跨區域資料集複製
透過 BigQuery 資料集複製功能,您可以在兩個不同的區域或多個區域之間設定資料集的自動複製作業。
總覽
在 BigQuery 中建立資料集時,您會選取資料的儲存區域或多區域。「區域」是指地理區域內的資料中心集合,而「多區域」是指包含兩個以上地理區域的大型地理區域。您的資料會儲存在其中一個包含的區域,不會在多個區域中複製。如要進一步瞭解單一地區與多地區,請參閱「BigQuery 位置」一文。
BigQuery 一律會在資料集位置的兩個不同Google Cloud 區域中儲存資料副本。「區域」是地區內 Google Cloud 資源的部署區域。在所有區域中,可用區之間的複製作業都會使用同步雙寫功能。選取多區域位置不會提供跨區域複製或區域備援機制,因此在區域服務中斷時,資料集的可用性不會增加。資料會儲存在地理位置內的單一地區。
如要增加地理冗餘性,您可以複製任何資料集。BigQuery 會建立資料集的次要複本,位於您指定的其他區域。然後,這個副本會在其他區域的兩個可用區之間以非同步方式複製,總共產生四個可用區副本。
資料集複製
如果複製資料集,BigQuery 會將資料儲存在您指定的區域。
主要區域:首次建立資料集時,BigQuery 會將資料集放在主要區域。
次要區域:新增資料集副本時,BigQuery 會將副本放置在次要區域。
最初,主要地區中的備用資源是「主要備用資源」,次要地區中的備用資源則是「次要備用資源」。
主要備用資源可寫入,次要備用資源則為唯讀。寫入主要備用資源的資料會以非同步方式複製到次要備用資源。在每個區域內,資料會備援儲存在兩個可用區中。網路流量絕不會離開 Google Cloud 網路。
下圖顯示複製資料集時發生的複製作業:
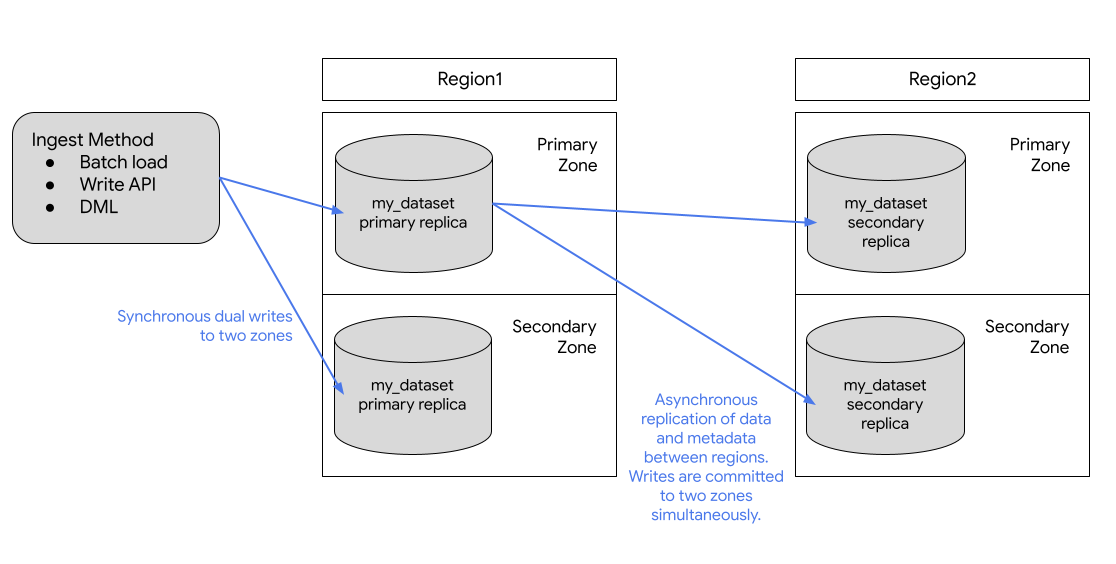
如果主要區域已上線,您可以手動切換至次要複本。詳情請參閱「升級次要複本」。
定價
系統會針對複寫資料集收取下列費用:
- 儲存空間。次要區域中的儲存空間位元組會以次要區域中的個別副本收費。請參閱 BigQuery 儲存空間定價。
- 資料複製。如要進一步瞭解資料複製服務的收費方式,請參閱「資料複製服務定價」。
次要區域的運算能力
如要針對次要區域中的複本執行工作和查詢,您必須在次要區域內購買運算單元,或執行隨選查詢。
您可以使用這些分割區,從次要複本執行唯讀查詢。如果將次要複本升級為主要複本,您也可以使用這些資料格來寫入複本。
您可以購買與主要區域相同數量的運算單元,也可以購買其他數量的運算單元。如果購買的運算單元較少,可能會影響查詢效能。
位置注意事項
在新增資料集副本之前,您必須先建立要複製的初始資料集 (如果尚未建立)。新增複本的位置會設為您在新增複本時指定的位置。新增副本的位置必須與初始資料集的位置不同。這表示資料集的資料會在資料集建立的位置和副本位置之間持續複製。如果是需要共置的副本 (例如檢視畫面、具體化檢視畫面或非 BigLake 外部資料表),如果在與來源資料位置不同的位置新增副本,或是與來源資料位置不相容,可能會導致工作錯誤。
當客戶跨區域複製資料集時,BigQuery 會確保資料只位於複本建立的位置。
主機代管規定
使用資料集複製功能時,必須符合下列並置需求。
Cloud Storage
如要查詢 Cloud Storage 中的資料,Cloud Storage 值區必須與副本一併放置。決定複本放置位置時,請參考外部資料表位置考量。
限制
BigQuery 資料集複製作業有下列限制:
- 透過 BigQuery Storage Write API 或
tabledata.insertAll方法將串流資料寫入主要複本,然後複製到次要複本,這項作業是盡力而為,可能會出現較長的複製延遲時間。 - 從 Datastream 或 BigQuery 變更資料擷取寫入主要副本的串流更新/插入作業,然後複製到次要副本,這項作業是盡力而為,可能會出現較長的複製延遲時間。複製完成後,次要備援資料庫中的上傳/插入作業會根據表格的設定
max_staleness值,合併至次要備援資料庫的表格基準資料。 - 您無法在複本資料集中的資料表上啟用精細 DML,也無法複製包含已啟用精細 DML 的資料表的資料集。
- 複製和切換作業會透過 SQL 資料定義語言 (DDL) 陳述式進行管理。
- 每個區域或多區域,每個資料集最多只能有一個副本。您無法在相同的目的地區域中建立相同資料集的兩個次要複本。
- 副本中的資源會受到「資源行為」一節所述的限制。
- 政策標記和相關資料政策不會複製到次要複本。任何參照原始區域以外的區域中含有政策標記的資料欄的查詢都會失敗,即使該備用資源已升級也一樣。
- 建立次要複本後,您只能在次要複本中使用時間旅行功能。
- 根據預設,在資料集中啟用跨區域複製功能的目的地區域大小限制為
us和eu多區域的 10 PB,其他區域則為 500 TB。這些限制可進行設定。如需詳細資訊,請與Google Cloud 支援團隊聯絡。 - 配額適用於邏輯資源。
- 您只能複製資料表數量少於 100,000 的資料集。
- 每個資料集每天最多只能在同一個區域新增 (然後刪除) 4 個副本。
- 受限於頻寬。
- 如果未設定
replica_kms_key值,則無法在次要區域查詢已套用客戶管理的加密金鑰 (CMEK) 的資料表。 - 不支援 BigLake 資料表。
- 您無法複製外部或聯合資料集。
- 不支援 BigQuery Omni 位置。
- 如果您要設定災難復原資料複製作業,則無法設定下列區域組合:
us-central1-us多地區us-west1-us多地區eu-west1-eu多地區eu-west4-eu多地區
- 您無法複製例行事項層級的存取權控管機制,但可以複製例行事項的資料集層級存取權控管機制。
資源行為
系統不支援在次要複本中的資源上執行下列作業:
如果您需要在次要備用資源中建立資源副本,就必須複製或查詢資源,然後在次要備用資源之外實現結果。舉例來說,您可以使用 CREATE TABLE AS SELECT 陳述式,從次要複本資源建立新資源。
主副本和次要副本之間有下列差異:
| 區域 1 的主要備用資源 | 區域 2 次要備用資源 | 附註 |
|---|---|---|
| BigLake 資料表 | BigLake 資料表 | 不支援。 |
| 外部資料表 | 外部資料表 | 系統只會複製外部資料表定義。如果 Cloud Storage 值區與副本不在同一位置,查詢就會失敗。 |
| 邏輯檢視畫面 | 邏輯檢視畫面 | 查詢時,如果邏輯檢視畫面參照的資料集或資源不在邏輯檢視畫面所在位置,就會失敗。 |
| 受管表格 | 受管表格 | 兩者沒有差別。 |
| 具體化檢視表 | 具體化檢視表 | 如果參照的資料表與具體化檢視表位於不同的區域,查詢就會失敗。備援的具體化檢視表可能會出現超過檢視表過時程度上限的過時情況。 |
| 模型 | 模型 | 儲存為受管理的資料表。 |
| 遠端函式 | 遠端函式 | 連線是區域性資源。參照資料集或資源 (連線) 的遠端函式,如果與遠端函式位於不同位置,則執行時會失敗。 |
| 處理常式 | 使用者定義函式 (UDF) 或已儲存程序 | 如果例行公事參照的資料集或資源不在與例行公事相同的位置,則在執行時會失敗。任何參照連線的例行程序 (例如遠端函式) 都無法在來源區域外運作。 |
| 資料列存取政策 | 資料列存取政策 | 兩者沒有差別。 |
| 搜尋索引 | 搜尋索引 | 未複製。 |
| 預存程序 | 預存程序 | 儲存程序參照的資料集或資源不在儲存程序所在位置,則執行時會失敗。 |
| 資料表本機副本 | 受管表格 | 以次要備援機制中的深層複製作業計費。 |
| 資料表快照 | 資料表快照 | 以次要備援機制中的深層複製作業計費。 |
| 資料表值函式 (TVF) | TVF | 如果 TVF 參照的資料集或資源不在與 TVF 相同的位置,則執行時會失敗。 |
| UDF | UDF | 如果 UDF 參照的資料集或資源不在與 UDF 相同的位置,則執行時會失敗。 |
中斷服務情境
跨區域複製作業不適用於整個區域停機時的災難復原計畫。如果主要備用資源所在的區域發生區域性服務中斷情形,您就無法推送次要備用資源。由於次要備用資源為唯讀,因此您無法在次要備用資源上執行任何寫入工作,而且必須等到主要備用資源的區域復原後,才能提升次要區域。如要進一步瞭解災難復原準備作業,請參閱「受管理的災難復原服務」。
下表說明全區域停機對複寫資料的影響:
| 區域 1 | 區域 2 | 服務中斷區域 | 影響 |
|---|---|---|---|
| 主要備用資源 | 次要備用資源 | 區域 2 | 在區域 2 針對次要備用資源執行的唯讀工作會失敗。 |
| 主要備用資源 | 次要備用資源 | 區域 1 | 在區域 1 執行的所有工作都會失敗。唯讀工作會繼續在次要備用資源所在的區域 2 中執行。區域 2 的內容會一直過時,直到成功與區域 1 同步為止。 |
使用資料集複製功能
本節說明如何複製資料集、升級次要複本,以及在次要區域中執行 BigQuery 讀取工作。
所需權限
如要取得管理複本所需的權限,請要求管理員授予您 bigquery.datasets.update 權限。
複製資料集
如要複製資料集,請使用 ALTER SCHEMA ADD REPLICA DDL 陳述式。
您可以在位於區域或多區域的任何資料集中新增副本,前提是該區域或多區域尚未複製資料。新增複本後,初始複製作業需要一段時間才能完成。在複製資料期間,您仍可執行參照主要備用資源的查詢,且不會影響查詢處理能力。您無法在多區域內的地理位置複製資料。
以下範例會在 us-central1 區域中建立名為 my_dataset 的資料集,然後在 us-east4 區域中新增複本:
-- Create the primary replica in the us-central1 region. CREATE SCHEMA my_dataset OPTIONS(location='us-central1'); -- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `my_replica` OPTIONS(location='us-east4');
如要確認已成功建立次要複本,您可以查詢 INFORMATION_SCHEMA.SCHEMATA_REPLICAS 檢視畫面中的 creation_complete 欄。
建立次要複本後,您可以將查詢的位置明確設定為次要區域,藉此查詢該次要複本。如果未明確設定位置,BigQuery 會使用資料集主要複本的地區。
升級次要備用資源
如果主要區域已上線,您可以升級次要備援機制。升級會將次要備用資源切換為可寫入的主要資料庫。如果次要備用資源已追上主要備用資源,這項作業會在幾秒內完成。如果次要副本未追上,則必須等到追上後,才能完成升級。如果主要區域發生服務中斷情形,次要備用資源就無法升級為主要備用資源。
注意事項:
- 在升級期間,所有寫入資料表的作業都會傳回錯誤。升級開始後,舊的主要複本會立即變成不可寫入。
- 在促銷活動啟動時未完全複製的資料表,會傳回過時的讀取結果。
如要將備用資源推送為主要備用資源,請使用 ALTER SCHEMA SET
OPTIONS DDL 陳述式,並設定 primary_replica 選項。
請注意下列事項: - 您必須在查詢設定中明確將工作位置設為次要區域。請參閱「BigQuery 指定位置」。
以下範例將 us-east4 備用資源推送為主要資料庫:
ALTER SCHEMA my_dataset SET OPTIONS(primary_replica = 'us-east4')
如要確認次要複本已成功升級,您可以查詢 INFORMATION_SCHEMA.SCHEMATA_REPLICAS 檢視畫面中的 replica_primary_assignment_complete 欄。
移除資料集備用資源
如要移除副本並停止複製資料集,請使用 ALTER SCHEMA DROP REPLICA DDL 陳述式。
以下範例會移除 us 副本:
ALTER SCHEMA my_dataset DROP REPLICA IF EXISTS `us`;
您必須先捨棄所有次要複本,才能刪除整個資料集。如果您刪除整個資料集 (例如使用 DROP
SCHEMA 陳述式),但未刪除所有次要複本,系統會傳回以下錯誤:
The dataset replica of the cross region dataset 'project_id:dataset_id' in region 'REGION' is not yet writable because the primary assignment is not yet complete.
詳情請參閱「升級次要複本」。
列出資料集備用資源
如要列出專案中的資料集副本,請查詢 INFORMATION_SCHEMA.SCHEMATA_REPLICAS 檢視畫面。
遷移資料集
您可以使用跨區域資料集複製功能,將資料集從一個區域遷移至另一個區域。以下範例說明如何使用跨區域複寫功能,將現有的 my_migration 資料集從 US 多區域遷移至 EU 多區域。
複製資料集
如要開始遷移程序,請先在要遷移資料的區域中複製資料集。在此情境中,您會將 my_migration 資料集遷移至 EU 多地區。
-- Create a replica in the secondary region. ALTER SCHEMA my_migration ADD REPLICA `eu` OPTIONS(location='eu');
這會在 EU 多區域中建立名為 eu 的次要備用資源。主要複本是 US 多區域中的 my_migration 資料集。
升級次要備用資源
如要繼續將資料集遷移至 EU 多區域,請升級次要複本:
ALTER SCHEMA my_migration SET OPTIONS(primary_replica = 'eu')
升級完成後,eu 就是主要備援機制。這是可寫複本。
完成遷移作業
如要完成從 US 多區域遷移至 EU 多區域的作業,請刪除 us 複本。這不是必要步驟,但如果您不需要資料集副本,除了遷移需求之外,這項操作就很有用。
ALTER SCHEMA my_migration DROP REPLICA IF EXISTS us;
您的資料集位於 EU 多區域,且沒有 my_migration 資料集的副本。您已成功將資料集遷移至 EU 多區域。如需完整的遷移資源清單,請參閱「資源行為」。
由客戶管理的加密金鑰 (CMEK)
建立次要複本時,系統不會自動複製客戶代管的 Cloud Key Management Service 金鑰。為了維持複本資料集的加密狀態,您必須為新增複本的位置設定 replica_kms_key。您可以使用 ALTER SCHEMA ADD REPLICA DDL 陳述式設定 replica_kms_key。
使用 CMEK 複製資料集的行為如下所述:
如果來源資料集含有
default_kms_key,您必須在使用ALTER SCHEMA ADD REPLICADDL 陳述式時,提供在複本資料集區域中建立的replica_kms_key。如果來源資料集未設定
default_kms_key的值,就無法設定replica_kms_key。如果您在
default_kms_key或replica_kms_key上使用 Cloud KMS 金鑰輪替 (或同時使用兩者),則複本資料集在金鑰輪替後仍可查詢。- 主要區域中的金鑰輪替作業只會更新輪替後建立的資料表金鑰版本,在金鑰輪替前建立的資料表仍會使用輪替前設定的金鑰版本。
- 次要區域中的金鑰輪替作業會將次要備用資源中的所有資料表更新為新金鑰版本。
- 將主要備用資源切換為次要備用資源後,系統會將次要備用資源 (先前的主要備用資源) 中的所有資料表更新為新金鑰版本。
- 如果在金鑰輪替之前,主要副本中資料表的金鑰版本設定遭到刪除,則在金鑰版本更新前,任何仍使用金鑰輪替前設定的金鑰版本的資料表都無法查詢。如要更新金鑰版本,舊版金鑰必須處於有效狀態 (未停用或刪除)。
如果來源資料集中沒有設定
default_kms_key的值,但來源資料集中有個別的資料表已套用 CMEK,則無法在複製的資料集中查詢這些資料表。如要查詢資料表,請執行下列操作:- 為來源資料集新增
default_kms_key值。 - 使用
ALTER SCHEMA ADD REPLICADDL 陳述式建立新副本時,請為replica_kms_key選項設定值。您可以在目的地區域查詢 CMEK 資料表。
無論來源區域使用哪個鍵,目的地區域中的所有 CMEK 表格都會使用相同的
replica_kms_key。- 為來源資料集新增
使用 CMEK 建立複本
以下範例會在 us-west1 區域中建立副本,並設定 replica_kms_key 值。針對 CMEK 金鑰,請授予 BigQuery 服務帳戶權限,以便進行加密和解密。
-- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `us-west1` OPTIONS(location='us-west1', replica_kms_key='my_us_west1_kms_key_name');
CMEK 限制
複製已套用 CMEK 的資料集時,會受到下列限制:
備份金鑰建立後,您就無法更新備份的 Cloud KMS 金鑰。
資料集副本建立後,您就無法更新來源資料集的
default_kms_key值。如果提供的
replica_kms_key在目的地區域無效,系統就不會複製資料集。
後續步驟
- 瞭解如何使用 BigQuery 預留項目。
- 瞭解 BigQuery 可靠性功能。