Exportar modelos
Esta página mostra-lhe como exportar modelos do BigQuery ML. Pode exportar modelos do BigQuery ML para o Cloud Storage e usá-los para previsões online ou editá-los em Python. Pode exportar um modelo do BigQuery ML das seguintes formas:
- Usando a Google Cloud consola.
- Usar a declaração
EXPORT MODEL. - Usando o comando
bq extractna ferramenta de linhas de comando bq. - Enviar uma tarefa
extractatravés da API ou das bibliotecas cliente.
Pode exportar os seguintes tipos de modelos:
AUTOENCODERAUTOML_CLASSIFIERAUTOML_REGRESSORBOOSTED_TREE_CLASSIFIERBOOSTED_TREE_REGRESSORDNN_CLASSIFIERDNN_REGRESSORDNN_LINEAR_COMBINED_CLASSIFIERDNN_LINEAR_COMBINED_REGRESSORKMEANSLINEAR_REGLOGISTIC_REGMATRIX_FACTORIZATIONRANDOM_FOREST_CLASSIFIERRANDOM_FOREST_REGRESSORTENSORFLOW(modelos do TensorFlow importados)PCATRANSFORM_ONLY
Formatos e amostras de modelos de exportação
A tabela seguinte mostra os formatos de destino de exportação para cada tipo de modelo do BigQuery ML e fornece um exemplo de ficheiros que são escritos no contentor do Cloud Storage.
| Tipo de modelo | Formato do modelo de exportação | Exemplo de ficheiros exportados |
|---|---|---|
| AUTOML_CLASSIFIER | TensorFlow SavedModel (TF 2.1.0) | gcs_bucket/
|
| AUTOML_REGRESSOR | ||
| AUTOENCODER | TensorFlow SavedModel (TF 1.15 ou superior) | |
| DNN_CLASSIFIER | ||
| DNN_REGRESSOR | ||
| DNN_LINEAR_COMBINED_CLASSIFIER | ||
| DNN_LINEAR_COMBINED_REGRESSOR | ||
| KMEANS | ||
| LINEAR_REGRESSOR | ||
| LOGISTIC_REG | ||
| MATRIX_FACTORIZATION | ||
| PCA | ||
| TRANSFORM_ONLY | ||
| BOOSTED_TREE_CLASSIFIER | Booster (XGBoost 0.82) | gcs_bucket/
main.py destina-se à execução local. Consulte o artigo Implementação de modelos para ver mais detalhes.
|
| BOOSTED_TREE_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| RANDOM_FOREST_REGRESSOR | ||
| TENSORFLOW (importado) | TensorFlow SavedModel | Exatamente os mesmos ficheiros que estavam presentes quando importou o modelo |
Exporte o modelo preparado com o TRANSFORM
Se o modelo for treinado com a cláusula TRANSFORM,TRANSFORM, um modelo de pré-processamento adicional executa a mesma lógica na cláusula TRANSFORM e é guardado no formato TensorFlow SavedModel no subdiretório transform.
Pode implementar um modelo preparado com a cláusula TRANSFORM
no Vertex AI, bem como localmente. Para mais informações, consulte o artigo
Implementação de modelos.
| Formato do modelo de exportação | Exemplo de ficheiros exportados |
|---|---|
|
Modelo de previsão: TensorFlow SavedModel ou Booster (XGBoost 0.82).
Modelo de pré-processamento para a cláusula TRANSFORM: TensorFlow SavedModel (TF 2.5 ou superior) |
gcs_bucket/
|
O modelo não contém as informações sobre a engenharia de funcionalidades
realizada fora da cláusula TRANSFORM
durante a preparação. Por exemplo, tudo o que estiver na declaração SELECT . Por isso, tem de converter manualmente os dados de entrada antes de os introduzir no modelo de pré-processamento.
Tipos de dados suportados
Quando exporta modelos preparados com a cláusula TRANSFORM, os seguintes tipos de dados são suportados para introdução na cláusula TRANSFORM.
| Tipo de entrada TRANSFORM | Amostras de entrada TRANSFORM | Amostras de entrada do modelo de pré-processamento exportadas |
|---|---|---|
| INT64 |
10,
|
tf.constant(
|
| NUMERIC |
NUMERIC 10,
|
tf.constant(
|
| BIGNUMERIC |
BIGNUMERIC 10,
|
tf.constant(
|
| FLOAT64 |
10.0,
|
tf.constant(
|
| BOOL |
TRUE,
|
tf.constant(
|
| STRING |
'abc',
|
tf.constant(
|
| BYTES |
b'abc',
|
tf.constant(
|
| DATA |
DATE '2020-09-27',
|
tf.constant(
|
| DATA/HORA |
DATETIME '2023-02-02 02:02:01.152903',
|
tf.constant(
|
| HORA |
TIME '16:32:36.152903',
|
tf.constant(
|
| TIMESTAMP |
TIMESTAMP '2017-02-28 12:30:30.45-08',
|
tf.constant(
|
| ARRAY |
['a', 'b'],
|
tf.constant(
|
| ARRAY< STRUCT< INT64, FLOAT64>> |
[(1, 1.0), (2, 1.0)],
|
tf.sparse.from_dense(
|
| NULL |
NULL,
|
tf.constant(
|
Funções SQL suportadas
Quando exporta modelos preparados com a cláusula TRANSFORM, pode usar as seguintes funções SQL na cláusula TRANSFORM
.
- Operadores
+,-,*,/,=,<,>,<=,>=,!=,<>,[NOT] BETWEEN,[NOT] IN,IS [NOT] NULL,IS [NOT] TRUE,IS [NOT] FALSE,NOT,AND,OR.
- Expressões condicionais
CASE expr,CASE,COALESCE,IF,IFNULL,NULLIF.
- Funções matemáticas
ABS,ACOS,ACOSH,ASINH,ATAN,ATAN2,ATANH,CBRT,CEIL,CEILING,COS,COSH,COT,COTH,CSC,CSCH,EXP,FLOOR,IS_INF,IS_NAN,LN,LOG,LOG10,MOD,POW,POWER,SEC,SECH,SIGN,SIN,SINH,SQRT,TAN,TANH.
- Funções de conversão
CAST AS INT64,CAST AS FLOAT64,CAST AS NUMERIC,CAST AS BIGNUMERIC,CAST AS STRING,SAFE_CAST AS INT64,SAFE_CAST AS FLOAT64
- Funções de texto
CONCAT,LEFT,LENGTH,LOWER,REGEXP_REPLACE,RIGHT,SPLIT,SUBSTR,SUBSTRING,TRIM,UPPER.
- Funções de data
Date,DATE_ADD,DATE_SUB,DATE_DIFF,DATE_TRUNC,EXTRACT,FORMAT_DATE,PARSE_DATE,SAFE.PARSE_DATE.
- Funções de data/hora
DATETIME,DATETIME_ADD,DATETIME_SUB,DATETIME_DIFF,DATETIME_TRUNC,EXTRACT,PARSE_DATETIME,SAFE.PARSE_DATETIME.
- Funções de tempo
TIME,TIME_ADD,TIME_SUB,TIME_DIFF,TIME_TRUNC,EXTRACT,FORMAT_TIME,PARSE_TIME,SAFE.PARSE_TIME.
- Funções de data/hora
TIMESTAMP,TIMESTAMP_ADD,TIMESTAMP_SUB,TIMESTAMP_DIFF,TIMESTAMP_TRUNC,FORMAT_TIMESTAMP,PARSE_TIMESTAMP,SAFE.PARSE_TIMESTAMP,TIMESTAMP_MICROS,TIMESTAMP_MILLIS,TIMESTAMP_SECONDS,EXTRACT,STRING,UNIX_MICROS,UNIX_MILLIS,UNIX_SECONDS.
- Funções de pré-processamento manual
ML.IMPUTER,ML.HASH_BUCKETIZE,ML.LABEL_ENCODER,ML.MULTI_HOT_ENCODER,ML.NGRAMS,ML.ONE_HOT_ENCODER,ML.BUCKETIZE,ML.MAX_ABS_SCALER,ML.MIN_MAX_SCALER,ML.NORMALIZER,ML.QUANTILE_BUCKETIZE,ML.ROBUST_SCALER,ML.STANDARD_SCALER.
Limitações
Aplicam-se as seguintes limitações quando exporta modelos:
A exportação de modelos não é suportada se tiver sido usada alguma das seguintes funcionalidades durante a preparação:
- Os tipos de funcionalidades
ARRAY,TIMESTAMPouGEOGRAPHYestavam presentes nos dados de entrada.
- Os tipos de funcionalidades
Os modelos exportados para os tipos de modelos
AUTOML_REGRESSOReAUTOML_CLASSIFIERnão suportam a implementação da Vertex AI para a previsão online.O limite de tamanho do modelo é de 1 GB para a exportação do modelo de fatorização de matrizes. O tamanho do modelo é aproximadamente proporcional a
num_factors, pelo que pode reduzirnum_factorsdurante a preparação para diminuir o tamanho do modelo se atingir o limite.Para modelos preparados com a cláusula BigQuery ML
TRANSFORMpara pré-processamento manual de caraterísticas, consulte os tipos de dados e as funções suportadas para exportação.Os modelos preparados com a cláusula BigQuery ML
TRANSFORMantes de 18 de setembro de 2023 têm de ser preparados novamente antes de poderem ser implementados através do registo de modelos para previsão online.Durante a exportação do modelo,
ARRAY<STRUCT<INT64, FLOAT64>>,ARRAYeTIMESTAMPsão suportados como dados pré-transformados, mas não são suportados como dados pós-transformados.
Exporte modelos do BigQuery ML
Para exportar um modelo, selecione uma das seguintes opções:
Consola
Abra a página do BigQuery na Google Cloud consola
.No painel esquerdo, clique em Explorador:

Se não vir o painel do lado esquerdo, clique em Expandir painel do lado esquerdo para o abrir.
No painel Explorador, expanda o seu projeto, clique em Conjuntos de dados e, de seguida, clique no seu conjunto de dados.
Clique em Vista geral > Modelos e clique no nome do modelo que está a exportar.
Clique em Mais > Exportar:
Na caixa de diálogo Exportar modelo para o Google Cloud Storage:
- Em Selecionar localização do GCS, procure o contentor ou a localização da pasta para onde quer exportar o modelo e clique em Selecionar.
- Clique em Enviar para exportar o modelo.
Para verificar o progresso da tarefa, no painel Explorador, clique em Histórico de tarefas e procure uma tarefa do tipo EXTRACT.
SQL
A declaração EXPORT MODEL permite-lhe exportar modelos do BigQuery ML
para o Cloud Storage através da sintaxe de consulta GoogleSQL.
Para exportar um modelo do BigQuery ML na Google Cloud consola através
da declaração EXPORT MODEL, siga estes passos:
Na Google Cloud consola, abra a página do BigQuery.
Clique em Redigir nova consulta.
No campo Editor de consultas, escreva a sua declaração
EXPORT MODEL.A seguinte consulta exporta um modelo denominado
myproject.mydataset.mymodelpara um contentor do Cloud Storage com o URIgs://bucket/path/to/saved_model/.EXPORT MODEL `myproject.mydataset.mymodel` OPTIONS(URI = 'gs://bucket/path/to/saved_model/')
Clique em Executar. Quando a consulta estiver concluída, é apresentado o seguinte no painel Resultados da consulta:
Successfully exported model.
bq
e posterior. Para ver a versão da ferramenta bq instalada, usebq version e, se necessário, atualize a CLI gcloud com gcloud components update.
Use o comando bq extract com a flag --model.
(Opcional) Forneça a flag --destination_format e escolha o formato do modelo exportado.
(Opcional) Forneça a flag --location e defina o valor para a sua localização.
bq --location=location extract \ --destination_format format \ --model project_id:dataset.model \ gs://bucket/model_folder
Onde:
- location é o nome da sua localização. A flag
--locationé opcional. Por exemplo, se estiver a usar o BigQuery na região de Tóquio, pode definir o valor da flag comoasia-northeast1. Pode predefinir um valor para a localização através do ficheiro.bigqueryrc. - destination_format é o formato do modelo exportado:
ML_TF_SAVED_MODEL(predefinição) ouML_XGBOOST_BOOSTER. - project_id é o ID do seu projeto.
- dataset é o nome do conjunto de dados de origem.
- model é o modelo que está a exportar.
- bucket é o nome do contentor do Cloud Storage para o qual está a exportar os dados. O conjunto de dados do BigQuery e o contentor do Cloud Storage têm de estar na mesma localização.
- model_folder é o nome da pasta onde os ficheiros de modelo exportados vão ser escritos.
Exemplos:
Por exemplo, o comando seguinte exporta mydataset.mymodel no formato TensorFlow SavedModel
para um contentor do Cloud Storage denominado mymodel_folder.
bq extract --model \ 'mydataset.mymodel' \ gs://example-bucket/mymodel_folder
O valor predefinido de destination_format é ML_TF_SAVED_MODEL.
O comando seguinte exporta mydataset.mymodel no formato XGBoost Booster
para um contentor do Cloud Storage denominado mymodel_folder.
bq extract --model \ --destination_format ML_XGBOOST_BOOSTER \ 'mydataset.mytable' \ gs://example-bucket/mymodel_folder
API
Para exportar o modelo, crie uma tarefa extract e preencha a configuração da tarefa.
(Opcional) Especifique a sua localização na propriedade location na secção jobReference do recurso de trabalho.
Crie uma tarefa de extração que aponte para o modelo do BigQuery ML e o destino do Cloud Storage.
Especifique o modelo de origem através do objeto de configuração
sourceModelque contém o ID do projeto, o ID do conjunto de dados e o ID do modelo.A propriedade
destination URI(s)tem de ser totalmente qualificada, no formato gs://bucket/model_folder.Especifique o formato de destino definindo a propriedade
configuration.extract.destinationFormat. Por exemplo, para exportar um modelo de árvore com reforço, defina esta propriedade com o valorML_XGBOOST_BOOSTER.Para verificar o estado da tarefa, chame jobs.get(job_id) com o ID da tarefa devolvido pelo pedido inicial.
- Se
status.state = DONE, a tarefa foi concluída com êxito. - Se a propriedade
status.errorResultestiver presente, o pedido falhou e esse objeto inclui informações que descrevem o que correu mal. - Se
status.errorResultestiver ausente, a tarefa foi concluída com êxito, embora possam ter ocorrido alguns erros não fatais. Os erros não fatais são apresentados na propriedadestatus.errorsdo objeto de tarefa devolvido.
- Se
Notas da API:
Como prática recomendada, gere um ID exclusivo e transmita-o como
jobReference.jobIdquando chamarjobs.insertpara criar uma tarefa. Esta abordagem é mais robusta em caso de falha de rede, porque o cliente pode sondar ou tentar novamente com o ID da tarefa conhecido.A chamada de
jobs.insertnum determinado ID da tarefa é idempotente; por outras palavras, pode tentar novamente quantas vezes quiser no mesmo ID da tarefa e, no máximo, uma dessas operações vai ter êxito.
Java
Antes de experimentar este exemplo, siga as Javainstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Java BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Implementação de modelos
Pode implementar o modelo exportado no Vertex AI, bem como localmente. Se a cláusula TRANSFORM do modelo contiver funções de data, funções de data/hora, funções de tempo ou funções de data/hora, tem de usar a biblioteca bigquery-ml-utils no contentor. A exceção é se estiver a implementar através do Model Registry, que não precisa de modelos exportados nem de contentores de publicação.
Implementação do Vertex AI
| Formato do modelo de exportação | Implementação |
|---|---|
| TensorFlow SavedModel (modelos não AutoML) | Implemente um SavedModel do TensorFlow. Tem de criar o ficheiro SavedModel com uma versão suportada do TensorFlow. |
| TensorFlow SavedModel (modelos da AutoML) | Não suportado. |
| XGBoost Booster |
Usar uma rotina de previsão personalizada. Para modelos de reforço XGBoost, as informações de pré-processamento e pós-processamento são guardadas nos ficheiros exportados, e uma rotina de previsão personalizada permite-lhe implementar o modelo com os ficheiros exportados adicionais.
Tem de criar os ficheiros do modelo com uma versão suportada do XGBoost. |
Implementação local
| Formato do modelo de exportação | Implementação |
|---|---|
| TensorFlow SavedModel (modelos não AutoML) |
O SavedModel é um formato padrão e pode implementá-los no contentor Docker do TensorFlow Serving. Também pode tirar partido da execução local da previsão online do Vertex AI. |
| TensorFlow SavedModel (modelos da AutoML) | Coloque o modelo em contentores e execute-o. |
| XGBoost Booster |
Para executar modelos de reforço XGBoost localmente, pode usar o ficheiro main.py
exportado:
|
Formato de saída da previsão
Esta secção apresenta o formato de saída da previsão dos modelos exportados para cada tipo de modelo. Todos os modelos exportados suportam a previsão em lote e podem processar várias linhas de entrada em simultâneo. Por exemplo, existem duas linhas de entrada em cada um dos seguintes exemplos de formato de saída.
AUTOENCODER
| Formato de saída da previsão | Exemplo de saída |
|---|---|
+------------------------+------------------------+------------------------+
| LATENT_COL_1 | LATENT_COL_2 | ... |
+------------------------+------------------------+------------------------+
| [FLOAT] | [FLOAT] | ... |
+------------------------+------------------------+------------------------+
|
+------------------+------------------+------------------+------------------+
| LATENT_COL_1 | LATENT_COL_2 | LATENT_COL_3 | LATENT_COL_4 |
+------------------------+------------+------------------+------------------+
| 0.21384512 | 0.93457112 | 0.64978097 | 0.00480489 |
+------------------+------------------+------------------+------------------+
|
AUTOML_CLASSIFIER
| Formato de saída da previsão | Exemplo de saída |
|---|---|
+------------------------------------------+
| predictions |
+------------------------------------------+
| [{"scores":[FLOAT], "classes":[STRING]}] |
+------------------------------------------+
|
+---------------------------------------------+
| predictions |
+---------------------------------------------+
| [{"scores":[1, 2], "classes":['a', 'b']}, |
| {"scores":[3, 0.2], "classes":['a', 'b']}] |
+---------------------------------------------+
|
AUTOML_REGRESSOR
| Formato de saída da previsão | Exemplo de saída |
|---|---|
+-----------------+
| predictions |
+-----------------+
| [FLOAT] |
+-----------------+
|
+-----------------+
| predictions |
+-----------------+
| [1.8, 2.46] |
+-----------------+
|
BOOSTED_TREE_CLASSIFIER e RANDOM_FOREST_CLASSIFIER
| Formato de saída da previsão | Exemplo de saída |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
BOOSTED_TREE_REGRESSOR E RANDOM_FOREST_REGRESSOR
| Formato de saída da previsão | Exemplo de saída |
|---|---|
+-----------------+
| predicted_label |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| predicted_label |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_CLASSIFIER
| Formato de saída da previsão | Exemplo de saída |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_REGRESSOR
| Formato de saída da previsão | Exemplo de saída |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
DNN_LINEAR_COMBINED_CLASSIFIER
| Formato de saída da previsão | Exemplo de saída |
|---|---|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [INT64] | [STRING] | INT64 | STRING | FLOAT | [FLOAT]| [FLOAT] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| ALL_CLASS_IDS | ALL_CLASSES | CLASS_IDS | CLASSES | LOGISTIC (binary only) | LOGITS | PROBABILITIES |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.36] | [-0.53]| [0.64, 0.36] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
| [0, 1] | ['a', 'b'] | [0] | ['a'] | [0.2] | [-1.38]| [0.8, 0.2] |
+---------------+-------------+-----------+---------+------------------------+--------+---------------+
|
DNN_LINEAR_COMBINED_REGRESSOR
| Formato de saída da previsão | Exemplo de saída |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
KMEANS
| Formato de saída da previsão | Exemplo de saída |
|---|---|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [FLOAT] | [INT64] | INT64 |
+--------------------+--------------+---------------------+
|
+--------------------+--------------+---------------------+
| CENTROID_DISTANCES | CENTROID_IDS | NEAREST_CENTROID_ID |
+--------------------+--------------+---------------------+
| [1.2, 1.3] | [1, 2] | [1] |
+--------------------+--------------+---------------------+
| [0.4, 0.1] | [1, 2] | [2] |
+--------------------+--------------+---------------------+
|
LINEAR_REG
| Formato de saída da previsão | Exemplo de saída |
|---|---|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| FLOAT |
+-----------------+
|
+-----------------+
| PREDICTED_LABEL |
+-----------------+
| [1.8] |
+-----------------+
| [2.46] |
+-----------------+
|
LOGISTIC_REG
| Formato de saída da previsão | Exemplo de saída |
|---|---|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [FLOAT] | [STRING] | STRING |
+-------------+--------------+-----------------+
|
+-------------+--------------+-----------------+
| LABEL_PROBS | LABEL_VALUES | PREDICTED_LABEL |
+-------------+--------------+-----------------+
| [0.1, 0.9] | ['a', 'b'] | ['b'] |
+-------------+--------------+-----------------+
| [0.8, 0.2] | ['a', 'b'] | ['a'] |
+-------------+--------------+-----------------+
|
MATRIX_FACTORIZATION
Nota: atualmente, só oferecemos compatibilidade com a obtenção de um utilizador de entrada e a saída dos 50 principais pares (predicted_rating, predicted_item) ordenados por predicted_rating por ordem descendente.
| Formato de saída da previsão | Exemplo de saída |
|---|---|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [FLOAT] | [STRING] |
+------------------+----------------+
|
+--------------------+--------------+
| PREDICTED_RATING | PREDICTED_ITEM |
+------------------+----------------+
| [5.5, 1.7] | ['A', 'B'] |
+------------------+----------------+
| [7.2, 2.7] | ['B', 'A'] |
+------------------+----------------+
|
TENSORFLOW (importado)
| Formato de saída da previsão |
|---|
| Igual ao modelo importado |
PCA
| Formato de saída da previsão | Exemplo de saída |
|---|---|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [INT64] | [FLOAT] |
+-------------------------+---------------------------------+
|
+-------------------------+---------------------------------+
| PRINCIPAL_COMPONENT_IDS | PRINCIPAL_COMPONENT_PROJECTIONS |
+-------------------------+---------------------------------+
| [1, 2] | [1.2, 5.0] |
+-------------------------+---------------------------------+
|
TRANSFORM_ONLY
| Formato de saída da previsão |
|---|
Igual às colunas especificadas na cláusula TRANSFORM
do modelo
|
Visualização do modelo XGBoost
Pode visualizar as árvores com reforço através da API Python plot_tree após a exportação do modelo. Por exemplo, pode tirar partido do Colab sem instalar as dependências:
- Exporte o modelo de árvore com reforço para um contentor do Cloud Storage.
- Transfira o ficheiro
model.bstdo contentor do Cloud Storage. - Num bloco de notas do Colab,
carregue o ficheiro
model.bstparaFiles. Execute o seguinte código no bloco de notas:
import xgboost as xgb import matplotlib.pyplot as plt model = xgb.Booster(model_file="model.bst") num_iterations = <iteration_number> for tree_num in range(num_iterations): xgb.plot_tree(model, num_trees=tree_num) plt.show
Este exemplo representa graficamente várias árvores (uma árvore por iteração):
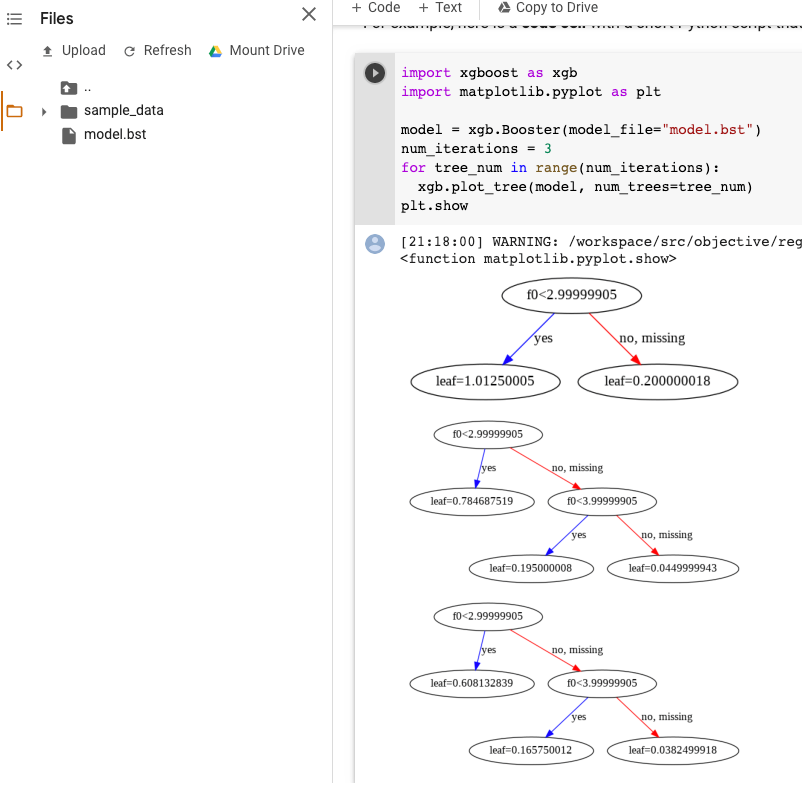
Atualmente, não guardamos os nomes das funcionalidades no modelo, pelo que verá nomes como "f0", "f1" e assim sucessivamente. Pode encontrar os nomes das funcionalidades correspondentes no
ficheiro assets/model_metadata.json exportado através destes nomes (como "f0")
como índices.
Autorizações necessárias
Para exportar um modelo do BigQuery ML para o Cloud Storage, precisa de autorizações para aceder ao modelo do BigQuery ML, autorizações para executar uma tarefa de extração e autorizações para escrever os dados no contentor do Cloud Storage.
Autorizações do BigQuery
No mínimo, para exportar o modelo, tem de ter
bigquery.models.exportautorizações. As seguintes funções predefinidas da gestão de identidade e de acesso (IAM) têm autorizaçõesbigquery.models.export:bigquery.dataViewerbigquery.dataOwnerbigquery.dataEditorbigquery.admin
No mínimo, para executar uma tarefa de exportação, tem de ter autorizações
bigquery.jobs.create. As seguintes funções do IAM predefinidas têm autorizaçõesbigquery.jobs.create:bigquery.userbigquery.jobUserbigquery.admin
Autorizações do Cloud Storage
Para escrever os dados num contentor do Cloud Storage existente, tem de ter autorizações
storage.objects.create. As seguintes funções do IAM predefinidas têm autorizaçõesstorage.objects.create:storage.objectCreatorstorage.objectAdminstorage.admin
Para mais informações sobre as funções e as autorizações do IAM no BigQuery ML, consulte o artigo Controlo de acesso.
Mova dados do BigQuery entre localizações
Não é possível alterar a localização de um conjunto de dados após a respetiva criação, mas pode fazer uma cópia do conjunto de dados.
Política de quotas
Para informações sobre as quotas de tarefas de extração, consulte o artigo Tarefas de extração na página Quotas e limites.
Preços
Não existe qualquer custo para exportar modelos do BigQuery ML, mas as exportações estão sujeitas às quotas e limites do BigQuery. Para mais informações sobre os preços do BigQuery, consulte a página Preços.
Após a exportação dos dados, é-lhe cobrado o armazenamento dos dados no Cloud Storage. Para mais informações sobre os preços do Cloud Storage, consulte a página de preços do Cloud Storage.
O que se segue?
- Siga o tutorial Exporte um modelo do BigQuery ML para a previsão online.