データ マスキングの概要
BigQuery は、列レベルでのデータ マスキングをサポートしています。データ マスキングを使用すると、ユーザー グループに対して列データを選択的に難読化しながら、列へのアクセスを許可できます。データ マスキング機能は、列レベルのアクセス制御の上に構築されているため、続行する前にこの機能についてよく理解しておく必要があります。
データ マスキングを列レベルのアクセス制御と組み合わせて使用すると、さまざまなユーザー グループのニーズに基づいて、完全アクセス権からアクセス権なしまで、列データへのアクセスの範囲を構成できます。たとえば、納税者番号データの場合、アカウント グループに完全アクセス権、アナリスト グループにマスクされたアクセス権を付与し、営業グループはアクセス権なしにすることができます。
利点
データ マスキングには次の利点があります。
- データ共有プロセスが効率化されます。機密性の高い列をマスクすると、より大きなグループでテーブルを共有できます。
- 列レベルのアクセス制御とは異なり、ユーザーがアクセスできない列を除外して既存のクエリを変更する必要はありません。データ マスキングを構成すると、ユーザーに付与されたロールに基づいて既存のクエリが列データを自動的にマスキングします。
- データアクセス ポリシーを大規模に適用できます。データポリシーを作成してポリシータグと関連付けて、ポリシータグを任意の数の列に適用できます。
- 属性ベースのアクセス制御が可能になります。列に添付されたポリシータグによって、データポリシーとそのポリシータグに関連付けられたプリンシパルによって決定される、コンテキストに応じたデータアクセスが提供されます。
データ マスキングのワークフロー
データをマスクする方法は 2 つあります。分類とポリシータグを作成し、ポリシータグにデータポリシーを構成できます。または、列の [プレビュー] でデータポリシーを直接設定することもできます。これにより、ポリシータグを処理したり、追加の分類を作成したりすることなく、データ マスキング ルールをデータにマッピングできます。
列にデータポリシーを直接設定する
列で動的データ マスキングを直接構成できます(プレビュー)。次の手順を実施します。
ポリシータグを使用してデータをマスクする
図 1 は、データ マスキングを構成するワークフローを示しています。
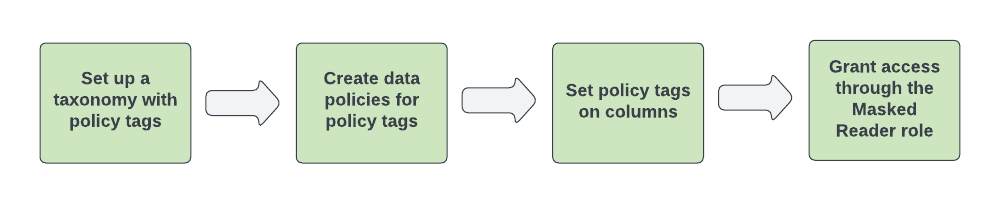 図 1. データ マスキングのコンポーネント。
図 1. データ マスキングのコンポーネント。
データ マスキングは次の手順で構成します。
- 分類と 1 つ以上のポリシータグを設定します。
ポリシータグのデータポリシーを構成します。データポリシーは、データ マスキング ルールと、ユーザーまたはグループを表す 1 つ以上のプリンシパルを、ポリシータグにマッピングします。
Google Cloud コンソールを使用してデータポリシーを作成する場合は、データ マスキング ルールを作成して、1 つのステップでプリンシパルを指定します。BigQuery Data Policy API を使用してデータポリシーを作成する場合は、1 つのステップでデータポリシーとデータ マスキング ルールを作成し、2 つ目のステップでデータポリシーのプリンシパルを指定します。
ポリシータグを BigQuery テーブルの列に割り当てて、データポリシーを適用します。
マスクされたデータにアクセスできるユーザーを、BigQuery のマスクされた読み取りロールに割り当てます。ベスト プラクティスとして、データポリシー レベルで BigQuery のマスクされた読み取りロールを割り当てることをおすすめします。プロジェクト レベル以上でロールを割り当てると、プロジェクト内のすべてのデータポリシーに対する権限がユーザーに付与されます。これにより、過剰な権限が原因で問題が発生する場合があります。
データポリシーに関連付けられているポリシータグは、列レベルのアクセス制御にも使用できます。その場合、ポリシータグは、Data Catalog のきめ細かい読み取りロールが付与された 1 つ以上のプリンシパルにも関連付けられます。これにより、これらのプリンシパルは、マスクされていない元の列データにアクセスできます。
図 2 は、列レベルのアクセス制御とデータ マスキングが連携する仕組みを示しています。
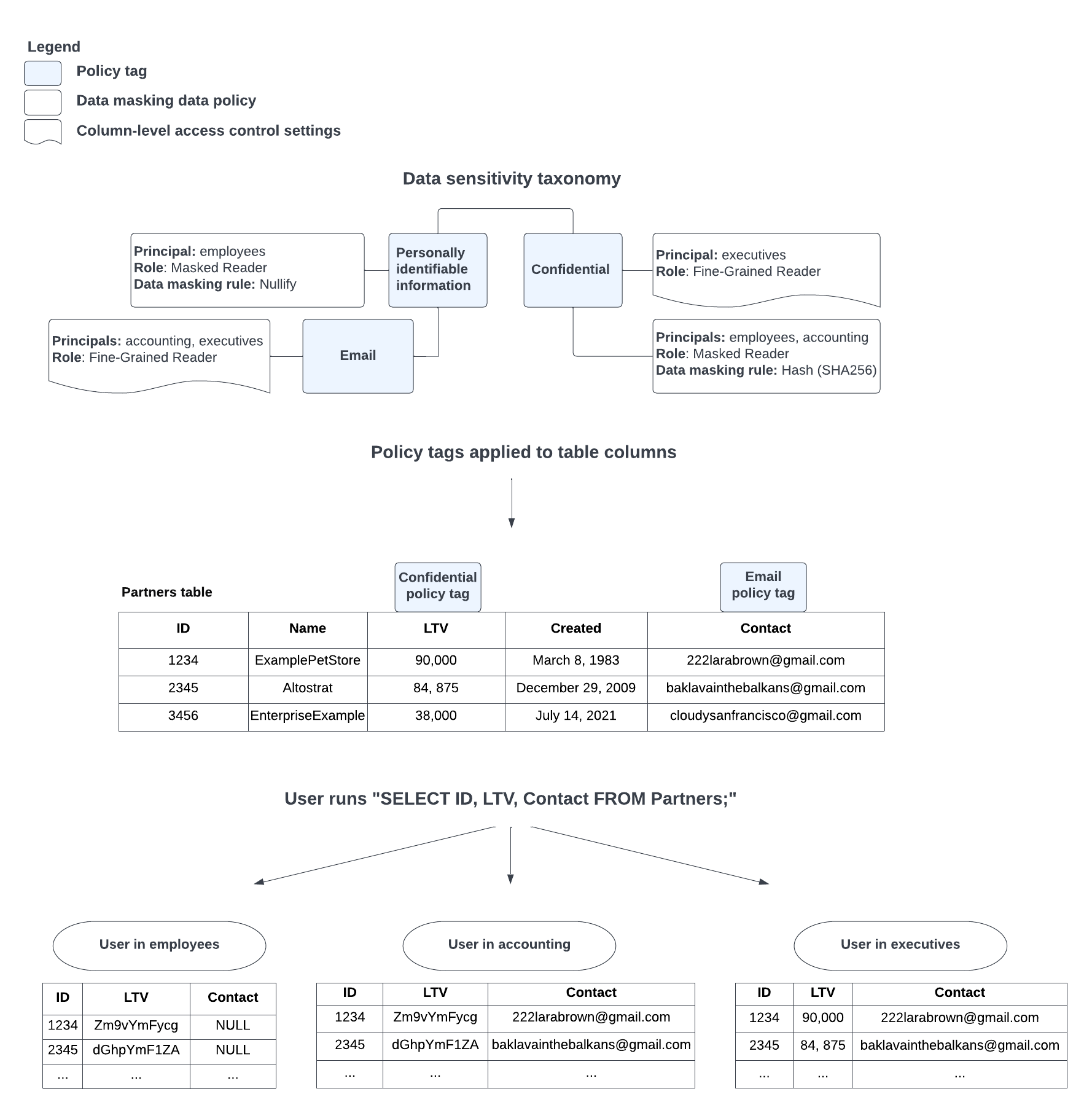 図 2. データ マスキングのコンポーネント。
図 2. データ マスキングのコンポーネント。
ロールのインタラクションの詳細については、マスクされた読み取りロールときめ細かい読み取りロールの仕組みをご覧ください。ポリシータグの継承の詳細については、ロールとポリシータグ階層をご覧ください。
データのマスキング ルール
データ マスキングを使用すると、クエリを実行するユーザーのロールに基づいて、クエリの実行時にデータ マスキング ルールが列に適用されます。マスキングは、クエリに関連する他のすべてのオペレーションよりも優先されます。データ マスキング ルールにより、列データに適用されるデータ マスキングのタイプが決まります。
次のデータ マスキング ルールを使用できます。
カスタム マスキング ルーティン。 ユーザー定義関数(UDF)を列に適用してから、列の値を返します。マスキング ルールを管理するには、ルーティン権限が必要です。このルールは、設計上、
STRUCTデータ型を除くすべての BigQuery データ型をサポートします。ただし、STRINGおよびBYTES以外のデータ型に対するサポートは制限されています。出力は、定義された関数によって異なります。カスタム マスキング ルーティン用の UDF の作成の詳細については、カスタム マスキング ルーティンを作成するをご覧ください。
年月日マスク。値を年に切り捨てて、値の年以外の部分をすべて年の初めに設定した後、列の値を返します。このルールは、
DATE、DATETIME、TIMESTAMPデータ型を使用する列でのみ使用できます。例:種類 元の値 マスク後の値 DATE2030-07-17 2030-01-01 DATETIME2030-07-17T01:45:06 2030-01-01T00:00:00 TIMESTAMP2030-07-17 01:45:06 2030-01-01 00:00:00 デフォルトのマスキング値。列のデータ型に基づいて列のデフォルトのマスキング値を返します。これは、列の値は非表示にするが、データ型は表示する場合に使用します。このデータ マスキング ルールを列に適用すると、マスクされた読み取り権限を持つユーザーに対して、クエリ
JOINオペレーションでの有用性が低下します。これは、テーブルを結合するときにデフォルト値が十分に一意でないためです。次の表に、各データ型のデフォルトのマスキング値を示します。
データ型 デフォルトのマスキング値 STRING"" BYTESb'' INTEGER0 FLOAT0.0 NUMERIC0 BOOLEANFALSETIMESTAMP1970-01-01 00:00:00 UTC DATE1970-01-01 TIME00:00:00 DATETIME1970-01-01T00:00:00 GEOGRAPHYPOINT(0 0) BIGNUMERIC0 ARRAY[] STRUCTNOT_APPLICABLE
ポリシータグは、
STRUCTデータ型を使用する列には適用できませんが、そのような列のリーフ フィールドに関連付けることができます。JSONnull メールマスク。有効なメールアドレスのユーザー名を
XXXXXに置き換えてから、列の値を返します。列の値が有効なメールアドレスでない場合は、SHA-256 ハッシュ関数を実行してから列の値を返します。このルールは、STRINGデータ型を使用する列でのみ使用できます。例:元の値 マスク後の値 abc123@gmail.comXXXXX@gmail.comrandomtextjQHDyQuj7vJcveEe59ygb3Zcvj0B5FJINBzgM6Bypgw=test@gmail@gmail.comQdje6MO+GLwI0u+KyRyAICDjHbLF1ImxRqaW08tY52k=先頭の 4 文字。列の値の先頭の 4 文字を返し、文字列の残りの部分を
XXXXXに置き換えます。列の値の長さが 4 文字以下の場合は、SHA-256 ハッシュ関数を実行してから列の値を返します。このルールは、STRINGデータ型を使用する列でのみ使用できます。ハッシュ(SHA-256)。SHA-256 ハッシュ関数を実行してから列の値を返します。これは、エンドユーザーがクエリの
JOINオペレーションでこの列を使用できるようにする場合に使用します。このルールは、STRINGデータ型またはBYTESデータ型を使用する列でのみ使用できます。データ マスキングで使用される SHA-256 関数は型を保持するため、返されるハッシュ値のデータ型は列の値と同じになります。たとえば、
STRING列の値のハッシュ値はSTRINGデータ型です。末尾の 4 文字。列の値の最後の 4 文字を返し、文字列の残りの部分を
XXXXXに置き換えます。列の値の長さが 4 文字以下の場合は、SHA-256 ハッシュ関数を実行してから列の値を返します。このルールは、STRINGデータ型を使用する列でのみ使用できます。null 化。列の値の代わりに
NULLを返します。これは、列の値とデータ型の両方を非表示にする場合に使用します。このデータ マスキング ルールを列に適用すると、マスクされた読み取り権限を持つユーザーに対して、クエリJOINオペレーションでの有用性が低下します。これは、テーブルを結合するときにNULL値が十分に一意でないためです。
データのマスキング ルールの階層
ポリシータグには最大 9 つのデータポリシーを構成し、それぞれに異なるデータ マスキング ルールを関連付けることができます。これらのポリシーのうち 1 つは、列レベルのアクセス制御設定用に予約されています。これにより、そのユーザーがメンバーになっているグループに基づいて、ユーザーのクエリの列に複数のデータポリシーを適用できます。この場合、BigQuery は、次の階層に基づいて適用するデータ マスキング ルールを選択します。
- カスタム マスキング ルーティン
- ハッシュ(SHA-256)
- メールマスク
- 末尾の 4 文字
- 先頭の 4 文字
- 年月日マスク
- デフォルトのマスキング値
- null 化
たとえば、ユーザー A は従業員グループとアカウント グループの両方のメンバーです。ユーザー A が、confidential ポリシータグが適用された sales_total フィールドを含むクエリを実行します。confidential ポリシータグには、2 つのデータポリシーが関連付けられています。1 つは従業員ロールをプリンシパルとして持ち、null 化データ マスキング ルールを適用するポリシーで、もう 1 つはアカウント ロールをプリンシパルとして持ち、ハッシュ(SHA-256)データ マスキング ルールを適用するポリシーです。この場合、ハッシュ(SHA-256)データ マスキング ルールが null 化データ マスキング ルールよりも優先されるため、ハッシュ(SHA-256)ルールがユーザー A のクエリで sales_total フィールド値に適用されます。
このシナリオを図 3 に示します。

図 3.データ マスキング ルールの優先順位付け。
ロールと権限
分類とポリシータグを管理するためのロール
分類とポリシータグを作成して管理するには、Data Catalog ポリシータグ管理者ロールが必要です。
| ロール / ID | 権限 | 説明 |
|---|---|---|
Data Catalog ポリシータグ管理者 / datacatalog.categoryAdmin |
datacatalog.categories.getIamPolicydatacatalog.categories.setIamPolicydatacatalog.taxonomies.createdatacatalog.taxonomies.deletedatacatalog.taxonomies.getdatacatalog.taxonomies.getIamPolicydatacatalog.taxonomies.listdatacatalog.taxonomies.setIamPolicydatacatalog.taxonomies.updateresourcemanager.projects.getresourcemanager.projects.list
|
プロジェクト レベルで適用されます。 このロールにより、次の権限が付与されます。
|
データポリシーを作成および管理するためのロール
データポリシーを作成して管理するには、次のいずれかの BigQuery ロールが必要です。
| ロール / ID | 権限 | 説明 |
|---|---|---|
BigQuery Data Policy 管理者 / bigquerydatapolicy.admin BigQuery 管理者 / bigquery.admin BigQuery データオーナー / bigquery.dataOwner
|
bigquery.dataPolicies.createbigquery.dataPolicies.deletebigquery.dataPolicies.getbigquery.dataPolicies.getIamPolicybigquery.dataPolicies.listbigquery.dataPolicies.setIamPolicybigquery.dataPolicies.update
|
このロールにより、次の権限が付与されます。
|
datacatalog.taxonomies.get 権限も必要です。この権限は、いくつかの Data Catalog の事前定義ロールから取得できます。ポリシータグを列に適用するためのロール
ポリシータグを列に付加するには、datacatalog.taxonomies.get 権限と bigquery.tables.setCategory 権限が必要です。datacatalog.taxonomies.get は、Data Catalog ポリシータグ管理者ロールと閲覧者ロールに含まれています。bigquery.tables.setCategory は、BigQuery 管理者(roles/bigquery.admin)ロールと BigQuery データオーナー(roles/bigquery.dataOwner)ロールに含まれています。
マスクされたデータに対してクエリを実行するためのロール
データ マスキングが適用された列のデータをクエリするには、BigQuery のマスクされた読み取りロールが必要です。
| ロール / ID | 権限 | 説明 |
|---|---|---|
マスクされた読み取り / bigquerydatapolicy.maskedReader |
bigquery.dataPolicies.maskedGet |
データポリシー レベルで適用されます。 このロールは、データポリシーに関連付けられている列のマスクされたデータを表示する権限を付与します。 この他にも、ユーザーには、テーブルをクエリするための適切な権限が必要です。詳細については、必要な権限をご覧ください。 |
マスクされた読み取りロールときめ細かい読み取りロールの仕組み
データ マスキングは、列レベルのアクセス制御の上に構築されています。特定の列に対して、一部のユーザーには、マスクされたデータの読み取りを許可する「BigQuery のマスクされた読み取り」ロールを付与し、一部のユーザーには、マスクされていないデータの読み取りを許可する「Data Catalog のきめ細かい読み取り」ロールを付与し、一部のユーザーにはその両方を付与し、一部のユーザーにどちらも付与しないようにすることができます。これらのロールは次のように相互作用します。
- きめ細かい読み取りロールとマスクされた読み取りロールの両方を持つユーザー: ユーザーに何が表示されるかは、各ロールが付与されるポリシータグ階層内の場所に応じて異なります。詳細については、ポリシータグ階層での承認の継承をご覧ください。
- きめ細かい読み取りロールを持つユーザー: マスクされていない(不明瞭ではない)列データを表示できます。
- マスクされた読み取りロールを持つユーザー: マスクされた(不明瞭な)列データを表示できます。
- ロールを持たないユーザー: 権限が却下されました。
保護されている列か、保護およびマスクされている列がテーブルにある場合、そのテーブルに対して SELECT * FROM ステートメントを実行するには、ユーザーは適切なグループのメンバーである(それらすべての列に対するマスクされた読み取りロールまたはきめ細かい読み取りロールが付与されている)必要があります。
これらのロールを付与されていないユーザーは、代わりに SELECT ステートメントでアクセス権がある列のみを指定するか、SELECT * EXCEPT
(restricted_columns) FROM を使用して、保護またはマスクされている列を除外する必要があります。
ポリシータグ階層での承認の継承
ロールは列に関連付けられたポリシータグから評価され、ユーザーが適切な権限を持っていると判断されるか、ポリシータグ階層の最上部に達するまで、分類の各レベルで昇順でチェックされます。
たとえば、図 4 に示すポリシータグとデータポリシーの構成を考えます。
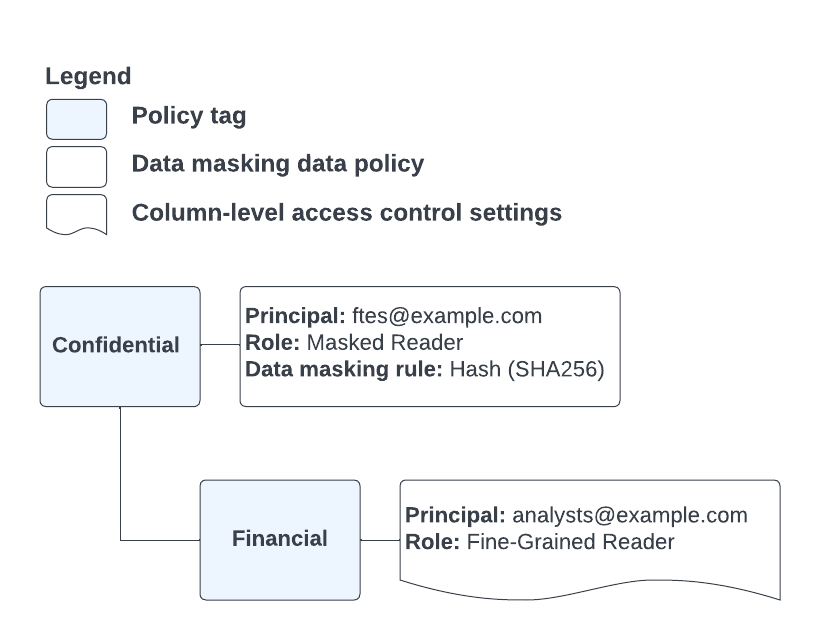
図 4.ポリシータグとデータポリシーの構成。
Financial ポリシータグでアノテーションが付けられたテーブル列と、ftes@example.com と analysts@example.com の両方のグループのメンバーであるユーザーが存在します。このユーザーがアノテーション付きの列を含むクエリを実行すると、ユーザーのアクセス権は、ポリシータグの分類で定義された階層によって決まります。ユーザーには Financial ポリシータグによって Data Catalog のきめ細かい読み取りロールが付与されているため、クエリはマスクされていない列データを返します。
ftes@example.com ロールのみのメンバーである別のユーザーがアノテーション付きの列を含むクエリを実行すると、クエリは、SHA-256 アルゴリズムを使用してハッシュ化された列データを返します。ユーザーには、Financial ポリシータグの親である Confidential ポリシータグによって BigQuery のマスクされた読み取りロールが付与されているためです。
これらのロールのいずれのメンバーでもないユーザーが、アノテーション付き列をクエリしようとすると、アクセス拒否エラーが発生します。
上記のシナリオとは対照的に、図 5 に示すポリシータグとデータポリシーの構成を考えます。
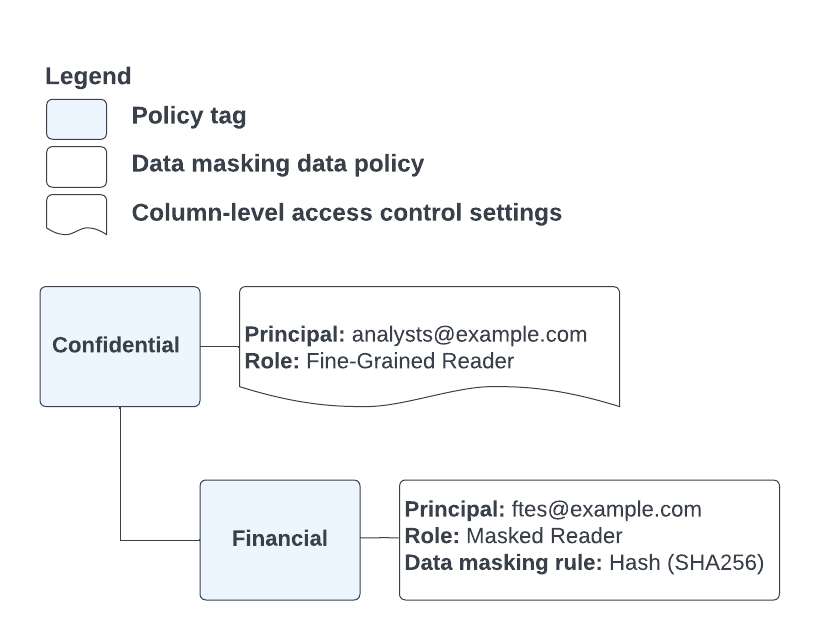
図 5. ポリシータグとデータポリシーの構成。
図 4 と同じ状況ですが、ユーザーにはポリシータグ階層の上位レベルできめ細かい読み取りロールが付与され、ポリシータグ階層の下位レベルでマスクされた読み取りロールが付与されています。 このため、クエリは、このユーザーに対してマスクされた列データを返します。これは、ユーザーがタグ階層のさらに上位できめ細かい読み取りロールが付与されている場合でも発生します。サービスは、ユーザー アクセスについてポリシータグ階層を昇順で確認する際に、最初に出現した割り当て済みのロールを使用するためです。
単一のデータポリシーを作成して、ポリシータグ階層の複数のレベルに適用する場合は、適用する最上位の階層レベルを表すポリシータグにデータポリシーを設定できます。たとえば、次の構造の分類を考えます。
- ポリシータグ 1
- ポリシータグ 1a
- ポリシータグ 1ai
- ポリシータグ 1b
- ポリシータグ 1bi
- ポリシータグ 1bii
- ポリシータグ 1a
データポリシーをこれらのポリシータグのすべてに適用する場合は、ポリシータグ 1 にデータポリシーを設定します。データポリシーをポリシータグ 1b とその子に適用する場合は、ポリシータグ 1b にデータポリシーを設定します。
互換性のない機能を使用したデータ マスキング
データ マスキングと互換性のない BigQuery の機能を使用すると、マスクされている列が保護されている列として扱われ、Data Catalog のきめ細かい読み取りロールを持つユーザーのみにアクセス権が付与されます。
たとえば、図 6 に示すポリシータグとデータポリシーの構成を考えます。
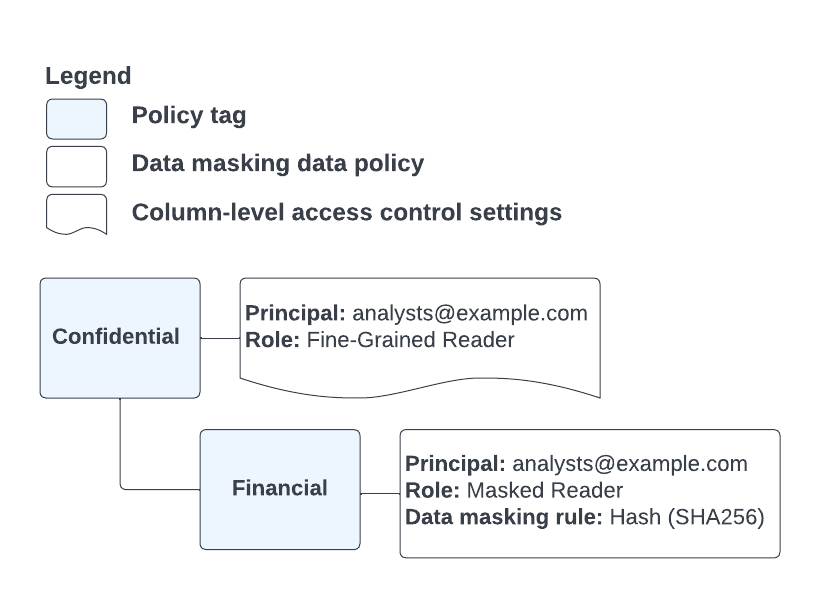
図 6. ポリシータグとデータポリシーの構成。
Financial ポリシータグでアノテーションが付けられたテーブル列と、analysts@example.com グループのメンバーであるユーザーが存在します。このユーザーが、互換性のない機能のいずれかを使用してアノテーション付きの列にアクセスしようとすると、アクセス拒否エラーが発生します。これは、Financial ポリシータグによって BigQuery のマスクされた読み取りロールが付与されているためですが、この場合は Data Catalog のきめ細かい読み取りロールが必要です。サービスではユーザーに適用可能なロールがすでに決定されているため、ポリシータグ階層で権限はそれ以上チェックされません。
出力でのデータ マスキングの例
タグ、プリンシパル、ロールがどのように連携するかを確認するために、次の例を考えます。
example.com で、data-users@example.com グループによって基本的なアクセス権が付与されます。BigQuery データへの定期的なアクセスが必要なすべての従業員がこのグループのメンバーであり、テーブルからの読み取りに必要なすべての権限と、BigQuery のマスクされた読み取りロールが割り当てられています。
従業員は、業務に必要な、保護またはマスクされている列にアクセスできる追加のグループに割り当てられています。これらの追加のグループのメンバーはすべて、data-users@example.com のメンバーでもあります。図 7 は、これらのグループが適切なロールにどのように関連付けられているかを示しています。
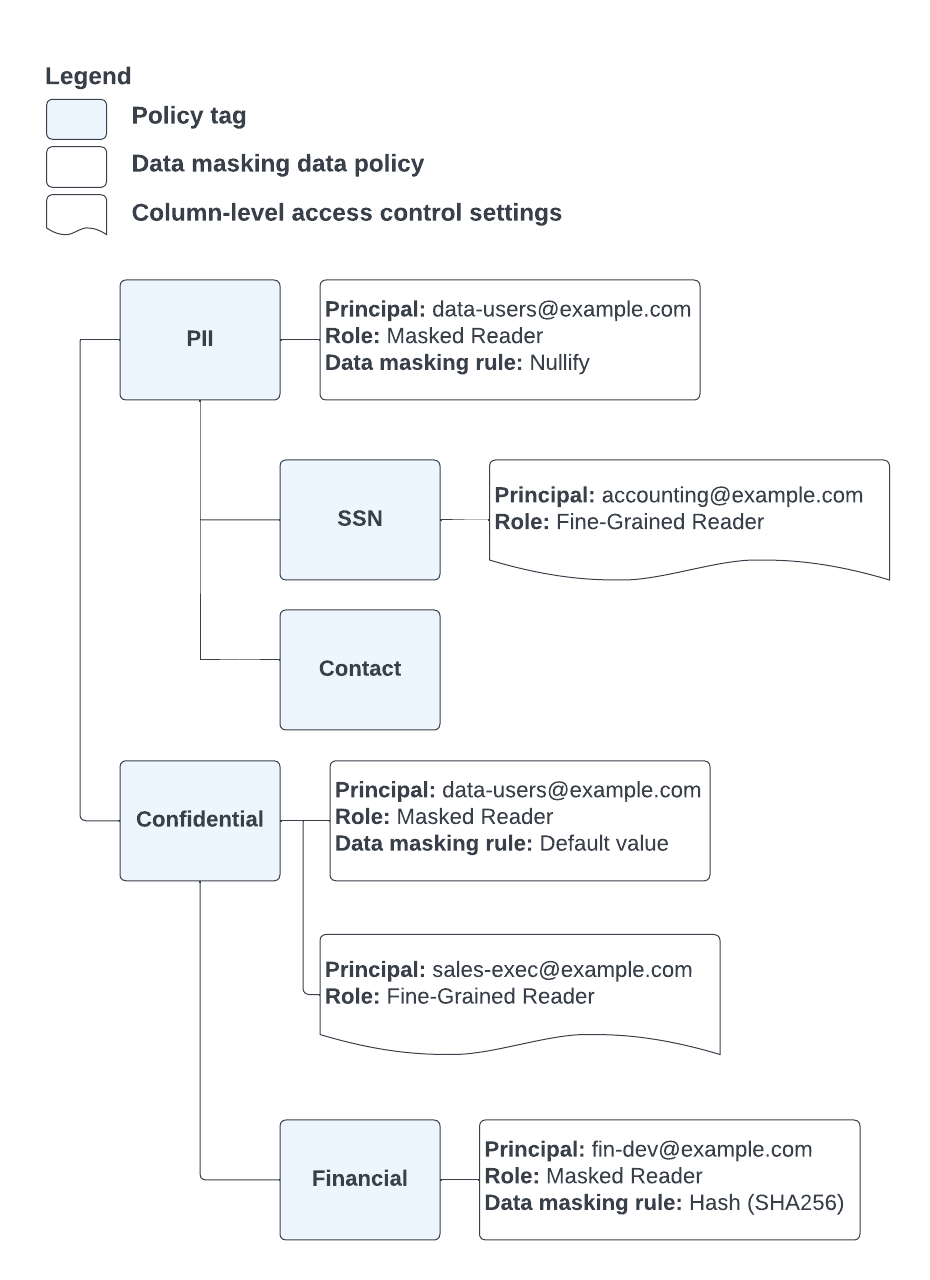
図 7. example.com のポリシータグとデータポリシー。
その後、図 8 に示すように、ポリシータグがテーブル列に関連付けられます。
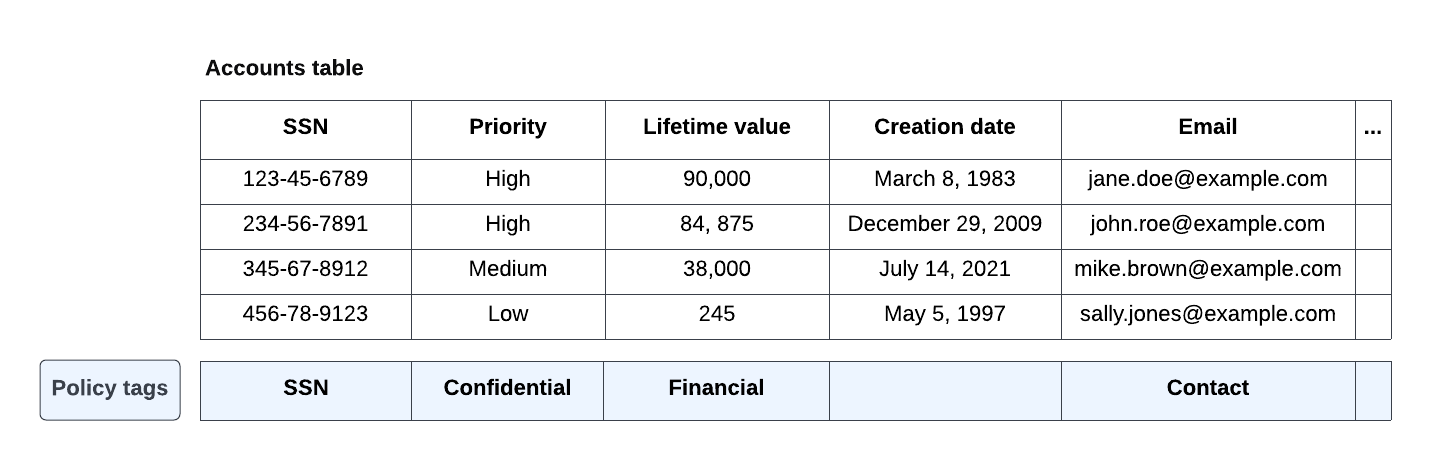
図 8: テーブルの列に関連付けられている example.com のポリシータグ。
列に関連付けられているタグを指定して SELECT * FROM Accounts; を実行すると、さまざまなグループに対して次の結果が得られます。
data-users@example.com: このグループには、
PIIとConfidentialの両方のポリシータグに対する BigQuery のマスクされた読み取りロールが付与されています。次の結果が返されます。SSN 優先度 ライフタイム バリュー 作成日 メール NULL "" 0 1983 年 3 月 8 日 NULL NULL "" 0 2009 年 12 月 29 日 NULL NULL "" 0 2021 年 7 月 14 日 NULL NULL "" 0 1997 年 5 月 5 日 NULL accounting@example.com: このグループには、
SSNポリシータグで Data Catalog のきめ細かい読み取りロールが付与されています。次の結果が返されます。SSN 優先度 ライフタイム バリュー 作成日 NULL 123-45-6789 "" 0 1983 年 3 月 8 日 NULL 234-56-7891 "" 0 2009 年 12 月 29 日 NULL 345-67-8912 "" 0 2021 年 7 月 14 日 NULL 456-78-9123 "" 0 1997 年 5 月 5 日 NULL sales-exec@example.com: このグループには、
Confidentialポリシータグで Data Catalog のきめ細かい読み取りロールが付与されています。次の結果が返されます。SSN 優先度 ライフタイム バリュー 作成日 メール NULL 高 90,000 1983 年 3 月 8 日 NULL NULL 高 84,875 2009 年 12 月 29 日 NULL NULL 中 38,000 2021 年 7 月 14 日 NULL NULL 低 245 1997 年 5 月 5 日 NULL fin-dev@example.com: このグループには
Financialポリシータグで BigQuery のマスクされた読み取りロールが付与されています。次の結果が返されます。SSN 優先度 ライフタイム バリュー 作成日 メール NULL "" Zmy9vydG5q= 1983 年 3 月 8 日 NULL NULL "" GhwTwq6Ynm= 2009 年 12 月 29 日 NULL NULL "" B6y7dsgaT9= 2021 年 7 月 14 日 NULL NULL "" Uh02hnR1sg= 1997 年 5 月 5 日 NULL その他のすべてのユーザー: 一覧表示されたグループのいずれにも属さないユーザーには、Data Catalog のきめ細かい読み取りロールも BigQuery のマスクされた読み取りロールも付与されていないため、アクセス拒否エラーが発生します。
Accountsテーブルに対してクエリを実行するには、代わりに、SELECT * EXCEPT (restricted_columns) FROM Accounts内のアクセス可能な列のみを指定し、保護されているかマスクされている列を除外する必要があります。
費用に関する考慮事項
データ マスキングは、処理されるバイト数に間接的に影響を与える可能性があるため、クエリの課金に影響する場合があります。ユーザーが null 化またはデフォルトのマスキング値のルールを使用してマスクされた列をクエリした場合、その列はまったくスキャンされず、処理されるバイト数が少なくなります。
制限事項
以降のセクションでは、データ マスキングが従う制限のカテゴリについて説明します。
データポリシー管理
- 特定の BigQuery エディションで作成された予約を使用する場合、この機能は使用できません。各エディションで有効になる機能の詳細については、BigQuery エディションの概要をご覧ください。
- ポリシータグには、最大 9 個のデータポリシーを作成できます。これらのポリシーのうち 1 つは、列レベルのアクセス制御設定用に予約されています。
- データポリシー、それに関連付けられたポリシータグ、それらを使用するルーティンはすべて、同じプロジェクト内に存在する必要があります。
ポリシータグ
- ポリシータグの分類を含むプロジェクトは、組織に属している必要があります。
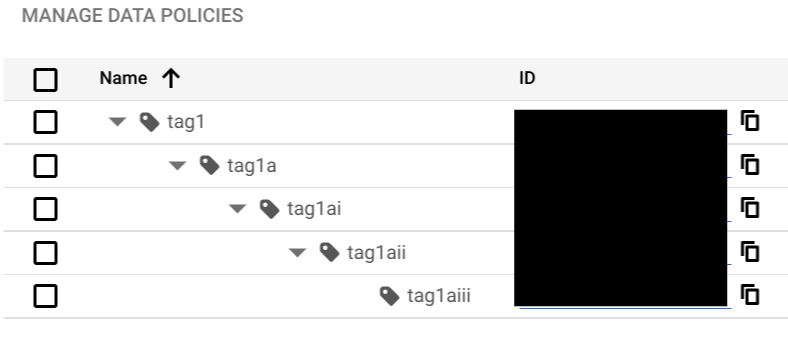
次のスクリーンショットに示すように、ポリシータグ階層は、ルートノードから最下位レベルのサブタグまでの深さが 5 レベルを超えることはできません。
アクセス制御
1 つ以上のポリシータグに関連付けられているデータポリシーを持つ分類には、アクセス制御が自動的に適用されます。アクセス制御をオフにするには、まず分類に関連付けられているすべてのデータポリシーを削除する必要があります。
マテリアライズド ビューと繰り返しのレコード マスキング クエリ
既存のマテリアライズド ビューがある場合、関連するベーステーブルに対する繰り返しのレコード マスキング クエリは失敗します。この問題を解決するには、マテリアライズド ビューを削除します。他の理由でマテリアライズド ビューが必要な場合は、別のデータセットに作成できます。
パーティション分割テーブルのマスクされた列をクエリする
パーティション分割列またはクラスタ化列に対する、データ マスキングを含むクエリはサポートされていません。
SQL 言語
レガシー SQL はサポートされていません。
カスタム マスキング ルーティン
カスタム マスキング ルーティンには次の制限があります。
- データ マスキングは
STRUCTデータ型のリーフ フィールドにのみ適用できるため、カスタム データ マスキングは、STRUCTを除くすべての BigQuery データ型をサポートします。 - カスタム マスキング ルーティンを削除しても、それを使用するすべてのデータポリシーは削除されません。ただし、削除されたマスキング ルーティンを使用するデータポリシーには、空のマスキング ルールが残ります。同じタグを持つ他のデータポリシーによって、マスクされた読み取りロールを持つユーザーは、マスクされたデータを表示できます。それ以外のユーザーの場合、「
Permission denied.」というメッセージが表示されます。空のマスキング ルールへのダングリング参照は、7 日後に自動プロセスによって消去される場合があります。
他の BigQuery 機能との互換性
BigQuery API
tabledata.list メソッドとは互換性がありません。tabledata.list を呼び出すには、このメソッドで返されるすべての列に対する完全アクセス権が必要です。Data Catalog のきめ細かい読み取りロールによって、適切なアクセス権が付与されます。
BigLake テーブル
互換性があります。データ マスキング ポリシーは BigLake テーブルに適用されます。
BigQuery Storage Read API
互換性があります。データ マスキング ポリシーは、BigQuery Storage Read API で適用されます。
BigQuery BI Engine
互換性があります。データ マスキング ポリシーは BI Engine で適用されます。データ マスキングが有効になっているクエリは、BI Engine によって高速化されません。Looker Studio でこのようなクエリを使用すると、関連するレポートやダッシュボードが低速になり、コストが上昇することがあります。
BigQuery Omni
互換性があります。データ マスキング ポリシーは、BigQuery Omni テーブルに適用されます。
照合順序
部分的に互換性があります。DDM は照合された列に適用できますが、マスキングは照合の前に適用されます。このオペレーションの順序により、照合がマスクされた値に意図したとおりに影響しないため(たとえば、マスク後に大文字と小文字を区別しない照合が機能しない)、予期しない結果が生じる可能性があります。マスキング関数を適用する前にデータを正規化するカスタム マスキング ルーティンを使用するなど、回避策は可能です。
コピージョブ
互換性がありません。コピー元からコピー先にテーブルをコピーするには、コピー元テーブルのすべての列に対する完全アクセス権が必要です。Data Catalog のきめ細かい読み取りロールによって、適切なアクセス権が付与されます。
データのエクスポート
互換性があります。BigQuery のマスクされた読み取りロールがある場合、エクスポートされたデータはマスクされます。Data Catalog のきめ細かい読み取りロールがある場合、エクスポートされたデータはマスクされません。
行レベルのセキュリティ
互換性があります。データ マスキングは行レベルのセキュリティに適用されます。たとえば、location = "US" に適用された行アクセス ポリシーがあり、location がマスクされている場合、ユーザーは location = "US" で行を表示できますが、ロケーション フィールドはマスクされます。
BigQuery で検索する
部分的に互換性があります。データ マスキングが適用されたインデックス付きの列またはインデックス付けされていない列で、SEARCH 関数を呼び出すことができます。
データ マスキングが適用されている列で SEARCH 関数を呼び出す場合、アクセスレベルとの互換性のある検索条件を使用する必要があります。たとえば、ハッシュ(SHA-256)データ マスキング ルールによって、マスクされた読み取りアクセス権がある場合、次のように SEARCH 句でハッシュ値を使用します。
SELECT * FROM myDataset.Customers WHERE SEARCH(Email, "sg172y34shw94fujaweu");
きめ細かい読み取りアクセス権がある場合は、次のように SEARCH 句で実際の列の値を使用します。
SELECT * FROM myDataset.Customers WHERE SEARCH(Email, "jane.doe@example.com");
データ マスキング ルールとして null 化またはデフォルトのマスキング値が使用されている列に対して、マスクされた読み取りアクセス権がある場合、検索はあまり役立ちません。これは、検索条件として使用するマスクされた結果(NULL や "" など)は、有用性が十分ではないためです。
データ マスキングが適用されたインデックス付きの列を検索する場合、検索インデックスは、その列に対するきめ細かい読み取りアクセス権がある場合にのみ使用されます。
スナップショット
互換性がありません。テーブルのスナップショットを作成するには、ソーステーブルのすべての列に対する完全アクセス権が必要です。Data Catalog のきめ細かい読み取りロールによって、適切なアクセス権が付与されます。
テーブル名の変更
互換性があります。テーブル名の変更はデータ マスキングの影響を受けません。
タイムトラベル
時間デコレータと SELECT ステートメントの FOR SYSTEM_TIME AS OF オプションの両方との互換性があります。現在のデータセット スキーマのポリシータグが、取得されたデータに適用されます。
クエリのキャッシュ
部分的に互換性があります。BigQuery は約 24 時間クエリ結果をキャッシュに保存しますが、それより前にテーブルのデータまたはスキーマを変更すると、キャッシュは無効になります。次のような状況では、列に対する Data Catalog のきめ細かい読み取りロールが付与されていないユーザーでも、クエリの実行時に列データを表示できます。
- ユーザーに、列に対する Data Catalog のきめ細かい読み取りロールが付与されている。
- ユーザーが、制限された列を含むクエリを実行し、データがキャッシュに保存される。
- ステップ 2 から 24 時間以内に、ユーザーに BigQuery のマスクされた読み取りロールが付与され、Data Catalog のきめ細かい読み取りロールが取り消される。
- ステップ 2 から 24 時間以内に、ユーザーが同じクエリを実行すると、キャッシュされたデータが返される。
ワイルドカード テーブルクエリ
互換性がありません。ワイルドカード クエリに一致するすべてのテーブルの、すべての参照先の列に対する完全アクセス権が必要です。Data Catalog のきめ細かい読み取りロールによって、適切なアクセス権が付与されます。
次のステップ
- 動的データ マスキングを有効にする手順ガイドを確認する。