Ce document fournit des informations générales sur la confidentialité différentielle pour BigQuery. Pour connaître la syntaxe, consultez la clause de confidentialité différentielle. Pour obtenir la liste des fonctions que vous pouvez utiliser avec cette syntaxe, consultez Fonctions d'agrégation différentiellement privées.
Qu'est-ce que la confidentialité différentielle ?
La confidentialité différentielle est une norme pour les calculs portant sur des données qui limitent les informations personnelles divulguées par une sortie. La confidentialité différentielle est couramment utilisée pour partager des données et permettre des inférences sur des groupes de personnes tout en empêchant la diffusion d'informations sur une personne.
La confidentialité différentielle est utile :
- en cas de risque de restauration de l'identification ;
- pour quantifier le compromis entre les risques et l'utilité des analyses ;
Pour mieux comprendre la confidentialité différentielle, prenons un exemple simple.
Ce graphique à barres montre la fréquentation d'un petit restaurant un soir particulier. De nombreux clients arrivent à 19h, et le restaurant est complètement vide à 1h du matin :
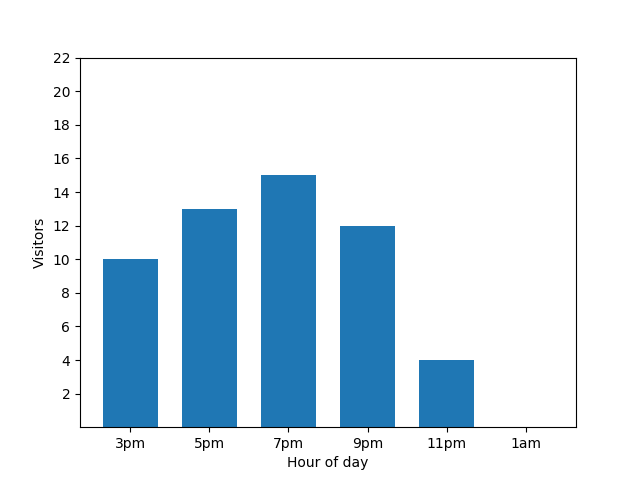
Ce graphique semble utile, mais il y a un bémol. Lorsqu'un nouveau client arrive, cela se voit immédiatement sur le graphique à barres. Dans le graphique suivant, il est clair qu'un nouveau client est arrivé à environ 1h :
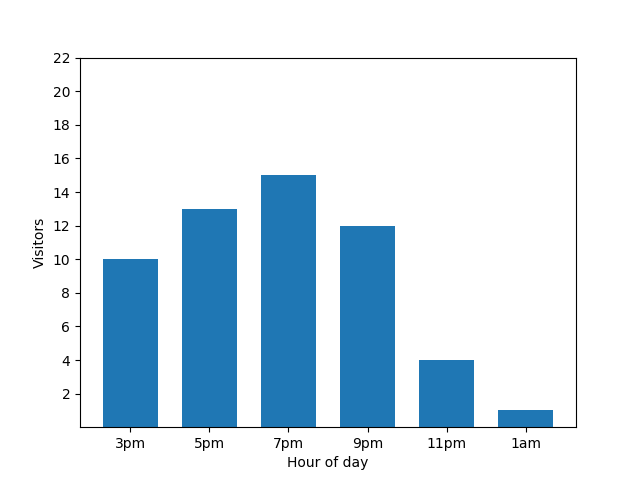
Afficher ces informations n'est pas idéal du point de vue de la confidentialité, car les statistiques anonymes ne doivent pas révéler de contributions individuelles. Le fait de placer ces deux graphiques côte à côte rend les choses plus évidentes : le graphique à barres orange a un client supplémentaire qui est arrivé vers 1h :
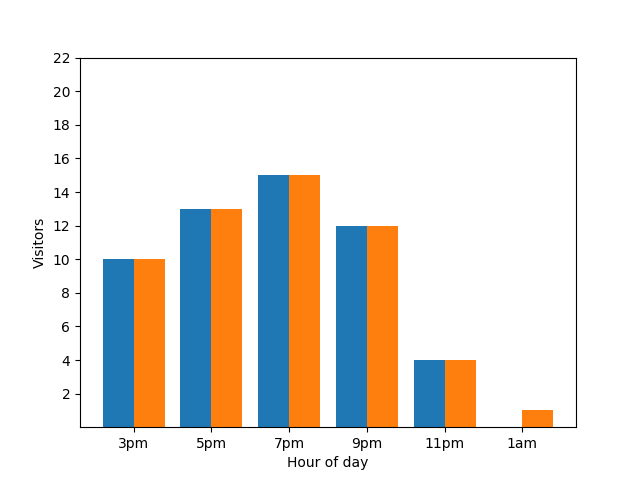
Là encore, cette représentation n'est pas idéale. Pour éviter ce type de problème lié à la confidentialité, vous pouvez ajouter du bruit aléatoire aux graphiques à barres à l'aide de la confidentialité différentielle. Dans le tableau comparatif suivant, les résultats sont anonymisés et ne révèlent plus les contributions individuelles.
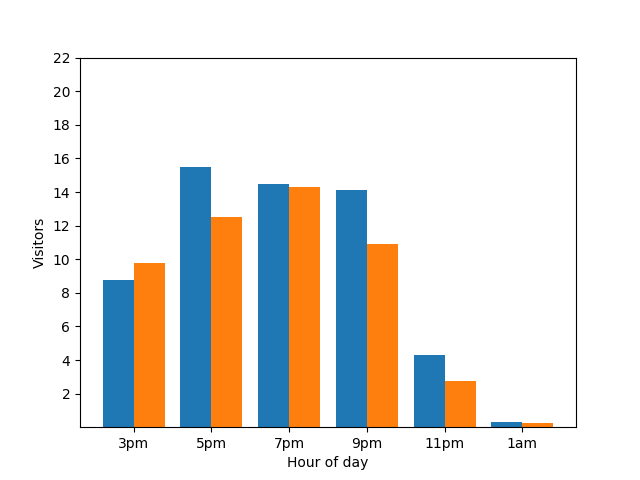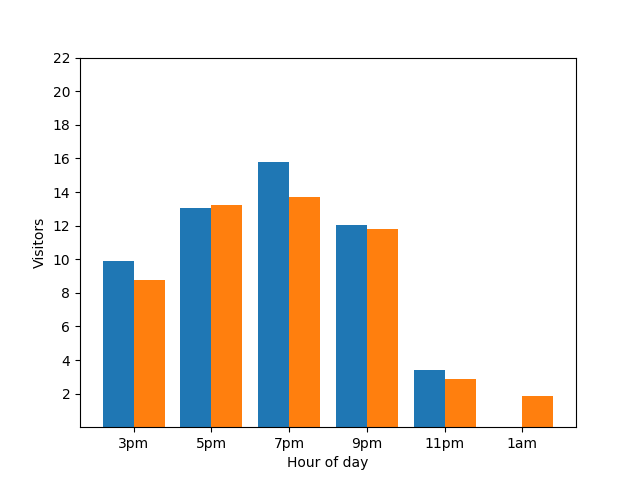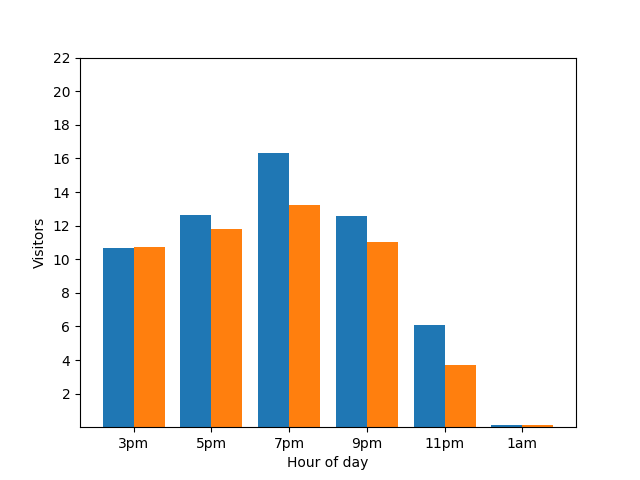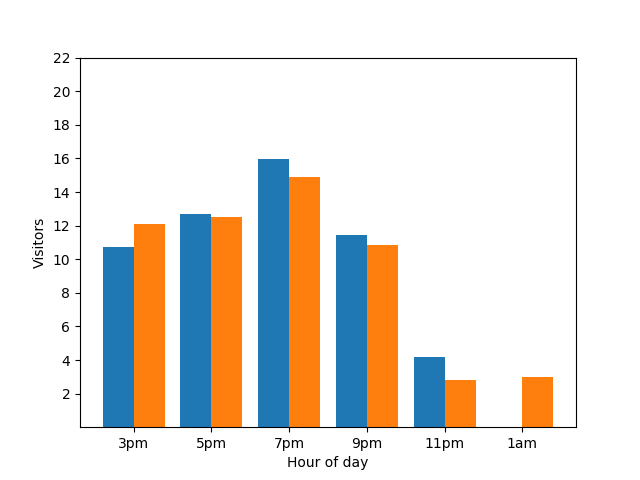
Fonctionnement de la confidentialité différentielle dans les requêtes
L'objectif de la confidentialité différentielle est de limiter le risque qu'un utilisateur puisse obtenir des informations sur un individu à partir d'un ensemble de données. La confidentialité différentielle établit un juste équilibre entre la nécessité de protéger la confidentialité et la nécessité du point de vue de l'analyse statistique. À mesure que la confidentialité augmente, l'utilité de l'analyse statistique diminue, et inversement.
Avec GoogleSQL pour BigQuery, vous pouvez transformer les résultats d'une requête à l'aide d'agrégations différentiellement privées. Lorsque la requête est exécutée, elle effectue les opérations suivantes :
- Elle calcule les agrégations par entité pour chaque groupe si des groupes sont spécifiés avec une clause
GROUP BY. Elle limite le nombre de groupes auxquels chaque entité peut contribuer, en fonction du paramètre de confidentialité différentiellemax_groups_contributed. - Elle limite chaque contribution d'agrégation par entité pour se trouver dans les marges de limitation. Si les limites de limitation ne sont pas spécifiées, elles sont calculées implicitement de manière différentielle privée.
- Elle agrège les contributions agrégées par entité pour chaque groupe.
- Elle ajoute du bruit à la valeur globale finale pour chaque groupe. L'échelle du bruit aléatoire est une fonction de l'ensemble des limites et des paramètres de confidentialité restreints.
- Elle calcule un nombre d'entités bruyantes pour chaque groupe et élimine les groupes contenant peu d'entités. Un nombre d'entités bruyantes aide à éliminer un ensemble non déterministe de groupes.
Le résultat final est un ensemble de données dans lequel chaque groupe comporte des résultats agrégés bruyants et où les petits groupes ont été éliminés.
Pour en savoir plus sur la confidentialité différentielle et ses cas d'utilisation, consultez les articles suivants :
- Présentation conviviale et non technique de la confidentialité différentielle
- SQL avec confidentialité différentielle et contribution utilisateur limitée
- Confidentialité différentielle sur Wikipedia
Produire une requête différentiellement privée valide
Les règles suivantes doivent être remplies pour que la requête différentielle soit valide :
- Une colonne d'unités de confidentialité est définie.
- La liste
SELECTcontient une clause différentiellement privée. - Seules les fonctions d'agrégation différentiellement privées figurent dans la liste
SELECTavec la clause de confidentialité différentielle.
Définir une colonne d'unités de confidentialité
Une unité de confidentialité est l'entité d'un ensemble de données protégé, utilisant la confidentialité différentielle. Une entité peut être une personne, une entreprise, un lieu ou toute colonne de votre choix.
Une requête différentiellement privée doit inclure une seule colonne d'unités de confidentialité. Une colonne d'unités de confidentialité est un identifiant unique pour une unité de confidentialité et peut exister dans plusieurs groupes. Étant donné que plusieurs groupes sont acceptés, le type de données de la colonne d'unité de confidentialité doit être groupable.
Vous pouvez définir une colonne d'unités de confidentialité dans la clause OPTIONS d'une clause de confidentialité différentielle avec l'identifiant unique privacy_unit_column.
Dans les exemples suivants, une colonne d'unités de confidentialité est ajoutée à une clause de confidentialité différentielle. id représente une colonne provenant d'une table appelée students.
SELECT WITH DIFFERENTIAL_PRIVACY
OPTIONS (epsilon=10, delta=.01, privacy_unit_column=id)
item,
COUNT(*, contribution_bounds_per_group=>(0, 100))
FROM students;
SELECT WITH DIFFERENTIAL_PRIVACY
OPTIONS (epsilon=10, delta=.01, privacy_unit_column=members.id)
item,
COUNT(*, contribution_bounds_per_group=>(0, 100))
FROM (SELECT * FROM students) AS members;
Supprimer le bruit d'une requête différentiellement privée
Dans la documentation de référence sur la syntaxe des requêtes, consultez la section Supprimer du bruit.
Ajouter du bruit à une requête différentiellement privée
Dans la documentation de référence sur la syntaxe des requêtes, consultez la section Ajouter du bruit.
Limiter les groupes dans lesquels un ID d'unité de confidentialité peut exister
Dans la documentation de référence sur la syntaxe des requêtes, consultez la section Limiter les groupes dans lesquels un ID d'unité de confidentialité peut exister.
Limites
Cette section décrit les limites de la confidentialité différentielle.
Implications de la confidentialité différentielle sur les performances
Les requêtes différentiellement privées s'exécutent plus lentement que les requêtes standards, car l'agrégation par entité est effectuée et la limitation max_groups_contributed est appliquée. Restreindre les limites de contribution peut améliorer les performances de vos requêtes différentielles privées.
Les profils de performances des requêtes suivantes ne sont pas similaires :
SELECT
WITH DIFFERENTIAL_PRIVACY OPTIONS(epsilon=1, delta=1e-10, privacy_unit_column=id)
column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
SELECT column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
Cette différence de performances s'explique par le fait qu'un niveau de regroupement plus précis est effectué pour les requêtes différentiellement privées, car l'agrégation par entité doit également être effectuée.
Les profils de performances des requêtes suivantes doivent être similaires, même si la requête différentielle privée est légèrement plus lente :
SELECT
WITH DIFFERENTIAL_PRIVACY OPTIONS(epsilon=1, delta=1e-10, privacy_unit_column=id)
column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
SELECT column_a, id, COUNT(column_b)
FROM table_a
GROUP BY column_a, id;
La requête différentiellement privée s'exécute plus lentement, car la colonne d'unités de confidentialité comporte un grand nombre de valeurs distinctes.
Limites de délimitation implicite pour les petits ensembles de données
La délimitation implicite fonctionne mieux lorsqu'elle est calculée à l'aide d'ensembles de données volumineux. La délimitation implicite peut échouer lorsque les ensembles de données contiennent un faible nombre d'unités de confidentialité et qu'ils ne renvoient aucun résultat. En outre, le fait de limiter implicitement un ensemble de données avec un faible nombre d'unités de confidentialité peut limiter une grande partie des anomalies, ce qui entraîne des agrégations et des résultats sous-représentés qui sont plus modifiés par la limitation que par le bruit supplémentaire. Les ensembles de données qui ont un petit nombre d'unités de confidentialité ou sont très partitionnés doivent utiliser le processus de limitation explicite plutôt qu'implicite.
Failles de confidentialité
Tout algorithme de confidentialité différentielle, y compris celui-ci, présente un risque de fuite de données privées lorsqu'un analyste agit de mauvaise foi, en particulier lors du calcul de statistiques de base telles que des sommes, en raison de limitations arithmétiques.
Limites des garanties de confidentialité
Bien que la confidentialité différentielle de BigQuery applique l'algorithme de confidentialité différentielle, elle ne garantit pas les propriétés de confidentialité de l'ensemble de données obtenu.
Erreurs d'exécution
Un analyste de mauvaise foi capable d'écrire des requêtes ou de contrôler les données d'entrée pourrait déclencher une erreur d'exécution sur des données privées.
Bruit à virgule flottante
Les failles liées aux attaques d'arrondis, d'arrondis répétés et de tri doivent être prises en compte avant d'utiliser la confidentialité différentielle. Ces failles sont particulièrement préoccupantes lorsqu'un pirate informatique peut contrôler une partie du contenu d'un ensemble de données ou l'ordre du contenu de celui-ci.
Les ajouts de bruit différentiellement privés sur les types de données à virgule flottante sont soumis aux failles décrites dans la section Sous-estimation diffuse de la sensibilité dans les bibliothèques différentielles privées et comment la corriger. Les ajouts de bruit sur les données de type entier ne sont pas soumis aux failles décrites dans l'article.
Risques liés aux attaques par minutage
Un analyste agissant de mauvaise foi pourrait exécuter une requête suffisamment complexe pour faire une inférence sur les données d'entrée en fonction de la durée d'exécution d'une requête.
Erreur de classification
La création d'une requête de confidentialité différentielle suppose que vos données sont dans une structure connue et comprise. Si vous appliquez la confidentialité différentielle aux mauvais identifiants (par exemple, à un identifiant représentant un ID de transaction au lieu de l'ID d'une personne), vous risquez d'exposer des données sensibles.
Si vous avez besoin d'aide pour interpréter vos données, envisagez d'utiliser des services et des outils, tels que les suivants :
Tarifs
L'utilisation de la confidentialité différentielle n'entraîne aucun coût supplémentaire, mais les tarifs standards de BigQuery liés à l'analyse s'appliquent.