Pengantar tabel yang dikelompokkan
Tabel yang dikelompokkan di BigQuery adalah tabel yang memiliki tata urutan kolom buatan pengguna menggunakan kolom yang dikelompokkan. Tabel yang dikelompokkan dapat meningkatkan performa kueri dan mengurangi biaya kueri.
Di BigQuery, kolom yang dikelompokkan adalah properti tabel buatan pengguna yang mengurutkan blok penyimpanan berdasarkan nilai dalam kolom yang dikelompokkan. Blok penyimpanan disesuaikan ukurannya berdasarkan ukuran tabel. Kolokasi terjadi di tingkat blok penyimpanan, bukan di tingkat setiap baris; untuk informasi selengkapnya tentang kolokasi dalam konteks ini, lihat Clustering.
Tabel yang dikelompokkan mempertahankan properti pengurutan dalam konteks setiap operasi yang memodifikasinya. Kueri yang memfilter atau menggabungkan kolom yang dikelompokkan hanya memindai blok yang relevan berdasarkan kolom yang dikelompokkan, bukan seluruh tabel atau partisi tabel. Akibatnya, BigQuery mungkin tidak dapat secara akurat memperkirakan byte yang akan diproses oleh kueri atau biaya kueri, tetapi berupaya mengurangi total byte saat eksekusi.
Jika Anda mengelompokkan tabel menggunakan beberapa kolom, urutan kolom akan menentukan
kolom mana yang lebih diutamakan saat BigQuery mengurutkan dan mengelompokkan
data ke dalam blok penyimpanan, seperti yang terlihat dalam contoh berikut. Tabel 1 menunjukkan
tata letak blok penyimpanan logis dari tabel yang tidak dikelompokkan. Sebagai perbandingan, tabel 2
hanya dikelompokkan berdasarkan kolom Country, sedangkan tabel 3 dikelompokkan berdasarkan beberapa
kolom, Country dan Status.
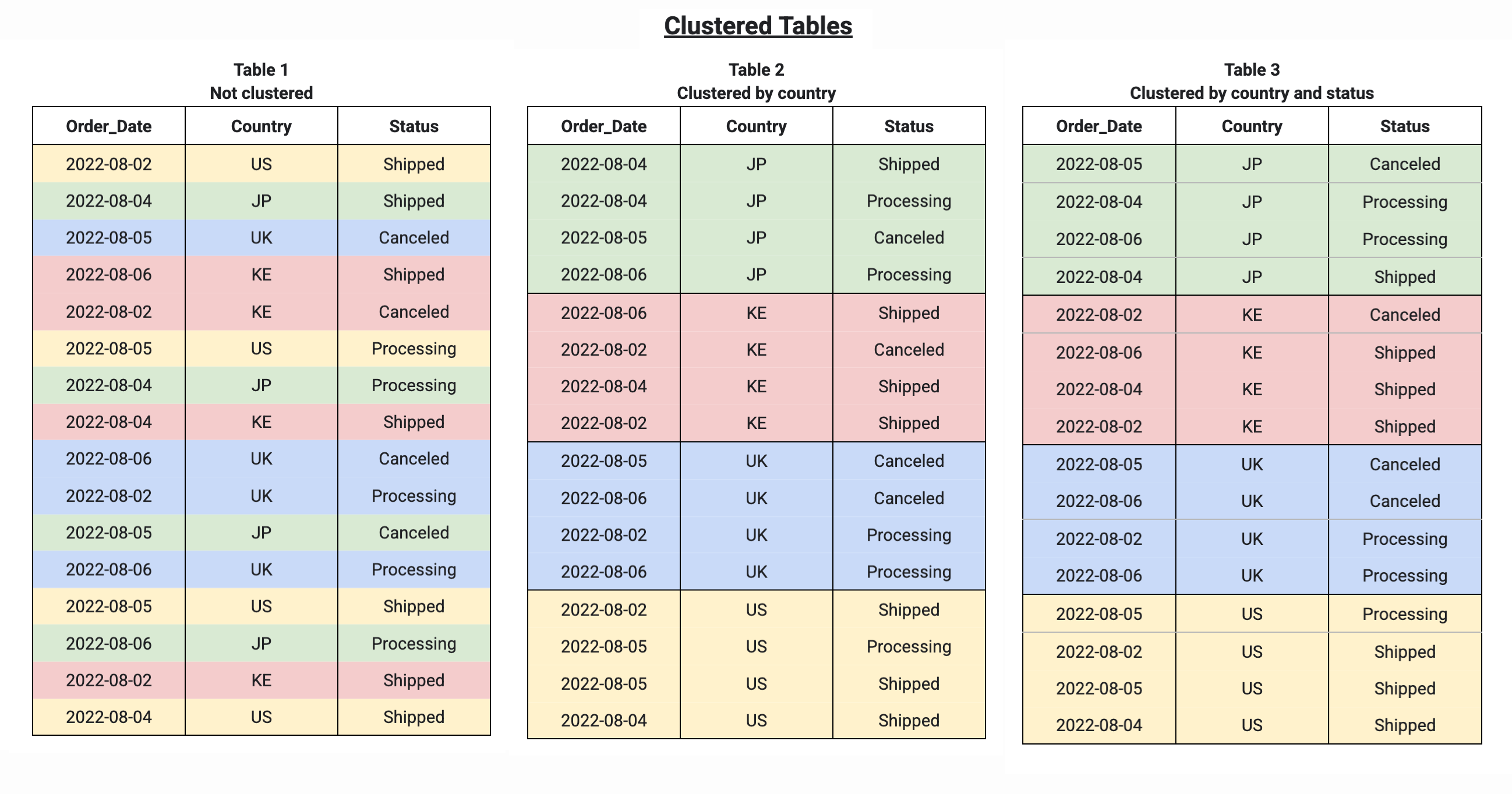
Saat membuat kueri tabel yang dikelompokkan, Anda tidak akan menerima perkiraan biaya kueri yang akurat sebelum eksekusi kueri karena jumlah blok penyimpanan yang akan dipindai tidak diketahui sebelum eksekusi kueri. Biaya akhir ditentukan setelah eksekusi kueri selesai dan didasarkan pada blok penyimpanan tertentu yang dipindai.
Kapan harus menggunakan pengelompokan
Pengelompokan menangani cara penyimpanan tabel, sehingga secara umum ini merupakan opsi pertama yang baik untuk meningkatkan performa kueri. Oleh karena itu, Anda harus selalu mempertimbangkan untuk mengelompokkan dengan mempertimbangkan keuntungan yang diberikannya berikut ini:
- Tabel yang tidak dipartisi dan berukuran lebih dari 64 MB kemungkinan akan mendapatkan manfaat dari clustering. Demikian pula, partisi tabel yang lebih besar dari 64 MB juga kemungkinan akan mendapatkan manfaat dari pengelompokan. Pengelompokan tabel atau partisi yang lebih kecil mungkin dilakukan, tetapi peningkatan performanya biasanya tidak signifikan.
- Jika kueri Anda umumnya memfilter kolom tertentu, pengelompokan akan mempercepat kueri karena kueri hanya memindai blok yang cocok dengan filter.
- Jika kueri Anda memfilter kolom yang memiliki banyak nilai berbeda (kardinalitas tinggi), pengelompokan akan mempercepat kueri ini dengan memberikan metadata mendetail terkait tempat untuk mendapatkan data input kepada BigQuery.
- Pengelompokan memungkinkan blok penyimpanan yang mendasarinya pada tabel Anda diberi ukuran secara adaptif berdasarkan ukuran tabel.
Sebaiknya Anda mempertimbangkan untuk mempartisi tabel selain pengelompokan. Dalam pendekatan ini, pertama-tama Anda akan menyegmentasi data menjadi beberapa partisi, lalu mengelompokkan data dalam setiap partisi berdasarkan kolom pengelompokan. Pertimbangkan pendekatan ini dalam keadaan berikut:
- Anda memerlukan perkiraan biaya kueri yang ketat sebelum menjalankan kueri. Biaya kueri pada tabel yang dikelompokkan hanya dapat ditentukan setelah kueri dijalankan. Dengan membuat partisi, akan menghasilkan perkiraan biaya kueri terperinci sebelum Anda menjalankan kueri.
- Dengan membuat partisi tabel, akan menghasilkan ukuran partisi rata-rata setidaknya 10 GB per partisi. Degan membuat banyak partisi kecil, akan meningkatkan metadata tabel, dan dapat memengaruhi waktu akses metadata saat membuat kueri tabel.
- Anda perlu terus mengupdate tabel, tetapi masih ingin memanfaatkan harga penyimpanan jangka panjang. Dengan mempartisi, setiap partisi akan dapat dipertimbangkan secara terpisah guna memenuhi syarat untuk harga jangka panjang. Jika tabel Anda tidak dipartisi, maka seluruh tabel tidak boleh diedit selama 90 hari berturut-turut agar dapat dipertimbangkan untuk harga jangka panjang.
Untuk informasi selengkapnya, lihat Menggabungkan tabel berpartisi dan yang dikelompokkan.
Pengurutan dan jenis kolom cluster
Bagian ini menjelaskan jenis kolom dan cara kerja urutan kolom dalam pengelompokan tabel.
Jenis kolom cluster
Kolom cluster harus berupa kolom level atas dan tidak berulang yang merupakan salah satu dari jenis berikut:
BIGNUMERICBOOLDATEDATETIMEGEOGRAPHYINT64NUMERICRANGESTRINGTIMESTAMP
Untuk mengetahui informasi selengkapnya tentang jenis data, lihat Jenis data GoogleSQL.
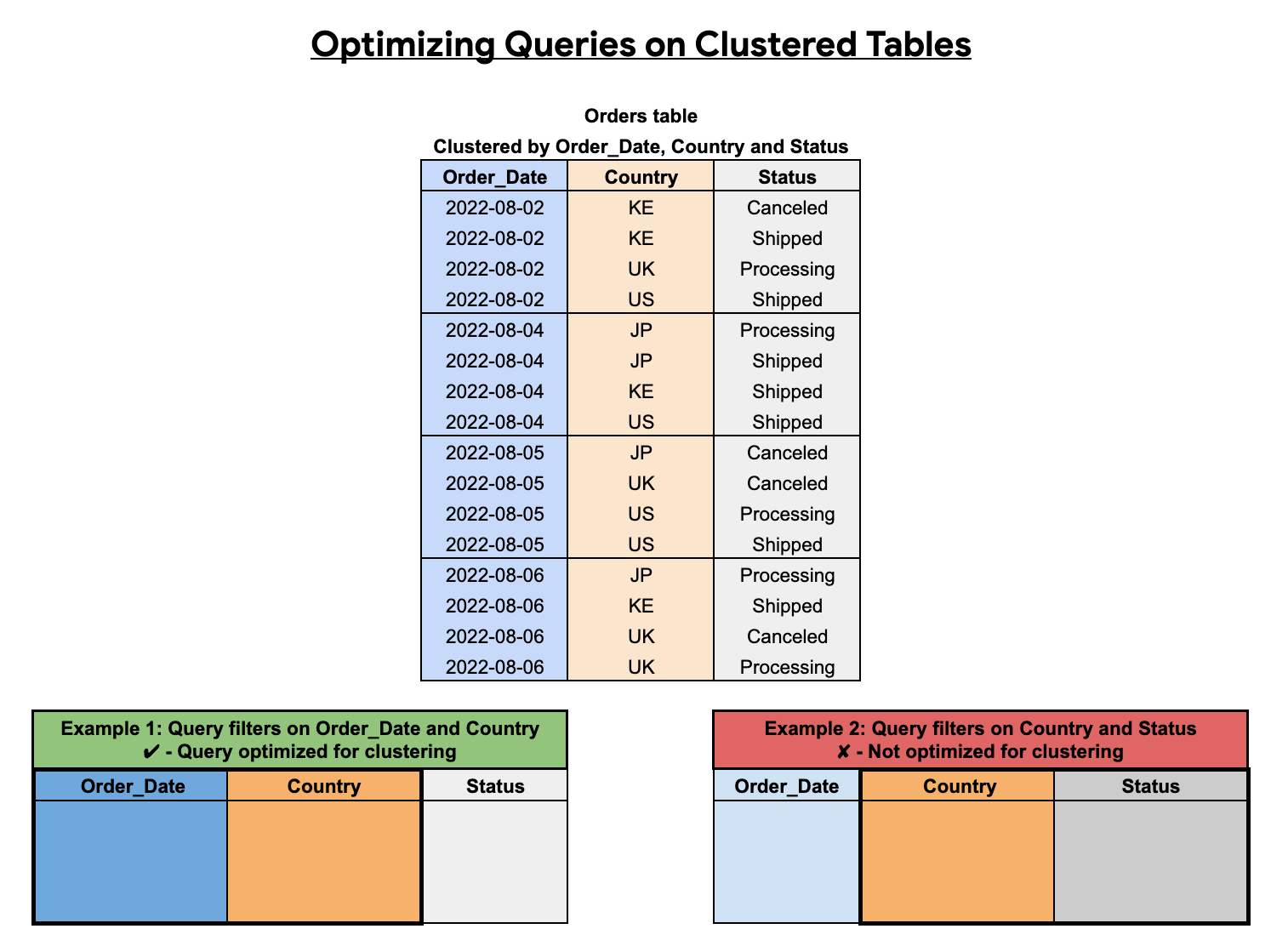
Pengurutan kolom cluster
Urutan kolom yang dikelompokkan akan memengaruhi performa kueri. Pada contoh berikut, tabel Orders dikelompokkan menggunakan tata
urutan kolom Order_Date, Country, dan Status. Kolom cluster pertama dalam
contoh ini adalah Order_Date, sehingga kueri yang memfilter pada Order_Date dan
Country dioptimalkan untuk pengelompokan, sedangkan kueri yang memfilter hanya pada
Country dan Status tidak dioptimalkan.
Pemangkasan blok
Tabel yang dikelompokkan dapat membantu Anda mengurangi biaya kueri dengan memangkas data agar tidak diproses oleh kueri. Proses ini disebut sebagai pemangkasan blok. BigQuery mengurutkan data dalam tabel yang dikelompokkan berdasarkan pada nilai kolom pengelompokan dan mengelolanya menjadi blok.
Saat Anda menjalankan kueri terhadap tabel yang dikelompokkan, dan kueri menyertakan filter pada kolom yang dikelompokkan, BigQuery akan menggunakan ekspresi filter dan metadata blok untuk memangkas blok yang dipindai oleh kueri. Hal ini memungkinkan BigQuery untuk hanya memindai blok yang relevan.
Ketika dipangkas, blok tidak akan dipindai. Hanya blok yang dipindai yang digunakan untuk menghitung byte data yang diproses oleh kueri. Jumlah byte yang diproses oleh kueri terhadap tabel yang dikelompokkan sama dengan jumlah byte yang dibaca di setiap kolom yang dirujuk oleh kueri pada blok yang dipindai.
Jika tabel yang dikelompokkan dirujuk beberapa kali dalam kueri yang menggunakan sejumlah filter, BigQuery akan mengenakan biaya atas pemindaian kolom di blok yang sesuai di masing-masing filter. Untuk contoh cara kerja pemangkasan blok, lihat Contoh.
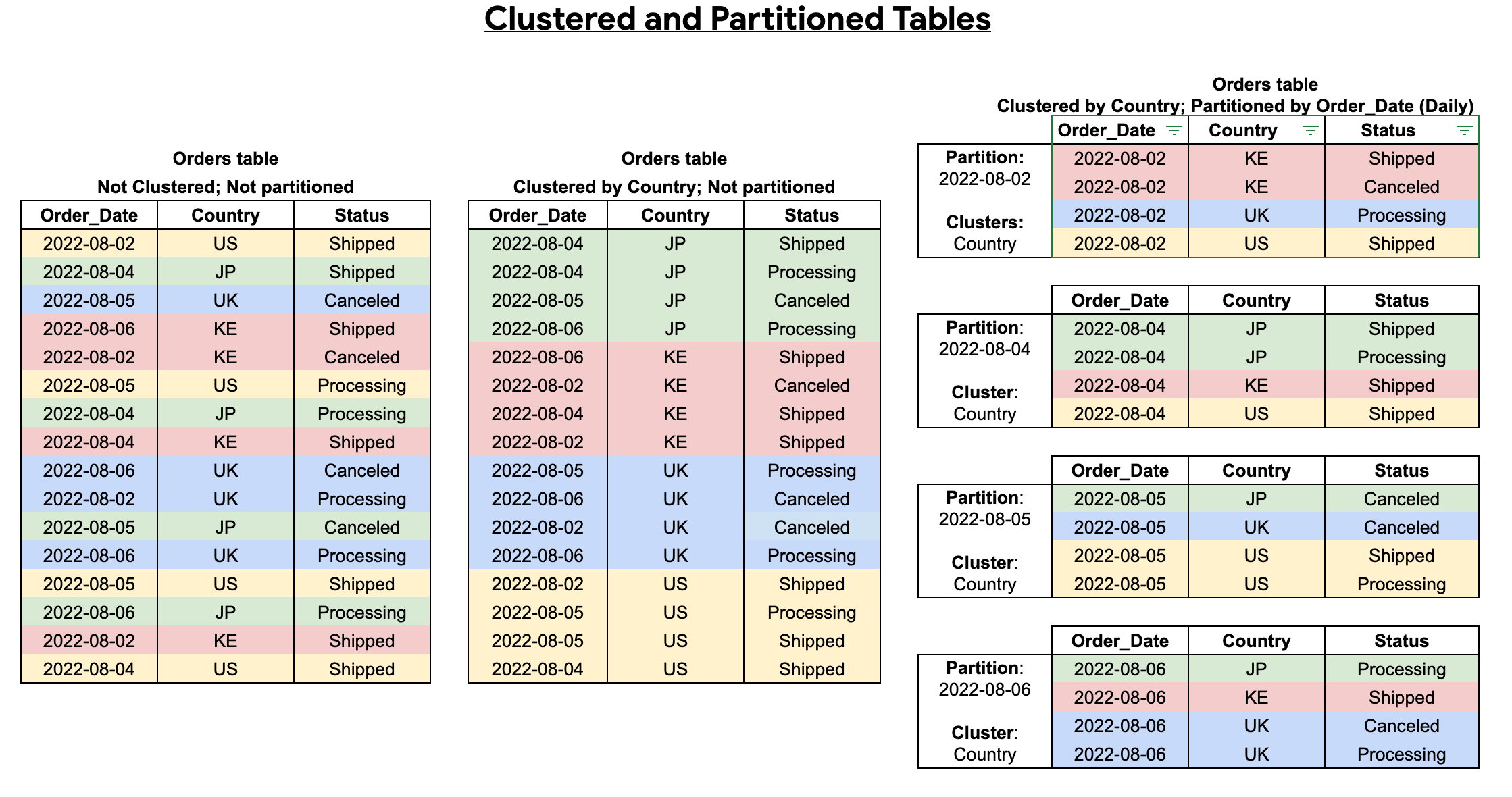
Menggabungkan tabel berpartisi dan yang dikelompokkan
Anda dapat menggabungkan pengelompokan tabel dengan partisi tabel untuk mendapatkan pengurutan yang lebih mendetail guna mengoptimalkan kueri lebih lanjut.
Dalam tabel berpartisi, data disimpan dalam blok fisik, yang masing-masing menyimpan satu partisi data. Setiap tabel berpartisi mempertahankan berbagai metadata tentang properti pengurutan di semua operasi yang mengubahnya. Dengan metadata, BigQuery akan dapat memperkirakan biaya kueri dengan lebih akurat sebelum kueri dijalankan. Namun, dengan membuat partisi akan mengharuskan BigQuery untuk mengelola lebih banyak metadata dibandingkan dengan tabel yang tidak berpartis. Seiring dengan bertambahnya jumlah partisi, jumlah metadata yang harus dipertahankan juga akan meningkat.
Saat membuat tabel yang dikelompokkan dan berpartisi, Anda dapat memperoleh pengurutan yang lebih detail, seperti yang ditunjukkan pada diagram berikut:
Contoh
Anda memiliki tabel yang dikelompokkan bernama ClusteredSalesData. Tabel berpartisi
berdasarkan kolom timestamp, dan dikelompokkan menurut kolom customer_id. Data dikelola ke dalam rangkaian blok berikut:
| ID partisi | ID blok | Nilai minimum untuk customer_id dalam blok | Nilai maksimum untuk customer_id dalam blok |
|---|---|---|---|
| 20160501 | B1 | 10000 | 19999 |
| 20160501 | B2 | 20000 | 24999 |
| 20160502 | B3 | 15000 | 17999 |
| 20160501 | B4 | 22000 | 27999 |
Anda menjalankan kueri berikut terhadap tabel. Kueri berisi filter pada
kolom customer_id.
SELECT SUM(totalSale) FROM `mydataset.ClusteredSalesData` WHERE customer_id BETWEEN 20000 AND 23000 AND DATE(timestamp) = "2016-05-01"
Kueri sebelumnya melibatkan langkah-langkah berikut:
- Memindai kolom
timestamp,customer_id, dantotalSaledalam blok B2 dan B4. - Memangkas blok B3 karena predikat
filter
DATE(timestamp) = "2016-05-01"pada kolom partisitimestamp. - Memangkas blok B1 karena predikat
filter
customer_id BETWEEN 20000 AND 23000pada kolom pengelompokancustomer_id.
Pengelompokan ulang otomatis
Saat data ditambahkan ke tabel yang dikelompokkan, data baru akan disusun ke dalam blok, yang dapat membuat blok penyimpanan baru atau mengupdate blok yang ada. Pengoptimalan blok diperlukan untuk performa kueri dan penyimpanan yang optimal karena data baru mungkin tidak dikelompokkan dengan data yang ada dan memiliki nilai cluster yang sama.
Untuk mempertahankan karakteristik performa tabel yang dikelompokkan, BigQuery akan melakukan pengelompokan ulang otomatis di latar belakang. Untuk tabel berpartisi, pengelompokan dipertahankan untuk data dalam cakupan setiap partisi.
Batasan
- Hanya GoogleSQL yang didukung untuk membuat kueri tabel yang dikelompokkan dan untuk menulis hasil kueri ke tabel yang dikelompokkan.
- Anda hanya dapat menentukan hingga empat kolom pengelompokan. Jika Anda membutuhkan kolom tambahan, sebaiknya gabungkan pengelompokan dengan partisi.
- Saat menggunakan kolom jenis
STRINGuntuk pengelompokan, BigQuery hanya menggunakan 1.024 karakter pertama untuk mengelompokkan data. Nilai dalam kolom itu sendiri bisa lebih dari 1.024 karakter. - Jika Anda mengubah tabel yang tidak dikelompokkan dan sudah ada untuk dikelompokkan, data yang ada tidak akan dikelompokkan secara otomatis. Hanya data baru yang disimpan menggunakan
kolom yang dikelompokkan yang dapat mengalami pengelompokan ulang otomatis. Untuk mengetahui informasi
selengkapnya tentang pengelompokan ulang data yang ada menggunakan
pernyataan
UPDATE, lihat Mengubah spesifikasi pengelompokan.
Kuota dan batas tabel yang dikelompokkan
BigQuery membatasi penggunaan resource Google Cloud bersama dengan kuota dan batas, termasuk batasan pada operasi tabel tertentu atau jumlah tugas yang dijalankan dalam satu hari.
Saat menggunakan fitur tabel yang dikelompokkan dengan tabel berpartisi, Anda akan tunduk pada batas tabel berpartisi.
Kuota dan batas juga berlaku untuk berbagai jenis tugas yang dapat Anda jalankan terhadap tabel yang dikelompokkan. Untuk mengetahui informasi tentang kuota tugas yang berlaku untuk tabel Anda, lihat Tugas di "Kuota dan Batas".
Harga tabel yang dikelompokkan
Saat membuat dan menggunakan tabel yang dikelompokkan di BigQuery, biaya yang ditagih kepada Anda ditentukan berdasarkan jumlah data yang disimpan dalam tabel dan di kueri yang Anda jalankan terhadap data tersebut. Untuk mengetahui informasi selengkapnya, lihat Harga penyimpanan dan Harga Kueri.
Seperti operasi tabel BigQuery lainnya, operasi tabel yang dikelompokkan akan memanfaatkan operasi bebas BigQuery seperti pemuatan batch, penyalinan tabel, pengelompokan ulang otomatis, dan ekspor data. Operasi ini tunduk pada kuota dan batas BigQuery. Untuk mengetahui informasi tentang operasi gratis, lihat Operasi gratis.
Untuk contoh harga tabel yang dikelompokkan secara mendetail, lihat Perkirakan biaya penyimpanan dan kueri.
Keamanan tabel
Untuk mengontrol akses ke tabel di BigQuery, lihat Mengontrol akses ke resource dengan IAM.
Langkah berikutnya
- Untuk mempelajari cara membuat dan menggunakan tabel yang dikelompokkan, lihat Membuat dan menggunakan tabel yang dikelompokkan.
- Untuk mengetahui informasi tentang membuat kueri tabel yang dikelompokkan, lihat Membuat kueri tabel yang dikelompokkan.