas por semana.
Exclui colunas que duplicam dados. Por exemplo, a coluna education, porque os valores das colunas education e education_num expressam os mesmos dados em formatos diferentes.
A coluna functional_weight é o número de indivíduos que a organização do censo considera que uma linha específica representa. Uma vez que o valor desta coluna não está relacionado com o valor de income_bracket para qualquer linha específica, usa o valor nesta coluna para separar os dados em conjuntos de preparação, avaliação e previsão criando uma nova coluna dataframe derivada da coluna functional_weight. Etiqueta 80% dos dados para preparar o modelo, 10% dos dados para avaliação e 10% dos dados para previsão.
SQL
Crie uma vista com os dados de amostra.
Esta vista é usada pela declaração CREATE MODEL mais adiante neste tutorial.
Execute a consulta que prepara os dados de exemplo:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, execute a seguinte consulta:
CREATE OR REPLACE VIEW `census.input_data` AS SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, CASE WHEN MOD(functional_weight, 10) < 8 THEN 'training' WHEN MOD(functional_weight, 10) = 8 THEN 'evaluation' WHEN MOD(functional_weight, 10) = 9 THEN 'prediction' END AS dataframe FROM `bigquery-public-data.ml_datasets.census_adult_income`;
Veja os dados de amostra:
SELECT * FROM `census.input_data`;
DataFrames do BigQuery
Cria um DataFrame chamado input_data. Vai usar input_data mais tarde neste tutorial para preparar o modelo, avaliá-lo e fazer previsões.
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
Crie um modelo de regressão logística
Crie um modelo de regressão logística com os dados de preparação que etiquetou na secção anterior.
SQL
Use a declaração
CREATE MODEL
e especifique LOGISTIC_REG para o tipo de modelo.
Seguem-se aspetos úteis a ter em conta acerca da declaração CREATE MODEL:
A opção
input_label_colsespecifica que coluna na declaraçãoSELECTdeve ser usada como a coluna de etiqueta. Aqui, a coluna de etiqueta éincome_bracket, pelo que o modelo aprende qual dos dois valores deincome_bracketé mais provável para uma determinada linha com base nos outros valores presentes nessa linha.Não é necessário especificar se um modelo de regressão logística é binário ou multiclasse. O BigQuery ML determina que tipo de modelo deve ser preparado com base no número de valores únicos na coluna de etiqueta.
A opção
auto_class_weightsestá definida comoTRUEpara equilibrar as etiquetas de classe nos dados de preparação. Por predefinição, os dados de preparação não têm ponderação. Se as etiquetas nos dados de preparação estiverem desequilibradas, o modelo pode aprender a prever a classe de etiquetas mais popular de forma mais intensa. Neste caso, a maioria dos inquiridos no conjunto de dados pertence ao grupo de rendimentos mais baixo. Isto pode levar a um modelo que prevê demasiado a classe de rendimento mais baixa. Os pesos das classes equilibram as etiquetas das classes calculando os pesos de cada classe na proporção inversa da frequência dessa classe.A opção
enable_global_explainestá definida comoTRUEpara lhe permitir usar a funçãoML.GLOBAL_EXPLAINno modelo mais tarde no tutorial.A declaração
SELECTconsulta a vistainput_dataque contém os dados de amostra. A cláusulaWHEREfiltra as linhas para que apenas as linhas etiquetadas como dados de preparação sejam usadas para preparar o modelo.
Execute a consulta que cria o seu modelo de regressão logística:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, execute a seguinte consulta:
CREATE OR REPLACE MODEL `census.census_model` OPTIONS ( model_type='LOGISTIC_REG', auto_class_weights=TRUE, enable_global_explain=TRUE, data_split_method='NO_SPLIT', input_label_cols=['income_bracket'], max_iterations=15) AS SELECT * EXCEPT(dataframe) FROM `census.input_data` WHERE dataframe = 'training'
No painel esquerdo, clique em Explorador:
No painel Explorador, clique em Conjuntos de dados.
No painel Conjuntos de dados, clique em
census.Clique no separador Modelos.
Clique em
census_model.O separador Detalhes apresenta os atributos que o BigQuery ML usou para realizar a regressão logística.
DataFrames do BigQuery
Use o método
fit
para preparar o modelo e o método
to_gbq
para o guardar no seu conjunto de dados.
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
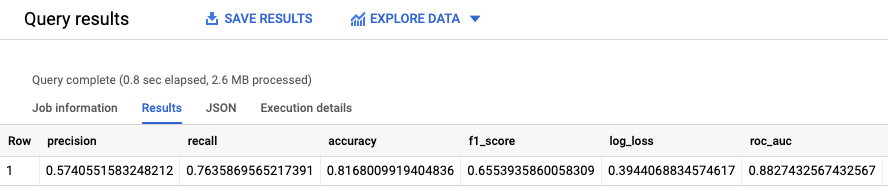
Avalie o desempenho do modelo
Depois de criar o modelo, avalie o respetivo desempenho em função dos dados de avaliação.
SQL
A função
ML.EVALUATE
avalia os valores previstos gerados pelo modelo em comparação com os dados de avaliação.
Para a entrada, a função ML.EVALUATE usa o modelo preparado e as linhas da vista input_data que têm evaluation como o valor da coluna dataframe. A função devolve uma única linha de estatísticas sobre o modelo.
Execute a consulta ML.EVALUATE:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, execute a seguinte consulta:
SELECT * FROM ML.EVALUATE (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation' ) );
Os resultados têm um aspeto semelhante ao seguinte:
DataFrames do BigQuery
Use o método
score
para avaliar o modelo em função dos dados reais.
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
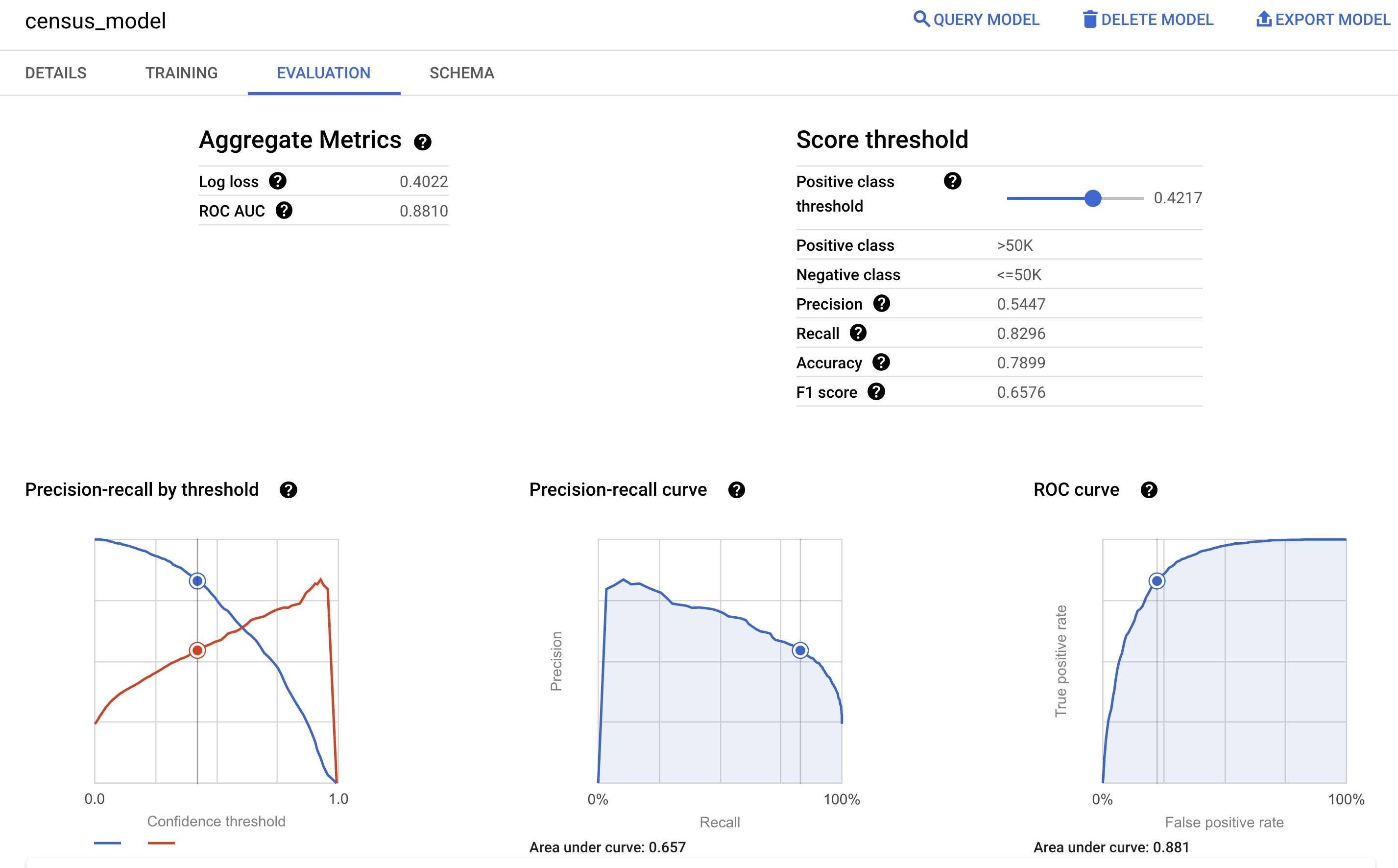
Também pode consultar o painel Avaliação do modelo na Google Cloud consola para ver as métricas de avaliação calculadas durante a preparação:
Preveja o intervalo de rendimento
Use o modelo para prever o intervalo de rendimentos mais provável para cada participante.
SQL
Use a
função ML.PREDICT
para fazer previsões sobre a faixa de rendimentos provável. Para a entrada, a função
ML.PREDICT usa o modelo preparado e as linhas da vista
input_data que têm prediction como valor da coluna dataframe.
Execute a consulta ML.PREDICT:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, execute a seguinte consulta:
SELECT * FROM ML.PREDICT (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'prediction' ) );
Os resultados têm um aspeto semelhante ao seguinte:
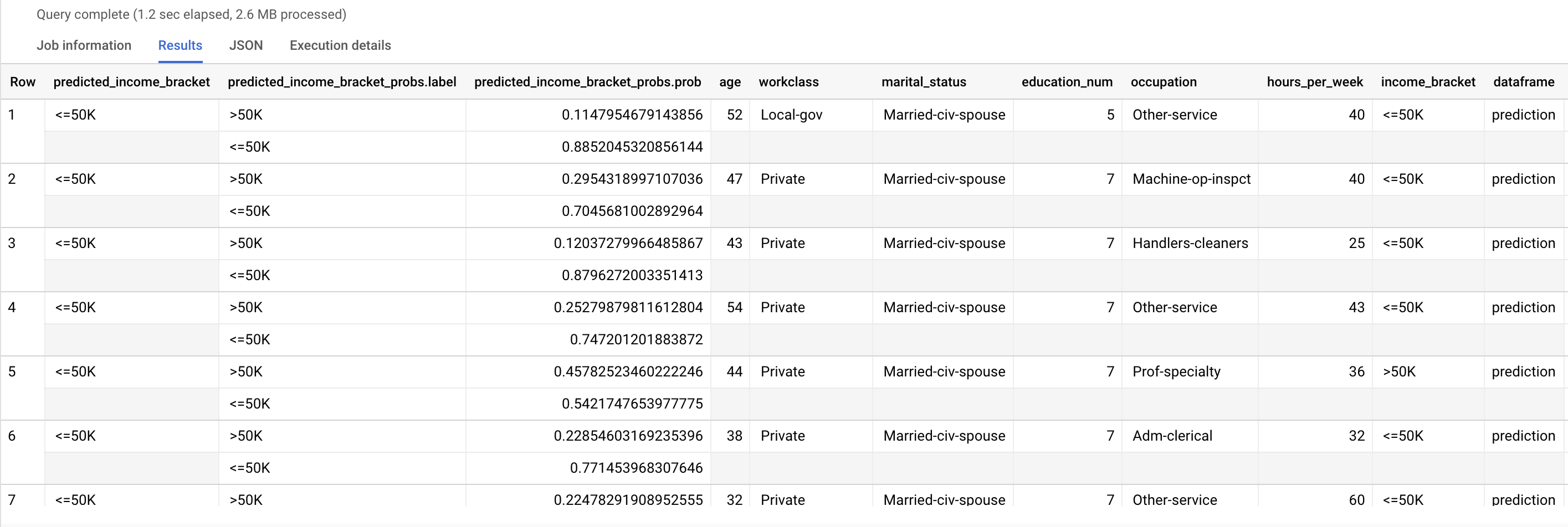
A coluna predicted_income_bracket contém o intervalo de rendimento previsto para o respondente.
DataFrames do BigQuery
Use o método
predict
para fazer previsões sobre a faixa de rendimento provável.
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
Explique os resultados da previsão
Para compreender por que motivo o modelo está a gerar estes resultados de previsão, pode usar a função ML.EXPLAIN_PREDICT.
ML.EXPLAIN_PREDICT é uma versão expandida da função ML.PREDICT.
ML.EXPLAIN_PREDICT não só produz resultados de previsão, como também produz colunas adicionais para explicar os resultados de previsão. Para mais informações
acerca da explicabilidade, consulte a
vista geral da IA explicável do BigQuery ML.
Execute a consulta ML.EXPLAIN_PREDICT:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, execute a seguinte consulta:
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation'), STRUCT(3 as top_k_features));
Os resultados têm um aspeto semelhante ao seguinte:
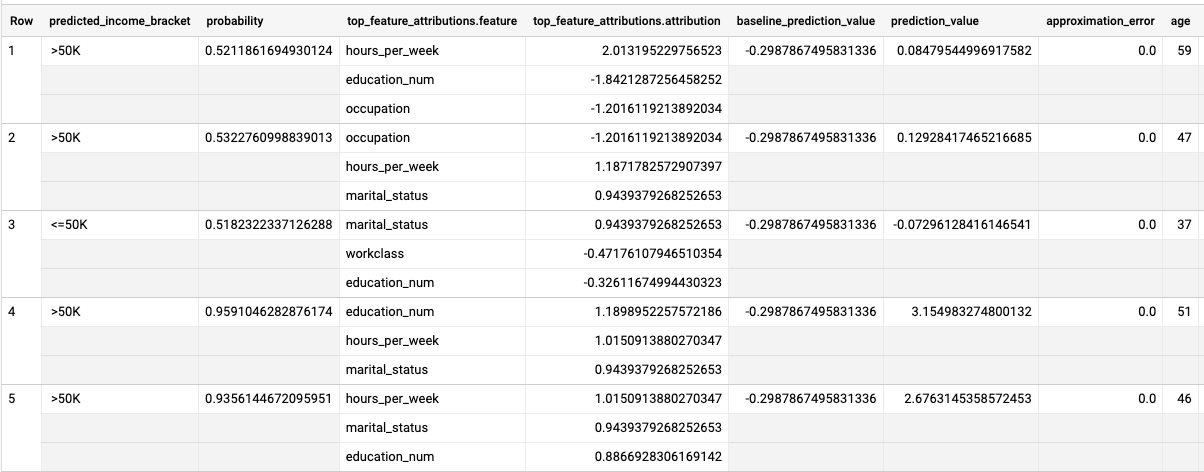
Para modelos de regressão logística, os valores de Shapley são usados para determinar a atribuição de caraterísticas relativa para cada caraterística no modelo. Uma vez que a opção foi definida como top_k_features
na consulta, 3 produz as três principais
atribuições de funcionalidades para cada linha da vista ML.EXPLAIN_PREDICT.input_data Estas atribuições são apresentadas por ordem descendente do valor absoluto da atribuição.
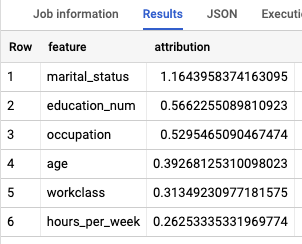
Explicar o modelo globalmente
Para saber que funcionalidades são mais importantes para determinar o intervalo de rendimentos,
use a função
ML.GLOBAL_EXPLAIN.
Obtenha explicações globais para o modelo:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, execute a seguinte consulta para obter explicações globais:
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `census.census_model`)
Os resultados têm um aspeto semelhante ao seguinte: