Membuat set data
Dokumen ini menjelaskan cara membuat set data di BigQuery.
Anda dapat membuat set data dengan cara berikut:
- Menggunakan Google Cloud console.
- Menggunakan kueri SQL.
- Menggunakan perintah
bq mkdi alat command line bq. - Memanggil metode API
datasets.insert. - Menggunakan library klien.
- Menyalin set data yang sudah ada.
Untuk mengetahui langkah-langkah menyalin set data, termasuk di berbagai region, lihat Menyalin set data.
Dokumen ini menjelaskan cara menggunakan set data reguler yang menyimpan data di BigQuery. Untuk mempelajari cara menggunakan set data eksternal Spanner, lihat Membuat set data eksternal Spanner. Untuk mempelajari cara menggunakan set data gabungan AWS Glue, lihat Membuat set data gabungan AWS Glue.
Untuk mempelajari cara mengkueri tabel di set data publik, lihat Membuat kueri set data publik dengan konsol Google Cloud .
Batasan set data
Set data BigQuery memiliki batasan berikut:
- Lokasi data set hanya dapat ditetapkan pada waktu pembuatan. Setelah set data dibuat, lokasinya tidak dapat diubah.
- Semua tabel yang direferensikan dalam kueri harus disimpan dalam set data di lokasi yang sama.
Set data eksternal tidak mendukung habis masa berlaku tabel, replika, perjalanan waktu, kolasi default, mode pembulatan default, atau opsi untuk mengaktifkan atau menonaktifkan nama tabel yang tidak peka huruf besar/kecil.
Saat Anda menyalin tabel, set data yang berisi tabel sumber dan tabel tujuan harus berada di lokasi yang sama.
Nama set data untuk setiap project harus unik.
Jika Anda mengubah model penagihan penyimpanan set data, Anda harus menunggu 14 hari sebelum dapat mengubah model penagihan penyimpanan lagi.
Anda tidak dapat mendaftarkan set data dalam penagihan penyimpanan fisik jika Anda memiliki komitmen slot tarif tetap lama yang sudah ada di region yang sama dengan set data tersebut.
Sebelum memulai
Berikan peran Identity and Access Management (IAM) yang memberi pengguna izin yang diperlukan untuk melakukan setiap tugas dalam dokumen ini.
Izin yang diperlukan
Untuk membuat set data, Anda memerlukan izin IAM bigquery.datasets.create.
Setiap peran IAM yang telah ditetapkan berikut mencakup izin yang Anda perlukan untuk membuat set data:
roles/bigquery.dataEditorroles/bigquery.dataOwnerroles/bigquery.userroles/bigquery.admin
Untuk mengetahui informasi selengkapnya tentang peran IAM di BigQuery, lihat Peran dan izin yang telah ditetapkan.
Membuat set data
Untuk membuat set data:
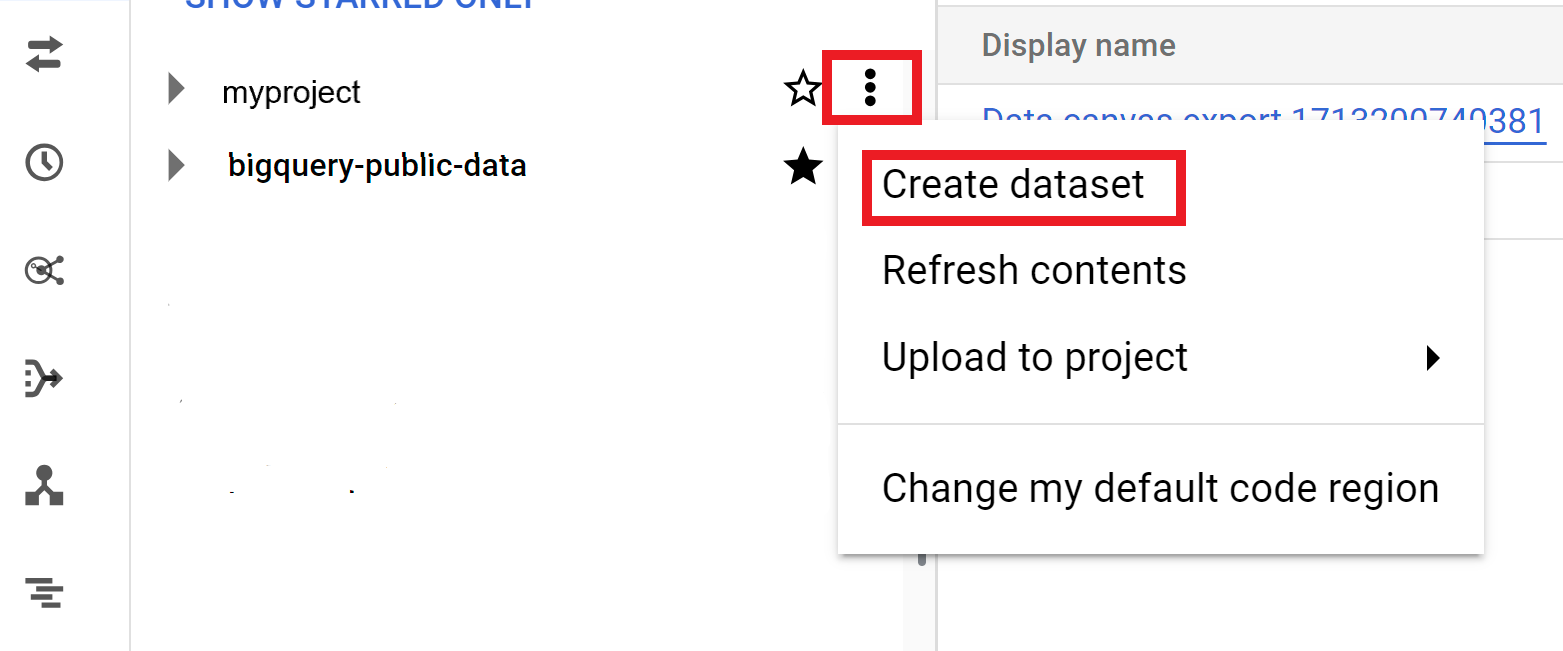
Konsol
- Buka halaman BigQuery di konsol Google Cloud . Buka halaman BigQuery
- Di panel kiri, klik Explorer.
- Pilih project tempat Anda ingin membuat set data.
- Klik Lihat tindakan, lalu klik Buat set data.
- Di halaman Create dataset:
- Untuk ID Set Data, masukkan nama set data yang unik.
- Untuk Location type, pilih lokasi geografis untuk set data. Setelah set data dibuat, lokasi tidak dapat diubah.
- Opsional: Pilih Tautkan ke set data eksternal jika Anda membuat set data eksternal.
- Jika Anda tidak perlu mengonfigurasi opsi tambahan seperti tag dan masa berlaku tabel, klik Buat set data. Atau, luaskan bagian berikut untuk mengonfigurasi opsi set data tambahan.
- Opsional: Luaskan bagian Tag untuk menambahkan tag ke set data Anda.
- Untuk menerapkan tag yang ada, lakukan hal berikut:
- Klik panah drop-down di samping Pilih cakupan, lalu pilih Cakupan saat ini—Pilih organisasi saat ini atau Pilih project saat ini.
- Untuk Kunci 1 dan Nilai 1, pilih nilai yang sesuai dari daftar.
- Untuk memasukkan tag baru secara manual, lakukan hal berikut:
- Klik panah drop-down di samping Pilih cakupan dan pilih Masukkan ID secara manual > Organisasi, Project, atau Tag.
- Jika Anda membuat tag untuk project atau organisasi,
di dialog, masukkan
PROJECT_IDatauORGANIZATION_ID, lalu klik Simpan. - Untuk Kunci 1 dan Nilai 1, pilih nilai yang sesuai dari daftar.
- Untuk menambahkan tag tambahan ke tabel, klik Tambahkan tag dan ikuti langkah-langkah sebelumnya.
- Opsional: Luaskan bagian Advanced options untuk mengonfigurasi satu atau beberapa opsi berikut.
- Untuk mengubah opsi Encryption agar menggunakan kunci kriptografi Anda sendiri dengan Cloud Key Management Service, pilih Cloud KMS key.
- Untuk menggunakan nama tabel yang tidak peka huruf besar/kecil, pilih Aktifkan nama tabel yang tidak peka huruf besar/kecil.
- Untuk mengubah Default collation spesifikasi, pilih jenis kolasi dari daftar.
- Untuk menetapkan masa berlaku tabel dalam set data, pilih Aktifkan masa berlaku tabel, lalu tentukan Usia tabel maksimum default dalam hari.
- Untuk menyetel Mode pembulatan default, pilih mode pembulatan dari daftar.
- Untuk mengaktifkan Model penagihan penyimpanan fisik, pilih model penagihan dari daftar.
- Untuk menetapkan periode perjalanan waktu set data, pilih ukuran periode dari daftar.
- Klik Create dataset.
Opsi tambahan untuk set data
Atau, klik Pilih cakupan untuk menelusuri resource atau melihat daftar resource saat ini.
Jika Anda mengubah model penagihan set data, perlu waktu 24 jam agar perubahan diterapkan.
Setelah mengubah model penagihan penyimpanan set data, Anda harus menunggu 14 hari sebelum dapat mengubah model penagihan penyimpanan lagi.
SQL
Gunakan pernyataan CREATE SCHEMA.
Untuk membuat set data di project selain project default Anda, tambahkan project ID ke ID set data dalam format berikut:
PROJECT_ID.DATASET_ID.
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, masukkan pernyataan berikut:
CREATE SCHEMA PROJECT_ID.DATASET_ID OPTIONS ( default_kms_key_name = 'KMS_KEY_NAME', default_partition_expiration_days = PARTITION_EXPIRATION, default_table_expiration_days = TABLE_EXPIRATION, description = 'DESCRIPTION', labels = [('KEY_1','VALUE_1'),('KEY_2','VALUE_2')], location = 'LOCATION', max_time_travel_hours = HOURS, storage_billing_model = BILLING_MODEL);
Ganti kode berikut:
PROJECT_ID: project ID AndaDATASET_ID: ID set data yang Anda buatKMS_KEY_NAME: nama kunci Cloud Key Management Service default yang digunakan untuk melindungi tabel yang baru dibuat dalam set data ini, kecuali jika kunci yang berbeda diberikan pada saat pembuatannya. Anda tidak dapat membuat tabel yang dienkripsi Google dalam set data yang menetapkan parameter ini.PARTITION_EXPIRATION: masa aktif default (dalam hari) untuk partisi dalam tabel berpartisi yang baru dibuat. Akhir masa berlaku partisi default tidak memiliki nilai minimum. Waktu habis masa berlaku mengevaluasi tanggal partisi ditambah nilai bilangan bulat. Setiap partisi yang dibuat dalam tabel berpartisi di set data akan dihapusPARTITION_EXPIRATIONhari setelah tanggal partisi. Jika Anda menyediakan opsitime_partitioning_expirationsaat membuat atau memperbarui tabel berpartisi, akhir masa berlaku partisi pada tingkat tabel lebih diutamakan daripada akhir masa berlaku partisi default pada tingkat set data.TABLE_EXPIRATION: masa aktif default (dalam hari) untuk tabel yang baru dibuat. Nilai minimumnya adalah 0,042 hari (satu jam). Waktu habis masa berlaku mengevaluasi waktu saat ini ditambah dengan nilai bilangan bulat. Setiap tabel yang dibuat dalam set data akan dihapusTABLE_EXPIRATIONhari setelah waktu pembuatannya. Nilai ini diterapkan jika Anda tidak menetapkan akhir masa berlaku tabel saat membuat tabel.DESCRIPTION: deskripsi set dataKEY_1:VALUE_1: key-value pair yang ingin Anda tetapkan sebagai label pertama di set data iniKEY_2:VALUE_2: key-value pair yang ingin Anda tetapkan sebagai label keduaLOCATION: lokasi set data. Setelah set data dibuat, lokasi tidak dapat diubah.HOURS: durasi dalam jam pada periode perjalanan waktu untuk set data baru. NilaiHOURSharus berupa bilangan bulat yang dinyatakan dalam kelipatan 24 (48, 72, 96, 120, 144, 168) antara 48 (2 hari) dan 168 (7 hari). Jika opsi ini tidak ditentukan, nilai defaultnya adalah 168 jam.BILLING_MODEL: menetapkan model penagihan penyimpanan untuk set data. Tetapkan nilaiBILLING_MODELkePHYSICALuntuk menggunakan byte fisik saat menghitung biaya penyimpanan, atau keLOGICALuntuk menggunakan byte logika.LOGICALadalah defaultnya.Jika Anda mengubah model penagihan set data, perlu waktu 24 jam agar perubahan diterapkan.
Setelah mengubah model penagihan penyimpanan set data, Anda harus menunggu 14 hari sebelum dapat mengubah model penagihan penyimpanan lagi.
Klik Run.
Untuk mengetahui informasi selengkapnya tentang cara menjalankan kueri, lihat artikel Menjalankan kueri interaktif.
bq
Untuk membuat set data baru, gunakan perintah bq mk dengan flag --location. Untuk daftar lengkap kemungkinan parameter, lihat referensi
perintah bq mk --dataset.
Untuk membuat set data dalam project selain project default Anda, tambahkan project ID ke nama set data dalam format berikut:
PROJECT_ID:DATASET_ID.
bq --location=LOCATION mk \ --dataset \ --default_kms_key=KMS_KEY_NAME \ --default_partition_expiration=PARTITION_EXPIRATION \ --default_table_expiration=TABLE_EXPIRATION \ --description="DESCRIPTION" \ --label=KEY_1:VALUE_1 \ --label=KEY_2:VALUE_2 \ --add_tags=KEY_3:VALUE_3[,...] \ --max_time_travel_hours=HOURS \ --storage_billing_model=BILLING_MODEL \ PROJECT_ID:DATASET_ID
Ganti kode berikut:
LOCATION: lokasi set data. Setelah set data dibuat, lokasi tidak dapat diubah. Anda dapat menetapkan nilai default untuk lokasi menggunakan file.bigqueryrc.KMS_KEY_NAME: nama kunci Cloud Key Management Service default yang digunakan untuk melindungi tabel yang baru dibuat dalam set data ini, kecuali jika kunci yang berbeda diberikan pada saat pembuatannya. Anda tidak dapat membuat tabel yang dienkripsi Google dalam set data yang menetapkan parameter ini.PARTITION_EXPIRATION: masa aktif default (dalam detik) untuk partisi dalam tabel berpartisi yang baru dibuat. Akhir masa berlaku partisi default tidak memiliki nilai minimum. Waktu habis masa berlaku mengevaluasi tanggal partisi ditambah nilai bilangan bulat. Setiap partisi yang dibuat dalam tabel berpartisi di set data akan dihapusPARTITION_EXPIRATIONdetik setelah tanggal partisi. Jika Anda menyediakan--time_partitioning_expirationflag saat membuat atau memperbarui tabel berpartisi, akhir masa berlaku partisi pada tingkat tabel lebih diutamakan daripada akhir masa berlaku partisi default pada tingkat set data.TABLE_EXPIRATION: masa aktif default (dalam detik) untuk tabel yang baru dibuat. Nilai minimumnya adalah 3.600 detik (satu jam). Waktu habis masa berlaku mengevaluasi waktu saat ini ditambah dengan nilai bilangan bulat. Setiap tabel yang dibuat dalam set data akan dihapusTABLE_EXPIRATIONdetik setelah waktu pembuatannya. Nilai ini diterapkan jika Anda tidak menetapkan akhir masa berlaku tabel saat membuat tabel.DESCRIPTION: deskripsi set dataKEY_1:VALUE_1: key-value pair yang ingin Anda tetapkan sebagai label pertama di set data ini, danKEY_2:VALUE_2adalah key-value pair yang ingin Anda tetapkan sebagai label kedua.KEY_3:VALUE_3: key-value pair yang ingin Anda tetapkan sebagai tag pada set data. Tambahkan beberapa tag di bawah tanda yang sama dengan koma di antara pasangan nilai kunci.HOURS: durasi dalam jam pada periode perjalanan waktu untuk set data baru. NilaiHOURSharus berupa bilangan bulat yang dinyatakan dalam kelipatan 24 (48, 72, 96, 120, 144, 168) antara 48 (2 hari) dan 168 (7 hari). Jika opsi ini tidak ditentukan, nilai defaultnya adalah 168 jam.BILLING_MODEL: menetapkan model penagihan penyimpanan untuk set data. Tetapkan nilaiBILLING_MODELkePHYSICALuntuk menggunakan byte fisik saat menghitung biaya penyimpanan, atau keLOGICALuntuk menggunakan byte logika.LOGICALadalah defaultnya.Jika Anda mengubah model penagihan set data, perlu waktu 24 jam agar perubahan diterapkan.
Setelah mengubah model penagihan penyimpanan set data, Anda harus menunggu 14 hari sebelum dapat mengubah model penagihan penyimpanan lagi.
PROJECT_ID: project ID Anda.DATASET_ID: ID set data yang Anda buat.
Misalnya, perintah berikut membuat set data bernama mydataset dengan lokasi data ditetapkan ke US, akhir masa berlaku tabel defaultnya adalah 3.600 detik (1 jam), dan deskripsi This is my dataset. Perintah ini menggunakan pintasan -d, bukan flag --dataset. Jika Anda menghapus -d dan --dataset, perintah defaultnya adalah membuat set data.
bq --location=US mk -d \ --default_table_expiration 3600 \ --description "This is my dataset." \ mydataset
Untuk mengonfirmasi bahwa set data telah dibuat, masukkan perintah bq ls. Selain itu, Anda dapat membuat tabel saat membuat set data baru menggunakan format berikut: bq mk -t dataset.table.
Untuk mengetahui informasi selengkapnya tentang cara membuat tabel, lihat Membuat tabel.
Terraform
Gunakan resource google_bigquery_dataset.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Membuat set data
Contoh berikut akan membuat set data bernama mydataset:
Saat Anda membuat set data menggunakan resourcegoogle_bigquery_dataset, resource tersebut akan otomatis memberikan akses untuk set data ke semua akun yang merupakan anggota peran dasar pada level project.
Jika Anda menjalankan terraform show perintah setelah membuat set data, blok access untuk set data akan terlihat mirip dengan berikut ini:
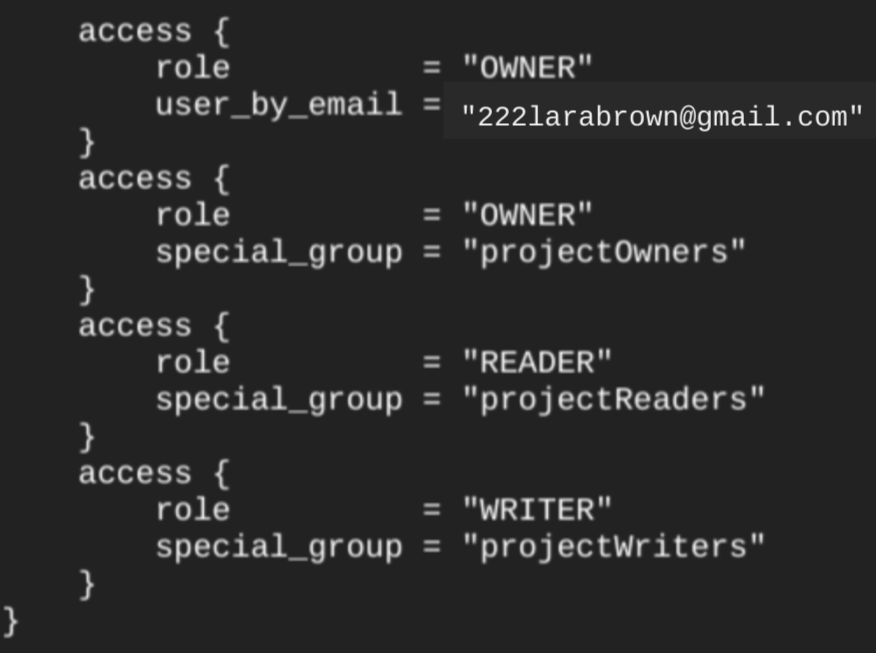
Untuk memberikan akses ke set data, sebaiknya gunakan salah satu resource google_bigquery_iam, seperti ditunjukkan pada contoh berikut, kecuali jika Anda berencana untuk membuat objek yang diotorisasi, seperti tabel virtual yang diotorisasi, dalam set data.
Dalam hal ini, gunakan
resource google_bigquery_dataset_access. Lihat dokumentasi tersebut untuk mengetahui contohnya.
Membuat set data dan memberikan akses ke set data tersebut
Contoh berikut membuat set data bernama mydataset, lalu menggunakan resource google_bigquery_dataset_iam_policy untuk memberikan akses ke set data tersebut.
Membuat set data dengan kunci enkripsi yang dikelola pelanggan
Contoh berikut membuat set data bernama mydataset, dan juga menggunakan google_kms_crypto_key dan resource google_kms_key_ring untuk menentukan kunci Cloud Key Management Service bagi set data. Anda harus mengaktifkan Cloud Key Management Service API sebelum menjalankan contoh ini.
Untuk menerapkan konfigurasi Terraform di project Google Cloud , selesaikan langkah-langkah di bagian berikut.
Menyiapkan Cloud Shell
- Luncurkan Cloud Shell.
-
Tetapkan project Google Cloud default tempat Anda ingin menerapkan konfigurasi Terraform.
Anda hanya perlu menjalankan perintah ini sekali per project, dan dapat dijalankan di direktori mana pun.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Variabel lingkungan akan diganti jika Anda menetapkan nilai eksplisit dalam file konfigurasi Terraform.
Menyiapkan direktori
Setiap file konfigurasi Terraform harus memiliki direktorinya sendiri (juga disebut modul root).
-
Di Cloud Shell, buat direktori dan file baru di dalam direktori tersebut. Nama file harus memiliki
ekstensi
.tf—misalnyamain.tf. Dalam tutorial ini, file ini disebut sebagaimain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
Jika mengikuti tutorial, Anda dapat menyalin kode contoh di setiap bagian atau langkah.
Salin kode contoh ke dalam
main.tfyang baru dibuat.Atau, salin kode dari GitHub. Tindakan ini direkomendasikan jika cuplikan Terraform adalah bagian dari solusi menyeluruh.
- Tinjau dan ubah contoh parameter untuk diterapkan pada lingkungan Anda.
- Simpan perubahan Anda.
-
Lakukan inisialisasi Terraform. Anda hanya perlu melakukan ini sekali per direktori.
terraform init
Secara opsional, untuk menggunakan versi penyedia Google terbaru, sertakan opsi
-upgrade:terraform init -upgrade
Menerapkan perubahan
-
Tinjau konfigurasi dan pastikan resource yang akan dibuat atau
diupdate oleh Terraform sesuai yang Anda inginkan:
terraform plan
Koreksi konfigurasi jika diperlukan.
-
Terapkan konfigurasi Terraform dengan menjalankan perintah berikut dan memasukkan
yespada prompt:terraform apply
Tunggu hingga Terraform menampilkan pesan "Apply complete!".
- Buka Google Cloud project Anda untuk melihat hasilnya. Di konsol Google Cloud , buka resource Anda di UI untuk memastikan bahwa Terraform telah membuat atau mengupdatenya.
API
Panggil metode datasets.insert dengan resource set data yang ditentukan.
C#
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan C# di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery C# API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Go
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Go di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Go API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Java
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Java di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Java API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Node.js
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Node.js di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Node.js API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
PHP
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan PHP di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery PHP API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Python
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Python di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Python API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Ruby
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Ruby di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Ruby API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Menamai set data
Saat Anda membuat set data di BigQuery, nama set data untuk setiap project harus unik. Nama set data dapat berisi hal berikut:
- Maksimal 1,024 karakter.
- Huruf (huruf besar atau huruf kecil), angka, dan garis bawah.
Nama set data peka huruf besar/kecil secara default. mydataset dan MyDataset dapat
berada dalam project yang sama, kecuali jika salah satunya menonaktifkan kepekaan huruf besar/kecil. Untuk contoh, lihat
Membuat set data yang tidak peka huruf besar/kecil
dan Resource: Dataset.
Nama set data tidak boleh berisi spasi atau karakter khusus seperti -, &, @, atau %.
Set data tersembunyi
Set data tersembunyi adalah set data yang namanya dimulai dengan garis bawah. Anda bisa melakukan kueri tabel dan tabel virtual di set data tersembunyi dengan cara yang sama seperti yang Anda lakukan pada set data lainnya. Set data tersembunyi memiliki batasan berikut:
- Set data tersebut disembunyikan dari panel Explorer di konsol Google Cloud .
- Set data tersebut tidak muncul di tabel virtual
INFORMATION_SCHEMAmana pun. - Set data tersembunyi tidak dapat digunakan dengan set data tertaut.
- Set data ini tidak dapat digunakan sebagai set data sumber dengan resource yang diotorisasi berikut:
- Set data tersebut tidak muncul di Data Catalog (tidak digunakan lagi) atau Dataplex Universal Catalog.
Keamanan set data
Untuk mengontrol akses ke set data di BigQuery, lihat Mengontrol akses ke set data. Untuk informasi tentang enkripsi data, lihat Enkripsi dalam penyimpanan.
Langkah berikutnya
- Untuk mengetahui informasi selengkapnya tentang cara menampilkan daftar set data dalam project, lihat Menampilkan daftar set data.
- Untuk mengetahui informasi selengkapnya tentang metadata set data, lihat Mendapatkan informasi tentang set data.
- Untuk mengetahui informasi selengkapnya tentang mengubah properti set data, lihat Memperbarui set data.
- Untuk informasi selengkapnya tentang cara membuat dan mengelola label, lihat Membuat dan mengelola label.
Coba sendiri
Jika Anda baru menggunakan Google Cloud, buat akun untuk mengevaluasi performa BigQuery dalam skenario dunia nyata. Pelanggan baru mendapatkan kredit gratis senilai $300 untuk menjalankan, menguji, dan men-deploy workload.
Coba BigQuery gratis