Introducción a las tablas agrupadas
Las tablas agrupadas en BigQuery son tablas que tienen un orden de clasificación de columnas definido por el usuario mediante columnas agrupadas. Las tablas agrupadas pueden mejorar el rendimiento de las consultas y reducir los costos.
En BigQuery, una columna agrupada es una propiedad de tabla definida por el usuario que ordena los bloques de almacenamiento según los valores de las columnas agrupadas. Los bloques de almacenamiento tienen un tamaño adaptable en función del tamaño de la tabla. La colocación se produce en el nivel de los bloques de almacenamiento y no en el de las filas individuales. Para obtener más información sobre la colocación en este contexto, consulta Agrupamiento en clústeres.
Una tabla agrupada en clústeres mantiene las propiedades de clasificación en el contexto de cada operación que la modifica. Las consultas que filtran o agregan según las columnas agrupadas solo analizan los bloques relevantes en función de las columnas agrupadas en lugar de la tabla completa o la partición de tabla. Como resultado, es posible que BigQuery no pueda estimar con precisión los bytes que se procesarán por la consulta o los costos de la consulta, pero intenta reducir los bytes totales en la ejecución.
Cuando agrupas una tabla con varias columnas, el orden de las columnas determina qué columnas tienen prioridad cuando BigQuery ordena y agrupa los datos en bloques de almacenamiento, como se ve en el siguiente ejemplo. En la tabla 1, se muestra el diseño de bloques de almacenamiento lógico de una tabla no agrupada. En comparación, la tabla 2 solo se agrupa en clústeres según la columna Country, mientras que la tabla 3 se agrupa en clústeres según varias columnas, Country y Status.
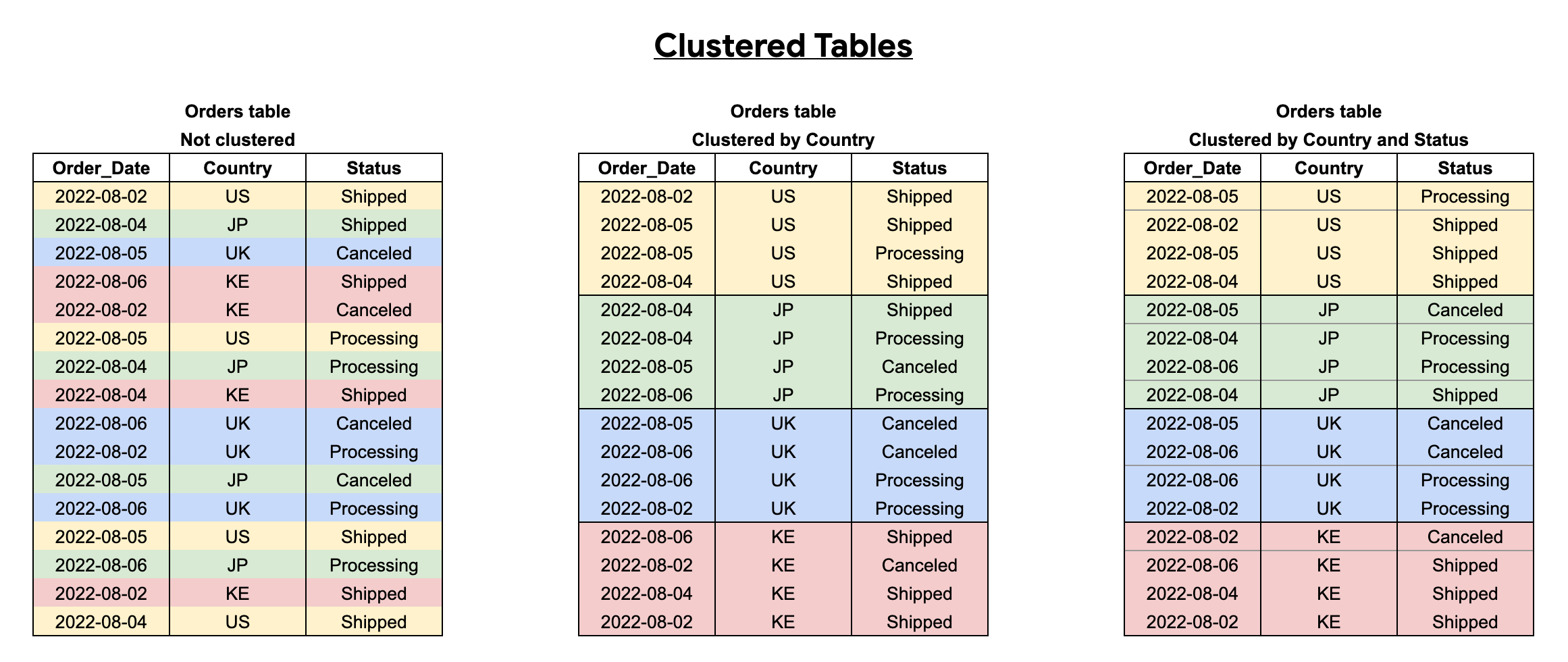
Cuando consultas una tabla agrupada, no recibes una estimación exacta de costos de consulta antes de la ejecución de la consulta, porque no se conoce la cantidad de bloques de almacenamiento que se analizarán antes de la ejecución de la consulta. El costo final se determina después de que se completa la ejecución de la consulta y se basa en los bloques de almacenamiento específicos que se analizaron.
Cuándo usar el agrupamiento en clústeres
Debido a que el agrupamiento aborda la forma en que se almacena una tabla, suele ser una buena primera opción para mejorar el rendimiento de las consultas. Por lo tanto, siempre debes considerar el agrupamiento en clústeres, dadas las siguientes ventajas que proporciona:
- Es probable que las tablas no particionadas de más de 64 MB se beneficien del agrupamiento en clústeres. Del mismo modo, es probable que las particiones de tablas de más de 64 MB se beneficien del agrupamiento en clústeres. Es posible agrupar en clústeres tablas o particiones más pequeñas, pero la mejora del rendimiento suele ser insignificante.
- Si tus consultas suelen filtrar en columnas particulares, el agrupamiento en clústeres acelera las consultas porque la consulta solo analiza los bloques que coinciden con el filtro.
- Si tus consultas filtran columnas que tienen muchos valores distintos (cardinalidad alta), el agrupamiento en clústeres acelera estas consultas ya que proporciona a BigQuery metadatos detallados sobre dónde obtener datos de entrada.
- El agrupamiento en clústeres permite que los bloques de almacenamiento subyacentes de tu tabla tengan un tamaño adaptable según el tamaño de la tabla.
Puedes considerar la partición de tu tabla, además de la agrupación en clústeres. En este enfoque, primero debes segmentar los datos en particiones y, luego, agruparlos en clústeres dentro de cada partición según las columnas de agrupamiento en clústeres. Considera este enfoque en las siguientes circunstancias:
- Necesitas una estimación estricta del costo de la consulta antes de ejecutar una consulta. El costo de las consultas en las tablas agrupadas solo se puede determinar después de ejecutar la consulta. La partición proporciona estimaciones detalladas de costos de consulta antes de ejecutar una consulta.
- La partición de la tabla da como resultado un tamaño de partición promedio de al menos 10 GB por partición. La creación de muchas particiones pequeñas aumenta los metadatos de la tabla y puede afectar los tiempos de acceso a los metadatos cuando se consulta la tabla.
- Debes actualizar tu tabla de forma continua, pero quieres aprovechar los precios del almacenamiento a largo plazo. La partición permite que cada partición se considere por separado para la elegibilidad a largo plazo. Si tu tabla no está particionada, toda tu tabla no se debe editar durante 90 días consecutivos para que se tengan en cuenta en el precio a largo plazo.
Para obtener más información, consulta Combina tablas agrupadas en clústeres y particionadas.
Tipos y orden de columnas agrupadas
En esta sección, se describen los tipos de columnas y cómo funciona el orden de las columnas en el agrupamiento de tablas.
Tipos de columnas agrupadas
Las columnas agrupadas deben ser de nivel superior, no se deben repetir y deben ser de uno de los tipos siguientes:
BIGNUMERICBOOLDATEDATETIMEGEOGRAPHYINT64NUMERICRANGESTRINGTIMESTAMP
Para obtener más información sobre los tipos de datos, consulta Tipos de datos de GoogleSQL.
Orden de las columnas agrupadas
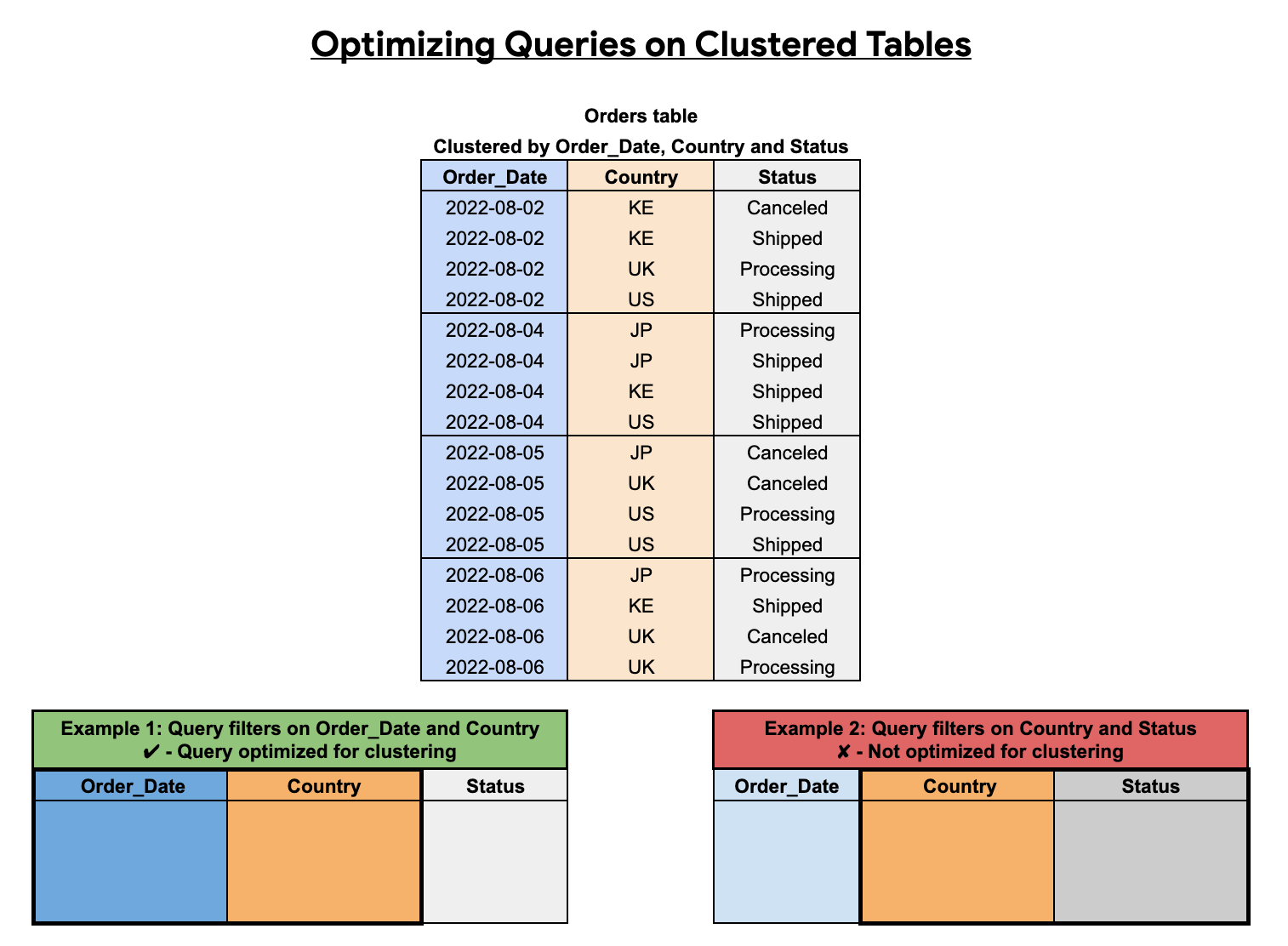
El orden de las columnas agrupadas afecta el rendimiento de las consultas. En el siguiente ejemplo, la tabla Orders se agrupa mediante un orden de clasificación de columnas de Order_Date, Country y Status. La primera columna agrupada en clústeres en este ejemplo es Order_Date, por lo que una consulta que filtra Order_Date y Country está optimizada para el agrupamiento en clústeres, mientras que una consulta que filtra solo Country y Status no está optimizada.
Reducción de bloques
Las tablas agrupadas en clústeres reducen los datos para que las consultas no los procesen, lo que te permite disminuir este tipo de gastos. Este proceso se conoce como reducción de bloques. BigQuery ordena los datos en una tabla agrupada en clústeres según los valores de las columnas de agrupamiento en clústeres y, luego, los organiza en bloques.
Cuando ejecutas una consulta en una tabla agrupada en clústeres, y la consulta tiene un filtro en las columnas agrupadas en clústeres, BigQuery usa la expresión de filtro y los metadatos del bloque a fin de reducir la cantidad de bloques que analiza la consulta. Esto permite que BigQuery analice solo los bloques relevantes.
Cuando se reduce un bloque, no se lo analiza. Para calcular los bytes de datos que procesó la consulta, solo se usan los bloques analizados. La cantidad de bytes que procesó una consulta en una tabla agrupada en clústeres equivale a la suma de los bytes leídos en cada columna a la que hizo referencia la consulta en los bloques analizados.
Si se hace referencia varias veces a una tabla agrupada en clústeres en una consulta que usa muchos filtros, BigQuery cobra por el análisis de las columnas en los bloques apropiados de cada filtro respectivo. Para ver un ejemplo de cómo funciona la reducción de bloques, consulta Ejemplo.
Combina tablas agrupadas en clústeres y particionadas
Puedes combinar el agrupamiento de tablas con la partición de tablas a fin de lograr un orden detallado para una mayor optimización de las consultas.
En una tabla particionada, los datos se almacenan en bloques físicos, y cada uno de ellos contiene una partición de datos. Cada tabla particionada mantiene varios metadatos sobre las propiedades de orden en todas las operaciones que la modifican. Los metadatos permiten que BigQuery calcule con mayor precisión un costo de consulta antes de ejecutar la consulta. Sin embargo, la partición requiere que BigQuery mantenga más metadatos que con una tabla sin particiones. A medida que aumenta la cantidad de particiones, aumenta la cantidad de metadatos que se mantendrán.
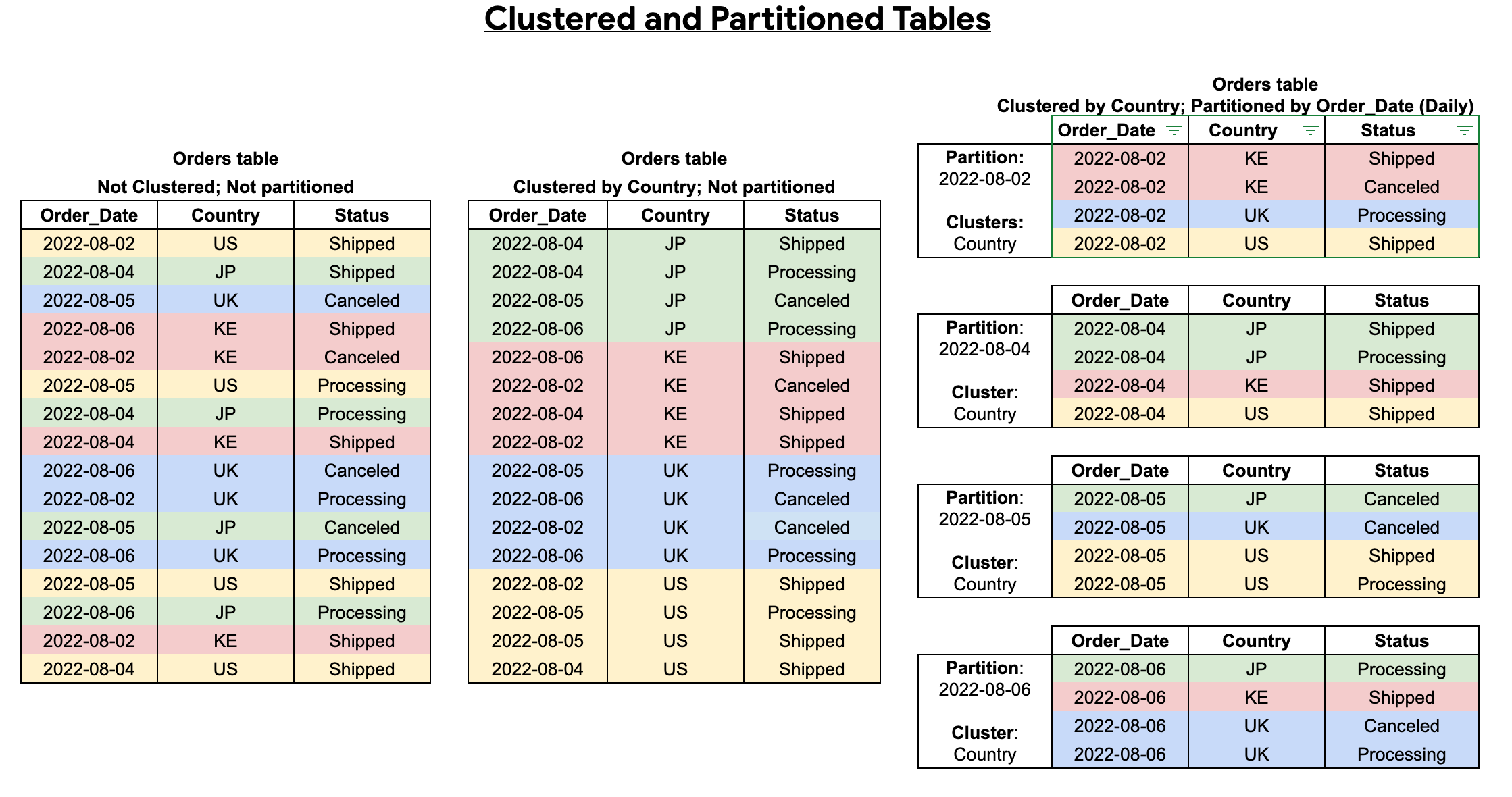
Cuando creas una tabla agrupada y particionada, puedes lograr una clasificación más detallada, como se muestra en el siguiente diagrama:
Ejemplo
Supón que tienes una tabla agrupada en clústeres con el nombre ClusteredSalesData. La tabla está particionada en la columna timestamp y se agrupa en clústeres según la columna customer_id. Los datos se organizan en el conjunto de bloques que se indica a continuación:
| Identificador de la partición | ID del bloque | Valor mínimo de customer_id en el bloque | Valor máximo de customer_id en el bloque |
|---|---|---|---|
| 20160501 | B1 | 10000 | 19999 |
| 20160501 | B2 | 20000 | 24999 |
| 20160502 | B3 | 15000 | 17999 |
| 20160501 | B4 | 22000 | 27999 |
Ejecutas la siguiente consulta en la tabla. La consulta contiene un filtro en la columna customer_id.
SELECT SUM(totalSale) FROM `mydataset.ClusteredSalesData` WHERE customer_id BETWEEN 20000 AND 23000 AND DATE(timestamp) = "2016-05-01"
La consulta anterior implica los siguientes pasos:
- Analiza las columnas
timestamp,customer_idytotalSaleen los bloques B2 y B4. - Reduce el bloque B3 debido al predicado de filtro
DATE(timestamp) = "2016-05-01"en la columna de particióntimestamp. - Reduce el bloque B1 debido al predicado de filtro
customer_id BETWEEN 20000 AND 23000en la columna de agrupamiento en clústerescustomer_id.
Reagrupamiento automático
A medida que se agregan datos a una tabla agrupada, los datos nuevos se organizan en bloques, que pueden crear bloques de almacenamiento nuevos o actualizar bloques existentes. La optimización de bloques es necesaria para un rendimiento óptimo de las consultas y el almacenamiento, ya que es posible que los datos nuevos no se agrupen con datos existentes que tienen los mismos valores de agrupamiento.
Para mantener las características de rendimiento de una tabla agrupada, BigQuery realiza un reagrupamiento automático en segundo plano. En las tablas particionadas, el agrupamiento se mantiene para los datos dentro del alcance de cada partición.
Limitaciones
- Solo se admite GoogleSQL para consultar tablas agrupadas y escribir resultados de consultas en tablas agrupadas.
- Solo puedes especificar hasta cuatro columnas de agrupamiento. Si necesitas columnas adicionales, considera combinar la agrupación con la partición.
- Cuando se usan columnas de tipo
STRINGpara el agrupamiento, BigQuery usa solo los primeros 1,024 caracteres a fin de agrupar los datos. Los valores de las columnas pueden tener más de 1,024 caracteres. - Si modificas una tabla existente no agrupada para agruparla, los datos existentes no se agruparán automáticamente. Solo los datos nuevos que se almacenan con las columnas agrupadas están sujetos al reagrupamiento automático. Para obtener más información sobre cómo volver a agrupar en clústeres datos existentes con una sentencia
UPDATE, consulta Modifica la especificación de agrupamiento en clústeres.
Cuotas y límites de las tablas agrupadas
BigQuery restringe el uso de los Google Cloud recursos compartidos con cuotas y límites, incluidas las limitaciones en ciertas operaciones de tabla o la cantidad de trabajos que se ejecutan en un día.
Cuando utilizas la función de tabla agrupada en clústeres con una tabla particionada, estás sujeto a los límites de las tablas particionadas.
Las cuotas y los límites se aplican a los diferentes tipos de trabajos que puedes ejecutar en las tablas agrupadas. Para obtener más información sobre las cuotas de trabajo que se aplican a tus tablas, consulta Trabajos en "Cuotas y límites".
Precios de las tablas agrupadas en clústeres
Cuando creas y usas tablas agrupadas en BigQuery, el cobro se basa en la cantidad de datos almacenados en las tablas y en las consultas que ejecutas en ellos. Para obtener más información, consulta Precios de almacenamiento y Precios de consulta.
Al igual que otras operaciones de tablas de BigQuery, las operaciones de tabla agrupadas aprovechan las operaciones gratuitas de BigQuery, como la carga por lotes, la copia de tablas, el reagrupamiento automático y la exportación de datos. Estas operaciones están sujetas a las cuotas y los límites de BigQuery. Para obtener información sobre las operaciones gratuitas, consulta Operaciones gratuitas.
Para obtener un ejemplo detallado de precios de tablas agrupadas, visita Estima los costos de almacenamiento y consultas.
Seguridad de las tablas
Para controlar el acceso a las tablas en BigQuery, consulta Controla el acceso a los recursos con IAM.
¿Qué sigue?
- Para aprender cómo crear y usar tablas agrupadas en clústeres, consulta Crea y usa tablas agrupadas.
- Para obtener información sobre cómo consultar tablas agrupadas en clústeres, visita Consulta tablas agrupadas.