Regionsübergreifende Dataset-Replikation
Mit der BigQuery-Dataset-Replikation können Sie die automatische Replikation eines Datasets zwischen zwei verschiedenen Regionen oder Multi-Regionen einrichten.
Übersicht
Beim Erstellen eines Datasets in BigQuery wählen Sie die Region oder Multi-Region aus, in der die Daten gespeichert werden. Eine Region ist eine Sammlung von Rechenzentren innerhalb eines geografischen Bereichs. Eine Multiregion ist ein großes geografisches Gebiet, das zwei oder mehr geografische Regionen enthält. Ihre Daten werden in einer der enthaltenen Regionen gespeichert und nicht innerhalb der Multiregion repliziert. Weitere Informationen zu Regionen und Multiregionen finden Sie unter BigQuery-Standorte.
BigQuery speichert Kopien Ihrer Daten immer in zwei verschiedenenGoogle Cloud -Zonen innerhalb des Dataset-Standorts. Eine Zone ist ein Bereitstellungsbereich für Google Cloud Ressourcen innerhalb einer Region. In allen Regionen verwendet die Replikation zwischen Zonen synchrone zweifache Exporte. Die Auswahl eines multiregionalen Standorts bietet keine regionsübergreifende Replikation oder regionale Redundanz, sodass die Verfügbarkeit der Datasets im Falle eines regionalen Ausfalls nicht erhöht wird. Die Daten werden in einer einzelnen Region innerhalb des geografischen Standorts gespeichert.
Sie können Datasets für zusätzliche Georedundanzen replizieren. In BigQuery wird ein sekundäres Replikat des Datasets in einer anderen von Ihnen angegebenen Region erstellt. Dieses Replikat wird dann asynchron zwischen zwei Zonen mit der anderen Region repliziert. Es gibt dann insgesamt vier zonale Kopien.
Dataset-Replikation
Wenn Sie ein Dataset replizieren, werden die Daten in der von Ihnen angegebenen Region in BigQuery gespeichert.
Primäre Region. Wenn Sie ein Dataset zum ersten Mal erstellen, platziert BigQuery es in der primären Region.
Sekundäre Region. Wenn Sie ein Dataset-Replikat hinzufügen, platziert BigQuery das Replikat in der sekundären Region.
Zuerst ist das Replikat in der primären Region das primäre Replikat und das Replikat in der sekundären Region das sekundäre Replikat.
Das primäre Replikat ist beschreibbar, das sekundäre Replikat schreibgeschützt. Schreibvorgänge auf dem primären Replikat werden asynchron auf das sekundäre Replikat repliziert. In den einzelnen Regionen werden die Daten redundant in zwei Zonen gespeichert. Der Netzwerkverkehr verlässt das Google Cloud Netzwerk nie.
Das folgende Diagramm zeigt die Replikation, die bei der Replikation eines Datensatzes auftritt:
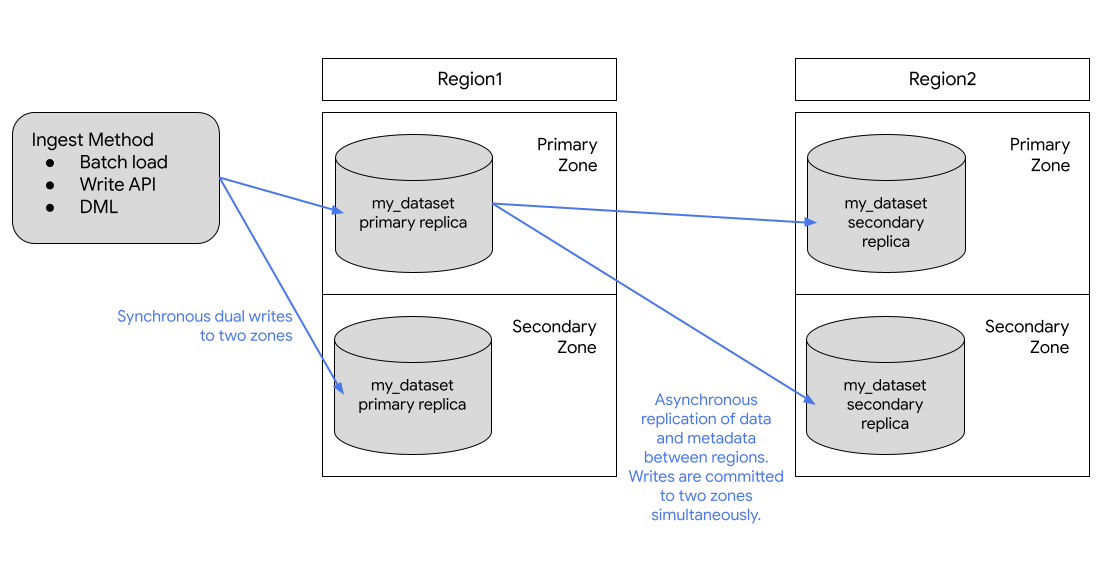
Wenn die primäre Region online ist, können Sie manuell zum sekundären Replikat wechseln. Weitere Informationen finden Sie unter Sekundäres Replikat zum primären Replikat machen.
Preise
Für replizierte Datensätze wird Ihnen Folgendes in Rechnung gestellt:
- Storage. Speicherbyte in der sekundären Region werden als separate Kopie in der sekundären Region abgerechnet. Weitere Informationen finden Sie unter BigQuery-Speicherpreise.
- Datenreplikation. Weitere Informationen zu den Preisen für die Datenreplikation finden Sie unter Preise für die Datenreplikation.
Rechenkapazität in der sekundären Region
Wenn Sie Jobs und Abfragen für das Replikat in der sekundären Region ausführen möchten, müssen Sie Slots in der sekundären Region erwerben oder eine Abfrage auf Abruf ausführen.
Sie können die Slots verwenden, um schreibgeschützte Abfragen vom sekundären Replikat auszuführen. Wenn Sie das sekundäre Replikat zum primären Replikat machen, können Sie auch diese Slots zum Schreiben in das Replikat verwenden.
Sie können die gleiche Anzahl von Slots wie in der primären Region oder eine andere Anzahl an Slots erwerben. Wenn Sie weniger Slots erwerben, kann sich das auf die Abfrageleistung auswirken.
Überlegungen zum Standort
Bevor Sie ein Dataset-Replikat hinzufügen, müssen Sie das ursprüngliche Dataset erstellen, das Sie in BigQuery replizieren möchten, falls es noch nicht vorhanden ist. Der Speicherort des hinzugefügten Replikats ist auf den Standort festgelegt, den Sie beim Hinzufügen des Replikats angeben. Der Speicherort des hinzugefügten Replikats muss sich vom Speicherort des ursprünglichen Datensatzes unterscheiden. Das bedeutet, dass die Daten in Ihrem Dataset kontinuierlich zwischen dem Speicherort, an dem das Dataset erstellt wurde, und dem Speicherort des Replikats repliziert werden. Für Replikate, die am selben Standort gespeichert sein müssen, z. B. Ansichten, materialisierte Ansichten oder externe Nicht-BigLake-Tabellen, fügen Sie ein Replikat an einem Speicherort hinzu, der sich von Ihrer Quelle unterscheidet oder mit dieser nicht kompatibel ist. Der Standort der Daten kann dann zu Jobfehlern führen.
Wenn Kunden ein Dataset über Regionen hinweg replizieren, sorgt BigQuery dafür, dass sich die Daten nur an den Orten befinden, an denen die Repliken erstellt wurden.
Anforderungen an Colocations
Die Verwendung der Datensatzreplikation hängt von den folgenden Anforderungen an die Co-Location ab.
Cloud Storage
Wenn Sie Daten in Cloud Storage abfragen möchten, muss der Cloud Storage-Bucket zusammen mit dem Replikat gespeichert sein. Berücksichtigen Sie bei der Wahl des Speicherorts des Replikats die Überlegungen zum externen Tabellenstandort.
Beschränkungen
Die Replikation von BigQuery-Datasets unterliegt den folgenden Einschränkungen:
- Streamingdaten, die über die BigQuery Storage Write API oder die Methode
tabledata.insertAllin das primäre Replikat geschrieben und dann in das sekundäre Replikat repliziert werden, erfolgen auf Best-Effort-Basis und können zu einer hohen Replikationsverzögerung führen. - Streaming-Upserts, die über Datastream oder BigQuery Change Data Capture in das primäre Replikat geschrieben und dann in das sekundäre Replikat repliziert werden, erfolgen auf Best-Effort-Basis und können zu einer hohen Replikationsverzögerung führen. Nach der Replikation werden die Upserts im sekundären Replikat gemäß dem konfigurierten Wert
max_stalenessder Tabelle in die Tabellengrundlage des sekundären Replikats zusammengeführt. - Sie können die detaillierte DML nicht für eine Tabelle in einem replizierten Datenpool aktivieren und auch keinen Datenpool replizieren, der eine Tabelle mit aktivierter detaillierter DML enthält.
- Replikation und Switchover werden über DDL-Anweisungen (Data Definition Language, Datendefinitionssprache) verwaltet.
- Sie sind auf jeweils ein Replikat jedes Datasets pro Region oder Multi-Region beschränkt. Sie können nicht zwei sekundäre Replikate desselben Datasets in derselben Zielregion erstellen.
- Für Ressourcen in Replicas gelten die Einschränkungen, die unter Ressourcenverhalten beschrieben sind.
- Richtlinien-Tags und zugehörige Datenrichtlinien werden nicht in das sekundäre Replika repliziert. Alle Abfragen, die auf Spalten mit Richtlinien-Tags in anderen Regionen als der ursprünglichen Region verweisen, schlagen fehl, auch wenn das relevante Replikat hochgestuft wurde.
- Zeitreisen sind im sekundären Replikat erst verfügbar, nachdem das Erstellen des sekundären Replikats abgeschlossen wurde.
- Das Limit für die Größe der Zielregion, um die regionsübergreifende Replikation für ein Dataset zu aktivieren, beträgt standardmäßig 10 PB für Multiregionen von
usundeuund 500 TB für andere Regionen. Diese Limits sind konfigurierbar. Weitere Informationen erhältst du vom Google Cloud -Support. - Das Kontingent gilt für logische Ressourcen.
- Sie können ein Dataset nur mit weniger als 100.000 Tabellen replizieren.
- Es können maximal vier Replikate pro Dataset und Tag für dieselbe Region hinzugefügt (und später gelöscht) werden.
- Sie sind durch die Bandbreite eingeschränkt.
- Tabellen, auf die vom Kunden verwaltete Verschlüsselungsschlüssel (CMEK) angewendet werden, können in der sekundären Region nicht abgefragt werden, wenn der Wert für
replica_kms_keynicht konfiguriert ist. - BigLake-Tabellen werden nicht unterstützt.
- Externe oder föderierte Datasets können nicht repliziert werden.
- BigQuery Omni-Speicherorte werden nicht unterstützt.
- Die folgenden Regionspaare können nicht konfiguriert werden, wenn Sie die Datenreplikation für die Notfallwiederherstellung konfigurieren:
us-central1-usMultiregional- Multiregion
us-west1-us - Multiregion
eu-west1-eu - Multiregion
eu-west4-eu
- Zugriffssteuerungen auf Ablaufebene können nicht repliziert werden. Sie können jedoch Zugriffssteuerungen auf Dataset-Ebene für Abläufe replizieren.
Ressourcenverhalten
Die folgenden Vorgänge werden für Ressourcen im sekundären Replikat nicht unterstützt:
Wenn Sie eine Kopie einer Ressource in einem sekundären Replik erstellen möchten, müssen Sie die Ressource kopieren oder abfragen und die Ergebnisse dann außerhalb des sekundären Repliks materialisieren. Verwenden Sie beispielsweise CREATE TABLE AS SELECT, um eine neue Ressource aus der sekundären Replikatressource zu erstellen.
Primäre und sekundäre Replikate unterscheiden sich in folgenden Punkten:
| Primäres Replikat aus Region 1 | Sekundäres Replikat aus Region 2 | Hinweise |
|---|---|---|
| BigLake-Tabelle | BigLake-Tabelle | Nicht unterstützt. |
| Externe Tabelle | Externe Tabelle | Es wird nur die Definition der externen Tabelle repliziert. Die Abfrage schlägt fehl, wenn sich der Cloud Storage-Bucket nicht am selben Speicherort wie ein Replikat befindet. |
| Logische Ansicht | Logische Ansicht | Logische Ansichten, die auf ein nicht am selben Standort wie die logische Ansicht befindlichen Dataset oder eine Ressource verweisen, schlagen bei der Abfrage fehl. |
| Verwaltete Tabelle | Verwaltete Tabelle | Kein Unterschied |
| Materialisierte Ansicht | Materialisierte Ansicht | Wenn sich eine referenzierte Tabelle nicht in derselben Region wie die materialisierte Ansicht befindet, schlägt die Abfrage fehl. Replizierte materialisierte Ansichten sind möglicherweise älter als es das maximale Verwerfsalter der Ansicht erlaubt. |
| Modell | Modell | Sie werden als verwaltete Tabellen gespeichert. |
| Remote-Funktion | Remote-Funktion | Verbindungen sind regional. Remote-Funktionen, die auf ein nicht am selben Standort wie die Remote-Funktion befindliches Dataset oder eine solche Ressource (Verbindung) verweisen, schlagen bei der Ausführung fehl. |
| Routinen | Benutzerdefinierte Funktion (UDFs, User-Defined Functions) oder gespeicherte Prozedur | Routinen, die auf ein nicht am selben Standort wie die Routine befindliches Dataset oder eine solche Ressource verweisen, schlagen bei der Ausführung fehl. Routinen, die auf eine Verbindung verweisen, z. B. Remote-Funktionen, funktionieren nicht außerhalb der Quellregion. |
| Zeilenzugriffsrichtlinie | Zeilenzugriffsrichtlinie | Kein Unterschied |
| Google-Suchindex | Google-Suchindex | Nicht repliziert. |
| Gespeicherte Prozedur | Gespeicherte Prozedur | Stored Procedures, die auf ein nicht am selben Speicherort wie die Stored Procedure befindliches Dataset oder eine solche Ressource verweisen, schlagen bei der Ausführung fehl. |
| Tabellenklon | Verwaltete Tabelle | Wird als Deep Copy im sekundären Replikat abgerechnet. |
| Tabellen-Snapshot | Tabellen-Snapshot | Wird als Deep Copy im sekundären Replikat abgerechnet. |
| Tabellenwertfunktion | TVF | TVFs, die auf ein nicht am selben Standort wie die TVF befindliches Dataset oder eine solche Ressource verweisen, schlagen bei der Ausführung fehl. |
| UDF | UDF | UDFs, die auf ein nicht am selben Standort wie die UDF befindliches Dataset oder eine solche Ressource verweisen, schlagen bei der Ausführung fehl. |
Ausfallszenarien
Die regionenübergreifende Replikation ist nicht als Notfallwiederherstellungsplan bei einem Ausfall einer ganzen Region vorgesehen. Bei einem regionalen Gesamtausfall in der Region des primären Replikats können Sie das sekundäre Replikat nicht hochstufen. Da sekundäre Replikate schreibgeschützt sind, können Sie keine Schreibjobs auf dem sekundären Replikat ausführen und die sekundäre Region erst hochstufen, wenn die Region des primären Replikats wiederhergestellt wurde. Weitere Informationen zur Vorbereitung auf die Notfallwiederherstellung finden Sie unter Verwaltete Notfallwiederherstellung.
In der folgenden Tabelle werden die Auswirkungen von gesamtregionalen Ausfällen auf Ihre replizierten Daten erläutert:
| Region 1 | Region 2 | Region des Ausfalls | Auswirkungen |
|---|---|---|---|
| Primäres Replikat | Sekundäres Replikat | Region 2 | Schreibgeschützte Jobs, die in Region 2 ausgeführt werden, schlagen fehl. |
| Primäres Replikat | Sekundäres Replikat | Region 1 | Alle in Region 1 ausgeführten Jobs schlagen fehl. Schreibgeschützte Jobs werden weiterhin in Region 2 ausgeführt, in der sich das sekundäre Replikat befindet. Der Inhalt von Region 2 ist veraltet, bis er erfolgreich mit Region 1 synchronisiert wird. |
Dataset-Replikation verwenden
In diesem Abschnitt wird beschrieben, wie Sie ein Dataset replizieren, das sekundäre Replikat zum primären Replikat machen und BigQuery-Lesejobs in der sekundären Region ausführen.
Erforderliche Berechtigungen
Bitten Sie Ihren Administrator, Ihnen die Berechtigung bigquery.datasets.update zu erteilen, um die Berechtigungen zu erhalten, die Sie zum Verwalten von Replicas benötigen.
Dataset replizieren
Zum Replizieren eines Datasets verwenden Sie die ALTER SCHEMA ADD REPLICA-DDL-Anweisung.
Sie können ein Replikat zu jedem Dataset hinzufügen, das sich in einer Region oder Multi-Region befindet und noch nicht in dieser Region oder Multi-Region repliziert wurde. Nach dem Hinzufügen eines Replikats dauert es einige Zeit, bis der anfängliche Kopiervorgang abgeschlossen ist. Sie können weiterhin Abfragen ausführen, die auf das primäre Replikat verweisen, während die Daten repliziert werden, ohne dass die Kapazität für die Abfrageverarbeitung reduziert wird. Sie können Daten an den geografischen Standorten innerhalb einer Multi-Region nicht replizieren.
Im folgenden Beispiel wird ein Dataset mit dem Namen my_dataset in der Region us-central1 erstellt und dann ein Replikat in der Region us-east4 hinzugefügt:
-- Create the primary replica in the us-central1 region. CREATE SCHEMA my_dataset OPTIONS(location='us-central1'); -- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `my_replica` OPTIONS(location='us-east4');
Wenn Sie wissen möchten, wann das sekundäre Replikat erfolgreich erstellt wurde, können Sie in der Ansicht INFORMATION_SCHEMA.SCHEMATA_REPLICAS die Spalte creation_complete abfragen.
Nachdem das sekundäre Replikat erstellt wurde, können Sie es abfragen, indem Sie den Speicherort der Abfrage explizit auf die sekundäre Region festlegen. Wenn kein Standort explizit festgelegt ist, verwendet BigQuery die Region des primären Replicas des Datasets.
Sekundäres Replikat hochstufen
Wenn die primäre Region online ist, können Sie das sekundäre Replikat hochstufen. Eine „Hochstufung“ macht das sekundäre Replikat zur beschreibbaren primären Instanz. Dieser Vorgang ist innerhalb weniger Sekunden abgeschlossen, wenn das sekundäre Replikat mit dem primären Replikat synchronisiert ist. Ist das sekundäre Replikat nicht aktuell, kann das Hochstufen erst abgeschlossen werden, wenn es aktuell ist. Das sekundäre Replikat kann nicht zur primären Instanz hochgestuft werden, wenn die Region mit der primären Instanz ausfällt.
Bitte beachten Sie dabei Folgendes:
- Alle Schreibvorgänge in Tabellen geben Fehler zurück, während die Umstellung in Bearbeitung ist. In das alte primäre Replikat kann ab Beginn der Hochstufung nicht mehr geschrieben werden.
- Tabellen, die zur Zeit der Initiierung der Hochstufung nicht vollständig repliziert waren, geben veraltete Lesevorgänge zurück.
Verwenden Sie die DDL-Anweisung ALTER SCHEMA SET
OPTIONS und legen Sie die Option primary_replica fest, um ein Replikat zu einem primären Replikat hochzustufen.
Beachten Sie Folgendes: Sie müssen den Jobstandort in den Abfrageeinstellungen explizit auf die sekundäre Region festlegen. Siehe BigQuery-Standorte angeben.
Im folgenden Beispiel wird das Replikat us-east4 zum primären Replikat hochgestuft:
ALTER SCHEMA my_dataset SET OPTIONS(primary_replica = 'us-east4')
Wenn Sie wissen möchten, wann das sekundäre Replikat erfolgreich hochgestuft wurde, können Sie in der Ansicht INFORMATION_SCHEMA.SCHEMATA_REPLICAS die Spalte replica_primary_assignment_complete abfragen.
Dataset-Replikat entfernen
Verwenden Sie die DDL-Anweisung ALTER SCHEMA DROP REPLICA, um ein Replikat zu entfernen und das Replizieren des Datasets zu beenden.
Im folgenden Beispiel wird das Replikat us entfernt:
ALTER SCHEMA my_dataset DROP REPLICA IF EXISTS `us`;
Sie müssen zuerst alle sekundären Replikate löschen, um den gesamten Datensatz zu löschen. Wenn Sie das gesamte Dataset löschen, z. B. mit der Anweisung DROP
SCHEMA, ohne alle sekundären Replikate zu löschen, erhalten Sie die folgende Fehlermeldung:
The dataset replica of the cross region dataset 'project_id:dataset_id' in region 'REGION' is not yet writable because the primary assignment is not yet complete.
Weitere Informationen finden Sie unter Sekundäres Replikat zum primären Replikat machen.
Dataset-Replikate auflisten
Wenn Sie die Dataset-Replikate in einem Projekt auflisten möchten, fragen Sie die Ansicht INFORMATION_SCHEMA.SCHEMATA_REPLICAS ab.
Datensätze migrieren
Mit der regionsübergreifenden Datensatzreplikation können Sie Ihre Datensätze von einer Region in eine andere migrieren. Das folgende Beispiel zeigt den Prozess der Migration des vorhandenen Datasets my_migration von der Multi-Region US mithilfe der regionenübergreifenden Replikation auf die Multi-Region EU.
Dataset replizieren
Bevor Sie mit der Migration beginnen, müssen Sie das Dataset in der Region replizieren, in die Sie die Daten migrieren möchten. In diesem Szenario migrieren Sie das Dataset my_migration zur Multi-Region EU.
-- Create a replica in the secondary region. ALTER SCHEMA my_migration ADD REPLICA `eu` OPTIONS(location='eu');
Dadurch wird ein sekundäres Replik mit dem Namen eu in der Multi-Region EU erstellt.
Das primäre Replikat ist das Dataset my_migration am multiregionalen Standort US.
Sekundäres Replikat hochstufen
Wenn Sie mit der Migration des Datensatzes zur Multi-Region EU fortfahren möchten, stufen Sie das sekundäre Replikat auf:
ALTER SCHEMA my_migration SET OPTIONS(primary_replica = 'eu')
Nach Abschluss der Umstellung ist eu die primäre Replik. Es ist eine beschreibbare Replik.
Migration abschließen
Um die Migration von der US-Multi-Region zur EU-Multi-Region abzuschließen, löschen Sie das us-Replikat. Dieser Schritt ist nicht erforderlich, aber nützlich, wenn Sie kein Dataset-Replikat benötigen, das über Ihre Migrationsanforderungen hinausgeht.
ALTER SCHEMA my_migration DROP REPLICA IF EXISTS us;
Ihr Dataset befindet sich in der EU-Multi-Region und es gibt keine Replikate des my_migration-Datasets. Sie haben Ihr Dataset erfolgreich in die Multi-Region EU migriert. Eine vollständige Liste der migrierten Ressourcen finden Sie unter Ressourcenverhalten.
Kunden-verwaltete Verschlüsselungsschlüssel (CMEK)
Vom Kunden verwaltete Cloud Key Management Service-Schlüssel werden nicht automatisch repliziert, wenn Sie ein sekundäres Replikat erstellen. Damit die Verschlüsselung für das replizierte Dataset beibehalten wird, müssen Sie replica_kms_key für den Speicherort des hinzugefügten Replikats festlegen. Sie können replica_kms_key mit der DDL-Anweisung ALTER SCHEMA ADD REPLICA festlegen.
Die Replikation von Datensätzen mit CMEK verhält sich in den folgenden Szenarien wie beschrieben:
Wenn das Quell-Dataset ein
default_kms_keyhat, müssen Siereplica_kms_keyangeben, das in der Region des Replikat-Datasets erstellt wurde, wenn die DDL-AnweisungALTER SCHEMA ADD REPLICAverwendet wird.Wenn für
default_kms_keyim Quelldatensatz kein Wert festgelegt ist, können Siereplica_kms_keynicht festlegen.Wenn Sie die Cloud KMS-Schlüsselrotation für
default_kms_keyoderreplica_kms_key(oder für beide Elemente) verwenden, kann das replizierte Dataset nach der Schlüsselrotation weiterhin abgefragt werden.- Die Schlüsselrotation in der primären Region aktualisiert die Schlüsselversion nur in Tabellen, die nach der Rotation erstellt wurden. Tabellen, die vor der Schlüsselrotation vorhanden waren, verwenden weiterhin die Schlüsselversion, die vor der Rotation festgelegt war.
- Durch die Schlüsselrotation in der sekundären Region werden alle Tabellen im sekundären Replikat auf die neue Schlüsselversion aktualisiert.
- Wenn Sie das primäre Replikat auf das sekundäre Replikat umstellen, werden alle Tabellen im sekundären Replikat (das zuvor das primäre Replikat war) auf die neue Schlüsselversion aktualisiert.
- Wenn die Schlüsselversion, die für Tabellen im primären Replikat vor der Schlüsselrotation festgelegt wurde, gelöscht wird, können Tabellen, die noch die Schlüsselversion verwenden, die vor der Schlüsselrotation festgelegt war, erst abgefragt werden, wenn die Schlüsselversion aktualisiert wurde. Damit die Schlüsselversion aktualisiert werden kann, muss die alte Schlüsselversion aktiv sein (d. h. weder deaktiviert noch gelöscht).
Wenn für das Quell-Dataset kein Wert für
default_kms_keyfestgelegt ist, aber einzelne Tabellen im Quell-Dataset mit CMEK angewendet werden, können diese Tabellen im replizierten Dataset nicht abgefragt werden. So fragen Sie die Tabellen ab:- Fügen Sie dem Quelldatensatz einen
default_kms_key-Wert hinzu. - Wenn Sie ein neues Replikat mit der DDL-Anweisung
ALTER SCHEMA ADD REPLICAerstellen, legen Sie einen Wert für die Optionreplica_kms_keyfest. Die CMEK-Tabellen können in der Zielregion abgefragt werden.
Alle CMEK-Tabellen in der Zielregion verwenden dieselbe
replica_kms_key, unabhängig vom Schlüssel, der in der Quellregion verwendet wird.- Fügen Sie dem Quelldatensatz einen
Replikat mit CMEK erstellen
Im folgenden Beispiel wird ein Replikat in der Region us-west1 mit einem festgelegten replica_kms_key-Wert erstellt. Gewähren Sie dem CMEK-Schlüssel die BigQuery-Dienstkonto-Berechtigung zum Verschlüsseln und Entschlüsseln.
-- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `us-west1` OPTIONS(location='us-west1', replica_kms_key='my_us_west1_kms_key_name');
CMEK-Einschränkungen
Für die Replikation von Datasets mit CMEK gelten die folgenden Einschränkungen:
Der replizierte Cloud KMS-Schlüssel kann nach dem Erstellen des Replikats nicht mehr aktualisiert werden.
Der Wert für
default_kms_keykann im Quelldatensatz nicht mehr aktualisiert werden, nachdem die Dataset-Replikate erstellt wurden.Wenn der angegebene
replica_kms_keyin der Zielregion nicht gültig ist, wird das Dataset nicht repliziert.
Nächste Schritte
- Mit BigQuery-Reservierungen arbeiten.
- Weitere Informationen zu Zuverlässigkeitsfunktionen in BigQuery