Utiliser le plug-in BigQuery JupyterLab
Pour demander un commentaire ou une assistance pour cette fonctionnalité, envoyez un e-mail à l'adresse bigquery-ide-plugin@google.com.
Ce document vous explique comment installer et utiliser le plug-in BigQuery JupyterLab pour effectuer les opérations suivantes :
- Explorez vos données BigQuery.
- Utilisez l'API BigQuery DataFrames.
- Déployez un notebook BigQuery DataFrames sur Cloud Composer
Le plug-in BigQuery JupyterLab inclut toutes les fonctionnalités du plug-in Dataproc JupyterLab, comme la création d'un modèle d'exécution sans serveur Dataproc, le lancement et la gestion des notebooks, le développement avec Apache Spark, le déploiement de votre code, et la gestion de vos ressources.
Installer le plug-in BigQuery JupyterLab
Pour installer et utiliser le plug-in BigQuery JupyterLab, procédez comme suit :
Dans votre terminal local, vérifiez que Python 3.8 ou une version ultérieure est installé sur votre système :
python3 --versionDans votre terminal local, initialisez gcloud CLI :
gcloud initInstallez Pipenv, un outil d'environnement virtuel Python :
pip3 install pipenvCréez un environnement virtuel :
pipenv shellInstallez JupyterLab dans le nouvel environnement virtuel :
pipenv install jupyterlabInstallez le plug-in BigQuery JupyterLab :
pipenv install bigquery-jupyter-pluginSi la version de JupyterLab que vous avez installée est antérieure à la version 4.0.0, activez l'extension du plug-in :
jupyter server extension enable bigquery_jupyter_pluginLancez JupyterLab :
jupyter labJupyterLab s'ouvre dans votre navigateur.
Modifier les paramètres de votre projet et de votre région
Par défaut, votre session s'exécute dans le projet et la région que vous avez définis en exécutant gcloud init. Pour modifier les paramètres de projet et de région, procédez comme suit :
- Dans le menu JupyterLab, cliquez sur Paramètres > Paramètres Google BigQuery.
Vous devez redémarrer le plug-in pour que les modifications prennent effet.
Explorer les données
Pour travailler avec vos données BigQuery dans JupyterLab, procédez comme suit :
- Dans la barre latérale JupyterLab, ouvrez le volet Explorateur d'ensembles de données : cliquez sur l'icône Ensembles de données
 .
. Pour développer un projet, dans le volet Explorateur d'ensembles de données, cliquez sur la flèche de développement à côté du nom du projet.
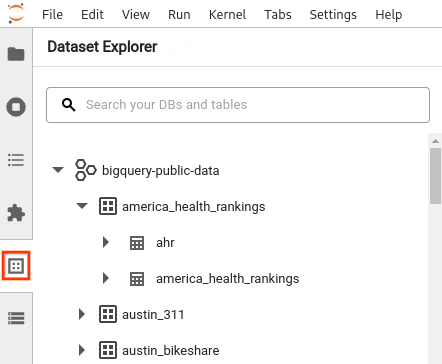
Le volet Explorateur d'ensembles de données affiche tous les ensembles de données d'un projet qui se trouvent dans la région BigQuery que vous avez configurée pour la session. Vous pouvez interagir avec un projet et un ensemble de données de différentes manières :
- Pour afficher des informations sur un ensemble de données, cliquez sur son nom.
- Pour afficher toutes les tables d'un ensemble de données, cliquez sur la flèche de développement à côté de l'ensemble de données.
- Pour afficher des informations sur une table, cliquez sur son nom.
- Pour modifier la région du projet ou de BigQuery, modifiez vos paramètres.
Exécuter des notebooks
Pour interroger vos données BigQuery à partir de JupyterLab, procédez comme suit :
- Pour ouvrir la page du lanceur d'applications, cliquez sur Fichier > Nouveau lanceur d'applications.
- Dans la section Notebooks BigQuery, cliquez sur la fiche BigQuery DataFrames. Un nouveau notebook s'ouvre et vous montre comment faire vos premiers pas avec BigQuery DataFrames.
Les notebooks BigQuery DataFrames sont compatibles avec le développement Python dans un noyau Python local. Les opérations BigQuery DataFrames sont exécutées à distance sur BigQuery, mais le reste du code est exécuté localement sur votre machine. Lorsqu'une opération est exécutée dans BigQuery, un ID de job de requête et le lien vers le job apparaissent sous la cellule de code.
- Pour afficher le job dans la console Google Cloud , cliquez sur Ouvrir le job.
Déployer un notebook BigQuery DataFrames
Vous pouvez déployer un notebook BigQuery DataFrames sur Cloud Composer à l'aide d'un modèle d'exécution sans serveur Dataproc. Vous devez utiliser une version d'exécution 2.1 ou ultérieure.
- Dans votre notebook JupyterLab, cliquez sur calendar_monthPlanificateur de jobs.
- Dans le champ Nom du job, saisissez un nom unique pour votre job.
- Dans le champ Environnement, saisissez le nom de l'environnement Cloud Composer dans lequel vous souhaitez déployer le job.
- Si votre notebook est paramétré, ajoutez des paramètres.
- Saisissez le nom du modèle d'exécution sans serveur.
- Pour gérer les échecs d'exécution des notebooks, saisissez un entier pour Nombre de tentatives et une valeur (en minutes) pour Délai avant nouvelle tentative.
Sélectionnez les notifications d'exécution à envoyer, puis saisissez les destinataires.
Les notifications sont envoyées à l'aide de la configuration SMTP d'Airflow.
Sélectionnez une programmation pour le notebook.
Cliquez sur Créer.
Une fois votre notebook programmé, il apparaît dans la liste des tâches programmées de l'environnement Cloud Composer sélectionné.
Étapes suivantes
- Consultez le guide de démarrage rapide sur BigQuery DataFrames.
- Apprenez-en plus sur l'API Python BigQuery DataFrames
- Utilisez JupyterLab pour les sessions de notebook et le traitement par lot sans serveur avec Dataproc.