Cloud Storage データを BigQuery に読み込む
BigQuery Data Transfer Service for Cloud Storage コネクタを使用して、Cloud Storage から BigQuery にデータを読み込むことができます。BigQuery Data Transfer Service を使用すると、Cloud Storage から BigQuery に最新のデータを追加する定期的な転送ジョブをスケジュールできます。
始める前に
Cloud Storage のデータ転送を作成する前に、次のことを行います。
- BigQuery Data Transfer Service の有効化に必要なすべての操作が完了していることを確認します。
- Cloud Storage URI を取得します。
- データを保存する BigQuery データセットを作成します。
- データ転送用に宛先テーブルを作成し、スキーマ定義を指定します。
- 顧客管理の暗号鍵(CMEK)を指定する場合は、サービス アカウントに暗号化と復号の権限があることと、CMEK の使用に必要な Cloud KMS 鍵のリソース ID があることを確認してください。CMEK が BigQuery Data Transfer Service とどのように連携するかについては、転送で暗号鍵を指定するをご覧ください。
制限事項
Cloud Storage から BigQuery への繰り返しのデータ転送には、次の制限があります。
- データ転送のワイルドカードまたはランタイム パラメータで定義したパターンに一致するファイルはすべて、宛先テーブルに対して定義したスキーマと同じスキーマを共有している必要があり、そうでない場合は転送が失敗します。転送後にテーブル スキーマを変更して再度転送を実行した場合も、転送が失敗します。
- Cloud Storage オブジェクトはバージョニングが可能ですが、アーカイブ済みの Cloud Storage オブジェクトは BigQuery データ転送ではサポートされていないことに注意してください。転送されるオブジェクトは、ライブデータである必要があります。
- Cloud Storage から BigQuery へのデータを個別に読み込む場合と異なり、継続的なデータ転送では、転送を設定する前に宛先テーブルを作成する必要があります。CSV ファイルと JSON ファイルについては、テーブル スキーマも事前に定義する必要があります。BigQuery では、繰り返しのデータ転送プロセスの一環としてテーブルを作成することはできません。
- Cloud Storage からのデータ転送では、書き込み設定パラメータがデフォルトで
APPENDに設定されます。このモードでは、変更されていないファイルを BigQuery に読み込むことができるのは 1 回だけです。ファイルのlast modification timeプロパティが更新されると、ファイルが再読み込みされます。 BigQuery Data Transfer Service では、データ転送中に Cloud Storage ファイルが変更された場合、すべてのファイルが転送されることや、ファイルが 1 回のみ転送されることは保証されません。Cloud Storage バケットから BigQuery にデータを読み込む際には、次の制限があります。
BigQuery では外部データソースに対して整合性が保証されません。クエリの実行中に基になるデータを変更すると、予期しない動作が発生する可能性があります。
BigQuery では、Cloud Storage オブジェクトのバージョニングはサポートされていません。Cloud Storage URI に世代番号を含めると、読み込みジョブは失敗します。
Cloud Storage のソースデータの形式によっては、追加の制限が適用される場合があります。詳しくは以下をご覧ください。
Cloud Storage バケットは、BigQuery の宛先データセットのリージョンまたはマルチリージョンと互換性のあるロケーションに存在する必要があります。これはコロケーションと呼ばれます。詳細については、Cloud Storage 転送のデータのロケーションをご覧ください。
最小間隔
- ソースファイルは、ファイル作成後の最小間隔なしで、すぐに取得され転送されます。
- 定期的なデータ転送の最小間隔は 15 分です。デフォルトの定期的なデータ転送の間隔は 24 時間です。
- イベント ドリブン転送を設定して、より短い間隔でデータ転送を自動的にスケジュールできます。
必要な権限
BigQuery にデータを読み込む場合は、新規または既存の BigQuery のテーブルやパーティションにデータを読み込むための権限が必要です。Cloud Storage からデータを読み込む場合は、データが格納されているバケットへのアクセス権も必要です。次の必要な権限があることを確認します。
BigQuery: データ転送を作成するユーザーまたはサービス アカウントに、BigQuery で次の権限が付与されていることを確認します。
- データ転送を作成する
bigquery.transfers.update権限 bigquery.datasets.getとbigquery.datasets.updateの両方(抽出先データセットに対する権限)
bigquery.transfers.update権限、bigquery.datasets.update権限、bigquery.datasets.get権限は IAM 事前定義ロールbigquery.adminに含まれています。BigQuery Data Transfer Service での IAM ロールの詳細については、アクセス制御をご覧ください。- データ転送を作成する
Cloud Storage: 個々のバケット以上のレベルで
storage.objects.get権限が必要です。URI のワイルドカードを使用する場合はstorage.objects.list権限も必要です。転送が完了するたびにソースファイルを削除する場合は、storage.objects.delete権限も必要です。これらすべての権限は、事前定義の IAM のロールstorage.objectAdminに含まれています。
Cloud Storage の転送を設定する
BigQuery Data Transfer Service で Cloud Storage データ転送を作成するには:
コンソール
Google Cloud コンソールの [データ転送] ページに移動します。
[転送を作成] をクリックします。
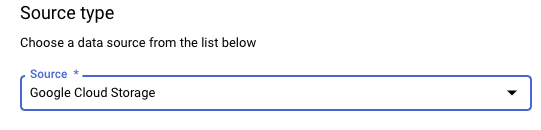
[ソースタイプ] セクションで、[ソース] として [Google Cloud Storage] を選択します。
[転送構成名] セクションの [表示名] に、データ転送の名前(例:
My Transfer)を入力します。転送名には、後で修正が必要になった場合に識別できる任意の名前を使用できます。
[スケジュール オプション] セクションで、[繰り返しの頻度] を選択します。
[時間]、[日]、[週]、[月] を選択する場合は、頻度も指定する必要があります。[カスタム] を選択して、カスタムの繰り返しの頻度を指定することもできます。[すぐに開始] を選択するか、[設定した時刻に開始] を選択して開始日と実行時間を指定できます。
[オンデマンド] を選択した場合、手動で転送をトリガーしたときにこのデータ転送が実行されます。
[イベント ドリブン] を選択した場合は、Pub/Sub サブスクリプションも指定する必要があります。サブスクリプション名を選択するか、[サブスクリプションの作成] をクリックします。このオプションを使用すると、イベントが Pub/Sub サブスクリプションに到達したときに転送実行をトリガーするイベント ドリブン転送が有効になります。
[転送先の設定] セクションの [宛先データセット] で、データを保存するために作成したデータセット ID を選択します。
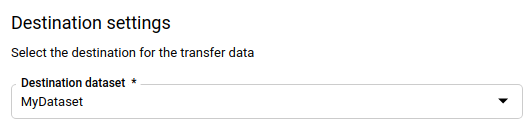
[データソースの詳細] セクションで、次の操作を行います。
- [宛先テーブル] に宛先テーブルの名前を入力します。宛先テーブルは、テーブルの命名規則に従う必要があります。宛先テーブル名ではパラメータもサポートされています。
- [Cloud Storage URI] に Cloud Storage URI を入力します。ワイルドカードとパラメータがサポートされています。URI がどのファイルにも一致しない場合、宛先テーブルでデータは上書きされません。
[書き込み設定] の場合、次から選択します。
- APPEND で、既存の宛先テーブルに新しいデータを追加します。APPEND は、[書き込み設定] のデフォルト値です。
- MIRROR で、各データ転送の実行中に宛先テーブル内のデータを上書きします。
BigQuery Data Transfer Service が APPEND または MIRROR を使用してデータを取り込む方法の詳細については、Cloud Storage の転送データの取り込みをご覧ください。
writeDispositionフィールドの詳細については、JobConfigurationLoadをご覧ください。データ転送が完了するたびにソースファイルを削除する場合は、[Delete source files after transfer] をオンにします。削除ジョブはベスト エフォート ベースです。最初にソースファイルの削除が失敗すると、削除ジョブは再試行されません。
[転送オプション] セクションで、次の操作を行います。
- [All Formats] セクション:
- [許容されるエラー数] には、BigQuery がジョブの実行中に無視できる不良レコードの最大数を入力します。不良レコード数がこの値を超えると、ジョブ結果で
invalidエラーが返され、ジョブが失敗します。デフォルト値は0です。 - (省略可)[Decimal target type] に、ソースの 10 進数値を変換できる、有効な SQL データ型のカンマ区切りのリストを入力します。変換にどの SQL データ型を選択するかは、次の条件によって決まります。
- 変換用に選択されるデータ型は、次のリスト内で、ソースデータの精度とスケールがサポートされる最初のデータ型になります。順序は
NUMERIC、BIGNUMERIC、STRINGの順になります。 - リストされたデータ型が精度とスケールをサポートしていない場合は、指定されたリストの最も広い範囲をサポートするデータ型が選択されます。ソースデータの読み取り時に、値がサポートされている範囲を超えると、エラーがスローされます。
- データ型
STRINGでは、すべての精度とスケールの値がサポートされています。 - このフィールドが空の場合、デフォルトのデータ型は、ORC では
NUMERIC,STRING、その他のファイル形式ではNUMERICになります。 - このフィールドに重複するデータ型を含めることはできません。
- このフィールドでリストするデータ型の順序は無視されます。
- 変換用に選択されるデータ型は、次のリスト内で、ソースデータの精度とスケールがサポートされる最初のデータ型になります。順序は
- [許容されるエラー数] には、BigQuery がジョブの実行中に無視できる不良レコードの最大数を入力します。不良レコード数がこの値を超えると、ジョブ結果で
- データ転送で宛先テーブルのスキーマに適合しないデータが削除されるようにする場合は、[JSON, CSV] の [不明な値を無視] をオンにします。
- データ転送で Avro の論理型を対応する BigQuery データ型に変換する場合は、[AVRO] の [Use avro logical types] をオンにします。デフォルトの動作では、ほとんどの型で
logicalType属性を無視し、代わりに基になる Avro 型を使用します。 [CSV] セクション:
- [フィールド区切り文字] に、フィールドを区切る文字を入力します。デフォルト値はカンマ(,)です。
- [引用符文字] に、CSV ファイル内のデータ セクションを囲む引用符として使用する文字を入力します。デフォルト値は二重引用符(
")です。 - [スキップするヘッダー行] に、インポートの対象外にするソースファイル内のヘッダー行の数を入力します。デフォルト値は
0です。 - 引用符で囲まれたフィールド内で改行を許可するには、[引用符で囲まれた改行を許可] をオンにします。
NULLABLE列がない行をデータ転送できるようにする場合は、[ジャグ行を許可] をオンにします。
詳細については、CSV 専用オプションをご覧ください。
- [All Formats] セクション:
[サービス アカウント] メニューで、 Google Cloud プロジェクトに関連付けられているサービス アカウントからサービス アカウントを選択します。ユーザー認証情報を使用する代わりに、サービス アカウントをデータ転送に関連付けることができます。データ転送でサービス アカウントを使用する方法の詳細については、サービス アカウントの使用をご覧ください。
- フェデレーション ID でログインした場合、データ転送を作成するにはサービス アカウントが必要です。Google アカウントでログインした場合、データ転送用のサービス アカウントは省略可能です。
- サービス アカウントには、BigQuery と Cloud Storage の両方に対して必要な権限が付与されている必要があります。
省略可: [通知オプション] セクションで、次の操作を行います。
省略可: CMEK を使用する場合は、[詳細オプション] セクションで [顧客管理の暗号鍵] を選択します。使用可能な CMEK のリストが表示され、ここから選択できます。CMEK が BigQuery Data Transfer Service と連携する仕組みについては、転送で暗号鍵を指定するをご覧ください。
[保存] をクリックします。
bq
bq mk コマンドを入力して、転送作成フラグ --transfer_config を構成します。次のフラグも必要です。
--data_source--display_name--target_dataset--params
オプションのフラグ:
--destination_kms_key: このデータ転送に顧客管理の暗号鍵(CMEK)を使用する場合、Cloud KMS 鍵の鍵のリソース ID を指定します。CMEK が BigQuery Data Transfer Service と連携する仕組みについては、転送で暗号鍵を指定するをご覧ください。--service_account_name: ユーザー アカウントの代わりに、Cloud Storage の転送認証に使用するサービス アカウントを指定します。
bq mk \ --transfer_config \ --project_id=PROJECT_ID \ --data_source=DATA_SOURCE \ --display_name=NAME \ --target_dataset=DATASET \ --destination_kms_key="DESTINATION_KEY" \ --params='PARAMETERS' \ --service_account_name=SERVICE_ACCOUNT_NAME
ここで
- PROJECT_ID はプロジェクト ID です。
--project_idで特定のプロジェクトを指定しない場合は、デフォルトのプロジェクトが使用されます。 - DATA_SOURCE はデータソースです(例:
google_cloud_storage)。 - NAME は、データ転送構成の表示名です。転送名には、後で修正が必要になった場合に識別できる任意の名前を使用できます。
- DATASET は、転送構成の抽出先データセットです。
- DESTINATION_KEY: Cloud KMS 鍵のリソース ID(例:
projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name)。 - PARAMETERS には、作成される転送構成のパラメータを JSON 形式で指定します。(例:
--params='{"param":"param_value"}')。destination_table_name_template: 宛先 BigQuery テーブルの名前。data_path_template: 転送するファイルが格納されている Cloud Storage URI。ワイルドカードとパラメータがサポートされています。write_disposition: 一致するファイルを宛先テーブルに追加するか、完全にミラーリングするかを決定します。サポートされている値は、APPENDとMIRRORです。BigQuery Data Transfer Service が Cloud Storage の転送でデータを追加またはミラーリングする方法については、Cloud Storage 転送のデータの取り込みをご覧ください。file_format: 転送するファイルの形式。形式は、CSV、JSON、AVRO、PARQUET、ORCのいずれかです。デフォルト値はCSVです。max_bad_records: 任意のfile_format値について、無視できる不良レコードの最大数。デフォルト値は0です。decimal_target_types: 任意のfile_format値に対する、ソースの 10 進数値を変換できる、有効な SQL データ型のカンマ区切りのリスト。このフィールドを指定しない場合は、ORCではデータ型はデフォルトで"NUMERIC,STRING"になり、他のファイル形式では"NUMERIC"になります。ignore_unknown_values: 任意のfile_formatの値に対してTRUEに設定すると、スキーマに一致しない値を含む行が許容されます。詳細については、JobConfigurationLoad参照テーブルのignoreUnknownvaluesフィールドの詳細をご覧ください。use_avro_logical_types:AVROfile_formatの値に対してTRUEに設定すると、元の型(例:INTEGER)のみを使用するのではなく、論理型を対応する型に変換します(例:TIMESTAMP)。parquet_enum_as_string:PARQUETfile_formatの値に対してTRUEに設定すると、PARQUETENUM論理型を、デフォルトのBYTESではなくSTRINGと推測します。parquet_enable_list_inference:PARQUETfile_formatの値に対してTRUEに設定すると、PARQUETLIST論理型専用のスキーマ推定を使用します。reference_file_schema_uri: リーダー スキーマを含む参照ファイルへの URI パス。field_delimiter:CSVfile_formatの値に対する、フィールドを区切る文字。デフォルト値はカンマ(,)です。quote:CSVfile_formatの値に対して、CSV ファイル内のデータ セクションを引用符で囲むために使用される文字。デフォルト値は二重引用符(")です。skip_leading_rows:CSVfile_formatの値に対して、インポート対象外にする先頭ヘッダー行の数を指定します。デフォルト値は 0 です。allow_quoted_newlines:CSVfile_formatの値に対してTRUEに設定すると、引用符で囲まれたフィールド内での改行が許可されます。allow_jagged_rows:CSVfile_formatの値に対してTRUEに設定すると、末尾のオプションの列が欠落している行を受け入れます。欠損値にはNULLが入力されます。preserve_ascii_control_characters:CSVfile_formatの値に対してTRUEに設定すると、埋め込みの ASCII 制御文字を保持します。encoding:CSVのエンコード タイプを指定します。サポートされる値はUTF8、ISO_8859_1、UTF16BE、UTF16LE、UTF32BE、UTF32LEです。delete_source_files:TRUEに設定すると、転送が完了するたびにソースファイルを削除します。ソースファイルの削除の初めての試行が失敗した場合、削除ジョブは再実行されません。デフォルト値はFALSEです。
- SERVICE_ACCOUNT_NAME は、転送の認証に使用されるサービス アカウント名です。サービス アカウントは、転送の作成に使用した
project_idが所有している必要があります。また、必要な権限がすべて付与されている必要があります。
たとえば、次のコマンドは、data_path_template の値に gs://mybucket/myfile/*.csv を使用し、ターゲット データセットとして mydataset、file_format として CSV を指定した、My Transfer という名前の Cloud Storage データ転送を作成します。この例では、file_format の CSV 値に関連するオプションのパラメータとして、デフォルト以外の値を使用しています。
このデータ転送はデフォルトのプロジェクトで作成されます。
bq mk --transfer_config \
--target_dataset=mydataset \
--project_id=myProject \
--display_name='My Transfer' \
--destination_kms_key=projects/myproject/locations/mylocation/keyRings/myRing/cryptoKeys/myKey \
--params='{"data_path_template":"gs://mybucket/myfile/*.csv",
"destination_table_name_template":"MyTable",
"file_format":"CSV",
"max_bad_records":"1",
"ignore_unknown_values":"true",
"field_delimiter":"|",
"quote":";",
"skip_leading_rows":"1",
"allow_quoted_newlines":"true",
"allow_jagged_rows":"false",
"delete_source_files":"true"}' \
--data_source=google_cloud_storage \
--service_account_name=abcdef-test-sa@abcdef-test.iam.gserviceaccount.com projects/862514376110/locations/us/transferConfigs/ 5dd12f26-0000-262f-bc38-089e0820fe38
コマンドを実行すると、次のようなメッセージが表示されます。
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
指示に従って、認証コードをコマンドラインに貼り付けます。
API
projects.locations.transferConfigs.create メソッドを使用して、TransferConfig リソースのインスタンスを指定します。
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
転送に使用する暗号鍵を指定する
転送実行のデータを暗号化する顧客管理の暗号鍵(CMEK)を指定できます。CMEK を使用して、Cloud Storage からの転送をサポートできます。転送で CMEK を指定すると、BigQuery Data Transfer Service は取り込まれたデータの中間ディスク上キャッシュに CMEK を適用して、データ転送ワークフロー全体が CMEK 遵守になるようにします。
最初に CMEK で作成されていなかった既存の転送は、更新して CMEK を追加することはできません。たとえば、最初にデフォルトの方法で暗号化されていた宛先テーブルを CMEK で暗号化されるように変更することはできません。逆に、CMEK で暗号化された宛先テーブルを別のタイプの暗号化に変更することはできません。
転送構成が CMEK 暗号化を使用して最初に作成された場合は、転送の CMEK を更新できます。転送構成の CMEK を更新すると、BigQuery Data Transfer Service は転送の次回実行時に CMEK を宛先テーブルに伝播します。BigQuery Data Transfer Service は、古い CMEK を転送中に新しい CMEK に置き換えます。詳細については、転送の更新をご覧ください。
プロジェクトのデフォルト鍵を使用することもできます。転送でプロジェクトのデフォルト鍵を指定すると、BigQuery Data Transfer Service は、新しい転送構成のデフォルト鍵としてプロジェクトのデフォルト鍵を使用します。
手動で転送をトリガーする
Cloud Storage から自動でデータ転送がスケジュールされるだけでなく、転送を手動でトリガーして追加のデータファイルを読み込むこともできます。
転送の構成がパラメータ化されたランタイムである場合、追加の転送を開始する期間を指定する必要があります。
データ転送をトリガーするには:
コンソール
Google Cloud コンソールの [BigQuery] ページに移動します。
[データ転送] をクリックします。
リストからデータ転送を選択します。
[今すぐ転送を実行] または [バックフィルのスケジュール構成] をクリックします(パラメータ化されたランタイムの転送構成の場合)。
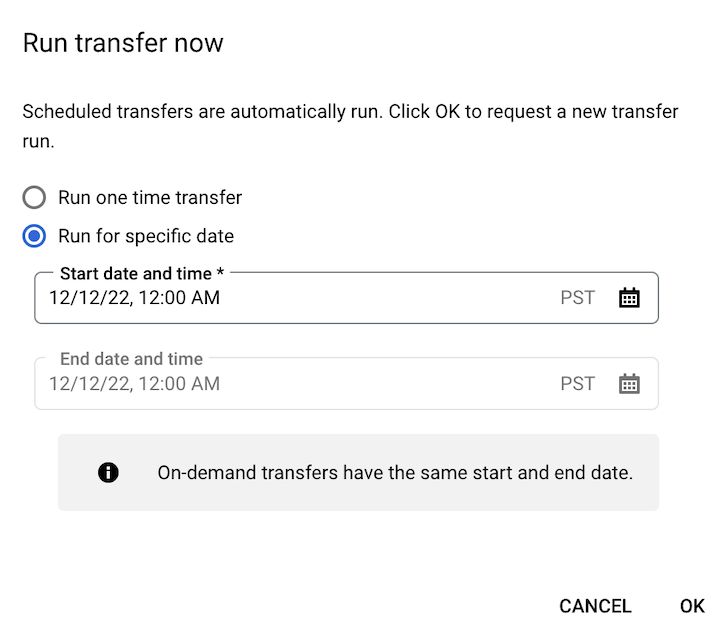
[今すぐ転送を実行] をクリックした場合は、[1 回限りの転送を実行] または [特定の日付で実行] を選択します(該当する場合)。[特定の日付で実行] を選択した場合は、具体的な日時を選択します。
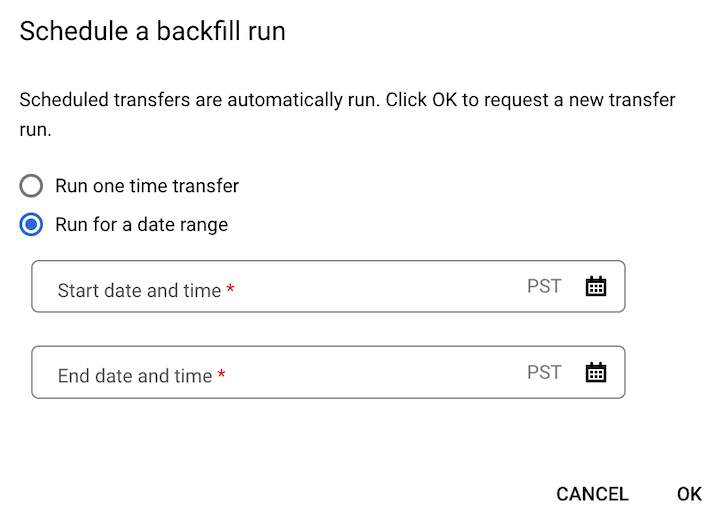
[バックフィルをスケジュール] をクリックした場合は、[1 回限りの転送を実行] または [期間を指定して実行] を適宜選択します。[期間を指定して実行] を選択した場合は、開始日時と終了日時を選択します。
[OK] をクリックします。
bq
bq mk コマンドを入力して、--transfer_run フラグを指定します。--run_time フラグ、または --start_time フラグと --end_time フラグを使用できます。
bq mk \ --transfer_run \ --start_time='START_TIME' \ --end_time='END_TIME' \ RESOURCE_NAME
bq mk \ --transfer_run \ --run_time='RUN_TIME' \ RESOURCE_NAME
ここで
START_TIME と END_TIME は、
Zで終わるタイムスタンプか、有効なタイムゾーンのオフセットを含むタイムスタンプです。次に例を示します。2017-08-19T12:11:35.00Z2017-05-25T00:00:00+00:00
RUN_TIME は、データ転送実行をスケジュールする時間を指定するタイムスタンプです。現在の時刻に対して 1 回限りの転送を実行する場合は、
--run_timeフラグを使用できます。RESOURCE_NAME は、転送のリソース名(転送構成)です(例:
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7)。転送のリソース名がわからない場合は、bq ls --transfer_config --transfer_location=LOCATIONコマンドを実行してリソース名を確認します。
API
projects.locations.transferConfigs.startManualRuns メソッドを使用し、parent パラメータで転送構成のリソースを指定します。
次のステップ
- Cloud Storage の転送でのランタイム パラメータをご覧ください。
- BigQuery Data Transfer Service の詳細を確認する。