在 dbt 中使用 BigQuery DataFrames
dbt (資料建構工具) 是開放原始碼的指令列架構,專為現代資料倉儲中的資料轉換作業而設計。dbt 可建立可重複使用的 SQL 和 Python 型模型,簡化模組化資料轉換作業。這項工具會自動調度管理目標資料倉儲中的轉換作業,著重於 ELT 管道的轉換步驟。詳情請參閱 dbt 說明文件。
在 dbt 中,Python 模型是一種資料轉換,可使用 dbt 專案中的 Python 程式碼定義及執行。您不必為轉換邏輯編寫 SQL,而是編寫 Python 指令碼,然後由 dbt 協調在資料倉儲環境中執行。Python 模型可讓您執行資料轉換,這類轉換可能很複雜,或難以用 SQL 表示。這項功能可充分運用 Python 的功能,同時享有 dbt 的專案結構、自動化調度管理、依附元件管理、測試和文件功能。詳情請參閱 Python 模型。
dbt-bigquery 轉接程式支援執行 BigQuery DataFrames 中定義的 Python 程式碼。這項功能適用於 dbt Cloud 和 dbt Core。您也可以複製最新版本的 dbt-bigquery 轉接程式,取得這項功能。
必要的角色
dbt-bigquery 轉接程式支援以 OAuth 為基礎的驗證,以及以服務帳戶為基礎的驗證。
如果您打算使用 OAuth 向 dbt-bigquery 介面卡進行驗證,請管理員授予您下列角色:
- 專案的 BigQuery 使用者角色 (
roles/bigquery.user) - 專案或資料集的 BigQuery 資料編輯者角色 (
roles/bigquery.dataEditor),資料表會儲存於該專案或資料集 - 專案的 Colab Enterprise 使用者角色
(
roles/colabEnterprise.user) - 暫存 Cloud Storage bucket 的Storage 管理員角色 (
roles/storage.admin),用於暫存程式碼和記錄
如果您打算使用服務帳戶向 dbt-bigquery 介面卡進行驗證,請管理員將下列角色授予您打算使用的服務帳戶:
- BigQuery 使用者角色
(
roles/bigquery.user) - BigQuery 資料編輯者角色
(
roles/bigquery.dataEditor) - Colab Enterprise 使用者角色
(
roles/colabEnterprise.user) - 儲存空間管理員角色
(
roles/storage.admin)
如果您使用服務帳戶進行驗證,請一併確認您已為要使用的服務帳戶授予服務帳戶使用者角色 (roles/iam.serviceAccountUser)。
Python 執行環境
dbt-bigquery 介面卡會使用 Colab Enterprise 筆記本執行器服務,執行 BigQuery DataFrames Python 程式碼。dbt-bigquery 轉接程式會自動為每個 Python 模型建立並執行 Colab Enterprise 筆記本。您可以選擇要執行筆記本的Google Cloud 專案。筆記本會執行模型中的 Python 程式碼,並由 BigQuery DataFrames 程式庫轉換為 BigQuery SQL。然後在設定的專案中執行 BigQuery SQL。下圖顯示控制流程:
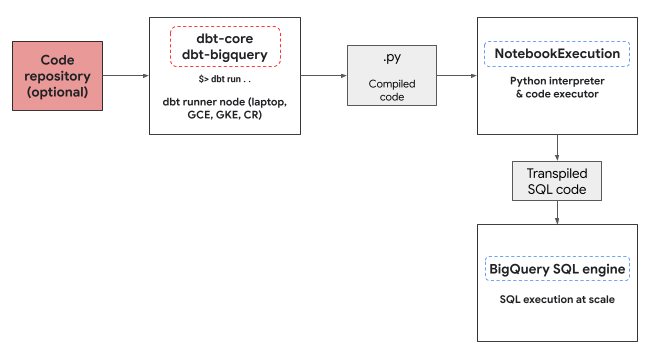
如果專案中沒有可用的筆記本範本,且執行程式碼的使用者有權建立範本,dbt-bigquery介面卡會自動建立並使用預設筆記本範本。您也可以使用 dbt 設定指定其他筆記本範本。
執行 Notebook 時,需要暫存 Cloud Storage bucket 來儲存程式碼和記錄。不過,dbt-bigquery 轉接器會將記錄複製到 dbt 記錄,因此您不必查看 bucket。
支援功能
dbt-bigquery 介面卡支援下列功能,可供執行 BigQuery DataFrames 的 dbt Python 模型使用:
- 使用
dbt.source()巨集從現有 BigQuery 資料表載入資料。 - 使用
dbt.ref()巨集從其他 dbt 模型載入資料,以建構依附元件,並使用 Python 模型建立有向無環圖 (DAG)。 - 指定及使用 PyPi 中的 Python 套件,這些套件可用於執行 Python 程式碼。詳情請參閱「設定」。
- 為 BigQuery DataFrames 模型指定自訂 Notebook 執行階段範本。
dbt-bigquery 轉接程式支援下列具體化策略:
- 資料表具體化,每次執行時都會重建資料表。
- 採用合併策略的增量具體化,將新資料或更新資料新增至現有資料表,通常會使用合併策略來處理變更。
設定 dbt 以使用 BigQuery DataFrames
如果您使用 dbt Core,則必須使用 profiles.yml 檔案搭配 BigQuery DataFrames。以下範例使用 oauth 方法:
your_project_name:
outputs:
dev:
compute_region: us-central1
dataset: your_bq_dateset
gcs_bucket: your_gcs_bucket
job_execution_timeout_seconds: 300
job_retries: 1
location: US
method: oauth
priority: interactive
project: your_gcp_project
threads: 1
type: bigquery
target: dev
如果您使用 dbt Cloud,可以直接在 dbt Cloud 介面連線至資料平台。在這種情況下,您不需要 profiles.yml 檔案。詳情請參閱「關於 profiles.yml」。
以下是 dbt_project.yml 檔案的專案層級設定範例:
# Name your project! Project names should contain only lowercase characters
# and underscores. A good package name should reflect your organization's
# name or the intended use of these models.
name: 'your_project_name'
version: '1.0.0'
# Configuring models
# Full documentation: https://docs.getdbt.com/docs/configuring-models
# In this example config, we tell dbt to build all models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the config(...) macro.
models:
your_project_name:
submission_method: bigframes
notebook_template_id: 7018811640745295872
packages: ["scikit-learn", "mlflow"]
timeout: 3000
# Config indicated by + and applies to all files under models/example/
example:
+materialized: view
您也可以在 Python 程式碼中使用 dbt.config 方法設定部分參數。如果這些設定與 dbt_project.yml 檔案衝突,系統會優先採用 dbt.config 中的設定。
詳情請參閱「模型設定」和「dbt_project.yml」。
設定
您可以使用 Python 模型中的 dbt.config 方法,設定下列設定。這些設定會覆寫專案層級設定。
| 設定 | 必填 | 用量 |
|---|---|---|
submission_method |
是 | submission_method=bigframes |
notebook_template_id |
否 | 如未指定,系統會建立並使用預設範本。 |
packages |
否 | 視需要指定其他 Python 套件清單。 |
timeout |
否 | 選用:延長工作執行逾時時間。 |
Python 模型範例
以下各節將介紹範例情境和 Python 模型。
從 BigQuery 資料表載入資料
如要使用現有 BigQuery 資料表的資料做為 Python 模型中的來源,請先在 YAML 檔案中定義這個來源。以下範例定義於 source.yml 檔案中。
version: 2
sources:
- name: my_project_source # A custom name for this source group
database: bigframes-dev # Your Google Cloud project ID
schema: yyy_test_us # The BigQuery dataset containing the table
tables:
- name: dev_sql1 # The name of your BigQuery table
接著,您會建構 Python 模型,該模型可使用這個 YAML 檔案中設定的資料來源:
def model(dbt, session):
# Configure the model to use BigFrames for submission
dbt.config(submission_method="bigframes")
# Load data from the 'dev_sql1' table within 'my_project_source'
source_data = dbt.source('my_project_source', 'dev_sql1')
# Example transformation: Create a new column 'id_new'
source_data['id_new'] = source_data['id'] * 10
return source_data
參照其他模型
您可以建構依附於其他 dbt 模型輸出的模型,如下例所示。這對建立模組化資料管道來說相當實用。
def model(dbt, session):
# Configure the model to use BigFrames
dbt.config(submission_method="bigframes")
# Reference another dbt model named 'dev_sql1'.
# It assumes you have a model defined in 'dev_sql1.sql' or 'dev_sql1.py'.
df_from_sql = dbt.ref("dev_sql1")
# Example transformation on the data from the referenced model
df_from_sql['id'] = df_from_sql['id'] * 100
return df_from_sql
指定套件依附元件
如果 Python 模型需要 MLflow 或 Boto3 等特定第三方程式庫,您可以在模型的設定中宣告套件,如下例所示。這些套件會安裝在執行環境中。
def model(dbt, session):
# Configure the model for BigFrames and specify required packages
dbt.config(
submission_method="bigframes",
packages=["mlflow", "boto3"] # List the packages your model needs
)
# Import the specified packages for use in your model
import mlflow
import boto3
# Example: Create a DataFrame showing the versions of the imported packages
data = {
"mlflow_version": [mlflow.__version__],
"boto3_version": [boto3.__version__],
"note": ["This demonstrates accessing package versions after import."]
}
bdf = bpd.DataFrame(data)
return bdf
指定非預設範本
如要進一步控管執行環境或使用預先設定的設定,您可以為 BigQuery DataFrames 模型指定非預設的筆記本範本,如下列範例所示。
def model(dbt, session):
dbt.config(
submission_method="bigframes",
# ID of your pre-created notebook template
notebook_template_id="857350349023451yyyy",
)
data = {"int": [1, 2, 3], "str": ['a', 'b', 'c']}
return bpd.DataFrame(data=data)
具體化資料表
dbt 執行 Python 模型時,需要知道如何將結果儲存在資料倉儲中。這稱為「具體化」。
如果是標準資料表具體化,dbt 每次執行時,都會在資料倉儲中建立或完全取代資料表,並使用模型的輸出內容。這項作業預設會執行,您也可以明確設定 materialized='table' 屬性,如下列範例所示。
def model(dbt, session):
dbt.config(
submission_method="bigframes",
# Instructs dbt to create/replace this model as a table
materialized='table',
)
data = {"int_column": [1, 2], "str_column": ['a', 'b']}
return bpd.DataFrame(data=data)
透過合併策略進行增量具體化,dbt 就能只更新資料表中的新資料列或修改過的資料列。這對大型資料集很有用,因為每次都完全重建資料表可能效率不彰。合併策略是處理這些更新的常見方式。
這個方法會透過下列方式智慧整合變更:
- 更新已變更的現有資料列。
- 新增資料列。
- 視設定而定,可選擇刪除來源中已不存在的資料列。
如要使用合併策略,您必須指定 unique_key 屬性,讓 dbt 能夠識別模型輸出內容與現有資料表之間的相符資料列,如下列範例所示。
def model(dbt, session):
dbt.config(
submission_method="bigframes",
materialized='incremental',
incremental_strategy='merge',
unique_key='int', # Specifies the column to identify unique rows
)
# In this example:
# - Row with 'int' value 1 remains unchanged.
# - Row with 'int' value 2 has been updated.
# - Row with 'int' value 4 is a new addition.
# The 'merge' strategy will ensure that only the updated row ('int 2')
# and the new row ('int 4') are processed and integrated into the table.
data = {"int": [1, 2, 4], "str": ['a', 'bbbb', 'd']}
return bpd.DataFrame(data=data)
疑難排解
您可以在 dbt 記錄中觀察 Python 執行作業。
此外,您可以在「Colab Enterprise 執行作業」頁面中查看程式碼和記錄 (包括先前的執行作業)。
帳單
搭配 BigQuery DataFrames 使用 dbt-bigquery 轉接程式時,會產生下列 Google Cloud 費用:
筆記本執行作業:系統會針對筆記本執行階段執行作業收費。詳情請參閱「Notebook 執行階段定價」。
執行 BigQuery 查詢:在筆記本中,BigQuery DataFrames 會將 Python 轉換為 SQL,並在 BigQuery 中執行程式碼。系統會根據專案設定和查詢向您收費,詳情請參閱 BigQuery DataFrame 的定價說明。
您可以在 BigQuery 帳單控制台中,使用下列帳單標籤篩除筆記本執行作業和 dbt-bigquery 介面卡觸發的 BigQuery 執行作業帳單報表:
- BigQuery 執行標籤:
bigframes-dbt-api
後續步驟
- 如要進一步瞭解 dbt 和 BigQuery DataFrames,請參閱「使用 BigQuery DataFrames 搭配 dbt Python 模型」。
- 如要進一步瞭解 dbt Python 模型,請參閱「Python 模型」和「Python 模型設定」。
- 如要進一步瞭解 Colab Enterprise 筆記本,請參閱「使用 Google Cloud 控制台建立 Colab Enterprise 筆記本」。
- 如要進一步瞭解合作夥伴,請參閱「Google Cloud Ready - BigQuery Partners」。 Google Cloud