Tablas de BigLake para Apache Iceberg en BigQuery
Las tablas de BigLake para Apache Iceberg en BigQuery (en adelante, tablas de BigLake Iceberg en BigQuery) proporcionan la base para compilar lakehouses de formato abierto en Google Cloud. Las tablas de BigLake Iceberg en BigQuery ofrecen la misma experiencia completamente administrada que las tablas estándar de BigQuery, pero almacenan datos en buckets de almacenamiento que pertenecen al cliente. Las tablas de BigLake Iceberg en BigQuery admiten el formato de tabla de Iceberg abierto para una mejor interoperabilidad con los motores de procesamiento de código abierto y de terceros en una sola copia de los datos.
Las tablas de BigLake para Apache Iceberg en BigQuery son distintas de las tablas externas de Apache Iceberg. Las tablas de BigLake para Apache Iceberg en BigQuery son tablas completamente administradas que se pueden modificar directamente en BigQuery, mientras que las tablas externas de Apache Iceberg son administradas por el cliente y ofrecen acceso de solo lectura desde BigQuery.
Las tablas de BigLake Iceberg en BigQuery admiten las siguientes funciones:
- Mutaciones de tablas con el lenguaje de manipulación de datos (DML) de GoogleSQL
- Transmisión continua unificada por lotes y de alta capacidad de procesamiento con la API de Storage Write a través de conectores de BigLake, como Spark, Dataflow y otros motores.
- Exportación de instantáneas de Iceberg V2 y actualización automática en cada mutación de la tabla para el acceso directo a las consultas con motores de consultas de código abierto y de terceros.
- Evolución del esquema, que te permite agregar, descartar y cambiar el nombre de las columnas según tus necesidades. Esta función también te permite cambiar el tipo de datos de una columna existente y el modo de columna. Para obtener más información, consulta las reglas de conversión de tipos.
- Optimización automática del almacenamiento, que incluye el tamaño de archivo adaptable, el agrupamiento automático, la recolección de elementos no utilizados y la optimización de metadatos.
- Viaje en el tiempo para acceder a datos históricos en BigQuery
- Seguridad a nivel de la columna y enmascaramiento de datos.
- Transacciones de varias instrucciones (en versión preliminar)
Arquitectura
Las tablas de BigLake Iceberg en BigQuery brindan la comodidad de la administración de recursos de BigQuery a las tablas que residen en tus propios buckets de nube. Puedes usar BigQuery y motores de procesamiento de código abierto en estas tablas sin mover los datos fuera de los buckets que controlas. Debes configurar un bucket de Cloud Storage antes de comenzar a usar tablas de BigLake Iceberg en BigQuery.
Las tablas de BigLake Iceberg en BigQuery utilizan BigLake Metastore como el metastore unificado de tiempo de ejecución para todos los datos de Iceberg. BigLake Metastore proporciona una sola fuente de información para administrar los metadatos de varios motores y permite la interoperabilidad entre motores.
En el siguiente diagrama, se muestra la arquitectura de las tablas administradas en un nivel alto:
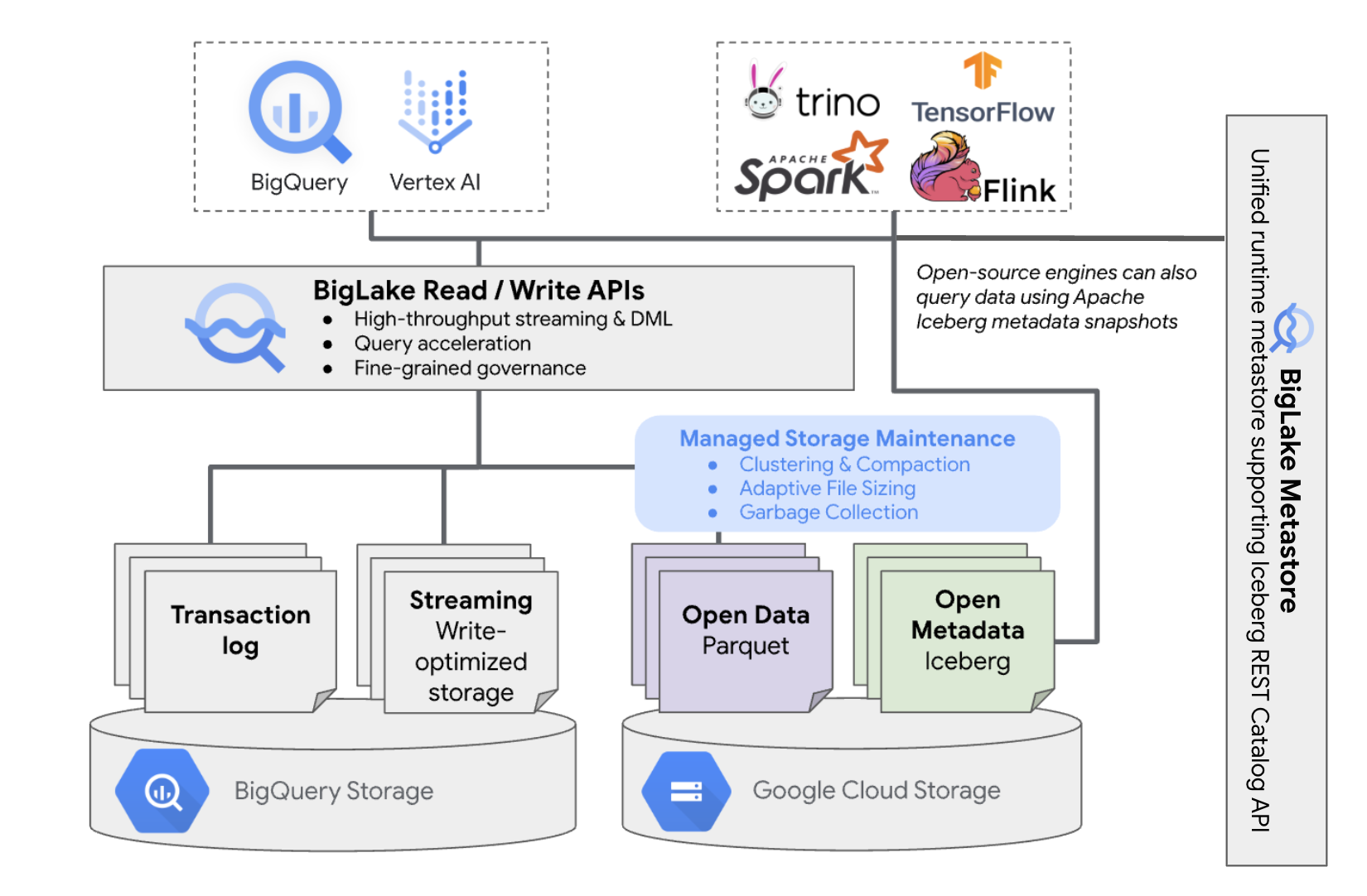
Esta administración de tablas tiene las siguientes implicaciones en tu bucket:
- BigQuery crea archivos de datos nuevos en el bucket en respuesta a solicitudes de escritura y optimizaciones de almacenamiento en segundo plano, como instrucciones DML y transmisión.
- Cuando borras una tabla administrada en BigQuery, BigQuery recopila los archivos de datos asociados en Cloud Storage después del vencimiento del período de viaje en el tiempo.
Crear una tabla de BigLake Iceberg en BigQuery es similar a crear tablas de BigQuery. Debido a que almacena datos en formatos abiertos en Cloud Storage, debes hacer lo siguiente:
- Especifica la conexión de recursos de Cloud con
WITH CONNECTIONpara configurar las credenciales de conexión de BigLake y acceder a Cloud Storage. - Especifica el formato de archivo del almacenamiento de datos como
PARQUETcon la instrucciónfile_format = PARQUET. - Especifica el formato de tabla de metadatos de código abierto como
ICEBERGcon la declaracióntable_format = ICEBERG.
Prácticas recomendadas
Si cambias o agregas archivos directamente al bucket fuera de BigQuery, se pueden perder datos o producirse errores irrecuperables. En la siguiente tabla, se describen las situaciones posibles:
| Operación | Consecuencias | Prevención |
|---|---|---|
| Agregar archivos nuevos al bucket fuera de BigQuery. | Pérdida de datos: BigQuery no realiza un seguimiento de los archivos u objetos nuevos que se agregan fuera de BigQuery. Los procesos de recolección de elementos no utilizados en segundo plano borran los archivos sin seguimiento. | Agregar datos exclusivamente a través de BigQuery. Esto permite que BigQuery haga un seguimiento de los archivos y evite que se recopilen como basura. Para evitar la pérdida de datos y las incorporaciones accidentales, también te recomendamos restringir los permisos de escritura de herramientas externas en los buckets que contienen tablas de BigLake Iceberg en BigQuery. |
| Crea una tabla de BigLake Iceberg nueva en BigQuery en un prefijo no vacío. | Pérdida de datos: BigQuery no realiza un seguimiento de los datos existentes, por lo que estos archivos se consideran sin seguimiento y se borran con los procesos de recolección de elementos no utilizados en segundo plano. | Solo crea tablas de BigLake Iceberg nuevas en BigQuery en prefijos vacíos. |
| Modificar o reemplazar la tabla de BigLake Iceberg en los archivos de datos de BigQuery | Pérdida de datos: En la modificación o el reemplazo externos, la tabla no pasa una verificación de coherencia y se vuelve ilegible. Las consultas a la tabla fallan. No hay una forma de autoservicio para recuperarse de este punto. Comunícate con el equipo de asistencia para obtener ayuda con la recuperación de datos. |
Modificar los datos exclusivamente a través de BigQuery. Esto permite que BigQuery haga un seguimiento de los archivos y evite que se recopilen como basura. Para evitar la pérdida de datos y las incorporaciones accidentales, también te recomendamos restringir los permisos de escritura de herramientas externas en los buckets que contienen tablas de BigLake Iceberg en BigQuery. |
| Crear dos tablas de BigLake Iceberg en BigQuery en los mismos URIs o en URIs superpuestos | Pérdida de datos: BigQuery no establece una vinculación entre instancias de URI idénticas de tablas de BigLake Iceberg en BigQuery. Los procesos de recolección de elementos no utilizados en segundo plano de cada tabla considerarán que los archivos de la tabla opuesta no tienen seguimiento y los borrarán, lo que provocará la pérdida de datos. | Usa URIs únicos para cada tabla de BigLake Iceberg en BigQuery. |
Prácticas recomendadas para la configuración de bucket de Cloud Storage
La configuración de tu bucket de Cloud Storage y su conexión con BigLake tienen un impacto directo en el rendimiento, el costo, la integridad de los datos, la seguridad y la administración de tus tablas de BigLake Iceberg en BigQuery. Estas son algunas prácticas recomendadas para ayudarte con esta configuración:
Selecciona un nombre que indique claramente que el bucket solo está destinado a las tablas de Iceberg de BigLake en BigQuery.
Elige buckets de Cloud Storage de una sola región que estén ubicados en la misma región que tu conjunto de datos de BigQuery. Esta coordinación mejora el rendimiento y reduce los costos, ya que evita los cargos por transferencia de datos.
De forma predeterminada, Cloud Storage almacena los datos en la clase de almacenamiento Estándar, que proporciona un rendimiento suficiente. Para optimizar los costos de almacenamiento de datos, puedes habilitar Autoclass para administrar automáticamente las transiciones de clases de almacenamiento. Autoclass comienza con la clase de almacenamiento Estándar y mueve los objetos a los que no se accede a clases progresivamente más frías para reducir los costos de almacenamiento. Cuando se vuelve a leer el objeto, se mueve de nuevo a la clase Standard.
Habilita el acceso uniforme a nivel del bucket y la prevención del acceso público.
Verifica que los roles requeridos estén asignados a los usuarios y las cuentas de servicio correctos.
Para evitar la eliminación o el daño accidental de datos de Iceberg en tu bucket de Cloud Storage, restringe los permisos de escritura y eliminación para la mayoría de los usuarios de tu organización. Para ello, establece una política de permisos de bucket con condiciones que denieguen las solicitudes
PUTyDELETEpara todos los usuarios, excepto los que especifiques.Aplica claves de encriptación administradas por Google o administradas por el cliente para proteger aún más los datos sensibles.
Habilita el registro de auditoría para la transparencia operativa, la solución de problemas y la supervisión del acceso a los datos.
Conserva la política de eliminación no definitiva predeterminada (retención de 7 días) para protegerte contra eliminaciones accidentales. Sin embargo, si detectas que se borraron datos de Iceberg, comunícate con el equipo de asistencia en lugar de restablecer los objetos de forma manual, ya que BigQuery no realiza un seguimiento de los objetos que se agregan o modifican fuera de BigQuery con los metadatos de BigQuery.
El tamaño de archivo adaptable, el agrupamiento automático y la recolección de elementos no utilizados se habilitan automáticamente y ayudan a optimizar el rendimiento y el costo de los archivos.
Evita las siguientes funciones de Cloud Storage, ya que no son compatibles con las tablas de BigLake Iceberg en BigQuery:
- Espacios de nombres jerárquicos
- Regiones duales y multirregiones
- Listas de control de acceso (LCA) de objetos
- Claves de encriptación proporcionadas por el cliente
- Control de versiones de objetos
- Bloqueo de objetos
- Bloqueo del bucket
- Cómo restablecer objetos borrados de forma no definitiva con la API de BigQuery o la herramienta de línea de comandos de bq
Puedes implementar estas prácticas recomendadas creando tu bucket con el siguiente comando:
gcloud storage buckets create gs://BUCKET_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --enable-autoclass \ --public-access-prevention \ --uniform-bucket-level-access
Reemplaza lo siguiente:
BUCKET_NAME: Es el nombre de tu bucket nuevo.PROJECT_ID: el ID del proyectoLOCATION: La ubicación de tu bucket nuevo
Tabla de BigLake Iceberg en flujos de trabajo de BigQuery
En las siguientes secciones, se describe cómo crear, cargar, administrar y consultar tablas administradas.
Antes de comenzar
Antes de crear y usar tablas de Iceberg de BigLake en BigQuery, asegúrate de haber configurado una conexión de recursos de Cloud a un bucket de almacenamiento. Tu conexión necesita permisos de escritura en el bucket de almacenamiento, como se especifica en la siguiente sección Roles obligatorios. Para obtener más información sobre los roles y permisos necesarios para las conexiones, consulta Administra conexiones.
Roles requeridos
Para obtener los permisos que necesitas para permitir que BigQuery administre las tablas de tu proyecto, pídele a tu administrador que te otorgue los siguientes roles de IAM:
-
Para crear tablas de BigLake Iceberg en BigQuery, haz lo siguiente:
-
Propietario de datos de BigQuery (
roles/bigquery.dataOwner) en tu proyecto -
Administrador de conexión de BigQuery (
roles/bigquery.connectionAdmin) en tu proyecto
-
Propietario de datos de BigQuery (
-
Para consultar tablas de BigLake Iceberg en BigQuery, haz lo siguiente:
-
Visualizador de datos de BigQuery (
roles/bigquery.dataViewer) en tu proyecto -
Usuario de BigQuery (
roles/bigquery.user) en tu proyecto
-
Visualizador de datos de BigQuery (
-
Otorga a la cuenta de servicio de conexión los siguientes roles para que pueda leer y escribir datos en Cloud Storage:
-
Usuario de objetos de almacenamiento (
roles/storage.objectUser) en el bucket -
Lector de depósitos heredados de Storage (
roles/storage.legacyBucketReader) en el bucket
-
Usuario de objetos de almacenamiento (
Para obtener más información sobre cómo otorgar roles, consulta Administra el acceso a proyectos, carpetas y organizaciones.
Estos roles predefinidos contienen los permisos necesarios para permitir que BigQuery administre las tablas de tu proyecto. Para ver los permisos exactos que son necesarios, expande la sección Permisos requeridos:
Permisos necesarios
Se requieren los siguientes permisos para permitir que BigQuery administre las tablas de tu proyecto:
bigquery.connections.delegateen tu proyectobigquery.jobs.createen tu proyectobigquery.readsessions.createen tu proyectobigquery.tables.createen tu proyectobigquery.tables.geten tu proyectobigquery.tables.getDataen tu proyecto-
storage.buckets.geten tu bucket -
storage.objects.createen tu bucket -
storage.objects.deleteen tu bucket -
storage.objects.geten tu bucket -
storage.objects.listen tu bucket
También puedes obtener estos permisos con roles personalizados o con otros roles predefinidos.
Crea tablas de BigLake Iceberg en BigQuery
Para crear una tabla de BigLake Iceberg en BigQuery, selecciona uno de los siguientes métodos:
SQL
CREATE TABLE [PROJECT_ID.]DATASET_ID.TABLE_NAME ( COLUMN DATA_TYPE[, ...] ) CLUSTER BY CLUSTER_COLUMN_LIST WITH CONNECTION {CONNECTION_NAME | DEFAULT} OPTIONS ( file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'STORAGE_URI');
Reemplaza lo siguiente:
- PROJECT_ID: Es el proyecto que contiene el conjunto de datos. Si no se define, el comando supone el proyecto predeterminado.
- DATASET_ID: Es un conjunto de datos existente.
- TABLE_NAME: es el nombre de la tabla que crearás.
- DATA_TYPE: Es el tipo de datos de la información que se contiene en la columna.
- CLUSTER_COLUMN_LIST (opcional): Es una lista separada por comas que contiene hasta cuatro columnas. Deben ser columnas de nivel superior que no se repitan.
CONNECTION_NAME: Es el nombre de la conexión. Por ejemplo,
myproject.us.myconnection.Para usar una conexión predeterminada, especifica
DEFAULTen lugar de la cadena de conexión que contiene PROJECT_ID.REGION.CONNECTION_ID.STORAGE_URI: Es un URI de Cloud Storage completamente calificado. Por ejemplo,
gs://mybucket/table.
bq
bq --project_id=PROJECT_ID mk \ --table \ --file_format=PARQUET \ --table_format=ICEBERG \ --connection_id=CONNECTION_NAME \ --storage_uri=STORAGE_URI \ --schema=COLUMN_NAME:DATA_TYPE[, ...] \ --clustering_fields=CLUSTER_COLUMN_LIST \ DATASET_ID.MANAGED_TABLE_NAME
Reemplaza lo siguiente:
- PROJECT_ID: Es el proyecto que contiene el conjunto de datos. Si no se define, el comando supone el proyecto predeterminado.
- CONNECTION_NAME: Es el nombre de la conexión. Por ejemplo,
myproject.us.myconnection. - STORAGE_URI: Es un URI de Cloud Storage completamente calificado.
Por ejemplo,
gs://mybucket/table. - COLUMN_NAME: El nombre de la columna.
- DATA_TYPE: Es el tipo de datos de la información que se incluye en la columna.
- CLUSTER_COLUMN_LIST (opcional): Es una lista separada por comas que contiene hasta cuatro columnas. Deben ser columnas de nivel superior que no se repitan.
- DATASET_ID: Es el ID de un conjunto de datos existente.
- MANAGED_TABLE_NAME: es el nombre de la tabla que crearás.
API
Llama al método tables.insert con un recurso de tabla definido, similar al siguiente:
{ "tableReference": { "tableId": "TABLE_NAME" }, "biglakeConfiguration": { "connectionId": "CONNECTION_NAME", "fileFormat": "PARQUET", "tableFormat": "ICEBERG", "storageUri": "STORAGE_URI" }, "schema": { "fields": [ { "name": "COLUMN_NAME", "type": "DATA_TYPE" } [, ...] ] } }
Reemplaza lo siguiente:
- TABLE_NAME: Es el nombre de la tabla que crearás.
- CONNECTION_NAME: Es el nombre de la conexión. Por ejemplo,
myproject.us.myconnection. - STORAGE_URI: Es un URI de Cloud Storage completamente calificado.
También se admiten comodines. Por ejemplo,
gs://mybucket/table - COLUMN_NAME: El nombre de la columna.
- DATA_TYPE: Es el tipo de datos de la información que se incluye en la columna.
Importa datos a tablas de BigLake Iceberg en BigQuery
En las siguientes secciones, se describe cómo importar datos de varios formatos de tablas a tablas de Iceberg de BigLake en BigQuery.
Carga datos estándar desde archivos planos
Las tablas de Iceberg de BigLake en BigQuery usan trabajos de carga de BigQuery para cargar archivos externos en tablas de Iceberg de BigLake en BigQuery. Si tienes una tabla de BigLake Iceberg existente en BigQuery, sigue la guía de la CLI de bq load o la guía de SQL de LOAD para cargar datos externos. Después de cargar los datos, se escriben archivos Parquet nuevos en la carpeta STORAGE_URI/data.
Si se usan las instrucciones anteriores sin una tabla de Iceberg BigLake existente en BigQuery, se creará una tabla de BigQuery.
Consulta lo siguiente para ver ejemplos específicos de herramientas de cargas por lotes en tablas administradas:
SQL
LOAD DATA INTO MANAGED_TABLE_NAME FROM FILES ( uris=['STORAGE_URI'], format='FILE_FORMAT');
Reemplaza lo siguiente:
- MANAGED_TABLE_NAME: Es el nombre de una tabla de Iceberg BigLake existente en BigQuery.
- STORAGE_URI: Es un URI de Cloud Storage completamente calificado o una lista de URI separados por comas.
También se admiten comodines. Por ejemplo,
gs://mybucket/table - FILE_FORMAT: Es el formato de la tabla de origen. Para conocer los formatos compatibles, consulta la fila
formatdeload_option_list.
bq
bq load \ --source_format=FILE_FORMAT \ MANAGED_TABLE \ STORAGE_URI
Reemplaza lo siguiente:
- FILE_FORMAT: Es el formato de la tabla de origen. Para conocer los formatos compatibles, consulta la fila
formatdeload_option_list. - MANAGED_TABLE_NAME: Es el nombre de una tabla de Iceberg BigLake existente en BigQuery.
- STORAGE_URI: Es un URI de Cloud Storage completamente calificado o una lista de URI separados por comas.
También se admiten comodines. Por ejemplo,
gs://mybucket/table
Carga estándar desde archivos particionados por Hive
Puedes cargar archivos particionados por Hive en tablas de BigLake Iceberg en BigQuery con trabajos de carga estándar de BigQuery. Para obtener más información, consulta Carga datos con particiones externas.
Carga datos de transmisión desde Pub/Sub
Puedes cargar datos de transmisión en tablas de BigLake Iceberg en BigQuery con una suscripción de BigQuery a Pub/Sub.
Exporta datos de tablas de BigLake Iceberg en BigQuery
En las siguientes secciones, se describe cómo exportar datos de tablas de Iceberg de BigLake en BigQuery a varios formatos de tabla.
Exporta datos a formatos planos
Para exportar una tabla de BigLake Iceberg en BigQuery a un formato plano, usa la sentencia EXPORT DATA y selecciona un formato de destino. Para obtener más información, consulta Cómo exportar datos.
Crea una tabla de BigLake Iceberg en las instantáneas de metadatos de BigQuery
Para crear una tabla de BigLake Iceberg en la instantánea de metadatos de BigQuery, sigue estos pasos:
Exporta los metadatos al formato Iceberg V2 con la instrucción de SQL
EXPORT TABLE METADATA.Opcional: Programa la actualización de la instantánea de metadatos de Iceberg. Para actualizar una instantánea de metadatos de Iceberg según un intervalo de tiempo establecido, usa una consulta programada.
Opcional: Habilita la actualización automática de metadatos para que tu proyecto actualice automáticamente la instantánea de metadatos de la tabla de Iceberg en cada mutación de la tabla. Para habilitar la actualización automática de metadatos, comunícate con bigquery-tables-for-apache-iceberg-help@google.com. Los costos de
EXPORT METADATAse aplican en cada operación de actualización.
En el siguiente ejemplo, se crea una consulta programada llamada My Scheduled Snapshot Refresh Query con la instrucción DDL EXPORT TABLE METADATA FROM mydataset.test. La sentencia DDL se ejecuta cada 24 horas.
bq query \ --use_legacy_sql=false \ --display_name='My Scheduled Snapshot Refresh Query' \ --schedule='every 24 hours' \ 'EXPORT TABLE METADATA FROM mydataset.test'
Consulta la tabla de BigLake Iceberg en la instantánea de metadatos de BigQuery
Después de actualizar la tabla de BigLake Iceberg en la instantánea de metadatos de BigQuery, puedes encontrar la instantánea en el URI de Cloud Storage en el que se creó originalmente la tabla de BigLake Iceberg en BigQuery. La carpeta /data contiene los fragmentos de datos del archivo Parquet, y la carpeta /metadata contiene la tabla de Iceberg de BigLake en la instantánea de metadatos de BigQuery.
SELECT table_name, REGEXP_EXTRACT(ddl, r"storage_uri\s*=\s*\"([^\"]+)\"") AS storage_uri FROM `mydataset`.INFORMATION_SCHEMA.TABLES;
Ten en cuenta que mydataset y table_name son marcadores de posición para tu conjunto de datos y tabla reales.
Cómo leer tablas de BigLake Iceberg en BigQuery con Apache Spark
En el siguiente ejemplo, se configura tu entorno para usar Spark SQL con Apache Iceberg y, luego, se ejecuta una consulta para recuperar datos de una tabla de BigLake Iceberg especificada en BigQuery.
spark-sql \ --packages org.apache.iceberg:iceberg-spark-runtime-ICEBERG_VERSION_NUMBER \ --conf spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.CATALOG_NAME.type=hadoop \ --conf spark.sql.catalog.CATALOG_NAME.warehouse='BUCKET_PATH' \ # Query the table SELECT * FROM CATALOG_NAME.FOLDER_NAME;
Reemplaza lo siguiente:
- ICEBERG_VERSION_NUMBER: Es la versión actual del entorno de ejecución de Apache Spark Iceberg. Descarga la versión más reciente de Spark Releases.
- CATALOG_NAME: Es el catálogo al que se hace referencia a tu tabla de BigLake Iceberg en BigQuery.
- BUCKET_PATH: Es la ruta de acceso al bucket que contiene los archivos de la tabla. Por ejemplo,
gs://mybucket/ - FOLDER_NAME: Es la carpeta que contiene los archivos de la tabla.
Por ejemplo,
myfolder
Modifica tablas de BigLake Iceberg en BigQuery
Para modificar una tabla de Iceberg de BigLake en BigQuery, sigue los pasos que se muestran en Modifica esquemas de tablas.
Usa transacciones de varias instrucciones
Para obtener acceso a las transacciones de varias declaraciones para las tablas de BigLake Iceberg en BigQuery, completa el formulario de registro.
Precios
Los precios de las tablas de BigLake Iceberg en BigQuery incluyen el almacenamiento, la optimización del almacenamiento, y las consultas y los trabajos.
Almacenamiento
Las tablas de Iceberg de BigLake en BigQuery almacenan todos los datos en Cloud Storage. Se te cobra por todos los datos almacenados, incluidos los datos históricos de las tablas. También se pueden aplicar los cargos de transferencia y el procesamiento de datos de Cloud Storage. Es posible que se eximan algunas tarifas de operaciones de Cloud Storage para las operaciones que se procesan a través de BigQuery o la API de BigQuery Storage. No hay tarifas de almacenamiento específicas de BigQuery. Para obtener más información, consulta los Precios de Cloud Storage.
Optimización del almacenamiento
Las tablas Iceberg de BigLake en BigQuery realizan la administración automática de tablas, lo que incluye la compactación, la agrupación en clústeres, la recolección de elementos no utilizados y la generación o actualización de metadatos de BigQuery para optimizar el rendimiento de las consultas y reducir los costos de almacenamiento. El uso de recursos de procesamiento para la administración de tablas de BigLake se factura en unidades de procesamiento de datos (DCU) a lo largo del tiempo, en incrementos por segundo. Para obtener más detalles, consulta la tabla de Iceberg de BigLake en los precios de BigQuery.
Las operaciones de exportación de datos que se realizan durante la transmisión a través de la API de BigQuery Storage Write se incluyen en los precios de la API de Storage Write y no se cobran como mantenimiento en segundo plano. Para obtener más información, consulta Precios por transferencia de datos.
El uso de la optimización del almacenamiento y de EXPORT TABLE METADATA se puede ver en la vista INFORMATION_SCHEMA.JOBS.
Consultas y trabajos
Al igual que con las tablas de BigQuery, se te cobra por las consultas y los bytes leídos (por TiB) si usas los precios según demanda de BigQuery o el consumo de ranuras (por ranura-hora) si usas los precios de procesamiento de capacidad de BigQuery.
Los precios de BigQuery también se aplican a la API de BigQuery Storage Read y a la API de BigQuery Storage Write.
Las operaciones de carga y exportación (como EXPORT METADATA) usan ranuras de pago por uso de la edición Enterprise.
Esto difiere de las tablas de BigQuery, que no se cobran por estas operaciones. Si hay reservas PIPELINE con ranuras de Enterprise o Enterprise Plus disponibles, las operaciones de carga y exportación usan de preferencia estas ranuras de reserva.
Limitaciones
Las tablas de BigLake Iceberg en BigQuery tienen las siguientes limitaciones:
- Las tablas de BigLake Iceberg en BigQuery no admiten operaciones de cambio de nombre ni declaraciones
ALTER TABLE RENAME TO. - Las tablas de BigLake Iceberg en BigQuery no admiten copias de tablas ni declaraciones
CREATE TABLE COPY. - Las tablas de BigLake Iceberg en BigQuery no admiten clones de tablas ni declaraciones
CREATE TABLE CLONE. - Las tablas de BigLake Iceberg en BigQuery no admiten instantáneas de tablas ni declaraciones
CREATE SNAPSHOT TABLE. - Las tablas de BigLake Iceberg en BigQuery no admiten el siguiente esquema de tabla:
- Esquema vacío
- Esquema con tipos de datos
BIGNUMERIC,INTERVAL,JSON,RANGEoGEOGRAPHY. - Esquema con comparaciones de campos.
- Esquema con expresiones de valor predeterminado.
- Las tablas de BigLake Iceberg en BigQuery no admiten los siguientes casos de evolución del esquema:
- Coerciones de tipo de
NUMERICaFLOAT - Coerciones de tipo de
INTaFLOAT - Agregar nuevos campos anidados a columnas
RECORDexistentes con instrucciones de DDL de SQL
- Coerciones de tipo de
- Las tablas de BigLake Iceberg en BigQuery muestran un tamaño de almacenamiento de 0 bytes cuando la consola o las APIs las consultan.
- Las tablas de BigLake Iceberg en BigQuery no admiten vistas materializadas.
- Las tablas de Iceberg de BigLake en BigQuery no admiten vistas autorizadas, pero sí control de acceso a nivel de columna.
- Las tablas de BigLake Iceberg en BigQuery no admiten actualizaciones de captura de datos modificados (CDC).
- Las tablas de BigLake Iceberg en BigQuery no admiten la recuperación ante desastres administrada.
- Las tablas de BigLake Iceberg en BigQuery no admiten la partición. Considera el agrupamiento en clústeres como una alternativa.
- Las tablas de BigLake Iceberg en BigQuery no admiten la seguridad a nivel de la fila.
- Las tablas de BigLake Iceberg en BigQuery no admiten ventanas de seguridad ante fallas.
- Las tablas de BigLake Iceberg en BigQuery no admiten trabajos de extracción.
- La vista
INFORMATION_SCHEMA.TABLE_STORAGEno incluye las tablas de BigLake Iceberg en BigQuery. - Las tablas de BigLake Iceberg en BigQuery no son compatibles como destinos de resultados de consultas. En su lugar, puedes usar la instrucción
CREATE TABLEcon el argumentoAS query_statementpara crear una tabla como destino del resultado de la consulta. CREATE OR REPLACEno admite el reemplazo de tablas estándar por tablas de Iceberg de BigLake en BigQuery, ni el reemplazo de tablas de Iceberg de BigLake en BigQuery por tablas estándar.- Las cargas por lotes y las sentencias
LOAD DATAsolo admiten la anexión de datos a tablas de Iceberg de BigLake existentes en BigQuery. - La carga por lotes y las sentencias
LOAD DATAno admiten actualizaciones de esquemas. TRUNCATE TABLEno admite tablas de BigLake Iceberg en BigQuery. Existen dos alternativas:CREATE OR REPLACE TABLE, con las mismas opciones de creación de tablas.DELETE FROMtablaWHEREverdadero
- La función con valor de tabla (TVF)
APPENDSno admite tablas de BigLake Iceberg en BigQuery. - Es posible que los metadatos de Iceberg no contengan datos que se transmitieron a BigQuery a través de la API de Storage Write en los últimos 90 minutos.
- El acceso paginado basado en registros con
tabledata.listno admite tablas de BigLake Iceberg en BigQuery. - Las tablas de BigLake Iceberg en BigQuery no admiten conjuntos de datos vinculados.
- Solo se ejecuta una declaración DML de mutación simultánea (
UPDATE,DELETEyMERGE) para cada tabla de BigLake Iceberg en BigQuery. Las declaraciones DML adicionales de mutación están en cola.