Este tutorial ensina-o a usar um modelo k-means no BigQuery ML para identificar clusters num conjunto de dados.
O algoritmo k-means que agrupa os seus dados em clusters é uma forma de aprendizagem automática não supervisionada. Ao contrário da aprendizagem automática supervisionada, que se centra na análise preditiva, a aprendizagem automática não supervisionada centra-se na análise descritiva. A aprendizagem automática não supervisionada pode ajudar a compreender os seus dados para que possa tomar decisões baseadas em dados.
As consultas neste tutorial usam funções geográficas disponíveis nas estatísticas geoespaciais. Para mais informações, consulte o artigo Introdução à estatística geoespacial.
Este tutorial usa o conjunto de dados público London Bicycle Hires. Os dados incluem datas/horas de início e de fim, nomes das estações e duração da viagem.
Objetivos
Este tutorial explica como concluir as seguintes tarefas:- Examine os dados usados para preparar o modelo.
- Crie um modelo de clustering k-means.
- Interprete os clusters de dados produzidos através da visualização dos clusters do BigQuery ML.
- Execute a
função
ML.PREDICTno modelo k-means para prever o cluster provável para um conjunto de estações de aluguer de bicicletas.
Custos
Este tutorial usa componentes faturáveis do Google Cloud, incluindo o seguinte:
- BigQuery
- BigQuery ML
Para informações sobre os custos do BigQuery, consulte a página de preços do BigQuery.
Para informações sobre os custos do BigQuery ML, consulte os preços do BigQuery ML.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- O BigQuery é ativado automaticamente em novos projetos.
Para ativar o BigQuery num projeto pré-existente, aceda a
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Para criar o conjunto de dados, precisa da autorização
bigquery.datasets.createIAM.Para criar o modelo, precisa das seguintes autorizações:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
Para executar a inferência, precisa das seguintes autorizações:
bigquery.models.getDatabigquery.jobs.create
Autorizações necessárias
Para mais informações acerca das funções e autorizações do IAM no BigQuery, consulte o artigo Introdução ao IAM.
Crie um conjunto de dados
Crie um conjunto de dados do BigQuery para armazenar o seu modelo de k-means:
Na Google Cloud consola, aceda à página do BigQuery.
No painel Explorador, clique no nome do projeto.
Clique em Ver ações > Criar conjunto de dados.
Na página Criar conjunto de dados, faça o seguinte:
Para o ID do conjunto de dados, introduza
bqml_tutorial.Para Tipo de localização, selecione Multirregional e, de seguida, selecione UE (várias regiões na União Europeia).
O conjunto de dados público London Bicycle Hires está armazenado na
EUmultirregião. O conjunto de dados tem de estar no mesmo local.Deixe as restantes predefinições como estão e clique em Criar conjunto de dados.

Examine os dados de preparação
Examine os dados que vai usar para preparar o seu modelo de k-means. Neste tutorial, vai agrupar estações de bicicletas com base nos seguintes atributos:
- Duração dos alugueres
- Número de viagens por dia
- Distância do centro da cidade
SQL
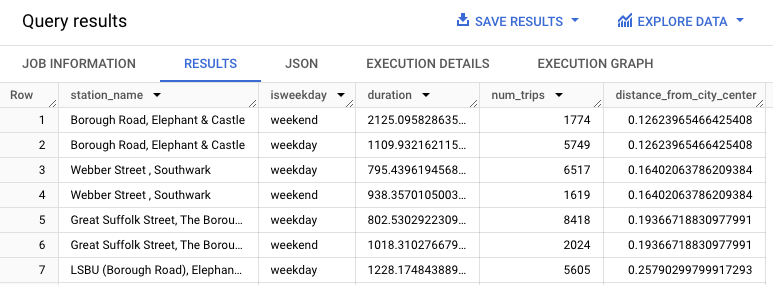
Esta consulta extrai dados sobre alugueres de bicicletas, incluindo as colunas start_station_name
e duration, e junta estes dados com informações sobre as estações. Isto inclui a criação de uma coluna calculada que contém a distância da estação ao centro da cidade. Em seguida, calcula os atributos da estação numa coluna stationstats, incluindo a duração média das viagens e o número de viagens, bem como a coluna distance_from_city_center calculada.
Siga estes passos para examinar os dados de preparação:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, cole a seguinte consulta e clique em Executar:
WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * FROM stationstats ORDER BY distance_from_city_center ASC;
Os resultados devem ter um aspeto semelhante ao seguinte:
DataFrames do BigQuery
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
Crie um modelo de k-means
Crie um modelo k-means com dados de preparação de alugueres de bicicletas de Londres.
SQL
Na consulta seguinte, a declaração CREATE MODEL especifica o número de clusters a usar: quatro. Na declaração SELECT, a cláusula EXCEPT exclui a coluna station_name porque esta coluna não contém uma funcionalidade. A consulta cria uma linha única por station_name e apenas as funcionalidades são mencionadas na declaração SELECT.
Siga estes passos para criar um modelo de k-means:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, cole a seguinte consulta e clique em Executar:
CREATE OR REPLACE MODEL `bqml_tutorial.london_station_clusters` OPTIONS ( model_type = 'kmeans', num_clusters = 4) AS WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT (station_name, isweekday) FROM stationstats;
DataFrames do BigQuery
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
Interprete os clusters de dados
As informações no separador Avaliação do modelo podem ajudar a interpretar os clusters produzidos pelo modelo.
Siga estes passos para ver as informações de avaliação do modelo:
Na Google Cloud consola, aceda à página BigQuery.
No painel Explorador, expanda o projeto, expanda o conjunto de dados
bqml_tutoriale, de seguida, expanda a pasta Modelos.Selecione o modelo
london_station_clusters.Selecione o separador Avaliação. Este separador apresenta visualizações dos clusters identificados pelo modelo k-means. Na secção Caraterísticas numéricas, os gráficos de barras apresentam os valores das caraterísticas numéricas mais importantes para cada centroide. Cada centroide representa um determinado cluster de dados. Pode selecionar as funcionalidades a visualizar no menu pendente.
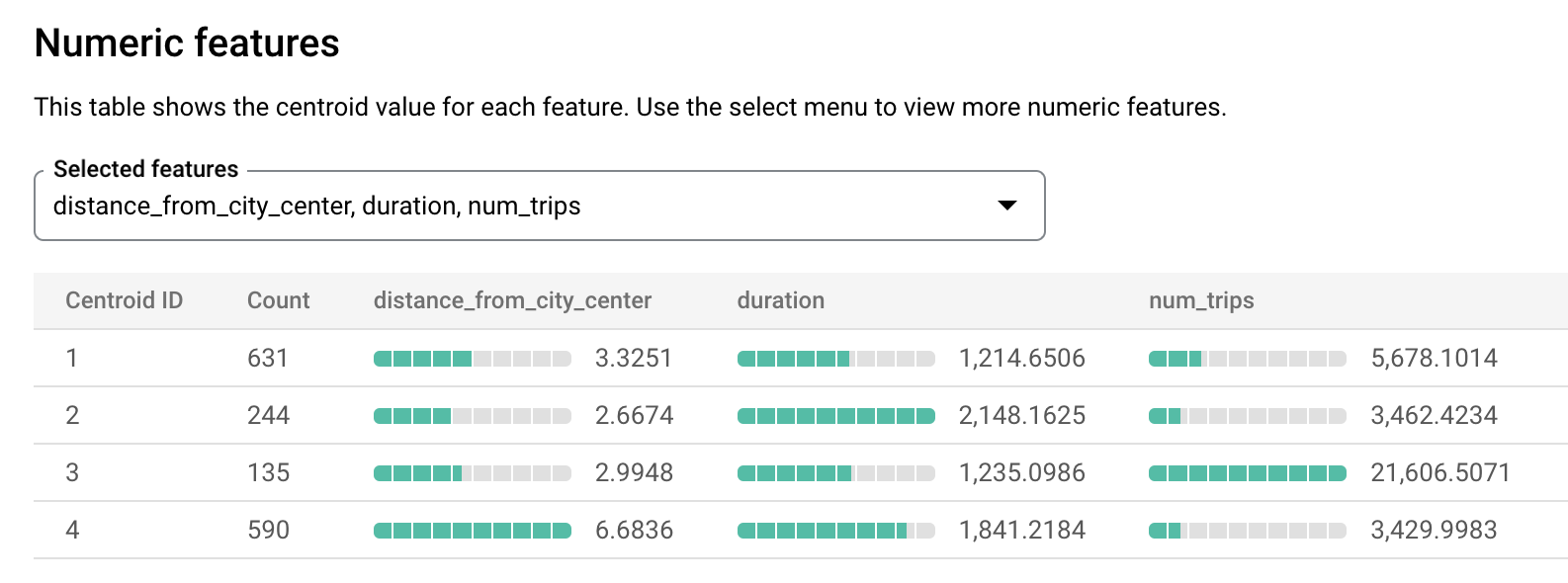
Este modelo cria os seguintes centroides:
- O centroide 1 mostra uma estação da cidade menos movimentada, com alugueres de menor duração.
- O centroide 2 mostra a segunda estação da cidade, que tem menos movimento e é usada para alugueres de maior duração.
- O centroide 3 mostra uma estação da cidade movimentada perto do centro da cidade.
- O centroide 4 mostra uma estação suburbana com viagens mais longas.
Se estivesse a gerir a empresa de aluguer de bicicletas, podia usar estas informações para tomar decisões empresariais. Por exemplo:
Suponha que precisa de experimentar um novo tipo de fechadura. Que cluster de estações deve escolher como assunto para esta experiência? As estações no centroide 1, centroide 2 ou centroide 4 parecem escolhas lógicas porque não são as estações mais movimentadas.
Suponha que quer ter algumas estações com bicicletas de corrida. Que estações deve escolher? O centroide 4 é o grupo de estações que estão longe do centro da cidade e têm as viagens mais longas. Estes são candidatos prováveis para bicicletas de corrida.
Use a função ML.PREDICT para prever o cluster de uma estação
Identifique o cluster ao qual uma determinada estação pertence através da função SQL ML.PREDICT ou da função predict BigQuery DataFrames.
SQL
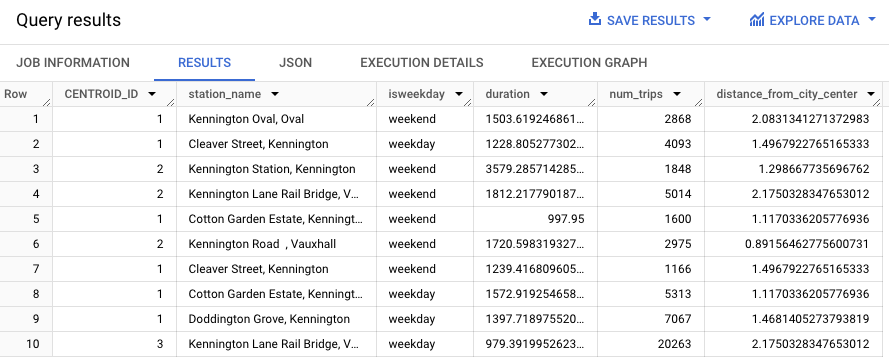
A consulta seguinte usa a função
REGEXP_CONTAINS
para encontrar todas as entradas na coluna station_name que contêm a string Kennington. A função ML.PREDICT usa esses valores para prever
que clusters podem conter essas estações.
Siga estes passos para prever o cluster de cada estação que tenha a string Kennington no nome:
Na Google Cloud consola, aceda à página BigQuery.
No editor de consultas, cole a seguinte consulta e clique em Executar:
WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT (nearest_centroids_distance) FROM ML.PREDICT( MODEL `bqml_tutorial.london_station_clusters`, ( SELECT * FROM stationstats WHERE REGEXP_CONTAINS(station_name, 'Kennington') ));
Os resultados devem ser semelhantes aos seguintes.
DataFrames do BigQuery
Antes de experimentar este exemplo, siga as instruções de configuração dos DataFrames do BigQuery no início rápido do BigQuery com os DataFrames do BigQuery. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure o ADC para um ambiente de desenvolvimento local.
Limpar
Para evitar incorrer em custos na sua conta do Google Cloud pelos recursos usados neste tutorial, elimine o projeto que contém os recursos ou mantenha o projeto e elimine os recursos individuais.
- Pode eliminar o projeto que criou.
- Em alternativa, pode manter o projeto e eliminar o conjunto de dados.
Elimine o conjunto de dados
A eliminação do projeto remove todos os conjuntos de dados e todas as tabelas no projeto. Se preferir reutilizar o projeto, pode eliminar o conjunto de dados que criou neste tutorial:
Se necessário, abra a página do BigQuery na Google Cloud consola.
Na navegação, clique no conjunto de dados bqml_tutorial que criou.
Clique em Eliminar conjunto de dados no lado direito da janela. Esta ação elimina o conjunto de dados e o modelo.
Na caixa de diálogo Eliminar conjunto de dados, confirme o comando de eliminação escrevendo o nome do conjunto de dados (
bqml_tutorial) e, de seguida, clique em Eliminar.
Elimine o projeto
Para eliminar o projeto:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
O que se segue?
- Para uma vista geral do BigQuery ML, consulte o artigo Introdução ao BigQuery ML.
- Para obter informações sobre como criar modelos, consulte a página de sintaxe
CREATE MODEL.